
Cursus
Data Engineering begrijpen
2 Hr
362.2K
Databricks is een open analyticsplatform voor het bouwen, uitrollen en beheren van data-, analytics- en AI-oplossingen op schaal. Het is gebouwd op Apache Spark en integreert met elk van de drie grote cloudproviders (AWS, Azure of GCP), waardoor we cloudinfrastructuur kunnen beheren en uitrollen namens ons, terwijl het ondersteuning biedt voor elke data science-toepassing die je je kunt voorstellen.
Vandaag neem ik je mee in een uitgebreide introductie tot Databricks, met de kernfuncties, praktische toepassingen en gestructureerde leerroutes om te beginnen. Van het opzetten van je omgeving tot het beheersen van datapreparatie, orkestratie en visualisatie: je vindt hier alles wat je nodig hebt om met Databricks te starten.
Databricks leren en een stevige basis opbouwen kan je verschillende belangrijke voordelen opleveren:
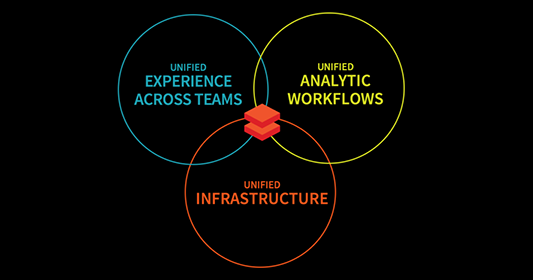
Databricks is een compleet platform voor data engineering, analytics en machine learning, met vijf hoofdkenmerken die schaalbaarheid, samenwerking en workflow-efficiëntie versterken.

Belangrijkste functies van Databricks. Afbeelding door de auteur.
Databricks verenigt de drie workflows voor data engineering, data science en machine learning in één platform. Dit vereenvoudigt datapreparatie, modeltraining en uitrol. Door deze domeinen te bundelen, versnelt Databricks AI-initiatieven en helpt het bedrijven om gesiloëde data om te zetten in bruikbare inzichten en samenwerking te bevorderen.
Apache Spark, het toonaangevende framework voor gedistribueerd rekenen, is diep geïntegreerd in Databricks. Hierdoor kan Databricks de Spark-configuratie automatisch afhandelen. Gebruikers kunnen zich dus richten op het bouwen van datasolutions zonder zich zorgen te maken over de setup.
Bovendien is de gedistribueerde verwerkingskracht van Spark ideaal voor big data-taken, en Databricks breidt dit uit met beveiliging op ondernemingsniveau, schaalbaarheid en optimalisatie.
Delta Lake is de ruggengraat van de Lakehouse-architectuur van Databricks en voegt functies toe zoals ACID-transacties, schemahandhaving en real-time dataconsistentie. Dit waarborgt betrouwbaarheid en nauwkeurigheid van data en maakt Delta Lake cruciaal voor het beheren van zowel batch- als streamingdata.
MLflow is een open-source platform voor het beheren van de volledige machinelearning-levenscyclus. Van het tracken van experimenten tot het beheren van modeluitrol: MLflow vereenvoudigt het bouwen en operationaliseren van ML-modellen.
Daarnaast breidt MLflow met de nieuwste integraties voor generatieve AI-tools zoals OpenAI en Hugging Face zijn mogelijkheden uit met toepassingen als chatbots, samenvattingen van documenten en sentimentanalyse.
Databricks stimuleert samenwerking via:
Starten met Databricks kan zowel spannend als overweldigend zijn. Daarom is de eerste stap bij het leren van elke nieuwe technologie een helder beeld te hebben van je doelen—waarom je het wilt leren en hoe je het wilt gebruiken.
Bepaal voordat je begint wat je met Databricks wilt bereiken.
Wil je als data engineer big data-processing stroomlijnen? Of wil je vooral de ML-mogelijkheden benutten om voorspellende modellen te bouwen en uit te rollen?
Door je hoofddoelen te definiëren, kun je een gerichte leerroute maken. Enkele tips per ambitie:
Aan de slag gaan met Databricks is makkelijker dan je denkt. Ik leid je door een stapsgewijze aanpak, zodat je snel vertrouwd raakt met de essentie van het platform.
Maak een gratis account aan op de Databricks Community Edition, die gratis toegang biedt tot de kernfuncties van het platform. Deze editie is ideaal om praktisch te verkennen, zodat je kunt experimenteren met Workspaces, Clusters en Notebooks zonder betaald abonnement.
Screenshot van het Databricks-aanmeldscherm. Afbeelding door de auteur
Zodra je je gegevens hebt ingevoerd, verschijnt het volgende scherm.

Screenshot van het Databricks-aanmeldscherm. Afbeelding door de auteur
Je krijgt vervolgens de keuze om een cloudprovider in te stellen of door te gaan met de Community Edition. Om het laagdrempelig te houden, gebruiken we de Community Edition. Die biedt minder functies dan de Enterprise-versie, maar is ideaal voor kleinere use-cases zoals tutorials en vereist geen cloudprovider-setup.
Na selectie van de Community Edition verifieer je je e-mailadres. Na verificatie kom je op een hoofddashboard dat er zo uitziet:
Screenshot van de Databricks-startpagina. Afbeelding door de auteur
Neem, zodra je bent ingelogd, de tijd om de indeling te begrijpen. Op het eerste gezicht lijkt de interface misschien basic, maar als je verder verkent of je account upgradet, ontdek je tal van sterke functies:
Databricks heeft drie kernconcepten die onmisbaar zijn voor elke professional die het onder de knie wil krijgen:
Leer Databricks met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
