
Course
Understanding Data Engineering
2 hr
355.8K
Databricks is an open analytics platform for building, deploying, and maintaining data, analytics, and AI solutions at scale. It is built on Apache Spark and integrates with any of the three major cloud providers (AWS, Azure, or GCP), allowing us to manage and deploy cloud infrastructure on our behalf while offering any data science application you can imagine.
Today I want to walk you through a comprehensive introduction to Databricks, covering its core features, practical applications, and structured learning paths to get you started. From setting up your environment to mastering data processing, orchestration, and visualization, you’ll find everything you need to get started with Databricks.
Learning Databricks and having some solid foundations in it might have several main positive advantages for you:
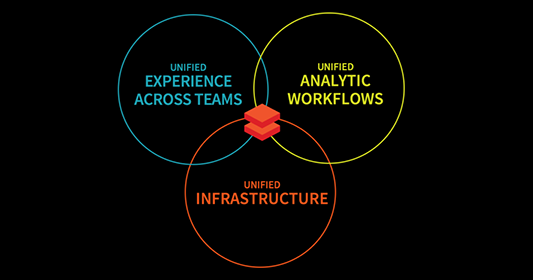
Databricks is a comprehensive platform for data engineering, analytics, and machine learning, combining five main features that enhance scalability, collaboration, and workflow efficiency.

Key features of Databricks. Image by Author.
Databricks combines all three data engineering, data science, and machine learning workflows into a single platform. This further simplifies data processing, model training, and deployment. By unifying these domains, Databricks accelerates AI initiatives, helping businesses transform siloed data into actionable insights while fostering collaboration.
Apache Spark, the leading distributed computing framework, is deeply integrated with Databricks. This allows Databricks to handle Spark configuration automatically. Therefore, users can focus on building data solutions without worrying about the setup.
Furthermore, Spark’s distributed processing power is ideal for big data tasks, and Databricks enhances it with enterprise-level security, scalability, and optimization.
Delta Lake is the backbone of Databricks’ Lakehouse architecture, which adds features like ACID transactions, schema enforcement, and real-time data consistency. This ensures data reliability and accuracy, making Delta Lake a critical tool for managing both batch and streaming data.
MLflow is an open-source platform for managing the entire machine learning lifecycle. Fom tracking experiments to managing model deployment, MLflow simplifies the process of building and operationalizing ML models.
Additionally, with the latest integrations for generative AI tools like OpenAI and Hugging Face, MLflow extends its capabilities to include cutting-edge applications such as chatbots, document summarization, and sentiment analysis.
Databricks fosters collaboration through:
Getting started with Databricks can be both exciting and overwhelming. That’s why the first step in learning any new technology is to have a clear understanding of your goals—why you want to learn it and how you plan to use it.
Before diving in, define what you want to achieve with Databricks.
Are you looking to streamline big data processing as a data engineer? Or are you focused on harnessing its ML capabilities to build and deploy predictive models?
By defining your main objectives, you can create a focused learning plan accordingly. Here are some tips depending on your main aspiration:
Getting started with Databricks can be easier than you might think. To do so, I will guide you into a step-by-step approach, so you can easily familiarize yourself with the platform’s essentials.
Begin by creating a free account on Databricks Community Edition, which provides access to core features of the platform at no cost. This edition is perfect for hands-on exploration, allowing you to experiment with Workspaces, Clusters, and Notebooks without needing a paid subscription.
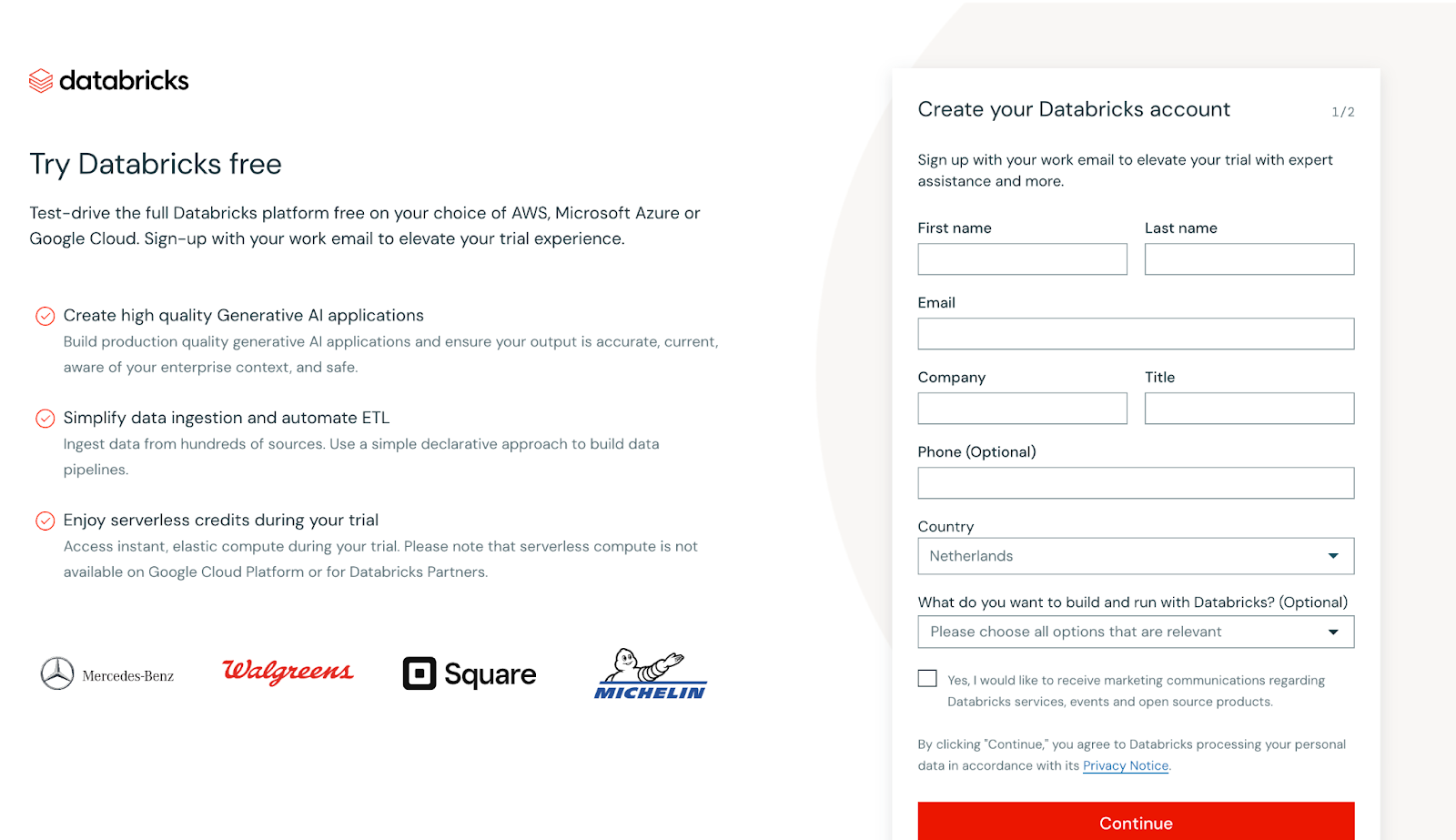
Screenshot of Databricks signing up main view. Image by Author
Once you give your details, the following view will appear.

Screenshot of Databricks signing up main view. Image by Author
In this case, you’ll be prompted to either set up a cloud provider or proceed with the Community Edition. To keep things accessible, we’ll use the Community Edition. While it offers fewer features than the Enterprise version, it’s ideal for smaller use cases like tutorials and doesn’t require a cloud provider setup.
After selecting the Community Edition, verify your email address. Once verified, you’ll be greeted with a main dashboard that looks like this:
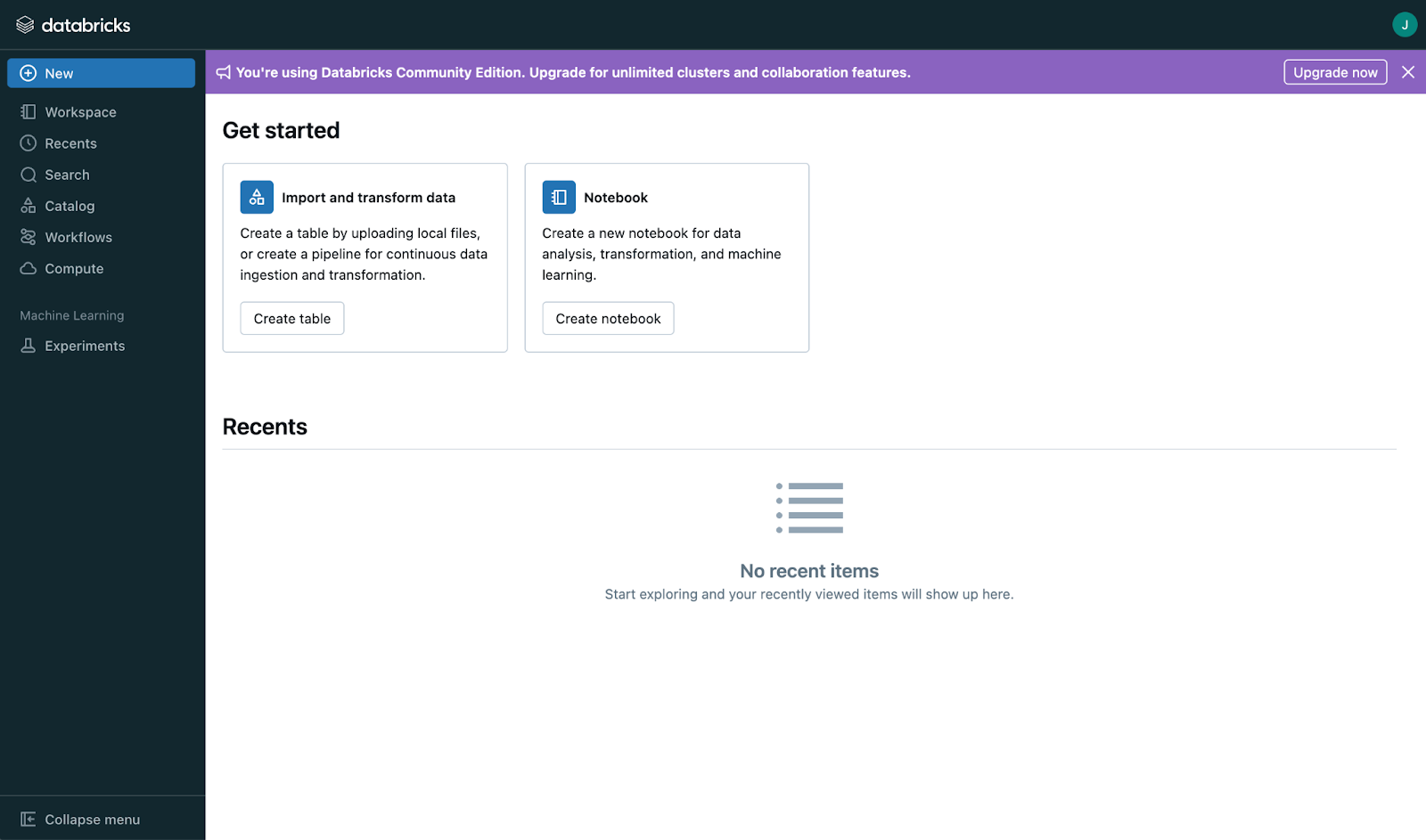
Screenshot of Databricks main page. Image by Author
Once logged in, take time to understand the layout. At first glance, the interface might seem basic, but once you explore further or upgrade your account, you’ll uncover lots of great features:
Databricks has three core concepts that will remain basic for any professional willing to master it:
Subscribe to DataFramed wherever you get your podcasts.

Learn Databricks with DataCamp
Course
Course
Course
blog
Gus Frazer
11 min
blog
Maria Eugenia Inzaugarat
15 min
blog
Thalia Barrera
15 min
Tutorial
Bex Tuychiev
Tutorial
Allan Ouko
Tutorial
Austin Chia

