
Courses
Tìm hiểu Data Engineering
2 giờ
362.2K
Databricks là một nền tảng phân tích mở để xây dựng, triển khai và vận hành các giải pháp dữ liệu, phân tích và AI ở quy mô lớn. Nền tảng này được xây dựng trên Apache Spark và tích hợp với ba nhà cung cấp đám mây lớn (AWS, Azure hoặc GCP), cho phép chúng ta quản lý và triển khai hạ tầng đám mây thay cho bạn, đồng thời cung cấp mọi ứng dụng khoa học dữ liệu mà bạn có thể hình dung.
Hôm nay tôi muốn giới thiệu toàn diện về Databricks, bao gồm các tính năng cốt lõi, ứng dụng thực tiễn và lộ trình học tập có cấu trúc để bạn bắt đầu. Từ thiết lập môi trường đến làm chủ xử lý dữ liệu, điều phối và trực quan hóa, bạn sẽ tìm thấy mọi thứ cần thiết để khởi đầu với Databricks.
Học Databricks và có nền tảng vững chắc về nó có thể mang lại cho bạn một số lợi thế chính sau:
Databricks là một nền tảng toàn diện cho kỹ thuật dữ liệu, phân tích và học máy, kết hợp năm tính năng chính giúp tăng khả năng mở rộng, cộng tác và hiệu quả quy trình làm việc.

Các tính năng chính của Databricks. Ảnh: Tác giả.
Databricks kết hợp cả ba quy trình làm việc về kỹ thuật dữ liệu, khoa học dữ liệu và học máy vào một nền tảng duy nhất. Điều này giúp đơn giản hóa hơn nữa việc xử lý dữ liệu, huấn luyện và triển khai mô hình. Bằng cách hợp nhất các lĩnh vực này, Databricks tăng tốc các sáng kiến AI, giúp doanh nghiệp chuyển dữ liệu rời rạc thành insight có thể hành động và thúc đẩy hợp tác.
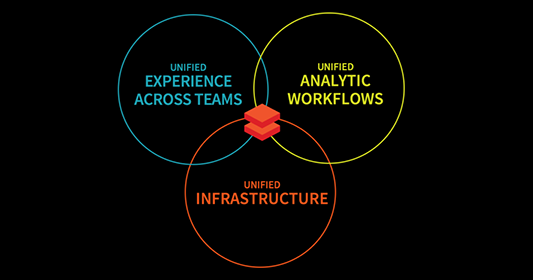
Apache Spark, khuôn khổ tính toán phân tán hàng đầu, được tích hợp sâu với Databricks. Nhờ đó, Databricks có thể tự động xử lý cấu hình Spark. Vì vậy, người dùng có thể tập trung xây dựng giải pháp dữ liệu mà không phải lo phần thiết lập.
Hơn nữa, sức mạnh xử lý phân tán của Spark lý tưởng cho các tác vụ dữ liệu lớn, và Databricks bổ sung bảo mật cấp doanh nghiệp, khả năng mở rộng và tối ưu hóa.
Delta Lake là xương sống của kiến trúc Lakehouse của Databricks, bổ sung các tính năng như giao dịch ACID, áp đặt lược đồ và tính nhất quán dữ liệu thời gian thực. Điều này đảm bảo độ tin cậy và chính xác của dữ liệu, khiến Delta Lake trở thành công cụ thiết yếu để quản lý cả dữ liệu theo lô và dữ liệu dòng.
MLflow là nền tảng mã nguồn mở để quản lý toàn bộ vòng đời học máy. Từ theo dõi thí nghiệm đến quản lý triển khai mô hình, MLflow đơn giản hóa quá trình xây dựng và đưa mô hình ML vào vận hành.
Ngoài ra, với các tích hợp mới nhất cho các công cụ AI tạo sinh như OpenAI và Hugging Face, MLflow mở rộng khả năng sang các ứng dụng tiên tiến như chatbot, tóm tắt tài liệu và phân tích cảm xúc.
Databricks thúc đẩy cộng tác thông qua:
Bắt đầu với Databricks vừa thú vị vừa có thể gây choáng ngợp. Vì vậy, bước đầu tiên khi học bất kỳ công nghệ mới nào là hiểu rõ mục tiêu của bạn—vì sao bạn muốn học và bạn dự định sử dụng nó như thế nào.
Trước khi bắt đầu, hãy xác định bạn muốn đạt được điều gì với Databricks.
Bạn có muốn tinh gọn xử lý dữ liệu lớn với vai trò kỹ sư dữ liệu? Hay bạn tập trung khai thác khả năng ML để xây dựng và triển khai mô hình dự đoán?
Bằng cách xác định mục tiêu chính, bạn có thể xây dựng kế hoạch học tập tập trung. Dưới đây là một số gợi ý tùy theo định hướng của bạn:
Bắt đầu với Databricks có thể dễ hơn bạn nghĩ. Tôi sẽ hướng dẫn bạn theo từng bước để bạn nhanh chóng làm quen với những yếu tố cốt lõi của nền tảng.
Bắt đầu bằng cách tạo tài khoản miễn phí trên Databricks Community Edition, phiên bản này cung cấp quyền truy cập các tính năng cốt lõi của nền tảng mà không tốn phí. Rất phù hợp để thực hành trực tiếp, cho phép bạn thử nghiệm với Workspaces, Clusters và Notebooks mà không cần đăng ký trả phí.
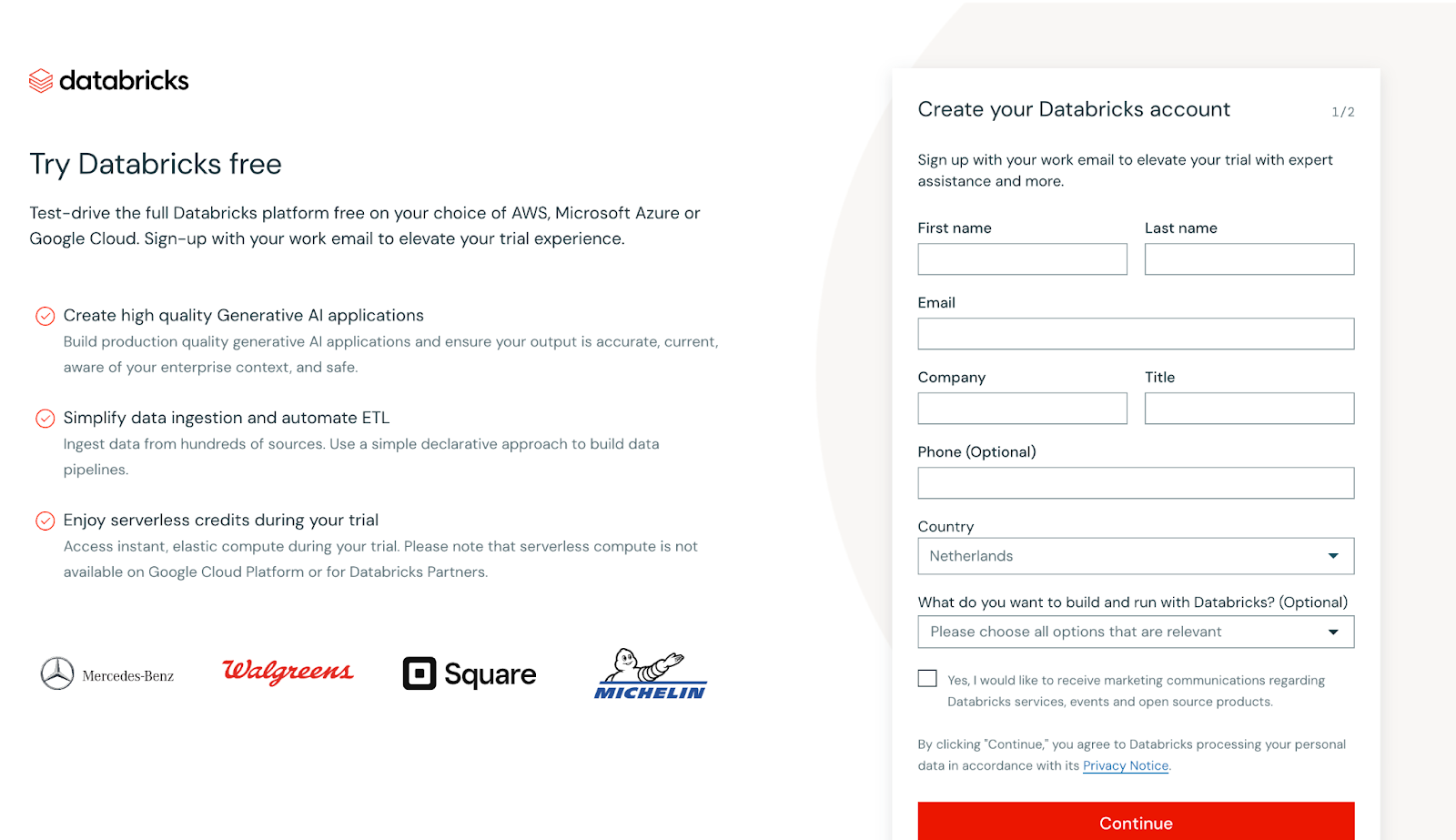
Ảnh chụp màn hình trang đăng ký Databricks. Ảnh: Tác giả
Sau khi bạn cung cấp thông tin, màn hình sau sẽ xuất hiện.

Ảnh chụp màn hình trang đăng ký Databricks. Ảnh: Tác giả
Lúc này, bạn sẽ được nhắc chọn thiết lập nhà cung cấp đám mây hoặc tiếp tục với Community Edition. Để dễ tiếp cận, chúng ta sẽ dùng Community Edition. Dù ít tính năng hơn phiên bản Enterprise, nó lý tưởng cho các mục đích nhỏ như hướng dẫn và không yêu cầu thiết lập nhà cung cấp đám mây.
Sau khi chọn Community Edition, hãy xác minh địa chỉ email của bạn. Khi xác minh xong, bạn sẽ thấy bảng điều khiển chính như sau:
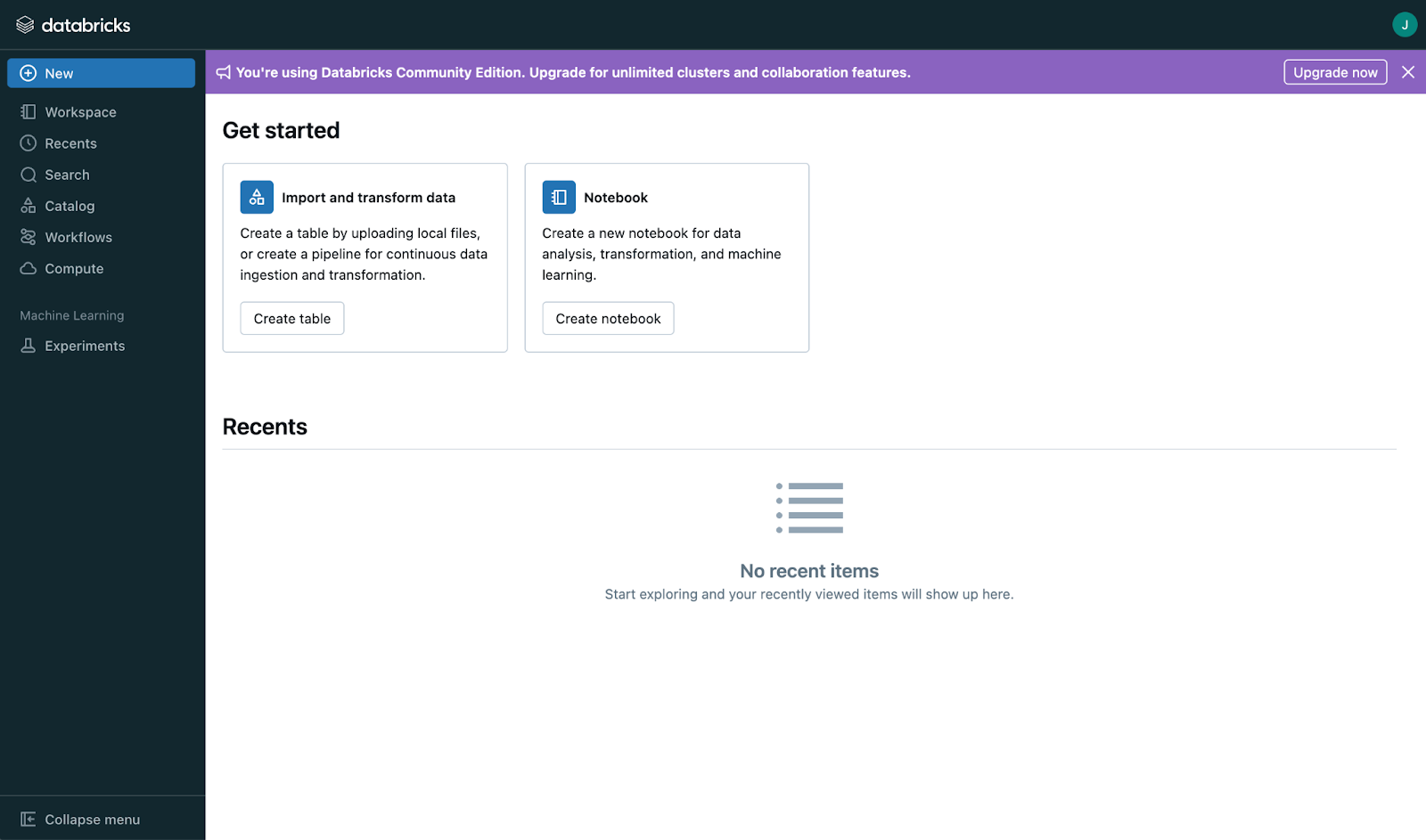
Ảnh chụp màn hình trang chính Databricks. Ảnh: Tác giả
Sau khi đăng nhập, hãy dành thời gian hiểu bố cục. Ở cái nhìn đầu tiên, giao diện có vẻ đơn giản, nhưng khi khám phá sâu hơn hoặc nâng cấp tài khoản, bạn sẽ thấy rất nhiều tính năng hữu ích:
Databricks có ba khái niệm cốt lõi mà bất kỳ chuyên gia nào muốn làm chủ cũng cần nắm:
Học Databricks với DataCamp
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút