
programa
Google Cloud Digital Leader
8 h
Si trabajas en un equipo de datos, este escenario te resultará familiar: el backlog no deja de crecer con peticiones ad hoc. El negocio pide variaciones sencillas de informes existentes una y otra vez: "¿Puedes agrupar esto por categoría de producto?", o "¿Cómo se compara con el mes pasado?" Mientras esperan turno, tus data engineers y analistas se ven sepultados en tareas repetitivas de SQL.
Con Conversational Analytics en BigQuery, por fin puedes mover el cuello de botella. Esta función lleva un motor de razonamiento con IA directamente a BigQuery Studio, para que los usuarios hagan preguntas en lenguaje natural y reciban al instante datos, gráficos y SQL generado.
En esta guía aprenderás a configurar y usar la analítica conversacional en BigQuery. Crearás, configurarás y pulirás tus propios agentes de datos para que tu organización pueda chatear con sus datos de forma segura.
La analítica conversacional cambia la interacción con los datos: de consultas SQL manuales a conversaciones en lenguaje natural. En lugar de escribir sentencias SELECT, hablas con un agente de datos que entiende tu contexto de negocio y devuelve respuestas basadas en tus tablas reales.
No es un simple conversor de texto a SQL; es un paso decisivo hacia la verdadera democratización de los datos.
Permite que perfiles no técnicos accedan de forma autónoma a insights en tiempo real y ofrece a los profesionales de datos una vía rápida para explorar datasets y automatizar informes.
En el corazón de la analítica conversacional de BigQuery hay un motor de razonamiento impulsado por la familia de modelos Gemini. Los agentes de datos usan una canalización estructurada y multinivel para garantizar que los insights estén fundamentados en tu contexto de datos específico:
Google Cloud ofrece analítica conversacional en distintos niveles de tu stack de datos. Elegir el punto de entrada correcto depende de tus usuarios y de dónde residen tus reglas de negocio:
|
Función |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (vía BigQuery Agents) |
|
Ideal para |
Equipos de datos, analistas y desarrolladores que crean aplicaciones personalizadas |
Usuarios de negocio que necesitan insights gobernados y listos para dashboard |
Usuarios de negocio que prefieren informes BI ligeros |
|
Método de grounding |
Esquemas del warehouse, metadatos de tablas y consultas verificadas |
LookML (capa semántica) |
Conectado directamente a agentes de datos de BigQuery preconfigurados |
|
Acceso a datos |
Puede analizar datos estructurados, predictivos (ML) y no estructurados |
Datos estrictamente estructurados y modelados |
Datos estructurados |
|
Estado de lanzamiento |
Vista previa (mayo de 2026) |
Disponibilidad general |
Vista previa |
¿Qué camino elegir?
Este tutorial se centra en BigQuery como la vía más rápida para que los equipos de datos prototipen y lleven a producción agentes justo donde viven los datos.
Antes de configurarlo, es importante entender la arquitectura de un agente de datos. En el entorno de Google Cloud, un agente de datos es la capa central de abstracción. Combina activos de BigQuery con las capacidades de razonamiento de la familia de modelos Gemini.
En lugar de exponer tablas en bruto, un agente de datos configura todo lo que el modelo necesita para interpretar preguntas, generar SQL seguro y devolver respuestas fiables. Esta combinación de fuentes de datos, instrucciones y lógica verificada hace que la analítica conversacional de BigQuery sea más sólida que las herramientas estándar de texto a SQL.
Las fuentes de conocimiento son la capa base de cualquier agente de datos. Definen exactamente a qué datos puede acceder y consultar el agente.
Tipos de activos: Tables, Views y User Defined Functions (UDFs) pueden conectarse como fuentes de conocimiento.
Escalabilidad: Varias fuentes de conocimiento pueden conectarse a un único agente. Esto permite combinar información de distintas áreas del negocio.
Control de acceso: Definir fuentes concretas garantiza que el agente opere solo dentro de los datos autorizados.
La inteligencia de un agente depende del contexto que le proporciones. Es clave para que un modelo genérico entienda el lenguaje de tu empresa.
Al definir instrucciones personalizadas, sinónimos y glosarios de negocio, el agente se ancla a un dominio específico. Por ejemplo, puedes enseñarle que "Top Customers" se refiere a usuarios con un valor de vida (LTV) superior a 1.000 $.
Elementos clave de grounding:
Instrucciones personalizadas: Directrices de alto nivel como "Excluye siempre las cuentas de prueba internas en los informes de ingresos".
Glosarios de negocio: Vinculan términos técnicos con lenguaje natural; por ejemplo, mapear store_id a "Sede".
Metadatos de campos: Descripciones que ayudan al agente a entender matices de variables concretas, como "ingresos brutos" frente a "beneficio neto".
Cuanto mejores sean tus instrucciones y metadatos, mayor será la precisión del agente.
Las consultas verificadas, antes llamadas Golden Queries, son pares de pregunta y respuesta predefinidos que actúan como fuente de verdad. Al mapear preguntas específicas a SQL validado por expertos, el agente usa las rutas de joins y filtros correctos para KPIs críticos.
Estas consultas pueden incluir funciones de BigQuery ML (BQML). Así, el agente puede manejar peticiones avanzadas, como generar predicciones de churn o previsiones de ventas, usando exactamente los parámetros de modelo definidos por los data scientists. Una vez verificadas, estos activos se gestionan a través del catálogo universal de Dataplex, garantizando la consistencia en toda la organización.
Ahora que conoces las piezas, pasemos a crear y configurar tu primer agente de datos.
Para seguir el tutorial, asegúrate de contar con estos requisitos previos:
Antes de crear tu primer agente, debes configurar tu proyecto de Google Cloud y asegurarte de que tu cuenta tenga los permisos necesarios. Los Data Agents operan como una capa sobre tus datos existentes, por lo que una configuración correcta de IAM (Identity and Access Management) es crítica para la seguridad y el funcionamiento.
Sigue estos pasos:
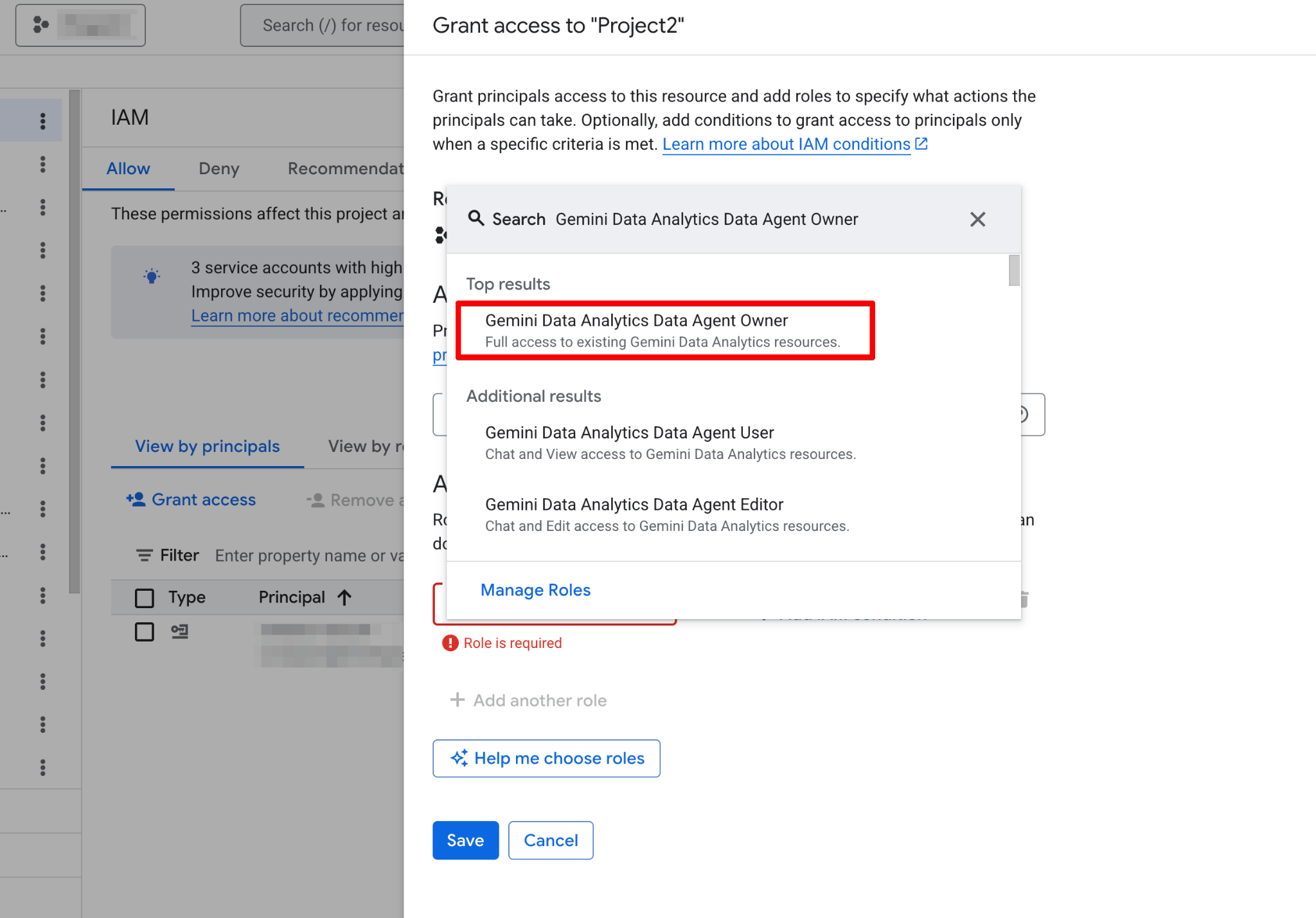
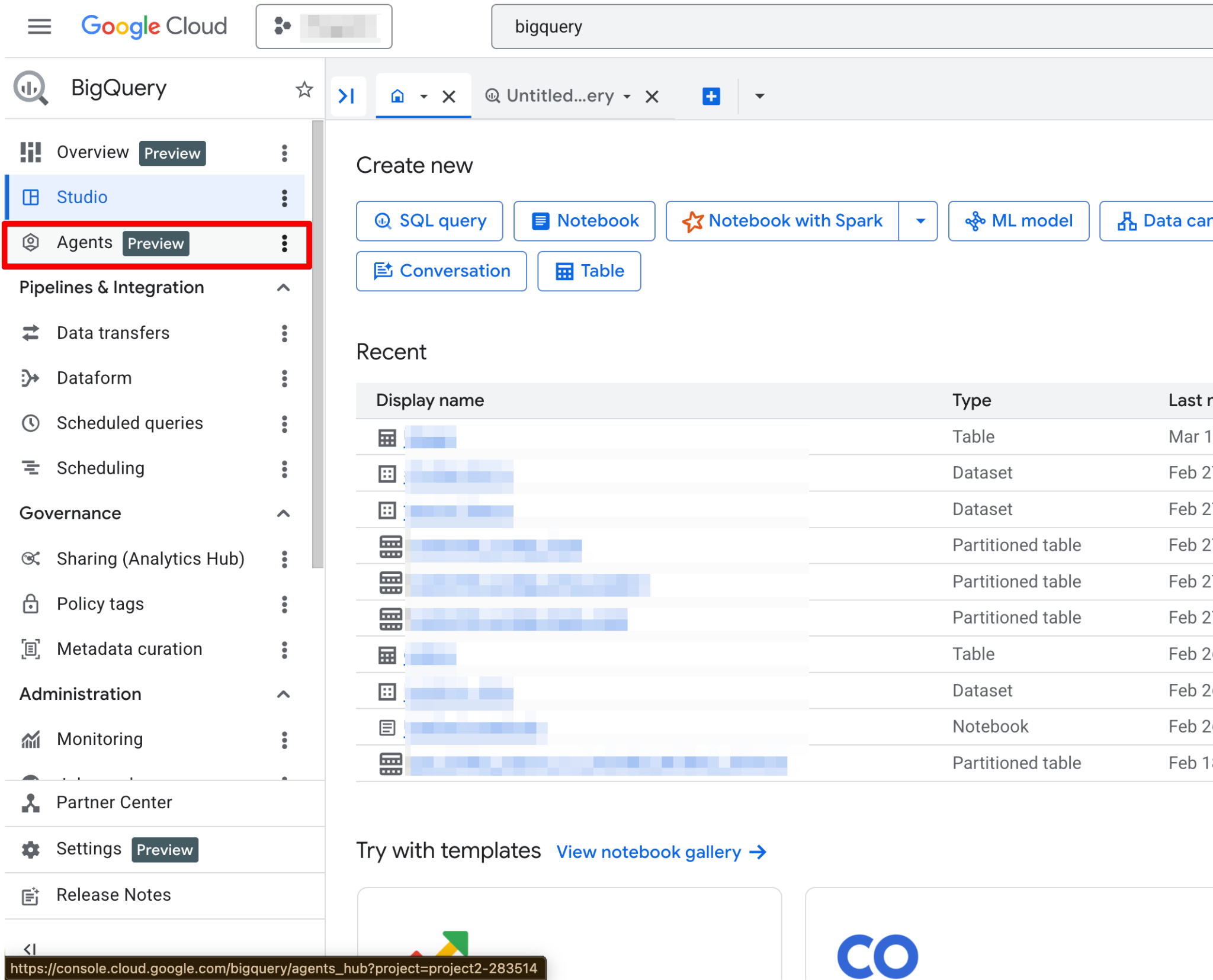
Una vez activadas, la página de Agents queda totalmente operativa. Deberías ver la nueva página de creación de agentes:
El Agent Catalog sirve para crear, gestionar y versionar agentes de datos dentro de BigQuery Studio.
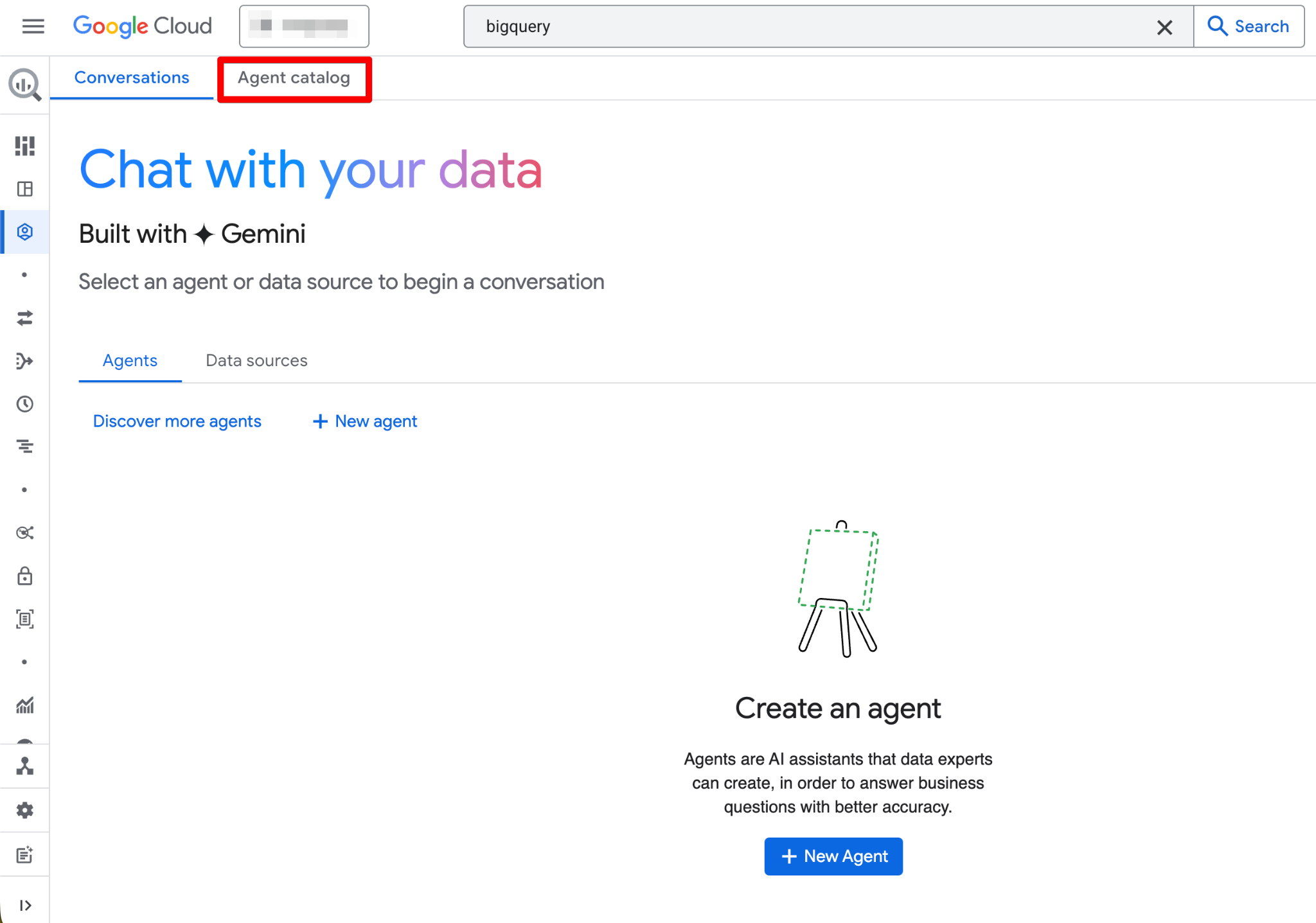
Aquí encontrarás:
El ciclo de vida del agente sigue esta estructura (Draft → Created → Published):
Haz clic en cualquier tarjeta de agente para abrirla, ver detalles, iniciar una conversación o editar (si tienes permisos de Owner). La interfaz también incluye una pestaña Conversations donde puedes gestionar chats anteriores con agentes o fuentes de datos.
Con la base lista, creemos un Data Agent desde cero. Usaremos el dataset bigquery-public-data.austin_bikeshare para convertir datos de viajes en bruto en una interfaz conversacional. Usaremos dos tablas:
bikeshare_trips — datos detallados a nivel de viaje
bikeshare_stations — metadatos de estaciones
Inicio de la creación del agente
Estos dos campos te ayudarán a identificar el agente más adelante. Con esto listo, ya puedes configurar los tres bloques clave que vimos: fuentes de conocimiento, instrucciones y (más tarde) consultas verificadas.
Las fuentes de conocimiento definen exactamente a qué datos accede el agente. Cuantas menos y más enfocadas, mejor precisión y menor coste. En la sección Knowledge sources del editor, haz clic en Add source. Busca austin_bikeshare y selecciona bikeshare_trips y bikeshare_stations como fuentes.
Para cada tabla que añadas, haz clic en Customize.
Gemini generará automáticamente una descripción y sugerirá metadatos de columnas. Revísalo todo, acepta lo correcto, ajusta lo necesario y haz clic en Update.
Un error común es añadir 50 tablas de golpe. Empieza con 2–3 tablas clave. Así es más fácil depurar la lógica del agente. Podrás ampliar más adelante cuando las consultas principales ya sean precisas.
Ahora toca asentar tu agente con instrucciones. En lugar de un prompt genérico (por ejemplo, "Responde preguntas sobre ventas"), la interfaz del agente de datos de BigQuery te permite aportar contexto muy estructurado para guiar la generación de consultas de la IA. Piénsalo como el onboarding de un nuevo analista con el diccionario de datos de tu empresa.
Usa el campo Instructions para proporcionar contexto de negocio estructurado. Aquí tienes un ejemplo completo, listo para pegar:
Sinónimos: Define términos alternativos para tus columnas para que el agente entienda variaciones en lenguaje natural. Ejemplo: "Journey", "Ride" y "Commute" se refieren a un registro en la tabla bikeshare_trips. "Dock", "Hub" o "Station" se refiere a un registro en la tabla bikeshare_stations.
Campos clave: Destaca los campos más importantes para el análisis. Así el agente prioriza columnas cuando la pregunta es amplia. Ejemplo: prioriza trip_id, start_station_name, end_station_name, subscriber_type, start_time y duration_minutes para informes generales.
Campos excluidos: Especifica columnas que el agente debe evitar. Muy útil para ocultar columnas obsoletas o irrelevantes. Ejemplo: no uses la columna bike_id en bikeshare_trips para la mayoría de análisis, rara vez se necesita.
Filtrado y agrupación: Indica formas estándar de segmentar los datos. Ejemplo: salvo que se indique lo contrario, excluye siempre viajes con duration_minutes < 1 (falsos inicios o pruebas). Agrupa por defecto por start_station_name cuando el usuario pida "por estación" o "top estaciones".
Relaciones de join: Como el agente usa varias tablas, define explícitamente cómo se conectan. Así evitas que adivine claves erróneas. Ejemplo: haz join de bikeshare_trips con bikeshare_stations igualando bikeshare_trips.start_station_id con bikeshare_stations.station_id (y de forma similar para end_station_id).
Puedes combinar todo lo anterior en un único bloque limpio en el campo Instructions. Aquí tienes una versión pulida y lista para pegar que incorpora la guía estructurada:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).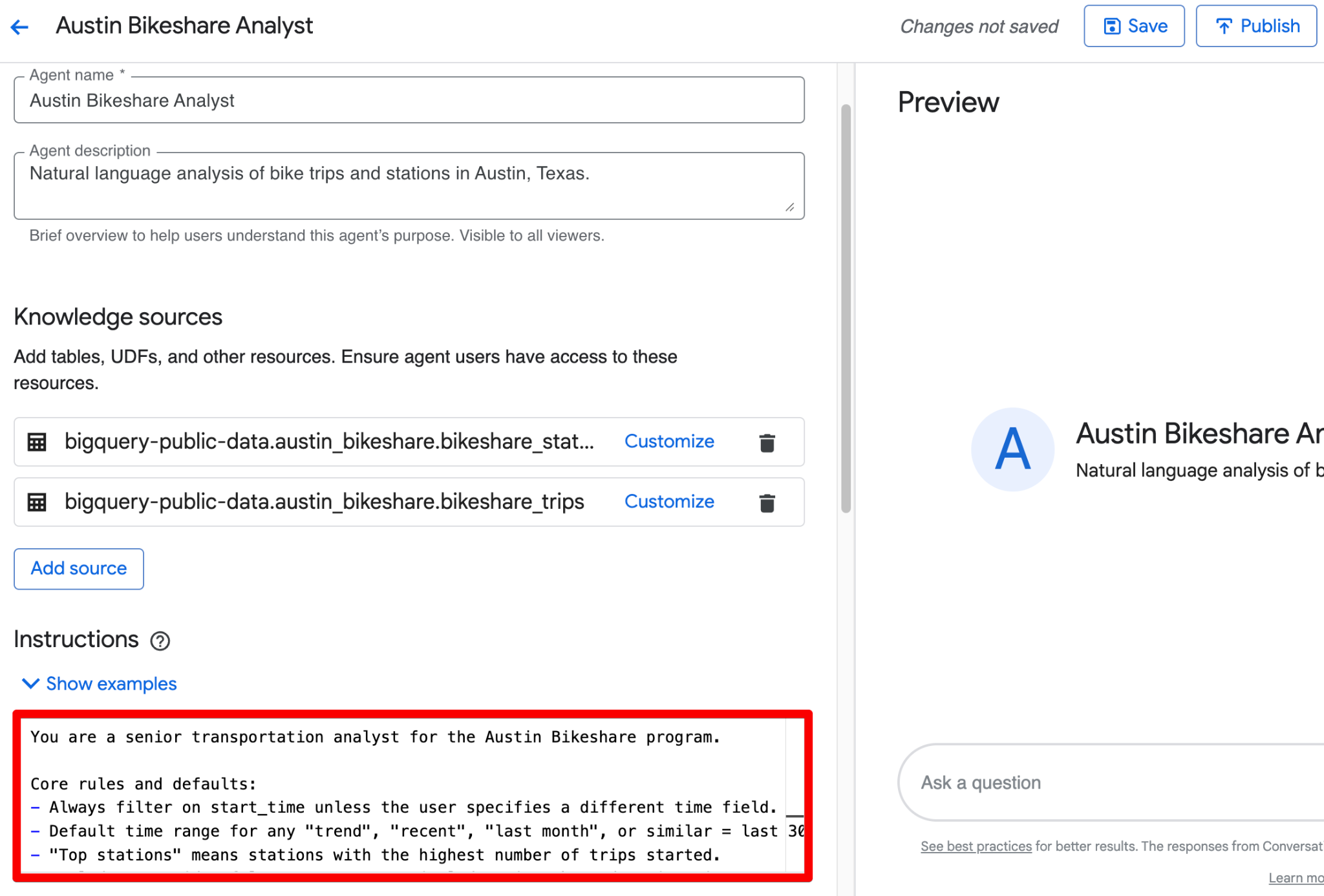
Por qué importa: Si dejas estos campos en blanco, una pregunta ambigua como "¿Cuáles fueron nuestras ventas top?" puede llevar al agente a unir tablas equivocadas, tirar de cuentas inactivas o incluir datos obsoletos. Al estructurar tus instrucciones en estas cinco categorías, aseguras que el SQL generado se ciña a tu lógica de negocio.
Además de las instrucciones, puedes (y debes) definir términos de glosario directamente en el agente. Ayudan a interpretar jerga, abreviaturas y conceptos derivados de forma consistente.
Haz clic en Add term en la sección Glossary (normalmente cerca de Instructions) y crea términos con término, definición y sinónimos (separados por comas).
Términos recomendados para el dataset de Austin Bikeshare:
| Término | Definición | Sinónimos |
duration_minutes |
Duración del viaje en minutos. Úsalo siempre en respuestas y cálculos de cara al usuario | tiempo de viaje, duración del viaje, duración, tiempo de recorrido |
ridership |
Número total (recuento) de viajes de bici iniciados | viajes, recorridos, trayectos, uso de bicicletas, recuento de desplazamientos |
peak_hours |
Horas punta de mañana (7-9) o tarde (16-19) según la hora extraída de start_time |
hora punta, horas de mayor actividad, periodo de alta demanda |
subscriber_type |
Tipo de ciclista — Subscriber (titular de pase mensual o anual) o Customer (viaje puntual | tipo de usuario, tipo de membresía, pass holder, member, usuario ocasional |
false_start |
Viaje muy corto (normalmente menos de 1 minuto) que probablemente sea una prueba o un desbloqueo accidental. Deberían excluirse del análisis | prueba, viaje no válido, viaje corto |
Puedes añadir más términos según necesites (por ejemplo, para start_station_name, end_station_name o métricas derivadas como "duración media del viaje" o "viaje largo").
Al usar glosarios, si dirección decide cambiar la definición oficial de "viaje largo" a 45 minutos el próximo trimestre, tu equipo de gobierno del dato solo tendrá que actualizarlo una vez en Dataplex. Todos los Data Agents conectados a ese glosario adoptarán al instante la nueva lógica, manteniendo la coherencia en toda la organización.
Cuando hayas configurado fuentes de conocimiento, instrucciones y glosario, es momento de probar el agente antes de publicarlo.
Desplázate a la derecha hasta el panel Preview. Esta interfaz de chat en vivo te permite interactuar con tu agente en tiempo real mientras lo construyes. Puedes hacer preguntas, revisar su razonamiento, inspeccionar el SQL generado e iterar rápido.
El panel Preview muestra:
Prueba estas cuatro consultas de complejidad creciente (ajusta al rango de datos del dataset hasta 2024):
Qué verás en la respuesta del agente:
Resumen — Una explicación en lenguaje natural de los resultados.
Resultado de la consulta — Una tabla limpia con los datos (p. ej., viajes totales, top estaciones o duración media).
Insights — Puntos clave que interpretan los resultados en contexto de negocio.
SQL generado — Haz clic en Open in Editor para ver la consulta completa que creó el agente (verás que filtra correctamente por start_time y aplica duration_minutes >= 1 para excluir falsos inicios).
Preguntas de seguimiento sugeridas — Prompts útiles al final (p. ej., "Top 10 estaciones de inicio en junio de 2024", "Haz una previsión del número diario de viajes…", etc.).
Visualización — Un gráfico generado automáticamente (de barras para rankings, como en el ejemplo de top 5 estaciones).
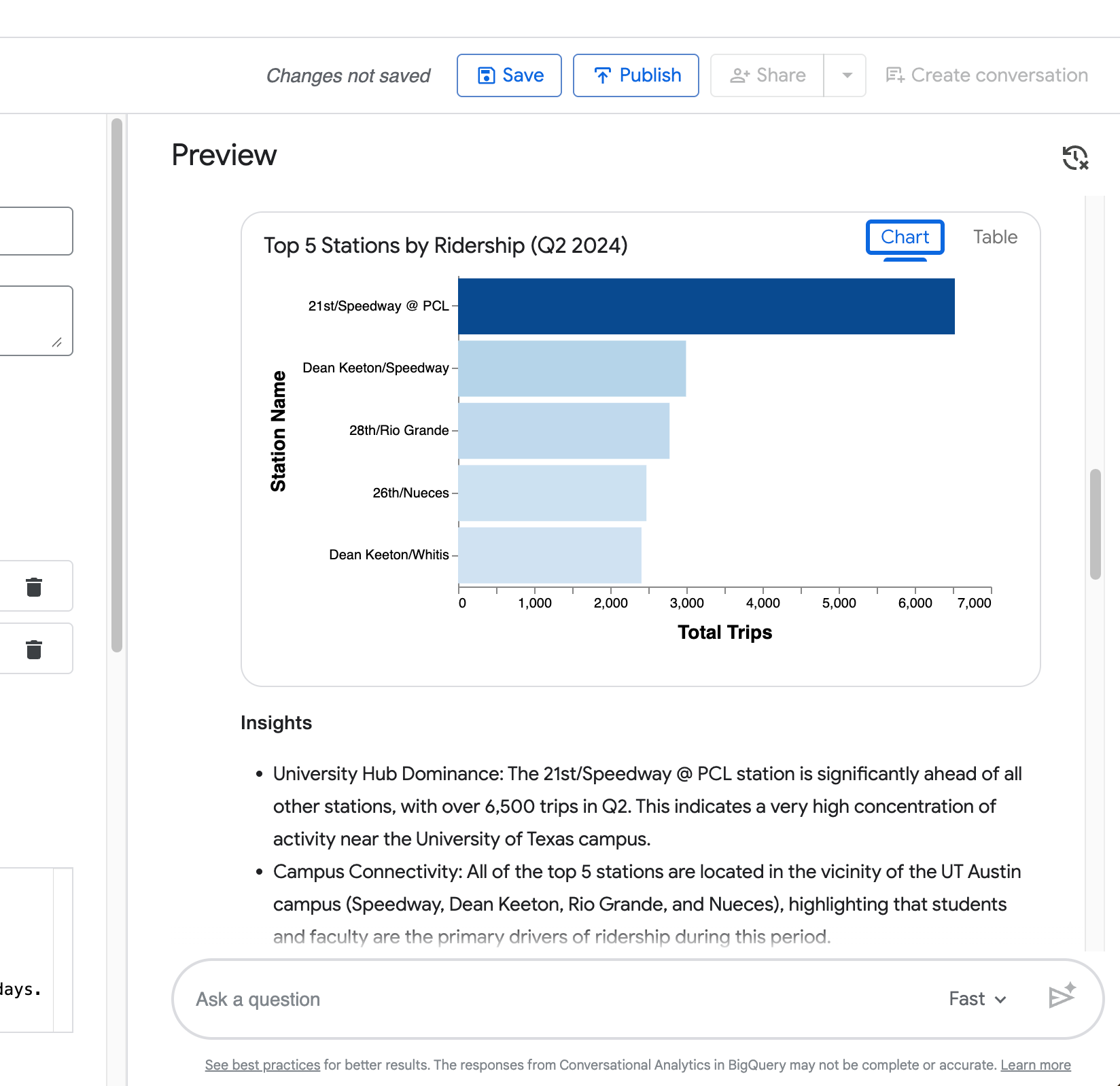
Tu cuarta consulta ("Ahora muestra la misma comparación pero solo para la estación Zilker Park") demuestra la capacidad del agente para retener el contexto de la pregunta anterior.
Como verás en la siguiente captura, acota correctamente la comparación entre días laborables y fines de semana a Zilker Park sin que repitas toda la solicitud.
Consejos de prueba:
Cuando el agente devuelva respuestas claras, precisas y bien estructuradas de forma consistente, haz clic en Save arriba y luego en Publish. ¡Tu agente Austin Bikeshare Analyst ya está listo!
Incluso con buenas instrucciones y glosario, tu agente puede interpretar mal alguna regla de negocio o generar respuestas inconsistentes.
Las consultas verificadas lo solucionan permitiéndote enseñar explícitamente al agente la manera correcta de tratar preguntas importantes o frecuentes. Cada consulta verificada consta de una pregunta en lenguaje natural emparejada con el SQL exacto que debe usarse.
Actúan como ejemplos de alta calidad que anclan el razonamiento del agente y son de las formas más efectivas de pasar de un agente "suficiente" a uno listo para producción.
En el editor del agente, desplázate a la sección Verified Queries. Tienes dos formas sencillas de añadirlas:
Haz clic en Add query. Verás la pantalla Add verified query, donde puedes:
Haz clic en View Gemini-generated suggestions. Se abrirá la pantalla “Review suggested verified queries”, donde Gemini propone preguntas relevantes según tus fuentes de conocimiento.
Puedes:
Un buen ejemplo para Austin Bikeshare sería:
Pregunta:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;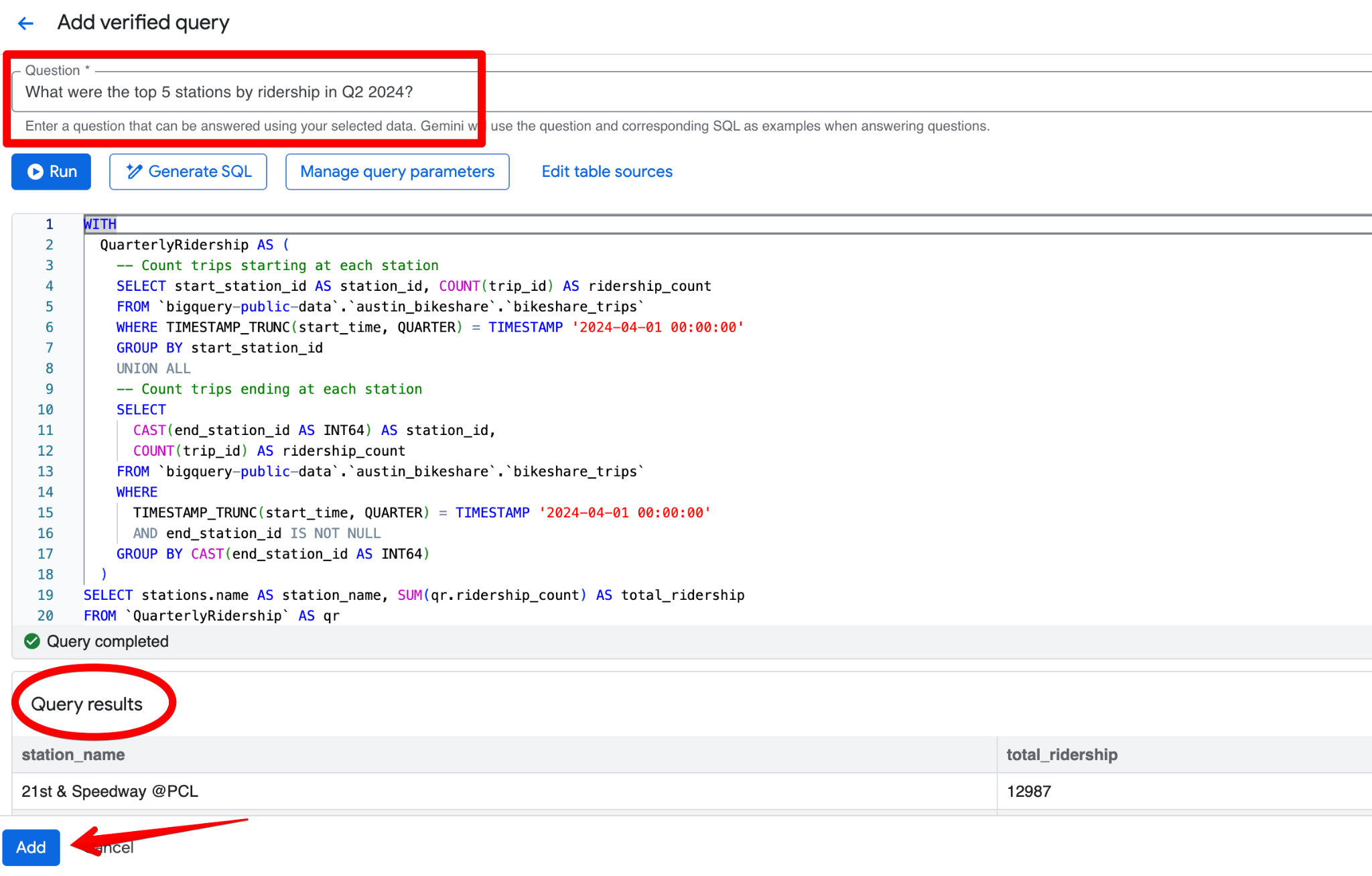
Aunque el agente dé una respuesta razonable a la primera, puedes hacerla mucho más precisa y consistente revisando el SQL generado y añadiendo consultas verificadas.
Sigue este flujo práctico:
Imagina que has preguntado: “¿Cuál fue la duración media de los viajes en junio de 2024?” En la respuesta inicial, el agente devuelve 26,68 minutos y excluye correctamente viajes de menos de 1 minuto. Ahora bien, si la regla estándar del equipo es excluir cualquier viaje de menos de 5 minutos…
Al abrir el SQL generado (vía Open in Editor), ves que el filtro es solo duration_minutes >= 1.
Haz clic en Add query en la sección Verified Queries y crea esta entrada:
Pregunta:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes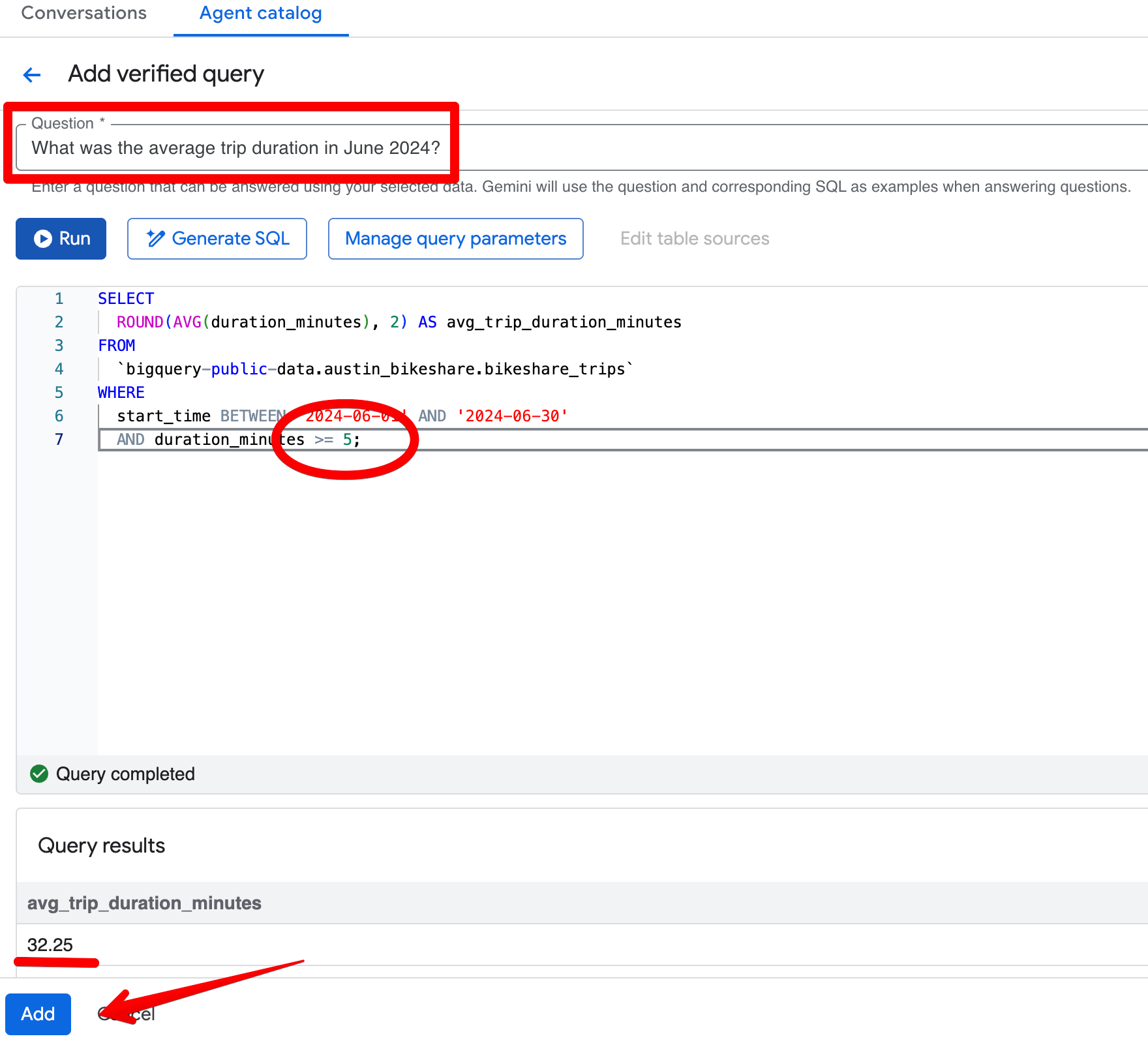
Tras guardar la consulta verificada, vuelve a hacer la misma pregunta en Preview. Ahora el agente devuelve de forma consistente ~32,08 minutos y aplica tu umbral más estricto de 5 minutos. Los resultados se alinean mejor con tu visión de viajes “significativos”.
La analítica conversacional de BigQuery destaca frente a herramientas simples de texto a SQL porque admite de forma nativa funciones de BigQuery ML, datos no estructurados y un uso compartido sencillo en todo el ecosistema de Google Cloud.
Una de las grandes diferencias es la capacidad del agente para llamar a funciones de BigQuery ML directamente desde lenguaje natural, y así pasar de informes retrospectivos a insights prospectivos.
Por ejemplo, puedes pedir a un agente que prediga el número diario de viajes para los próximos 30 días basándose en las tendencias de 2024. Invocará AI.FORECAST y generará una previsión para julio de 2024 junto a un gráfico con los viajes diarios históricos (línea azul) y el forecast a 30 días (línea naranja) con un intervalo de confianza del 95% sombreado.
Otra forma en la que ayudan los algoritmos de ML es detectando si algo no cuadra en tus datos. Si, por ejemplo, pides a un agente que detecte anomalías en el ridership diario durante junio de 2024, invocará AI.DETECT_ANOMALIES, comparará junio de 2024 con meses previos y devolverá una serie temporal y un gráfico de líneas.
En este caso, no señaló anomalías formales al 95% de confianza, pero destacó el 19 de junio como casi anomalía (92,1% de probabilidad) con una caída notable en el uso.
La mayoría de herramientas de BI conversacional fallan en cuanto los datos no están en filas y columnas. BigQuery, sin embargo, admite Object Tables, que permiten analizar datos no estructurados (como PDFs, imágenes y logs de texto) almacenados en Google Cloud Storage.
Gracias a las capacidades multimodales de Gemini, el Data Agent puede razonar a la vez con tus métricas estructuradas y tus ficheros no estructurados. Es un diferenciador enorme y único de BigQuery.
Si tienes PDFs de encuestas a usuarios o imágenes de inspecciones de estaciones en una object table, simplemente pide: “Resume las principales quejas de los PDFs de la encuesta a usuarios del Q2 de 2024”. El agente leerá esos ficheros no estructurados y combinará la información con tus datos estructurados de viajes
Tu equipo de datos crea y prueba Data Agents en BigQuery Studio, pero tus usuarios finales viven en otras aplicaciones. Google facilita desacoplar el agente de la consola de GCP para llegar al usuario de negocio allí donde ya trabaja.
Si quieres probar a crear tu propia aplicación de chat personalizada, también puedes leer más en la Introducción a la analítica conversacional en BigQuery oficial.
Si hay una idea clave que llevarte, es esta: la analítica conversacional traslada el cuello de botella analítico de esperar al equipo de datos a simplemente formular bien la pregunta.
Esta democratización no hace obsoletos a los equipos de datos, pero sí cambia su papel. Un agente de IA solo es tan inteligente como los límites que le pongas. La precisión y la seguridad de tus agentes dependen por completo de las instrucciones, el contexto y la arquitectura de esquemas que definas.
Para crear agentes conversacionales realmente eficaces, sigues necesitando un dominio sólido del data warehouse subyacente. Si tú o tu equipo queréis reforzar esas competencias y dominar la plataforma que potencia estas funciones de IA, echa un vistazo hoy al curso Introduction to BigQuery de DataCamp.
Cursos de Google Cloud
programa
Curso
Curso
blog
Matt Crabtree
13 min
blog
Abid Ali Awan
10 min
blog
Austin Chia
blog
Matt Crabtree
12 min
Tutorial
Moez Ali
Tutorial
Adel Nehme