
Course
Foundations of PySpark
4 hr
157.5K
PySpark is the combination of two powerful technologies: Python and Apache Spark.
Python is one the most used programming languages in software development, particularly for data science and machine learning, mainly due to its easy-to-use and straightforward syntax.
On the other hand, Apache Spark is a framework that can handle large amounts of unstructured data. Spark was built using Scala, a language that gives us more control over It. However, Scala is not a popular programming language among data practitioners. So, PySpark was created to overcome this gap.
PySpark offers an API and a user-friendly interface for interacting with Spark. It uses Python's simplicity and flexibility to make big data processing accessible to a wider audience.
In recent years, PySpark has become an important tool for data practitioners who need to process huge amounts of data. We can explain its popularity by several key factors:
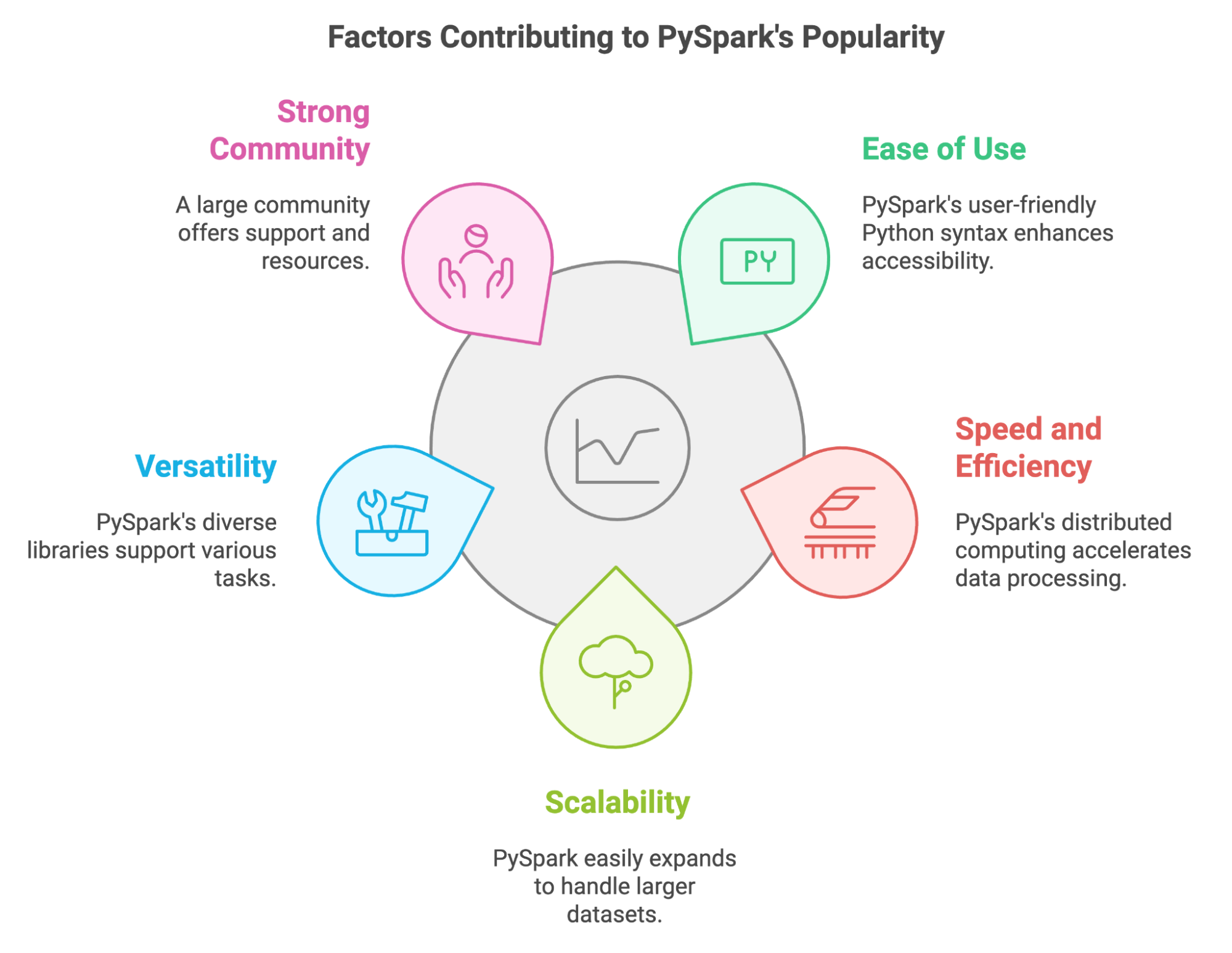
PySpark also allows us to leverage existing Python skills and libraries. We can easily integrate it with popular tools like Pandas and Scikit-learn, and it lets us use various data sources.
PySpark was created especially for big data and machine learning developments. But what features make it a powerful tool for handling huge amounts of data? Let’s have a look at them:
The volume of data is only increasing. Today, data wrangling, data analysis, and machine learning tasks involve working with large amounts of data. We need to use powerful tools that process that data efficiently and promptly. PySpark is among one of those tools.
We’ve already mentioned the strengths of PySpark, but let’s look at a few specific examples of where you can use them:
With the rise of data science and machine learning and the increase in data available, there is a high demand for professionals with data manipulation skills. According to The State of Data & AI Literacy Report 2024, 80% of leaders value data analysis and manipulation skills.
Learning PySpark can open up a wide range of career opportunities. Over 800 job listings on Indeed, from data engineers to data scientists, highlight the demand for PySpark proficiency in data-related job postings.
If you learn PySpark methodically, you have more chances of success. Let’s focus on a few principles you can use in your learning journey.
Before you learn technical details, define your motivation for learning PySpark. Ask yourself:
After you identify your goals, master the basics of PySpark and understand how they work.
Because PySpark is built on top of Python, you must become familiar with Python before using PySpark. You should feel comfortable working with variables and functions. Also, it might be a good idea to be familiar with data manipulation libraries such as Pandas. DataCamp's Introduction to Python course and Data Manipulation with Pandas can help you get up to speed.
You need to install PySpark to start using it. You can download PySpark using pip or Conda, manually download it from the official website, or start with DataLab to get started with PySpark in your browser.
If you want a full explanation of how to set up PySpark, check out this guide on how to install PySpark on Windows, Mac, and Linux.
The first concept you should learn is how PySpark DataFrames work. They are one of the key reasons why PySpark works so fast and efficiently. Understand how to create, transform (map and filter), and manipulate them. The tutorial on how to start working with PySpark will help you with these concepts.
Once you're comfortable with the basics, it's time to explore intermediate PySpark skills.
One of the biggest advantages of PySpark is its ability to perform SQL-like queries to read and manipulate DataFrames, perform aggregations, and use window functions. Behind the scenes, PySpark uses Spark SQL. This introduction to Spark SQL in Python can help you with this skill.
Working with data implies becoming proficient in cleaning, transforming, and preparing it for analysis. This includes handling missing values, managing different data types, and performing aggregations using PySpark. Take the DataCamp's Cleaning Data with PySpark to gain practical experience and master these skills.
PySpark can also be used to develop and deploy machine learning models, thanks to its MLlib library. You should learn to perform feature engineering, model evaluation, and hyperparameter tuning using this library. DataCamp's Machine Learning with PySpark course provides a comprehensive introduction.
Taking courses and practicing exercises using PySpark is an excellent way to get familiar with the technology. However, to get proficient in PySpark, you need to solve challenging and skill-building problems, such as those you’ll face on real-world projects. You can start by taking simple data analysis tasks and gradually move to more complex challenges.
Here are some ways to practice your skills:
As you keep moving in your PySpark learning journey, you will complete different projects. To showcase your PySpark skills and experience to potential employers, you should compile them into a portfolio. This portfolio should reflect your skills and interests and be tailored to the career or industry you're interested in.
Try to make your projects original and showcase your problem-solving skills. Include projects that demonstrate your proficiency in various aspects of PySpark, such as data wrangling, machine learning, and data visualization. Document your projects, providing context, methodology, code, and results. You can use DataLab, which is an online IDE that allows you to write code, analyze data collaboratively, and share your insights.
Here are two PySpark projects you can work on:
Learning PySpark is a continuous journey. Technology constantly evolves, and new features and applications are being developed regularly. PySpark is not the exception to that.
Once you’ve mastered the fundamentals, you can look for more challenging tasks and projects such as performance optimization or GraphX. Focus on your goals and specialize in areas that are relevant to your career goals and interests.
Keep up to date with the new developments and learn how to apply them to your current projects. Keep practicing, seek out new challenges and opportunities, and embrace the idea of making mistakes as a way to learn.
Let’s recap the steps we can take for a successful PySpark learning plan:
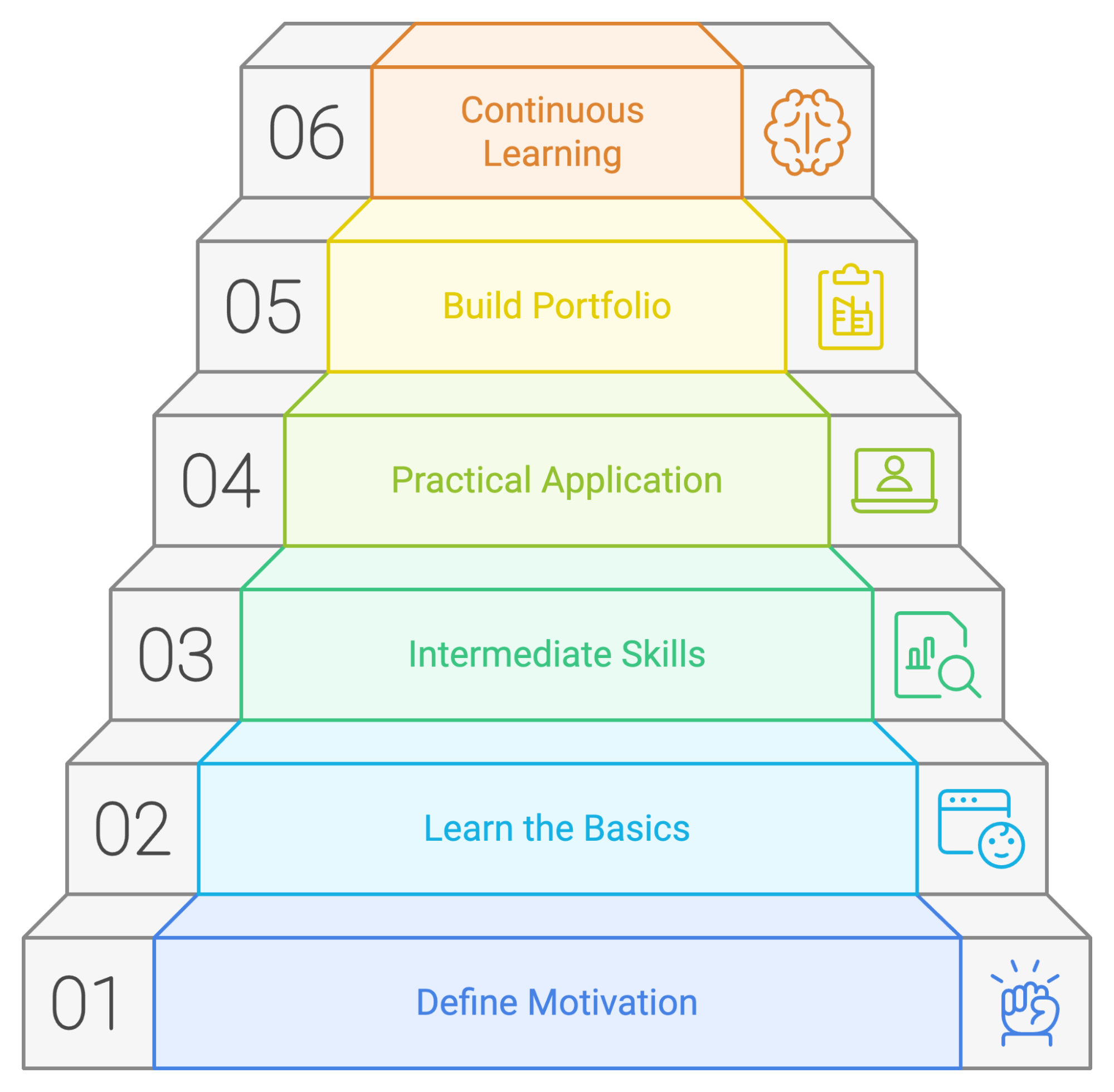
Even though each person has their way of learning, it’s always a good idea to have a plan or guide to follow for learning a new tool. We’ve created a potential learning plan outlining where to focus your time and efforts if you’re just starting with PySpark.
I imagine that by now, you are ready to jump into learning PySpark and get your hands on a large dataset to practice your new skill. But before you do, let me highlight these tips that will help you navigate the path to PySpark proficiency.
PySpark is a tool that can have many different applications. To keep focus and achieve your goal, you should identify your area of interest. Do you want to focus on data analysis, data engineering, or machine learning? Taking a focused approach can help you gain the most relevant aspects and knowledge of PySpark for your chosen path.
Consistency is key to mastering any new skill. You should set aside dedicated time to practice PySpark. Just a short amount of time every day will do. You don’t need to tackle complex concepts every day. You can review what you’ve learned or revisit a simple exercise to refactor it. Regular practice will reinforce your understanding of concepts and build your confidence in applying them.
This is one of the key tips, and you will read it several times in this guide. Practicing exercises is great for gaining confidence. However, applying your PySpark skills to real-world projects is what will make you excel at it. Look for datasets that interest you and use PySpark to analyze them, extract insights, and solve problems.
Start with simple projects and questions and gradually take on more complex ones. This can be as simple as reading and cleaning a real dataset and writing a complex query to perform aggregations and predict the price of a house.
Learning is often more effective when done collaboratively. Sharing your experiences and learning from others can accelerate your progress and provide valuable insights.
To exchange knowledge, ideas, and questions, you can join some groups related to PySpark, and attend meet-ups and conferences. The Databricks Community, the company founded by the creators of Spark, has an active community forum where you can engage in discussion and ask questions about PySpark. Moreover, the Spark Summit, organized by Databricks, is the largest Spark conference.
As with any other technology, learning PySpark is an iterative process. And learning from your mistakes is an essential part of the learning process. Don't be afraid to experiment, try different approaches, and learn from your errors. Try different functions and alternatives for aggregating the data, perform subqueries or nested queries, and observe the fast response that PySpark gives.
Let’s cover a few efficient methods of learning PySpark.
Online courses offer an excellent way to learn PySpark at your own speed. DataCamp offers PySpark courses for all levels, which together make up the Big Data with PySpark track. The courses cover introductory concepts to machine learning topics and are designed with hands-on exercises.
Here are some of the PySpark-related courses on DataCamp:
Tutorials are another great way to learn PySpark, especially if you are new to the technology. They contain step-by-step instructions on how to perform specific tasks or understand certain concepts. For a start, consider these tutorials:
Cheat sheets come in handy when you need a quick reference guide on PySpark topics. Here are two useful cheat sheets:
Learning PySpark requires hands-on practice. Facing challenges while completing projects that will allow you to apply all the skills you’ve learned. As you start to take on more complex tasks, you’ll need to find solutions and research new alternatives to get the results you want, boosting your PySpark expertise.
Check for the PySpark projects to work on at DataCamp. These allow you to apply your data manipulation skills and machine learning model building leveraging PySpark:
Books are an excellent resource for learning PySpark. They offer in-depth knowledge and insights from experts alongside code snippets and explanations. Here are some of the most popular books on PySpark:
The demand for PySpark skills has increased across several data-related roles, from data analysts to big data engineers. If you’re getting ready for an interview, consider these PySpark interview questions for
As a big data engineer, you are the architect of big data solutions, responsible for designing, building, and maintaining the infrastructure that handles large datasets. You will rely on PySpark to create scalable data pipelines, ensuring efficient data ingestion, processing, and storage.
You will require a strong understanding of distributed computing and cloud platforms and expertise in data warehousing and ETL processes.
Our certification programs help you stand out and prove your skills are job-ready to potential employers.

Learn PySpark with these courses!
Course
Course
Course
blog
Bex Tuychiev
15 min
blog
Thalia Barrera
15 min
blog
Matt Crabtree
15 min
blog
Bex Tuychiev
14 min
blog
Josep Ferrer
blog
Josef Waples
12 min
