
Tracks
Nhà phát triển Python
28 giờ
Các công cụ trích xuất PDF truyền thống như pypdf hoặc PDFMiner cho bạn văn bản thô nhưng làm mất cấu trúc tài liệu. Bảng biểu biến thành văn bản lộn xộn, tiêu đề lẫn với phần nội dung, và hình ảnh biến mất. Với các hệ thống RAG, dữ liệu bừa bộn này dẫn đến khả năng truy xuất kém và câu trả lời thiếu tin cậy. Docling là bộ công cụ mã nguồn mở từ IBM Research sử dụng các mô hình thị giác máy tính để hiểu bố cục tài liệu, giữ nguyên bảng biểu, hình ảnh, tiêu đề và cấu trúc. Nó xử lý tài liệu nhanh hơn đến 30 lần so với các phương pháp dựa trên OCR truyền thống và chạy cục bộ trên máy của bạn.
Trong hướng dẫn này, chúng ta sẽ dùng Docling để xây dựng một Trợ lý Trí tuệ Tài liệu — một ứng dụng web Streamlit cho phép bạn tải tài liệu lên, trực quan hóa cấu trúc của chúng và đặt câu hỏi bằng chatbot vận hành bởi RAG. Bạn sẽ học cách xử lý tài liệu đa định dạng với Docling, trích xuất và hiển thị bảng biểu và hình ảnh, xây dựng kho vector với ChromaDB, và tạo tác tử hội thoại với LangGraph. Cuối cùng, bạn sẽ có một ứng dụng hoạt động biến tài liệu phức tạp thành dữ liệu có cấu trúc và cho phép hỏi đáp thông minh.
Xem trước ứng dụng:
Trực quan hóa cấu trúc tài liệu:
Trước khi bắt đầu, bạn nên có:
Kỹ năng kỹ thuật: Thoải mái với các lớp Python, decorator, type hint và context manager. Chúng ta sẽ dùng async và các mẫu factory xuyên suốt. Cần hiểu cách mô hình ngôn ngữ lớn hoạt động với prompt, token và embedding. Quen thuộc với hệ thống RAG và cơ sở dữ liệu vector là hữu ích nhưng không bắt buộc — chúng ta sẽ giải thích các khái niệm cốt lõi trong quá trình xây dựng.
Thiết lập môi trường phát triển: Python 3.10 trở lên với pip để quản lý gói. Khuyến nghị dùng trình soạn thảo như VS Code. Bạn sẽ cần khóa API OpenAI từ platform.openai.com — chi phí xử lý khoảng $0,10–0,20 mỗi tài liệu.
Thời gian thực hiện: Dự kiến 60–90 phút để hoàn thành, gồm đọc giải thích, viết mã và kiểm thử ứng dụng. Hướng dẫn này giả định trình độ Python trung cấp.
Hầu hết công cụ xử lý tài liệu xem PDF như tệp ảnh hoặc luồng văn bản. Chúng hoặc chạy OCR trên mọi trang, hoặc trích xuất văn bản thuần mà không hiểu nội dung. Docling tiếp cận khác. Đây là bộ công cụ mã nguồn mở từ IBM Research dùng mô hình thị giác máy tính để hiểu cấu trúc tài liệu như con người.
Khi bạn đưa tài liệu vào Docling, hai mô hình AI sẽ phân tích:
Những mô hình này hiểu rằng tài liệu không chỉ là một khối văn bản. Nó có phân cấp, mối quan hệ và ý nghĩa.
Sự hiểu biết về cấu trúc rất quan trọng cho hệ thống RAG. Khi bạn xây dựng ứng dụng RAG, chất lượng xử lý tài liệu ảnh hưởng trực tiếp đến độ chính xác truy xuất. Nếu trích xuất PDF biến một bảng tài chính thành văn bản lộn xộn, tìm kiếm vector sẽ trả về dữ liệu rác. Docling giữ nguyên cấu trúc, vì vậy khi bạn chia khối và nhúng tài liệu, bạn đang làm việc với dữ liệu sạch, có tổ chức.
Docling hỗ trợ nhiều định dạng tài liệu sẵn có:
Bạn cũng có thể bật OCR cho tài liệu scan bằng các engine như EasyOCR, Tesseract hoặc RapidOCR. Bộ công cụ xuất ra nhiều định dạng gồm Markdown (tốt cho LLM), JSON (cho pipeline dữ liệu có cấu trúc) và DocTags (định dạng lưu các phần tử phức tạp như công thức toán và khối mã).
Vượt ra ngoài sự linh hoạt định dạng, Docling còn có ưu thế hiệu năng. Xử lý tài liệu dựa trên OCR truyền thống chậm vì coi mỗi trang như một ảnh cần nhận dạng ký tự. Docling bỏ qua bước này với tài liệu số, giúp xử lý nhanh hơn nhiều. Nó chạy cục bộ trên phần cứng phổ thông, nên bạn không tốn chi phí API hay gửi tài liệu nhạy cảm đến dịch vụ bên thứ ba. Tốc độ xử lý thay đổi theo độ phức tạp tài liệu, số trang và cấu hình phần cứng, thường từ dưới một giây đến vài giây mỗi trang trên phần cứng hiện đại.
IBM tiếp tục cải thiện năng lực của Docling. Họ đã phát hành Granite-Docling, một mô hình thị giác-ngôn ngữ 258 triệu tham số xuất sắc ở bố cục phức tạp và hỗ trợ đa ngôn ngữ thử nghiệm (tiếng Anh là chính, và hỗ trợ giai đoạn đầu cho tiếng Ả Rập, Trung, Nhật). Bộ công cụ cũng hỗ trợ trích xuất hình ảnh với độ phân giải cấu hình được, chúng ta sẽ dùng trong ứng dụng để hiển thị ảnh thật từ PDF bên cạnh nội dung văn bản.
Với bài toán của chúng ta, Docling hợp lý vì chúng ta cần dữ liệu có cấu trúc, không chỉ văn bản thô. Nếu bạn chỉ cần trích xuất văn bản cơ bản, công cụ đơn giản như pypdf có thể đủ. Nhưng vì chúng ta đang xây ứng dụng AI xử lý tài liệu để phân tích và hội thoại, xử lý nhận biết cấu trúc của Docling là lựa chọn tốt hơn. Nó đặc biệt hữu ích với tài liệu kỹ thuật, bài báo nghiên cứu hoặc báo cáo kinh doanh, nơi bảng biểu và bố cục rất quan trọng.
Trước khi xây trình xử lý tài liệu, bạn cần thiết lập cấu trúc dự án và cài đặt gói cần thiết. Phần này bao gồm bước đầu: tạo thư mục, cài phụ thuộc và cấu hình khóa API.
Bắt đầu bằng cách tạo thư mục mới cho dự án:
mkdir docling-demo
cd docling-demoBên trong thư mục này, tạo thư mục src/ cho các mô-đun Python:
mkdir src
touch src/__init__.pyTệp __init__.py cho Python biết src/ là một package, cho phép import như from src.document_processor import DocumentProcessor.
Cấu trúc dự án của bạn:
docling-demo/
├── src/
│ └── __init__.pyTạo tệp requirements.txt ở thư mục gốc dự án:
docling>=2.55.0
langchain-docling>=0.1.0
langchain>=0.3.0
langchain-openai>=0.2.0
langgraph>=0.2.0
langchain-chroma>=0.1.0
streamlit>=1.28.0
streamlit-extras>=0.7.0
python-dotenv>=1.0.0
chromadb>=0.4.22
tiktoken>=0.5.0
pandas>=2.0.0
numpy<2Ràng buộc numpy<2 tồn tại vì các phụ thuộc của Docling (TensorFlow và Transformers) yêu cầu NumPy 1.x.
Cài đặt các gói:
pip install -r requirements.txtLần cài đầu tiên mất vài phút vì Docling tải xuống các mô hình AI tiền huấn luyện (khoảng 500MB). Những mô hình này xử lý phân tích bố cục và nhận diện cấu trúc bảng. Chúng được cache cục bộ, nên các lần chạy sau nhanh hơn.
Tạo tệp .env để lưu khóa API OpenAI của bạn:
OPENAI_API_KEY=your-openai-api-key-hereLấy khóa API từ platform.openai.com. Bạn sẽ cần nó cho embeddings và tác tử chat.
Tạo tệp mẫu .env.example:
OPENAI_API_KEY=your-openai-api-key-hereThêm .gitignore để tránh commit dữ liệu nhạy cảm:
# Environment variables
.env
# Python
__pycache__/
*.py[cod]
*.so
venv/
*.egg-info/
# Chroma
chroma_db/Tạo app.py ở thư mục gốc dự án. Chúng ta sẽ xây tệp này dần trong hướng dẫn. Tạm thời, thêm import và cấu hình cơ bản:
import streamlit as st
from dotenv import load_dotenv
# Load environment variables
load_dotenv()
# Page configuration
st.set_page_config(
page_title="Document Intelligence Assistant",
page_icon="📄",
layout="wide"
)
st.title("Document Intelligence Assistant")
st.write("Application setup complete. We'll build the functionality next.")Kiểm tra thiết lập của bạn:
streamlit run app.pyStreamlit mở cửa sổ trình duyệt tại http://localhost:8501 hiển thị trang cơ bản của bạn.
Cấu trúc dự án cuối cùng của bạn (trước khi thêm script mới ở các phần sau):
docling-demo/
├── .env
├── .env.example
├── .gitignore
├── requirements.txt
├── app.py
└── src/
└── __init__.pyVới môi trường sẵn sàng, chúng ta có thể xây trình xử lý tài liệu dùng Docling để trích xuất cấu trúc từ tệp tải lên.
> Lưu ý: Các phần bên dưới sẽ chia nhỏ script ứng dụng theo từng khối. Vì vậy, để có cái nhìn toàn cảnh và dễ theo dõi, chúng tôi khuyến nghị mở kho GitHub của dự án này trong một thẻ riêng.
📄 Script đầy đủ: src/document_processor.py
Trình xử lý tài liệu là nơi Docling làm việc. Thành phần này nhận các tệp tải lên và chuyển chúng thành dữ liệu có cấu trúc để dùng cho cả RAG và trực quan hóa. Chúng ta cần hai đầu ra từ quá trình này: văn bản markdown sạch cho kho vector và đối tượng tài liệu Docling gốc giữ tất cả thông tin cấu trúc như bảng và hình ảnh.
Hãy tạo điều này bằng cách tạo tệp document_processor.py mới trong thư mục src/ của bạn. Chúng ta sẽ tạo lớp DocumentProcessor để cấu hình pipeline xử lý của Docling và xử lý tệp tải lên.
Docling cho phép bạn kiểm soát cách nó xử lý tài liệu qua các tùy chọn pipeline. Với PDF, bạn có thể bật OCR cho tài liệu scan, kích hoạt nhận diện cấu trúc bảng và trích xuất hình ảnh:
from docling.document_converter import DocumentConverter, PdfFormatOption
from docling.datamodel.base_models import InputFormat
from docling.datamodel.pipeline_options import PdfPipelineOptions
from langchain_core.documents import Document
class DocumentProcessor:
def __init__(self):
# Configure pipeline options for PDF processing
pipeline_options = PdfPipelineOptions()
pipeline_options.do_ocr = True
pipeline_options.do_table_structure = True
pipeline_options.generate_picture_images = True
pipeline_options.images_scale = 2.0
Chúng ta tạo một đối tượng PdfPipelineOptions để cấu hình cách Docling xử lý tệp PDF. Mỗi tùy chọn điều khiển một khả năng cụ thể: do_ocr bật nhận dạng ký tự quang học cho tài liệu scan, do_table_structure kích hoạt phát hiện và phân tích bảng, generate_picture_images yêu cầu Docling trích xuất hình ảnh nhúng dưới dạng đối tượng PIL, và images_scale đặt hệ số độ phân giải cho hình ảnh trích xuất.
# Initialize converter with PDF options
self.converter = DocumentConverter(
format_options={InputFormat.PDF: PdfFormatOption(pipeline_options=pipeline_options)}
)DocumentConverter là bộ máy xử lý chính của Docling. Chúng ta khởi tạo nó với tùy chọn pipeline cho PDF được bọc trong PdfFormatOption, ánh xạ các thiết lập này riêng cho tệp đầu vào PDF.
Hãy xem từng tùy chọn pipeline làm gì. Cờ do_ocr bật OCR. Khi xử lý PDF số có lớp văn bản nhúng, Docling tự động bỏ qua OCR để tiết kiệm thời gian. Với tài liệu scan hoặc hình ảnh chứa văn bản, thiết lập này yêu cầu Docling chạy mô hình thị giác để trích xuất văn bản.
Tùy chọn do_table_structure bật nhận diện cấu trúc bảng. Không có tùy chọn này, bảng sẽ được trích như văn bản thuần và mất định dạng. Khi bật, Docling dùng mô hình AI TableFormer để nhận diện hàng, cột, tiêu đề và mối quan hệ ô. Biểu diễn có cấu trúc này cho phép bạn xuất bảng dưới dạng pandas DataFrame sau đó, giữ nguyên định dạng bảng.
Đặt generate_picture_images là True bật trích xuất hình ảnh. Mặc định, Docling chỉ ghi nhận vị trí ảnh mà không trích xuất ảnh thực. Bật tùy chọn này sẽ cho bạn các đối tượng ảnh PIL có thể hiển thị trên UI hoặc xử lý bằng mô hình thị giác. Tham số images_scale điều khiển độ phân giải trích xuất — giá trị 2.0 nhân đôi độ phân giải để hiển thị đẹp hơn hoặc phục vụ phân tích thêm.
Với pipeline đã cấu hình, chúng ta thêm phương thức xử lý tệp tải lên qua Streamlit. Phương thức này xử lý đối tượng tệp của Streamlit, lưu tạm, chạy chuyển đổi của Docling, và trả về cả markdown cho RAG và tài liệu Docling để trực quan hóa:
import os
import tempfile
from typing import List, Any
def process_uploaded_files(self, uploaded_files) -> tuple[List[Document], List[Any]]:
documents = []
docling_docs = []
temp_dir = tempfile.mkdtemp()
try:
for uploaded_file in uploaded_files:
# Save uploaded file to temporary location
temp_file_path = os.path.join(temp_dir, uploaded_file.name)
with open(temp_file_path, "wb") as f:
f.write(uploaded_file.getbuffer())
Streamlit cung cấp tệp tải lên dưới dạng đối tượng tệp trong bộ nhớ, nhưng Docling cần tệp thực trên đĩa để xử lý. Chúng ta tạo thư mục tạm và ghi từng tệp vào đó, giữ nguyên tên gốc.
# Process the document with Docling
result = self.converter.convert(temp_file_path)
# Export to markdown
markdown_content = result.document.export_to_markdown()Lời gọi converter.convert() chạy toàn bộ pipeline phân tích tài liệu của Docling. Nó nhận diện bố cục, áp dụng OCR nếu cần, phát hiện bảng và hình ảnh, và xây dựng biểu diễn có cấu trúc. Dự kiến 20–30 giây nếu không trích xuất ảnh, hoặc 40–60 giây nếu bật trích ảnh.
Sau khi chuyển đổi xong, chúng ta xuất ra định dạng markdown để có văn bản sạch, thân thiện với LLM với định dạng được giữ đúng — tiêu đề vẫn là tiêu đề, danh sách giữ cấu trúc, và bảng chuyển thành bảng markdown.
# Create LangChain document
doc = Document(
page_content=markdown_content,
metadata={
"filename": uploaded_file.name,
"file_type": uploaded_file.type,
"source": uploaded_file.name,
}
)
documents.append(doc)
# Store the Docling document for structure visualization
docling_docs.append({
"filename": uploaded_file.name,
"doc": result.document
})Chúng ta tạo hai biểu diễn cho mỗi tài liệu đã xử lý. Đối tượng Document của LangChain chứa văn bản markdown trong page_content kèm metadata — đi vào kho vector cho RAG. Đối tượng tài liệu Docling gốc được lưu riêng với tên tệp, giữ mọi thông tin cấu trúc (bảng, hình, phân cấp) để trực quan hóa về sau.
finally:
import shutil
shutil.rmtree(temp_dir)
return documents, docling_docs
Khối finally đảm bảo tệp tạm được dọn dẹp dù xử lý thành công hay thất bại. Chúng ta trả về một tuple gồm cả hai biểu diễn: tài liệu LangChain cho hệ RAG và tài liệu Docling cho trực quan hóa cấu trúc.
Trình xử lý tài liệu đã sẵn sàng. Tiếp theo, chúng ta sẽ xây giao diện Streamlit cho phép người dùng tải tệp và xem trạng thái xử lý.
📄 Script đầy đủ: src/structure_visualizer.py
Giờ chúng ta đã có thể xử lý tài liệu với Docling, cần một cách để trực quan hóa những gì đã trích xuất. Đối tượng tài liệu Docling thô chứa thông tin cấu trúc phong phú (tiêu đề, bảng, hình ảnh và metadata) nhưng không thân thiện với người dùng ở dạng gốc. Chúng ta sẽ xây lớp trực quan hóa chuyển đổi dữ liệu này thành giao diện tương tác với bốn chế độ xem: bảng điều khiển tóm tắt, dàn ý phân cấp, bảng tương tác và hình ảnh trích xuất.
Tạo tệp mới tên structure_visualizer.py trong thư mục src/. Thành phần này sẽ phân tích cấu trúc tài liệu của Docling và tổ chức để hiển thị.
Bắt đầu bằng cách tạo lớp bao bọc tài liệu Docling và cung cấp phương thức trích xuất các phần tử cấu trúc khác nhau:
from typing import List, Dict, Any
import pandas as pd
from docling_core.types.doc import DoclingDocument
class DocumentStructureVisualizer:
def __init__(self, docling_document: DoclingDocument):
self.doc = docling_document
Hàm khởi tạo nhận một đối tượng DoclingDocument (cùng loại với đối tượng trả về bởi DocumentConverter.convert()). Đối tượng này chứa mọi thứ Docling trích xuất từ tài liệu. Thuộc tính texts chứa tất cả phần tử văn bản với nhãn và vị trí, tables giữ dữ liệu bảng với thông tin cấu trúc, pictures lưu metadata hình ảnh và dữ liệu ảnh thực, và pages cung cấp thông tin cấp trang.
Tài liệu có cấu trúc vượt qua các đoạn văn. Tiêu đề tạo phân cấp giúp người đọc điều hướng nội dung. Đây là cách trích xuất phân cấp này:
def get_document_hierarchy(self) -> List[Dict[str, Any]]:
hierarchy = []
if not hasattr(self.doc, "texts") or not self.doc.texts:
return hierarchy
for item in self.doc.texts:
label = getattr(item, "label", None)
if label and "header" in label.lower():
text = getattr(item, "text", "")
prov = getattr(item, "prov", [])
page_no = prov[0].page_no if prov else None
hierarchy.append({
"type": label,
"text": text,
"page": page_no,
"level": self._infer_heading_level(label)
})
return hierarchyChúng ta lặp qua tất cả phần tử văn bản trong tài liệu, lọc những phần có nhãn chứa header. Mỗi phần tử văn bản có thuộc tính label do Docling gán trong quá trình phân tích bố cục. Các nhãn phổ biến gồm section_header, page_header, title, và text thông thường. Thuộc tính prov (viết tắt của provenance) chứa thông tin vị trí, gồm số trang phần tử xuất hiện. Chúng ta trích tiêu đề, số trang, và suy ra cấp phân cấp từ loại nhãn.
Khi hiển thị dàn ý, cấp tiêu đề quyết định thụt lề. Một hàm trợ giúp ánh xạ loại nhãn sang cấp số:
def _infer_heading_level(self, label: str) -> int:
if "title" in label.lower():
return 1
elif "section" in label.lower():
return 2
elif "subsection" in label.lower():
return 3
else:
return 4Điều này tạo phân cấp trong đó tiêu đề tài liệu là cấp 1, tiêu đề phần là cấp 2, tiêu đề tiểu mục là cấp 3, và các tiêu đề khác mặc định cấp 4.
Với phân cấp tài liệu đã trích xuất, hãy xử lý bảng. Không giống trích xuất văn bản đơn giản biến bảng thành chuỗi lộn xộn, Docling giữ nguyên cấu trúc của chúng — một trong những tính năng giá trị nhất:
def get_tables_info(self) -> List[Dict[str, Any]]:
tables_info = []
if not hasattr(self.doc, "tables") or not self.doc.tables:
return tables_info
for i, table in enumerate(self.doc.tables, 1):
try:
df = table.export_to_dataframe(doc=self.doc)
prov = getattr(table, "prov", [])
page_no = prov[0].page_no if prov else None
caption_text = getattr(table, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
tables_info.append({
"table_number": i,
"page": page_no,
"caption": caption,
"dataframe": df,
"shape": df.shape,
"is_empty": df.empty
})
except Exception as e:
print(f"Warning: Could not process table {i}: {e}")
continue
return tables_infoPhương thức table.export_to_dataframe(doc=self.doc) chuyển biểu diễn bảng của Docling thành pandas DataFrame. Chúng ta trích xuất chú thích và số trang khi có.
Ngoài bảng, Docling có thể trích xuất dữ liệu ảnh thực từ tài liệu. Đây là tính năng mới hơn, vượt qua việc chỉ theo dõi vị trí ảnh — nó truy xuất byte ảnh thực để bạn hiển thị. (Chúng ta đã bật tính năng này trong tùy chọn pipeline của trình xử lý tài liệu.)
def get_pictures_info(self) -> List[Dict[str, Any]]:
pictures_info = []
if not hasattr(self.doc, "pictures") or not self.doc.pictures:
return pictures_info
for i, pic in enumerate(self.doc.pictures, 1):
prov = getattr(pic, "prov", [])
if prov:
page_no = prov[0].page_no
bbox = prov[0].bbox
caption_text = getattr(pic, "caption_text", None)
caption = caption_text if caption_text and not callable(caption_text) else None
pil_image = None
try:
if hasattr(pic, "image") and pic.image is not None:
if hasattr(pic.image, "pil_image"):
pil_image = pic.image.pil_image
except Exception as e:
print(f"Warning: Could not extract image {i}: {e}")
pictures_info.append({
"picture_number": i,
"page": page_no,
"caption": caption,
"pil_image": pil_image,
"bounding_box": {
"left": bbox.l,
"top": bbox.t,
"right": bbox.r,
"bottom": bbox.b
} if bbox else None
})
return pictures_infoMỗi hình ảnh có thông tin nguồn gốc, gồm số trang và tọa độ bounding box. Bounding box xác định vị trí ảnh trên trang bằng các tọa độ trái, trên, phải, dưới.
Khi bật trích xuất ảnh, đối tượng hình có thuộc tính image chứa dữ liệu ảnh thực. Chúng ta truy cập ảnh PIL qua picture.image.pil_image, trả về đối tượng PIL Image mà Streamlit có thể hiển thị trực tiếp với st.image(). Khối try-except xử lý trường hợp trích xuất ảnh thất bại hoặc không bật, chuyển sang chỉ hiển thị metadata.
Visualizer cần thêm một phương thức: tóm tắt cấp cao giúp người dùng có cái nhìn tổng quan về cấu trúc tài liệu:
def get_document_summary(self) -> Dict[str, Any]:
pages = getattr(self.doc, "pages", {})
texts = getattr(self.doc, "texts", [])
tables = getattr(self.doc, "tables", [])
pictures = getattr(self.doc, "pictures", [])
text_types = {}
for item in texts:
label = getattr(item, "label", "unknown")
text_types[label] = text_types.get(label, 0) + 1
return {
"name": self.doc.name,
"num_pages": len(pages) if pages else 0,
"num_texts": len(texts),
"num_tables": len(tables),
"num_pictures": len(pictures),
"text_types": text_types
}Chúng ta đếm số trang, phần tử văn bản, bảng, và hình ảnh trong tài liệu. Từ điển text_types phân loại phần tử văn bản theo nhãn, cho thấy có bao nhiêu tiêu đề, đoạn văn và phần tử khác mà Docling nhận diện. Điều này cho người dùng cảm nhận nhanh về cấu trúc và độ phức tạp của tài liệu.
Với visualizer hoàn tất, hãy tích hợp vào Streamlit với bốn tab: Summary, Hierarchy, Tables, và Images.
def render_structure_viz():
st.title("📊 Document Structure")
if not st.session_state.docling_docs:
st.info("👈 Please upload and process your documents first!")
return
doc_names = [doc["filename"] for doc in st.session_state.docling_docs]
selected_doc_name = st.selectbox("Select document to analyze:", doc_names)
selected_doc_data = next(
(doc for doc in st.session_state.docling_docs if doc["filename"] == selected_doc_name),
None
)
if not selected_doc_data:
return
visualizer = DocumentStructureVisualizer(selected_doc_data["doc"])
tab1, tab2, tab3, tab4 = st.tabs(["📑 Summary", "🏗️ Hierarchy", "📊 Tables", "🖼️ Images"])Chúng ta tạo dropdown để người dùng chọn tài liệu cần phân tích (hữu ích khi tải nhiều tệp). Sau khi lấy tài liệu Docling đã chọn từ session state, khởi tạo visualizer và tạo bốn tab cho các chế độ xem khác nhau.
with tab1:
st.subheader("Document Summary")
summary = visualizer.get_document_summary()
col1, col2, col3, col4 = st.columns(4)
with col1:
st.metric("Pages", summary["num_pages"])
with col2:
st.metric("Tables", summary["num_tables"])
with col3:
st.metric("Images", summary["num_pictures"])
with col4:
st.metric("Text Items", summary["num_texts"])
st.subheader("Content Types")
text_types_df = pd.DataFrame([
{"Type": k, "Count": v}
for k, v in sorted(summary["text_types"].items(), key=lambda x: -x[1])
])
st.dataframe(text_types_df, use_container_width=True)
with tab2:
st.subheader("Document Hierarchy")
hierarchy = visualizer.get_document_hierarchy()
if hierarchy:
for item in hierarchy:
indent = " " * (item["level"] - 1)
st.markdown(f"{indent}**{item['text']}** _(Page {item['page']})_")
else:
st.info("No hierarchical structure detected")
with tab3:
st.subheader("Tables")
tables_info = visualizer.get_tables_info()
if tables_info:
for table_data in tables_info:
st.markdown(f"### Table {table_data['table_number']} (Page {table_data['page']})")
if table_data["caption"]:
st.caption(table_data["caption"])
if not table_data["is_empty"]:
st.dataframe(table_data["dataframe"], use_container_width=True)
else:
st.info("Table is empty")
st.divider()
else:
st.info("No tables found in this document")
with tab4:
st.subheader("Images")
pictures_info = visualizer.get_pictures_info()
if pictures_info:
for pic_data in pictures_info:
st.markdown(f"**Image {pic_data['picture_number']}** (Page {pic_data['page']})")
if pic_data["caption"]:
st.caption(pic_data["caption"])
if pic_data["pil_image"] is not None:
st.image(pic_data["pil_image"], use_container_width=True)
else:
st.info("Image data not available")
if pic_data["bounding_box"]:
bbox = pic_data["bounding_box"]
with st.expander("📐 Position Details"):
st.text(
f"Position: ({bbox['left']:.1f}, {bbox['top']:.1f}) - "
f"({bbox['right']:.1f}, {bbox['bottom']:.1f})"
)
st.divider()
else:
st.info("No images found in this document")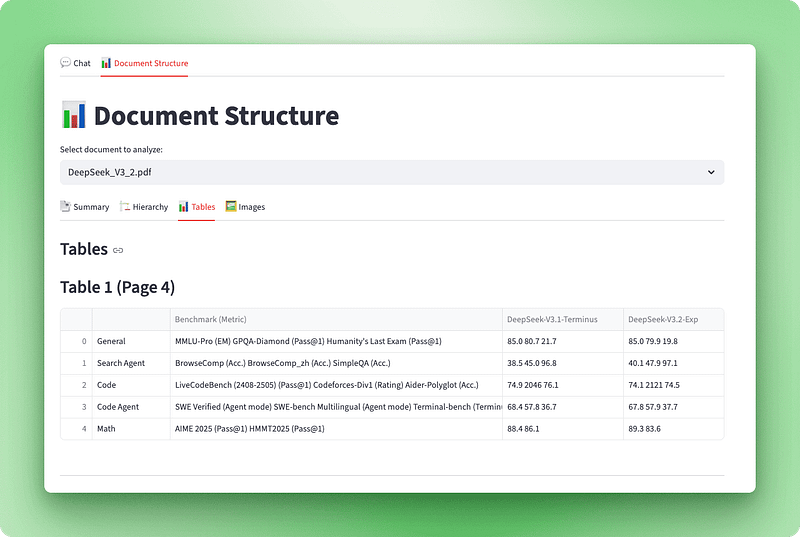
Bộ trực quan hóa cấu trúc đã hoàn tất. Người dùng có thể tải tài liệu và ngay lập tức xem “giải phẫu” của nó — bao nhiêu trang, bảng, và hình ảnh, cấu trúc phân cấp với tiêu đề và mục, các bảng tương tác để khám phá, và ảnh thực được trích xuất từ tài liệu. Tính minh bạch này giúp người dùng hiểu Docling đã trích xuất gì và tăng niềm tin vào hệ thống.
Với xử lý và trực quan hóa tài liệu đã hoạt động, chúng ta có thể xây hệ thống RAG cho phép hỏi đáp trên những tài liệu đã xử lý này.
📄 Script đầy đủ: src/vectorstore.py | src/tools.py
Với xử lý và trực quan hóa tài liệu hoàn thành, chúng ta có thể xây khả năng H&Đ. RAG (Retrieval Augmented Generation) cho phép người dùng đặt câu hỏi về tài liệu của họ. Hệ thống chuyển tài liệu thành embedding, lưu trong cơ sở dữ liệu vector, và truy xuất các đoạn liên quan để trả lời.
Phần này gồm hai thành phần: trình quản lý kho vector để chia nhỏ và nhúng tài liệu, và công cụ tìm kiếm để truy xuất thông tin liên quan.
Kho vector là nơi lưu embedding tài liệu. Khi người dùng hỏi, chúng ta tìm trong kho này các đoạn liên quan và đưa cho LLM làm ngữ cảnh.
Tạo vectorstore.py trong thư mục src/:
from typing import List
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import OpenAIEmbeddings
from langchain_chroma import ChromaNhững import này mang vào các thành phần LangChain cho xử lý tài liệu, tách văn bản, sinh embedding, và lưu trữ vector ChromaDB. Chúng phối hợp như sau:
class VectorStoreManager:
def __init__(self):
self.embeddings = OpenAIEmbeddings(model="text-embedding-3-small")
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=100,
length_function=len,
)Chúng ta khởi tạo hai thành phần chính. Mô hình text-embedding-3-small của OpenAI chuyển văn bản thành vector. Nó nhỏ và nhanh hơn text-embedding-3-large, quan trọng khi nhúng hàng trăm đoạn. RecursiveCharacterTextSplitter chia tài liệu thành đoạn 1000 ký tự với chồng lấn 100 ký tự, đảm bảo thông tin quan trọng ở ranh giới đoạn không bị cắt giữa câu.
1000 ký tự cân bằng giữa độ chính xác và ngữ cảnh — đoạn nhỏ cho truy xuất chính xác nhưng mất ngữ cảnh, đoạn lớn giữ ngữ cảnh nhưng loãng mức độ liên quan.
Thêm phương thức chia đoạn:
def chunk_documents(self, documents: List[Document]) -> List[Document]:
"""Split documents into smaller chunks for better retrieval."""
chunks = self.text_splitter.split_documents(documents)
return chunksBộ chia tự động xử lý metadata, giữ thông tin từ tài liệu gốc. Mỗi đoạn biết nó đến từ tệp nào, điều này quan trọng khi tác tử trích dẫn nguồn trong câu trả lời.
Bây giờ thêm phương thức tạo kho vector:
def create_vectorstore(self, chunks: List[Document]) -> Chroma:
"""Create a Chroma vector store from document chunks."""
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
collection_name="documents"
)
return vectorstoreChromaDB xử lý phần nặng. Nó nhúng từng đoạn bằng mô hình embedding của chúng ta và lưu vector trong bộ nhớ. Khi bạn chạy tìm kiếm tương đồng, ChromaDB tính cosine similarity giữa vector truy vấn và tất cả vector tài liệu, trả về các kết quả gần nhất.
Với kho vector sẵn sàng xử lý embedding, chúng ta cần cung cấp cho tác tử cách truy vấn nó. Tool là các hàm LLM có thể gọi khi cần thông tin nó chưa có.
Tạo tools.py trong thư mục src/:
from typing import Annotated
from langchain_core.tools import tool
def create_search_tool(vectorstore):
"""Create a search tool that has access to the vector store."""Hàm factory này dùng mẫu closure: nhận kho vector và trả về tool có thể tìm kiếm nó. Tool giữ quyền truy cập kho vector mà không cần biến toàn cục.
@tool
def search_documents(query: Annotated[str, "The search query or question about the documents"]) -> str:
"""Search the uploaded documents for relevant information."""Decorator @tool biến hàm này thành một tool của LangChain mà tác tử có thể gọi. Kiểu gợi ý Annotated mô tả tham số, giúp LLM hiểu cần truyền gì khi gọi tool.
try:
results = vectorstore.similarity_search(query, k=8)
if not results:
return "No relevant information found in the documents for this query."Chúng ta truy xuất 8 đoạn tương tự (k=8) từ kho vector. Con số này cho LLM đủ ngữ cảnh mà không bị tràn thông tin lặp lại. Số phù hợp phụ thuộc loại tài liệu — tài liệu kỹ thuật dày đặc có thể phù hợp với ít đoạn hơn (k=4–6), trong khi tài liệu tự sự có thể cần nhiều hơn (k=10–12).
context_parts = []
for i, doc in enumerate(results, 1):
source = doc.metadata.get("filename", doc.metadata.get("source", "Unknown source"))
content = doc.page_content.strip()
context_parts.append(
f"[Source {i}: {source}]\n"
f"Content: {content}\n"
)
return "\n---\n".join(context_parts)Chúng ta định dạng mỗi đoạn với tên tệp nguồn, rồi nối bằng dấu phân cách. LLM nhận ngữ cảnh có cấu trúc này và dùng để sinh câu trả lời kèm trích dẫn nguồn.
except Exception as e:
return f"Error searching documents: {str(e)}"
return search_documentsXử lý lỗi đảm bảo tác tử nhận thông điệp rõ ràng nếu tìm kiếm thất bại, thay vì bị sập. Hàm trả về tool đã cấu hình, sẵn sàng cho tác tử sử dụng.
Kho vector và công cụ tìm kiếm đã sẵn sàng. Tiếp theo, chúng ta sẽ xây tác tử LangGraph điều phối truy xuất và sinh để trả lời câu hỏi người dùng.
📄 Script đầy đủ: src/agent.py
Công cụ tìm kiếm có thể truy vấn kho vector, nhưng cần một bộ điều phối thông minh. Tác tử LangGraph quyết định khi nào cần tìm kiếm, diễn giải kết quả và sinh câu trả lời tự nhiên. Chúng ta cũng sẽ triển khai streaming để hiển thị tiến trình theo thời gian thực.
Tác tử nhận câu hỏi, quyết định khi nào tìm trong tài liệu và sinh câu trả lời dựa trên ngữ cảnh truy xuất.
Tạo agent.py trong thư mục src/:
from typing import List
from langchain_core.tools import BaseTool
from langchain_openai import ChatOpenAI
from langgraph.prebuilt import create_react_agent
from langgraph.checkpoint.memory import MemorySaverChúng ta import các thành phần để xử lý tool, mô hình chat của OpenAI, triển khai tác tử ReAct của LangGraph và bộ nhớ hội thoại.
SYSTEM_PROMPT = """You are a helpful document intelligence assistant. You have access to documents that have been uploaded and processed.
GUIDELINES:
- Use the search_documents tool to find relevant information
- Keep it simple: one well-crafted search is usually sufficient
- Only search again if the first results are clearly incomplete
- Provide clear, accurate answers based on the document contents
- Always cite your sources with filenames
- If information isn't found, say so clearly
- Be concise but thorough
When answering:
1. Search the documents with a focused query
2. Synthesize a clear answer from the results
3. Include source citations (filenames)
4. Only search again if absolutely necessary
"""
def create_documentation_agent(tools: List[BaseTool], model_name: str = "gpt-4o-mini"):
"""Create a document intelligence assistant agent using LangGraph."""
llm = ChatOpenAI(model=model_name, temperature=0)
memory = MemorySaver()Chúng ta dùng gpt-4o-mini thay vì gpt-5 vì nó nhanh và rẻ hơn nhưng vẫn xử lý H&Đ tài liệu tốt. Nhiệt độ đặt 0 để phản hồi nhất quán, thực tế. MemorySaver cung cấp bộ nhớ hội thoại, giúp tác tử nhớ các lượt trao đổi trước trong một phiên.
agent = create_react_agent(
llm,
tools=tools,
prompt=SYSTEM_PROMPT,
checkpointer=memory
)
return agentcreate_react_agent của LangGraph triển khai mẫu ReAct (Reasoning + Acting). Tác tử lý luận về việc cần làm, hành động bằng tool, quan sát kết quả, và lặp lại cho đến khi có câu trả lời. Mẫu này phù hợp với RAG vì tác tử có thể quyết định khi nào tìm kiếm và cách dùng ngữ cảnh truy xuất.
Tác tử giờ có thể tìm kiếm và sinh câu trả lời, nhưng người dùng không nên chờ 10 giây nhìn màn hình trống trong khi nó xử lý. Streaming hiển thị tiến trình theo thời gian thực — đầu tiên là trạng thái “đang suy nghĩ”, rồi “đang tìm kiếm”, sau đó câu trả lời xuất hiện dần từng token.
Cập nhật hàm render_chat() trong app.py để hoàn tất xử lý phản hồi chúng ta đã đánh dấu TODO trước đó:
if prompt:
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("user"):
st.markdown(prompt)Chúng ta thêm tin nhắn của người dùng vào lịch sử hội thoại và hiển thị nó trong giao diện chat.
with st.chat_message("assistant"):
status_placeholder = st.empty()
message_placeholder = st.empty()
try:
config = {"configurable": {"thread_id": "document_chat"}}Chúng ta tạo placeholder cho chỉ báo trạng thái và thông điệp phản hồi. Cấu hình gồm ID luồng mà LangGraph dùng để duy trì bộ nhớ hội thoại qua các lượt.
def generate_response():
"""Generator that yields tokens from LangGraph stream."""
status_placeholder.markdown("🤔 **Thinking...**")
first_content_token = True
tool_call_detected = False
final_answer_started = FalseHàm generator này xử lý đầu ra stream của LangGraph. Chúng ta theo dõi trạng thái bằng các cờ để hiển thị thông điệp phù hợp khi tác tử tiến qua các bước công việc.
for msg, metadata in st.session_state.agent.stream(
{"messages": [HumanMessage(content=prompt)]},
config=config,
stream_mode="messages",
):
langgraph_node = metadata.get("langgraph_node", "")Tham số stream_mode="messages" cho chúng ta token LLM theo thời gian thực, không chỉ kết quả cuối. LangGraph phát sự kiện suốt quá trình thực thi tác tử — khi bắt đầu suy nghĩ, khi gọi tool, và khi sinh văn bản.
if "tools" in langgraph_node.lower() or "tool" in langgraph_node.lower():
if not tool_call_detected:
status_placeholder.markdown("🔍 **Searching documents...**")
tool_call_detected = True
continue
if "agent" in langgraph_node.lower() and hasattr(msg, "content"):
content = msg.content
if content:
if first_content_token:
status_placeholder.markdown("💬 **Generating answer...**")
first_content_token = False
final_answer_started = True
if final_answer_started:
yield contentKhi nút agent bắt đầu sinh câu trả lời cuối, chúng ta cập nhật trạng thái và bắt đầu phát các token nội dung. Mỗi token được hiển thị ngay, tạo hiệu ứng gõ mượt.
status_placeholder.empty()
with message_placeholder.container():
full_response = st.write_stream(generate_response())Sau khi streaming hoàn tất, chúng ta xóa chỉ báo trạng thái. st.write_stream() của Streamlit xử lý hiển thị từng token tự động, tích lũy token và cập nhật UI mượt mà. Kết quả là trải nghiệm chat phản hồi nhanh, tạo niềm tin rằng hệ thống đang hoạt động.
st.session_state.messages.append({"role": "assistant", "content": full_response})
except Exception as e:
st.error(f"Error generating response: {str(e)}")Chúng ta lưu phản hồi hoàn chỉnh vào lịch sử tin nhắn và xử lý mọi lỗi phát sinh trong quá trình streaming.
Hệ thống RAG đã hoàn chỉnh. Người dùng giờ có thể tải tài liệu, xử lý bằng Docling, khám phá cấu trúc, và trò chuyện tự nhiên về nội dung. Tác tử tìm kiếm thông minh, trích dẫn nguồn và stream câu trả lời cho trải nghiệm mượt mà.
Ứng dụng Trợ lý Trí tuệ Tài liệu của bạn đã hoàn thành. Trước khi triển khai hoặc chia sẻ, bạn nên kiểm thử để xác minh mọi thứ hoạt động đúng.
Khởi chạy ứng dụng từ thư mục gốc dự án:
streamlit run app.pyStreamlit sẽ mở trình duyệt tại http://localhost:8501. Bạn sẽ thấy sidebar với điều khiển tải lên và hai tab ở khu vực chính.
Tải một PDF mẫu có bảng và hình ảnh để kiểm thử đầy đủ khả năng xử lý:
Theo dõi các chỉ báo xử lý:
Khi hoàn tất, bạn sẽ thấy “✅ Ready to chat!” trong phần trạng thái.
Chuyển sang tab “Document Structure” để xác minh Docling trích xuất chính xác mọi thứ:
Nếu bảng hiển thị rỗng hoặc ảnh không xuất hiện, hãy kiểm tra bạn đã bật do_table_structure=True và generate_picture_images=True trong tùy chọn pipeline.
Quay lại tab “Chat” và kiểm thử tác tử với các câu hỏi mẫu sau:
Câu hỏi khởi đầu tốt:
Câu hỏi theo tài liệu cụ thể (điều chỉnh theo tài liệu của bạn):
Câu hỏi tiếp nối để kiểm thử bộ nhớ hội thoại:
Tìm các câu trả lời trực tiếp từ tài liệu của bạn kèm trích dẫn nguồn, luồng token mượt, và các chỉ báo trạng thái (“Thinking…”, “Searching documents…”, “Generating answer…”). Cảnh giác với phản hồi chung chung không đến từ tài liệu của bạn, thiếu trích dẫn nguồn, phản hồi chậm không có chỉ báo trạng thái, hoặc lỗi về thiếu khóa API.
Lỗi “No module named ‘docling’”
pip install docling langchain langchain-openai langchain-chroma langgraph streamlit streamlit-extras pandas python-dotenv
Lỗi “OpenAI API key not found”
Xác minh tệp .env tồn tại với OPENAI_API_KEY=your-key-here
Khởi động lại Streamlit
Xử lý mất hơn 60 giây
Tác tử trả lời chung chung
Bảng hiển thị DataFrame rỗng
Xác nhận do_table_structure=True trong PdfPipelineOptions
Thử PDF khác có bảng native
Ứng dụng hiện đã được xác nhận và sẵn sàng sử dụng. Bạn có thể thử với tài liệu của riêng mình hoặc triển khai cho người khác sử dụng.
Giờ đây bạn có một Trợ lý Trí tuệ Tài liệu hoạt động, xử lý PDF, Word, PowerPoint và tệp HTML đồng thời giữ nguyên cấu trúc của chúng. Docling trích xuất văn bản, bảng, hình ảnh và phân cấp tài liệu mà người dùng có thể khám phá qua các tab tương tác. Hệ thống RAG, kết hợp với ChromaDB và LangGraph, cho phép H&Đ hội thoại với trích dẫn nguồn được stream theo thời gian thực. Điều này minh họa cách xử lý tài liệu nhận biết cấu trúc cải thiện chất lượng truy xuất so với trích xuất văn bản cơ bản. Toàn bộ mã nguồn có tại kho GitHub.
Nền tảng này mở ra nhiều hướng mở rộng:
Để đào sâu hơn về hệ thống RAG và ứng dụng LLM, lộ trình AI Engineering của chúng tôi bao quát các khái niệm và mẫu bạn đã dùng tại đây.
Học với DataCamp
Tracks
Courses
Courses