
Leerpad
Python-ontwikkelaar
28 Hr
Traditionele pdf-extractietools zoals pypdf of PDFMiner geven je ruwe tekst maar verliezen de documentstructuur. Tabellen worden rommelige tekst, koppen vermengen zich met bodytekst en afbeeldingen verdwijnen. Voor RAG-systemen betekent deze rommelige data slechte retrieval en onbetrouwbare antwoorden. Docling is een open-sourcetoolkit van IBM Research die computervisiemodellen gebruikt om documentlay-outs te begrijpen en zo tabellen, afbeeldingen, koppen en structuur te behouden. Het verwerkt documenten tot 30 keer sneller dan traditionele OCR-methoden en draait lokaal op je machine.
In deze tutorial gebruiken we Docling om een Document Intelligence Assistant te bouwen — een Streamlit-webapp waarmee je documenten kunt uploaden, hun structuur kunt visualiseren en vragen kunt stellen via een RAG-aangedreven chatbot. Je leert hoe je documenten in meerdere formaten verwerkt met Docling, tabellen en afbeeldingen extraheert en weergeeft, een vectorstore bouwt met ChromaDB en een conversationele agent maakt met LangGraph. Aan het einde heb je een werkende applicatie die complexe documenten omzet in gestructureerde data en intelligente vraag-en-antwoordfuncties mogelijk maakt.
Preview van de applicatie:
Visualisatie van documentstructuur:
Voor je met deze tutorial begint, heb je het volgende nodig:
Technische skills: Je bent vertrouwd met Python-klassen, decorators, type hints en contextmanagers. We gebruiken overal async-operations en factorypatronen. Inzicht in hoe large language models werken met prompts, tokens en embeddings is nodig. Bekendheid met retrieval-augmented generation-systemen en vectordatabases is handig maar niet vereist — we leggen kernconcepten uit terwijl we bouwen.
Ontwikkelomgeving: Python 3.10 of hoger met pip voor pakketbeheer. Een code-editor zoals VS Code is aan te raden. Je hebt een OpenAI API-sleutel nodig van platform.openai.com — de verwerkingskosten zijn ongeveer $0,10–0,20 per document.
Tijdsinvestering: Reken op 60–90 minuten om de tutorial te voltooien, inclusief het lezen van uitleg, het schrijven van code en het testen van de applicatie. Deze tutorial gaat uit van gemiddelde Python-vaardigheden.
De meeste documentverwerkingstools behandelen pdf’s als afbeeldingsbestanden of tekststromen. Ze draaien ofwel OCR op elke pagina of ze extraheren platte tekst zonder te begrijpen wat ze lezen. Docling pakt het anders aan. Het is een open-sourcetoolkit van IBM Research dat computervisiemodellen gebruikt om documentstructuur te begrijpen zoals een mens dat zou doen.
Wanneer je een document in Docling stopt, analyseren twee AI-modellen het:
Deze modellen begrijpen dat een document niet zomaar een brok tekst is. Het heeft hiërarchie, relaties en betekenis.
Dit structurele begrip is belangrijk voor RAG-systemen. Wanneer je retrieval-augmented generation-applicaties bouwt, heeft de kwaliteit van je documentverwerking direct invloed op je retrieval-nauwkeurigheid. Als je pdf-extractie een financiële tabel verandert in rommelige tekst, levert je vectorzoekopdracht troep op. Docling behoudt de structuur, zodat je bij het chunken en embedden van je documenten werkt met schone, georganiseerde data.
Docling ondersteunt standaard meerdere documentformaten:
Je kunt ook OCR inschakelen voor gescande documenten met engines zoals EasyOCR, Tesseract of RapidOCR. De toolkit exporteert naar verschillende formaten, waaronder Markdown (ideaal voor LLM’s), JSON (voor gestructureerde datapijplijnen) en DocTags (een formaat dat complexe elementen zoals wiskundige vergelijkingen en codeblokken vastlegt).
Naast formatflexibiliteit biedt Docling prestatievoordelen. Traditionele, op OCR gebaseerde documentverwerking is traag omdat elke pagina als afbeelding wordt behandeld die karakterherkenning vereist. Docling slaat deze stap over voor digitale documenten en biedt veel snellere verwerking. Het draait lokaal op standaardhardware, dus je betaalt geen API-kosten en stuurt geen gevoelige documenten naar externe services. De verwerkingssnelheid varieert op basis van documentcomplexiteit, paginatal en hardwarespecificaties, met typische prestaties van minder dan een seconde tot enkele seconden per pagina op moderne hardware.
IBM blijft de mogelijkheden van Docling verbeteren. Ze hebben Granite-Docling uitgebracht, een vision-language model met 258 miljoen parameters dat uitblinkt in complexe lay-outs en experimentele meertalige ondersteuning biedt (met Engels als primaire taal en vroege ondersteuning voor Arabisch, Chinees en Japans). De toolkit ondersteunt nu ook afbeeldingsextractie met instelbare resolutie, wat we in onze applicatie gebruiken om echte afbeeldingen uit pdf’s naast hun tekstinhoud weer te geven.
Voor onze usecase is Docling logisch omdat we gestructureerde data nodig hebben, niet alleen ruwe tekst. Als je alleen basis-textextractie nodig hebt, volstaan eenvoudigere tools zoals pypdf mogelijk. Maar omdat we een AI-applicatie bouwen die documenten verwerkt voor analyse en conversatie, is Doclings structuurbewuste verwerking de betere keuze. Het is vooral waardevol bij technische documenten, onderzoekspapers of bedrijfsrapporten waar tabellen en lay-out ertoe doen.
Voordat we de documentprocessor gaan bouwen, moet je je projectstructuur opzetten en de vereiste pakketten installeren. Deze sectie behandelt de initiële setup: mappen aanmaken, dependencies installeren en je API-sleutels configureren.
Begin met het aanmaken van een nieuwe map voor je project:
mkdir docling-demo
cd docling-demoMaak binnen deze map een src/ map voor je Python-modules:
mkdir src
touch src/__init__.pyHet bestand __init__.py vertelt Python dat src/ een package is, waardoor imports zoals from src.document_processor import DocumentProcessor mogelijk worden.
Je projectstructuur:
docling-demo/
├── src/
│ └── __init__.pyMaak een requirements.txt bestand in de hoofdmap van je project:
docling>=2.55.0
langchain-docling>=0.1.0
langchain>=0.3.0
langchain-openai>=0.2.0
langgraph>=0.2.0
langchain-chroma>=0.1.0
streamlit>=1.28.0
streamlit-extras>=0.7.0
python-dotenv>=1.0.0
chromadb>=0.4.22
tiktoken>=0.5.0
pandas>=2.0.0
numpy<2De beperking numpy<2 bestaat omdat Doclings dependencies (TensorFlow en Transformers) NumPy 1.x vereisen.
Installeer de pakketten:
pip install -r requirements.txtDe eerste installatie duurt een paar minuten omdat Docling voorgetrainde AI-modellen downloadt (ongeveer 500MB). Deze modellen verzorgen de lay-outanalyse en tabelstructuurherkenning. Ze worden lokaal gecachet, dus volgende runs zijn sneller.
Maak een .env bestand om je OpenAI API-sleutel op te slaan:
OPENAI_API_KEY=your-openai-api-key-hereHaal je API-sleutel op via platform.openai.com. Je hebt deze nodig voor embeddings en de chatagent.
Maak een .env.example template:
OPENAI_API_KEY=your-openai-api-key-hereVoeg een .gitignore toe om te voorkomen dat je gevoelige data commit:
# Environment variables
.env
# Python
__pycache__/
*.py[cod]
*.so
venv/
*.egg-info/
# Chroma
chroma_db/Maak app.py in de hoofdmap van je project. We bouwen dit bestand stap voor stap door de tutorial heen. Voeg voor nu de basisimports en -configuratie toe:
import streamlit as st
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Page configuration
st.set_page_config(
page_title="Document Intelligence Assistant",
page_icon="📄",
layout="wide"
)
st.title("Document Intelligence Assistant")
st.write("Application setup complete. We'll build the functionality next.")Test je setup:
streamlit run app.pyStreamlit opent een browservenster op http://localhost:8501 met je basispagina.
Je uiteindelijke projectstructuur (voordat we in de volgende secties nieuwe scripts toevoegen):
docling-demo/
├── .env
├── .env.example
├── .gitignore
├── requirements.txt
├── app.py
└── src/
└── __init__.pyMet de omgeving klaar kunnen we de documentprocessor bouwen die Docling gebruikt om structuur uit geüploade bestanden te halen.
> Opmerking: De onderstaande secties splitsen de applicatiescripts in stukken op. Om het geheel te overzien en makkelijk mee te volgen, raden we aan om de GitHub-repository voor dit project in een apart tabblad te openen.
📄 Volledig script: src/document_processor.py
De documentprocessor is waar Docling zijn werk doet. Deze component neemt geüploade bestanden en zet ze om in gestructureerde data die we zowel voor RAG als voor visualisatie kunnen gebruiken. We hebben twee outputs nodig van dit proces: schone markdown-tekst voor de vectorstore en het originele Docling-documentobject dat alle structurele informatie zoals tabellen en afbeeldingen bewaart.
Laten we dit bouwen door een nieuw bestand document_processor.py aan te maken in je src/ map. We maken een DocumentProcessor klasse die Doclings verwerkingspipeline configureert en uploads afhandelt.
Met pipeline-opties kun je bepalen hoe Docling documenten verwerkt. Voor pdf’s kun je OCR inschakelen voor gescande documenten, tabelstructuurherkenning activeren en afbeeldingen extraheren:
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from langchain_core.documents import Document
class DocumentProcessor:
def __init__(self):
# Configure pipeline options for PDF processing
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2.0
We maken een PdfPipelineOptions object om te configureren hoe Docling pdf-bestanden verwerkt. Elke optie stuurt een specifieke verwerkingsmogelijkheid aan: do_ocr schakelt optische tekenherkenning in voor gescande documenten, do_table_structure activeert detectie en parsing van tabellen, generate_picture_images vertelt Docling om ingesloten afbeeldingen als PIL-objecten te extraheren, en images_scale stelt de resolutiemultiplicator in voor geëxtraheerde afbeeldingen.
# Initialize converter with PDF options
self.converter = DocumentConverter(
format_options={InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)}
)De DocumentConverter is Doclings belangrijkste verwerkingsengine. We initialiseren deze met onze pdf-pipeline-opties, verpakt in een PdfFormatOption object, waarmee deze instellingen specifiek aan pdf-invoerbestanden worden gekoppeld.
Laten we bekijken wat elke pipeline-optie doet. De vlag do_ocr activeert optische tekenherkenning. Bij digitale pdf’s met ingesloten tekstlagen slaat Docling OCR automatisch over om tijd te besparen. Voor gescande documenten of afbeeldingen met tekst vertelt deze instelling Docling om visiemodellen te gebruiken om de tekst te extraheren.
De optie do_table_structure schakelt tabelstructuurherkenning in. Zonder dit worden tabellen als platte tekst geëxtraheerd en gaat de opmaak verloren. Met deze optie gebruikt Docling zijn TableFormer AI-model om rijen, kolommen, koppen en celrelaties te identificeren. Deze gestructureerde representatie stelt je in staat om tabellen later als pandas DataFrames te exporteren, waarbij het tabelformaat behouden blijft.
Door generate_picture_images op True te zetten, schakel je afbeeldingsextractie in. Standaard registreert Docling alleen afbeeldingslocaties zonder de daadwerkelijke afbeeldingen te extraheren. Door dit in te schakelen, krijg je PIL-afbeeldingsobjecten die je in je UI kunt tonen of met visiemodellen kunt verwerken. De parameter images_scale bepaalt de extractieresolutie—een waarde van 2.0 verdubbelt de resolutie voor betere kwaliteit bij het tonen van afbeeldingen of extra analyse.
Met de pipeline geconfigureerd kunnen we de methode toevoegen die via Streamlit geüploade bestanden verwerkt. Deze methode handelt de bestandsobjecten van Streamlit af, slaat ze tijdelijk op, draait Doclings conversie en retourneert zowel markdown voor RAG als Docling-documenten voor visualisatie:
import os
import tempfile
from typing import List, Any
def process_uploaded_files(self, uploaded_files) -> tuple[List[Document], List[Any]]:
documents = []
docling_docs = []
temp_dir = tempfile.mkdtemp()
try:
for uploaded_file in uploaded_files:
# Save uploaded file to temporary location
temp_file_path = os.path.join(temp_dir, uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
Streamlit levert geüploade bestanden als in-memory bestandsobjecten, maar Docling heeft echte bestanden op schijf nodig om te verwerken. We maken een tijdelijke map en schrijven elk geüpload bestand daarin weg, met behoud van de oorspronkelijke bestandsnaam.
# Process the document with Docling
result = self.converter.convert(temp_file_path)
# Export to markdown
markdown_content = result.document.export_to_markdown()De aanroep converter.convert() draait Doclings volledige documentanalysepipeline. Het identificeert de documentlay-out, past indien nodig OCR toe, detecteert tabellen en afbeeldingen en bouwt een gestructureerde representatie op. Reken op 20–30 seconden voor verwerking zonder afbeeldingsextractie, of 40–60 seconden met afbeeldingen ingeschakeld.
Na de conversie exporteren we naar markdown, wat schone, LLM-vriendelijke tekst oplevert met behouden opmaak — koppen blijven koppen, lijsten blijven gestructureerd en tabellen worden omgezet naar markdown-tabellen.
# Create LangChain document
doc = Document(
page_content=markdown_content,
metadata={
"filename": uploaded_file.name,
"file_type": uploaded_file.type,
"source": uploaded_file.name,
}
)
documents.append(doc)
# Store the Docling document for structure visualization
docling_docs.append({
"filename": uploaded_file.name,
"doc": result.document
})We maken twee representaties van elk verwerkt document. Het LangChain-Document object bevat de markdown-tekst als page_content met bijbehorende metadata—dit gaat naar de vectorstore voor RAG. Het originele Docling-documentobject wordt apart opgeslagen met de bestandsnaam, waarbij alle structurele informatie (tabellen, afbeeldingen, hiërarchie) behouden blijft voor latere visualisatie.
finally:
import shutil
shutil.rmtree(temp_dir)
return documents, docling_docs
De finally-blok zorgt ervoor dat tijdelijke bestanden worden opgeschoond, ongeacht of de verwerking slaagt of faalt. We retourneren een tuple met beide documentrepresentaties: LangChain-documenten voor het RAG-systeem en Docling-documenten voor structuurvisualisatie.
De documentprocessor is nu klaar. Vervolgens bouwen we de Streamlit-interface waarmee gebruikers bestanden kunnen uploaden en de verwerkingsstatus kunnen zien.
📄 Volledig script: src/structure_visualizer.py
Nu we documenten met Docling kunnen verwerken, hebben we een manier nodig om te visualiseren wat er is geëxtraheerd. Het ruwe Docling-documentobject bevat rijke structurele informatie (koppen, tabellen, afbeeldingen en metadata), maar is in zijn oorspronkelijke vorm niet gebruiksvriendelijk. We bouwen een visualisatielaag die deze data omzet in een interactieve interface met vier weergaven: een overzichtsdashboard, een hiërarchische outline, interactieve tabellen en geëxtraheerde afbeeldingen.
Maak een nieuw bestand structure_visualizer.py in je src/ map. Deze component parseert Doclings documentstructuur en organiseert deze voor weergave.
Begin met het maken van een klasse die een Docling-document omhult en methodes biedt voor het extraheren van verschillende structurele elementen:
from typing import List, Dict, Any
import pandas as pd
from docling_core.types.doc import DoclingDocument
class DocumentStructureVisualizer:
def __init__(self, docling_document: DoclingDocument):
self.doc = docling_document
De initializer neemt een DoclingDocument object (hetzelfde object dat wordt geretourneerd door DocumentConverter.convert()). Dit object bevat alles wat Docling uit het document heeft gehaald. Het attribuut texts bevat alle tekstelementen met hun labels en posities, tables bevat tabeldata met structuurinformatie, pictures slaat afbeeldingsmetadata en daadwerkelijke beelddata op, en pages biedt informatie op paginaniveau.
Documenten hebben meer structuur dan alleen alinea’s. Koppen creëren hiërarchie die lezers helpt door de inhoud te navigeren. Zo haal je deze hiërarchie eruit:
def get_document_hierarchy(self) -> List[Dict[str, Any]]:
hierarchy = []
if not hasattr(self.doc, "texts") or not self.doc.texts:
return hierarchy
for item in self.doc.texts:
label = getattr(item, "label", None)
if label and "header" in label.lower():
text = getattr(item, "text", "")
prov = getattr(item, "prov", [])
page_no = prov[0].page_no if prov else None
hierarchy.append({
"type": label,
"text": text,
"page": page_no,
"level": self._infer_heading_level(label)
})
return hierarchyWe lopen door alle tekstelementen in het document en filteren op items met labels die header bevatten. Elk tekstelement heeft een label dat Docling tijdens de lay-outanalyse toewijst. Veelvoorkomende labels zijn section_header, page_header, title en reguliere text. Het attribuut prov (afkorting van provenance) bevat positioneringsinformatie, waaronder op welke pagina het element staat. We halen de koptekst, het paginanummer en leiden het hiërarchische niveau af uit het labeltype.
Bij het weergeven van de outline bepaalt het kopniveau de inspringing. Een helpermethode koppelt labeltypen aan numerieke niveaus:
def _infer_heading_level(self, label: str) -> int:
if "title" in label.lower():
return 1
elif "section" in label.lower():
return 2
elif "subsection" in label.lower():
return 3
else:
return 4Dit creëert een hiërarchie waarbij documenttitels niveau 1 zijn, sectiekoppen niveau 2, subsecties niveau 3 en alle andere koppen standaard op niveau 4 staan.
Met de documenthiërarchie geëxtraheerd, pakken we nu tabellen aan. In tegenstelling tot eenvoudige textextractie die tabellen in rommelige strings verandert, bewaart Docling hun structuur als een van de meest waardevolle functies:
def get_tables_info(self) -> List[Dict[str, Any]]:
tables_info = []
if not hasattr(self.doc, "tables") or not self.doc.tables:
return tables_info
for i, table in enumerate(self.doc.tables, 1):
try:
df = table.export_to_dataframe(doc=self.doc)
prov = getattr(table, "prov", [])
page_no = prov[0].page_no if prov else None
caption_text = getattr(table, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
tables_info.append({
"table_number": i,
"page": page_no,
"caption": caption,
"dataframe": df,
"shape": df.shape,
"is_empty": df.empty
})
except Exception as e:
print(f"Warning: Could not process table {i}: {e}")
continue
return tables_infoDe methode table.export_to_dataframe(doc=self.doc) zet Doclings tabelrepresentatie om naar een pandas DataFrame. We halen bijschriften en paginanummers op wanneer beschikbaar.
Naast tabellen kan Docling daadwerkelijke beelddata uit documenten extraheren. Dit is een nieuwere functie die verder gaat dan alleen het bijhouden van afbeeldingsposities — het haalt de echte afbeeldingbytes op zodat je ze kunt weergeven. (We hebben dit ingeschakeld in de pipeline-opties van de documentprocessor.)
def get_pictures_info(self) -> List[Dict[str, Any]]:
pictures_info = []
if not hasattr(self.doc, "pictures") or not self.doc.pictures:
return pictures_info
for i, pic in enumerate(self.doc.pictures, 1):
prov = getattr(pic, "prov", [])
if prov:
page_no = prov[0].page_no
bbox = prov[0].bbox
caption_text = getattr(pic, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
pil_image = None
try:
if hasattr(pic, "image") and pic.image is not None:
if hasattr(pic.image, "pil_image"):
pil_image = pic.image.pil_image
except Exception as e:
print(f"Warning: Could not extract image {i}: {e}")
pictures_info.append({
"picture_number": i,
"page": page_no,
"caption": caption,
"pil_image": pil_image,
"bounding_box": {
"left": bbox.l,
"top": bbox.t,
"right": bbox.r,
"bottom": bbox.b
} if bbox else None
})
return pictures_infoElke afbeelding heeft provenance-informatie, waaronder het paginanummer en de coördinaten van de begrenzingsbox. De bounding box definieert de positie van de afbeelding op de pagina met linker-, boven-, rechter- en ondercoördinaten.
Als afbeeldingsextractie is ingeschakeld, heeft het afbeeldingobject een image attribuut met de daadwerkelijke beelddata. We benaderen de PIL-afbeelding via picture.image.pil_image, wat een PIL Image-object teruggeeft dat Streamlit direct kan weergeven met st.image(). De try-except blok behandelt gevallen waarin afbeeldingsextractie faalt of niet was ingeschakeld, en valt dan netjes terug op alleen metadata.
De visualizer heeft nog een methode nodig: een overzicht op hoog niveau dat gebruikers een beeld geeft van de documentstructuur:
def get_document_summary(self) -> Dict[str, Any]:
pages = getattr(self.doc, "pages", {})
texts = getattr(self.doc, "texts", [])
tables = getattr(self.doc, "tables", [])
pictures = getattr(self.doc, "pictures", [])
text_types = {}
for item in texts:
label = getattr(item, "label", "unknown")
text_types[label] = text_types.get(label, 0) + 1
return {
"name": self.doc.name,
"num_pages": len(pages) if pages else 0,
"num_texts": len(texts),
"num_tables": len(tables),
"num_pictures": len(pictures),
"text_types": text_types
}We tellen het aantal pagina’s, tekstelementen, tabellen en afbeeldingen in het document. De dictionary text_types splitst tekstelementen uit naar hun labels en toont hoeveel titels, koppen, alinea’s en andere elementen Docling heeft geïdentificeerd. Dit geeft gebruikers snel een idee van de structuur en complexiteit van het document.
Met de visualizer compleet integreren we deze in Streamlit met vier tabs: Summary, Hierarchy, Tables en Images.
def render_structure_viz():
st.title("📊 Document Structure")
if not st.session_state.docling_docs:
st.info("👈 Please upload and process your documents first!")
return
doc_names = [doc["filename"] for doc in st.session_state.docling_docs]
selected_doc_name = st.selectbox("Select document to analyze:", doc_names)
selected_doc_data = next(
(doc for doc in st.session_state.docling_docs if doc["filename"] == selected_doc_name),
None
)
if not selected_doc_data:
return
visualizer = DocumentStructureVisualizer(selected_doc_data["doc"])
tab1, tab2, tab3, tab4 = st.tabs(["📑 Summary", "🏗️ Hierarchy", "📊 Tables", "🖼️ Images"])We maken een dropdown zodat gebruikers kunnen kiezen welk document ze willen analyseren (handig als meerdere bestanden zijn geüpload). Nadat we het geselecteerde Docling-document uit de session state hebben opgehaald, maken we de visualizer aan en creëren we vier tabs voor de verschillende weergaven.
with tab1:
st.subheader("Document Summary")
summary = visualizer.get_document_summary()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Pages", summary["num_pages"])
with col2:
st.metric("Tables", summary["num_tables"])
with col3:
st.metric("Images", summary["num_pictures"])
with col4:
st.metric("Text Items", summary["num_texts"])
st.subheader("Content Types")
text_types_df = pd.DataFrame([
{"Type": k, "Count": v}
for k, v in sorted(summary["text_types"].items(), key=lambda x: -x[1])
])
st.dataframe(text_types_df, use_container_width=True)
with tab2:
st.subheader("Document Hierarchy")
hierarchy = visualizer.get_document_hierarchy()
if hierarchy:
for item in hierarchy:
indent = " " * (item["level"] - 1)
st.markdown(f"{indent}**{item['text']}** _(Page {item['page']})_")
else:
st.info("No hierarchical structure detected")
with tab3:
st.subheader("Tables")
tables_info = visualizer.get_tables_info()
if tables_info:
for table_data in tables_info:
st.markdown(f"### Table {table_data['table_number']} (Page {table_data['page']})")
if table_data["caption"]:
st.caption(table_data["caption"])
if not table_data["is_empty"]:
st.dataframe(table_data["dataframe"], use_container_width=True)
else:
st.info("Table is empty")
st.divider()
else:
st.info("No tables found in this document")
with tab4:
st.subheader("Images")
pictures_info = visualizer.get_pictures_info()
if pictures_info:
for pic_data in pictures_info:
st.markdown(f"**Image {pic_data['picture_number']}** (Page {pic_data['page']})")
if pic_data["caption"]:
st.caption(pic_data["caption"])
if pic_data["pil_image"] is not None:
st.image(pic_data["pil_image"], use_container_width=True)
else:
st.info("Image data not available")
if pic_data["bounding_box"]:
bbox = pic_data["bounding_box"]
with st.expander("📐 Position Details"):
st.text(
f"Position: ({bbox['left']:.1f}, {bbox['top']:.1f}) - "
f"({bbox['right']:.1f}, {bbox['bottom']:.1f})"
)
st.divider()
else:
st.info("No images found in this document")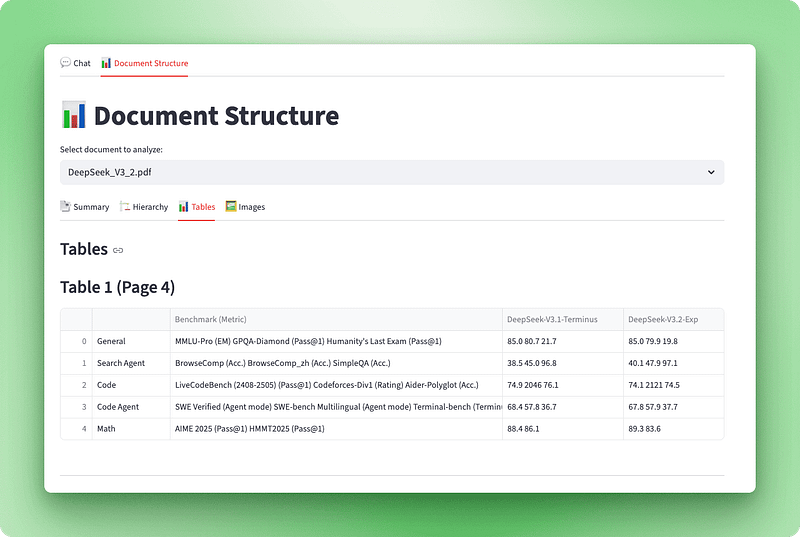
De structuurvisualizer is klaar. Gebruikers kunnen een document uploaden en direct de anatomie zien — hoeveel pagina’s, tabellen en afbeeldingen het bevat, de hiërarchische structuur met koppen en secties, interactieve tabellen om te verkennen en de daadwerkelijke afbeeldingen die uit het document zijn gehaald. Deze transparantie helpt gebruikers te begrijpen wat Docling heeft geëxtraheerd en vergroot het vertrouwen in het systeem.
Met documentverwerking en visualisatie werkend, kunnen we het RAG-systeem bouwen dat vraag-en-antwoord over deze verwerkte documenten mogelijk maakt.
📄 Volledige scripts: src/vectorstore.py | src/tools.py
Met documentverwerking en visualisatie afgerond kunnen we de Q&A-mogelijkheden bouwen. RAG (Retrieval Augmented Generation) stelt gebruikers in staat vragen te stellen over hun documenten. Het systeem zet documenten om in embeddings, slaat deze op in een vectordatabase en haalt relevante chunks op om vragen te beantwoorden.
Deze sectie behandelt twee componenten: een vectorstoremanager die documenten chunkt en embed, en een zoektool die relevante informatie ophaalt.
De vectorstore is waar documentembeddings leven. Wanneer gebruikers een vraag stellen, doorzoeken we deze store naar relevante chunks en geven die als context aan de LLM.
Maak vectorstore.py in je src/ map aan:
from typing import List
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import ChromaDeze imports halen LangChain-componenten binnen voor documentafhandeling, tekstsplitsing, het genereren van embeddings en ChromaDB-vectoropslag. Zo werken ze samen:
class VectorStoreManager:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)We initialiseren twee belangrijke componenten. OpenAI’s text-embedding-3-small model zet tekst om in vectoren. Het is kleiner en sneller dan text-embedding-3-large, wat uitmaakt wanneer je honderden chunks embed. De RecursiveCharacterTextSplitter breekt documenten op in chunks van 1000 tekens met 100 tekens overlap, zodat belangrijke informatie op chunkgrenzen niet midden in een zin wordt afgeknipt.
1000 tekens balanceert precisie en context — kleinere chunks geven preciezere retrieval maar verliezen context, grotere chunks behouden context maar verdunnen relevantie.
Voeg de chunkingmethode toe:
def chunk_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents into smaller chunks for better retrieval."""
chunks = self.text_splitter.split_documents(documents)
return chunksDe splitter handelt metadata automatisch af en behoudt informatie uit de originele documenten. Elke chunk weet uit welk bestand hij komt, wat belangrijk wordt wanneer de agent bronnen citeert in zijn antwoorden.
Voeg nu de methode toe die de vectorstore aanmaakt:
def create_vectorstore(self, chunks: List[Document]) -> Chroma:
"""Create a Chroma vector store from document chunks."""
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
collection_name="documents"
)
return vectorstoreChromaDB doet het zware werk. Het embed elke chunk met ons embeddingsmodel en slaat de vectoren in het geheugen op. Wanneer je een similariteitszoekopdracht doet, berekent ChromaDB de cosinusgelijkenis tussen de queryvector en alle documentvectoren en retourneert de dichtstbijzijnde matches.
Met de vectorstore klaar om embeddings te verwerken, moeten we de agent een manier geven om deze te bevragen. Tools zijn functies die de LLM kan aanroepen wanneer het informatie nodig heeft die het zelf niet heeft.
Maak tools.py in je src/ map:
from typing import Annotated
from langchain_core.tools import tool
def create_search_tool(vectorstore):
"""Create a search tool that has access to the vector store."""Deze factoryfunctie gebruikt een closurepatroon: hij ontvangt een vectorstore en retourneert een tool die deze kan doorzoeken. De tool behoudt toegang tot de vectorstore zonder globale variabelen nodig te hebben.
@tool
def search_documents(query: Annotated[str, "The search query or question about the documents"]) -> str:
"""Search the uploaded documents for relevant information."""De @tool decorator maakt van deze functie een LangChain-tool die de agent kan aanroepen. De typehint Annotated beschrijft de parameter en helpt de LLM te begrijpen wat er moet worden doorgegeven bij het aanroepen van de tool.
try:
results = vectorstore.similarity_search(query, k=8)
if not results:
return "No relevant information found in the documents for this query."We halen 8 vergelijkbare chunks op (k=8) uit de vectorstore. Dit geeft de LLM voldoende context zonder die te overspoelen met redundante informatie. Het juiste aantal hangt af van je documenttype—technische docs met dichte informatie werken mogelijk beter met minder chunks (k=4–6), terwijl narratieve documenten baat kunnen hebben bij meer (k=10–12).
context_parts = []
for i, doc in enumerate(results, 1):
source = doc.metadata.get("filename", doc.metadata.get("source", "Unknown source"))
content = doc.page_content.strip()
context_parts.append(
f"[Source {i}: {source}]\n"
f"Content: {content}\n"
)
return "\n---\n".join(context_parts)We formatteren elke chunk met de bronnaam van het bestand en voegen ze samen met scheidingstekens. De LLM ontvangt deze gestructureerde context en gebruikt die om antwoorden te genereren met bronvermelding.
except Exception as e:
return f"Error searching documents: {str(e)}"
return search_documentsFoutenafhandeling zorgt ervoor dat de agent een duidelijke boodschap krijgt als zoeken faalt, in plaats van te crashen. De functie retourneert de geconfigureerde tool die klaar is voor gebruik door de agent.
De vectorstore en zoektool zijn nu klaar. Vervolgens bouwen we de LangGraph-agent die retrieval en generatie orkestreert om gebruikersvragen te beantwoorden.
📄 Volledig script: src/agent.py
De zoektool kan de vectorstore bevragen, maar heeft een slimme coördinator nodig. De LangGraph-agent beslist wanneer er gezocht moet worden, interpreteert resultaten en genereert natuurlijke antwoorden. We implementeren ook streaming om voortgang in realtime te tonen.
De agent ontvangt vragen, beslist wanneer documenten te doorzoeken en genereert antwoorden op basis van opgehaalde context.
Maak agent.py in je src/ map:
from typing import List
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaverWe importeren componenten voor toolafhandeling, OpenAI’s chatmodellen, LangGraphs ReAct-agentimplementatie en conversatiegeheugen.
SYSTEM_PROMPT = """You are a helpful document intelligence assistant. You have access to documents that have been uploaded and processed.
GUIDELINES:
- Use the search_documents tool to find relevant information
- Keep it simple: one well-crafted search is usually sufficient
- Only search again if the first results are clearly incomplete
- Provide clear, accurate answers based on the document contents
- Always cite your sources with filenames
- If information isn't found, say so clearly
- Be concise but thorough
When answering:
1. Search the documents with a focused query
2. Synthesize a clear answer from the results
3. Include source citations (filenames)
4. Only search again if absolutely necessary
"""
def create_documentation_agent(tools: List[BaseTool], model_name: str = "gpt-4o-mini"):
"""Create a document intelligence assistant agent using LangGraph."""
llm = ChatOpenAI(model=model_name, temperature=0)
memory = MemorySaver()We gebruiken gpt-4o-mini in plaats van gpt-5 omdat het sneller en goedkoper is en toch document-Q&A goed aankan. De temperatuur staat op 0 voor consistente, feitelijke antwoorden. De MemorySaver geeft de agent conversatiegeheugen, zodat hij eerdere uitwisselingen binnen een sessie onthoudt.
agent = create_react_agent(
llm,
tools=tools,
prompt=SYSTEM_PROMPT,
checkpointer=memory
)
return agentLangGraphs create_react_agent implementeert het ReAct-patroon (Reasoning + Acting). De agent redeneert over wat er moet gebeuren, onderneemt actie met tools, observeert resultaten en herhaalt dit totdat er een antwoord is. Dit patroon werkt goed voor RAG omdat de agent kan beslissen wanneer te zoeken en hoe de opgehaalde context te gebruiken.
De agent kan nu zoeken en antwoorden genereren, maar gebruikers zouden niet 10 seconden naar een leeg scherm moeten staren terwijl hij werkt. Streaming toont de voortgang in realtime — eerst verschijnt een “denken”-indicator, dan “zoeken”, en vervolgens het antwoord dat token voor token verschijnt.
Werk je render_chat() functie in app.py bij om de responsafhandeling te voltooien die we eerder met TODO markeerden:
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)We voegen het bericht van de gebruiker toe aan de gespreksgeschiedenis en tonen het in de chatinterface.
with st.chat_message("assistant"):
status_placeholder = st.empty()
message_placeholder = st.empty()
try:
config = {"configurable": {"thread_id": "document_chat"}}We maken placeholders voor de statusindicator en het antwoordbericht. De config bevat een thread-ID die LangGraph gebruikt om het conversatiegeheugen over beurten heen te behouden.
def generate_response():
"""Generator that yields tokens from LangGraph stream."""
status_placeholder.markdown("🤔 **Thinking...**")
first_content_token = True
tool_call_detected = False
final_answer_started = FalseDeze generatorfunctie verwerkt de streamoutput van LangGraph. We volgen de status met flags om de juiste statusberichten te tonen terwijl de agent vordert door zijn workflow.
for msg, metadata in st.session_state.agent.stream(
{"messages": [HumanMessage(content=prompt)]},
config=config,
stream_mode="messages",
):
langgraph_node = metadata.get("langgraph_node", "")De parameter stream_mode="messages" geeft ons echte LLM-tokens terwijl ze worden gegenereerd, niet alleen eindoutputs. LangGraph zendt events uit gedurende de uitvoering van de agent—wanneer hij begint te denken, wanneer hij tools aanroept en wanneer hij tekst genereert.
if "tools" in langgraph_node.lower() or "tool" in langgraph_node.lower():
if not tool_call_detected:
status_placeholder.markdown("🔍 **Searching documents...**")
tool_call_detected = True
continue
if "agent" in langgraph_node.lower() and hasattr(msg, "content"):
content = msg.content
if content:
if first_content_token:
status_placeholder.markdown("💬 **Generating answer...**")
first_content_token = False
final_answer_started = True
if final_answer_started:
yield contentWanneer het agentnode het uiteindelijke antwoord begint te genereren, werken we de status bij en beginnen we contenttokens te leveren. Elk token wordt meteen weergegeven, wat een vloeiend type-effect geeft.
status_placeholder.empty()
with message_placeholder.container():
full_response = st.write_stream(generate_response())Na het streamen wissen we de statusindicator. Streamlits st.write_stream() verzorgt de token-voor-token weergave automatisch, verzamelt tokens en werkt de UI soepel bij. Het resultaat is een chatervaring die responsief aanvoelt en gebruikers vertrouwen geeft dat het systeem werkt.
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error generating response: {str(e)}")We slaan het volledige antwoord op in de berichtengeschiedenis en handelen eventuele fouten af die tijdens het streamen optreden.
Het RAG-systeem is compleet. Gebruikers kunnen nu documenten uploaden, ze met Docling verwerken, hun structuur verkennen en natuurlijke gesprekken over de inhoud voeren. De agent zoekt intelligent, citeert bronnen en streamt antwoorden voor een soepele ervaring.
Je Document Intelligence Assistant is klaar. Voordat je deze implementeert of deelt, moet je de applicatie testen om te verifiëren dat alles correct werkt.
Start de applicatie vanuit de hoofdmap van je project:
streamlit run app.pyStreamlit opent een browservenster op http://localhost:8501. Je zou de zijbalk met uploadbesturingselementen en twee tabs in het hoofdgedeelte moeten zien.
Upload een voorbeeld-pdf met tabellen en afbeeldingen om de volledige verwerkingsmogelijkheden te testen:
Let op de verwerkingsindicatoren:
Als alles klaar is, zie je “✅ Ready to chat!” in de statussectie.
Schakel over naar het tabblad “Document Structure” om te verifiëren dat Docling alles correct heeft geëxtraheerd:
Als tabellen leeg worden weergegeven of afbeeldingen niet verschijnen, controleer dan of je do_table_structure=True en generate_picture_images=True hebt ingeschakeld in de pipeline-opties.
Ga terug naar het tabblad “Chat” en test de agent met deze voorbeeldvragen:
Goede startvragen:
Documentspecifieke vragen (pas aan op basis van je document):
Vervolgvraag om conversatiegeheugen te testen:
Let op directe antwoorden uit je document met bronvermelding, vloeiende streamingtokens en statusindicatoren (“Thinking…”, “Searching documents…”, “Generating answer…”). Let op generieke antwoorden die niet uit je document komen, ontbrekende bronvermeldingen, trage reacties zonder statusindicatoren of fouten over ontbrekende API-sleutels.
“No module named ‘docling’”-fout
pip install docling langchain langchain-openai langchain-chroma langgraph streamlit streamlit-extras pandas python-dotenv
“OpenAI API key not found”-fout
Controleer of het .env bestand bestaat met OPENAI_API_KEY=your-key-here
Herstart Streamlit
Verwerken duurt langer dan 60 seconden
Agent geeft generieke antwoorden
Tabellen worden als lege DataFrames weergegeven
Bevestig do_table_structure=True in PdfPipelineOptions
Probeer een andere pdf met native tabellen
De applicatie is nu gevalideerd en klaar voor gebruik. Je kunt hem testen met je eigen documenten of deployen voor anderen.
Je hebt nu een werkende Document Intelligence Assistant die pdf’s, Word-documenten, PowerPoint-presentaties en HTML-bestanden verwerkt met behoud van hun structuur. Docling extraheert tekst, tabellen, afbeeldingen en documenthiërarchie die gebruikers kunnen verkennen via interactieve tabs. Het RAG-systeem, gecombineerd met ChromaDB en LangGraph, maakt conversationele Q&A met bronvermelding mogelijk, live gestreamd. Dit laat zien hoe structuurbewuste documentverwerking de kwaliteit van retrieval verbetert ten opzichte van basis-textextractie. De complete broncode is beschikbaar in de GitHub-repository.
Deze basis opent meerdere richtingen voor uitbreiding:
Voor een diepere verkenning van RAG-systemen en LLM-applicaties behandelt onze AI Engineering track de concepten en patronen die je hier hebt gebruikt.
Leer met DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
