
Curso
Fundamentos do PySpark
4 h
157.5K
PySpark é a combinação de duas tecnologias poderosas: Python e Apache Spark.
Python é uma das linguagens de programação mais usadas no desenvolvimento de software, principalmente para ciência de dados e machine learning, porque é fácil de usar e tem uma sintaxe simples.
Por outro lado, o Apache Spark é uma estrutura que consegue lidar com grandes quantidades de dados não estruturados. O Spark foi criado usando Scala, uma linguagem que nos dá mais controle sobre ele. Mas, Scala não é uma linguagem de programação muito popular entre quem trabalha com dados. Então, o PySpark foi criado pra resolver essa questão.
O PySpark oferece uma API e uma interface fácil de usar para interagir com o Spark. Ele usa a simplicidade e flexibilidade do Python para tornar o processamento de big data acessível a um público mais amplo.
Nos últimos anos, o PySpark virou uma ferramenta importante para quem trabalha com dados e precisa lidar com um monte de informação. A gente pode explicar a popularidade dele por vários fatores importantes:
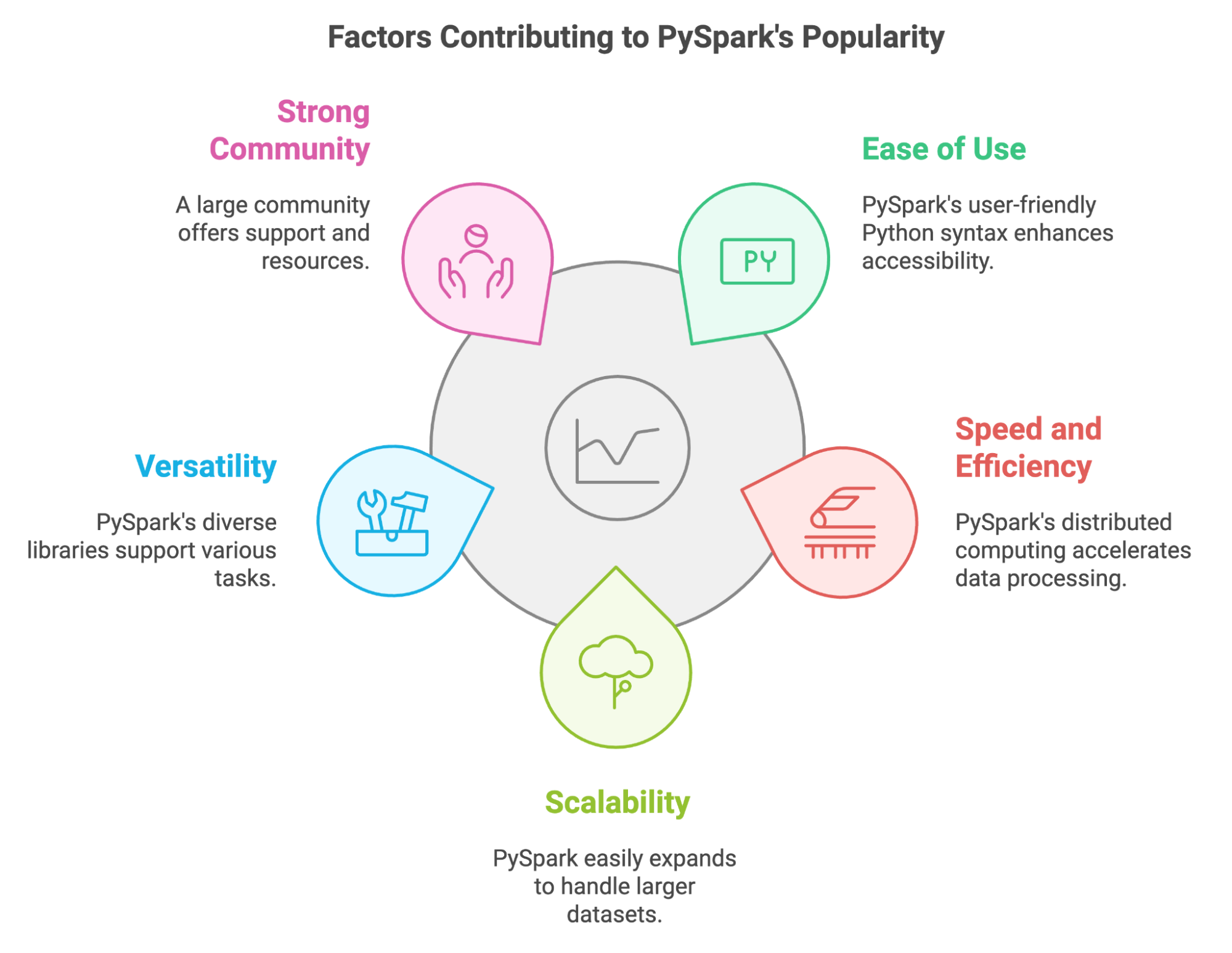
O PySpark também nos permite aproveitar os conhecimentos e bibliotecas Python já existentes. Podemos integrá-lo facilmente com ferramentas populares como Pandas e Scikit-learn, e isso nos permite usar várias fontes de dados.
O PySpark foi feito especialmente para big data e machine learning developments. Mas quais são as funcionalidades que fazem dele uma ferramenta poderosa para lidar com grandes quantidades de dados? Vamos dar uma olhada neles:
O volume de dados só está aumentando. Hoje em dia, as tarefas de manipulação de dados, análise de dados e machine learning envolvem trabalhar com grandes quantidades de dados. Precisamos usar ferramentas poderosas que processem esses dados de forma eficiente e rápida. O PySpark é uma dessas ferramentas.
Já falamos sobre os pontos fortes do PySpark, mas vamos ver alguns exemplos específicos de onde você pode usá-los:
Com o surgimento da ciência de dados e do machine learning e o aumento dos dados disponíveis, tem uma demanda alta por profissionais que sabem mexer com dados. De acordo com o Relatório sobre o estado da alfabetização em dados e IA 2024, 80% dos líderes valorizam as habilidades de análise e manipulação de dados.
Aprender PySpark pode abrir um monte de oportunidades de carreira. Mais de 800 anúncios de emprego no Indeed, de engenheiros de dados a cientistas de dados, mostram a procura por pessoas que sabem usar o PySpark em anúncios de emprego relacionados a dados.
Se você aprender PySpark de forma organizada, vai ter mais chances de sucesso. Vamos focar em alguns princípios que você pode usar na sua jornada de aprendizado.
Antes de aprender os detalhes técnicos, pense por que você quer aprender PySpark. Pergunte a si mesmo:
Depois de definir seus objetivos, aprenda o básico do PySpark e entenda como ele funciona.
Como o PySpark é baseado no Python, você precisa se familiarizar com o Python antes de usar o PySpark. Você deve se sentir à vontade para trabalhar com variáveis e funções. Além disso, pode ser uma boa ideia se familiarizar com bibliotecas de manipulação de dados, como o Pandas. Curso de introdução ao Python da DataCamp Introdução ao Python e Manipulação de dados com Pandas podem te ajudar a se atualizar.
Você precisa instalar o PySpark para começar a usá-lo. Você pode baixar o PySpark usando o pip ou o Conda, baixá-lo manualmente do site oficial ou começar com o DataLab para começar a usar o PySpark no seu navegador.
Se você quiser uma explicação completa sobre como configurar o PySpark, confira este guia sobre como instalar o PySpark no Windows, Mac e Linux.
O primeiro conceito que você deve aprender é como funcionam os DataFrame do PySpark. Eles são uma das principais razões pelas quais o PySpark funciona tão rápido e eficiente. Entenda como criar, transformar (mapear e filtrar) e mexer neles. O tutorial sobre como começar a trabalhar com o PySpark vai te ajudar com esses conceitos.
Quando você já estiver de boa com o básico, é hora de explorar as habilidades intermediárias do PySpark.
Uma das maiores vantagens do PySpark é a capacidade de fazer consultas tipo SQL para ler e mexer em DataFrame, fazer agregações e usar funções de janela. Nos bastidores, o PySpark usa o Spark SQL. Essa introdução ao Spark SQL em Python pode te ajudar com essa habilidade.
Trabalhar com dados significa aprender a limpar, transformar e preparar os dados para análise. Isso inclui lidar com valores ausentes, gerenciar diferentes tipos de dados e fazer agregações usando o PySpark. Faça o DataCamp: Limpeza de Dados com PySpark para ganhar experiência prática e dominar essas habilidades.
O PySpark também pode ser usado para desenvolver e implantar modelos de machine learning, graças à sua biblioteca MLlib. Você deve aprender a fazer engenharia de recursos, avaliação de modelos e ajuste de hiperparâmetros usando essa biblioteca. DataCamp's Machine learning com PySpark oferece uma introdução bem completa.
Fazer cursos e praticar exercícios usando o PySpark é uma ótima maneira de se familiarizar com a tecnologia. Mas, pra ficar craque no PySpark, você precisa resolver problemas desafiadores e que desenvolvam suas habilidades, tipo aqueles que você vai encontrar em projetos reais. Você pode começar com tarefas simples de análise de dados e, aos poucos, passar para desafios mais complexos.
Aqui estão algumas maneiras de praticar suas habilidades:
À medida que você avança na sua jornada de aprendizado do PySpark, você vai concluir diferentes projetos. Para mostrar suas habilidades e experiência em PySpark para possíveis empregadores, você deve juntar tudo em um portfólio. Esse portfólio deve mostrar suas habilidades e interesses e ser feito sob medida para a carreira ou setor que você curte.
Tente fazer projetos originais e mostrar suas habilidades pra resolver problemas. Inclua projetos que mostrem sua habilidade em vários aspectos do PySpark, como manipulação de dados, machine learning e visualização de dados. Documente seus projetos, mostrando o contexto, a metodologia, o código e os resultados. Você pode usar o DataLab, que é um IDE online que permite escrever código, analisar dados de forma colaborativa e compartilhar suas ideias.
Aqui estão dois projetos PySpark nos quais você pode trabalhar:
Aprender PySpark é uma jornada contínua. A tecnologia está sempre mudando, e novos recursos e aplicativos são criados o tempo todo. O PySpark não é exceção a isso.
Depois de dominar o básico, você pode procurar tarefas e projetos mais desafiadores, como otimização de desempenho ou GraphX. Concentre-se em seus objetivos e especialize-se em áreas que sejam relevantes para suas metas profissionais e interesses.
Fique por dentro das novidades e aprenda como aplicá-las nos seus projetos atuais. Continue praticando, procure novos desafios e oportunidades e aceite a ideia de cometer erros como uma forma de aprender.
Vamos recapitular os passos que podemos seguir para um plano de aprendizagem bem-sucedido do PySpark:
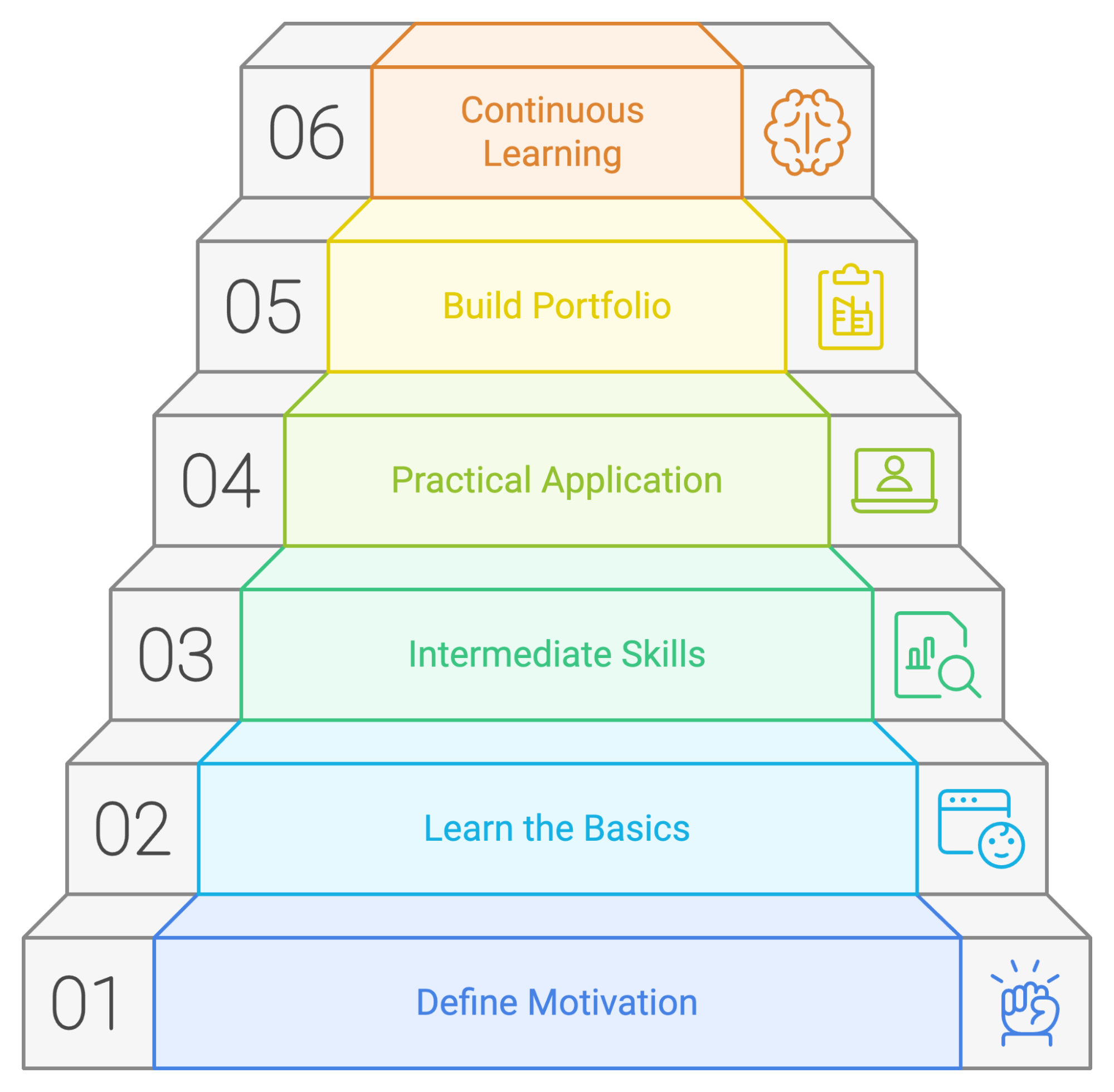
Mesmo que cada pessoa tenha sua maneira de aprender, é sempre uma boa ideia ter um plano ou guia para seguir ao aprender uma nova ferramenta. Criamos um plano de aprendizado potencial que mostra onde você deve focar seu tempo e esforços se estiver começando com o PySpark.
Imagino que, a essa altura, você já esteja pronto para começar a aprender PySpark e colocar as mãos em um grande conjunto de dados para praticar sua nova habilidade. Mas antes disso, deixa eu te dar umas dicas que vão te ajudar a chegar lá e dominar o PySpark.
PySpark é uma ferramenta que pode ter várias aplicações diferentes. Para manter o foco e alcançar seu objetivo, você deve identificar sua área de interesse. Quer focar em análise de dados, engenharia de dados ou machine learning? Adotar uma abordagem focada pode te ajudar a obter os aspectos e conhecimentos mais relevantes do PySpark para o caminho que você escolheu.
A consistência é fundamental para dominar qualquer nova habilidade. Você deve reservar um tempo dedicado para praticar o PySpark. Basta dedicar um tempinho todos os dias. Você não precisa lidar com conceitos complexos todos os dias. Você pode revisar o que aprendeu ou revisitar um exercício simples para refatorá-lo. A prática regular vai ajudar você a entender melhor os conceitos e a ficar mais confiante na hora de aplicá-los.
Essa é uma das dicas mais importantes, e você vai ver isso várias vezes neste guia. Fazer exercícios é ótimo pra ganhar confiança. Mas, usar suas habilidades em PySpark em projetos reais é o que vai fazer você se destacar nisso. Procure conjuntos de dados que te interessem e use o PySpark para analisá-los, extrair insights e resolver problemas.
Comece com projetos e questões simples e, aos poucos, vá encarando os mais complexos. Isso pode ser tão simples quanto ler e limpar um conjunto de dados reais e escrever uma consulta complexa para fazer agregações e prever o preço de uma casa.
Aprender costuma ser mais eficaz quando feito em grupo. Compartilhar suas experiências e aprender com os outros pode acelerar seu progresso e trazer insights valiosos.
Pra trocar conhecimento, ideias e perguntas, você pode entrar em alguns grupos relacionados ao PySpark e participar de encontros e conferências. A Comunidade Databricks, a empresa criada pelos caras que inventaram o Spark, tem um fórum bem ativo onde você pode participar de discussões e tirar dúvidas sobre o PySpark. Além disso, o Spark Summit, organizado pela Databricks, é a maior conferência sobre Spark.
Como com qualquer outra tecnologia, aprender PySpark é um processo que vai acontecendo aos poucos. E aprender com os seus erros é uma parte essencial do processo de aprendizagem. Não tenha medo de experimentar, tente diferentes abordagens e aprenda com seus erros. Experimente diferentes funções e alternativas para juntar os dados, faça subconsultas ou consultas aninhadas e veja como o PySpark responde rapidinho.
Vamos ver alguns métodos eficientes para aprender PySpark.
Os cursos online são uma ótima maneira de aprender PySpark no seu próprio ritmo. DataCamp oferece cursos de PySpark para todos os níveis, que juntos formam o Big Data com PySpark programa. Os cursos abordam conceitos introdutórios sobre temas relacionados ao machine learning e são elaborados com exercícios práticos.
Aqui estão alguns dos cursos relacionados ao PySpark no DataCamp:
Os tutoriais são outra ótima maneira de aprender PySpark, principalmente se você é novo nessa tecnologia. Eles têm instruções passo a passo sobre como fazer tarefas específicas ou entender certos conceitos. Pra começar, dá uma olhada nesses tutoriais:
As folhas de referência são úteis quando você precisa de um guia rápido sobre os tópicos do PySpark. Aqui estão duas folhas de dicas úteis:
Aprender PySpark precisa de prática. Enfrentar desafios enquanto conclui projetos que permitirão que você aplique todas as habilidades que aprendeu. À medida que você começa a assumir tarefas mais complexas, vai precisar encontrar soluções e pesquisar novas alternativas para obter os resultados desejados, aumentando sua experiência com o PySpark.
Dá uma olhada nos projetos PySpark para trabalhar no DataCamp. Isso permite que você use suas habilidades de manipulação de dados e construção de modelos de machine learning usando o PySpark:
Os livros são um excelente recurso para aprender PySpark. Eles oferecem conhecimento aprofundado e insights de especialistas, além de trechos de código e explicações. Aqui estão alguns dos livros mais populares sobre PySpark:
A procura por habilidades em PySpark aumentou em várias funções relacionadas a dados, desde analistas de dados até engenheiros de big data. Se você está se preparando para uma entrevista, considere estas perguntas sobre PySpark para
Como engenheiro de big data, você é o arquiteto das soluções de big data, responsável por projetar, construir e manter a infraestrutura que lida com grandes conjuntos de dados. Você vai usar o PySpark pra criar pipelines de dados escaláveis, garantindo uma ingestão, processamento e armazenamento eficientes dos dados.
Você vai precisar de um bom conhecimento sobre computação distribuída e plataformas em nuvem, além de experiência em warehouse e processos ETL.
Nossos programas de certificação ajudam você a se destacar e a provar que suas habilidades estão prontas para o trabalho para possíveis empregadores.

Aprenda PySpark com esses cursos!
Curso
Curso
Curso
blog
Gus Frazer
11 min
blog
Laiba Siddiqui
13 min
blog
Adel Nehme
15 min
blog
Natassha Selvaraj
14 min
Tutorial
Natassha Selvaraj
