
Leerpad
Google Cloud Digital Leader
8 Hr
Als je in een datateam werkt, klinkt dit scenario vast bekend: je backlog puilt uit van de ad-hocverzoeken. Businessgebruikers hebben voortdurend simpele variaties op bestaande rapporten nodig en vragen: "Kun je dit groeperen op productcategorie?" of "Hoe verhoudt dit zich tot vorige maand?" Terwijl zij in de wachtrij staan voor een antwoord, worden je data-engineers en analisten bedolven onder repetitieve SQL-taken.
Met Conversational Analytics in BigQuery kun je die flessenhals eindelijk verplaatsen. Deze functie brengt een door AI aangedreven redeneermotor rechtstreeks naar BigQuery Studio, waardoor gebruikers vragen in natuurlijke taal kunnen stellen en direct data, grafieken en gegenereerde SQL ontvangen.
In deze gids leer je hoe je conversational analytics in BigQuery instelt en gebruikt. Je bouwt, configureert en verfijnt je eigen data-agents, zodat je organisatie veilig met de data kan chatten.
Conversational analytics verschuift de data-interactie van handmatige SQL-queries naar gesprekken in natuurlijke taal. In plaats van SELECT-statements te schrijven, praat je met een data-agent die je zakelijke context begrijpt en antwoorden geeft die zijn onderbouwd met je echte tabellen.
Dit is niet zomaar een simpele text-to-SQL-parser; het is een grote stap richting échte datagedemocratiseerd gebruik.
Het stelt niet-technische gebruikers in staat om zelfstandig realtime inzichten te krijgen en geeft dataprofessionals een snelle manier om datasets te verkennen en rapportages te automatiseren.
De kern van BigQuery’s conversational analytics is een redeneermotor die wordt aangedreven door de Gemini-modelreeks. Data-agents gebruiken een gestructureerde pipeline in meerdere stappen om te zorgen dat inzichten gebaseerd zijn op jouw specifieke datacontent:
Google Cloud biedt conversational analytics op verschillende lagen van je datastack. De juiste instap kiezen hangt af van je gebruikers en waar je businesslogica zich bevindt:
|
Functie |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (via BigQuery Agents) |
|
Beste voor |
Datateams, analisten en developers die maatwerkapplicaties bouwen |
Businessgebruikers die gecontroleerde, dashboardklare inzichten nodig hebben |
Businessgebruikers die de voorkeur geven aan lichte BI-rapportage |
|
Verankeringsmethode |
Directe warehouse-schema’s, tabelmetadata en geverifieerde queries |
LookML (semantische laag) |
Direct gekoppeld aan vooraf gebouwde BigQuery-data-agents |
|
Data-toegang |
Kan gestructureerde, voorspellende (ML) en ongestructureerde data analyseren |
Strikt gestructureerde, gemodelleerde data |
Gestructureerde data |
|
Release-status |
Preview (per mei 2026) |
Algemeen beschikbaar |
Preview |
Welke route kies je?
Deze tutorial richt zich op BigQuery als de snelste manier voor datateams om agents te prototypen en in productie te brengen, precies daar waar de data zich bevindt.
Het is belangrijk om de architectuur van een data-agent te begrijpen voordat je hem instelt. In de Google Cloud-omgeving is een data-agent de centrale abstractielaag. Hij combineert BigQuery-assets met de redeneercapaciteiten van de Gemini-modellenfamilie.
In plaats van ruwe tabellen direct bloot te leggen, configureert een data-agent alles wat het model nodig heeft om vragen te interpreteren, veilige SQL te genereren en betrouwbare antwoorden te geven. Deze combinatie van databronnen, instructies en geverifieerde logica maakt BigQuery’s conversational analytics betrouwbaarder dan standaard text-to-SQL-tools.
Kennisbronnen zijn de funderingslaag van elke data-agent. Ze definiëren precies welke data de agent mag benaderen en bevragen.
Assettypen: Tables, Views en User Defined Functions (UDF’s) kunnen als kennisbron worden gekoppeld.
Schaalbaarheid: Meerdere kennisbronnen kunnen aan één agent gekoppeld worden. Hierdoor kan de agent informatie uit verschillende bedrijfsdomeinen combineren.
Toegangsbeheer: Door specifieke kennisbronnen te definiëren zorg je dat de agent alleen binnen geautoriseerde data opereert.
De intelligentie van een agent hangt af van de geboden context. Dit is cruciaal om een generiek model de taal van een bedrijf te laten begrijpen.
Door aangepaste instructies, synoniemen en businessglossaria te definiëren, wordt de agent geaard in een specifiek domein. Zo kun je de agent bijvoorbeeld leren dat "Top Customers" verwijst naar gebruikers met een lifetime value (LTV) van meer dan $ 1.000.
Belangrijke verankeringselementen:
Aangepaste instructies: Bied richtlijnen op hoog niveau, zoals "Sluit interne testaccounts altijd uit in omzetrapporten."
Businessglossaria: Koppel technische termen aan natuurlijke taal, bijvoorbeeld store_id aan "Vestigingslocatie".
Veldmetadata: Omschrijvingen die de agent helpen de nuances van specifieke variabelen te begrijpen, zoals "Bruto-omzet" versus "Nettowinst".
Hoe beter je instructies en metadata, hoe hoger de nauwkeurigheid van de agent.
Geverifieerde queries, voorheen bekend als Golden Queries, zijn vooraf gedefinieerde vraag-antwoordparen die als bron van waarheid dienen. Door specifieke vragen te koppelen aan door experts getoetste SQL gebruikt de agent de juiste joinpaden en filters voor kritieke KPI’s.
Deze queries kunnen BigQuery ML- (BQML) functies bevatten. Zo kan de agent geavanceerde verzoeken afhandelen, zoals churn-voorspellingen of verkoopprognoses genereren, met exact de modelparameters die door data scientists zijn gedefinieerd. Zodra ze zijn geverifieerd, worden deze assets beheerd via de Dataplex Universal Catalog, wat consistentie in de hele organisatie waarborgt.
Nu je de bouwstenen begrijpt, gaan we daadwerkelijk je eerste data-agent bouwen en configureren.
Zorg ervoor dat je aan de volgende vereisten voldoet om onze tutorial te volgen:
Voordat je je eerste agent bouwt, moet je je Google Cloud-project configureren en controleren of je gebruikersaccount de benodigde machtigingen heeft. Data-agents werken als een laag bovenop je bestaande data, dus een correcte IAM-configuratie (Identity and Access Management) is cruciaal voor zowel beveiliging als functionaliteit.
Volg deze stappen:
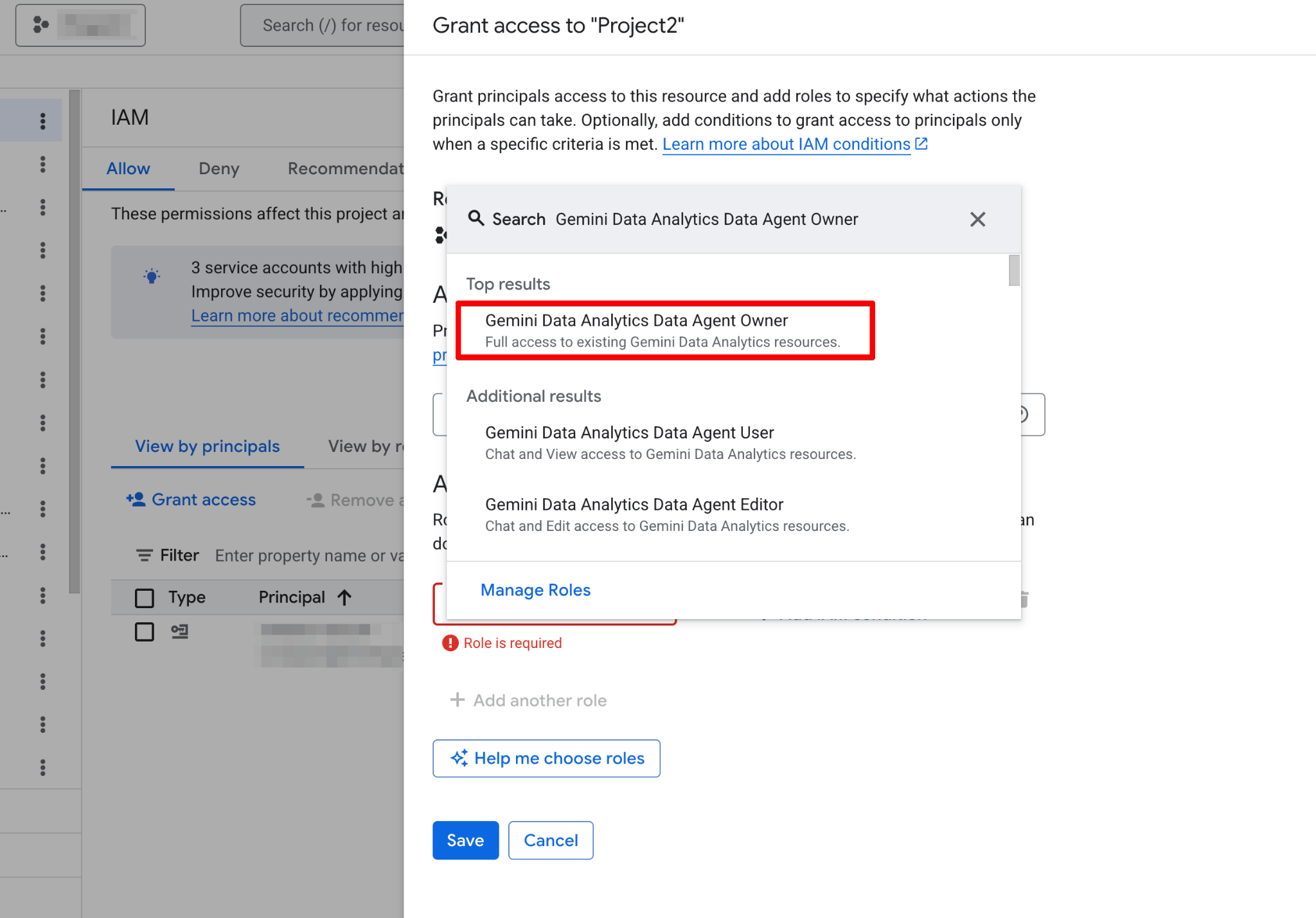
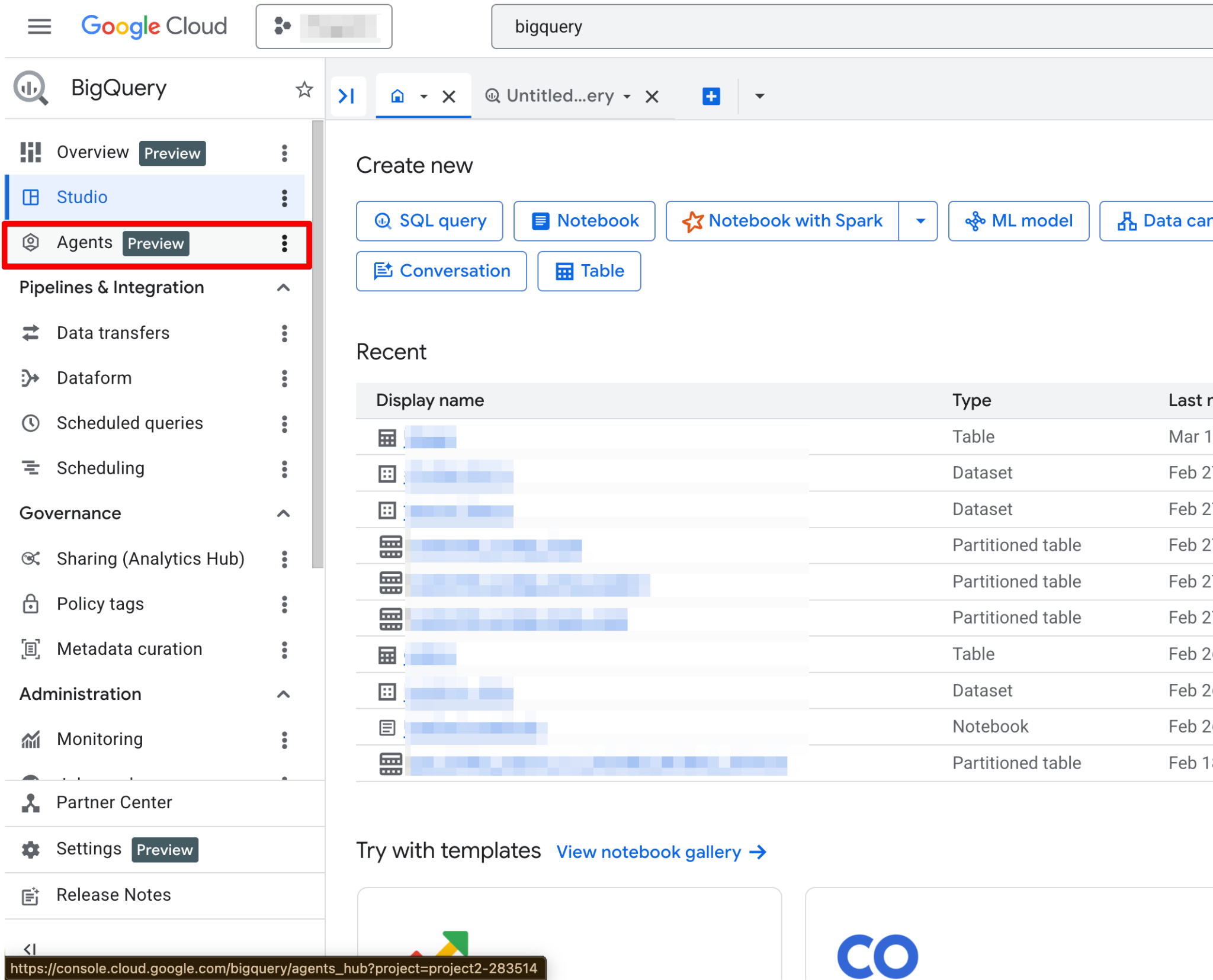
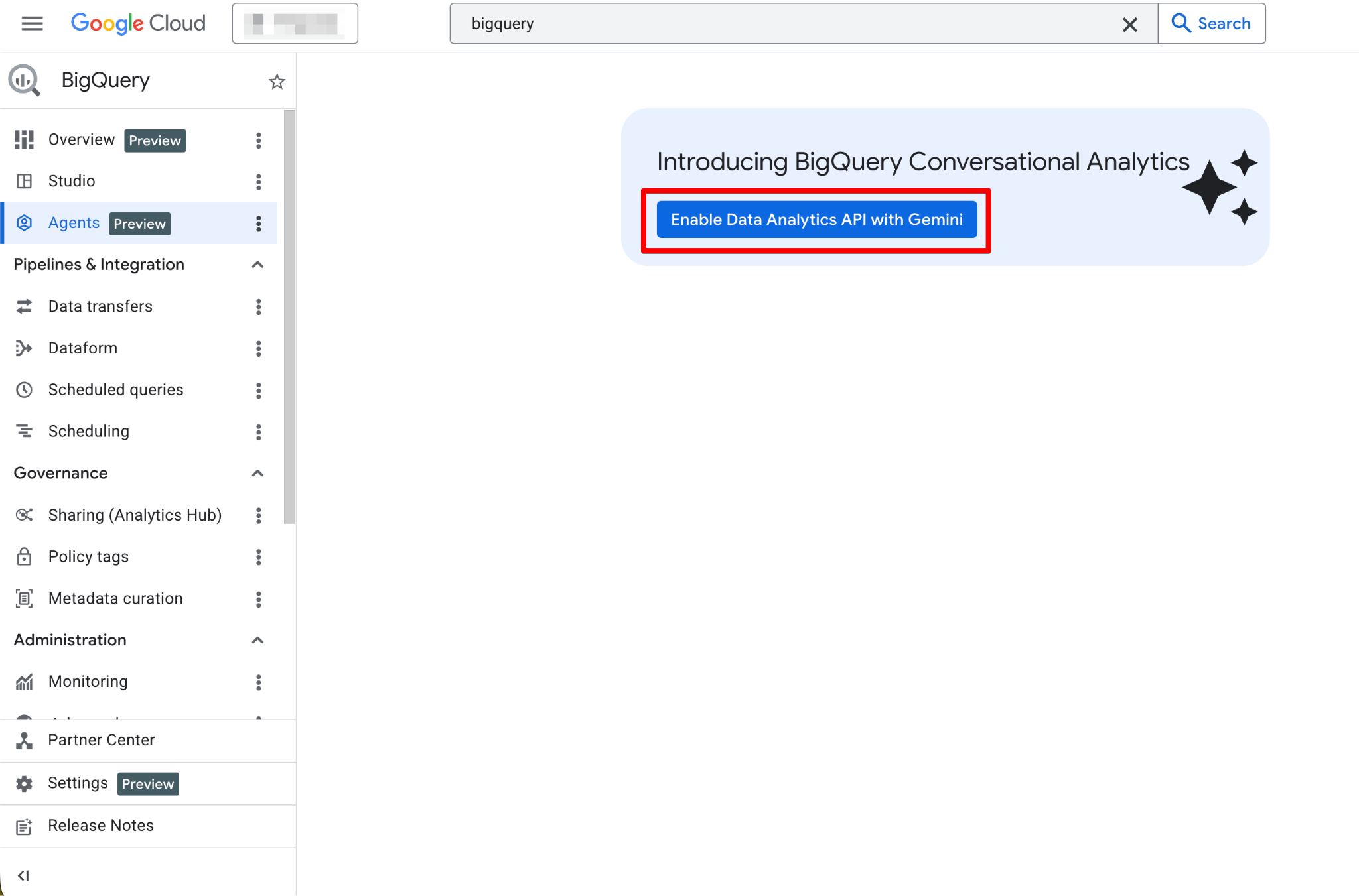
Zodra dit is ingeschakeld, wordt de Agents-pagina volledig functioneel. Je zou nu de nieuwe agentpagina moeten zien:
De Agent Catalog wordt gebruikt om data-agents te maken, beheren en versies te onderhouden binnen BigQuery Studio.
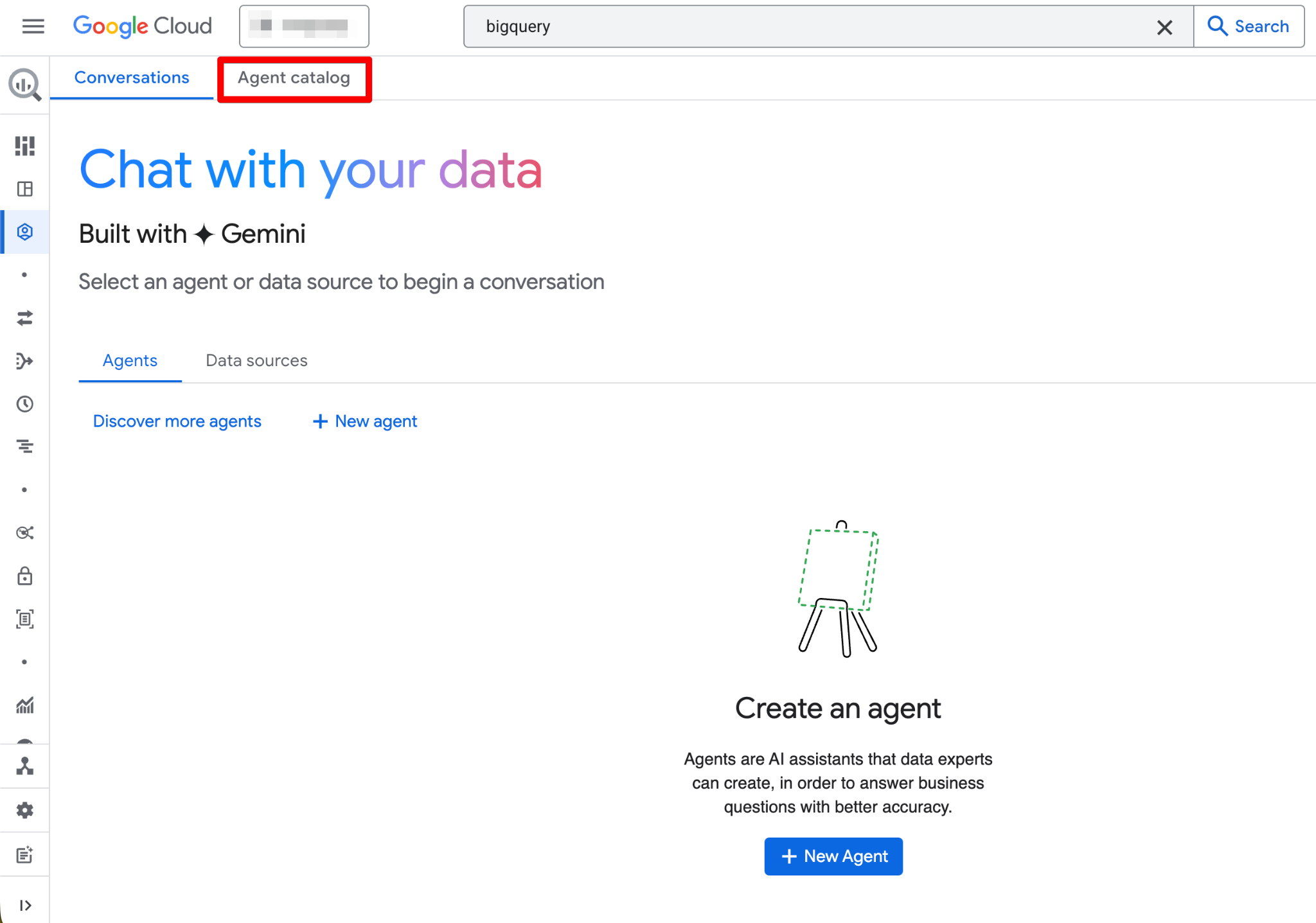
Dit vind je in de Agent Catalog:
De levenscyclus van een agent volgt deze structuur (Draft → Created → Published):
Klik op een agentkaart om deze te openen, details te bekijken, een gesprek te starten of te bewerken (als je Owner-machtigingen hebt). De interface bevat ook een tabblad Conversations waar je eerdere chats met agents of databronnen kunt beheren.
Nu de basis staat, gaan we een data-agent from scratch bouwen. We gebruiken de dataset bigquery-public-data.austin_bikeshare om ruwe ritdata om te zetten in een conversational interface. We gebruiken twee tabellen:
bikeshare_trips — gedetailleerde data op ritniveau
bikeshare_stations — stationmetadata
De agentaanmaak starten
Met deze twee velden kun je de agent later snel herkennen. Zodra ze zijn ingesteld, ben je klaar om de drie kernbouwstenen te configureren die we eerder bespraken: kennisbronnen, instructies en (later) geverifieerde queries.
Kennisbronnen bepalen precies welke data de agent kan benaderen. Hoe minder en gerichter de bronnen, hoe beter de nauwkeurigheid en hoe lager de kosten. Klik in het gedeelte Knowledge sources van de editor op Add source. Zoek naar austin_bikeshare en selecteer bikeshare_trips en bikeshare_stations als bronnen.
Klik voor elke tabel die je toevoegt op Customize.
Gemini genereert automatisch een beschrijving en stelt kolommetadata voor. Bekijk alles, accepteer de juiste suggesties, voer eventuele aanpassingen door en klik op Update.
Een veelgemaakte fout is om in één keer 50 tabellen toe te voegen. Begin met 2–3 kerntabellen. Zo kun je de logica van de agent makkelijker debuggen. Je kunt de kennis later altijd uitbreiden zodra de kernqueries kloppen.
Vervolgens moet je je agent verankeren met instructies. In plaats van alleen een generieke tekstprompt te schrijven (bijv. "Beantwoord vragen over sales"), kun je in de data-agentinterface van BigQuery zeer gestructureerde context bieden om de AI te sturen bij het genereren van queries. Zie het als het onboarden van een nieuwe analist met jullie exacte datadictionary.
Gebruik het veld Instructions om gestructureerde businesscontext te geven. Hier is een complete, kant-en-klare voorbeeldtekst die je kunt plakken:
Synoniemen: Definieer alternatieve termen voor je kolommen zodat de agent natuurlijke taalvariaties begrijpt. Voorbeeld: "Journey", "Ride" en "Commute" verwijzen allemaal naar een record in de tabel bikeshare_trips. "Dock", "Hub" of "Station" verwijst naar een record in de tabel bikeshare_stations.
Sleutelveelden: Markeer de belangrijkste velden voor analyses. Dit vertelt de agent welke kolommen prioriteit hebben als de vraag van een gebruiker breed is. Voorbeeld: Geef prioriteit aan trip_id, start_station_name, end_station_name, subscriber_type, start_time en duration_minutes voor algemene rapportages.
Uit te sluiten velden: Geef kolommen op die de data-agent strikt moet vermijden. Dit is erg handig om verouderde kolommen of irrelevante data te verbergen. Voorbeeld: Gebruik de kolom bike_id in de tabel bikeshare_trips niet voor de meeste analyses, omdat deze zelden nodig is voor businessvragen.
Filteren en groeperen: Instrueer de agent over standaardmanieren om de data te segmenteren. Voorbeeld: Tenzij anders aangegeven, filter ritten altijd uit waar duration_minutes < 1 (dit zijn valse starts of testritten). Groepeer standaard op start_station_name wanneer de gebruiker vraagt om “per station” of “topstations”.
Join-relaties: Omdat onze agent meerdere tabellen gebruikt, definieer je expliciet hoe ze met elkaar zijn verbonden. Dit zorgt ervoor dat de agent niet gokt met de verkeerde foreign keys. Voorbeeld: Join de tabel bikeshare_trips met bikeshare_stations door bikeshare_trips.start_station_id te matchen met bikeshare_stations.station_id (en op vergelijkbare wijze voor end_station_id).
Je kunt alles hierboven combineren tot één nette bloktekst in het veld Instructions. Hier is een gepolijste, kant-en-klare versie die de gestructureerde richtlijnen bevat:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).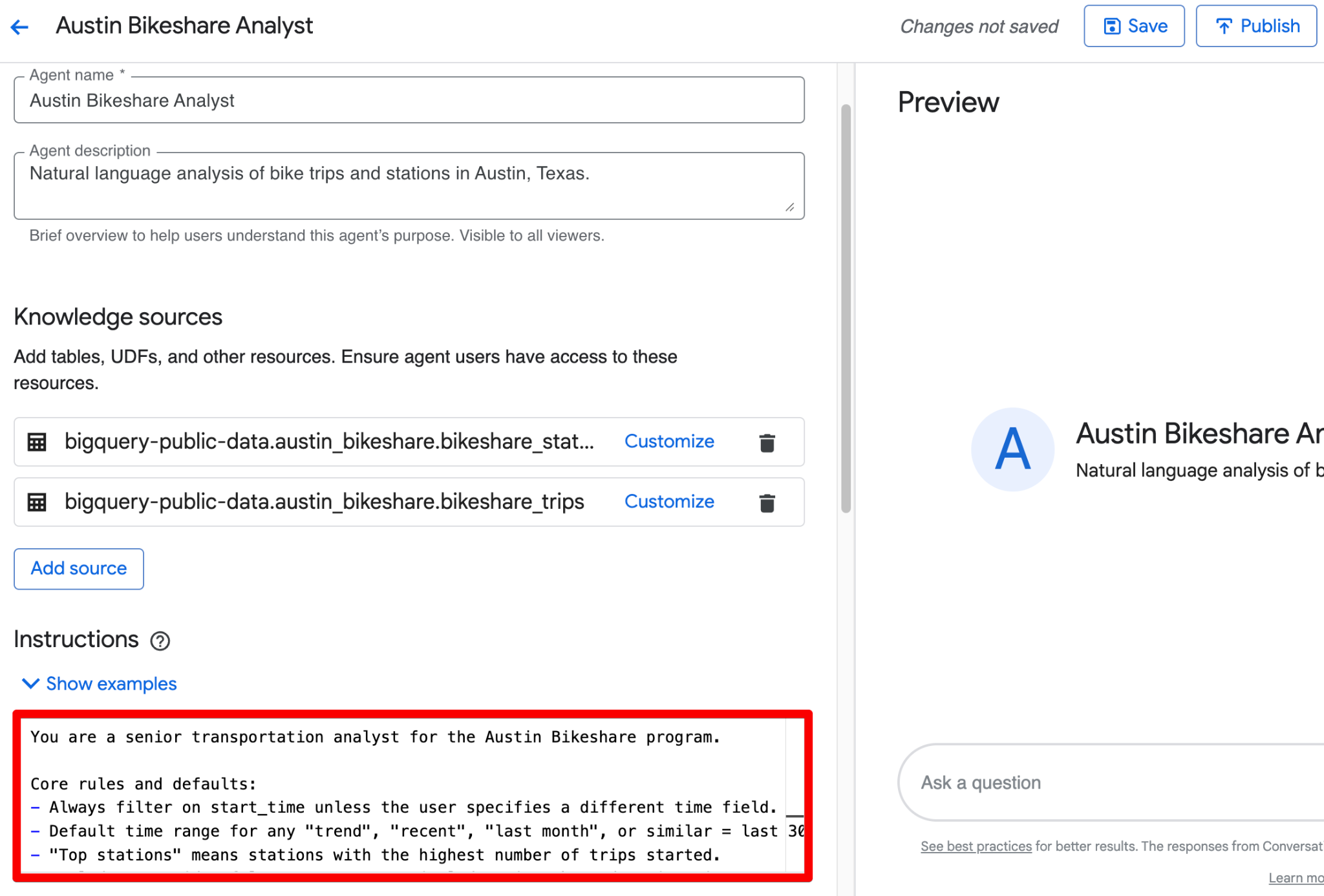
Waarom dit ertoe doet: Als je deze velden leeg laat, kan een vage vraag als "Wat waren onze topverkopen?" ertoe leiden dat de agent de verkeerde tabellen joint, put uit inactieve accounts of verouderde data meeneemt. Door je instructies over deze vijf categorieën te structureren, zorg je ervoor dat de gegenereerde SQL strikt aansluit bij jullie gevestigde businesslogica.
Naast instructies kun je (en zou je) begrippen direct in de agent definiëren. Deze helpen de agent om vakjargon, afkortingen en afgeleide concepten consistent te interpreteren.
Klik op Add term in het gedeelte Glossary (meestal in de buurt van Instructions) en maak begrippen aan met een term, definitie en synoniemen (komma-gescheiden).
Hier zijn aanbevolen glossariumtermen voor de Austin Bikeshare-dataset:
| Term | Definitie | Synoniemen |
duration_minutes |
Ritduur in minuten. Gebruik dit altijd voor antwoorden richting gebruikers en berekeningen | ritduur, ritlengte, duur, rijtijd |
ridership |
Het totaal (aantal) gestarte fietsritten | ritten, trips, journeys, fietgebruik, aantal ritten |
peak_hours |
Ochtendpiek (7-9) of avondpiek (16-19) op basis van het uur dat uit start_time is gehaald |
spitsuur, drukke uren, periode met hoge vraag |
subscriber_type |
Type rijder — Subscriber (maand- of jaarabonnement) of Customer (eenmalige rit | gebruikerstype, lidmaatschapstype, pashouder, lid, gelegenheidsrijder |
false_start |
Een zeer korte rit (meestal korter dan 1 minuut) die waarschijnlijk een testrit of per ongeluk ontgrendelen is. Deze moeten normaal gesproken uit de analyse worden uitgesloten | testrit, ongeldige rit, korte rit |
Je kunt naar behoefte meer termen toevoegen (bijvoorbeeld voor start_station_name, end_station_name of afgeleide metrics zoals “gemiddelde ritduur” of “lange rit”).
Met glossaria geldt: als het management besluit om de officiële definitie van een “Lange rit” volgend kwartaal te wijzigen naar 45 minuten, hoeft je datagovernanceteam dit slechts één keer in Dataplex bij te werken. Elke data-agent die aan dat glossarium is gekoppeld neemt de nieuwe logica direct over, zodat je consistentie houdt in de hele organisatie.
Zodra je de kennisbronnen, instructies en glossariumtermen hebt geconfigureerd, is het tijd om je agent te testen voordat je publiceert.
Scroll naar de rechterkant van het scherm naar het Preview-paneel. Deze livechatinterface laat je in realtime met je agent interacteren terwijl je hem bouwt. Je kunt vragen stellen, de redenering van de agent beoordelen, de gegenereerde SQL inspecteren en snel itereren.
Het Preview-paneel toont:
Probeer deze vier queries met oplopende complexiteit (aangepast aan het bereik van de dataset tot 2024):
Wat je ziet in het antwoord van de agent:
Samenvatting — Een uitleg in natuurlijke taal van de resultaten.
Queryresultaat — Een overzichtelijke tabel met de data (bijv. totaal aantal ritten, topstations of gemiddelde duur).
Inzichten — Bulletpoints met bevindingen die de resultaten in een businesscontext duiden.
Gegenereerde SQL — Klik op Open in Editor om de volledige SQL-query te bekijken die de agent heeft gemaakt (je ziet dat correct wordt gefilterd op start_time en dat duration_minutes >= 1 wordt toegepast om valse starts uit te sluiten).
Voorgestelde vervolgvraag — Handige prompts onderaan (bijv. “Wat waren de top 10 startstations in juni 2024?”, “Maak een voorspelling van het dagelijks aantal ritten…” enz.).
Visualisatie — Een automatisch gegenereerde grafiek (staafdiagram voor ranglijsten, zoals te zien in je top 5-stationsvoorbeeld).
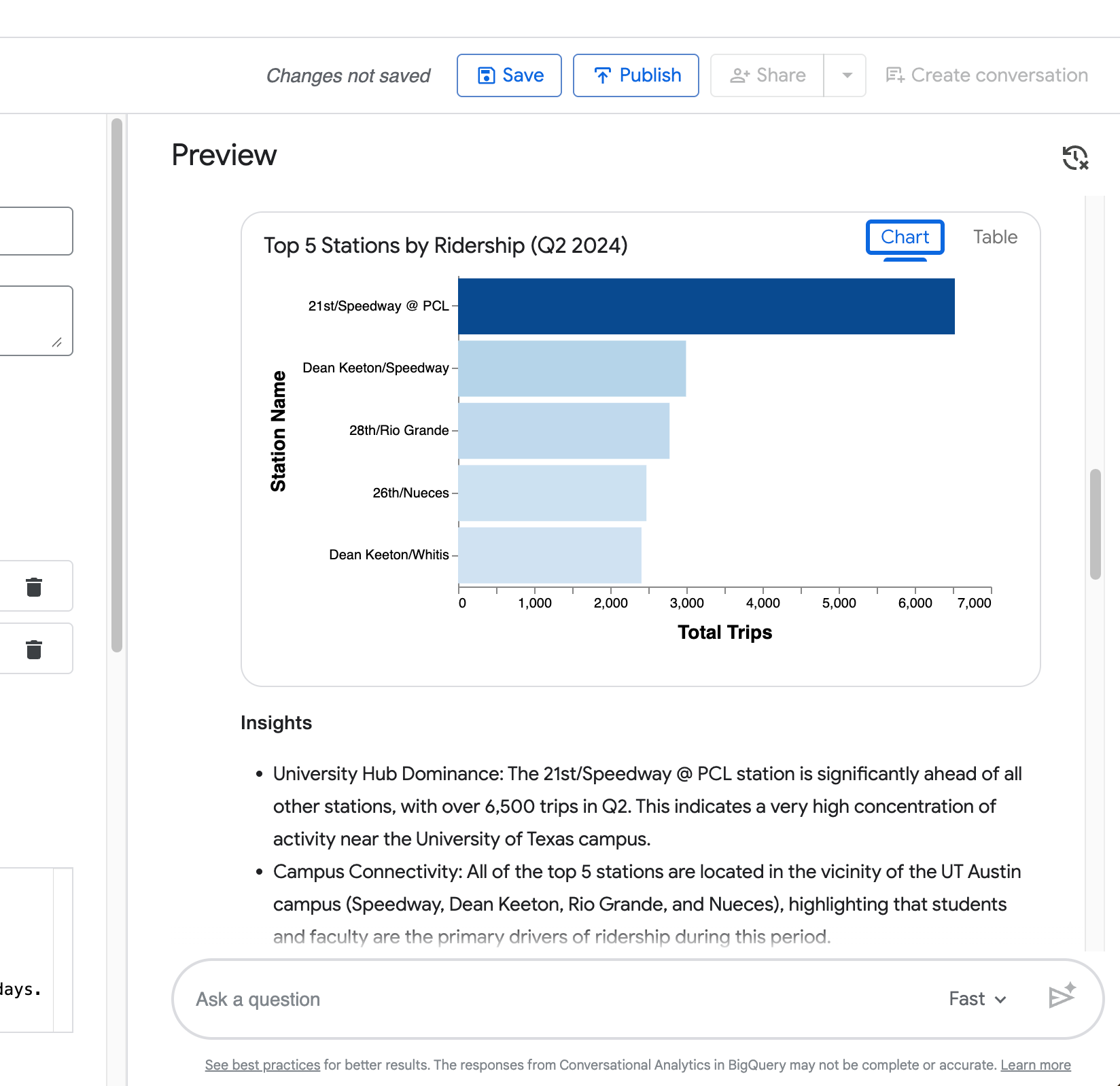
Je vierde query (“Laat nu dezelfde vergelijking zien maar alleen voor het Zilker Park-station”) toont het vermogen van de agent om context uit de vorige vraag vast te houden.
Zoals je in de volgende screenshot ziet, beperkt hij de vergelijking tussen weekdagen en weekenden correct tot Zilker Park zonder dat jij het volledige verzoek herhaalt.
Testtips:
Zodra de agent consequent duidelijke, nauwkeurige en goed gestructureerde antwoorden geeft, klik je bovenaan op Save en daarna op Publish. Je Austin Bikeshare Analyst-agent is nu klaar voor gebruik!
Zelfs met goede instructies en glossariumtermen kan je data-agent soms nog businessregels verkeerd interpreteren of inconsistente antwoorden genereren.
Geverifieerde queries lossen dit op door je in staat te stellen de agent expliciet de juiste aanpak te leren voor belangrijke of veelgestelde vragen. Elke geverifieerde query bestaat uit een vraag in natuurlijke taal, gekoppeld aan de exacte SQL die moet worden gebruikt.
Ze fungeren als hoogwaardige voorbeelden die de redenering van de agent verankeren en zijn een van de effectiefste manieren om van een “goed genoeg”-agent naar een productieklare agent te gaan.
Scroll in de agenteditor naar het gedeelte Verified Queries. Je hebt twee eenvoudige manieren om geverifieerde queries toe te voegen:
Klik op Add query. Je ziet het scherm Add verified query, waar je kunt:
Klik op View Gemini-generated suggestions. Dit opent het scherm “Review suggested verified queries”, waar Gemini relevante vragen voorstelt op basis van je kennisbronnen.
Je kunt:
Een goede geverifieerde query voor de Austin Bikeshare-dataset zou kunnen zijn:
Vraag:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;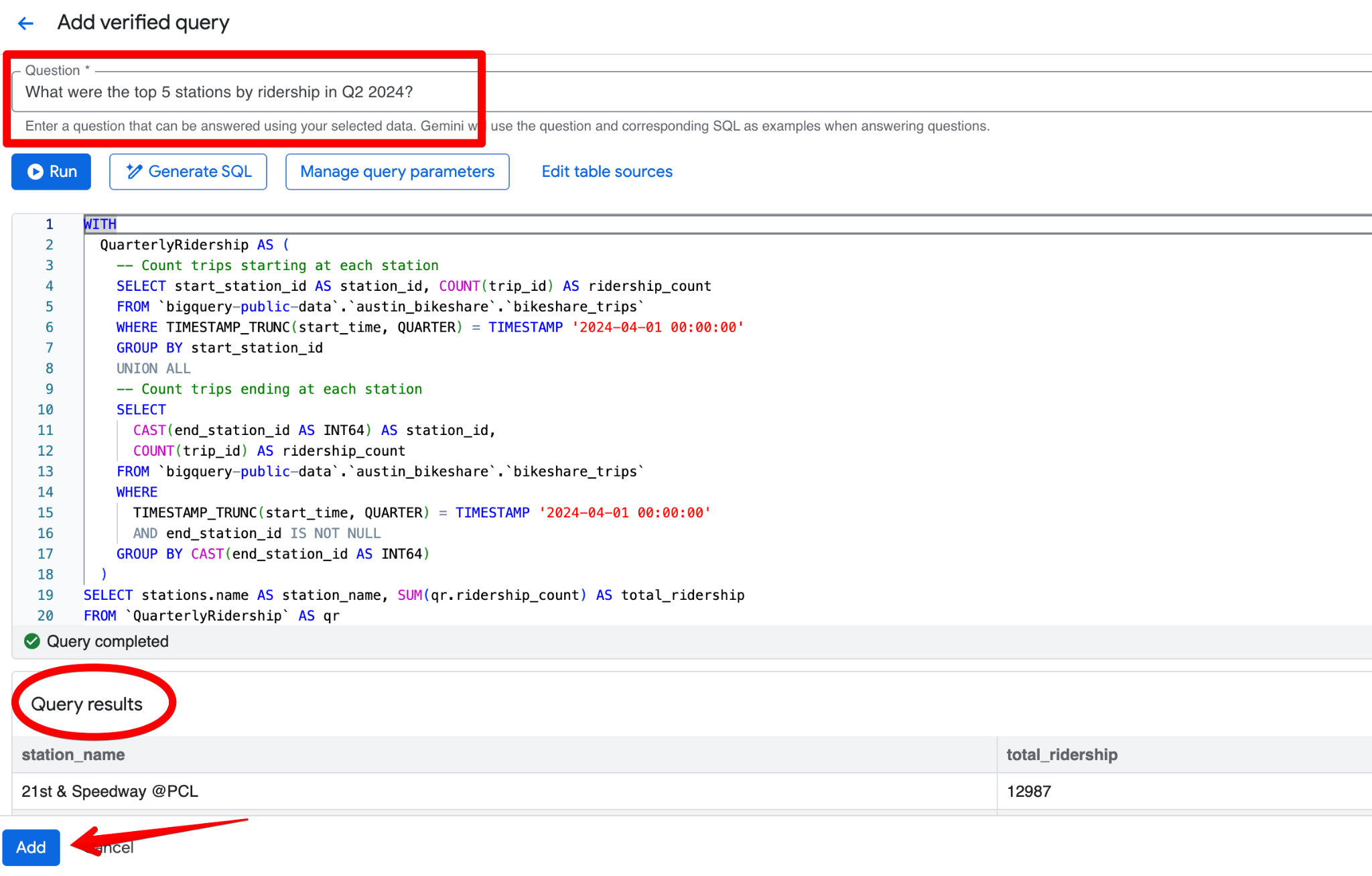
Zelfs als de agent bij de eerste poging een redelijk antwoord geeft, kun je de nauwkeurigheid en consistentie aanzienlijk verbeteren door de gegenereerde SQL te bekijken en geverifieerde queries toe te voegen.
Volg deze praktische workflow:
Stel, je vroeg: “Wat was de gemiddelde ritduur in juni 2024?” In het eerste antwoord geeft de agent 26,68 minuten terug en sluit ritten korter dan 1 minuut correct uit. Stel nu dat de standaard businessregel van het team is om ritten korter dan 5 minuten uit te sluiten.
Als je de gegenereerde SQL opent (via Open in Editor), zie je dat de filter slechts duration_minutes >= 1 is.
Klik op Add query in het gedeelte Verified Queries en maak deze entry aan:
Vraag:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes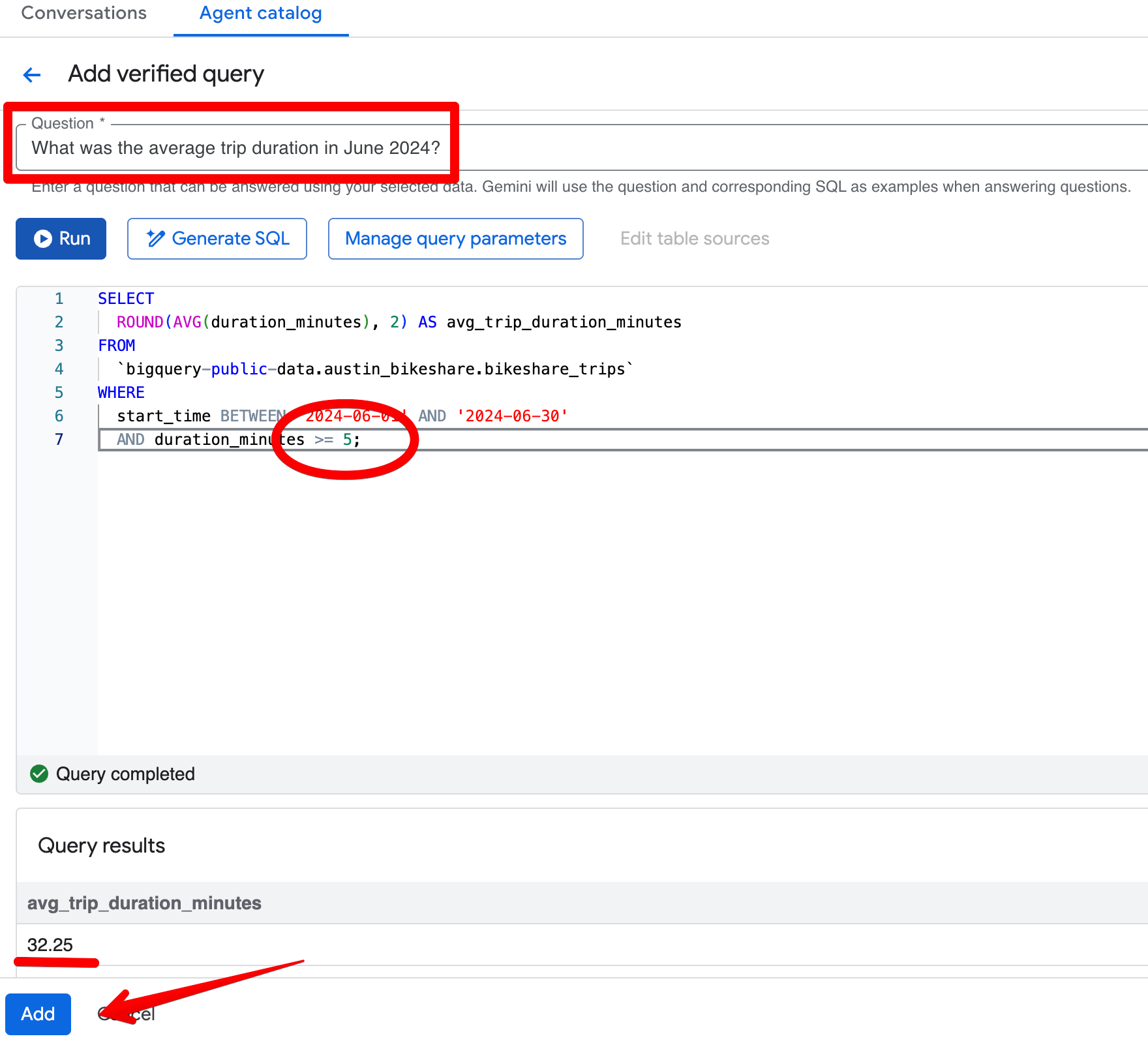
Na het opslaan van de geverifieerde query stel je dezelfde vraag opnieuw in het Preview-paneel. De agent geeft nu consequent ~32,08 minuten terug en past je striktere 5-minutendrempel toe. De resultaten sluiten beter aan bij jullie zakelijke definitie van “zinvolle” ritten.
BigQuery’s conversational analytics onderscheidt zich van eenvoudige text-to-SQL-tools door native ondersteuning voor BigQuery ML-functies, ongestructureerde data en eenvoudig delen binnen het Google Cloud-ecosysteem.
Een van de grootste onderscheiders is het vermogen van de agent om BigQuery ML-functies rechtstreeks vanuit natuurlijke taal aan te roepen, zodat je verder gaat dan terugblikkende rapportage naar vooruitkijkende inzichten.
Je kunt bijvoorbeeld een data-agent vragen het dagelijks aantal ritten voor de komende 30 dagen te voorspellen op basis van trends in 2024. Hij triggert AI.FORECAST en genereert een voorspelling voor juli 2024, naast een fraaie grafiek met historische dagelijkse ritten (blauwe lijn) en de 30-daagse voorspelling (oranje lijn) met een gearceerd 95%-betrouwbaarheidsinterval.
Een andere manier waarop machinelearningalgoritmen nuttig kunnen zijn, is door te detecteren of er iets mis is in je data. Als je bijvoorbeeld een agent vraagt om afwijkingen in het dagelijks aantal ritten in juni 2024 te detecteren, zal hij AI.DETECT_ANOMALIES aanroepen, juni 2024 vergelijken met voorgaande maanden en een tijdreeks-tabel plus een lijngrafiek retourneren.
In dit geval werden geen formele afwijkingen op 95%-niveau gemarkeerd, maar 19 juni werd wel aangewezen als bijna-afwijking (92,1% kans) met een duidelijke daling in rittenaantal.
De meeste conversational BI-tools haken af zodra data niet netjes in rijen en kolommen is georganiseerd. BigQuery ondersteunt echter Object Tables, waarmee je ongestructureerde data (zoals pdf’s, afbeeldingen en ruwe tekstlogs) uit Google Cloud Storage kunt analyseren.
Omdat de data-agent wordt aangedreven door de multimodale capaciteiten van Gemini, kan hij tegelijkertijd redeneren over zowel je gestructureerde metrics als je ongestructureerde bestanden. Dit is een enorme, unieke troef van BigQuery.
Als je rijdersenquête-pdf’s of stationinspectieafbeeldingen in een objecttabel hebt, vraag dan simpelweg: “Vat de belangrijkste klachten samen uit de rijdersenquêtes-pdf’s van Q2 2024.” De agent leest de ongestructureerde bestanden en combineert de informatie met je gestructureerde ritdata
Je datateam bouwt en test data-agents in BigQuery Studio, maar je eindgebruikers werken waarschijnlijk in heel andere applicaties. Google maakt het eenvoudig om de agent los te koppelen van de GCP Console, zodat je businessgebruikers kunt bedienen waar ze al werken.
Als je zelf een maatwerkchatapplicatie wilt bouwen, kun je allees dan ook meer in de officiële Introduction to Conversational Analytics in BigQuery.
Als er één belangrijk principe is om mee te nemen, dan is het dit: conversational analytics verplaatst de analytische flessenhals van wachten op een datateam naar simpelweg de juiste vraag stellen.
Deze democratisering betekent niet dat datateams overbodig zijn, maar hun rol verandert. Een AI-agent is slechts zo intelligent als de vangrails die je eromheen bouwt. De nauwkeurigheid en veiligheid van je data-agents hangen volledig af van de instructies, context en schema-architectuur die je biedt.
Om de meest effectieve conversational agents te bouwen, heb je nog steeds een sterke beheersing van het onderliggende datawarehouse nodig. Wil jij of je team die kernvaardigheden versterken en het platform beheersen dat deze AI-functies aandrijft, bekijk dan vandaag nog DataCamp’s Introduction to BigQuery-cursus!
Google Cloud-cursussen
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
