Tracks
Google Cloud 数字领导者
8小时
如果您在数据团队工作,这种情景大概并不陌生:待办清单被临时请求挤满。业务用户不断需要现有报表的简单变体,比如会问:“您能按产品类别分组吗?”或“这和上个月相比如何?”在他们排队等待答案的同时,数据工程师和分析师却埋头于重复的 SQL 任务。
借助 BigQuery 的对话式分析,您终于可以打破这个瓶颈。该功能将由 AI 驱动的推理引擎直接引入 BigQuery Studio,让用户可以用自然语言提问,并即时获得数据、图表以及生成的 SQL。
在本指南中,您将学习如何在 BigQuery 中设置和使用对话式分析。您将构建、配置并优化自己的数据代理,让组织能够安全地“与数据对话”。
对话式分析将人与数据的交互从手写 SQL 查询转变为自然语言对话。您无需再写 SELECT 语句,而是与理解您业务语境的数据代理“聊天”,它会基于您真实的表返回答案。
这不仅仅是一个基础的文本转 SQL 解析器;而是迈向真正数据民主化的重要一步。
它让非技术用户也能独立获取实时洞察,同时为数据专业人士提供快速探索数据集和自动化报表的途径。
BigQuery 对话式分析的核心是一套由 Gemini 模型家族驱动的推理引擎。数据代理采用结构化的多阶段流水线,确保洞察依据您的特定数据语境:
Google Cloud 在数据栈的不同层提供对话式分析。选择合适的入口取决于您的用户类型以及业务逻辑所在位置:
|
功能 |
BigQuery 对话式分析 |
Looker 对话式分析 |
Data Studio(通过 BigQuery 代理) |
|
最佳适用对象 |
构建自定义应用的数据团队、分析师与开发者 |
需要受治理且可用于仪表盘洞察的业务用户 |
偏好轻量级 BI 报告的业务用户 |
|
扎根方式 |
直接基于数仓架构、表元数据与经验证的查询 |
LookML(语义层) |
直接连接到预构建的 BigQuery 数据代理 |
|
数据访问 |
可分析结构化、预测(ML)与非结构化数据 |
严格结构化、建模后的数据 |
结构化数据 |
|
发布状态 |
预览(截至 2026 年 5 月) |
正式可用 |
预览 |
该选哪条路径?
本教程将聚焦 BigQuery,因为它是数据团队在数据所在之处直接快速原型与投产代理的最快途径。
在设置前了解数据代理的架构很重要。在 Google Cloud 环境中,数据代理是核心抽象层。它将 BigQuery 资产与 Gemini 模型家族的推理能力结合起来。
数据代理不会直接暴露原始表,而是配置模型理解问题、生成安全 SQL 并返回可信答案所需的一切。这种数据源、指令与经验证逻辑的组合,使 BigQuery 的对话式分析比标准的文本转 SQL 工具更可靠。
知识源是任何数据代理的基础层,定义了代理被允许访问与查询的数据范围。
资产类型:表(Tables)、视图(Views)和用户自定义函数(UDFs)都可作为知识源连接。
可扩展性:多个知识源可连接到同一个代理,使其能跨不同业务域整合信息。
访问控制:明确指定知识源可确保代理仅在授权数据范围内运行。
代理的智能性取决于所提供的语境。这是让通用模型理解公司语言的关键。
通过定义自定义指令、同义词与业务词汇表,代理将被扎根于特定领域。例如,您可以教会代理,“Top Customers” 指终身价值(LTV)超过 1,000 美元的用户。
关键扎根要素:
自定义指令:提供高层指导,如“收入报表中始终排除内部测试账号”。
业务词汇表:将技术术语映射为自然语言,例如将 store_id 映射为“分店位置”。
字段元数据:帮助代理理解特定变量细微差异的描述,如“总营收”与“净利润”。
您的指令和元数据越完善,代理的准确性就越高。
经验证查询(先前称为 Golden Queries)是预定义的问答对,作为权威来源。通过将特定问题映射到专家审核过的 SQL,代理会在关键 KPI 上使用正确的关联路径和筛选条件。
这些查询可包含 BigQuery ML(BQML)函数,使代理能够按数据科学家定义的精确模型参数处理高级请求,例如生成流失预测或销售预测。一旦验证,这些资产将通过 Dataplex 通用目录进行管理,确保全组织一致性。
现在您已了解构建模块,让我们进入实际构建与配置首个数据代理的阶段。
要跟随本教程,请先确保具备以下前提条件:
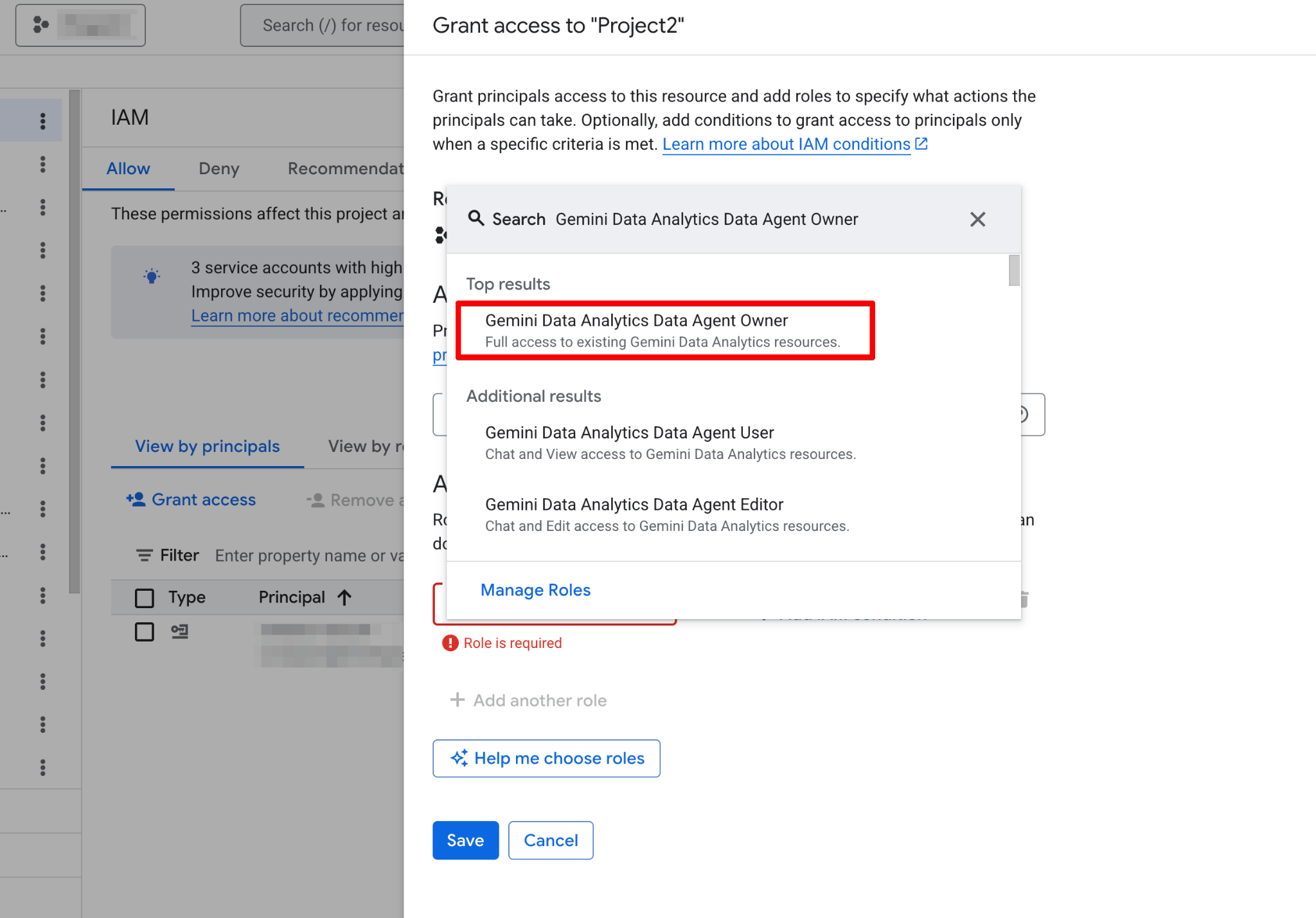
在构建第一个代理之前,您需要配置 Google Cloud 项目并确保您的用户账号具备必要权限。数据代理作为您现有数据之上的一层运行,因此正确的 IAM(身份与访问管理)配置对安全与功能都至关重要。
请按以下步骤操作:
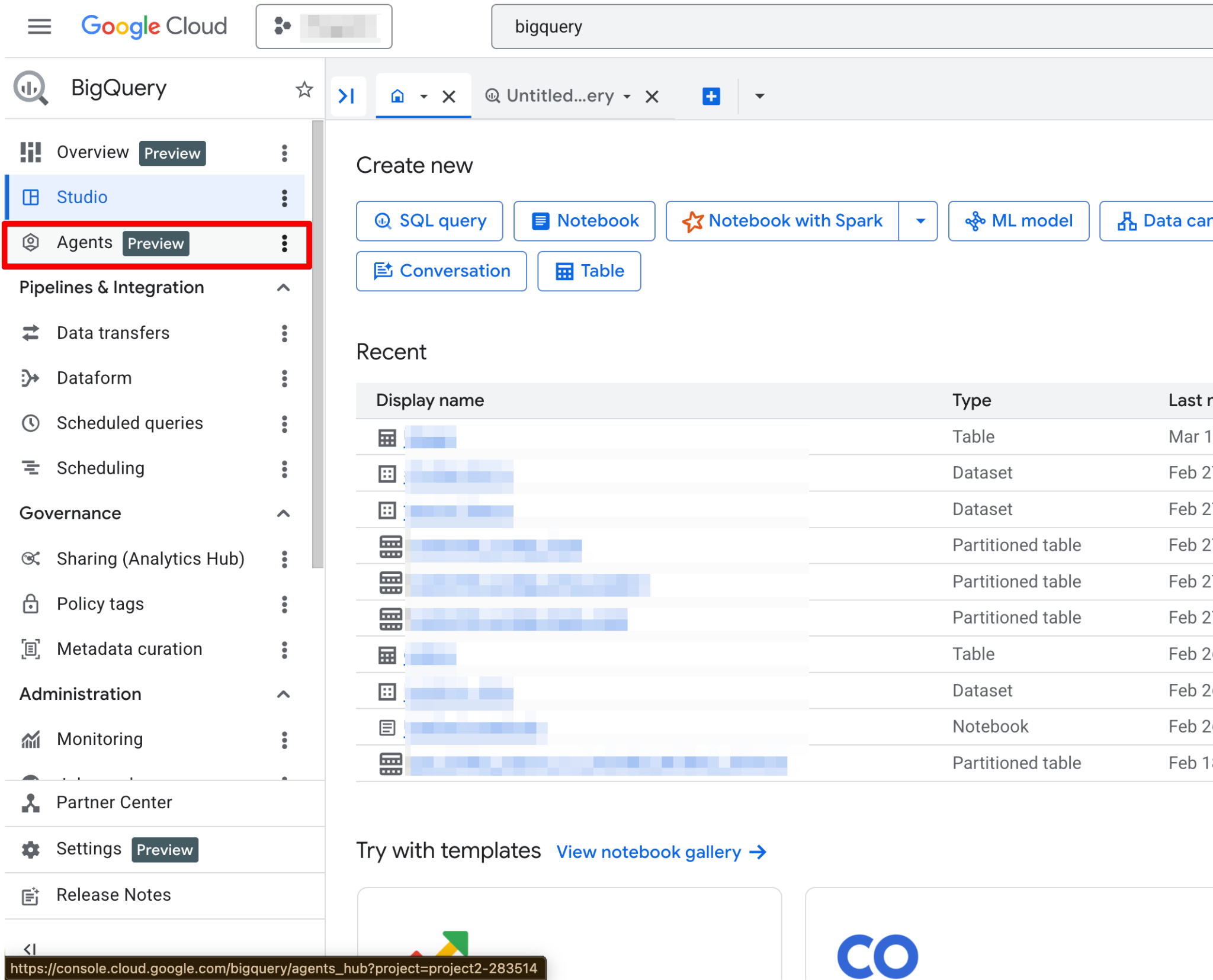
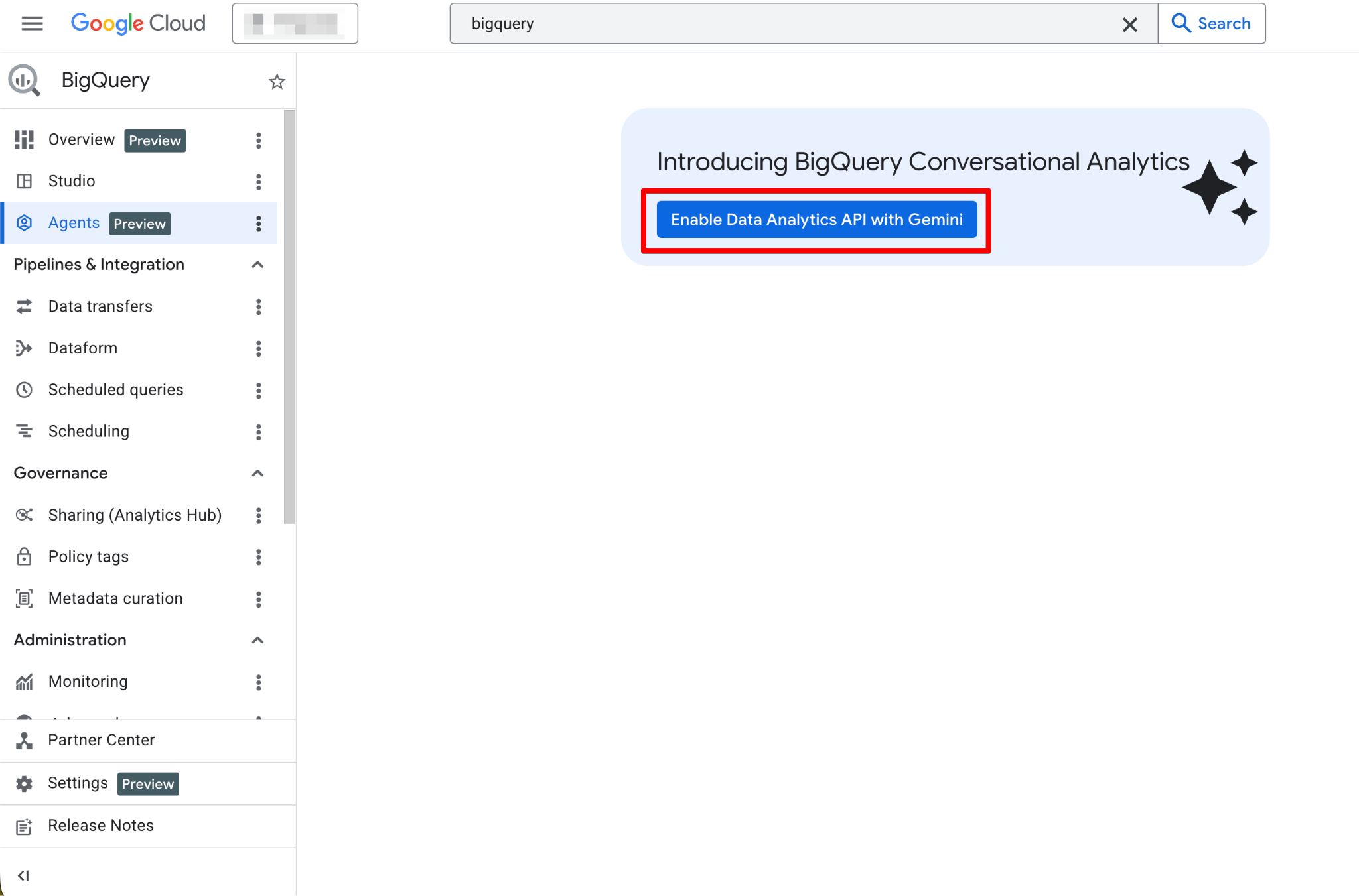
启用后,Agents 页面将全面可用。您现在应能看到新的代理页面:
代理目录用于在 BigQuery Studio 中创建、管理和版本化数据代理。
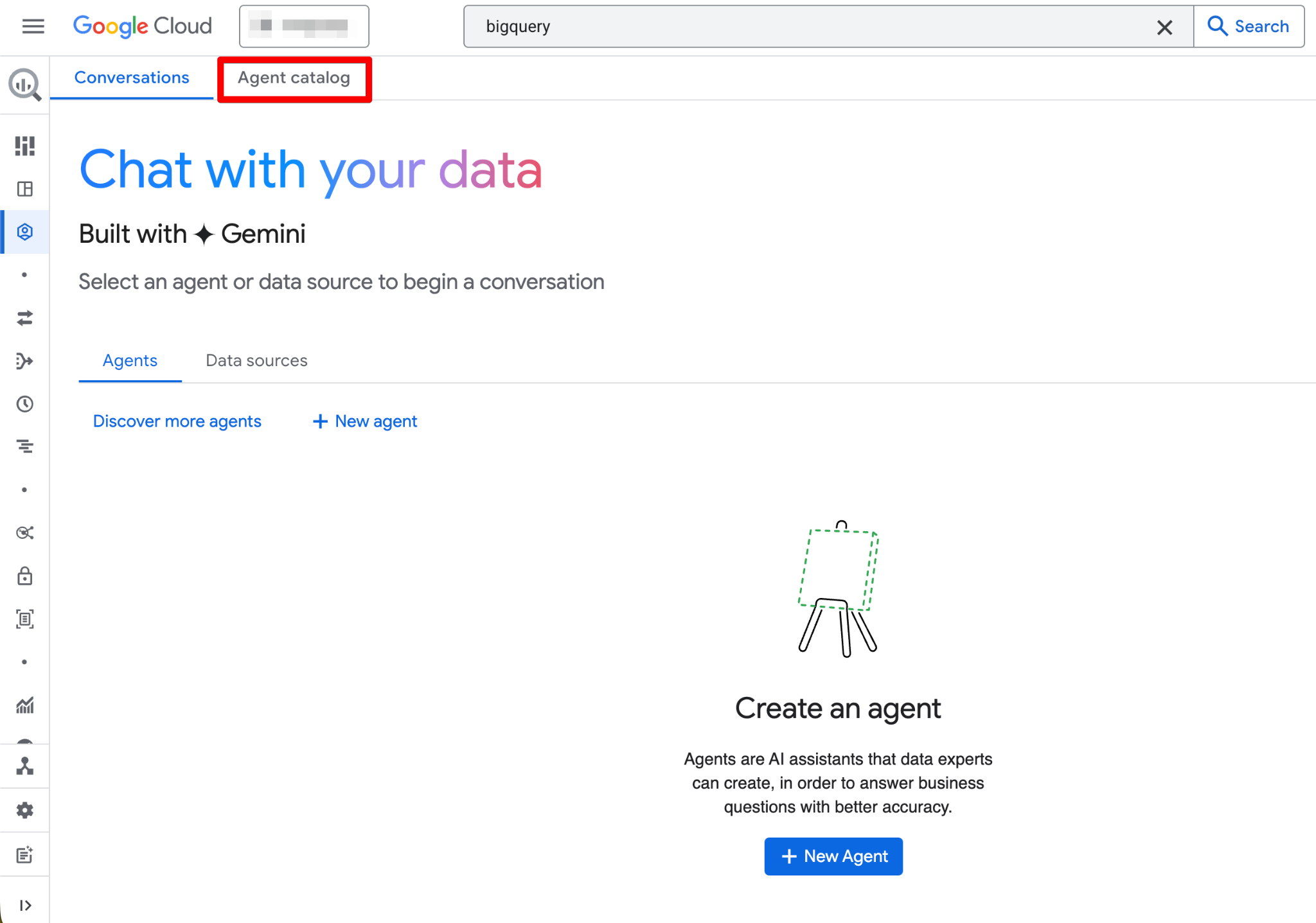
在代理目录中,您会看到:
代理生命周期遵循如下结构(Draft → Created → Published):
点击任意代理卡片即可打开、查看详情、开始对话,或在您拥有 Owner 权限时进行编辑。界面还包含一个 Conversations 选项卡,您可以在其中管理与代理或数据源的历史对话。
打好基础后,我们从零构建一个数据代理。我们将使用 bigquery-public-data.austin_bikeshare 数据集,把原始行程数据转化为对话界面。我们将用到两张表:
bikeshare_trips —— 详细的行程级数据
bikeshare_stations —— 站点元数据
开始创建代理
这两个字段便于您后续快速识别代理。设置完成后,您即可配置我们之前提到的三个核心构建块:知识源、指令,以及(稍后)经验证查询。
知识源定义了代理可访问的数据范围。来源越少、越聚焦,准确性越高、成本越低。在编辑器的 Knowledge sources 区域,点击 Add source。搜索 austin_bikeshare,并选择 bikeshare_trips 与 bikeshare_stations 作为来源。
为您添加的每张表点击 Customize。
Gemini 会自动生成描述并建议列元数据。请逐项审核,接受准确的建议,按需微调后点击 Update。
一个常见错误是一次性添加 50 张表。请先从 2–3 张核心表开始,这样更易调试代理逻辑。核心查询准确后,您随时可以再扩展知识范围。
接下来,您需要用指令为代理提供扎实的语境。与其只写一段泛泛提示(例如“回答有关销售的问题”),BigQuery 的数据代理界面允许您提供高度结构化的上下文来引导 AI 生成查询。把这当作按您公司精确数据字典为一名新分析师做入职培训。
使用 Instructions 字段提供结构化业务语境。以下是一段完整、可直接粘贴的示例:
同义词:为列定义替代表达,便于代理理解自然语言的变化形式。例如:“Journey”“Ride”“Commute” 都指 bikeshare_trips 表中的一条记录;“Dock”“Hub” 或 “Station” 指 bikeshare_stations 表中的一条记录。
关键字段:突出最重要的分析字段。这能在用户提问较宽泛时,指示代理优先考虑哪些列。例如:在常规报表中优先 trip_id、start_station_name、end_station_name、subscriber_type、start_time 和 duration_minutes。
排除字段:指定代理必须严格避免使用的列。这对于隐藏弃用列或无关数据非常有用。例如:大多数分析不使用 bike_id(位于 bikeshare_trips 表),因为它很少用于业务问题。
筛选与分组:指导代理采用标准的数据切分方式。例如:除非另有说明,始终排除 duration_minutes < 1 的行程(这些是误触发或测试骑行)。当用户要求“按站点”或“热门站点”时,默认按 start_station_name 分组。
关联关系:由于我们的代理使用多张表,请明确其连接方式,避免代理猜错外键。例如:将 bikeshare_trips 与 bikeshare_stations 通过 bikeshare_trips.start_station_id 关联到 bikeshare_stations.station_id(end_station_id 同理)。
您可以把上述内容整合为一段简洁文字放入 Instructions 字段。以下是一版打磨好的可粘贴版本,涵盖结构化指引:
You are a senior transportation analyst for the Austin Bikeshare program.
Core rules and defaults:
- Always filter on start_time unless the user specifies a different time field.
- Default time range for any "trend", "recent", "last month", or similar = last 30 days.
- "Top stations" means stations with the highest ridership (highest number of trips started).
- Exclude false start rides/test rides: never include trips where duration_minutes < 1.
- Display station names in final results; use station_id only for joins.
- Prefer clear, readable visualizations: bar charts for rankings, line charts for time-based trends.
Key fields: Prioritize trip_id, start_station_name, end_station_name, subscriber_type, start_time, and duration_minutes for most analyses.
Join relationships: Join bikeshare_trips to bikeshare_stations on bikeshare_trips.start_station_id = bikeshare_stations.station_id (and similarly for end_station_id).
Persona framework (very effective): Begin your instructions with a clear persona statement. This sets the tone, depth of analysis, and output style (e.g., “You are a senior transportation analyst…”).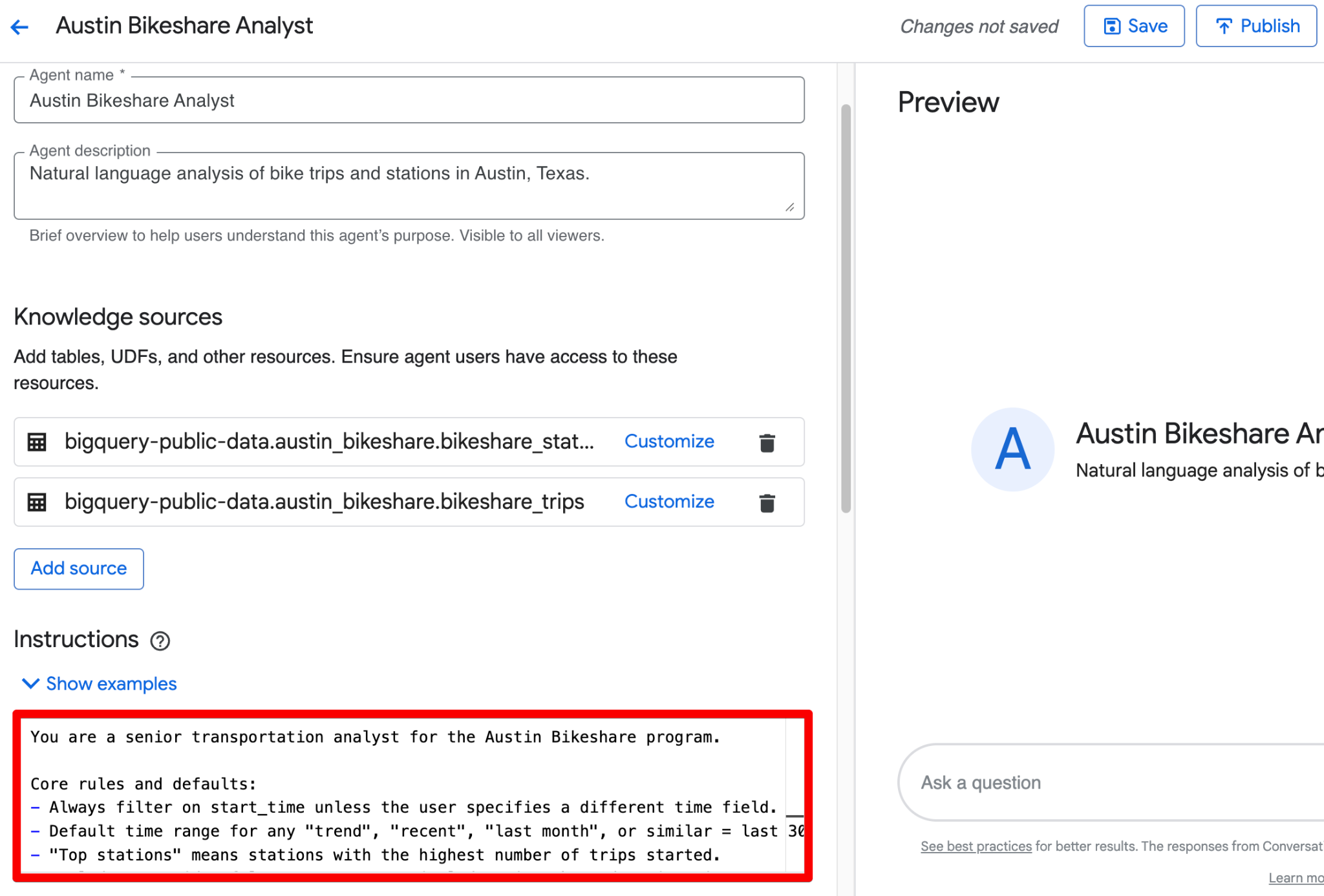
重要性:如果您将这些字段留空,像“我们的畅销产品是什么?”这类含糊问题可能会导致代理关联错误的表、抓取非活跃账户或包含已弃用数据。将指令按上述五类结构化,能确保生成的 SQL 严格遵循您既定的业务逻辑。
除了指令,您还可以(且应该)在代理中直接定义词汇表术语,帮助代理一致地理解业务行话、缩写和衍生概念。
在 Glossary 区域(通常靠近 Instructions)点击 Add term,并创建包含术语、定义和同义词(逗号分隔)的词条。
以下是 Austin Bikeshare 数据集的推荐词汇表术语:
| 术语 | 定义 | 同义词 |
duration_minutes |
行程时长(分钟)。面向用户的答案与计算始终使用该字段 | ride time, trip length, duration, ride duration |
ridership |
发起的自行车行程总数(计数) | trips, rides, journeys, bike usage, commute count |
peak_hours |
基于从 start_time 提取的小时,早高峰(7-9)或晚高峰(16-19) |
rush hour, busy hours, high demand period |
subscriber_type |
骑行者类型——Subscriber(按月或年费持有者)或 Customer(一次性骑行 | user type, membership type, pass holder, member, casual rider |
false_start |
非常短的行程(通常少于 1 分钟),很可能为测试或意外解锁。通常应在分析中排除 | test ride, invalid trip, short trip |
您可按需补充更多术语(例如针对 start_station_name、end_station_name,或衍生指标如“平均行程时长”“长途骑行”)。
通过使用词汇表,如果管理层决定下季度将“长途骑行”的官方定义改为 45 分钟,您的数据治理团队只需在 Dataplex 中更新一次。连接到该词汇表的每个数据代理都会立即采用新逻辑,从而在全组织保持一致。
在配置好知识源、指令与词汇表后,就该在发布前测试代理了。
滚动到屏幕右侧的预览窗格。这个实时聊天界面允许您在构建过程中与代理实时交互。您可以提问、查看代理的推理、检查生成的 SQL,并快速迭代。
预览窗格展示:
试试以下四个复杂度递增的查询(已根据数据集截至 2024 年的范围调整):
您将在代理响应中看到:
摘要 —— 对结果的自然语言说明。
查询结果 —— 数据的整洁表格(如总行程数、热门站点或平均时长)。
洞察 —— 在业务语境下解读结果的要点。
生成的 SQL —— 点击 Open in Editor 查看代理创建的完整 SQL(您会看到其正确在 start_time 上筛选,并应用 duration_minutes >= 1 以排除误触发骑行)。
建议的追问 —— 底部提供有用提示(例如“2024 年 6 月按行程数排名前十的起始站点?”“预测每日行程数……”等)。
可视化 —— 自动生成图表(如在前五站点示例中,排名使用条形图)。
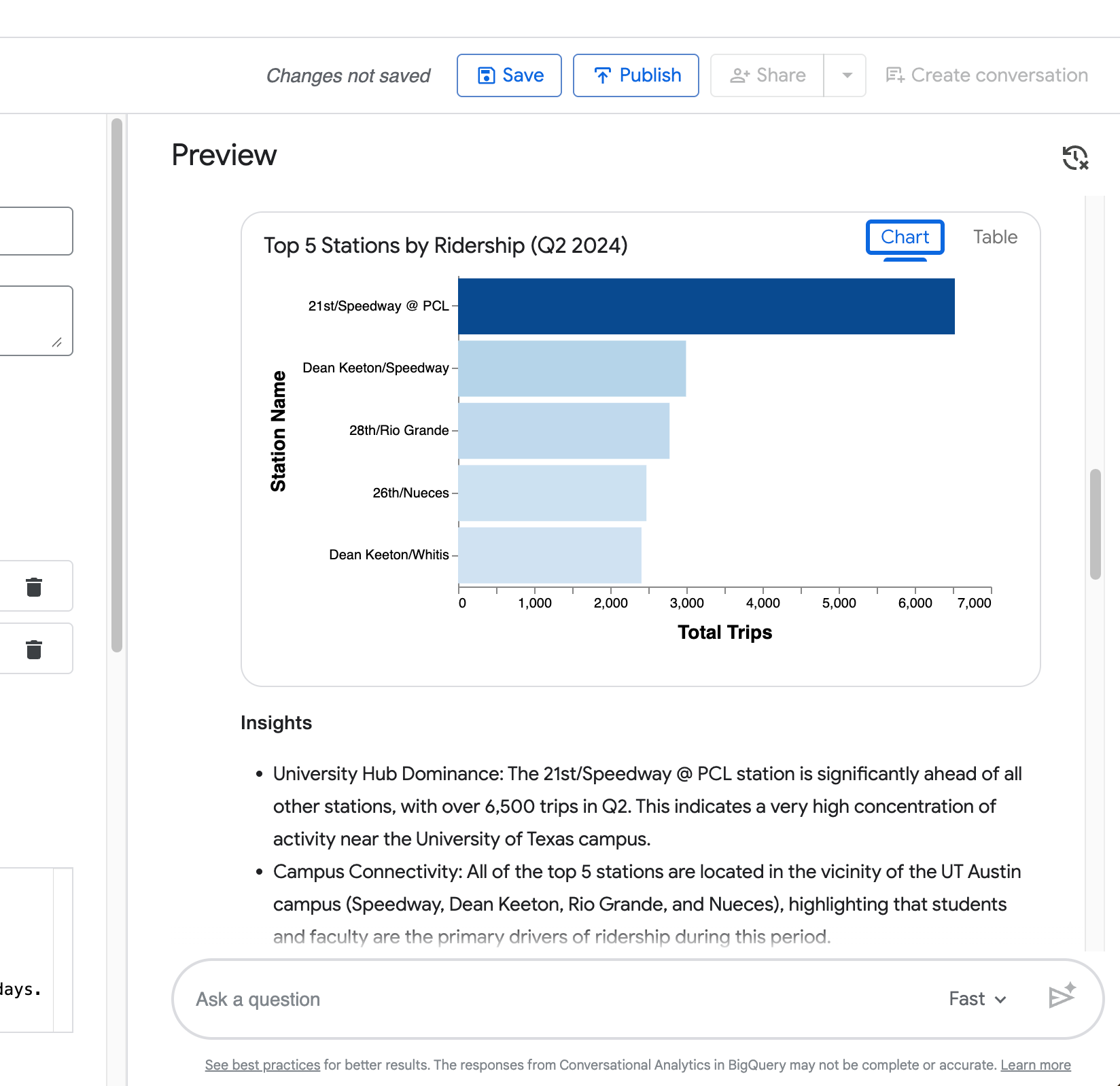
第四个查询(“现在仅针对 Zilker Park 站点给出同样的比较”)展示了代理保留先前上下文的能力。
从下图可见,它在无需您重复完整请求的情况下,正确将工作日 vs 周末时长比较限定到 Zilker Park。
测试建议:
当代理能持续给出清晰、准确、结构良好的答案时,点击 Save 顶部按钮,然后点击 Publish。您的 Austin Bikeshare Analyst 代理已准备就绪!
即使拥有良好的指令与词汇表,数据代理仍可能偶尔误解业务规则或产生不一致的答案。
经验证查询可解决此问题,让您明确教授代理处理重要或高频问题的正确方式。每条经验证查询由一个自然语言问题与应使用的精确 SQL 配对而成。
它们作为高质量示例为代理推理提供锚点,是将代理从“勉强够用”提升到“可投产”的最有效手段之一。
在代理编辑器中,滚动到 Verified Queries 区域。您有两种简单方式添加经验证查询:
点击 Add query。在“Add verified query”界面,您可以:
点击 View Gemini-generated suggestions。这会打开“Review suggested verified queries”界面,Gemini 会基于您的知识源提出相关问题。
您可以:
针对 Austin Bikeshare 数据集的一个优质经验证查询示例:
问题:
What were the top 5 stations by ridership in Q2 2024?SQL:
WITH
QuarterlyRidership AS (
-- Count trips starting at each station
SELECT start_station_id AS station_id, COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
GROUP BY start_station_id
UNION ALL
-- Count trips ending at each station
SELECT
CAST(end_station_id AS INT64) AS station_id,
COUNT(trip_id) AS ridership_count
FROM bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
TIMESTAMP_TRUNC(start_time, QUARTER) = TIMESTAMP '2024-04-01 00:00:00'
AND end_station_id IS NOT NULL
GROUP BY CAST(end_station_id AS INT64)
)
SELECT stations.name AS station_name, SUM(qr.ridership_count) AS total_ridership
FROM QuarterlyRidership AS qr
INNER JOIN
bigquery-public-data.austin_bikeshare.bikeshare_stations AS stations
ON qr.station_id = stations.station_id
GROUP BY stations.name
ORDER BY SUM(qr.ridership_count) DESC
LIMIT 5;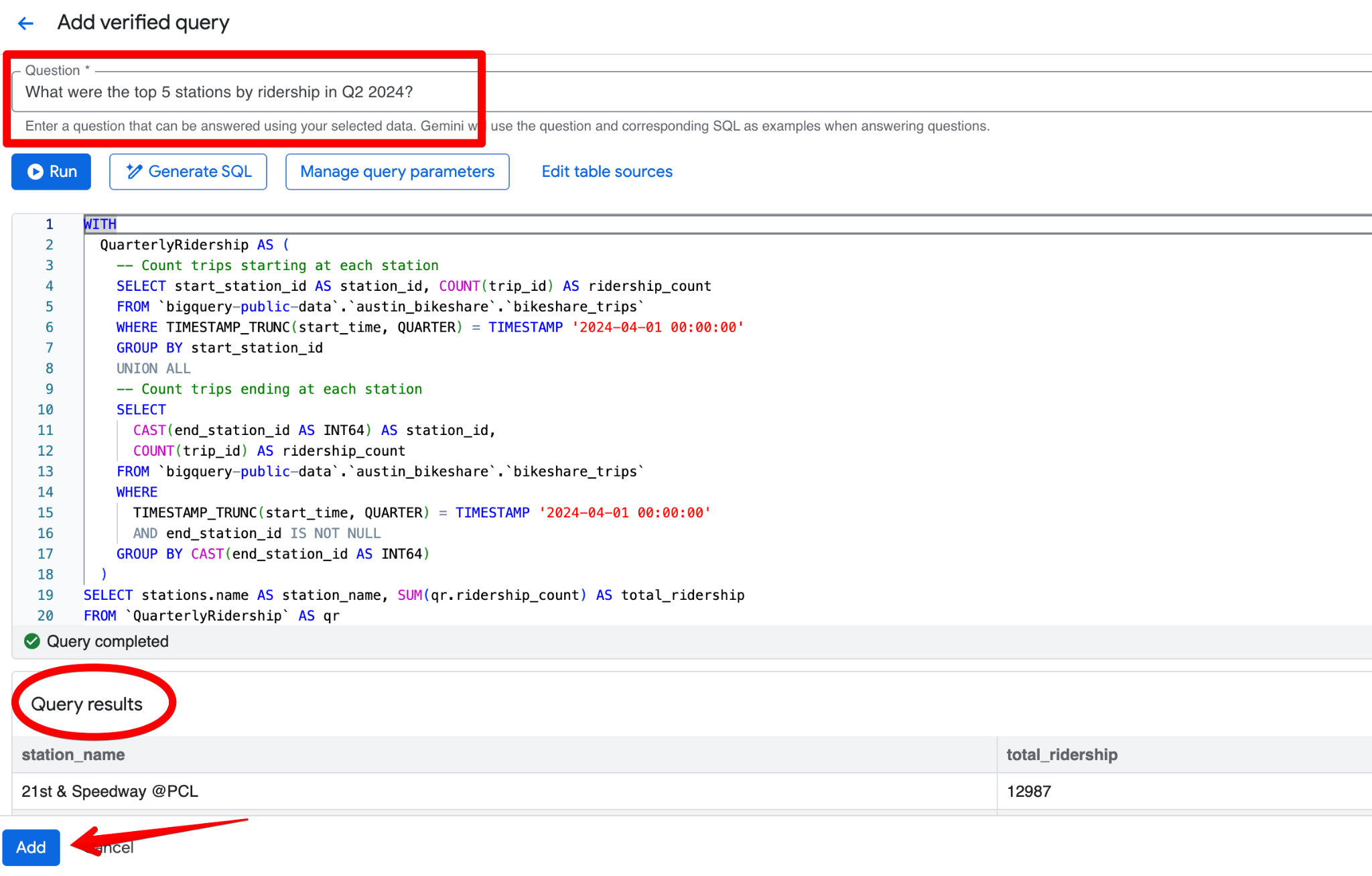
即使代理首次给出的答案看似合理,您仍可通过审阅生成的 SQL 并添加经验证查询,显著提升其准确性与一致性。
请遵循以下实操流程:
举例来说,您问:“2024 年 6 月的平均行程时长是多少?”在初始响应中,代理返回 26.68 分钟,并且正确排除了小于 1 分钟的行程。现在,假设团队的标准业务规则是排除任何小于 5 分钟的行程。
当您打开生成的 SQL(通过 Open in Editor)时,会看到筛选条件仅为 duration_minutes >= 1。
在 Verified Queries 区域点击 Add query 并创建如下条目:
问题:
What was the average trip duration in June 2024?SQL:
SELECT
ROUND(AVG(duration_minutes), 2) AS avg_trip_duration_minutes
FROM
bigquery-public-data.austin_bikeshare.bikeshare_trips
WHERE
start_time BETWEEN '2024-06-01' AND '2024-06-30'
AND duration_minutes >= 5; -- stricter rule: exclude trips under 5 minutes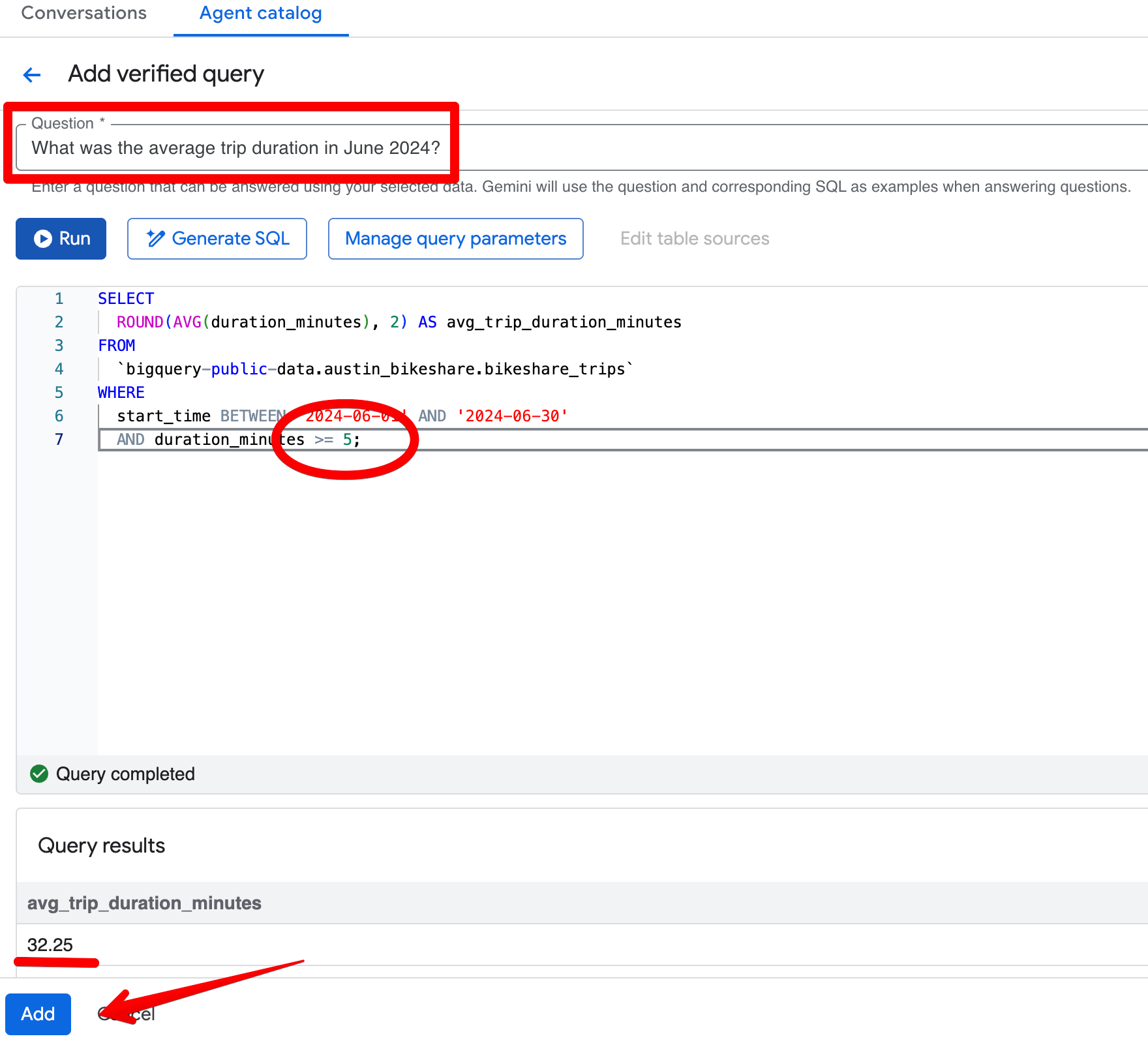
保存经验证查询后,在预览窗格中重新提出同一问题。现在代理会稳定返回约 32.08 分钟,并应用更严格的 5 分钟阈值。结果将更符合您对“有意义”行程的业务定义。
BigQuery 的对话式分析区别于简单的文本转 SQL 工具之处,在于其原生支持 BigQuery ML 函数、非结构化数据,并可在 Google Cloud 生态内便捷共享。
一大差异化能力是代理可直接从自然语言调用 BigQuery ML 函数,从回溯报表迈向前瞻性洞察。
例如,您可以让数据代理基于 2024 年趋势预测未来 30 天的每日行程数。 它会触发 AI.FORECAST,生成 2024 年 7 月的预测,并配以精美图表:历史每日行程(蓝线)与 30 天预测(橙线),并带有 95% 置信区间的阴影。
机器学习算法的另一用途是在数据异常时发出信号。例如,您让代理检测 2024 年 6 月每日骑行量的异常情况,它会调用 AI.DETECT_ANOMALIES,将 2024 年 6 月与前几个月对比,并返回时间序列表与折线图。
在该案例中,它未在 95% 置信水平下标记正式异常,但指出 6 月 19 日为接近异常(概率 92.1%),骑行量出现明显下降。
大多数对话式 BI 工具在遇到非行列式数据时便“失灵”。而 BigQuery 支持对象表(Object Tables),可分析存储在 Google Cloud Storage 中的非结构化数据(如 PDF、图像、原始文本日志)。
由于数据代理由 Gemini 的多模态能力驱动,它可同时对您的结构化指标与非结构化文件进行推理。这是 BigQuery 巨大的、独特的差异化优势。
如果您在对象表中保存了骑行者调查 PDF 或站点巡检图片,只需提问:“请总结 2024 年第二季度骑行者调查 PDF 的主要投诉。”代理会读取非结构化文件,并将信息与您的结构化行程数据结合。
您的数据团队在 BigQuery Studio 中构建并测试数据代理,但终端用户往往使用完全不同的应用。Google 使您可以轻松将代理与 GCP 控制台解耦,从而在业务用户常用的场景中提供能力。
如果您希望亲自尝试构建自定义聊天应用,也可进一步阅读官方 BigQuery 对话式分析简介。
若要提炼一个核心原则,那就是:对话式分析将分析瓶颈从“等待数据团队”转移为“提出正确问题”。
这并不意味着数据团队将被取代,但其角色正在变化。AI 代理的智能只与您为其建立的护栏同样智能。数据代理的准确性与安全性,完全取决于您提供的指令、语境与架构设计。
要构建最有效的对话式代理,您仍需对底层数据仓库有扎实掌控。如果您或您的团队希望强化这些核心技能,并掌握为这些 AI 功能提供支持的平台,欢迎查看 DataCamp 的 Introduction to BigQuery 课程!
Google Cloud 课程
Tracks
Courses
Courses