
Program
Google Cloud Digital Leader
8 Hr
Jika Anda bekerja di tim data, skenario ini mungkin terasa akrab: backlog Anda penuh sesak dengan permintaan ad-hoc. Pengguna bisnis terus-menerus membutuhkan variasi sederhana dari laporan yang sudah ada, bertanya, "Bisakah Anda mengelompokkan ini berdasarkan kategori produk?", atau "Bagaimana perbandingannya dengan bulan lalu?" Saat mereka menunggu giliran untuk mendapatkan jawaban, engineer dan analis data Anda tertimbun tugas SQL yang berulang.
Dengan Conversational Analytics di BigQuery, Anda akhirnya dapat menggeser bottleneck tersebut. Fitur ini menghadirkan mesin penalaran bertenaga AI langsung ke BigQuery Studio, memungkinkan pengguna mengajukan pertanyaan dalam bahasa alami dan segera menerima data, bagan, serta SQL yang dihasilkan.
Dalam panduan ini, Anda akan mempelajari cara menyiapkan dan menggunakan analitik percakapan di BigQuery. Anda akan membangun, mengonfigurasi, dan menyempurnakan agen data Anda sendiri, sehingga organisasi Anda dapat berinteraksi dengan data secara aman.
Conversational analytics mengalihkan interaksi data dari kueri SQL manual ke percakapan bahasa alami. Alih-alih menulis pernyataan SELECT, Anda berinteraksi dengan agen data yang memahami konteks bisnis Anda dan mengembalikan jawaban yang berlandaskan pada tabel aktual Anda.
Ini bukan sekadar parser text-to-SQL dasar; ini adalah langkah besar menuju demokratisasi data yang sesungguhnya.
Fitur ini memungkinkan pengguna non-teknis mengakses insight real-time secara mandiri, dan memberikan profesional data cara cepat untuk mengeksplorasi dataset serta mengotomatiskan pelaporan.
Inti dari analitik percakapan BigQuery adalah mesin penalaran yang didukung oleh keluarga model Gemini. Agen data menggunakan pipeline terstruktur multi-tahap untuk memastikan insight didasarkan pada konteks data spesifik Anda:
Google Cloud menawarkan analitik percakapan di berbagai lapisan stack data Anda. Memilih titik masuk yang tepat bergantung pada pengguna Anda dan di mana logika bisnis Anda berada:
|
Fitur |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (melalui BigQuery Agents) |
|
Terbaik Untuk |
Tim data, analis, dan developer yang membangun aplikasi kustom |
Pengguna bisnis yang membutuhkan insight terkelola siap-dasbor |
Pengguna bisnis yang lebih menyukai pelaporan BI ringan |
|
Metode Grounding |
Skema gudang data langsung, metadata tabel, dan kueri terverifikasi |
LookML (lapisan semantik) |
Terhubung langsung ke agen data BigQuery yang sudah dibuat |
|
Akses Data |
Dapat menganalisis data terstruktur, prediktif (ML), dan tidak terstruktur |
Data terstruktur dan termodelkan secara ketat |
Data terstruktur |
|
Status Rilis |
Pratinjau (per Mei 2026) |
Tersedia umum |
Pratinjau |
Jalur mana yang harus Anda pilih?
Tutorial ini berfokus pada BigQuery sebagai cara tercepat bagi tim data untuk membuat prototipe dan memproduksi agen langsung di tempat data berada.
Penting untuk memahami arsitektur agen data sebelum menyiapkannya. Di lingkungan Google Cloud, agen data adalah lapisan abstraksi pusat. Ini menggabungkan aset BigQuery dengan kemampuan penalaran dari keluarga model Gemini.
Alih-alih mengekspos tabel mentah secara langsung, agen data mengonfigurasi semua yang dibutuhkan model untuk menafsirkan pertanyaan, menghasilkan SQL yang aman, dan mengembalikan jawaban yang tepercaya. Kombinasi sumber data, instruksi, dan logika terverifikasi ini membuat analitik percakapan BigQuery lebih andal daripada alat text-to-SQL standar.
Sumber pengetahuan adalah lapisan dasar dari setiap agen data. Mereka mendefinisikan dengan tepat data apa yang diizinkan untuk diakses dan dikueri oleh agen.
Jenis aset: Tabel, View, dan User Defined Functions (UDF) dapat terhubung sebagai sumber pengetahuan.
Skalabilitas: Beberapa sumber pengetahuan dapat terhubung ke satu agen. Ini memungkinkan agen menggabungkan informasi di berbagai area bisnis.
Kontrol akses: Mendefinisikan sumber pengetahuan tertentu memastikan agen hanya beroperasi dalam data yang berizin.
Kecerdasan agen bergantung pada konteks yang diberikan. Ini kunci agar model generik memahami bahasa sebuah perusahaan.
Dengan mendefinisikan instruksi khusus, sinonim, dan glosarium bisnis, agen di-grounding dalam domain tertentu. Misalnya, agen dapat diajarkan bahwa "Top Customers" merujuk pada pengguna dengan nilai umur pelanggan (LTV) di atas $1.000.
Elemen Grounding Kunci:
Instruksi khusus: Berikan arahan tingkat tinggi, seperti "Selalu kecualikan akun uji internal dari laporan pendapatan."
Glosarium bisnis: Petakan istilah teknis ke bahasa alami, misalnya, store_id menjadi "Lokasi Cabang".
Metadata field: Deskripsi yang membantu agen memahami nuansa variabel tertentu, seperti "Pendapatan Kotor" versus "Laba Bersih".
Semakin baik instruksi dan metadata Anda, semakin tinggi akurasi agen.
Kueri terverifikasi, sebelumnya dikenal sebagai Golden Queries, adalah pasangan pertanyaan-dan-jawaban yang telah ditentukan yang berfungsi sebagai sumber kebenaran. Dengan memetakan pertanyaan spesifik ke SQL yang dikurasi pakar, agen menggunakan jalur join dan filter yang benar untuk KPI kritis.
Kueri ini dapat menyertakan fungsi BigQuery ML (BQML). Ini memungkinkan agen menangani permintaan lanjutan, seperti menghasilkan prediksi churn atau prakiraan penjualan, menggunakan parameter model persis yang ditetapkan oleh ilmuwan data. Setelah diverifikasi, aset ini dikelola melalui Dataplex Universal Catalog, memastikan konsistensi di seluruh organisasi.
Sekarang setelah Anda memahami blok pembangunnya, mari beralih ke pembangunan dan konfigurasi agen data pertama Anda.
Untuk mengikuti tutorial kami, pastikan Anda memiliki prasyarat berikut:
Sebelum membangun agen pertama Anda, Anda harus mengonfigurasi proyek Google Cloud dan memastikan akun pengguna Anda memiliki izin yang diperlukan. Data Agents beroperasi sebagai lapisan di atas data yang sudah ada, jadi konfigurasi IAM (Identity and Access Management) yang benar sangat penting untuk keamanan dan fungsionalitas.
Ikuti langkah-langkah berikut:
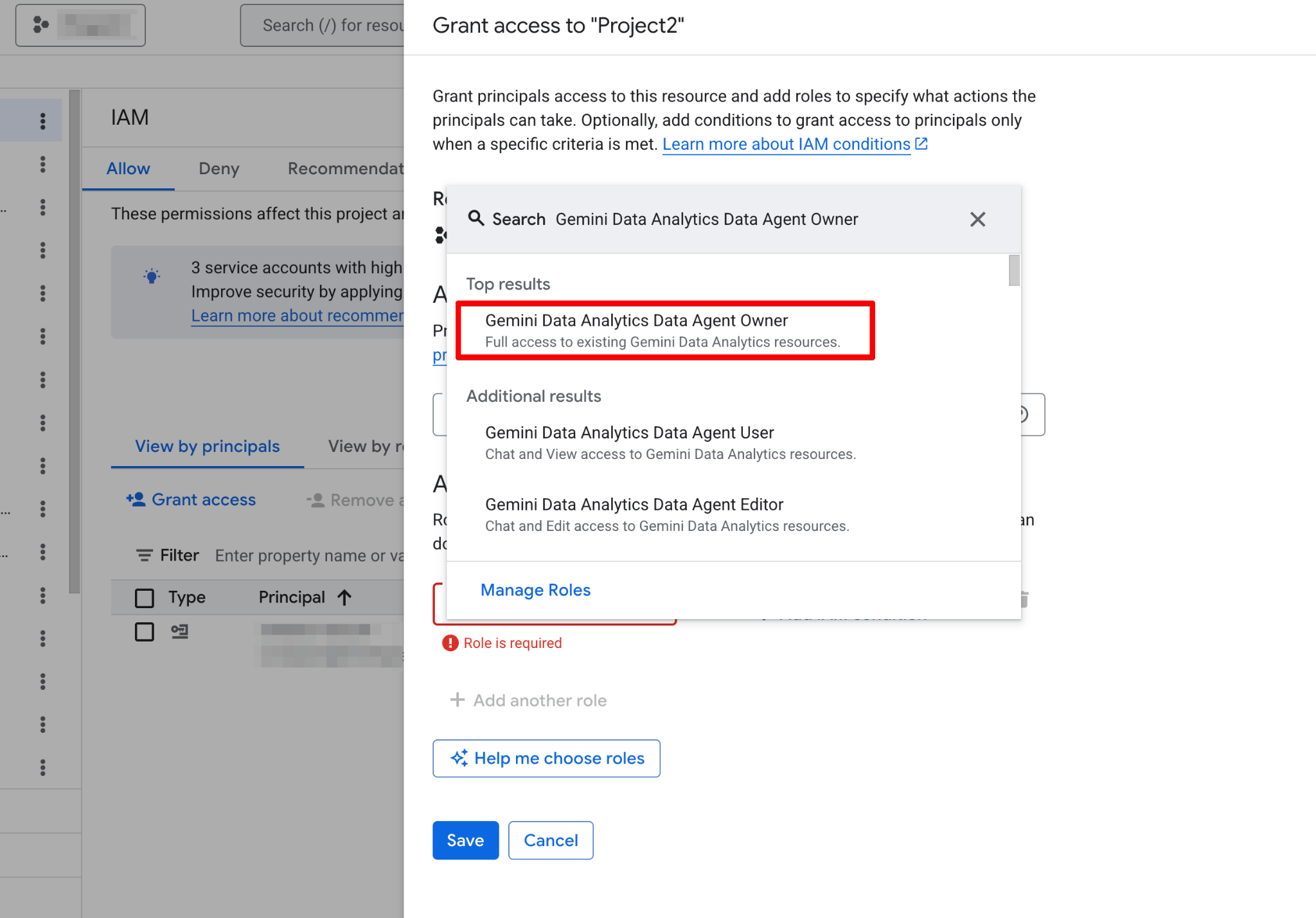
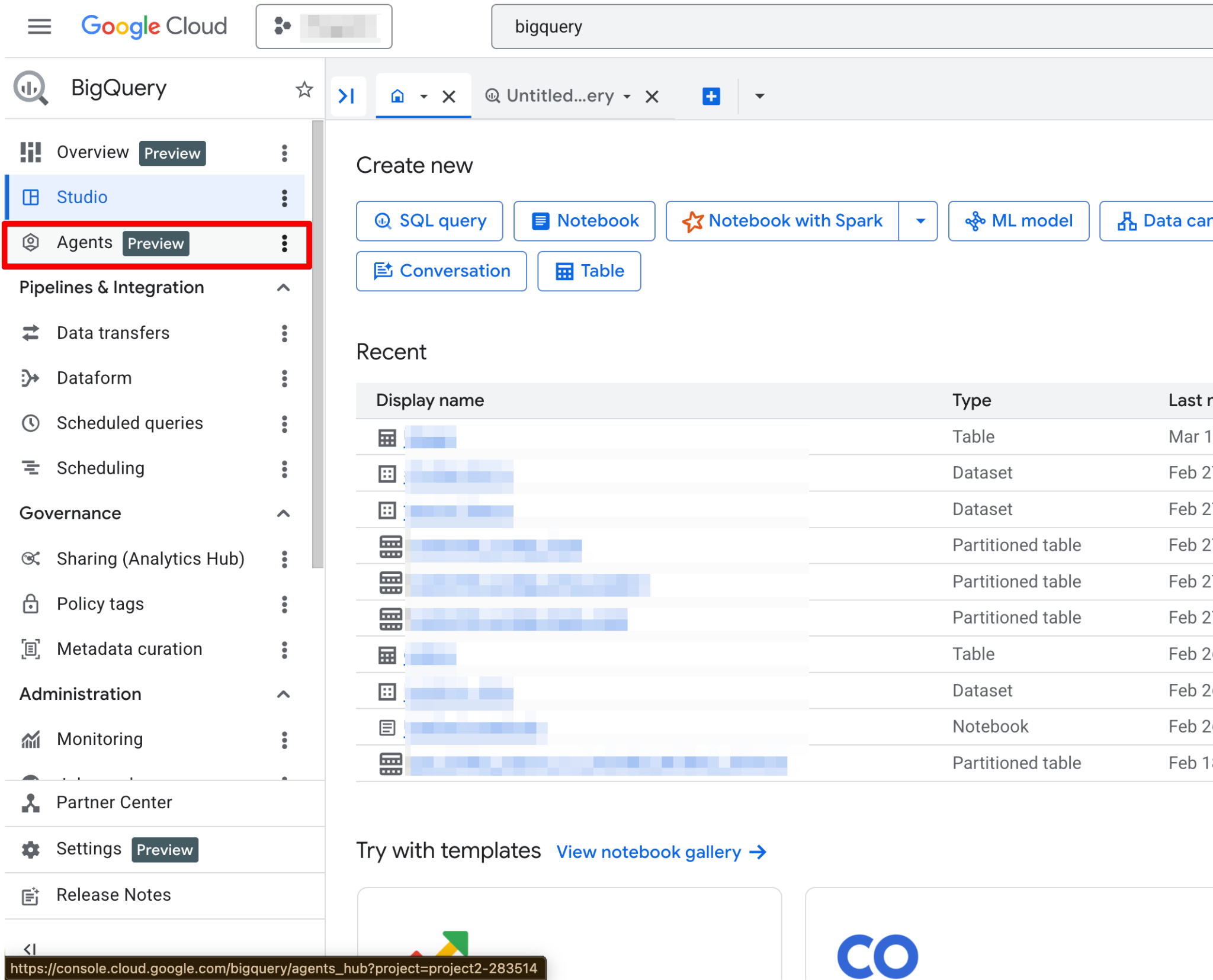
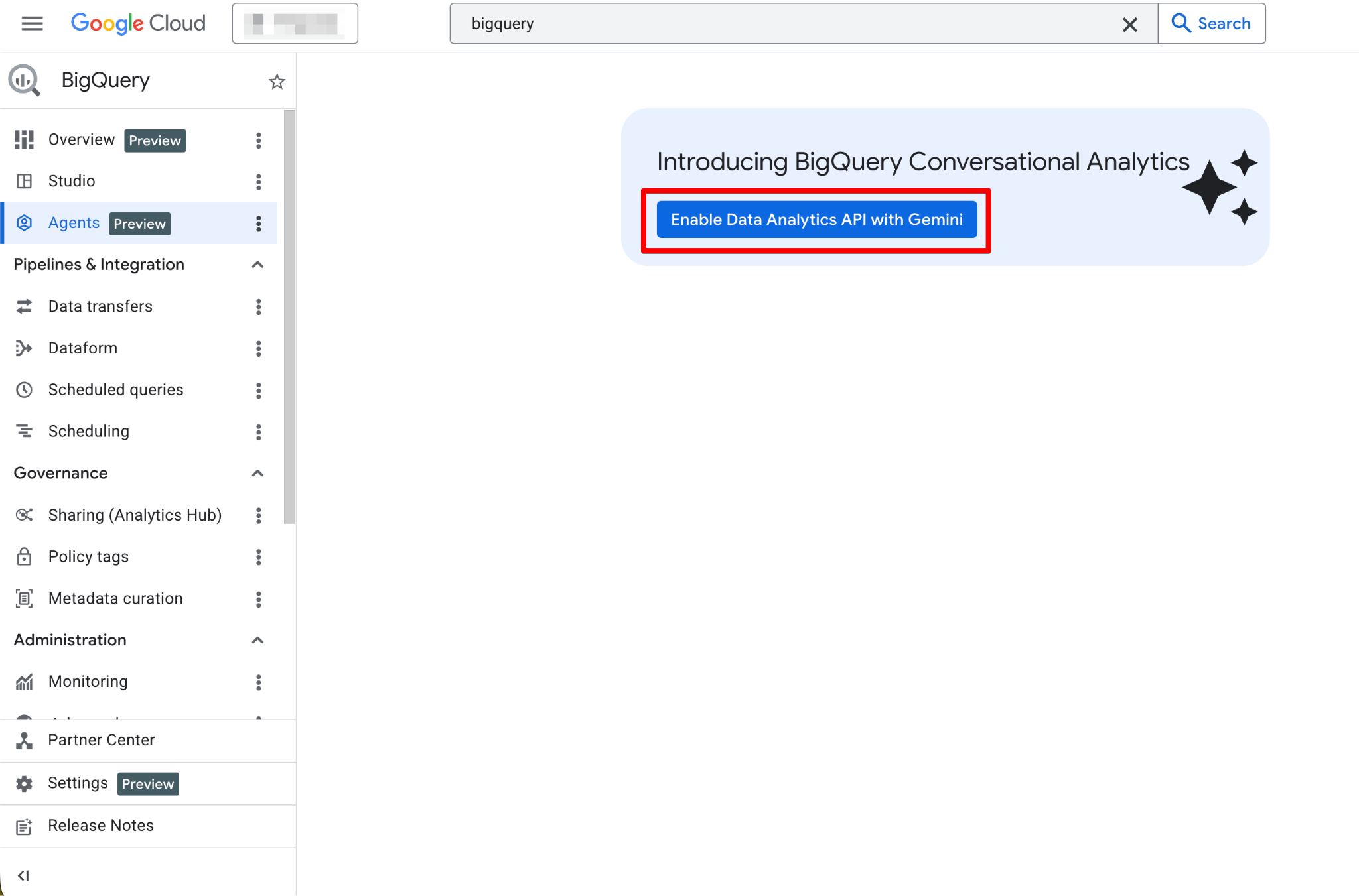
Setelah diaktifkan, halaman Agents menjadi sepenuhnya fungsional. Anda sekarang seharusnya melihat halaman agen baru:
Agent Catalog digunakan untuk membuat, mengelola, dan melakukan versioning agen data di BigQuery Studio.
Berikut yang akan Anda temukan di Agent Catalog:
Siklus hidup agen mengikuti struktur ini (Draft → Created → Published):
Klik kartu agen mana pun untuk membukanya, melihat detail, memulai percakapan, atau mengedit (jika Anda memiliki izin Owner). Antarmuka juga menyertakan tab Conversations tempat Anda dapat mengelola chat sebelumnya dengan agen atau sumber data.
Setelah fondasinya siap, mari membangun Agen Data dari nol. Kita akan menggunakan dataset bigquery-public-data.austin_bikeshare untuk mengubah data perjalanan mentah menjadi antarmuka percakapan. Kita akan menggunakan dua tabel:
bikeshare_trips — data detail tingkat perjalanan
bikeshare_stations — metadata stasiun
Memulai pembuatan agen
Dua field ini membantu Anda dengan cepat mengidentifikasi agen nanti. Setelah disetel, Anda siap mengonfigurasi tiga blok bangunan inti yang telah kita bahas sebelumnya: sumber pengetahuan, instruksi, dan (nantinya) kueri terverifikasi.
Sumber pengetahuan mendefinisikan secara tepat data apa yang dapat diakses agen. Semakin sedikit dan fokus sumbernya, semakin baik akurasi dan semakin rendah biaya. Di bagian Knowledge sources pada editor, klik Add source. Cari austin_bikeshare dan pilih bikeshare_trips serta bikeshare_stations sebagai sumber.
Untuk setiap tabel yang Anda tambahkan, klik Customize.
Gemini akan otomatis menghasilkan deskripsi dan menyarankan metadata kolom. Tinjau semuanya, terima saran yang akurat, lakukan penyesuaian, lalu klik Update.
Kesalahan umum adalah menambahkan 50 tabel sekaligus. Mulailah dengan 2–3 tabel inti. Ini memudahkan debug logika agen. Anda selalu dapat memperluas pengetahuan nanti setelah kueri inti akurat.
Selanjutnya, Anda perlu me-grounding agen dengan instruksi. Alih-alih hanya menulis prompt teks generik (mis., "Jawab pertanyaan tentang penjualan"), antarmuka agen data BigQuery memungkinkan Anda memberikan konteks yang sangat terstruktur untuk memandu AI dalam menghasilkan kueri. Anggap ini sebagai proses onboarding analis baru dengan kamus data perusahaan Anda yang tepat.
Gunakan field Instructions untuk memberikan konteks bisnis terstruktur. Berikut contoh lengkap siap pakai yang dapat Anda tempel:
Sinonim: Definisikan istilah alternatif untuk kolom Anda agar agen memahami variasi bahasa alami. Contoh: "Journey", "Ride", dan "Commute" semuanya merujuk pada satu record di tabel bikeshare_trips. "Dock", "Hub", atau "Station" merujuk pada satu record di tabel bikeshare_stations.
Field kunci: Soroti field terpenting untuk analisis. Ini memberi tahu agen kolom mana yang diprioritaskan saat pertanyaan pengguna bersifat umum. Contoh: Prioritaskan trip_id, start_station_name, end_station_name, subscriber_type, start_time, dan duration_minutes untuk pelaporan umum.
Field yang dikecualikan: Tentukan kolom yang harus benar-benar dihindari agen data. Ini sangat berguna untuk menyembunyikan kolom usang atau data yang tidak relevan. Contoh: Jangan gunakan kolom bike_id di tabel bikeshare_trips untuk sebagian besar analisis, karena jarang dibutuhkan untuk pertanyaan bisnis.
Pemfilteran dan pengelompokan: Instruksikan agen tentang cara standar memotong data. Contoh: Kecuali ditentukan lain, selalu kecualikan perjalanan di mana duration_minutes < 1 (ini adalah false start atau uji coba). Secara default kelompokkan data berdasarkan start_station_name ketika pengguna meminta “berdasarkan stasiun” atau “stasiun teratas”.
Relasi join: Karena agen kita menarik dari beberapa tabel, definisikan secara eksplisit cara mereka terhubung. Ini memastikan agen tidak menebak foreign key yang salah. Contoh: Join tabel bikeshare_trips ke tabel bikeshare_stations dengan memasangkan bikeshare_trips.start_station_id ke bikeshare_stations.station_id (dan serupa untuk end_station_id).
Anda dapat menggabungkan semua hal di atas menjadi satu blok bersih di field Instructions. Berikut versi yang sudah dipoles dan siap ditempel yang menggabungkan panduan terstruktur:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).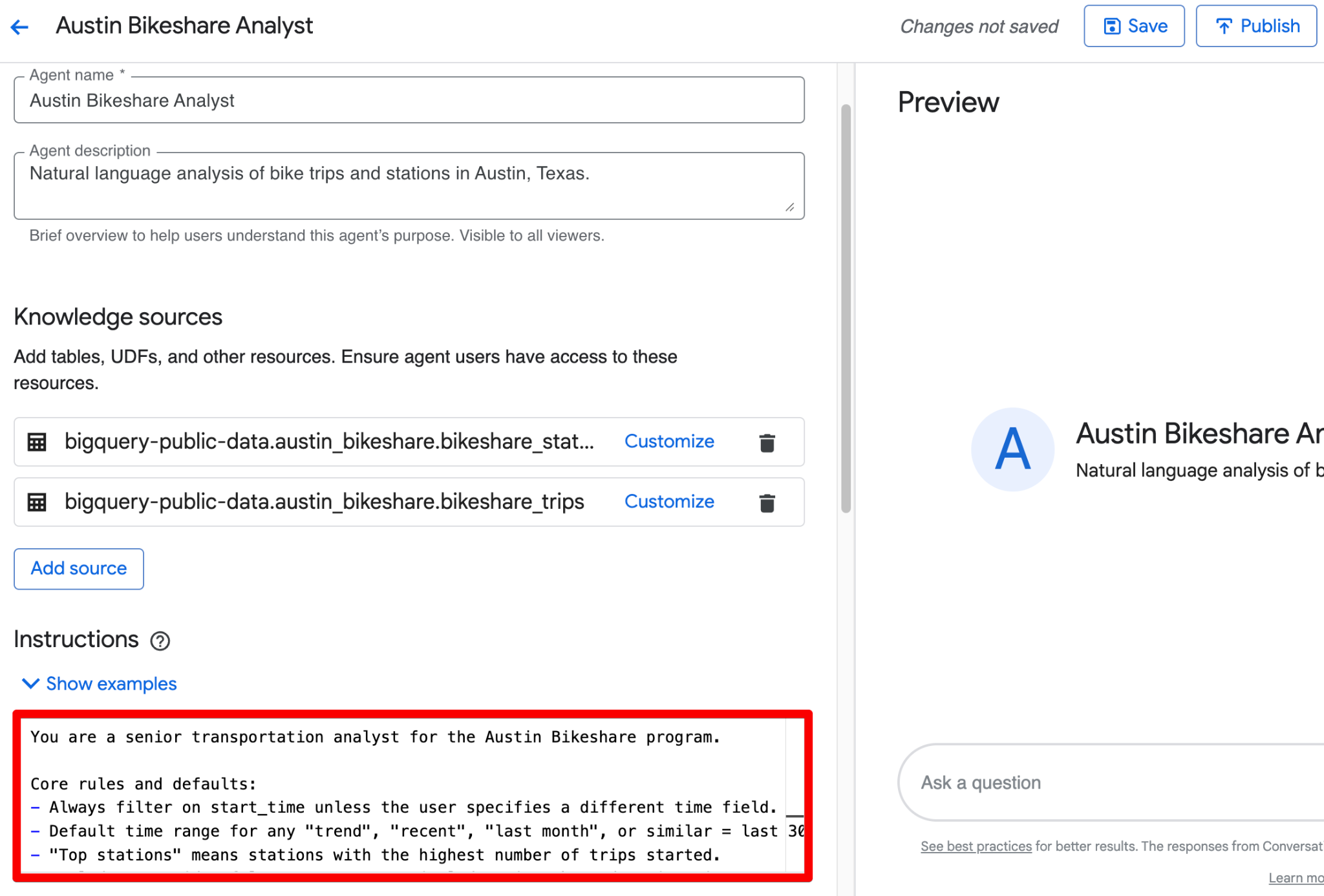
Mengapa ini penting: Jika Anda membiarkan field ini kosong, pertanyaan ambigu seperti "Penjualan teratas kami apa?" dapat menyebabkan agen men-join tabel yang salah, menarik dari akun tidak aktif, atau menyertakan data usang. Dengan menstrukturkan instruksi Anda di lima kategori ini, Anda memastikan SQL yang dihasilkan mematuhi ketat logika bisnis yang telah Anda tetapkan.
Selain instruksi, Anda dapat (dan sebaiknya) mendefinisikan istilah glosarium langsung di agen. Ini membantu agen menafsirkan jargon bisnis, singkatan, dan konsep turunan secara konsisten.
Klik Add term di bagian Glossary (biasanya dekat Instructions) dan buat istilah dengan istilah, definisi, dan sinonim (dipisahkan koma).
Berikut istilah glosarium yang direkomendasikan untuk dataset Austin Bikeshare:
| Istilah | Definisi | Sinonim |
duration_minutes |
Durasi perjalanan dalam menit. Selalu gunakan ini untuk jawaban dan perhitungan yang menghadap pengguna | waktu berkendara, lama perjalanan, durasi, durasi berkendara |
ridership |
Jumlah total (hitung) perjalanan sepeda yang dimulai | trips, rides, journeys, penggunaan sepeda, jumlah komuter |
peak_hours |
Jam puncak pagi (7-9) atau sore (16-19) berdasarkan jam yang diekstrak dari start_time |
jam sibuk, jam ramai, periode permintaan tinggi |
subscriber_type |
Jenis pengendara — Subscriber (pemegang pass bulanan atau tahunan) atau Customer (perjalanan sekali | tipe pengguna, jenis keanggotaan, pemegang pass, member, pengendara kasual |
false_start |
Perjalanan yang sangat singkat (biasanya di bawah 1 menit) yang kemungkinan merupakan uji coba atau pembukaan kunci tidak sengaja. Ini biasanya harus dikecualikan dari analisis | uji coba, perjalanan tidak valid, perjalanan singkat |
Anda dapat menambahkan lebih banyak istilah sesuai kebutuhan (misalnya, untuk start_station_name, end_station_name, atau metrik turunan seperti “rata-rata durasi perjalanan” atau “perjalanan panjang”).
Dengan menggunakan glosarium, jika pimpinan memutuskan untuk mengubah definisi resmi “Perjalanan Panjang” menjadi 45 menit pada kuartal berikutnya, tim tata kelola data Anda hanya perlu memperbaruinya sekali di Dataplex. Setiap Data Agent yang terhubung ke glosarium tersebut akan langsung mengadopsi logika baru, sehingga Anda tetap konsisten di seluruh organisasi.
Setelah Anda mengonfigurasi sumber pengetahuan, instruksi, dan istilah glosarium, saatnya menguji agen Anda sebelum dipublikasikan.
Gulir ke sisi kanan layar ke panel Preview. Antarmuka chat langsung ini memungkinkan Anda berinteraksi dengan agen secara real-time saat Anda membangunnya. Anda dapat mengajukan pertanyaan, meninjau penalaran agen, memeriksa SQL yang dihasilkan, dan beriterasi dengan cepat.
Panel Preview menampilkan:
Coba empat kueri dengan tingkat kompleksitas meningkat (disesuaikan dengan rentang data dataset hingga 2024):
Apa yang akan Anda lihat di respons agen:
Ringkasan — Penjelasan hasil dalam bahasa alami.
Hasil kueri — Tabel rapi dengan data (mis., total perjalanan, stasiun teratas, atau durasi rata-rata).
Insight — Poin-poin utama yang menafsirkan hasil dalam konteks bisnis.
SQL yang dihasilkan — Klik Open in Editor untuk melihat kueri SQL lengkap yang dibuat agen (Anda akan melihatnya memfilter dengan benar pada start_time dan menerapkan duration_minutes >= 1 untuk mengecualikan false start).
Pertanyaan lanjutan yang disarankan — Prompt bantuan di bagian bawah (mis., “Apa 10 stasiun mulai teratas pada Juni 2024?”, “Buat prakiraan jumlah perjalanan harian…”, dll.).
Visualisasi — Bagan yang dihasilkan otomatis (diagram batang untuk pemeringkatan, seperti pada contoh 5 stasiun teratas Anda).
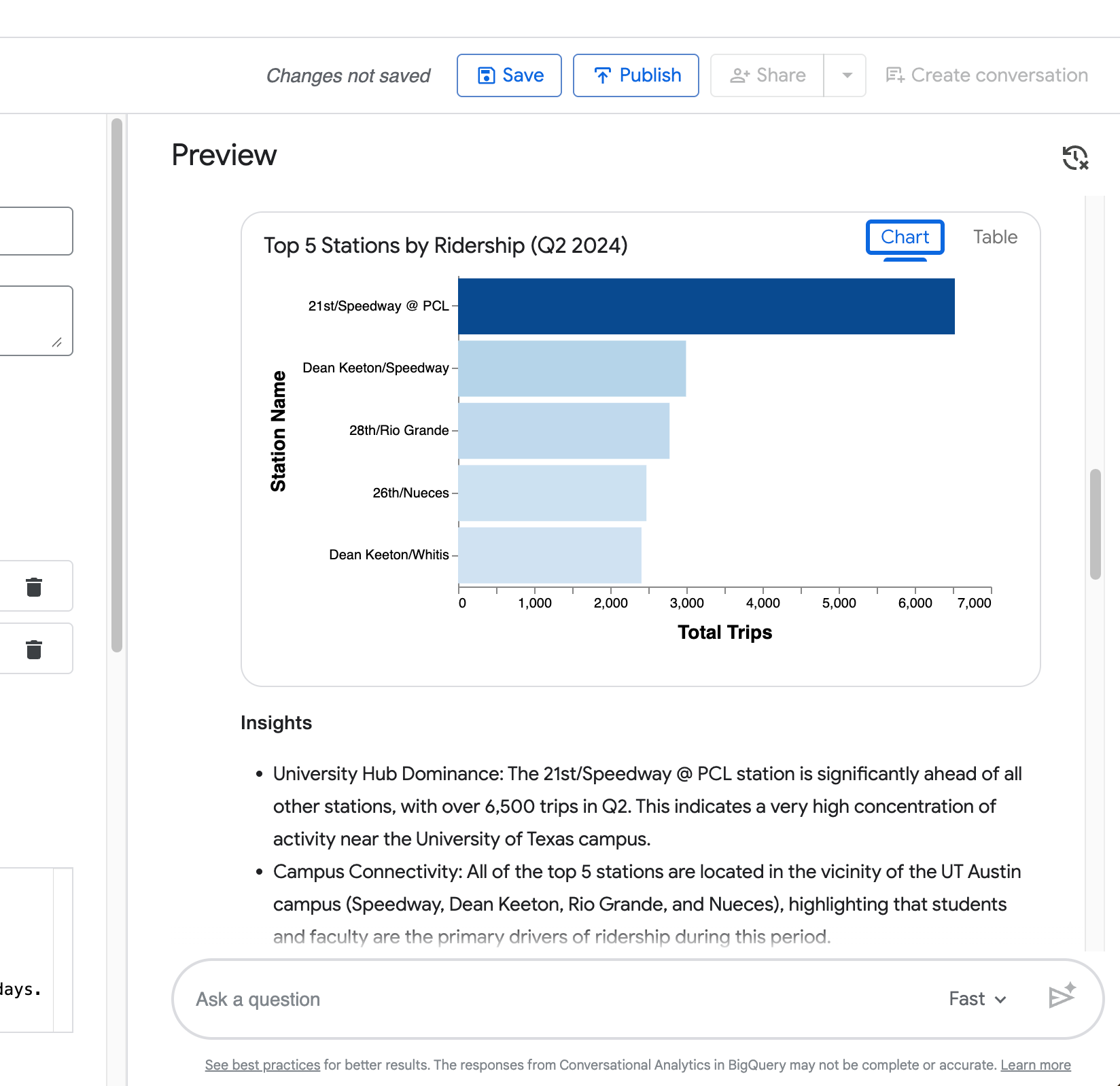
Kueri keempat Anda (“Sekarang tampilkan perbandingan yang sama tetapi hanya untuk stasiun Zilker Park”) menunjukkan kemampuan agen untuk mempertahankan konteks dari pertanyaan sebelumnya.
Seperti yang terlihat pada tangkapan layar berikut, agen mempersempit perbandingan durasi hari kerja vs akhir pekan ke Zilker Park dengan benar tanpa Anda mengulangi permintaan lengkap.
Tips pengujian:
Setelah agen secara konsisten memberikan jawaban yang jelas, akurat, dan terstruktur dengan baik, klik Save di bagian atas, lalu Publish. Agen Austin Bikeshare Analyst Anda sekarang siap digunakan!
Bahkan dengan instruksi dan istilah glosarium yang baik, agen data Anda masih sesekali dapat salah menafsirkan aturan bisnis atau menghasilkan jawaban yang tidak konsisten.
Kueri terverifikasi mengatasi hal ini dengan memungkinkan Anda secara eksplisit mengajarkan cara yang benar kepada agen untuk menangani pertanyaan penting atau sering ditanyakan. Setiap kueri terverifikasi terdiri dari pertanyaan bahasa alami yang dipasangkan dengan SQL persis yang harus digunakan.
Kueri ini berfungsi sebagai contoh berkualitas tinggi yang menjadi jangkar penalaran agen dan merupakan salah satu cara paling efektif untuk beralih dari agen “cukup baik” menjadi siap produksi.
Di editor agen, gulir ke bagian Verified Queries. Ada dua cara mudah untuk menambahkan kueri terverifikasi:
Klik Add query. Anda akan melihat layar Add verified query, tempat Anda dapat:
Klik View Gemini-generated suggestions. Ini akan membuka layar “Review suggested verified queries”, tempat Gemini mengusulkan pertanyaan relevan berdasarkan sumber pengetahuan Anda.
Anda dapat:
Kueri terverifikasi yang baik untuk dataset Austin Bikeshare dapat berupa:
Pertanyaan:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;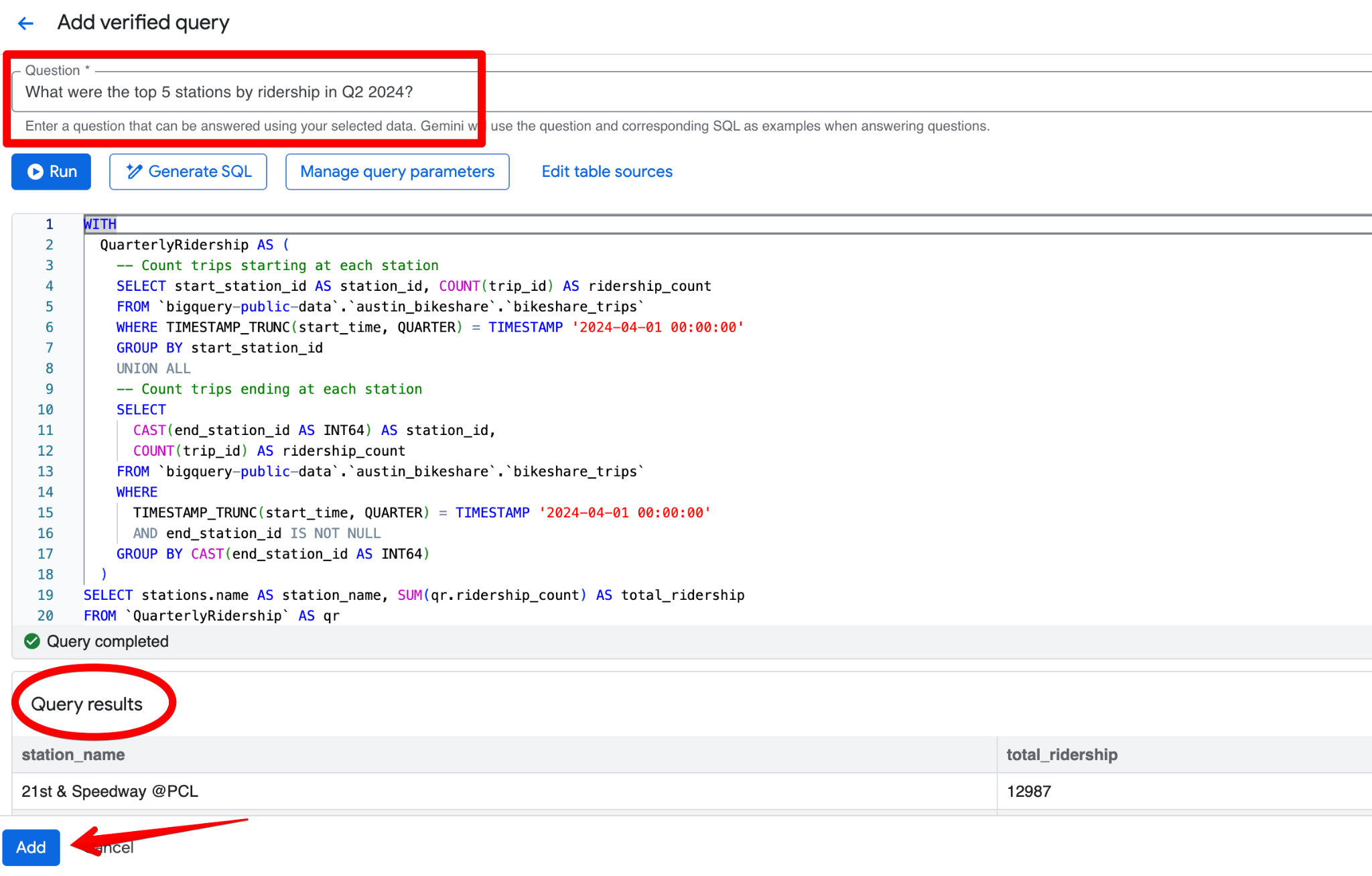
Bahkan ketika agen memberikan jawaban yang wajar pada percobaan pertama, Anda dapat membuatnya jauh lebih akurat dan konsisten dengan meninjau SQL yang dihasilkan dan menambahkan kueri terverifikasi.
Ikuti alur kerja praktis ini:
Misalnya, Anda bertanya, “Berapa rata-rata durasi perjalanan pada Juni 2024?” Pada respons awal, agen mengembalikan 26,68 menit dan dengan benar mengecualikan perjalanan kurang dari 1 menit. Sekarang, anggap aturan bisnis standar tim adalah mengecualikan perjalanan kurang dari 5 menit.
Saat Anda membuka SQL yang dihasilkan (melalui Open in Editor), Anda melihat filternya hanya duration_minutes >= 1.
Klik Add query di bagian Verified Queries dan buat entri ini:
Pertanyaan:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes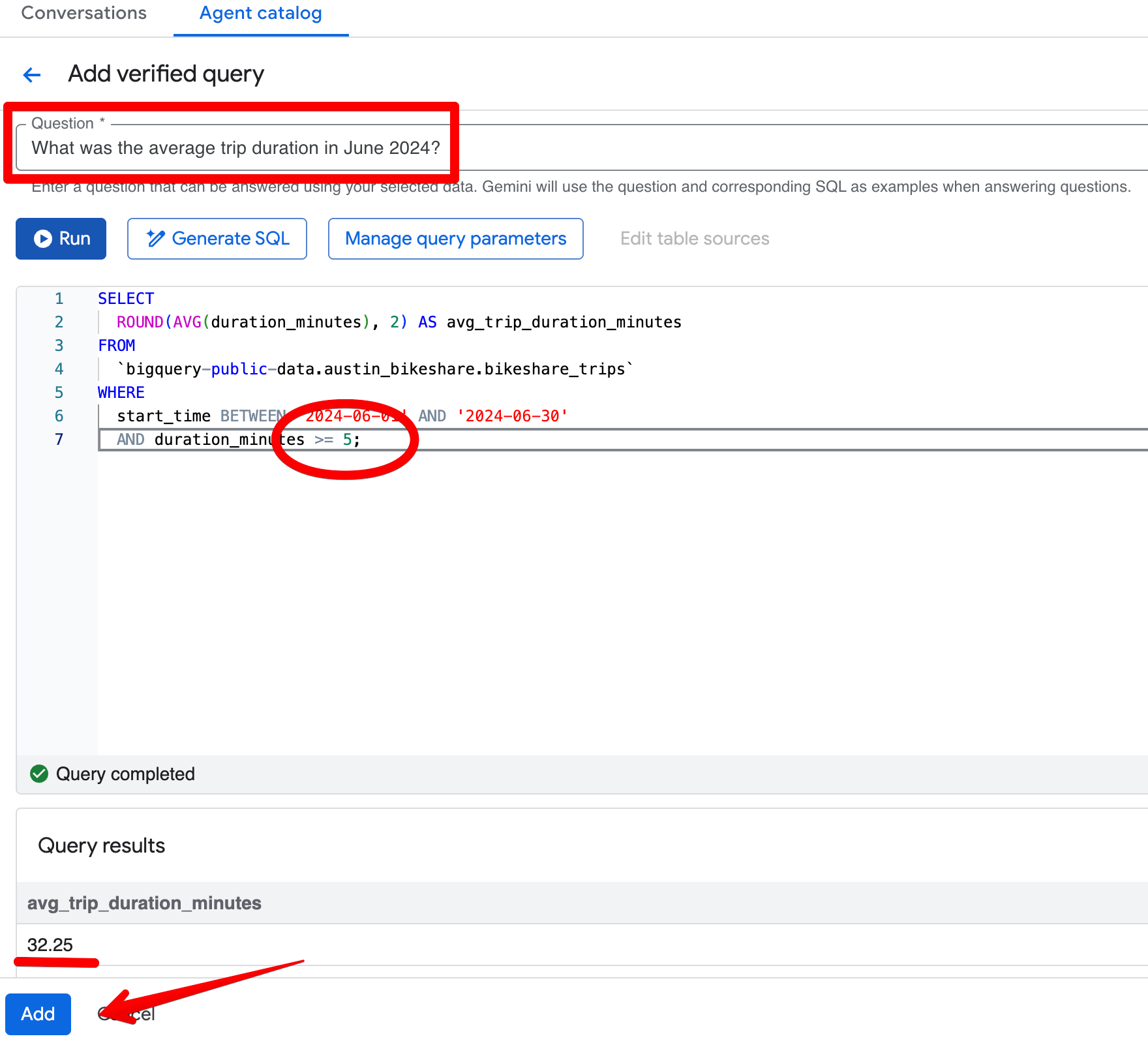
Setelah menyimpan kueri terverifikasi, ajukan kembali pertanyaan yang sama di panel Preview. Agen sekarang secara konsisten mengembalikan ~32,08 menit dan menerapkan ambang 5 menit yang lebih ketat. Hasilnya menjadi lebih selaras dengan pandangan bisnis Anda tentang perjalanan yang “bermakna”.
Analitik percakapan BigQuery menonjol dari alat text-to-SQL sederhana dengan dukungan native untuk fungsi BigQuery ML, data tidak terstruktur, dan kemudahan berbagi di seluruh ekosistem Google Cloud.
Salah satu pembeda terbesar adalah kemampuan agen untuk memanggil fungsi BigQuery ML langsung dari bahasa alami, sehingga melampaui pelaporan retrospektif menuju insight prospektif.
Misalnya, Anda dapat meminta agen data untuk memprediksi jumlah perjalanan harian selama 30 hari ke depan berdasarkan tren 2024. Agen akan memicu AI.FORECAST, dan menghasilkan prakiraan untuk Juli 2024 beserta bagan indah yang menampilkan perjalanan harian historis (garis biru) dan prakiraan 30 hari (garis oranye) dengan interval kepercayaan 95% yang diarsir.
Cara lain algoritma machine learning dapat membantu adalah dengan mendeteksi jika ada sesuatu yang tidak beres pada data Anda. Ketika, misalnya, Anda meminta agen mendeteksi anomali dalam ridership harian selama Juni 2024, agen akan memanggil AI.DETECT_ANOMALIES, membandingkan Juni 2024 dengan bulan-bulan sebelumnya, dan mengembalikan tabel deret waktu plus bagan garis.
Dalam kasus ini, tidak ada anomali formal pada tingkat kepercayaan 95% tetapi menyoroti 19 Juni sebagai hampir-anomali (probabilitas 92,1%) dengan penurunan ridership yang mencolok.
Sebagian besar alat BI percakapan gagal saat data tidak tertata rapi dalam baris dan kolom. Namun, BigQuery mendukung Object Tables, yang memungkinkan Anda menganalisis data tidak terstruktur (seperti PDF, gambar, dan log teks mentah) yang disimpan di Google Cloud Storage.
Karena Data Agent didukung oleh kemampuan multimodal Gemini, agen dapat melakukan penalaran di seluruh metrik terstruktur dan file tidak terstruktur Anda secara bersamaan. Ini adalah pembeda besar dan unik untuk BigQuery.
Jika Anda memiliki PDF survei pengendara atau gambar inspeksi stasiun dalam object table, cukup tanyakan, “Ringkas keluhan utama dari PDF survei pengendara Q2 2024.” Agen akan membaca file tidak terstruktur dan menggabungkan informasi tersebut dengan data perjalanan terstruktur Anda
Tim data Anda membangun dan menguji Data Agents di BigQuery Studio, tetapi pengguna akhir Anda kemungkinan bekerja di aplikasi yang sama sekali berbeda. Google memudahkan untuk memisahkan agen dari GCP Console sehingga Anda dapat hadir di tempat para pengguna bisnis sudah bekerja.
Jika Anda ingin mencoba membangun aplikasi chat kustom sendiri, Anda juga dapat membaca lebih lanjut di Introduction to Conversational Analytics in BigQuery resmi.
Jika ada satu prinsip kunci yang perlu diambil, ini dia: analitik percakapan menggeser bottleneck analitis dari menunggu tim data menjadi sekadar mengajukan pertanyaan yang tepat.
Demokratisasi ini bukan berarti tim data menjadi usang, namun perannya berubah. Agen AI hanya sepintar pagar pembatas yang Anda bangun di sekitarnya. Akurasi dan keamanan agen data Anda sepenuhnya bergantung pada instruksi, konteks, dan arsitektur skema yang Anda sediakan.
Untuk membangun agen percakapan yang paling efektif, Anda tetap memerlukan penguasaan kuat terhadap gudang data yang mendasarinya. Jika Anda atau tim ingin memperkuat keterampilan inti tersebut dan menguasai platform yang memberdayakan fitur AI ini, lihat kursus DataCamp Introduction to BigQuery hari ini!
Kursus Google Cloud
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
David Woods
13 mnt
