
Kurs
Einführung in PySpark
4 Std.
157.5K
PySpark ist die Kombination aus zwei starken Technologien: Python und Apache Spark.
Python ist eine der beliebtesten Programmiersprachen in der Softwareentwicklung, vor allem für Data Science und maschinelles Lernen, weil sie einfach zu benutzen ist und eine klare Syntax hat.
Apache Spark ist dagegen ein Framework, das große Mengen unstrukturierter Daten verarbeiten kann. Spark wurde mit Scala entwickelt, einer Sprache, die uns mehr Kontrolle darüber gibt. Scala ist bei Datenfachleuten aber nicht so beliebt. Also wurde PySpark entwickelt, um diese Lücke zu schließen.
PySpark hat eine API und eine einfache Benutzeroberfläche, um mit Spark zu arbeiten. Es nutzt die Einfachheit und Flexibilität von Python, um die Verarbeitung von Big Data für mehr Leute zugänglich zu machen.
In den letzten Jahren hat sich PySpark zu einem wichtigen Tool für Leute entwickelt, die mit riesigen Datenmengen arbeiten müssen. Wir können seine Beliebtheit mit ein paar wichtigen Sachen erklären:
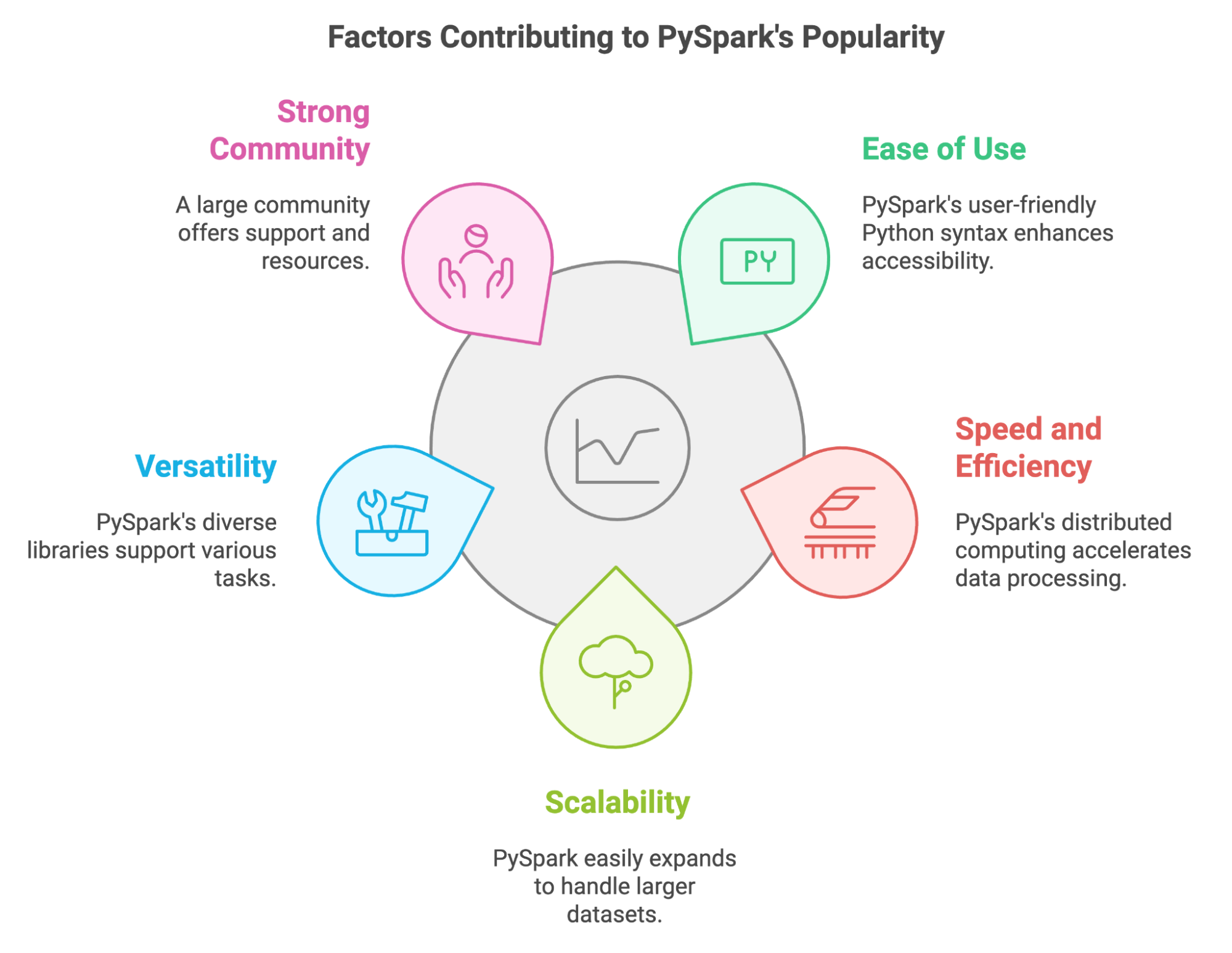
Mit PySpark können wir auch unsere vorhandenen Python-Kenntnisse und -Bibliotheken nutzen. Wir können es ganz einfach mit beliebten Tools wie Pandas und Scikit-learn, und es lässt uns verschiedene Datenquellen nutzen.
PySpark wurde extra für Big-Data- und Machine-Learning-Entwicklungen entwickelt worden. Aber welche Funktionen machen es zu einem starken Tool für die Bearbeitung riesiger Datenmengen? Schauen wir sie uns mal an:
Die Datenmenge wird immer größer. Heutzutage geht's bei Datenverarbeitung, Datenanalyse und maschinellem Lernen darum, mit riesigen Datenmengen zu arbeiten. Wir brauchen starke Tools, die diese Daten schnell und effizient verarbeiten. PySpark ist eins dieser Tools.
Wir haben schon die Vorteile von PySpark angesprochen, aber schauen wir uns mal ein paar konkrete Beispiele an, wo du sie nutzen kannst:
Mit dem Aufkommen von Datenwissenschaft und maschinellem Lernen und der Zunahme verfügbarer Daten gibt's eine hohe Nachfrage nach Fachleuten mit Datenbearbeitung. Laut dem Bericht „The State of Data & AI Literacy Report 2024”schätzen 80 % der Führungskräfte Fähigkeiten in der Datenanalyse und -bearbeitung.
Das Lernen von PySpark kann dir viele neue Jobchancen bringen. Über 800 Stellenangebote auf Indeed, von Dateningenieuren bis hin zu Datenwissenschaftlern, zeigen, wie gefragt PySpark-Kenntnisse in der Datenbranche sind. Stellenangeboten im Datenbereich.
Wenn du PySpark systematisch lernst, hast du bessere Chancen auf Erfolg. Schauen wir uns ein paar Prinzipien an, die du auf deinem Lernweg nutzen kannst.
Bevor du dich mit den technischen Details beschäftigst, überleg dir, warum du PySpark lernen willst. Frag dich mal:
Nachdem du deine Ziele festgelegt hast, lerne die Grundlagen von PySpark und wie sie funktionieren.
Da PySpark auf Python basiert, solltest du dich erst mal mit Python auskennen, bevor du PySpark benutzt. Du solltest dich mit Variablen und Funktionen gut auskennen. Außerdem könnte es hilfreich sein, sich mit Bibliotheken zur Datenbearbeitung wie Pandas auszukennen. DataCamps Einführungskurs in Python und Datenbearbeitung mit Pandas können dir helfen, dich schnell einzuarbeiten.
Du musst PySpark installieren, um es nutzen zu können. Du kannst PySpark mit pip oder Conda runterladen, es manuell von der offiziellen Website holen oder mit DataLab an, um PySpark in deinem Browser auszuprobieren.
Wenn du eine ausführliche Erklärung zur Einrichtung von PySpark brauchst, schau dir diese Anleitung zur die Installation von PySpark unter Windows, Mac und Linux.
Das erste Konzept, das du lernen solltest, ist, wie PySpark DataFrames funktionieren. Sie sind einer der Hauptgründe, warum PySpark so schnell und effizient läuft. Lerne, wie du sie erstellen, umwandeln (zuordnen und filtern) und bearbeiten kannst. Das Tutorial zum Thema die ersten Schritte mit PySpark hilft dir bei diesen Konzepten.
Sobald du mit den Grundlagen vertraut bist, kannst du dich mit den fortgeschrittenen PySpark-Fähigkeiten beschäftigen.
Einer der größten Vorteile von PySpark ist, dass man damit SQL-ähnliche Abfragen machen kann, um DataFrame zu lesen und zu bearbeiten, Aggregationen durchzuführen und Fensterfunktionen zu nutzen. Hinter den Kulissen nutzt PySpark Spark SQL. Das ist Einführung in Spark SQL in Python kann dir dabei helfen, diese Fähigkeit zu erlernen.
Mit Daten zu arbeiten heißt, dass man sie richtig bereinigen, umwandeln und für die Analyse vorbereiten kann. Dazu gehört, mit fehlenden Werten umzugehen, verschiedene Datentypen zu verwalten und Aggregationen mit PySpark durchzuführen. Mach den Kurs „Datenbereinigung mit PySpark” von DataCamp, um praktische Erfahrungen zu sammeln und diese Fähigkeiten zu meistern.
PySpark kann dank seiner MLlib-Bibliothek auch zum Entwickeln und Bereitstellen von Machine-Learning-Modellen genutzt werden. Du solltest lernen, wie man mit dieser Bibliothek Feature Engineering, Modellbewertung und Hyperparameter-Tuning macht. DataCamps Kurs „Machine Learning mit PySpark” bietet eine umfassende Einführung.
Kurse zu besuchen und Übungen mit PySpark zu machen, ist echt eine super Möglichkeit, um sich mit der Technologie vertraut zu machen. Um PySpark richtig gut zu beherrschen, musst du aber knifflige Probleme lösen, die deine Fähigkeiten fördern, so wie du sie auch in echten Projekten findest. Du kannst mit einfachen Datenanalyseaufgaben anfangen und dich dann nach und nach an komplexere Herausforderungen ranwagen.
Hier sind ein paar Möglichkeiten, deine Fähigkeiten zu trainieren:
Während du dich weiter durch deine PySpark-Lernreise bewegst, wirst du verschiedene Projekte abschließen. Um potenziellen Arbeitgebern deine PySpark-Kenntnisse und -Erfahrungen zu zeigen, solltest du sie in einem Portfolio zusammenfassen. Dieses Portfolio sollte deine Fähigkeiten und Interessen zeigen und auf den Job oder die Branche zugeschnitten sein, die dich interessieren.
Mach deine Projekte originell und zeig, wie gut du Probleme lösen kannst. Zeig Projekte, die zeigen, wie gut du dich mit verschiedenen Aspekten von PySpark auskennst, wie zum Beispiel Datenaufbereitung, maschinelles Lernen und Datenvisualisierung. Dokumentiere deine Projekte und gib dabei den Kontext, die Methodik, den Code und die Ergebnisse an. Du kannst DataLabverwenden, eine Online-IDE, mit der du Code schreiben, Daten gemeinsam analysieren und deine Erkenntnisse teilen kannst.
Hier sind zwei PySpark-Projekte, an denen du arbeiten kannst:
PySpark zu lernen ist ein ständiger Prozess. Die Technik entwickelt sich ständig weiter, und es kommen immer wieder neue Funktionen und Anwendungen dazu. PySpark ist da keine Ausnahme.
Sobald du die Grundlagen drauf hast, kannst du dich an anspruchsvollere Aufgaben und Projekte wie Performance-Optimierung oder GraphX wagen. Konzentrier dich auf deine Ziele und spezialisier dich auf Bereiche, die für deine Karrierepläne und Interessen wichtig sind.
Bleib auf dem Laufenden über die neuesten Entwicklungen und lerne, wie du sie in deinen aktuellen Projekten anwenden kannst. Mach weiter so, such dir neue Herausforderungen und Chancen und sieh Fehler als Chance, um was Neues zu lernen.
Lass uns mal zusammenfassen, was wir für einen erfolgreichen PySpark-Lernplan machen können:
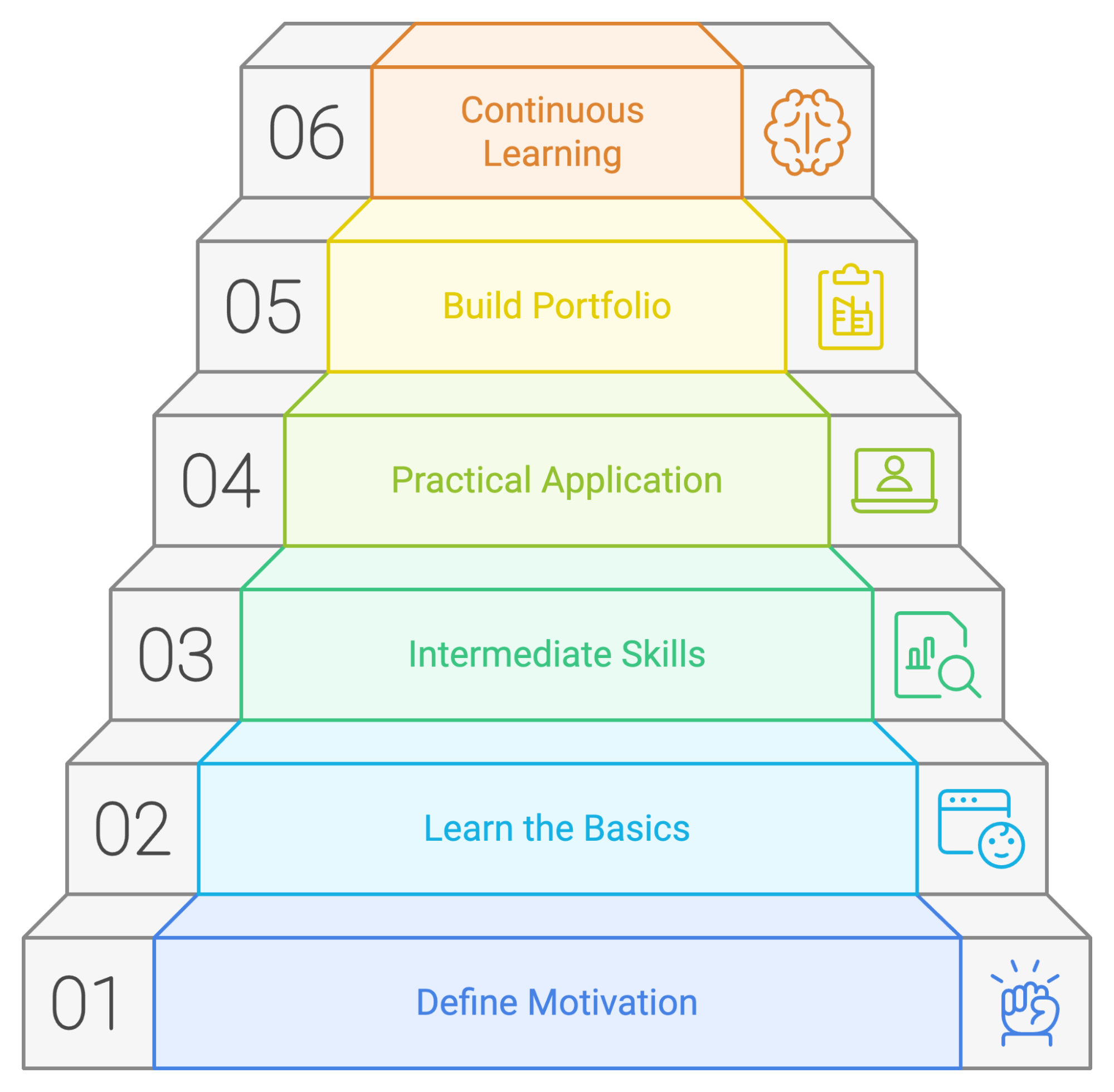
Auch wenn jeder Mensch seine eigene Art zu lernen hat, ist es immer gut, einen Plan oder Leitfaden zu haben, an dem man sich beim Erlernen eines neuen Tools orientieren kann. Wir haben einen möglichen Lernplan erstellt, der zeigt, worauf du dich konzentrieren solltest, wenn du gerade erst mit PySpark anfängst.
Ich denke, du bist jetzt bereit, dich mit PySpark zu beschäftigen und dich mit einem großen Datensatz zu beschäftigen, um deine neuen Fähigkeiten auszuprobieren. Bevor du das machst, lass mich dir noch ein paar Tipps geben, die dir helfen werden, den Weg zur PySpark-Kompetenz zu meistern.
PySpark ist ein Tool, das man für viele verschiedene Sachen nutzen kann. Um fokussiert zu bleiben und dein Ziel zu erreichen, solltest du herausfinden, was dich wirklich interessiert. Willst du dich auf Datenanalyse, Datenverarbeitung oder maschinelles Lernen konzentrieren? Wenn du dich auf das Wesentliche konzentrierst, kannst du die wichtigsten Aspekte und Kenntnisse von PySpark für deinen gewählten Weg besser verstehen.
Um eine neue Fähigkeit richtig zu lernen, ist es wichtig, dranzubleiben. Du solltest dir Zeit nehmen, um PySpark zu üben. Ein bisschen Zeit jeden Tag reicht schon. Du musst dich nicht jeden Tag mit komplizierten Sachen rumschlagen. Du kannst das Gelernte wiederholen oder eine einfache Übung noch mal machen, um sie zu überarbeiten. Regelmäßiges Üben hilft dir, Konzepte besser zu verstehen und macht dich sicherer bei ihrer Anwendung.
Das ist einer der wichtigsten Tipps, und du wirst ihn in diesem Leitfaden mehrmals lesen. Übungen zu machen ist super, um Selbstvertrauen zu gewinnen. Aber erst wenn du deine PySpark-Kenntnisse in echten Projekten anwendest, wirst du richtig gut darin. Such dir Datensätze, die dich interessieren, und nutze PySpark, um sie zu analysieren, Erkenntnisse zu gewinnen und Probleme zu lösen.
Fang mit einfachen Projekten und Fragen an und mach dich dann nach und nach an komplexere Sachen ran. Das kann so einfach sein wie das Lesen und Bereinigen eines echten Datensatzes und das Schreiben einer komplexen Abfrage, um Aggregationen durchzuführen und den Preis eines Hauses vorherzusagen.
Gemeinsam lernt man oft besser. Wenn du deine Erfahrungen teilst und von anderen lernst, kannst du schneller vorankommen und wertvolle Einblicke gewinnen.
Um Wissen, Ideen und Fragen auszutauschen, kannst du Gruppen beitreten, die sich mit PySpark beschäftigen, und an Treffen und Konferenzen teilnehmen. Die Databricks-Community, die Firma, die von den Machern von Spark gegründet wurde, hat ein aktives Community-Forum, wo du dich an Diskussionen beteiligen und Fragen zu PySpark stellen kannst. Außerdem ist der Spark Summit, den Databricks organisiert, die größte Spark-Konferenz.
Wie bei jeder anderen Technologie ist auch das Lernen von PySpark ein schrittweiser Prozess. Und aus Fehlern zu lernen ist ein wichtiger Teil des Lernprozesses. Hab keine Angst davor, zu experimentieren, verschiedene Ansätze auszuprobieren und aus deinen Fehlern zu lernen. Probier verschiedene Funktionen und Alternativen zum Aggregieren der Daten aus, mach Unterabfragen oder verschachtelte Abfragen und schau dir die schnelle Antwort von PySpark an.
Schauen wir uns mal ein paar coole Methoden an, um PySpark zu lernen.
Online-Kurse sind super, um PySpark in deinem eigenen Tempo zu lernen. DataCamp hat PySpark-Kurse für alle Niveaus, die zusammen das Big Data mit PySpark Lernpfad. Die Kurse behandeln einführende Konzepte zu Themen des maschinellen Lernens und sind mit praktischen Übungen ausgestattet.
Hier sind ein paar der PySpark-Kurse auf DataCamp:
Tutorials sind auch super, um PySpark zu lernen, vor allem wenn du noch keine Erfahrung mit der Technologie hast. Sie haben Schritt-für-Schritt-Anleitungen, wie man bestimmte Aufgaben macht oder bestimmte Konzepte versteht. Schau dir mal diese Tutorials an:
Spickzettel sind echt praktisch, wenn du schnell was zu PySpark-Themen nachschlagen willst. Hier sind zwei hilfreiche Spickzettel:
PySpark zu lernen braucht einfach praktische Übung. Du stellst dich Herausforderungen bei der Umsetzung von Projekten, bei denen du all deine erworbenen Fähigkeiten anwenden kannst. Wenn du anfängst, dich mit komplexeren Aufgaben zu beschäftigen, musst du Lösungen finden und neue Alternativen ausprobieren, um die gewünschten Ergebnisse zu erzielen und deine PySpark-Kenntnisse zu verbessern.
Schau mal bei DataCamp nach PySpark-Projekten, an denen du arbeiten kannst. Damit kannst du deine Fähigkeiten in der Datenbearbeitung und beim Erstellen von Machine-Learning-Modellen mit PySpark anwenden:
Bücher sind echt super, um PySpark zu lernen. Sie bieten fundiertes Wissen und Einblicke von Experten sowie Code-Schnipsel und Erklärungen. Hier sind ein paar der beliebtesten Bücher über PySpark:
Die Nachfrage nach PySpark-Kenntnissen ist in vielen datenbezogenen Jobs gestiegen, von Datenanalysten bis hin zu Big-Data-Ingenieuren. Wenn du dich auf ein Vorstellungsgespräch vorbereitest, solltest du diese PySpark-Interviewfragen berücksichtigen:
Als Big-Data-Ingenieur bist du der Architekt von Big-Data-Lösungen und dafür zuständig, die Infrastruktur zu entwerfen, aufzubauen und zu warten, die große Datensätze verarbeitet. Du wirst PySpark nutzen, um skalierbare Datenpipelines zu erstellen, die eine effiziente Datenerfassung, -verarbeitung und -speicherung sicherstellen.
Du brauchst ein gutes Verständnis von verteilten Rechensystemen und Cloud-Plattformen sowie Fachwissen in den Bereichen Data Warehousing und ETL-Prozesse.
Unsere Zertifizierungsprogramme helfen dir, dich von anderen abzuheben und potenziellen Arbeitgebern zu beweisen, dass deine Fähigkeiten für den Job geeignet sind.

Lerne PySpark mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Matt Crabtree
14 Min.
Tutorial
Matt Crabtree
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Laiba Siddiqui
