
Kurs
Grundlagen von Data Engineering
2 Std.
355.8K
Databricks ist eine offene Analyseplattform für den Aufbau, den Einsatz und die Pflege von Daten, Analysen und KI-Lösungen in großem Maßstab. Es basiert auf Apache Spark und lässt sich mit jedem der drei großen Cloud-Anbieter (AWS, Azure oder GCP) integrieren. So können wir die Cloud-Infrastruktur in unserem Namen verwalten und bereitstellen und gleichzeitig jede erdenkliche Data Science-Anwendung anbieten.
Heute möchte ich dir eine umfassende Einführung in Databricks geben, die die wichtigsten Funktionen, praktische Anwendungen und strukturierte Lernpfade für den Einstieg umfasst. Von der Einrichtung deiner Umgebung bis zur Beherrschung von Datenverarbeitung, Orchestrierung und Visualisierung findest du hier alles, was du für den Einstieg in Databricks brauchst.
Wenn du Databricks lernst und über ein solides Fundament verfügst, kann das mehrere positive Vorteile für dich haben:
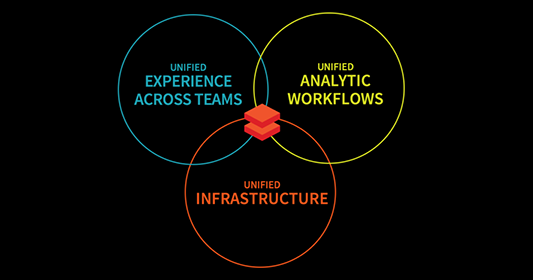
Databricks ist eine umfassende Plattform für Data Engineering, Analytik und maschinelles Lernen, die fünf Hauptfunktionen zur Verbesserung der Skalierbarkeit, Zusammenarbeit und Workflow-Effizienz vereint.

Die wichtigsten Merkmale von Databricks. Bild vom Autor.
Databricks vereint alle drei Arbeitsabläufe für Data Engineering, Data Science und maschinelles Lernen in einer einzigen Plattform. Dies vereinfacht die Datenverarbeitung, die Modellschulung und den Einsatz weiter. Durch die Vereinheitlichung dieser Bereiche beschleunigt Databricks KI-Initiativen und hilft Unternehmen dabei, isolierte Daten in verwertbare Erkenntnisse zu verwandeln und gleichzeitig die Zusammenarbeit zu fördern.
Apache Spark, das führende Framework für verteiltes Rechnen, ist eng mit Databricks integriert. So kann Databricks die Spark-Konfiguration automatisch übernehmen. So können sich die Nutzer auf die Erstellung von Datenlösungen konzentrieren, ohne sich um die Einrichtung kümmern zu müssen.
Außerdem ist die verteilte Rechenleistung von Spark ideal für Big-Data-Aufgaben, und Databricks erweitert sie um Sicherheit, Skalierbarkeit und Optimierung auf Unternehmensebene.
Delta Lake ist das Rückgrat der Lakehouse-Architektur von Databricks, die Funktionen wie ACID-Transaktionen, Schema-Enforcement und Echtzeit-Datenkonsistenz bietet . Dies gewährleistet die Zuverlässigkeit und Genauigkeit der Daten und macht Delta Lake zu einem wichtigen Werkzeug für die Verwaltung von Batch- und Streaming-Daten.
MLflow ist eine Open-Source-Plattform für die Verwaltung des gesamten Lebenszyklus von Machine Learning. Von der Nachverfolgung von Experimenten bis zur Verwaltung der Modellbereitstellung vereinfacht MLflow den Aufbau und die Anwendung von ML-Modellen.
Mit den neuesten Integrationen für generative KI-Tools wie OpenAI und Hugging Face erweitert MLflow seine Möglichkeiten um innovative Anwendungen wie Chatbots, Dokumentenzusammenfassung und Sentimentanalyse.
Databricks fördert die Zusammenarbeit durch:
Der Einstieg in Databricks kann sowohl spannend als auch überwältigend sein. Deshalb ist der erste Schritt beim Erlernen einer neuen Technologie, dass du dir über deine Ziele im Klaren bist - warum du sie lernen willst und wie du sie nutzen willst.
Bevor du einsteigst, solltest du definieren, was du mit Databricks erreichen willst.
Willst du als Dateningenieur/in die Verarbeitung von Big Data optimieren? Oder konzentrierst du dich darauf, die ML-Funktionen zu nutzen, um Vorhersagemodelle zu erstellen und einzusetzen?
Wenn du deine Hauptziele definierst, kannst du einen gezielten Lernplan erstellen. Hier sind einige Tipps, die von deinem Hauptziel abhängen:
Der Einstieg in Databricks kann einfacher sein, als du vielleicht denkst. Dazu werde ich dich Schritt für Schritt anleiten, damit du dich leicht mit den Grundlagen der Plattform vertraut machen kannst.
Beginnen Sie mit der Erstellung eines kostenlosen Kontos bei Databricks Community Editionan, mit dem du kostenlos auf die wichtigsten Funktionen der Plattform zugreifen kannst. Diese Edition ist perfekt für die praktische Erkundung, denn sie ermöglicht es dir, mit Workspaces, Clustern und Notizbüchern zu experimentieren, ohne dass du ein kostenpflichtiges Abonnement benötigst.
Screenshot der Hauptansicht der Databricks-Anmeldung. Bild vom Autor
Sobald du deine Daten eingegeben hast, erscheint die folgende Ansicht.

Screenshot der Hauptansicht der Databricks-Anmeldung. Bild vom Autor
In diesem Fall wirst du aufgefordert, entweder einen Cloud-Anbieter einzurichten oder mit der Community Edition fortzufahren. Um die Dinge zugänglich zu halten, werden wir die Community Edition verwenden. Sie bietet zwar weniger Funktionen als die Enterprise-Version, ist aber ideal für kleinere Anwendungsfälle wie Tutorials und erfordert keine Einrichtung bei einem Cloud-Anbieter.
Nachdem du die Community Edition ausgewählt hast, verifiziere deine E-Mail-Adresse. Sobald du verifiziert bist, wirst du mit einem Haupt-Dashboard begrüßt, das wie folgt aussieht:
Screenshot der Hauptseite von Databricks. Bild vom Autor
Wenn du eingeloggt bist, nimm dir Zeit, um das Layout zu verstehen. Auf den ersten Blick mag die Benutzeroberfläche einfach erscheinen, aber wenn du sie weiter erkundest oder dein Konto erweiterst, wirst du viele tolle Funktionen entdecken:
Databricks hat drei Kernkonzepte, die für jeden Profi, der sie beherrschen will, grundlegend bleiben:
Abonniere DataFramed, wo auch immer du deine Podcasts hörst.

Databricks lernen mit DataCamp
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
Tutorial
Allan Ouko
Tutorial
Javier Canales Luna
Tutorial
Laiba Siddiqui



