track
Google Cloud Digital Leader
8 timmar
Om du arbetar i ett datateam känner du säkert igen det här: er backlogg svämmar över av ad hoc-begäranden. Verksamhetsanvändare behöver ständigt enkla varianter av befintliga rapporter och frågar: ”Kan du gruppera det här efter produktkategori?” eller ”Hur står det sig jämfört med förra månaden?” Medan de väntar i kö på ett svar begravs era dataingenjörer och analytiker i repetitiva SQL-uppgifter.
Med Conversational Analytics i BigQuery kan du äntligen flytta flaskhalsen. Denna funktion för in en AI-driven resonemangsmotor direkt i BigQuery Studio, så att användare kan ställa frågor på naturligt språk och omedelbart få data, diagram och genererad SQL.
I den här guiden lär du dig hur du ställer in och använder konversationsanalys i BigQuery. Du kommer att bygga, konfigurera och förfina egna dataagenter, så att din organisation på ett säkert sätt kan chatta med sina data.
Konversationsanalys flyttar interaktionen med data från manuella SQL-frågor till samtal i naturligt språk. I stället för att skriva SELECT-satser chattar du med en dataagent som förstår din affärskontext och ger svar förankrade i dina faktiska tabeller.
Det här är inte bara en enkel text-till-SQL-parser; det är ett avgörande steg mot verklig datademokratisering.
Det gör att icke-tekniska användare kan få tillgång till insikter i realtid på egen hand, och ger dataprofessionella ett snabbt sätt att utforska dataset och automatisera rapportering.
Kärnan i BigQuerys konversationsanalys är en resonemangsmotor som drivs av modellfamiljen Gemini. Dataagenter använder en strukturerad process i flera steg för att säkerställa att insikterna baseras på just din datakontext:
Google Cloud erbjuder konversationsanalys i olika lager av din datastack. Att välja rätt ingång beror på dina användare och var din affärslogik finns:
|
Funktion |
BigQuery Conversational Analytics |
Looker Conversational Analytics |
Data Studio (via BigQuery-agenter) |
|
Bäst för |
Datateam, analytiker och utvecklare som bygger skräddarsydda applikationer |
Verksamhetsanvändare som behöver styrda, instrumentpanelsklara insikter |
Verksamhetsanvändare som föredrar lättviktig BI-rapportering |
|
Förankringsmetod |
Direkta lagerscheman, tabellmetadata och verifierade frågor |
LookML (semantiskt lager) |
Anslutet direkt till färdigbyggda BigQuery-dataagenter |
|
Datatillgång |
Kan analysera strukturerad, prediktiv (ML) och ostrukturerad data |
Strikt strukturerad, modellerad data |
Strukturerad data |
|
Lanseringsstatus |
Förhandsversion (i maj 2026) |
Allmänt tillgänglig |
Förhandsversion |
Vilken väg ska du välja?
Den här handledningen fokuserar på BigQuery som det snabbaste sättet för datateam att prototypa och sätta agenter i produktion där data finns.
Det är viktigt att förstå en dataagents arkitektur innan du sätter upp den. I Google Cloud-miljön är en dataagent det centrala abstraktionslagret. Den kombinerar BigQuery-resurser med resonemangsförmågan hos modellfamiljen Gemini.
I stället för att exponera råtabeller direkt konfigurerar en dataagent allt modellen behöver för att tolka frågor, generera säker SQL och leverera tillförlitliga svar. Denna kombination av datakällor, instruktioner och verifierad logik gör BigQuerys konversationsanalys mer tillförlitlig än standardverktyg för text-till-SQL.
Kunskapskällor är den grundläggande nivån i varje dataagent. De definierar exakt vilken data agenten får komma åt och fråga.
Resurstyper: Tabeller, vyer och användardefinierade funktioner (UDF:er) kan anslutas som kunskapskällor.
Skalbarhet: Flera kunskapskällor kan kopplas till en enda agent. Detta gör att agenten kan kombinera information från olika affärsområden.
Åtkomstkontroll: Genom att definiera specifika kunskapskällor säkerställs att agenten bara arbetar inom auktoriserad data.
En agents intelligens beror på det sammanhang som tillhandahålls. Det är nyckeln till att få en generisk modell att förstå ett företags språk.
Genom att definiera anpassade instruktioner, synonymer och affärsordlistor förankras agenten i en specifik domän. Till exempel kan agenten läras att ”Top Customers” syftar på användare med ett livstidsvärde (LTV) över 1 000 $.
Viktiga förankringselement:
Anpassade instruktioner: Ge övergripande riktlinjer, som ”Exkludera alltid interna testkonton från intäktsrapporter.”
Affärsordlistor: Mappa tekniska termer till naturligt språk, till exempel store_id till ”Filialens läge”.
Fältmetadata: Beskrivningar som hjälper agenten att förstå nyanserna i specifika variabler, som ”Bruttointäkter” jämfört med ”Nettovinst”.
Ju bättre dina instruktioner och metadata är, desto högre blir agentens träffsäkerhet.
Verifierade frågor, tidigare kända som Golden Queries, är fördefinierade par av fråga och svar som fungerar som källan till sanning. Genom att mappa specifika frågor till expertgranskad SQL använder agenten korrekta join-vägar och filter för kritiska KPI:er.
Dessa frågor kan inkludera BigQuery ML-funktioner (BQML). Det gör att agenten kan hantera avancerade begäranden, såsom att generera churn-prognoser eller försäljningsprognoser, med exakt de modellparametrar som definierats av dataforskare. När de väl har verifierats hanteras dessa tillgångar via Dataplex Universal Catalog, vilket säkerställer konsekvens i hela organisationen.
Nu när du förstår byggstenarna går vi vidare till att faktiskt bygga och konfigurera din första dataagent.
För att följa vår handledning, se till att du har följande förutsättningar:
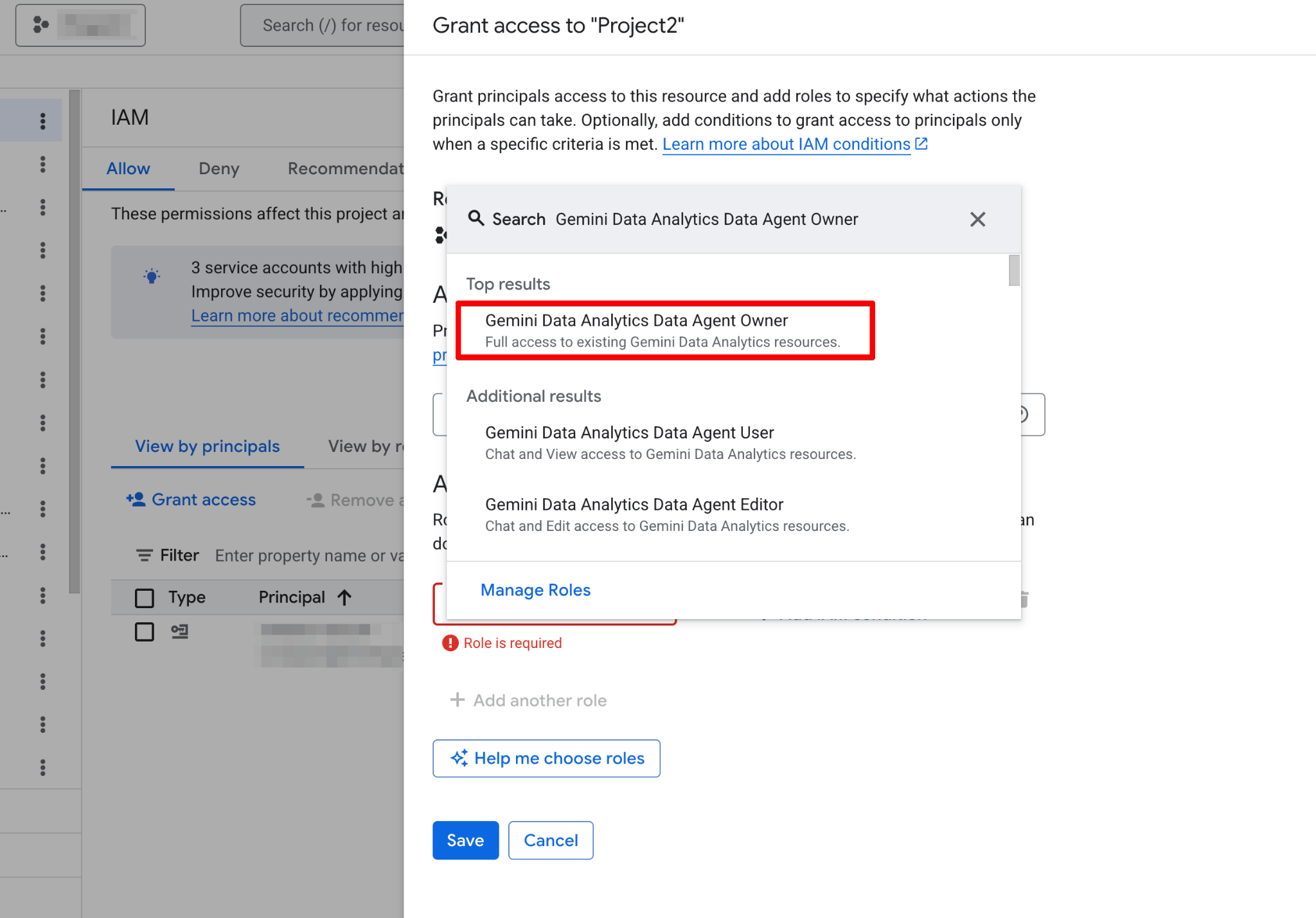
Innan du bygger din första agent måste du konfigurera ditt Google Cloud-projekt och säkerställa att ditt användarkonto har nödvändiga behörigheter. Dataagenter fungerar som ett lager ovanpå din befintliga data, så korrekt IAM-konfiguration (Identity and Access Management) är avgörande för både säkerhet och funktionalitet.
Följ dessa steg:
När det är aktiverat blir sidan Agents fullt fungerande. Du bör nu se den nya agentsidan:
Agentkatalogen används för att skapa, hantera och versionssätta dataagenter i BigQuery Studio.
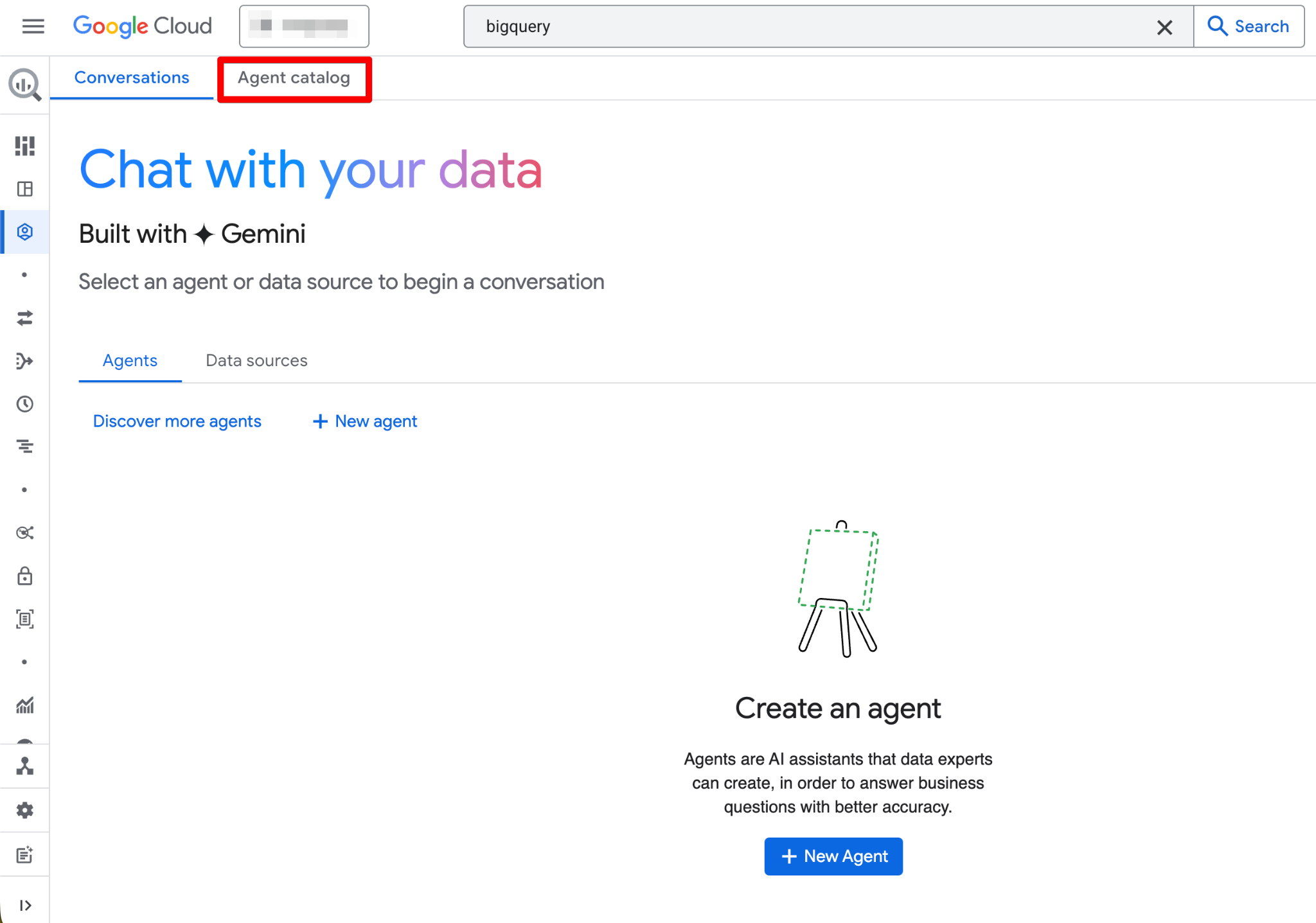
Här är vad du hittar i Agentkatalogen:
Agentens livscykel följer denna struktur (Draft → Created → Published):
Klicka på valfritt agentkort för att öppna det, visa detaljer, starta en konversation eller redigera (om du har Owner-behörighet). Gränssnittet innehåller också en flik Conversations där du kan hantera tidigare chattar med agenter eller datakällor.
Nu när grunden är lagd bygger vi en dataagent från grunden. Vi använder datasetet bigquery-public-data.austin_bikeshare för att förvandla råa reseuppgifter till ett konversationsgränssnitt. Vi använder två tabeller:
bikeshare_trips — detaljerad data på resenivå
bikeshare_stations — stationsmetadata
Starta agentskapandet
Dessa två fält hjälper dig att snabbt identifiera agenten senare. När de är satta är du redo att konfigurera de tre kärnblocken vi gick igenom tidigare: kunskapskällor, instruktioner och (senare) verifierade frågor.
Kunskapskällor definierar exakt vilken data agenten kan komma åt. Ju färre och mer fokuserade källor, desto bättre precision och lägre kostnad. I avsnittet Knowledge sources i editorn klickar du på Add source. Sök efter austin_bikeshare och välj bikeshare_trips och bikeshare_stations som källor.
För varje tabell du lägger till, klicka på Customize.
Gemini genererar automatiskt en beskrivning och föreslår kolumnmetadata. Granska allt, acceptera korrekta förslag, gör eventuella justeringar och klicka på Update.
Ett vanligt misstag är att lägga till 50 tabeller på en gång. Börja med 2–3 kärntabeller. Det gör det enklare att felsöka agentens logik. Du kan alltid utöka kunskapen senare när kärnfrågorna är korrekta.
Nästa steg är att förankra din agent med instruktioner. I stället för att bara skriva en generisk prompt (t.ex. ”Svara på frågor om försäljning”) kan du i BigQuerys dataagentsgränssnitt ge mycket strukturerat sammanhang för att styra AI:ns frågegenerering. Tänk på detta som att introducera en ny analytiker till ditt företags exakta datakatalog.
Använd fältet Instructions för att ge strukturerad affärskontext. Här är ett komplett, färdigt exempel du kan klistra in:
Synonymer: Definiera alternativa termer för dina kolumner så att agenten förstår naturliga språkvariationer. Exempel: ”Journey”, ”Ride” och ”Commute” syftar alla på en post i tabellen bikeshare_trips. ”Dock”, ”Hub” eller ”Station” syftar på en post i tabellen bikeshare_stations.
Nyckelfält: Lyft fram de viktigaste fälten för analys. Det talar om för agenten vilka kolumner som ska prioriteras när en användares fråga är bred. Exempel: Prioritera trip_id, start_station_name, end_station_name, subscriber_type, start_time och duration_minutes för allmän rapportering.
Exkluderade fält: Specificera kolumner som dataagenten strikt ska undvika. Detta är mycket användbart för att dölja utfasade kolumner eller irrelevant data. Exempel: Använd inte kolumnen bike_id i tabellen bikeshare_trips för de flesta analyser, eftersom den sällan behövs för affärsfrågor.
Filtrering och gruppering: Instruera agenten om standardmetoder att skära datan på. Exempel: Om inget annat anges, filtrera alltid bort resor där duration_minutes < 1 (detta är felsarter eller testrundor). Standardisera gruppering efter start_station_name när användaren ber om ”per station” eller ”toppstationer”.
Join-relationer: Eftersom vår agent hämtar från flera tabeller, definiera tydligt hur de hänger ihop. Det säkerställer att agenten inte gissar fel främmande nycklar. Exempel: Join:a tabellen bikeshare_trips med tabellen bikeshare_stations genom att matcha bikeshare_trips.start_station_id med bikeshare_stations.station_id (och på motsvarande sätt för end_station_id).
Du kan kombinera allt ovan i ett rent block i fältet Instructions. Här är en putsad, färdig version att klistra in som innehåller den strukturerade vägledningen:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).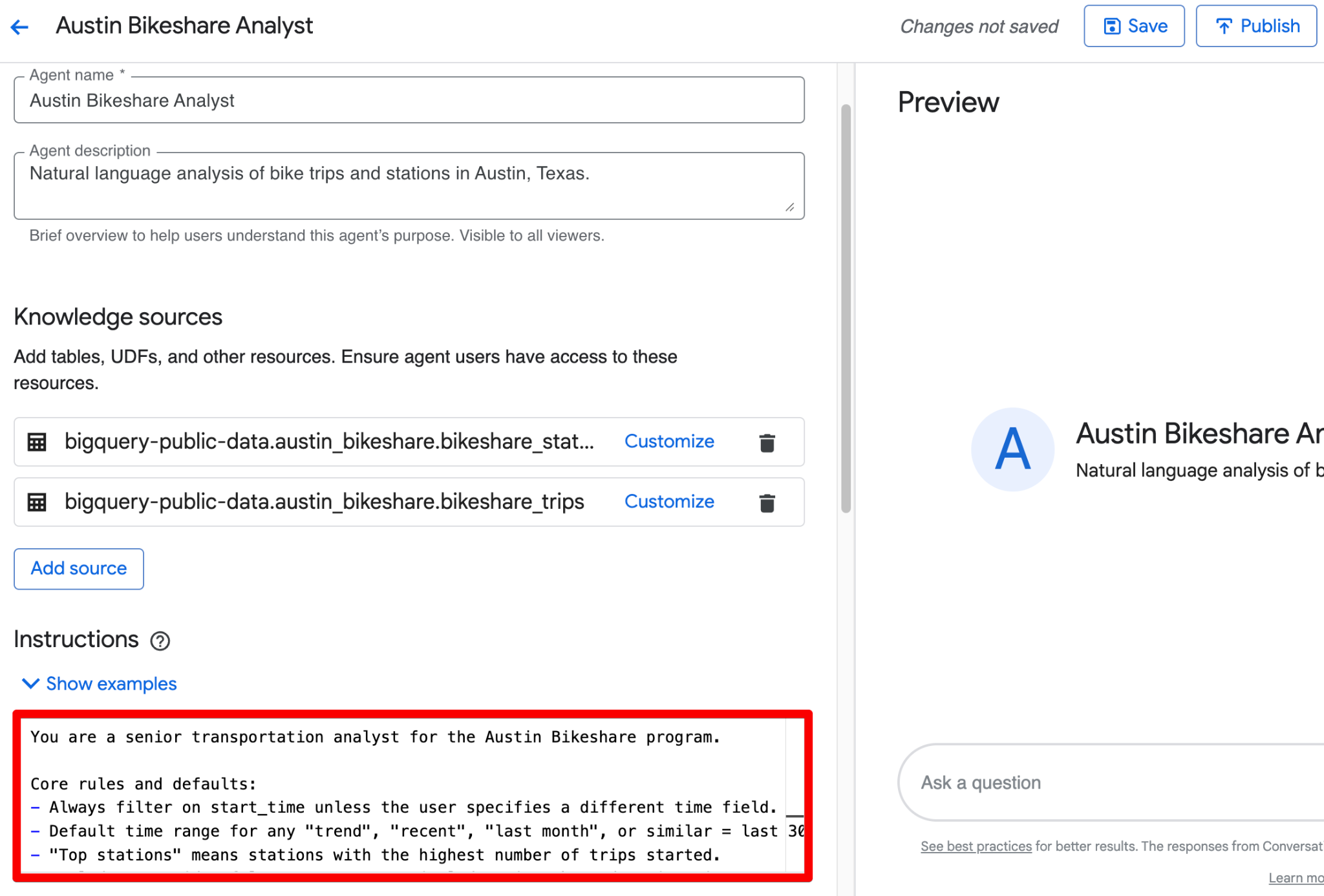
Därför är detta viktigt: Om du lämnar dessa fält tomma kan en tvetydig fråga som ”Vad var våra bästa försäljningar?” få agenten att joina fel tabeller, hämta från inaktiva konton eller inkludera utfasad data. Genom att strukturera dina instruktioner över dessa fem kategorier säkerställer du att den genererade SQL:en strikt följer din etablerade affärslogik.
Utöver instruktioner kan du (och bör) definiera ordlistetermer direkt i agenten. Dessa hjälper agenten att tolka branschjargong, förkortningar och härledda begrepp konsekvent.
Klicka Add term i avsnittet Glossary (vanligtvis nära Instructions) och skapa termer med term, definition och synonymer (kommaavgränsade).
Här är rekommenderade ordlistetermer för datasetet Austin Bikeshare:
| Term | Definition | Synonymer |
duration_minutes |
Resans längd i minuter. Använd alltid detta i användarvända svar och beräkningar | körtid, reslängd, duration, åktid |
ridership |
Det totala antalet (räkning) cykelresor som startats | resor, åk, färder, cykelanvändning, pendlingsantal |
peak_hours |
Morgonspets (7–9) eller kvällsspets (16–19) baserat på timmen extraherad från start_time |
rusningstid, högbelastningstid, period med hög efterfrågan |
subscriber_type |
Typ av åkare — Subscriber (månatlig eller årlig passinnehavare) eller Customer (engångsresa | användartyp, medlemstyp, passinnehavare, medlem, tillfällig åkare |
false_start |
En mycket kort resa (vanligtvis under 1 minut) som troligen är en testrunda eller oavsiktlig upplåsning. Dessa ska normalt exkluderas från analysen | testrunda, ogiltig resa, kort resa |
Du kan lägga till fler termer vid behov (till exempel för start_station_name, end_station_name eller härledda mått som ”genomsnittlig resetid” eller ”lång resa”).
Genom att använda ordlistor, om ledningen bestämmer sig för att ändra den officiella definitionen av en ”Lång resa” till 45 minuter nästa kvartal, behöver ditt datastyrningsteam bara uppdatera det en gång i Dataplex. Varje dataagent som är kopplad till den ordlistan tar omedelbart till sig den nya logiken, så du behåller konsekvens i hela organisationen.
När du har konfigurerat kunskapskällor, instruktioner och ordlistetermer är det dags att testa din agent innan publicering.
Rulla till höger sida av skärmen till förhandsgranskningspanelen. Detta live-chattgränssnitt låter dig interagera med din agent i realtid medan du bygger den. Du kan ställa frågor, granska agentens resonemang, inspektera den genererade SQL:en och iterera snabbt.
Förhandsgranskningspanelen visar:
Prova dessa fyra frågor med ökande komplexitet (justerade för datasetets dataintervall till och med 2024):
Det här ser du i agentens svar:
Sammanfattning — En förklaring i naturligt språk av resultaten.
Frågeresultat — En ren tabell med data (t.ex. totalt antal resor, toppstationer eller genomsnittlig duration).
Insikter — Punktvisa slutsatser som tolkar resultaten i ett affärssammanhang.
Genererad SQL — Klicka på Open in Editor för att visa hela SQL-frågan som agenten skapade (du ser att den korrekt filtrerar på start_time och tillämpar duration_minutes >= 1 för att exkludera felsarter).
Föreslagna följdfrågor — Hjälpsamma förslag längst ner (t.ex. ”Vilka var de 10 största startstationerna i juni 2024?”, ”Prognostisera det dagliga antalet resor …”, osv.).
Visualisering — Ett automatiskt genererat diagram (stapeldiagram för rankningar, som i ditt exempel med topp 5-stationer).
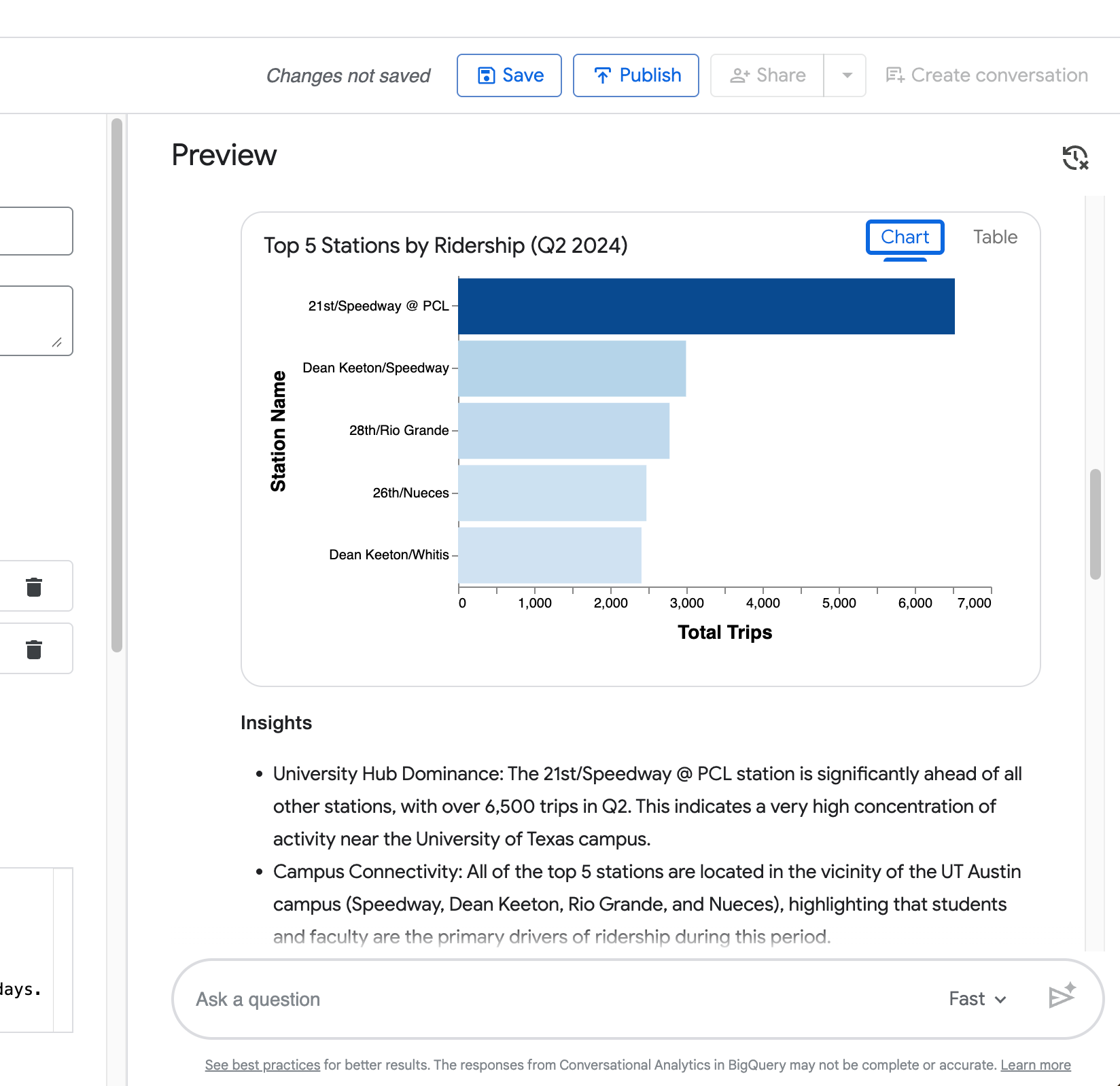
Din fjärde fråga (”Visa nu samma jämförelse men bara för stationen Zilker Park”) visar agentens förmåga att behålla sammanhang från föregående fråga.
Som du kan se på följande skärmdump begränsar den korrekt jämförelsen vardag kontra helg till Zilker Park utan att du behöver upprepa hela begäran.
Testtips:
När agenten konsekvent ger tydliga, korrekta och välstrukturerade svar klickar du på Save högst upp och sedan Publish. Din agent Austin Bikeshare Analyst är nu redo att användas!
Även med bra instruktioner och ordlistetermer kan din dataagent ibland misstolka affärsregler eller skapa inkonsekventa svar.
Verifierade frågor löser detta genom att låta dig uttryckligen lära agenten det korrekta sättet att hantera viktiga eller ofta förekommande frågor. Varje verifierad fråga består av en fråga i naturligt språk parad med den exakta SQL som ska användas.
De fungerar som högkvalitativa exempel som förankrar agentens resonemang och är ett av de mest effektiva sätten att gå från en ”tillräckligt bra” agent till en produktionsredo.
I agenteditorn, bläddra till avsnittet Verified Queries. Du har två enkla sätt att lägga till verifierade frågor:
Klicka på Add query. Du ser skärmen Add verified query där du kan:
Klicka på View Gemini-generated suggestions. Detta öppnar skärmen ”Review suggested verified queries”, där Gemini föreslår relevanta frågor baserat på dina kunskapskällor.
Du kan:
En bra verifierad fråga för datasetet Austin Bikeshare kan vara:
Fråga:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;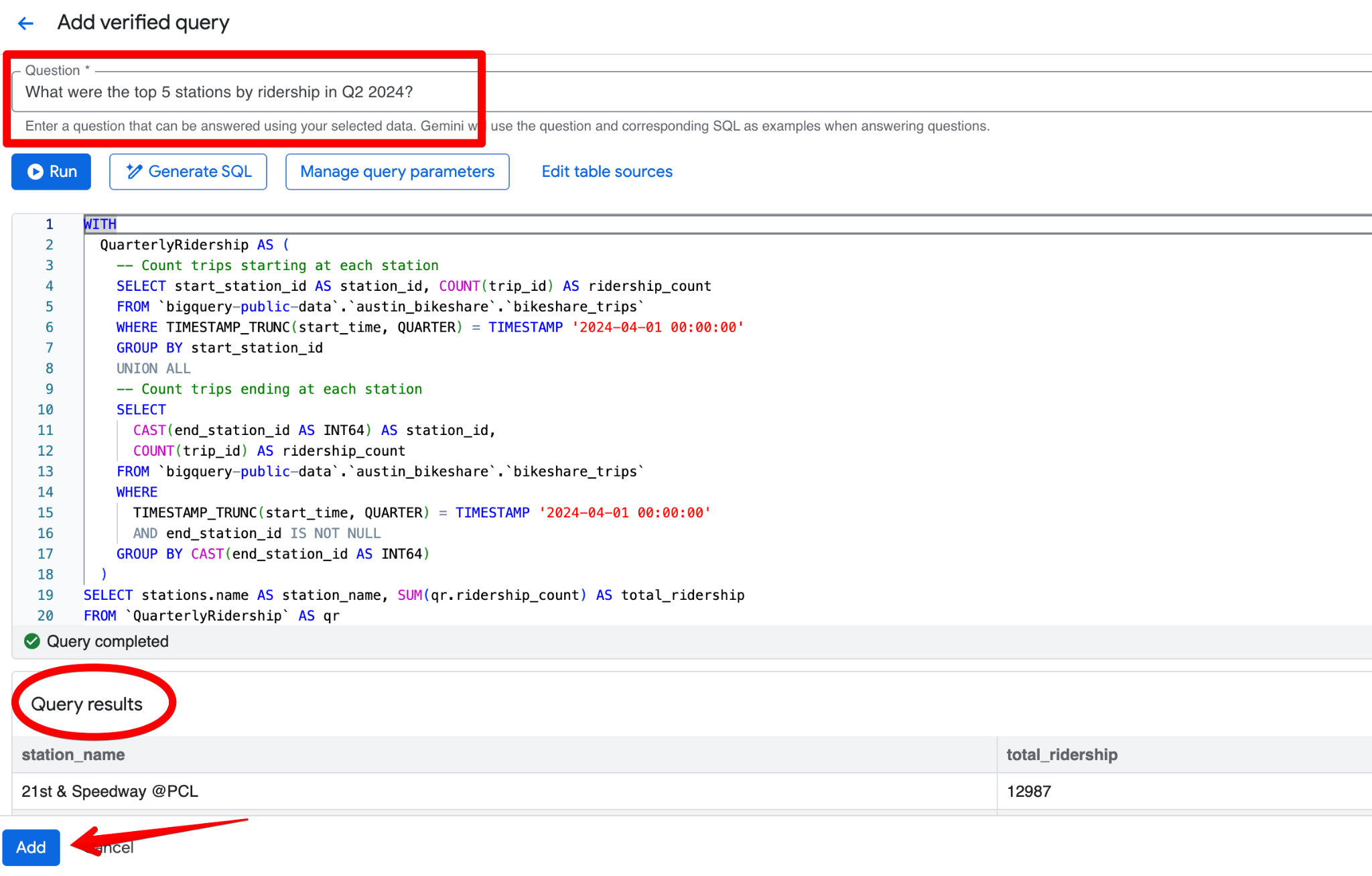
Även när agenten ger ett rimligt svar på första försöket kan du göra den betydligt mer exakt och konsekvent genom att granska den genererade SQL:en och lägga till verifierade frågor.
Följ detta praktiska arbetsflöde:
Säg att du frågade: ”Vad var den genomsnittliga resetiden i juni 2024?” I det första svaret returnerar agenten 26,68 minuter och exkluderar korrekt resor kortare än 1 minut. Anta nu att teamets standardregel är att exkludera alla resor kortare än 5 minuter i stället.
När du öppnar den genererade SQL:en (via Open in Editor) ser du att filtret bara är duration_minutes >= 1.
Klicka på Add query i avsnittet Verified Queries och skapa denna post:
Fråga:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes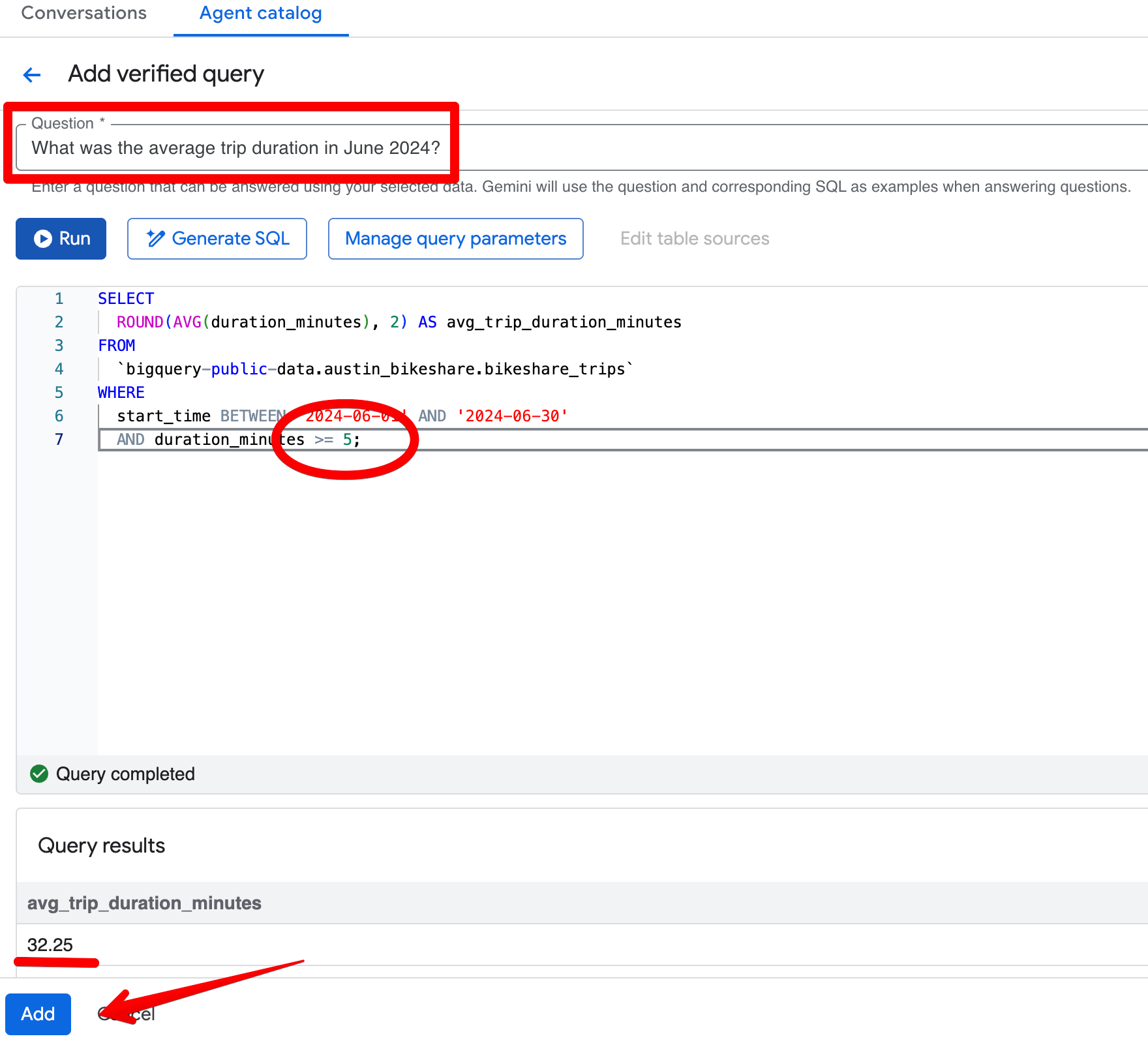
Efter att ha sparat den verifierade frågan, ställ samma fråga igen i förhandsgranskningspanelen. Agenten returnerar nu konsekvent ~32,08 minuter och tillämpar din striktare 5-minutersgräns. Resultaten blir mer i linje med er affärssyn på ”meningsfulla” resor.
BigQuerys konversationsanalys utmärker sig från enkla text-till-SQL-verktyg genom att inbyggt stödja BigQuery ML-funktioner, ostrukturerad data och enkel delning i Google Cloud-ekosystemet.
En av de största skillnaderna är agentens förmåga att anropa BigQuery ML-funktioner direkt från naturligt språk, för att gå bortom retrospektiv rapportering till framåtblickande insikter.
Du kan till exempel be en dataagent att förutsäga det dagliga antalet resor de kommande 30 dagarna baserat på trender under 2024. Den kommer att trigga AI.FORECAST och generera en prognos för juli 2024 tillsammans med ett snyggt diagram som visar historiska dagliga resor (blå linje) och 30-dagarsprognosen (orange linje) med ett skuggat 95 % konfidensintervall.
Ett annat sätt som maskininlärningsalgoritmer kan vara till hjälp på är genom att upptäcka om något är avvikande i dina data. När du till exempel ber en agent att upptäcka avvikelser i daglig ridership under juni 2024, kommer den att använda AI.DETECT_ANOMALIES, jämföra juni 2024 med föregående månader och returnera en tidsserietabell plus ett linjediagram.
I det här fallet flaggade den inga formella avvikelser på 95 % konfidensnivå men lyfte fram 19 juni som en nära-avvikelse (92,1 % sannolikhet) med ett tydligt fall i ridership.
De flesta konverserande BI-verktyg fallerar i samma ögonblick som data inte är snyggt organiserade i rader och kolumner. BigQuery stöder däremot objektabeller, vilket gör att du kan analysera ostrukturerad data (som PDF:er, bilder och råa textloggar) som lagras i Google Cloud Storage.
Eftersom dataagenten drivs av Geminis multimodala kapacitet kan den resonera över både dina strukturerade mått och dina ostrukturerade filer samtidigt. Detta är en stor, unik differentiator för BigQuery.
Om du har kundundersökningar i PDF eller bilder från stationsinspektioner i en objektabell kan du helt enkelt fråga: ”Sammanfatta de främsta klagomålen från kundundersökningarna i Q2 2024.” Agenten läser de ostrukturerade filerna och kombinerar informationen med dina strukturerade reseuppgifter
Ditt datateam bygger och testar dataagenter i BigQuery Studio, men dina slutanvändare arbetar sannolikt i helt andra applikationer. Google gör det enkelt att frikoppla agenten från GCP-konsolen så att du kan möta verksamhetsanvändare där de redan arbetar.
Om du vill prova att bygga en egen skräddarsydd chattapplikation kan du alså läsa mer i den officiella Introduction to Conversational Analytics in BigQuery.
Om det är en sak att ta med sig så är det denna: konversationsanalys flyttar den analytiska flaskhalsen från att vänta på ett datateam till att helt enkelt ställa rätt fråga.
Denna demokratisering betyder inte att datateam blir överflödiga, men deras roll förändras. En AI-agent är bara så intelligent som de skyddsräcken du bygger runt den. Noggrannheten och säkerheten hos dina dataagenter beror helt på de instruktioner, det sammanhang och den schemaarkitektur du tillhandahåller.
För att bygga de mest effektiva konversationsagenterna behöver du fortfarande god förståelse för det underliggande data lagret. Om du eller ditt team vill stärka dessa kärnkunskaper och bemästra plattformen som driver dessa AI-funktioner, kolla in DataCamps kurs Introduction to BigQuery redan idag!
Kurser om Google Cloud
track
course
course