
Corso
Fondamenti di PySpark
4 h
157.6K
PySpark è l'unione di due tecnologie potenti: Python e Apache Spark.
Python è uno dei linguaggi di programmazione più utilizzati nello sviluppo software, in particolare per data science e machine learning, soprattutto per la sua sintassi semplice e immediata.
Dall'altro lato, Apache Spark è un framework in grado di gestire grandi quantità di dati non strutturati. Spark è stato costruito con Scala, un linguaggio che offre maggiore controllo. Tuttavia, Scala non è particolarmente popolare tra chi lavora con i dati. Così è nato PySpark per colmare questo gap.
PySpark offre un'API e un'interfaccia intuitiva per interagire con Spark. Sfrutta la semplicità e la flessibilità di Python per rendere l'elaborazione dei big data accessibile a un pubblico più ampio.
Negli ultimi anni, PySpark è diventato uno strumento importante per i professionisti dei dati che devono elaborare enormi quantità di informazioni. Possiamo spiegare la sua popolarità con diversi fattori chiave:
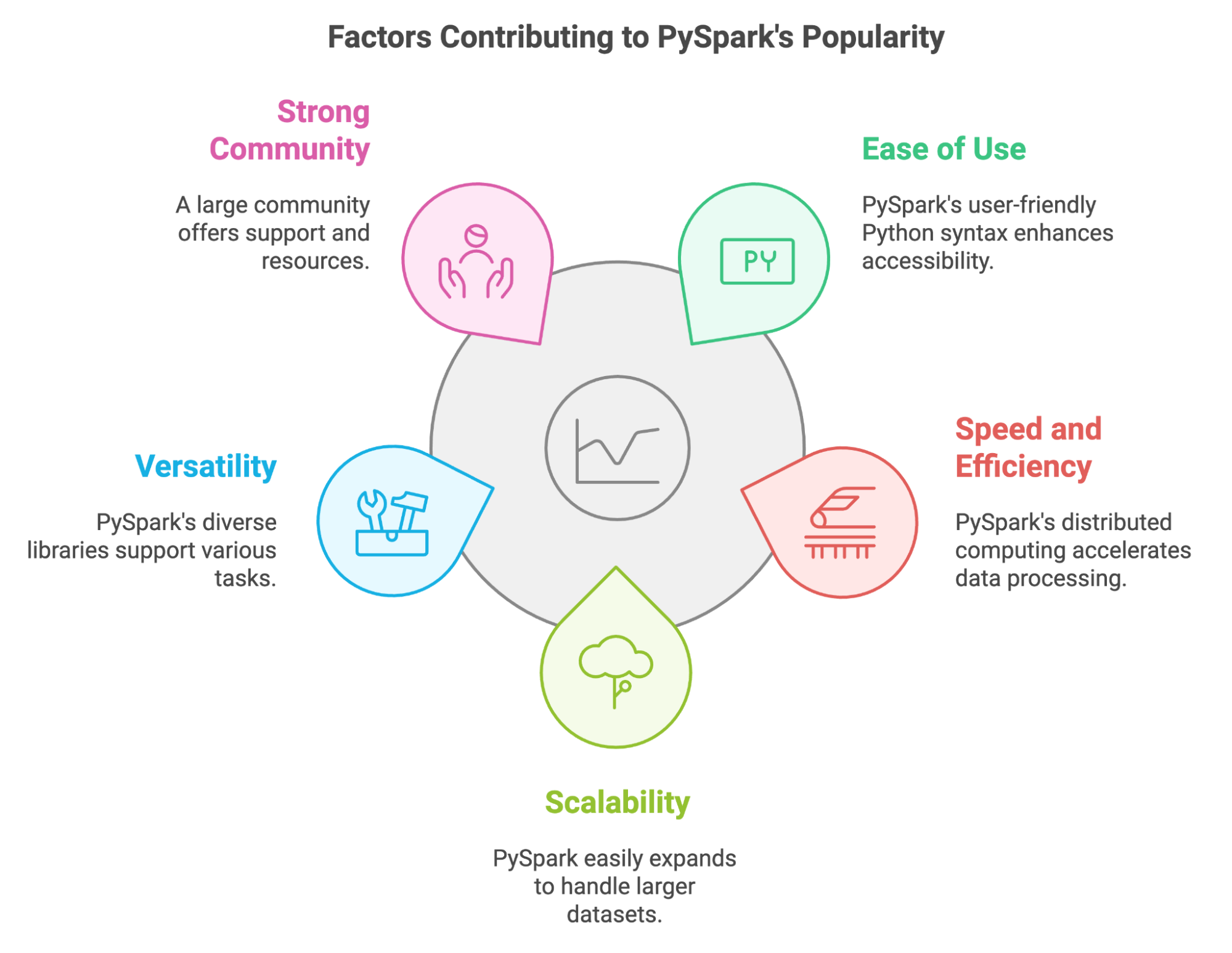
PySpark ci permette anche di sfruttare le competenze e le librerie già esistenti in Python. Possiamo integrarlo facilmente con strumenti popolari come Pandas e Scikit-learn, e consente di utilizzare diverse fonti di dati.
PySpark è stato creato appositamente per i big data e gli sviluppi di machine learning. Ma quali caratteristiche lo rendono uno strumento potente per gestire enormi quantità di dati? Diamo un'occhiata:
Il volume dei dati è in continua crescita. Oggi, data wrangling, analisi dei dati e attività di machine learning implicano il lavoro con grandi quantità di informazioni. Dobbiamo usare strumenti potenti che elaborino quei dati in modo efficiente e rapido. PySpark è tra questi strumenti.
Abbiamo già menzionato i punti di forza di PySpark, ma vediamo alcuni esempi specifici di dove puoi usarli:
Con l'ascesa della data science e del machine learning e l'aumento dei dati disponibili, c'è una forte domanda di professionisti con competenze di manipolazione dei dati. Secondo il The State of Data & AI Literacy Report 2024, l'80% dei leader valuta le competenze di analisi e manipolazione dei dati.
Imparare PySpark può aprire un'ampia gamma di opportunità di carriera. Oltre 800 offerte di lavoro su Indeed, dai data engineer ai data scientist, evidenziano la richiesta di competenze in PySpark nelle posizioni legate ai dati.
Se impari PySpark in modo metodico, hai più possibilità di successo. Concentrati su alcuni principi che puoi applicare nel tuo percorso di apprendimento.
Prima di passare ai dettagli tecnici, definisci la tua motivazione per imparare PySpark. Chiediti:
Dopo aver individuato i tuoi obiettivi, padroneggia le basi di PySpark e capisci come funzionano.
Poiché PySpark è costruito su Python, prima di usarlo devi familiarizzare con Python. Dovresti sentirti a tuo agio con variabili e funzioni. Inoltre, può essere utile conoscere librerie per la manipolazione dei dati come Pandas. I corsi di DataCamp Introduzione a Python e Data Manipulation with Pandas possono aiutarti a metterti in pari.
Devi installare PySpark per iniziare a usarlo. Puoi scaricarlo con pip o Conda, scaricarlo manualmente dal sito ufficiale oppure iniziare con DataLab per usare PySpark direttamente nel browser.
Se vuoi una spiegazione completa della configurazione di PySpark, consulta questa guida su come installare PySpark su Windows, Mac e Linux.
Il primo concetto da apprendere è come funzionano i DataFrame di PySpark. Sono uno dei motivi principali per cui PySpark è così veloce ed efficiente. Capisci come crearli, trasformarli (map e filter) e manipolarli. Il tutorial su come iniziare a lavorare con PySpark ti aiuterà con questi concetti.
Una volta che hai confidenza con le basi, è il momento di esplorare le competenze intermedie di PySpark.
Uno dei maggiori vantaggi di PySpark è la possibilità di eseguire query di tipo SQL per leggere e manipolare DataFrame, effettuare aggregazioni e usare funzioni finestra. Dietro le quinte, PySpark utilizza Spark SQL. Questa introduzione a Spark SQL in Python può aiutarti con questa competenza.
Lavorare con i dati significa diventare abili nel pulirli, trasformarli e prepararli per l'analisi. Ciò include la gestione dei valori mancanti, dei diversi tipi di dato e l'esecuzione di aggregazioni con PySpark. Segui il corso Cleaning Data with PySpark di DataCamp per fare pratica e padroneggiare queste abilità.
PySpark può essere usato anche per sviluppare e distribuire modelli di machine learning grazie alla sua libreria MLlib. Dovresti imparare a eseguire feature engineering, valutazione dei modelli e tuning degli iperparametri con questa libreria. Il corso di DataCamp Machine Learning with PySpark offre un'introduzione completa.
Seguire corsi ed esercitarti con PySpark è un ottimo modo per familiarizzare con la tecnologia. Tuttavia, per diventare davvero competente in PySpark, devi risolvere problemi sfidanti che fanno crescere le competenze, simili a quelli dei progetti reali. Puoi iniziare con semplici attività di analisi e passare gradualmente a sfide più complesse.
Ecco alcuni modi per esercitare le tue abilità:
Man mano che avanzi nel tuo percorso di apprendimento su PySpark, completerai diversi progetti. Per mostrare a potenziali datori di lavoro le tue competenze ed esperienza con PySpark, dovresti raccoglierli in un portfolio. Questo portfolio dovrebbe riflettere le tue abilità e i tuoi interessi ed essere allineato alla carriera o al settore che ti interessa.
Cerca di rendere i tuoi progetti originali e mostra le tue capacità di problem solving. Includi progetti che dimostrino la tua padronanza di vari aspetti di PySpark, come data wrangling, machine learning e data visualization. Documenta i progetti fornendo contesto, metodologia, codice e risultati. Puoi usare DataLab, un IDE online che ti consente di scrivere codice, analizzare dati in modo collaborativo e condividere i tuoi insight.
Ecco due progetti PySpark su cui puoi lavorare:
Imparare PySpark è un percorso continuo. La tecnologia evolve costantemente e nuove funzionalità e applicazioni vengono sviluppate regolarmente. PySpark non fa eccezione.
Una volta padroneggiate le basi, puoi cercare compiti e progetti più sfidanti come l'ottimizzazione delle prestazioni o GraphX. Rimani concentrato sui tuoi obiettivi e specializzati nelle aree rilevanti per i tuoi interessi e la tua carriera.
Rimani aggiornato sugli sviluppi e impara ad applicarli ai tuoi progetti attuali. Continua a esercitarti, cerca nuove sfide e opportunità e accetta l'idea di sbagliare come modo per imparare.
Ricapitoliamo i passaggi per un piano di apprendimento PySpark di successo:
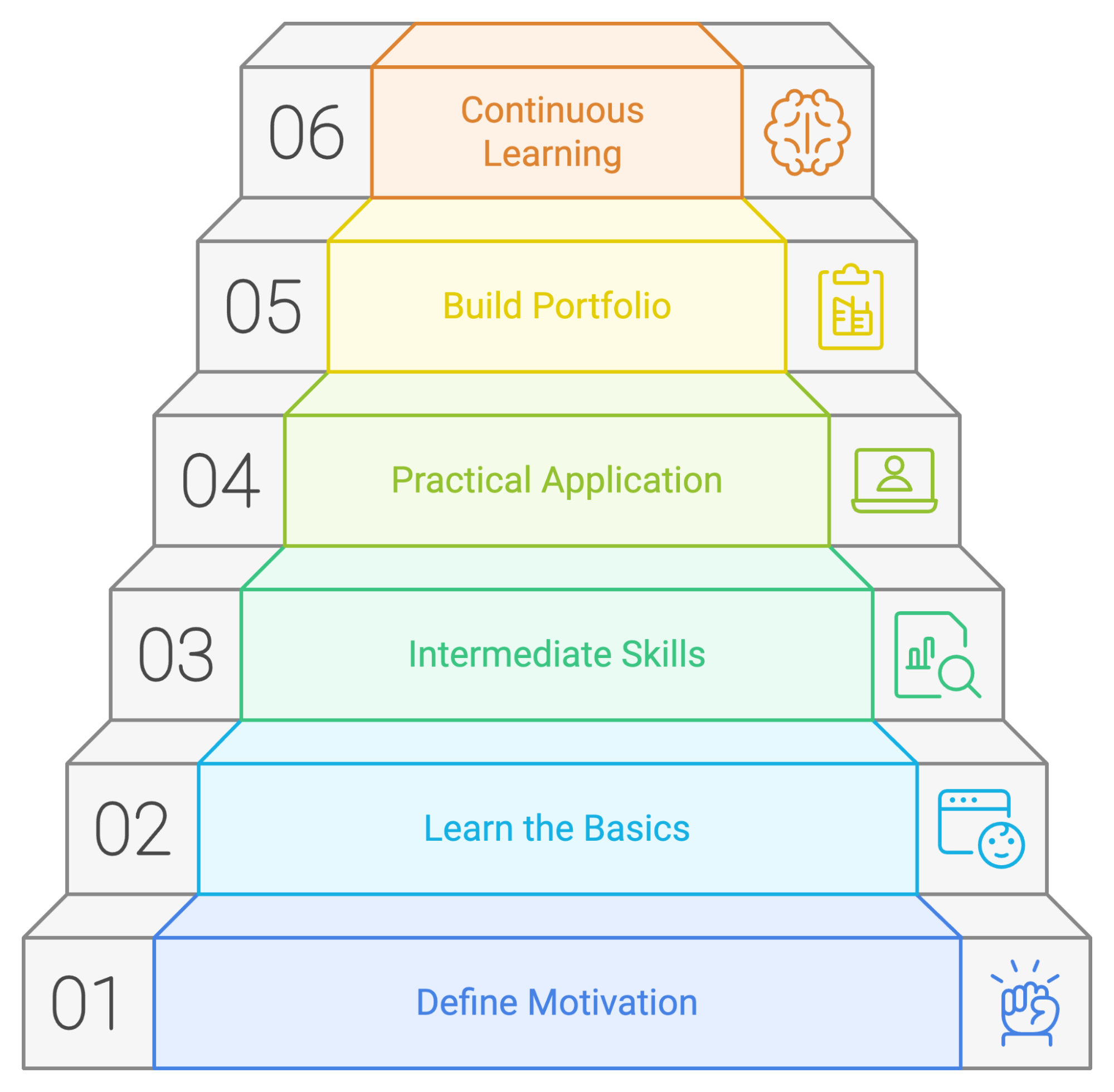
Anche se ognuno ha il proprio modo di imparare, è sempre una buona idea avere un piano o una guida da seguire per apprendere un nuovo strumento. Abbiamo creato un possibile piano di apprendimento che indica dove concentrare tempo ed energie se stai iniziando con PySpark.
Immagino che ormai tu sia pronto a tuffarti nell'apprendimento di PySpark e a mettere le mani su un grande dataset per esercitare la tua nuova competenza. Ma prima, lascia che evidenzi questi consigli che ti aiuteranno a percorrere la strada verso la padronanza di PySpark.
PySpark è uno strumento che può avere molte applicazioni diverse. Per mantenere il focus e raggiungere l'obiettivo, dovresti identificare la tua area di interesse. Vuoi concentrarti su analisi dei dati, data engineering o machine learning? Un approccio mirato ti aiuta a ottenere gli aspetti e le conoscenze più rilevanti di PySpark per il percorso scelto.
La costanza è la chiave per padroneggiare qualsiasi nuova competenza. Dovresti ritagliarti del tempo dedicato per esercitarti con PySpark. Anche poco ogni giorno va bene. Non serve affrontare concetti complessi quotidianamente. Puoi rivedere ciò che hai imparato o riprendere un esercizio semplice per rifattorizzarlo. La pratica regolare rafforzerà la comprensione dei concetti e aumenterà la fiducia nell'applicarli.
Questo è uno dei consigli chiave, e lo leggerai più volte in questa guida. Esercitarsi con gli esercizi è ottimo per prendere confidenza. Tuttavia, applicare le tue competenze PySpark a progetti reali è ciò che ti farà eccellere. Cerca dataset che ti interessano e usa PySpark per analizzarli, estrarre insight e risolvere problemi.
Inizia con progetti e domande semplici e passa gradualmente a quelli più complessi. Può essere qualcosa di semplice, come leggere e pulire un dataset reale e scrivere una query complessa per fare aggregazioni e prevedere il prezzo di una casa.
Spesso imparare insieme è più efficace. Condividere le esperienze e apprendere dagli altri può accelerare i tuoi progressi e offrire insight preziosi.
Per scambiare conoscenze, idee e domande, puoi unirti a gruppi legati a PySpark e partecipare a meet-up e conferenze. La Databricks Community, l'azienda fondata dai creatori di Spark, ha un forum attivo dove puoi discutere e fare domande su PySpark. Inoltre, lo Spark Summit, organizzato da Databricks, è la più grande conferenza su Spark.
Come per qualsiasi altra tecnologia, imparare PySpark è un processo iterativo. E imparare dai propri errori è una parte essenziale del percorso. Non avere paura di sperimentare, provare approcci diversi e imparare dagli errori. Prova funzioni e alternative diverse per aggregare i dati, esegui sottoquery o query annidate e osserva la rapidità di risposta che PySpark offre.
Vediamo alcuni metodi efficaci per imparare PySpark.
I corsi online sono un ottimo modo per imparare PySpark ai tuoi ritmi. DataCamp offre corsi PySpark per tutti i livelli, che insieme compongono il percorso Big Data with PySpark. I corsi coprono concetti introduttivi fino a temi di machine learning e sono progettati con esercizi pratici.
Ecco alcuni dei corsi su PySpark presenti su DataCamp:
I tutorial sono un altro ottimo modo per imparare PySpark, soprattutto se sei alle prime armi con la tecnologia. Contengono istruzioni passo passo su come eseguire compiti specifici o comprendere determinati concetti. Per iniziare, considera questi tutorial:
Le cheat sheet sono utili quando ti serve una guida rapida di riferimento su argomenti PySpark. Ecco due cheat sheet utili:
Imparare PySpark richiede pratica concreta. Affrontare sfide completando progetti ti permetterà di applicare tutte le competenze acquisite. Quando inizi a occuparti di compiti più complessi, dovrai trovare soluzioni e ricercare nuove alternative per ottenere i risultati desiderati, migliorando la tua esperienza con PySpark.
Cerca i progetti PySpark su cui lavorare su DataCamp. Ti permettono di applicare le tue competenze di manipolazione dei dati e di costruzione di modelli di machine learning sfruttando PySpark:
I libri sono un'ottima risorsa per imparare PySpark. Offrono conoscenze approfondite e insight da parte di esperti insieme a frammenti di codice e spiegazioni. Ecco alcuni dei libri più popolari su PySpark:
La domanda di competenze PySpark è aumentata in diversi ruoli legati ai dati, dai data analyst ai big data engineer. Se ti stai preparando per un colloquio, considera queste domande su PySpark per
Come big data engineer, sei l'architetto delle soluzioni big data, responsabile della progettazione, costruzione e manutenzione dell'infrastruttura che gestisce grandi dataset. Farai affidamento su PySpark per creare pipeline dati scalabili, garantendo un'acquisizione, un'elaborazione e un'archiviazione efficienti.
Ti servirà una solida comprensione del computing distribuito e delle piattaforme cloud, oltre a competenze in data warehousing e processi ETL.
Impara PySpark con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

