Track
Цифровой лидер Google Cloud
8 ч
Если вы работаете в дата-команде, этот сценарий наверняка знаком: ваш бэклог разрывается от разовых запросов. Бизнес-пользователям постоянно нужны простые вариации существующих отчётов: «Можете сгруппировать это по категории продукта?» или «Как это соотносится с прошлым месяцем?» Пока они ждут ответа в очереди, ваши дата-инженеры и аналитики погребены под повторяющимися SQL‑задачами.
С Conversational Analytics в BigQuery вы наконец-то можете снять это узкое место. Эта функция приносит движок логического вывода на базе ИИ прямо в BigQuery Studio, позволяя пользователям задавать вопросы на естественном языке и мгновенно получать данные, диаграммы и сгенерированный SQL.
В этом руководстве вы узнаете, как настроить и использовать разговорную аналитику в BigQuery. Вы создадите, настроите и отточите собственных дата-агентов, чтобы в вашей организации можно было безопасно «общаться» с данными.
Разговорная аналитика переводит взаимодействие с данными от ручных SQL‑запросов к диалогу на естественном языке. Вместо написания операторов SELECT вы общаетесь с дата-агентом, который понимает контекст вашего бизнеса и возвращает ответы, основанные на ваших реальных таблицах.
Это не просто базовый преобразователь текста в SQL; это серьёзный шаг к настоящей демократизации данных.
Это позволяет нетехническим пользователям самостоятельно получать оперативные инсайты, а специалистам по данным — быстро исследовать датасеты и автоматизировать отчётность.
В основе разговорной аналитики BigQuery — движок логического вывода на базе семейства моделей Gemini. Дата-агенты используют структурированный многоэтапный конвейер, чтобы обеспечить привязку инсайтов к вашему конкретному контексту данных:
Google Cloud предлагает разговорную аналитику на разных уровнях вашего дата-стека. Выбор точки входа зависит от ваших пользователей и того, где живёт бизнес-логика:
|
Функция |
Conversational Analytics в BigQuery |
Conversational Analytics в Looker |
Data Studio (через BigQuery Agents) |
|
Лучше всего подходит для |
Дата-команд, аналитиков и разработчиков, создающих кастомные приложения |
Бизнес-пользователей, которым нужны управляемые инсайты, готовые к дашбордам |
Бизнес-пользователей, предпочитающих «лёгкую» BI‑отчётность |
|
Метод привязки |
Прямые схемы хранилища, метаданные таблиц и проверенные запросы |
LookML (семантический слой) |
Подключение напрямую к предварительно созданным дата-агентам BigQuery |
|
Доступ к данным |
Может анализировать структурированные, предиктивные (ML) и неструктурированные данные |
Строго структурированные, моделированные данные |
Структурированные данные |
|
Статус релиза |
Предпросмотр (по состоянию на май 2026 года) |
Доступно для общего пользования |
Предпросмотр |
Какой путь выбрать?
Это руководство сосредоточено на BigQuery как самом быстром способе для дата-команд прототипировать и вводить агентов в прод прямо там, где находятся данные.
Важно понять архитектуру дата-агента до его настройки. В среде Google Cloud дата-агент — это центральный слой абстракции. Он объединяет активы BigQuery с возможностями рассуждения семейства моделей Gemini.
Вместо прямой выдачи «сырых» таблиц дата-агент настраивает всё необходимое модели, чтобы интерпретировать вопросы, генерировать безопасный SQL и возвращать надёжные ответы. Эта комбинация источников данных, инструкций и проверенной логики делает разговорную аналитику BigQuery более надёжной, чем стандартные инструменты «текст в SQL».
Источники знаний — базовый слой любого дата-агента. Они точно определяют, к каким данным агент может получать доступ и что запрашивать.
Типы активов: Таблицы, представления (Views) и пользовательские функции (UDF) можно подключать как источники знаний.
Масштабируемость: К одному агенту можно подключить несколько источников знаний. Это позволяет агрегировать информацию из разных бизнес-областей.
Контроль доступа: Определение конкретных источников знаний гарантирует, что агент работает только в рамках разрешённых данных.
Интеллект агента зависит от предоставленного контекста. Это ключ к тому, чтобы сделать общую модель понимающей язык компании.
Определяя пользовательские инструкции, синонимы и бизнес-глоссарии, вы «заземляете» агента в конкретной предметной области. Например, можно обучить агента, что «Top Customers» — это пользователи с пожизненной ценностью (LTV) свыше $1 000.
Ключевые элементы привязки:
Пользовательские инструкции: Давайте общие директивы, например: «Всегда исключайте внутренние тестовые аккаунты из отчётов по выручке».
Бизнес-глоссарии: Сопоставляйте технические термины с естественным языком, например, store_id — «Локация филиала».
Метаданные полей: Описания, помогающие агенту понимать нюансы конкретных переменных, например, «Валовая выручка» против «Чистой прибыли».
Чем лучше ваши инструкции и метаданные, тем выше точность агента.
Проверенные запросы (ранее Golden Queries) — это предопределённые пары «вопрос–ответ», служащие источником истины. Сопоставляя конкретные вопросы со SQL, проверенным экспертами, агент использует корректные пути объединения и фильтры для критичных KPI.
Эти запросы могут включать функции BigQuery ML (BQML). Это позволяет агенту обрабатывать продвинутые запросы, такие как генерация прогнозов оттока или продаж, с использованием точных параметров моделей, заданных дата-сайентистами. После проверки эти активы управляются через Dataplex Universal Catalog, что обеспечивает единообразие по всей организации.
Теперь, когда вы понимаете строительные блоки, перейдём к созданию и настройке вашего первого дата-агента.
Чтобы следовать нашему туториалу, убедитесь, что у вас есть следующие предпосылки:
Прежде чем создавать первого агента, необходимо настроить ваш проект Google Cloud и убедиться, что у вашей учётной записи есть необходимые разрешения. Дата-агенты работают как слой поверх ваших существующих данных, поэтому корректная настройка IAM (Identity and Access Management) критична и для безопасности, и для работоспособности.
Действуйте так:
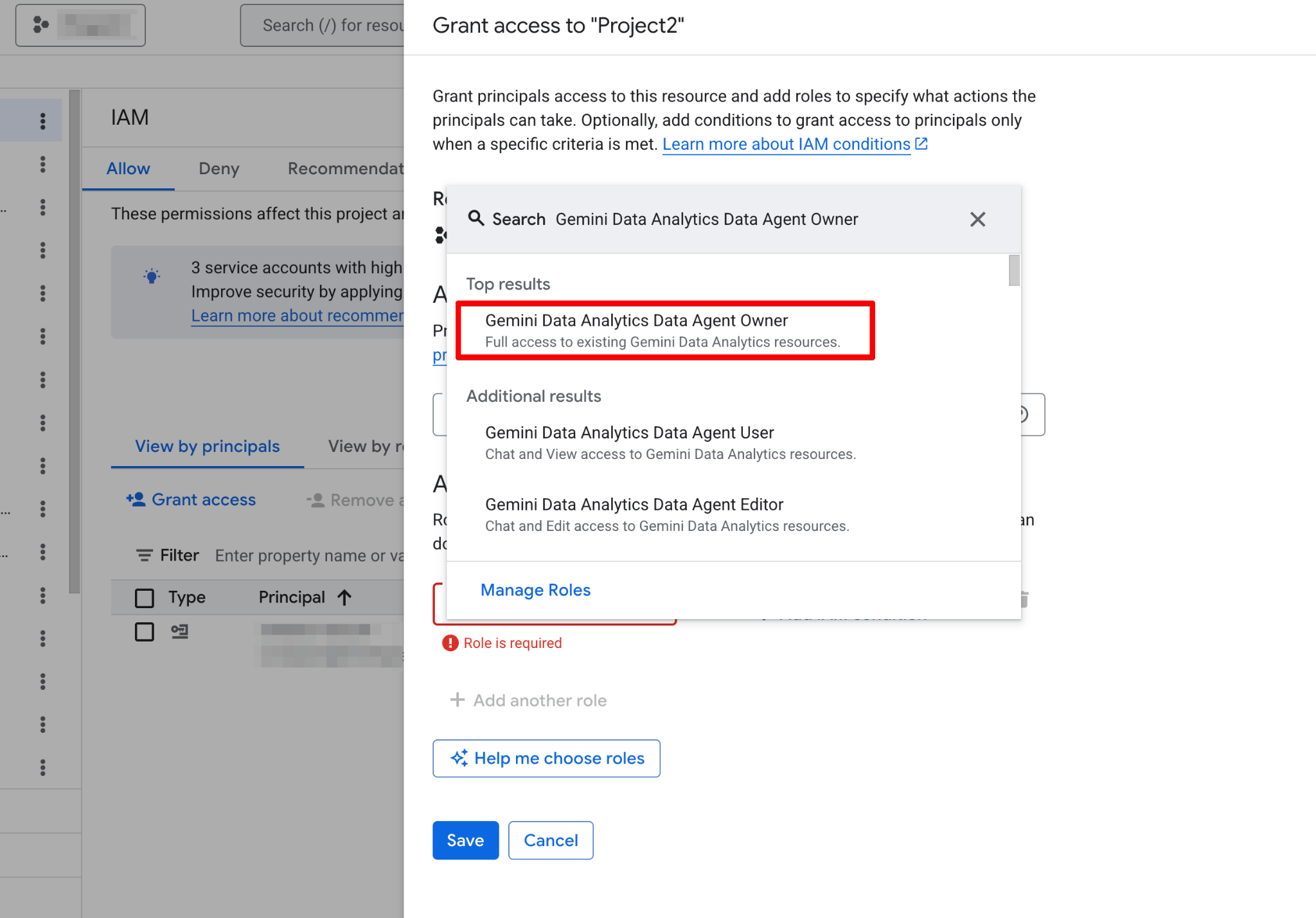
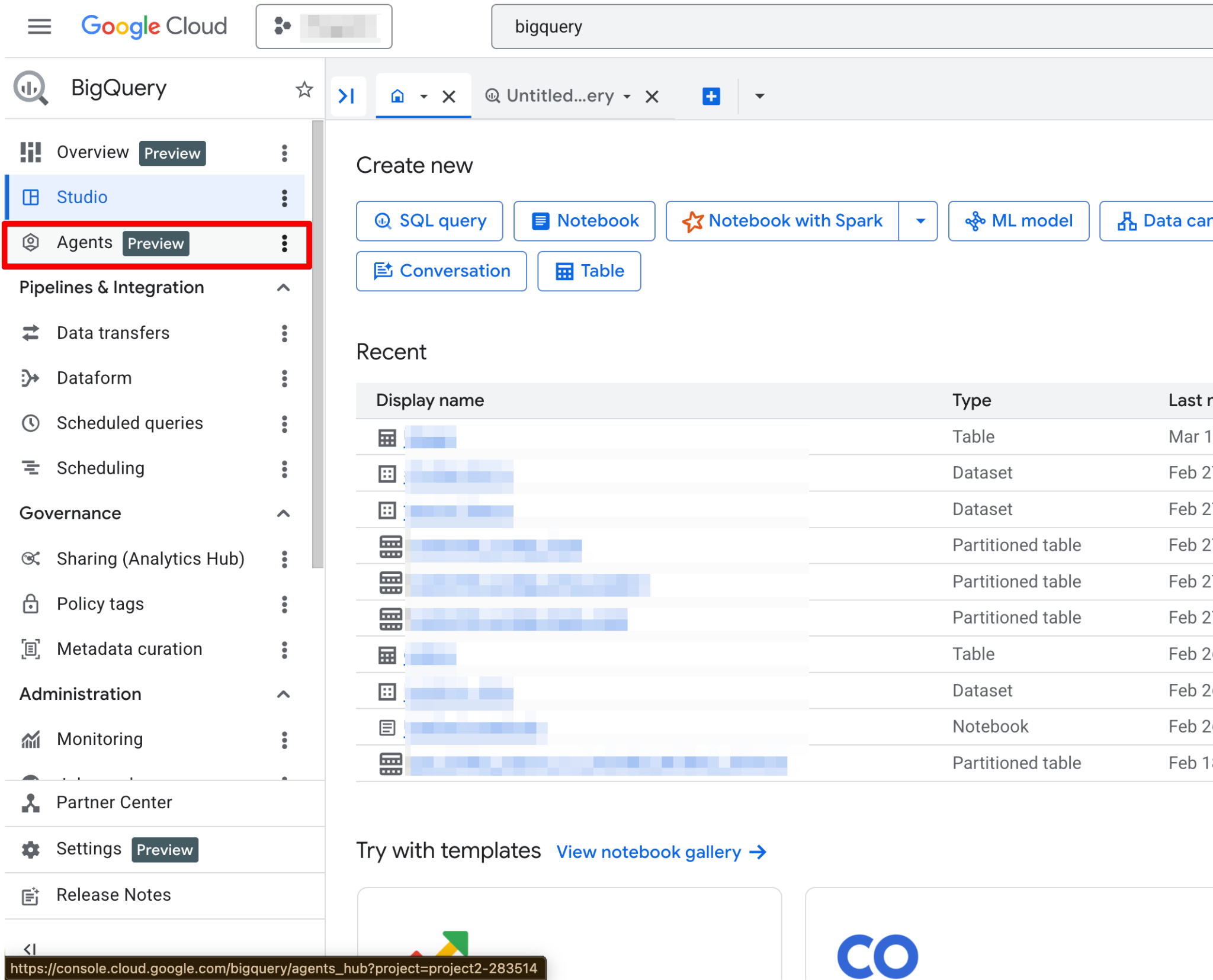
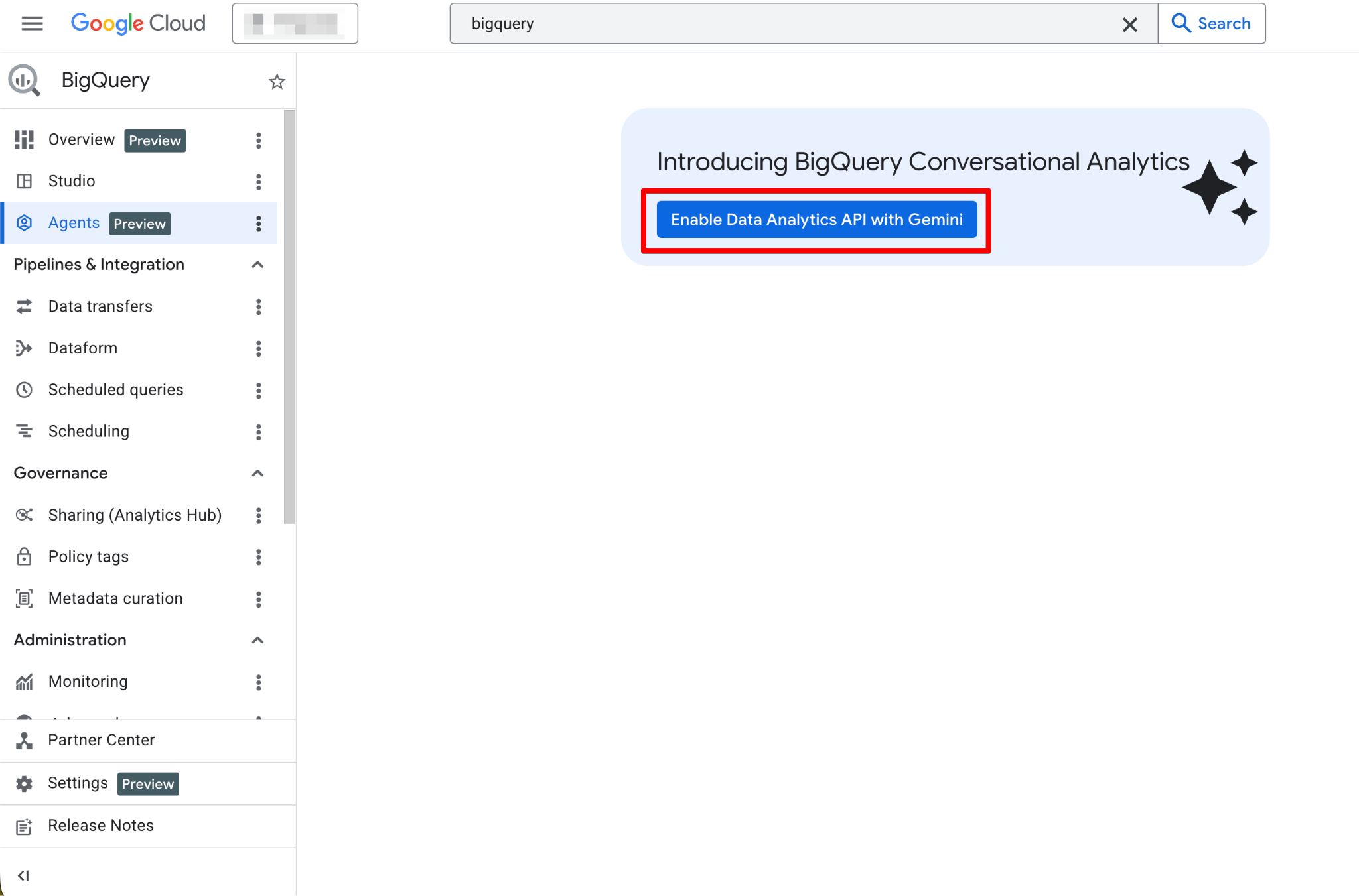
После включения страница Agents станет полностью функциональной. Вы должны увидеть новую страницу агента:
Agent Catalog используется для создания, управления и версионирования дата-агентов в BigQuery Studio.
В каталоге агентов вы найдёте:
Жизненный цикл агента следует структуре (Draft → Created → Published):
Нажмите любую карточку агента, чтобы открыть её, просмотреть детали, начать диалог или отредактировать (если у вас есть права Owner). В интерфейсе также есть вкладка Conversations, где вы можете управлять прошлыми чатами с агентами или источниками данных.
Теперь, когда фундамент заложен, создадим дата-агента с нуля. Мы используем датасет bigquery-public-data.austin_bikeshare, чтобы превратить «сырые» данные о поездках в разговорный интерфейс. Нам понадобятся две таблицы:
bikeshare_trips — детализированные данные на уровне поездок
bikeshare_stations — метаданные станций
Начало создания агента
Эти два поля помогут вам быстро находить агента позже. После их заполнения переходите к настройке трёх основных блоков, о которых мы говорили ранее: источников знаний, инструкций и (позже) проверенных запросов.
Источники знаний определяют, к каким данным агент имеет доступ. Чем их меньше и чем они фокусированнее, тем выше точность и ниже стоимость. В разделе Knowledge sources редактора нажмите Add source. Найдите austin_bikeshare и выберите bikeshare_trips и bikeshare_stations как источники.
Для каждой добавленной таблицы нажмите Customize.
Gemini автоматически сгенерирует описание и предложит метаданные столбцов. Проверьте всё, примите корректные предложения, внесите правки и нажмите Update.
Распространённая ошибка — добавить сразу 50 таблиц. Начните с 2–3 ключевых. Так проще отладить логику агента. Позже вы всегда сможете расширить знания, когда ядро запросов станет точным.
Далее нужно «заземлить» агента инструкциями. Вместо общего текстового промпта (например, «Отвечай на вопросы о продажах») интерфейс дата-агента BigQuery позволяет задать строго структурированный контекст, направляющий генерацию запросов ИИ. Думайте об этом как об онбординге нового аналитика с вашим точным дата-словарём.
Используйте поле Instructions, чтобы дать структурированный бизнес-контекст. Вот полный, готовый пример, который можно вставить:
Синонимы: Определите альтернативные термины для ваших столбцов, чтобы агент понимал вариации естественного языка. Пример: «Journey», «Ride» и «Commute» — это запись в таблице bikeshare_trips. «Dock», «Hub» или «Station» — запись в таблице bikeshare_stations.
Ключевые поля: Выделите наиболее важные поля для анализа. Это подскажет агенту, каким столбцам отдавать приоритет, когда вопрос пользователя общий. Пример: для общего репортинга приоритезируйте trip_id, start_station_name, end_station_name, subscriber_type, start_time и duration_minutes.
Исключаемые поля: Укажите столбцы, которые агент должен строго избегать. Это крайне полезно для сокрытия устаревших столбцов или нерелевантных данных. Пример: не используйте столбец bike_id в таблице bikeshare_trips для большинства анализов, так как он редко нужен для бизнес-вопросов.
Фильтрация и группировка: Дайте агенту инструкции о стандартных способах срезать данные. Пример: если не указано иное, всегда исключайте поездки, где duration_minutes < 1 (это ложные старты или тестовые поездки). По умолчанию группируйте данные по start_station_name, когда пользователь просит «по станциям» или «топ станций».
Связи для объединения: Поскольку наш агент берёт данные из нескольких таблиц, явно определите, как они соединяются. Это не даст агенту угадать неправильные внешние ключи. Пример: соединяйте таблицу bikeshare_trips с таблицей bikeshare_stations, сопоставляя bikeshare_trips.start_station_id с bikeshare_stations.station_id (и аналогично для end_station_id).
Всё вышеперечисленное можно объединить в один аккуратный блок в поле Instructions. Вот отточенная, готовая к вставке версия со структурированными указаниями:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).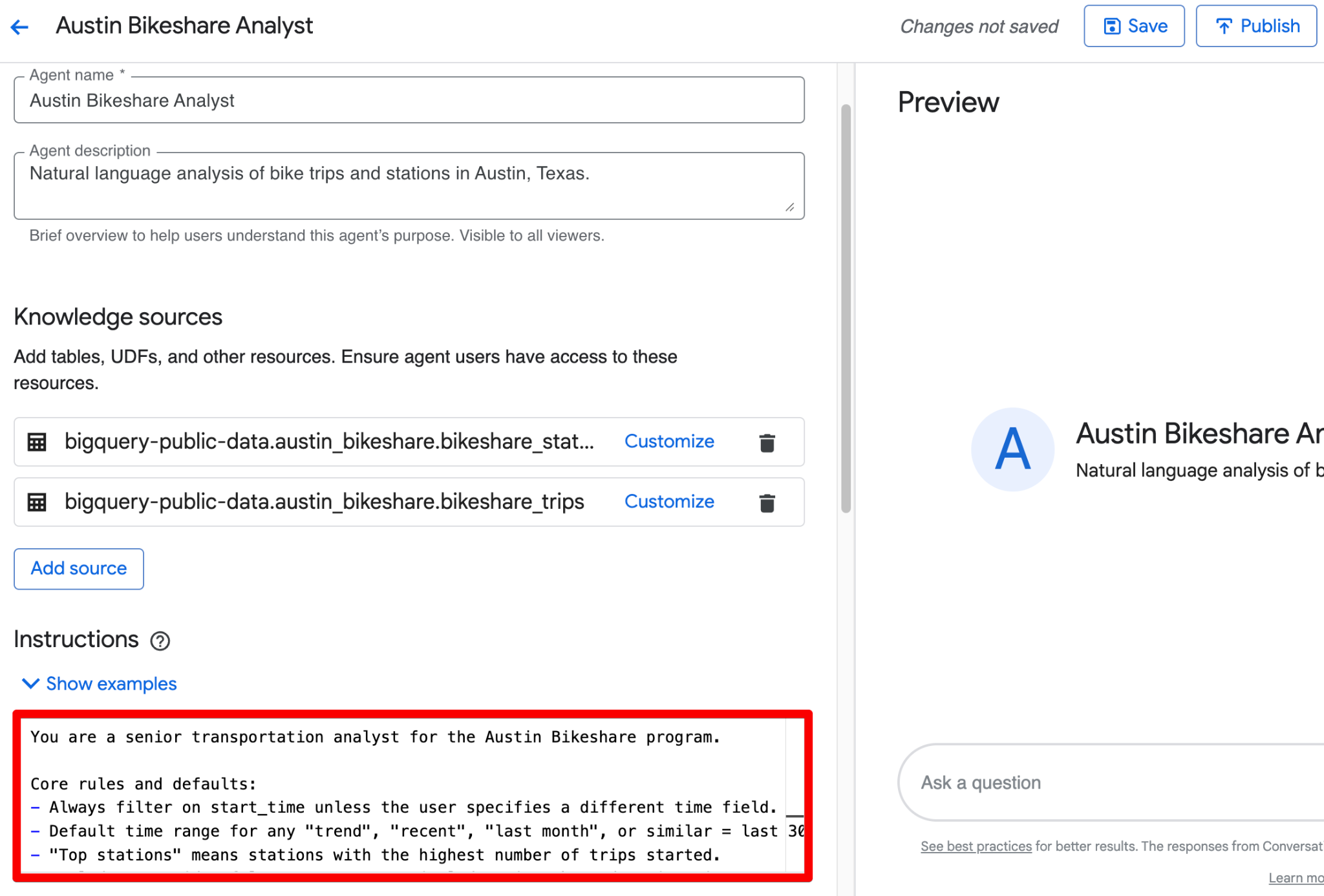
Почему это важно: Если оставить эти поля пустыми, неоднозначный вопрос вроде «Какие были наши топовые продажи?» может привести к тому, что агент соединит неверные таблицы, возьмёт данные из неактивных аккаунтов или включит устаревшие данные. Структурируя инструкции по этим пяти категориям, вы гарантируете, что сгенерированный SQL строго следует вашей устоявшейся бизнес-логике.
Помимо инструкций, вы можете (и должны) определять термины глоссария прямо в агенте. Они помогают агенту последовательно интерпретировать бизнес-жаргон, аббревиатуры и производные понятия.
Нажмите Add term в разделе Glossary (обычно рядом с Instructions) и создайте термины: термин, определение и синонимы (через запятую).
Рекомендуемые термины глоссария для датасета Austin Bikeshare:
| Термин | Определение | Синонимы |
duration_minutes |
Длительность поездки в минутах. Всегда используйте это поле для пользовательских ответов и расчётов | время поездки, длительность поездки, длительность, время в пути |
ridership |
Общее количество (счёт) начатых велопоездок | поездки, поездки на велосипеде, поездки (journeys), использование велосипеда, число поездок |
peak_hours |
Утренний пик (7–9) или вечерний пик (16–19) на основе часа, извлечённого из start_time |
час пик, загруженные часы, период высокого спроса |
subscriber_type |
Тип райдера — Subscriber (владелец месячного или годового абонемента) или Customer (разовая поездка | тип пользователя, тип членства, держатель абонемента, участник, случайный райдер |
false_start |
Очень короткая поездка (обычно менее 1 минуты), скорее всего тестовая или случайная разблокировка. Обычно её следует исключать из анализа | тестовая поездка, недействительная поездка, короткая поездка |
Вы можете добавлять и другие термины по мере необходимости (например, для start_station_name, end_station_name или производных метрик вроде «средней длительности поездки» или «длинной поездки»).
Благодаря глоссариям, если руководство решит со следующего квартала изменить официальное определение «Длинной поездки» на 45 минут, вашей команде по управлению данными нужно будет обновить это только один раз в Dataplex. Каждый дата-агент, подключённый к этому глоссарию, сразу примет новую логику, сохраняя консистентность по всей организации.
После настройки источников знаний, инструкций и терминов глоссария пора протестировать агента до публикации.
Прокрутите вправо к панели Preview. Этот интерфейс живого чата позволяет взаимодействовать с агентом в реальном времени по мере его создания. Вы можете задавать вопросы, просматривать рассуждения агента, проверять сгенерированный SQL и быстро итератировать.
Панель Preview показывает:
Попробуйте эти четыре запроса с нарастающей сложностью (адаптируйте к диапазону данных датасета до 2024 года):
Что вы увидите в ответе агента:
Summary — объяснение результатов на естественном языке.
Query result — аккуратная таблица с данными (например, общее число поездок, топ станций или средняя длительность).
Insights — маркированные выводы, интерпретирующие результаты в бизнес-контексте.
Generated SQL — нажмите Open in Editor, чтобы посмотреть полный SQL‑запрос, созданный агентом (вы увидите корректную фильтрацию по start_time и применение duration_minutes >= 1 для исключения ложных стартов).
Suggested follow-up questions — полезные подсказки внизу (например, «Какие 10 стартовых станций были топовыми в июне 2024?» или «Спрогнозируй дневное число поездок…» и т. п.).
Visualization — автоматически сгенерированная диаграмма (столбчатая для рейтингов, как в примере с топ‑5 станций).
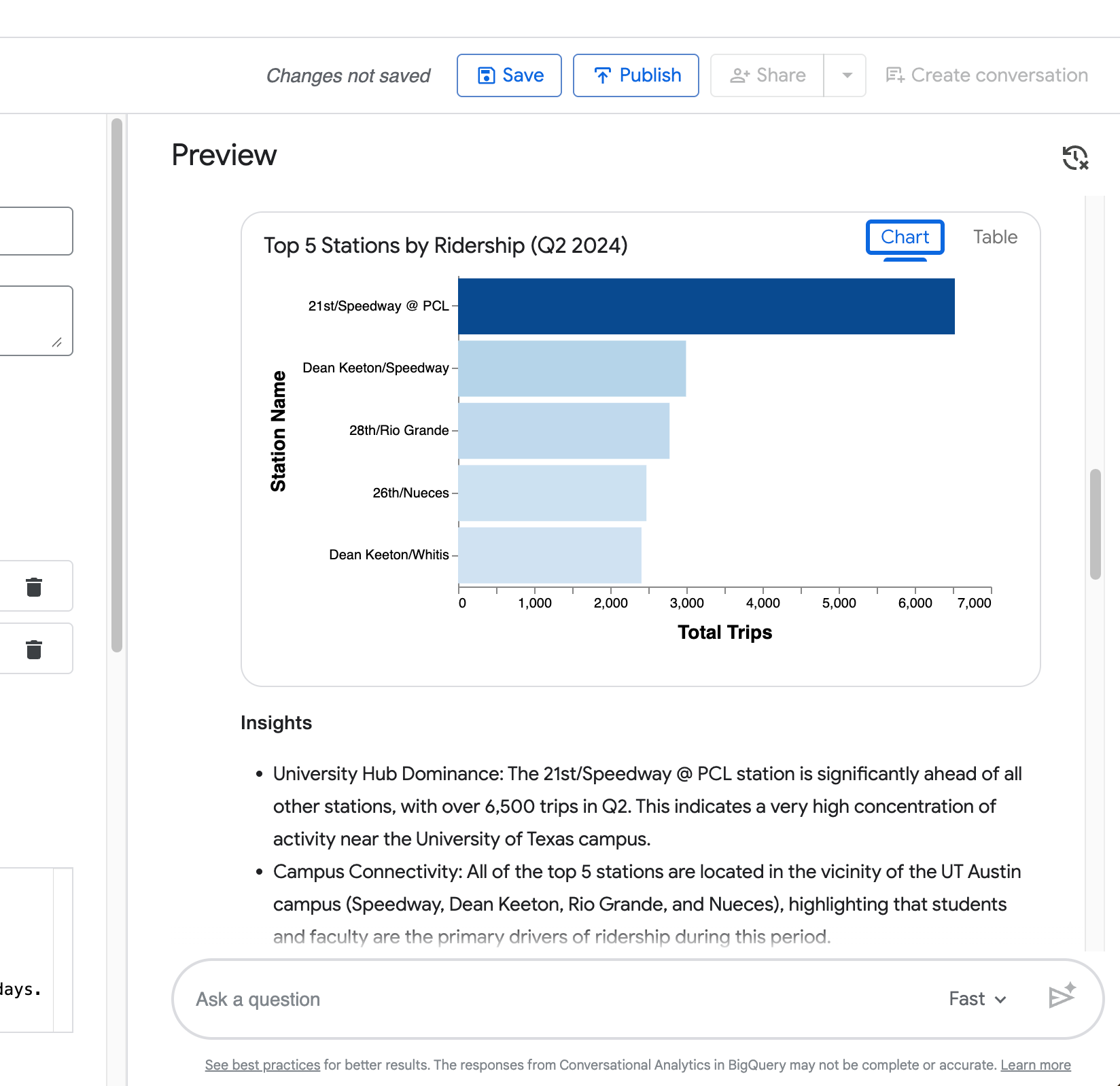
Ваш четвёртый запрос («Теперь покажите то же сравнение, но только для станции Zilker Park») демонстрирует умение агента сохранять контекст предыдущего вопроса.
Как видно на следующем скриншоте, он корректно сужает сравнение длительности в будни/выходные до Zilker Park без повторения полного запроса.
Советы по тестированию:
Когда агент стабильно даёт чёткие, точные и хорошо структурированные ответы, нажмите Save вверху, затем Publish. Ваш агент Austin Bikeshare Analyst готов к использованию!
Даже при хороших инструкциях и глоссариях ваш агент может время от времени неверно трактовать бизнес-правила или давать непоследовательные ответы.
Проверенные запросы решают это, позволяя явно обучить агента корректной обработке важных или часто задаваемых вопросов. Каждый проверенный запрос — это вопрос на естественном языке в паре с точным SQL, который следует использовать.
Они служат высококачественными примерами, закрепляющими логику агента, и являются одним из самых эффективных способов перейти от «в целом неплохо» к продакшен-уровню.
В редакторе агента прокрутите до раздела Verified Queries. Есть два простых способа добавить проверенные запросы:
Нажмите Add query. Вы увидите экран Add verified query, где можно:
Нажмите View Gemini-generated suggestions. Откроется экран «Review suggested verified queries», где Gemini предложит релевантные вопросы на основе ваших источников знаний.
Вы можете:
Хороший проверенный запрос для датасета Austin Bikeshare может быть таким:
Вопрос:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;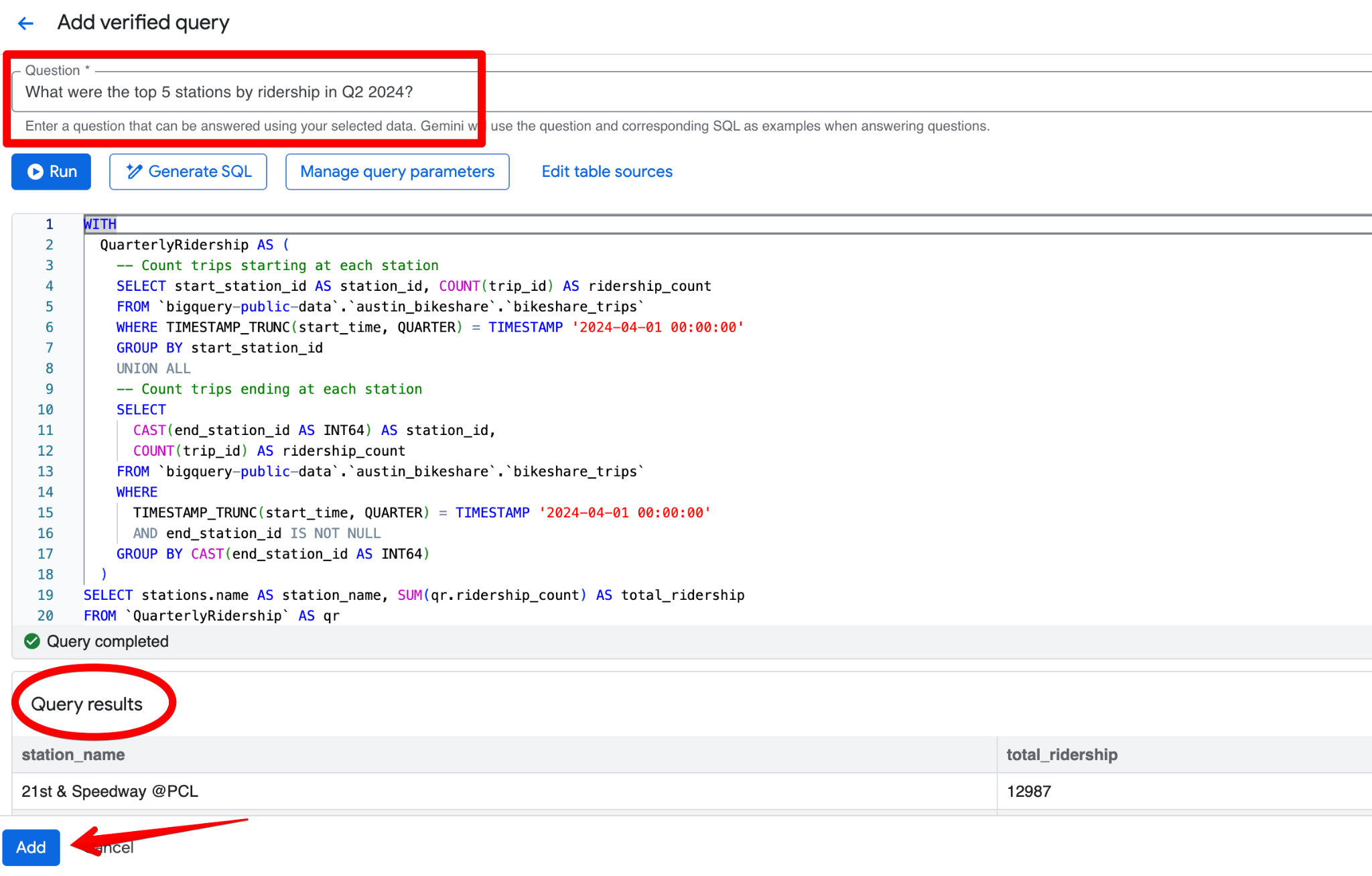
Даже если агент дал разумный ответ с первой попытки, вы можете заметно повысить его точность и стабильность, проверяя сгенерированный SQL и добавляя проверенные запросы.
Следуйте практичному рабочему процессу:
Допустим, вы спросили: «Какова была средняя длительность поездки в июне 2024?» В изначальном ответе агент вернул 26,68 минуты и корректно исключил поездки короче 1 минуты. Теперь предположим, что стандартное бизнес-правило команды — исключать любые поездки короче 5 минут.
Когда вы открываете сгенерированный SQL (через Open in Editor), видите, что фильтр — только duration_minutes >= 1.
Нажмите Add query в разделе Verified Queries и создайте следующую запись:
Вопрос:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes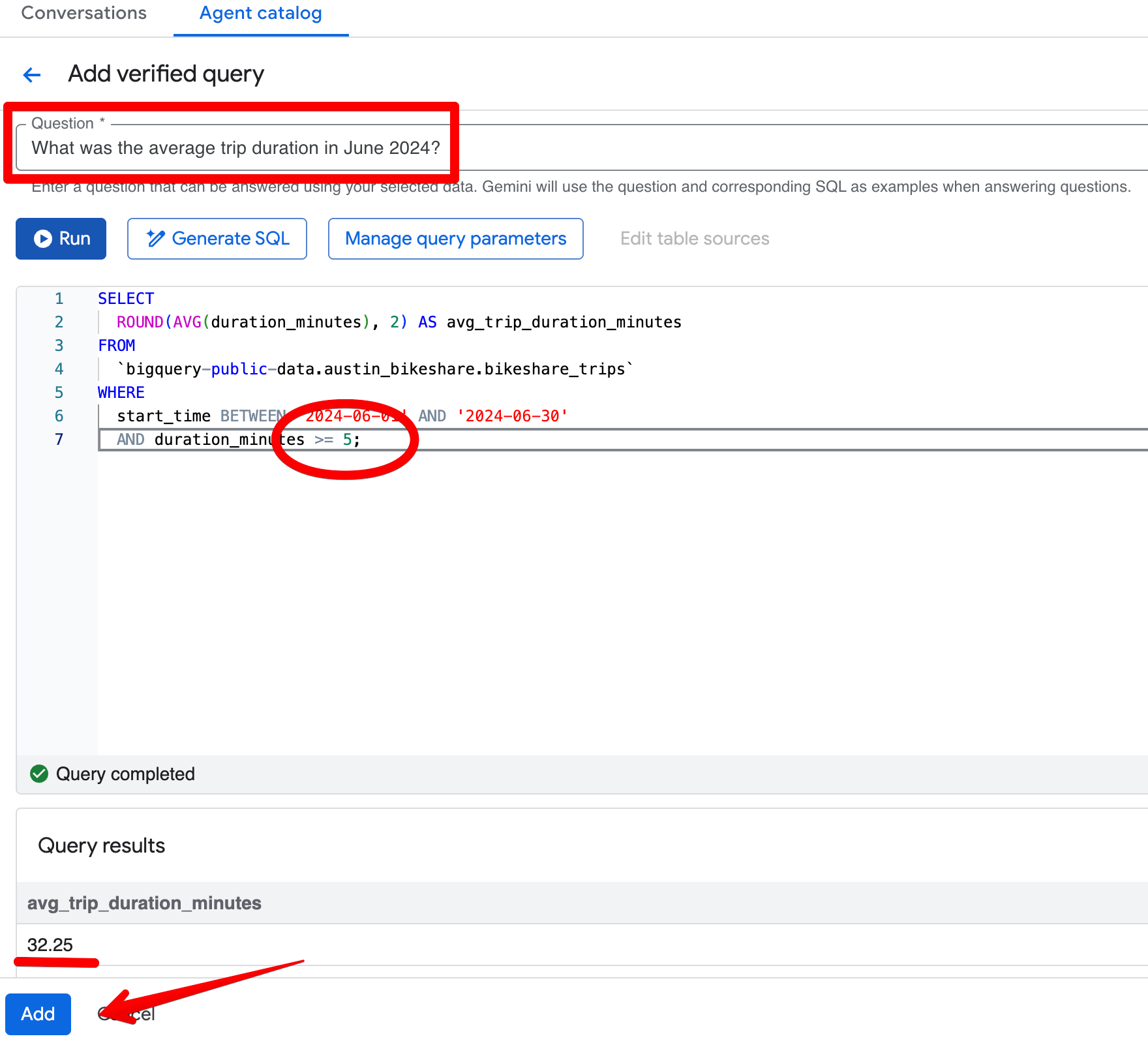
После сохранения проверенного запроса снова задайте тот же вопрос в панели Preview. Теперь агент стабильно возвращает ~32,08 минуты и применяет более жёсткий порог в 5 минут. Результаты лучше согласуются с вашим бизнес-пониманием «содержательных» поездок.
Разговорная аналитика BigQuery выделяется среди простых инструментов «текст в SQL» за счёт нативной поддержки функций BigQuery ML, неструктурированных данных и простого шаринга по экосистеме Google Cloud.
Одно из ключевых отличий — способность агента вызывать функции BigQuery ML напрямую из естественного языка, переходя от ретроспективной отчётности к прогнозной аналитике.
Например, вы можете попросить агента спрогнозировать дневное число поездок на следующие 30 дней на основе трендов 2024 года. Он вызовет AI.FORECAST и построит прогноз на июль 2024 года вместе с наглядной диаграммой, показывающей исторические дневные поездки (синяя линия) и 30‑дневный прогноз (оранжевая линия) с заштрихованным 95% доверительным интервалом.
Ещё один полезный сценарий применения алгоритмов — выявление сбоев в данных. Если, например, вы попросите агента найти аномалии в дневном количестве поездок в июне 2024 года, он вызовет AI.DETECT_ANOMALIES, сравнит июнь 2024 с предыдущими месяцами и вернёт таблицу временного ряда плюс линейную диаграмму.
В данном случае формальных аномалий на уровне доверия 95% не обнаружено, но 19 июня отмечен как «почти аномалия» (вероятность 92,1%) с заметным падением числа поездок.
Большинство разговорных BI‑инструментов «ломаются», как только данные выходят за рамки строк и столбцов. BigQuery поддерживает Object Tables, что позволяет анализировать неструктурированные данные (PDF, изображения, «сырые» текстовые логи) в Google Cloud Storage.
Поскольку дата-агент работает на мультимодальных возможностях Gemini, он может рассуждать одновременно по вашим структурированным метрикам и неструктурированным файлам. Это серьёзное и уникальное преимущество BigQuery.
Если у вас есть PDF‑опросы райдеров или изображения инспекций станций в объектной таблице, просто спросите: «Суммируйте основные жалобы из PDF‑опросов райдеров за II квартал 2024 года». Агент прочитает неструктурированные файлы и объединит информацию с вашими структурированными данными о поездках
Ваша дата-команда создаёт и тестирует дата-агентов в BigQuery Studio, но конечные пользователи работают в других приложениях. Google позволяет легко «отвязать» агента от консоли GCP, чтобы вы могли прийти к бизнес-пользователям там, где они уже работают.
Если вы хотите попробовать создать кастомное чат‑приложение самостоятельно, вы также можете прочитать больше в официальном руководстве Introduction to Conversational Analytics in BigQuery.
Если вынести один главный принцип, то вот он: разговорная аналитика снимает аналитическое узкое место — вместо ожидания дата-команды достаточно просто задать правильный вопрос.
Это «расширение прав и возможностей» не означает, что дата-команды больше не нужны, но их роль меняется. Агент ИИ настолько умён, насколько надёжны ограждения, которые вы вокруг него построили. Точность и безопасность ваших дата-агентов полностью зависят от инструкций, контекста и архитектуры схем, которые вы предоставляете.
Чтобы создать максимально эффективных разговорных агентов, всё ещё нужна сильная экспертиза в базовом дата-warehouse. Если вы или ваша команда хотите прокачать эти ядровые навыки и освоить платформу, на которой работают эти AI‑функции, загляните на курс DataCamp Introduction to BigQuery уже сегодня!
Курсы по Google Cloud
Track
Course
Course