
Courses
Nền tảng về PySpark
4 giờ
157.6K
PySpark là sự kết hợp của hai công nghệ mạnh mẽ: Python và Apache Spark.
Python là một trong những ngôn ngữ lập trình được sử dụng nhiều nhất trong phát triển phần mềm, đặc biệt cho khoa học dữ liệu và machine learning, chủ yếu nhờ cú pháp dễ dùng và rõ ràng.
Mặt khác, Apache Spark là một framework có thể xử lý lượng lớn dữ liệu phi cấu trúc. Spark được xây dựng bằng Scala, một ngôn ngữ cho phép chúng ta kiểm soát nhiều hơn. Tuy nhiên, Scala không phổ biến trong giới làm dữ liệu. Vì vậy, PySpark ra đời để lấp đầy khoảng trống này.
PySpark cung cấp một API và giao diện thân thiện để tương tác với Spark. Nó tận dụng sự đơn giản và linh hoạt của Python để giúp việc xử lý dữ liệu lớn tiếp cận được với đông đảo người dùng hơn.
Những năm gần đây, PySpark đã trở thành công cụ quan trọng cho những người làm dữ liệu cần xử lý lượng dữ liệu khổng lồ. Có thể lý giải sự phổ biến của nó bằng một số yếu tố then chốt:
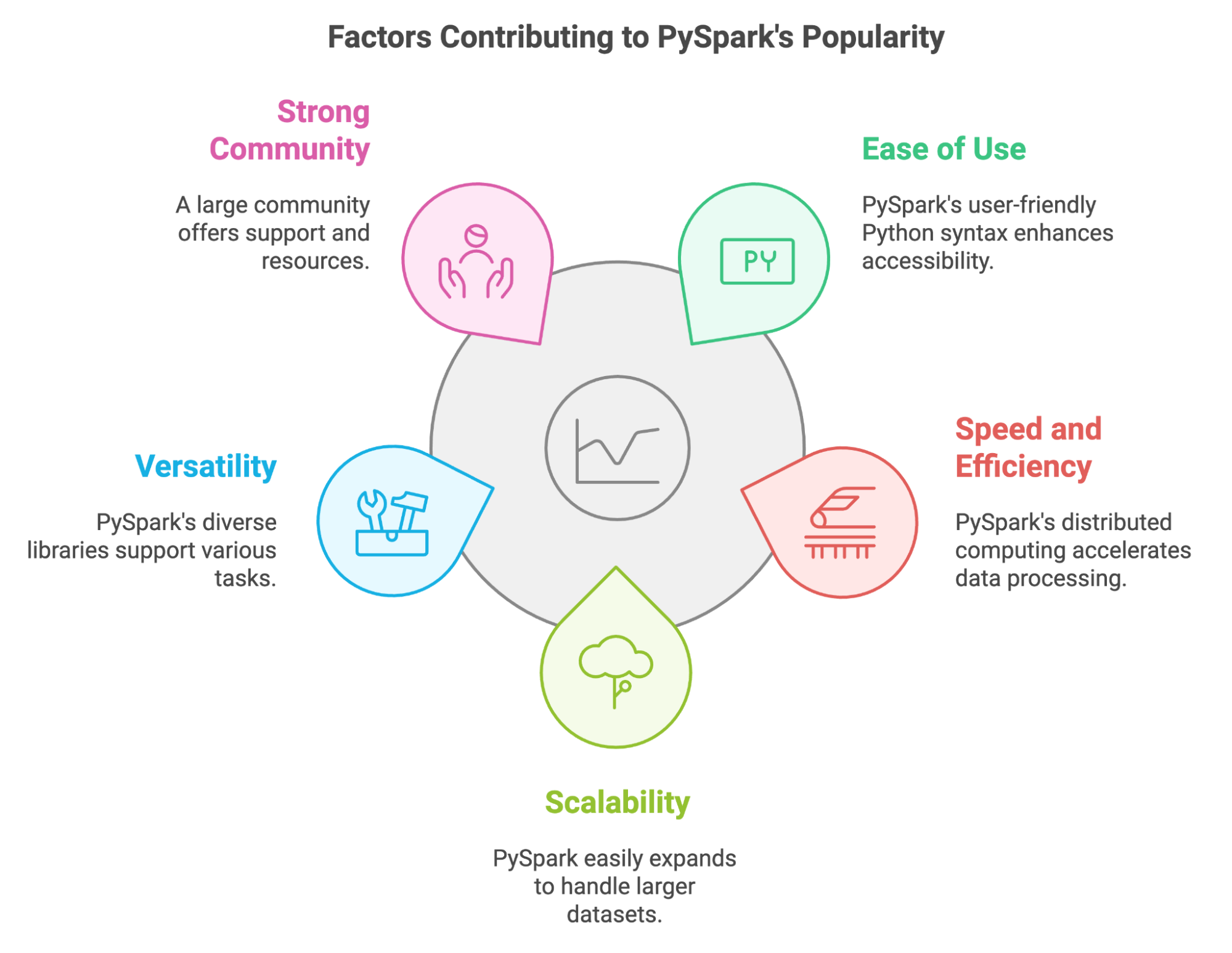
PySpark cũng cho phép chúng ta tận dụng kỹ năng và thư viện Python sẵn có. Bạn có thể dễ dàng tích hợp với các công cụ phổ biến như Pandas và Scikit-learn, và làm việc với nhiều nguồn dữ liệu khác nhau.
PySpark được tạo ra đặc biệt cho big data và các phát triển về machine learning. Nhưng những tính năng nào khiến nó trở thành công cụ mạnh để xử lý lượng dữ liệu khổng lồ? Hãy cùng xem:
Khối lượng dữ liệu chỉ có tăng lên. Ngày nay, các tác vụ xử lý dữ liệu, phân tích dữ liệu và machine learning đều liên quan đến làm việc với lượng dữ liệu lớn. Chúng ta cần dùng những công cụ mạnh mẽ để xử lý dữ liệu đó hiệu quả và kịp thời. PySpark là một trong số những công cụ như vậy.
Chúng ta đã đề cập đến điểm mạnh của PySpark, nhưng hãy xem một vài ví dụ cụ thể nơi bạn có thể áp dụng:
Với sự trỗi dậy của khoa học dữ liệu và machine learning cùng lượng dữ liệu gia tăng, nhu cầu về các chuyên gia có kỹ năng thao tác dữ liệu rất cao. Theo Báo cáo State of Data & AI Literacy 2024, 80% lãnh đạo đánh giá cao kỹ năng phân tích và thao tác dữ liệu.
Học PySpark có thể mở ra nhiều cơ hội nghề nghiệp. Hơn 800 tin tuyển dụng trên Indeed, từ kỹ sư dữ liệu đến nhà khoa học dữ liệu, nhấn mạnh nhu cầu thành thạo PySpark trong các vị trí liên quan đến dữ liệu.
Nếu học PySpark một cách có phương pháp, bạn sẽ có nhiều cơ hội thành công hơn. Hãy tập trung vào một vài nguyên tắc bạn có thể dùng trong hành trình học tập.
Trước khi đi vào chi tiết kỹ thuật, hãy xác định động lực của bạn khi học PySpark. Tự hỏi bản thân:
Sau khi xác định mục tiêu, hãy nắm vững các kiến thức nền tảng của PySpark và cách chúng hoạt động.
Vì PySpark được xây dựng trên Python, bạn cần quen thuộc với Python trước khi dùng PySpark. Bạn nên thoải mái khi làm việc với biến và hàm. Ngoài ra, sẽ hữu ích nếu bạn quen với các thư viện thao tác dữ liệu như Pandas. Khóa Nhập môn Python và Xử lý dữ liệu với Pandas của DataCamp có thể giúp bạn bắt kịp nhanh.
Bạn cần cài đặt PySpark để bắt đầu sử dụng. Bạn có thể tải PySpark bằng pip hoặc Conda, tải thủ công từ trang chính thức, hoặc bắt đầu với DataLab để dùng PySpark ngay trên trình duyệt.
Nếu bạn muốn hướng dẫn đầy đủ cách thiết lập PySpark, hãy xem bài hướng dẫn cách cài đặt PySpark trên Windows, Mac và Linux.
Khái niệm đầu tiên bạn nên học là cách DataFrame của PySpark hoạt động. Đây là một trong những lý do chính khiến PySpark hoạt động nhanh và hiệu quả. Hãy hiểu cách tạo, biến đổi (map và filter) và thao tác với chúng. Bài hướng dẫn bắt đầu làm việc với PySpark sẽ giúp bạn nắm các khái niệm này.
Khi đã thoải mái với nền tảng, đã đến lúc khám phá các kỹ năng PySpark ở mức trung cấp.
Một trong những ưu điểm lớn của PySpark là khả năng thực hiện các truy vấn kiểu SQL để đọc và thao tác DataFrame, thực hiện tổng hợp và dùng window function. Phía sau, PySpark dùng Spark SQL. Khóa nhập môn Spark SQL bằng Python có thể giúp bạn kỹ năng này.
Làm việc với dữ liệu đòi hỏi thành thạo việc làm sạch, biến đổi và chuẩn bị dữ liệu cho phân tích. Điều này bao gồm xử lý giá trị khuyết, quản lý các kiểu dữ liệu khác nhau, và thực hiện các phép tổng hợp bằng PySpark. Hãy học khóa Làm sạch dữ liệu với PySpark của DataCamp để có kinh nghiệm thực hành và làm chủ các kỹ năng này.
PySpark cũng có thể được dùng để phát triển và triển khai mô hình machine learning nhờ thư viện MLlib. Bạn nên học cách thực hiện kỹ thuật đặc trưng, đánh giá mô hình và tinh chỉnh siêu tham số bằng thư viện này. Khóa Machine Learning với PySpark của DataCamp cung cấp phần giới thiệu toàn diện.
Tham gia các khóa học và luyện tập bài tập với PySpark là cách tuyệt vời để làm quen với công nghệ. Tuy vậy, để thành thạo PySpark, bạn cần giải quyết những vấn đề thách thức và bồi dưỡng kỹ năng, giống như những gì bạn sẽ gặp trong các dự án thực tế. Hãy bắt đầu bằng những tác vụ phân tích dữ liệu đơn giản và dần chuyển sang các thử thách phức tạp hơn.
Dưới đây là vài cách để rèn luyện kỹ năng:
Khi tiến xa hơn trong hành trình học PySpark, bạn sẽ hoàn thành nhiều dự án khác nhau. Để phô diễn kỹ năng và kinh nghiệm PySpark với nhà tuyển dụng tiềm năng, bạn nên tổng hợp chúng thành một danh mục. Danh mục này cần phản ánh kỹ năng và sở thích của bạn, đồng thời phù hợp với sự nghiệp hoặc ngành mà bạn quan tâm.
Hãy cố gắng làm dự án có tính riêng và thể hiện kỹ năng giải quyết vấn đề. Bao gồm các dự án chứng minh năng lực ở nhiều khía cạnh của PySpark như tiền xử lý dữ liệu, machine learning và trực quan hóa dữ liệu. Ghi chép dự án, cung cấp bối cảnh, phương pháp, mã và kết quả. Bạn có thể dùng DataLab, một IDE trực tuyến cho phép bạn viết mã, phân tích dữ liệu cộng tác và chia sẻ insight.
Dưới đây là hai dự án PySpark bạn có thể làm:
Học PySpark là một hành trình liên tục. Công nghệ luôn phát triển và các tính năng, ứng dụng mới được ra mắt thường xuyên. PySpark cũng không ngoại lệ.
Khi đã nắm vững nền tảng, bạn có thể tìm các tác vụ và dự án thách thức hơn như tối ưu hiệu năng hoặc GraphX. Tập trung vào mục tiêu và chuyên sâu ở các mảng phù hợp với định hướng và sở thích nghề nghiệp của bạn.
Luôn cập nhật các phát triển mới và học cách áp dụng chúng vào dự án hiện tại. Tiếp tục luyện tập, tìm kiếm thử thách và cơ hội mới, và chấp nhận việc mắc lỗi như một cách để học.
Hãy cùng điểm lại các bước để có một kế hoạch học PySpark thành công:
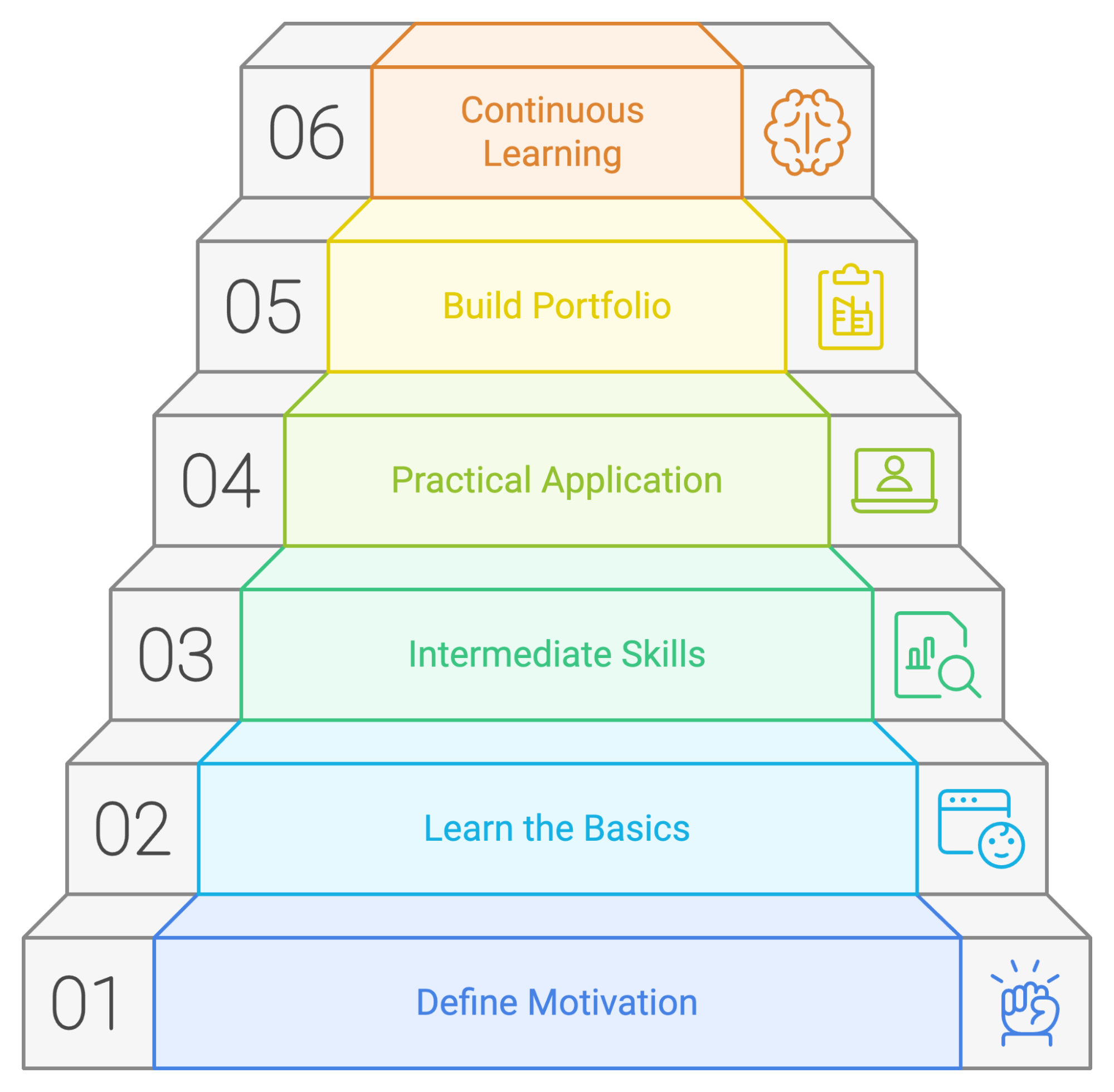
Dù mỗi người có cách học riêng, việc có một kế hoạch hoặc lộ trình để theo khi học công cụ mới luôn hữu ích. Chúng tôi đã xây dựng một kế hoạch học tiềm năng nêu rõ nơi bạn nên tập trung thời gian và công sức nếu bạn mới bắt đầu với PySpark.
Tôi hình dung đến lúc này bạn đã sẵn sàng bắt tay vào học PySpark và thực hành trên một tập dữ liệu lớn. Nhưng trước đó, hãy điểm qua những mẹo sẽ giúp bạn đi nhanh hơn trên con đường thành thạo PySpark.
PySpark là công cụ có thể ứng dụng vào nhiều việc khác nhau. Để giữ tập trung và đạt mục tiêu, bạn nên xác định mảng quan tâm. Bạn muốn tập trung vào phân tích dữ liệu, kỹ thuật dữ liệu hay machine learning? Cách tiếp cận có trọng tâm sẽ giúp bạn học những khía cạnh và kiến thức liên quan nhất của PySpark cho con đường bạn chọn.
Tính đều đặn là chìa khóa để làm chủ kỹ năng mới. Bạn nên dành thời gian cố định để luyện PySpark. Chỉ cần một khoảng thời gian ngắn mỗi ngày là được. Không cần mỗi ngày đều học khái niệm phức tạp; bạn có thể ôn lại những gì đã học hoặc làm lại một bài tập đơn giản để refactor. Luyện tập thường xuyên sẽ củng cố hiểu biết và xây dựng sự tự tin khi áp dụng.
Đây là một mẹo then chốt và bạn sẽ gặp lại nhiều lần trong hướng dẫn này. Luyện bài tập giúp bạn tự tin, nhưng áp dụng kỹ năng PySpark vào dự án thực tế mới là điều giúp bạn vượt trội. Hãy tìm các bộ dữ liệu bạn hứng thú và dùng PySpark để phân tích, rút ra insight và giải quyết vấn đề.
Bắt đầu với dự án và câu hỏi đơn giản rồi dần nâng độ phức tạp. Đơn giản như đọc và làm sạch một bộ dữ liệu thực, viết truy vấn phức tạp để tổng hợp và dự đoán giá nhà.
Học tập thường hiệu quả hơn khi có sự cộng tác. Chia sẻ trải nghiệm và học hỏi từ người khác có thể tăng tốc tiến bộ và mang lại insight giá trị.
Để trao đổi kiến thức, ý tưởng và câu hỏi, bạn có thể tham gia các nhóm liên quan đến PySpark, tham dự meet-up và hội thảo. Cộng đồng Databricks, công ty do những người sáng lập Spark thành lập, có diễn đàn sôi động để thảo luận và đặt câu hỏi về PySpark. Ngoài ra, Spark Summit do Databricks tổ chức là hội nghị Spark lớn nhất.
Giống như bất kỳ công nghệ nào khác, học PySpark là quá trình lặp. Và học từ sai lầm là phần thiết yếu. Đừng ngại thử nghiệm, thử cách tiếp cận khác nhau và rút kinh nghiệm từ lỗi. Thử các hàm và phương án tổng hợp dữ liệu khác nhau, thực hiện truy vấn lồng hoặc con, và quan sát phản hồi nhanh mà PySpark mang lại.
Hãy cùng điểm qua một vài phương pháp hiệu quả để học PySpark.
Các khóa học trực tuyến là cách tuyệt vời để học PySpark theo tốc độ của bạn. DataCamp cung cấp khóa học PySpark cho mọi cấp độ, hợp thành lộ trình Big Data với PySpark. Các khóa học bao quát từ khái niệm nhập môn đến chủ đề machine learning và được thiết kế với bài tập thực hành.
Một số khóa học liên quan đến PySpark trên DataCamp:
Các tutorial là cách tuyệt vời khác để học PySpark, đặc biệt nếu bạn mới. Chúng có hướng dẫn từng bước để thực hiện tác vụ cụ thể hoặc hiểu một số khái niệm. Khởi đầu, hãy tham khảo các bài này:
Cheat sheet rất hữu ích khi bạn cần tài liệu tham khảo nhanh về PySpark. Dưới đây là hai cheat sheet hữu ích:
Học PySpark cần thực hành trực tiếp. Đối mặt với thử thách khi làm các dự án sẽ cho phép bạn áp dụng mọi kỹ năng đã học. Khi đảm nhiệm các tác vụ phức tạp hơn, bạn sẽ cần tìm giải pháp và nghiên cứu phương án mới để đạt kết quả mong muốn, qua đó nâng cao chuyên môn PySpark.
Tìm các dự án PySpark trên DataCamp để thực hành. Chúng cho phép bạn áp dụng kỹ năng thao tác dữ liệu và xây dựng mô hình machine learning với PySpark:
Sách là nguồn tuyệt vời để học PySpark. Chúng cung cấp kiến thức chuyên sâu và góc nhìn từ chuyên gia kèm đoạn mã và giải thích. Dưới đây là một số sách phổ biến về PySpark:
Nhu cầu về kỹ năng PySpark đã tăng lên ở nhiều vai trò liên quan đến dữ liệu, từ nhà phân tích dữ liệu đến kỹ sư big data. Nếu bạn đang chuẩn bị phỏng vấn, hãy cân nhắc các câu hỏi phỏng vấn PySpark cho
Với vai trò kỹ sư big data, bạn là kiến trúc sư của các giải pháp big data, chịu trách nhiệm thiết kế, xây dựng và duy trì hạ tầng xử lý các tập dữ liệu lớn. Bạn sẽ dựa vào PySpark để tạo pipeline dữ liệu có khả năng mở rộng, bảo đảm nạp, xử lý và lưu trữ dữ liệu hiệu quả.
Bạn sẽ cần hiểu biết vững về điện toán phân tán và nền tảng đám mây, cùng chuyên môn về kho dữ liệu và quy trình ETL.
Học PySpark với các khóa học này!
Courses
Courses
Courses