
Cursus
Basis van PySpark
4 Hr
157.6K
PySpark is de combinatie van twee krachtige technologieën: Python en Apache Spark.
Python is een van de meest gebruikte programmeertalen in softwareontwikkeling, met name voor data science en machine learning, vooral dankzij de eenvoudige en duidelijke syntax.
Apache Spark is daarentegen een framework dat grote hoeveelheden ongestructureerde data aankan. Spark is gebouwd met Scala, een taal die ons meer controle geeft. Scala is echter niet erg populair onder dataprofessionals. Daarom is PySpark ontwikkeld om dit gat te dichten.
PySpark biedt een API en een gebruiksvriendelijke interface om met Spark te werken. Het gebruikt de eenvoud en flexibiliteit van Python om big data-verwerking voor een breder publiek toegankelijk te maken.
De laatste jaren is PySpark een belangrijk hulpmiddel geworden voor dataprofessionals die enorme hoeveelheden data moeten verwerken. De populariteit is te verklaren door verschillende factoren:
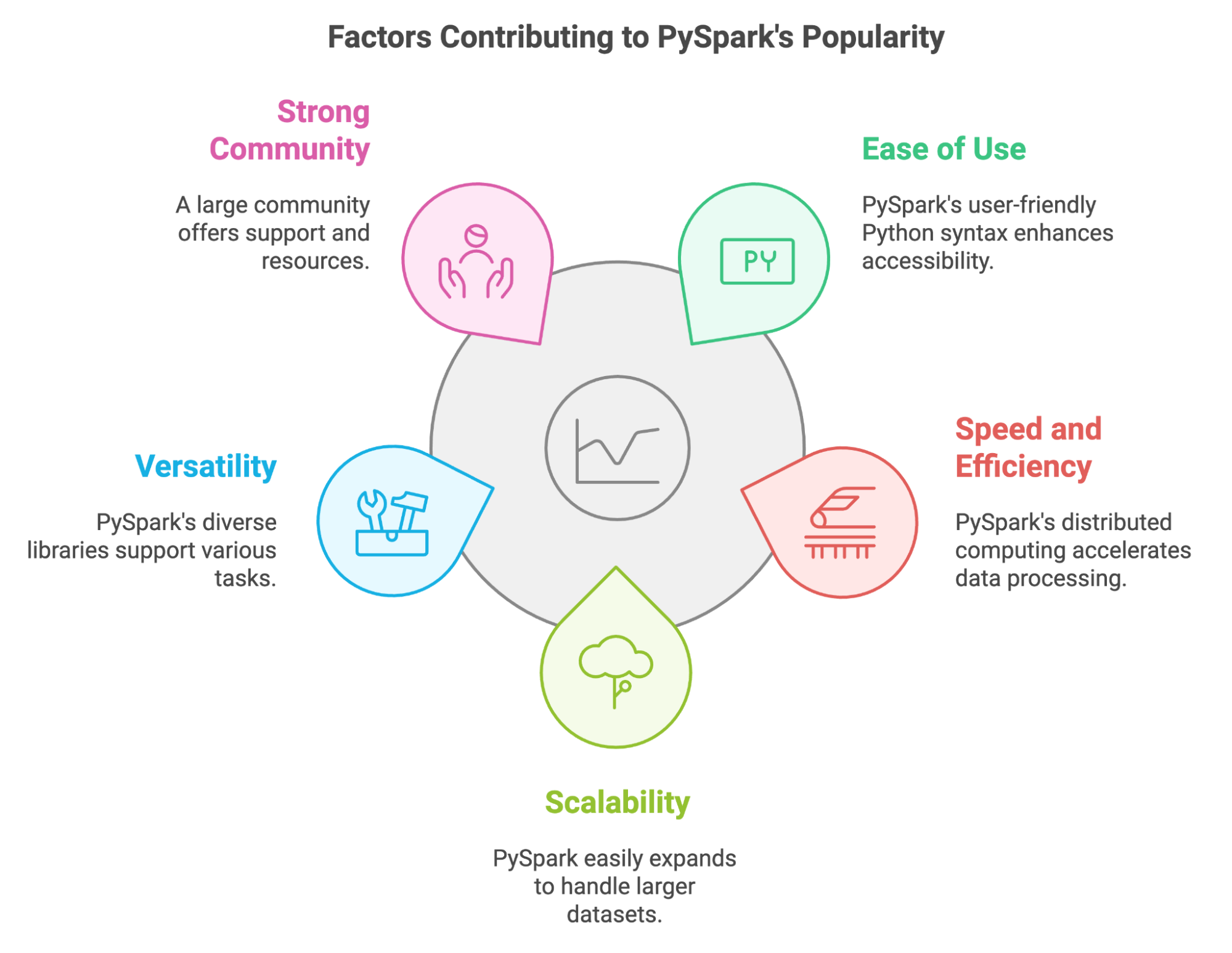
Met PySpark kunnen we ook bestaande Python-skills en -bibliotheken benutten. Je integreert het eenvoudig met populaire tools zoals Pandas en Scikit-learn, en je kunt diverse databronnen gebruiken.
PySpark is speciaal ontwikkeld voor big data en machine learning. Maar welke features maken het zo krachtig voor het omgaan met enorme hoeveelheden data? Laten we ze bekijken:
De hoeveelheid data blijft alleen maar toenemen. Tegenwoordig omvatten taken voor data wrangling, data-analyse en machine learning het werken met grote hoeveelheden data. We hebben krachtige tools nodig die die data efficiënt en snel verwerken. PySpark is zo'n tool.
We hebben de sterke punten van PySpark al genoemd, maar laten we een paar concrete voorbeelden bekijken waar je ze kunt inzetten:
Met de opkomst van data science en machine learning en de toename van beschikbare data is er veel vraag naar professionals met datamanipulatie-skills. Volgens het State of Data & AI Literacy Report 2024 hecht 80% van de leiders waarde aan data-analyse en -manipulatievaardigheden.
PySpark leren kan veel carrièrekansen openen. Meer dan 800 vacatures op Indeed, van data engineers tot data scientists, benadrukken de vraag naar PySpark-vaardigheid in data-gerelateerde functies.
Als je PySpark methodisch leert, vergroot je je kans op succes. Laten we ons richten op een paar principes die je in je leertraject kunt toepassen.
Voordat je in de technische details duikt, bepaal je motivatie om PySpark te leren. Vraag jezelf af:
Nadat je je doelen hebt bepaald, beheers je de basis van PySpark en begrijp je hoe het werkt.
Omdat PySpark is gebouwd bovenop Python, moet je eerst vertrouwd raken met Python. Je moet je prettig voelen bij het werken met variabelen en functies. Het is ook handig om bekend te zijn met datamanipulatiebibliotheken zoals Pandas. DataCamps cursus Introduction to Python en Data Manipulation with Pandas helpen je snel op weg.
Je moet PySpark installeren om ermee aan de slag te gaan. Je kunt PySpark downloaden met pip of Conda, het handmatig downloaden van de officiële website, of starten met DataLab om direct in je browser met PySpark te werken.
Wil je een volledige uitleg over het opzetten van PySpark, bekijk dan deze handleiding over hoe je PySpark installeert op Windows, Mac en Linux.
Het eerste concept dat je moet leren is hoe PySpark DataFrames werken. Ze zijn een van de belangrijkste redenen waarom PySpark zo snel en efficiënt is. Begrijp hoe je ze maakt, transformeert (map en filter) en manipuleert. De tutorial over hoe je begint met PySpark helpt je met deze concepten.
Als je je prettig voelt bij de basis, is het tijd om intermediate PySpark-skills te verkennen.
Een van de grootste voordelen van PySpark is de mogelijkheid om SQL-achtige queries uit te voeren om DataFrames te lezen en te manipuleren, aggregaties uit te voeren en windowfuncties te gebruiken. Onder de motorkap gebruikt PySpark Spark SQL. Deze introductie tot Spark SQL in Python kan je hierbij helpen.
Werken met data betekent dat je vaardig wordt in het opschonen, transformeren en voorbereiden ervan voor analyse. Dit omvat het omgaan met missende waarden, verschillende datatypen en het uitvoeren van aggregaties met PySpark. Volg DataCamp's Cleaning Data with PySpark om praktische ervaring op te doen en deze skills te beheersen.
Met PySpark kun je dankzij de MLlib-bibliotheek ook machinelearningmodellen ontwikkelen en deployen. Je zou feature engineering, model-evaluatie en hyperparameter-tuning met deze bibliotheek moeten leren. De cursus Machine Learning with PySpark van DataCamp biedt een uitgebreide introductie.
Cursussen volgen en oefeningen doen met PySpark is een uitstekende manier om vertrouwd te raken met de technologie. Maar om echt vaardig te worden, moet je uitdagende, skill-versterkende problemen oplossen, zoals je die in echte projecten tegenkomt. Begin met eenvoudige data-analysetaken en ga geleidelijk naar complexere uitdagingen.
Zo kun je je skills oefenen:
Terwijl je vordert in je PySpark-leertraject, rond je verschillende projecten af. Om je PySpark-skills en -ervaring aan potentiële werkgevers te tonen, moet je ze bundelen in een portfolio. Dit portfolio moet je skills en interesses weerspiegelen en afgestemd zijn op de carrière of sector die je ambieert.
Probeer originele projecten te maken die je probleemoplossend vermogen laten zien. Neem projecten op die je vaardigheid tonen in diverse aspecten van PySpark, zoals data wrangling, machine learning en datavisualisatie. Documenteer je projecten met context, methodologie, code en resultaten. Je kunt DataLab gebruiken, een online IDE waarmee je samen code kunt schrijven, data analyseren en inzichten delen.
Hier zijn twee PySpark-projecten waar je aan kunt werken:
PySpark leren is een continu traject. Technologie evolueert constant, en er worden regelmatig nieuwe features en toepassingen ontwikkeld. PySpark vormt daarop geen uitzondering.
Als je de fundamentals beheerst, kun je zoeken naar uitdagendere taken en projecten zoals performance-optimalisatie of GraphX. Richt je op je doelen en specialiseer je in gebieden die relevant zijn voor jouw carrière en interesses.
Blijf op de hoogte van nieuwe ontwikkelingen en leer hoe je die toepast in je huidige projecten. Blijf oefenen, zoek nieuwe uitdagingen en kansen, en omarm het idee dat fouten maken een manier is om te leren.
Laten we de stappen samenvatten voor een succesvol PySpark-leerplan:
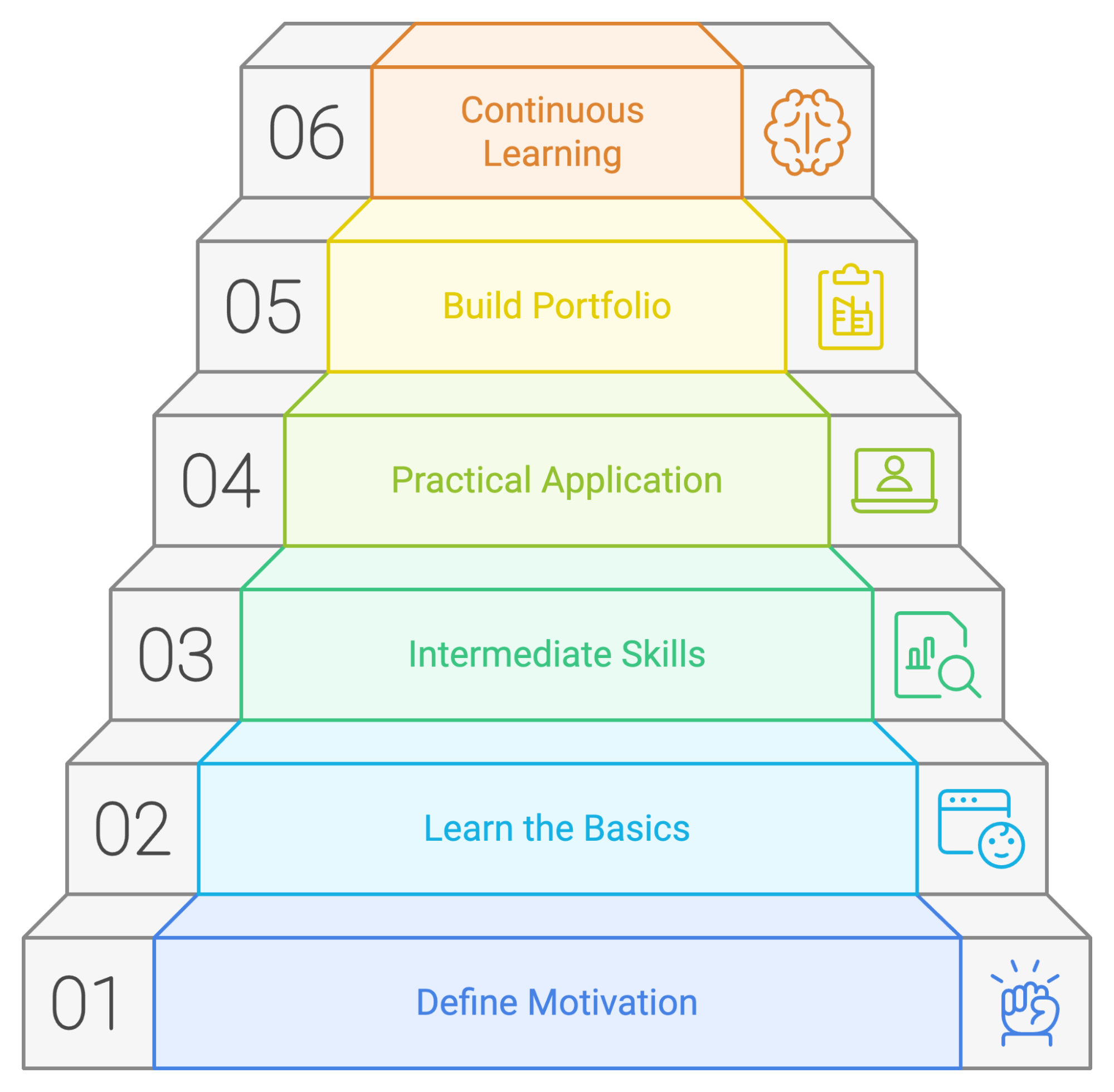
Hoewel iedereen op zijn eigen manier leert, is het altijd slim om een plan of leidraad te hebben bij het leren van een nieuwe tool. We hebben een mogelijk leerplan opgesteld met de focuspunten als je net begint met PySpark.
Ik kan me voorstellen dat je nu klaar bent om in PySpark te duiken en met een grote dataset aan de slag te gaan om te oefenen. Maar voordat je dat doet, licht ik graag deze tips uit die je helpen op weg naar PySpark-vaardigheid.
PySpark is een tool met veel verschillende toepassingen. Om gefocust te blijven en je doel te bereiken, moet je je interessegebied bepalen. Wil je je richten op data-analyse, data engineering of machine learning? Een gerichte aanpak helpt je de meest relevante aspecten en kennis van PySpark voor jouw pad op te doen.
Consistentie is de sleutel om een nieuwe skill te beheersen. Plan vaste tijd in om PySpark te oefenen. Een korte tijd per dag is voldoende. Je hoeft niet elke dag complexe concepten aan te pakken. Je kunt herhalen wat je hebt geleerd of een eenvoudige oefening opnieuw schrijven. Regelmatige oefening versterkt je begrip en bouwt je vertrouwen om het toe te passen.
Dit is een van de belangrijkste tips, en je zult het meerdere keren in deze gids lezen. Oefeningen zijn geweldig om vertrouwen op te bouwen. Maar je PySpark-skills toepassen in echte projecten is wat je echt doet uitblinken. Zoek datasets die je interesseren en gebruik PySpark om ze te analyseren, inzichten te halen en problemen op te lossen.
Begin met simpele projecten en vragen en neem geleidelijk complexere aan. Dit kan zo eenvoudig zijn als het inlezen en opschonen van een echte dataset en het schrijven van een complexe query voor aggregaties en het voorspellen van de prijs van een huis.
Samen leren werkt vaak effectiever. Ervaringen delen en van anderen leren versnelt je voortgang en levert waardevolle inzichten op.
Om kennis, ideeën en vragen uit te wisselen, kun je je aansluiten bij groepen rond PySpark en meet-ups en conferenties bijwonen. De Databricks Community, het bedrijf opgericht door de makers van Spark, heeft een actief forum waar je kunt discussiëren en vragen stellen over PySpark. Daarnaast is de Spark Summit, georganiseerd door Databricks, de grootste Spark-conferentie.
Zoals met elke technologie is PySpark leren een iteratief proces. En leren van je fouten is een essentieel onderdeel daarvan. Wees niet bang om te experimenteren, verschillende aanpakken te proberen en van je fouten te leren. Probeer verschillende functies en alternatieven voor het aggregeren van data, voer subqueries of geneste queries uit en merk op hoe snel PySpark reageert.
Laten we een paar efficiënte methoden bespreken om PySpark te leren.
Online cursussen zijn een uitstekende manier om PySpark in je eigen tempo te leren. DataCamp biedt PySpark-cursussen voor alle niveaus, die samen het Big Data with PySpark-track vormen. De cursussen behandelen introductieconcepten tot en met machine learning en zijn ontworpen met hands-on oefeningen.
Enkele PySpark-gerelateerde cursussen op DataCamp:
Tutorials zijn een andere geweldige manier om PySpark te leren, vooral als je nieuw bent met de technologie. Ze bevatten stapsgewijze instructies om specifieke taken uit te voeren of bepaalde concepten te begrijpen. Ter start, bekijk deze tutorials:
Cheat sheets zijn handig als je snel een naslag nodig hebt over PySpark-onderwerpen. Hier zijn twee nuttige cheat sheets:
PySpark leren vraagt om hands-on oefening. Je ontwikkelt je het snelst door uitdagingen in projecten aan te gaan waarin je al je geleerde skills toepast. Naarmate je complexere taken oppakt, moet je oplossingen vinden en alternatieven onderzoeken om de gewenste resultaten te behalen, wat je PySpark-expertise vergroot.
Bekijk de PySpark-projecten op DataCamp. Hiermee pas je je datamanipulatieskills en het bouwen van ML-modellen toe met PySpark:
Boeken zijn een uitstekend middel om PySpark te leren. Ze bieden diepgaande kennis en inzichten van experts, naast codefragmenten en uitleg. Enkele populaire boeken over PySpark:
De vraag naar PySpark-skills is toegenomen in verschillende datarollen, van data-analist tot big data engineer. Als je je voorbereidt op een interview, overweeg dan deze PySpark-interviewvragen voor
Als big data engineer ben je de architect van big data-oplossingen, verantwoordelijk voor het ontwerpen, bouwen en onderhouden van de infrastructuur die grote datasets verwerkt. Je vertrouwt op PySpark om schaalbare datapijplijnen te bouwen en zo efficiënte datainname, -verwerking en -opslag te garanderen.
Je hebt een sterke kennis nodig van gedistribueerd rekenen en cloudplatforms, en expertise in datawarehousing en ETL-processen.
Leer PySpark met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
