
Cours
Introduction à PySpark
4 h
157.5K
PySpark est la combinaison de deux technologies performantes : Python et Apache Spark.
Python est l'un des langages de programmation les plus utilisés dans le développement de logiciels, en particulier pour la science des données et l'apprentissage automatique, principalement en raison de sa syntaxe simple et conviviale.
D'autre part, Apache Spark est un framework capable de traiter de grandes quantités de données non structurées. Spark a été développé à l'aide de Scala, un langage qui nous offre un plus grand contrôle sur le système. Cependant, Scala n'est pas un langage de programmation très répandu parmi les professionnels des données. PySpark a donc été créé pour combler cette lacune.
PySpark fournit une API et une interface conviviale pour interagir avec Spark. Il exploite la simplicité et la flexibilité de Python pour rendre le traitement des mégadonnées accessible à un public plus large.
Ces dernières années, PySpark est devenu un outil essentiel pour les professionnels des données qui doivent traiter d'énormes quantités de données. Nous pouvons expliquer sa popularité par plusieurs facteurs clés :
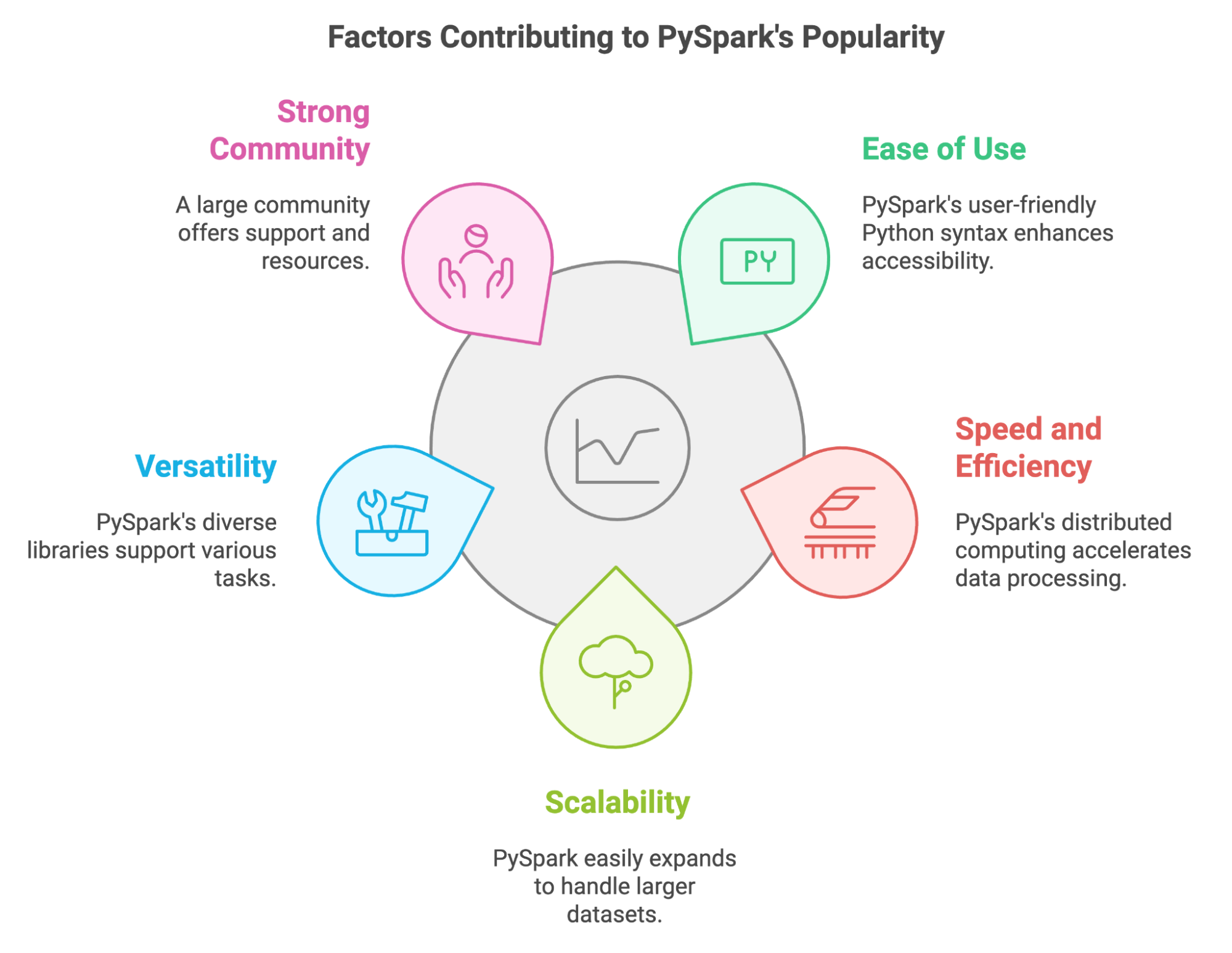
PySpark nous permet également de tirer parti des compétences et des bibliothèques Python existantes. Nous pouvons facilement l'intégrer à des outils populaires tels que Pandas et Scikit-learn, et il nous permet d'utiliser diverses sources de données.
PySpark a été spécialement conçu pour le traitement des mégadonnées. le big data et le machine learning. Quelles sont les fonctionnalités qui en font un outil performant pour traiter de grandes quantités de données ? Examinons-les :
Le volume de données ne cesse d'augmenter. De nos jours, les tâches de traitement et d'analyse des données, ainsi que d'apprentissage automatique, impliquent de travailler avec de grandes quantités de données. Il est nécessaire d'utiliser des outils performants qui traitent ces données de manière efficace et rapide. PySpark est l'un de ces outils.
Nous avons déjà évoqué les points forts de PySpark, mais examinons quelques exemples concrets d'utilisation :
Avec l'essor de la science des données et de l'apprentissage automatique, ainsi que l'augmentation des données disponibles, il existe une forte demande pour des professionnels possédant des compétences en manipulation de données. Selon le rapport 2024 sur l'état des connaissances en matière de données et d'IA, 80 % des dirigeants accordent de l'importance aux compétences en analyse et en manipulation des données.
L'apprentissage de PySpark peut ouvrir de nombreuses opportunités professionnelles. Plus de 800 offres d'emploi sur Indeed, allant d'ingénieurs de données à des scientifiques de données, soulignent la demande en compétences PySpark dans le domaine des données. offres d'emploi liées aux données.
Si vous apprenez PySpark de manière méthodique, vous aurez davantage de chances de réussir. Concentrons-nous sur quelques principes que vous pouvez appliquer dans votre parcours d'apprentissage.
Avant d'aborder les détails techniques, veuillez définir votre motivation pour apprendre PySpark. Veuillez vous poser la question suivante :
Une fois vos objectifs définis, veuillez acquérir les bases de PySpark et comprendre leur fonctionnement.
Étant donné que PySpark est basé sur Python, il est nécessaire de se familiariser avec Python avant d'utiliser PySpark. Il est important que vous soyez à l'aise avec les variables et les fonctions. Il pourrait également être utile de se familiariser avec les bibliothèques de manipulation de données telles que Pandas. Cours d'introduction à Python de DataCamp Introduction à Python de DataCamp et Manipulation de données avec Pandas peuvent vous aider à vous familiariser avec ces outils.
Il est nécessaire d'installer PySpark pour pouvoir commencer à l'utiliser. Vous pouvez télécharger PySpark à l'aide de pip ou Conda, le télécharger manuellement depuis le site officiel ou commencer avec DataLab pour vous familiariser avec PySpark dans votre navigateur.
Si vous souhaitez obtenir des explications détaillées sur la configuration de PySpark, veuillez consulter ce guide sur comment installer PySpark sur Windows, Mac et Linux.
Le premier concept que vous devez acquérir est le fonctionnement des DataFrame PySpark. Ils constituent l'une des principales raisons pour lesquelles PySpark fonctionne de manière si rapide et efficace. Comprenez comment les créer, les transformer (mapper et filtrer) et les manipuler. Le tutoriel sur comment commencer à travailler avec PySpark vous aidera à comprendre ces concepts.
Une fois que vous maîtrisez les bases, il est temps d'explorer les compétences intermédiaires de PySpark.
L'un des principaux avantages de PySpark réside dans sa capacité à exécuter des requêtes de type SQL pour lire et manipuler des DataFrame, effectuer des agrégations et utiliser des fonctions de fenêtre. En arrière-plan, PySpark utilise Spark SQL. Cette introduction à Spark SQL en Python peut vous aider à acquérir cette compétence.
Travailler avec des données implique de maîtriser leur nettoyage, leur transformation et leur préparation en vue de leur analyse. Cela comprend le traitement des valeurs manquantes, la gestion de différents types de données et la réalisation d'agrégations à l'aide de PySpark. Veuillez consulter le cours « Nettoyage des données avec PySpark » de DataCamp pour acquérir une expérience pratique et maîtriser ces compétences.
PySpark peut également être utilisé pour développer et déployer des modèles d'apprentissage automatique, grâce à sa bibliothèque MLlib. Il est recommandé d'apprendre à effectuer l'ingénierie des caractéristiques, l'évaluation des modèles et le réglage des hyperparamètres à l'aide de cette bibliothèque. DataCamp's Le cours « Machine Learning with PySpark » de DataCamp de DataCamp propose une introduction complète.
Suivre des cours et pratiquer des exercices à l'aide de PySpark constitue un excellent moyen de se familiariser avec cette technologie. Cependant, pour maîtriser PySpark, il est nécessaire de résoudre des problèmes complexes et stimulants, similaires à ceux que vous rencontrerez dans des projets réels. Vous pouvez commencer par effectuer des tâches simples d'analyse de données, puis passer progressivement à des défis plus complexes.
Voici quelques méthodes pour exercer vos compétences :
Au fur et à mesure que vous progresserez dans votre apprentissage de PySpark, vous réaliserez différents projets. Afin de mettre en valeur vos compétences et votre expérience en PySpark auprès d'employeurs potentiels, il est recommandé de les compiler dans un portfolio. Ce portfolio doit refléter vos compétences et vos centres d'intérêt, et être adapté à la carrière ou au secteur qui vous intéresse.
Veuillez vous efforcer de rendre vos projets originaux et de mettre en avant vos compétences en matière de résolution de problèmes. Veuillez inclure des projets qui démontrent votre maîtrise de divers aspects de PySpark, tels que le traitement des données, l'apprentissage automatique et la visualisation des données. Veuillez documenter vos projets en fournissant le contexte, la méthodologie, le code et les résultats. Vous pouvez utiliser DataLab, un environnement de développement intégré en ligne qui vous permet d'écrire du code, d'analyser des données de manière collaborative et de partager vos conclusions.
Voici deux projets PySpark sur lesquels vous pouvez travailler :
L'apprentissage de PySpark est un processus continu. La technologie évolue constamment, et de nouvelles fonctionnalités et applications sont régulièrement développées. PySpark ne fait pas exception à cette règle.
Une fois que vous maîtrisez les principes fondamentaux, vous pouvez vous tourner vers des tâches et des projets plus complexes, tels que l'optimisation des performances ou GraphX. Concentrez-vous sur vos objectifs et spécialisez-vous dans des domaines pertinents pour vos objectifs de carrière et vos centres d'intérêt.
Restez informé des dernières évolutions et découvrez comment les appliquer à vos projets actuels. Continuez à vous exercer, recherchez de nouveaux défis et opportunités, et considérez les erreurs comme un moyen d'apprendre.
Récapitulons les étapes à suivre pour un plan d'apprentissage PySpark réussi :
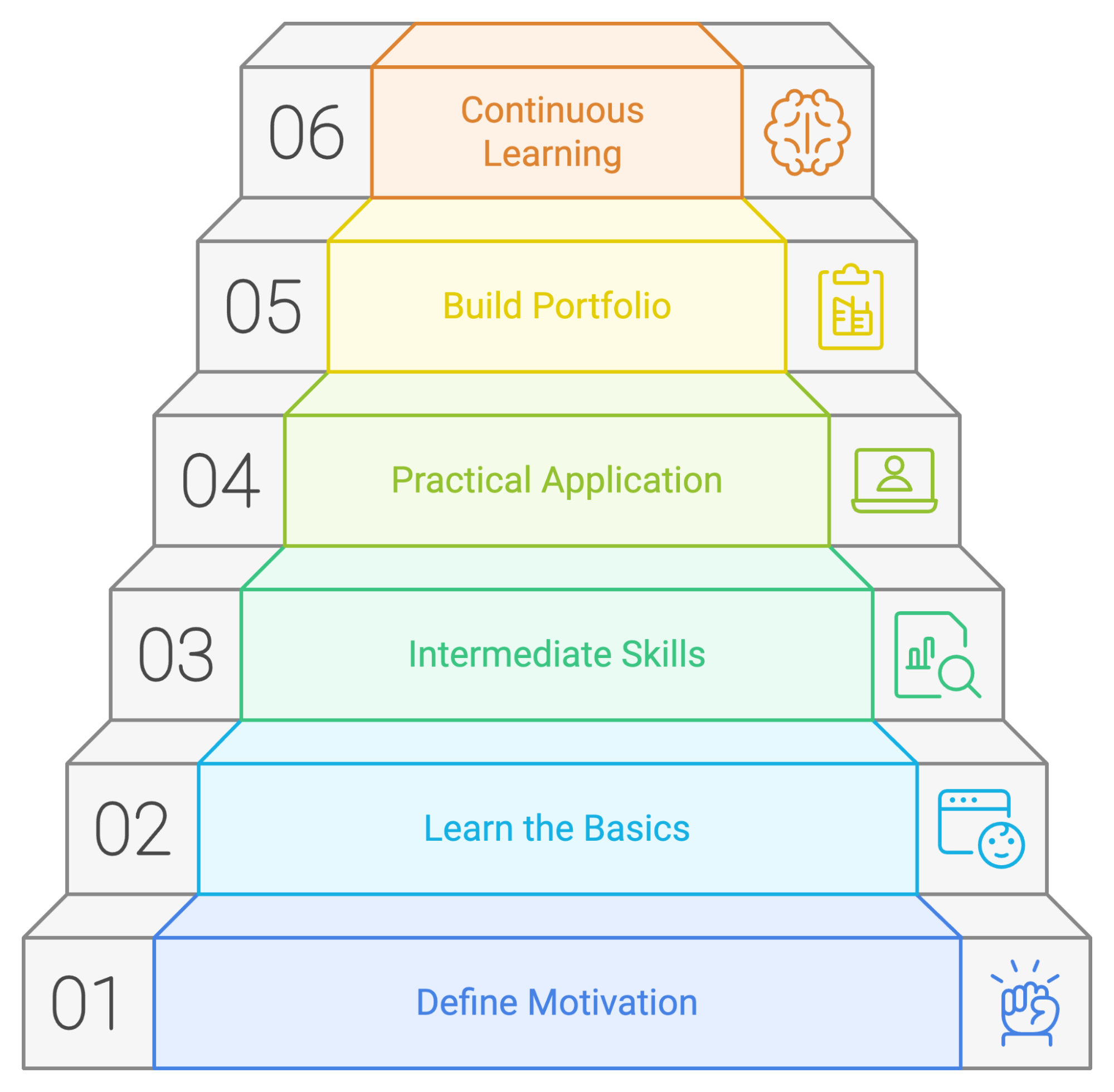
Même si chaque individu a sa propre méthode d'apprentissage, il est toujours judicieux de disposer d'un plan ou d'un guide à suivre pour apprendre à utiliser un nouvel outil. Nous avons élaboré un plan d'apprentissage potentiel qui indique où concentrer votre temps et vos efforts si vous débutez avec PySpark.
J'imagine qu'à présent, vous êtes prêt à vous lancer dans l'apprentissage de PySpark et à vous procurer un ensemble de données volumineux afin de mettre en pratique vos nouvelles compétences. Cependant, avant de vous lancer, permettez-moi de vous présenter quelques conseils qui vous aideront à maîtriser PySpark.
PySpark est un outil qui peut être utilisé dans de nombreuses applications différentes. Pour rester concentré et atteindre votre objectif, il est important d'identifier votre domaine d'intérêt. Souhaitez-vous vous concentrer sur l'analyse de données, l'ingénierie de données ou l'apprentissage automatique ? Adopter une approche ciblée peut vous aider à acquérir les connaissances et les aspects les plus pertinents de PySpark pour le parcours que vous avez choisi.
La constance est essentielle pour maîtriser toute nouvelle compétence. Il est recommandé de prévoir du temps dédié à la pratique de PySpark. Quelques instants chaque jour suffisent. Il n'est pas nécessaire d'aborder des concepts complexes quotidiennement. Vous pouvez revoir ce que vous avez appris ou revenir sur un exercice simple afin de le refactoriser. Une pratique régulière renforcera votre compréhension des concepts et vous permettra de gagner en assurance dans leur application.
Il s'agit d'un conseil essentiel, que vous retrouverez à plusieurs reprises dans ce guide. La pratique d'exercices est un excellent moyen de gagner en confiance. Cependant, c'est en appliquant vos compétences PySpark à des projets concrets que vous parviendrez à les maîtriser parfaitement. Recherchez les ensembles de données qui vous intéressent et utilisez PySpark pour les analyser, en extraire des informations et résoudre des problèmes.
Commencez par des projets et des questions simples, puis passez progressivement à des projets et des questions plus complexes. Cela peut être aussi simple que de lire et nettoyer un ensemble de données réelles et de rédiger une requête complexe pour effectuer des agrégations et prédire le prix d'une maison.
L'apprentissage est souvent plus efficace lorsqu'il est effectué de manière collaborative. Partager vos expériences et apprendre des autres peut accélérer vos progrès et vous apporter des informations précieuses.
Pour échanger des connaissances, des idées et poser des questions, vous pouvez rejoindre des groupes liés à PySpark et participer à des rencontres et des conférences. La communauté Databricks, société fondée par les créateurs de Spark, dispose d'un forum communautaire actif où vous pouvez participer à des discussions et poser des questions sur PySpark. De plus, le Spark Summit, organisé par Databricks, est la plus grande conférence consacrée à Spark.
Comme pour toute autre technologie, l'apprentissage de PySpark est un processus itératif. Et apprendre de ses erreurs est une partie essentielle du processus d'apprentissage. N'hésitez pas à expérimenter, à essayer différentes approches et à tirer des leçons de vos erreurs. Veuillez tester différentes fonctions et alternatives pour agréger les données, exécuter des sous-requêtes ou des requêtes imbriquées, et observer la rapidité de réponse offerte par PySpark.
Examinons quelques méthodes efficaces pour apprendre PySpark.
Les cours en ligne constituent un excellent moyen d'apprendre PySpark à votre rythme. DataCamp propose des cours PySpark pour tous les niveaux, qui constituent ensemble le programme Big Data avec PySpark. Big Data avec PySpark cursus. Les cours couvrent les concepts introductifs aux thèmes de l'apprentissage automatique et sont conçus avec des exercices pratiques.
Voici quelques-uns des cours liés à PySpark proposés sur DataCamp :
Les tutoriels constituent un autre excellent moyen d'apprendre PySpark, en particulier si vous débutez avec cette technologie. Ils contiennent des instructions détaillées sur la manière d'effectuer des tâches spécifiques ou de comprendre certains concepts. Pour commencer, veuillez consulter ces tutoriels :
Les aide-mémoire sont utiles lorsque vous avez besoin d'un guide de référence rapide sur les sujets liés à PySpark. Voici deux aide-mémoire utiles :
L'apprentissage de PySpark nécessite une pratique approfondie. Relever des défis tout en menant à bien des projets qui vous permettront de mettre en pratique toutes les compétences acquises. À mesure que vous vous lancerez dans des tâches plus complexes, il sera nécessaire de trouver des solutions et d'explorer de nouvelles alternatives pour obtenir les résultats souhaités, ce qui vous permettra d'approfondir votre expertise PySpark.
Veuillez consulter les projets PySpark disponibles sur DataCamp. Ces exemples vous permettent de mettre en pratique vos compétences en matière de manipulation de données et de création de modèles d'apprentissage automatique à l'aide de PySpark :
Les livres constituent une excellente ressource pour apprendre PySpark. Ils offrent des connaissances approfondies et des informations provenant d'experts, ainsi que des extraits de code et des explications. Voici quelques-uns des ouvrages les plus populaires sur PySpark :
La demande en compétences PySpark a augmenté dans plusieurs postes liés aux données, des analystes de données aux ingénieurs big data. Si vous vous préparez pour un entretien, veuillez prendre en considération ces questions d'entretien sur PySpark pour
En tant qu'ingénieur Big Data, vous êtes l'architecte des solutions Big Data, chargé de concevoir, de construire et de maintenir l'infrastructure qui traite les grands ensembles de données. Vous utiliserez PySpark pour créer des pipelines de données évolutifs, garantissant une ingestion, un traitement et un stockage efficaces des données.
Vous devrez posséder une solide compréhension des plateformes informatiques distribuées et cloud, ainsi qu'une expertise dans le domaine du stockage de données et des processus ETL.
Nos programmes de certification vous aident à vous démarquer et à prouver aux employeurs potentiels que vos compétences sont adaptées à l'emploi.

Apprenez PySpark grâce à ces cours.
Cours
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
Tutoriel
Matt Crabtree
Tutoriel
Sejal Jaiswal