
Cursus
Multivariate kansverdelingen in R
4 Hr
8.8K
Weinig concepten zijn zo fundamenteel en breed toepasbaar in statistiek en data science als de Gaussische verdeling. Ook wel de normale verdeling genoemd, vormt dit wiskundige model de basis van talloze statistische methoden en data-analysetechnieken.
Deze uitgebreide gids ontrafelt het concept van Gaussische verdelingen, met aandacht voor hun eigenschappen, toepassingen en betekenis in moderne data-analyse. We bekijken waarom ze zo vaak voorkomen in natuurlijke verschijnselen en hoe ze worden gebruikt in uiteenlopende domeinen, van financiën tot productie.
Als je nieuw bent in statistiek of de basis wilt opfrissen, biedt onze cursus Introduction to Statistics een uitstekende basis. Voor wie deze concepten wil toepassen in specifieke programmeertalen, helpen onze cursussen Statistical Thinking in Python (Part 1) en Statistics Fundamentals with R je de vele manieren te waarderen waarop de Gaussische verdeling voorkomt in beschrijvende en inferentiële statistiek.
Een Gaussische verdeling, ook wel normale verdeling, is een continue kansverdeling met een klokvormige curve. Ze wordt bepaald door twee parameters:
De kansdichtheidsfunctie (PDF) van een Gaussische verdeling is als volgt gegeven:
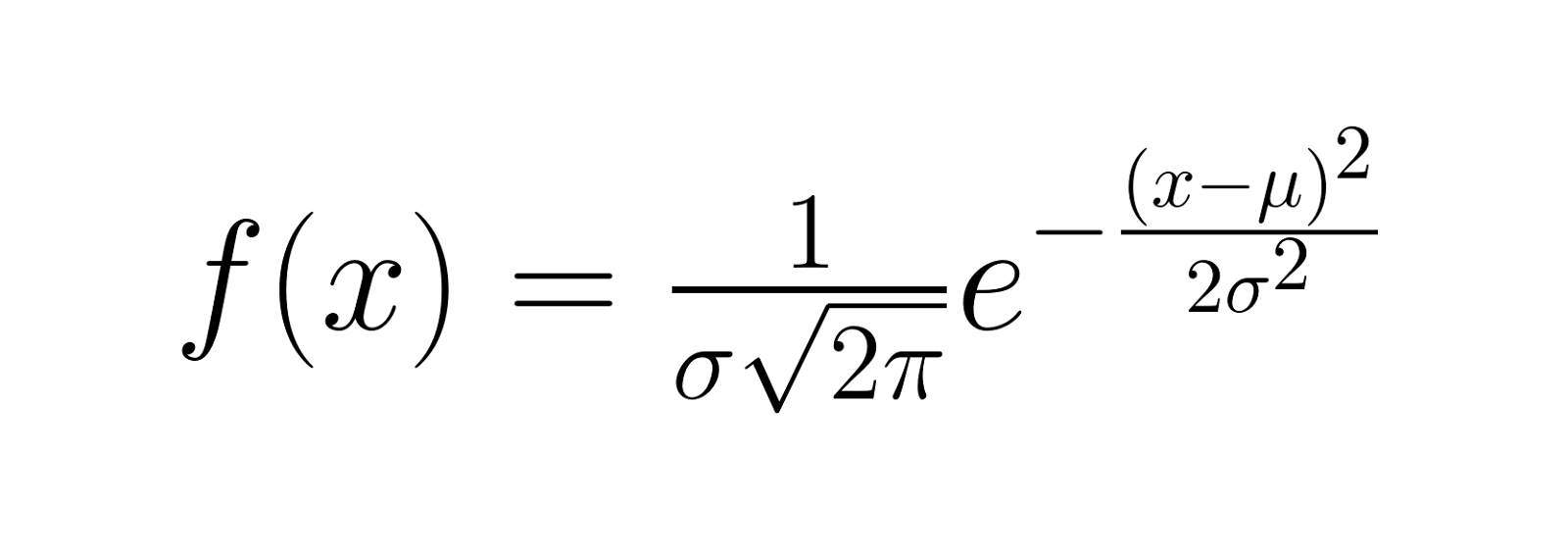
Waarbij:
Om het concept van een Gaussische verdeling te illustreren, kun je denken aan de verdeling van geboortegewichten van voldragen baby’s in een grote populatie:
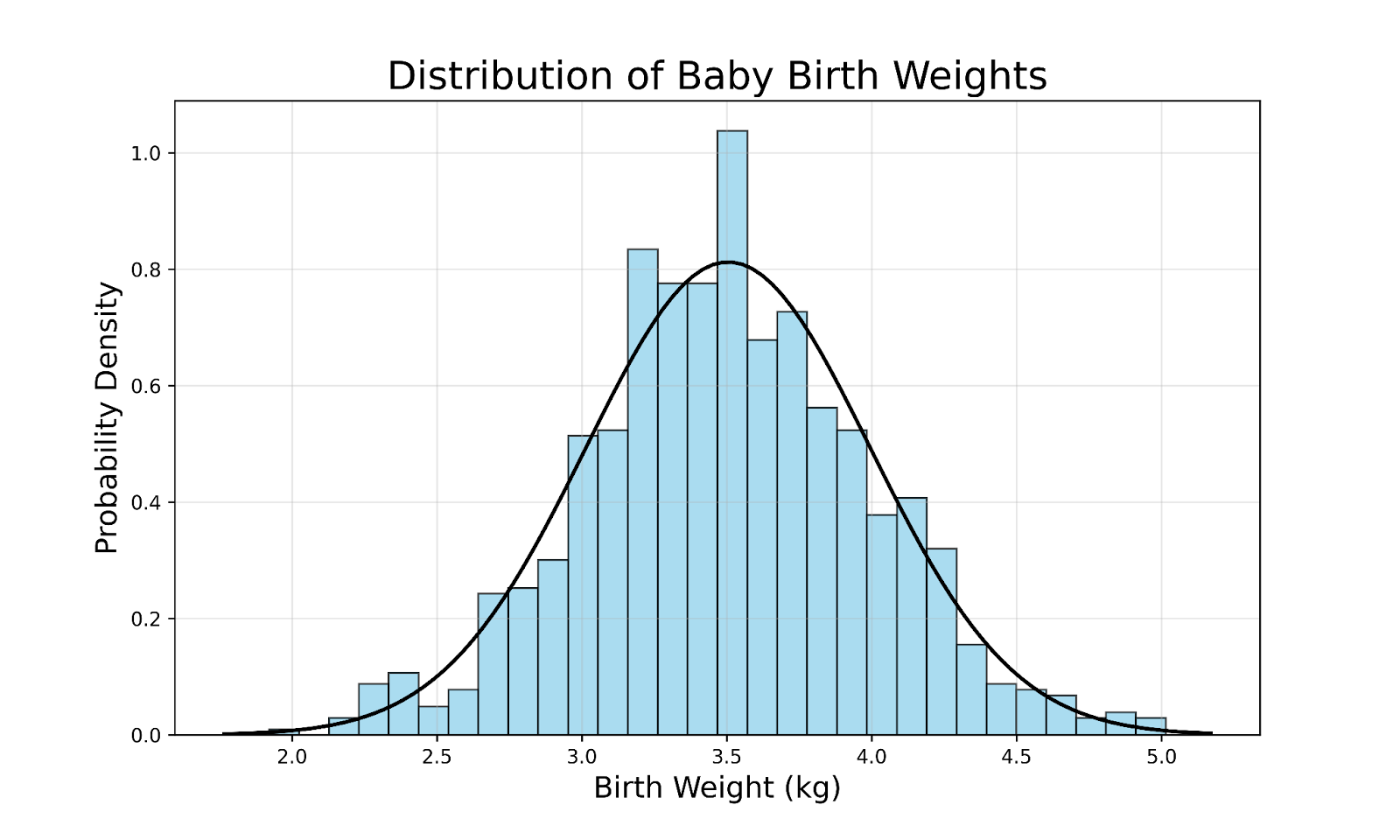
Enkele belangrijke observaties uit deze grafiek zijn:
De alomtegenwoordigheid van Gaussische verdelingen in de natuur en de statistiek kan worden verklaard door de centrale limietstelling (CLT). De CLT stelt dat de verdeling van steekproefgemiddelden naar een normale verdeling convergeert naarmate de steekproefgrootte toeneemt (bijv. n ≥ 30), ongeacht de verdeling van de onderliggende populatie.
Een belangrijk aspect van de CLT is dat deze convergentie naar een normale verdeling relatief snel optreedt naarmate de steekproef groter wordt. Voor de meeste praktische doeleinden zijn zelfs middelgrote steekproeven (bijv. n ≥ 30) voldoende om de steekproefgemiddelden een normale verdeling te laten benaderen. Dit geldt zelfs als de populatie zelf scheef verdeeld is.
Binnen de klasse van Gaussische verdelingen is er een speciaal geval, bekend als de standaard Gaussische verdeling, ook wel de standaardnormale verdeling. Dit is een Gaussische verdeling waarbij:
De kansdichtheidsfunctie van een standaard Gaussische verdeling wordt gegeven door de volgende formule.
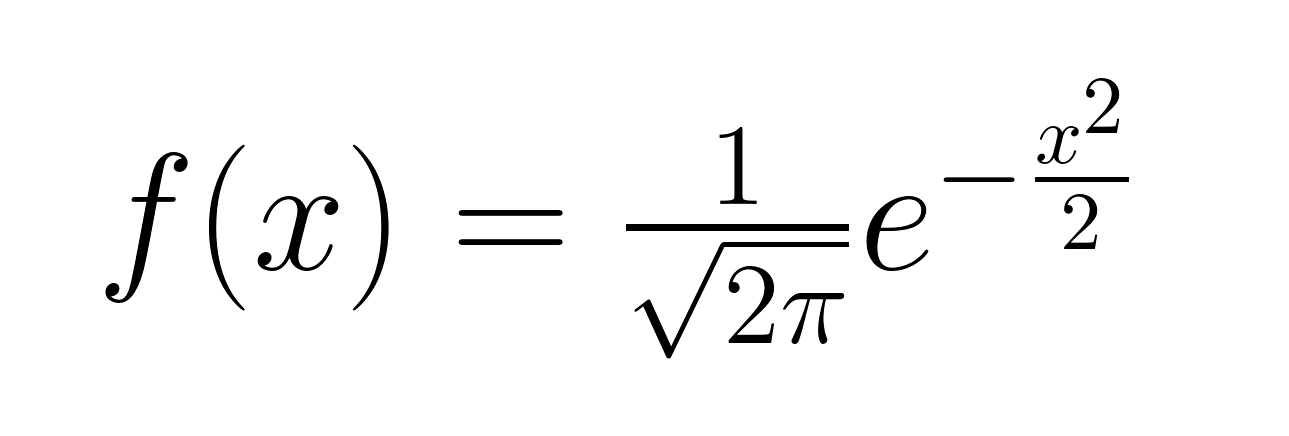
Merk op dat de formule voor de standaard Gaussische kansdichtheid vereenvoudigt ten opzichte van de algemene vorm vanwege de specifieke waarden van het gemiddelde en de standaardafwijking. Laten we nu de standaard Gaussische verdeling visualiseren.
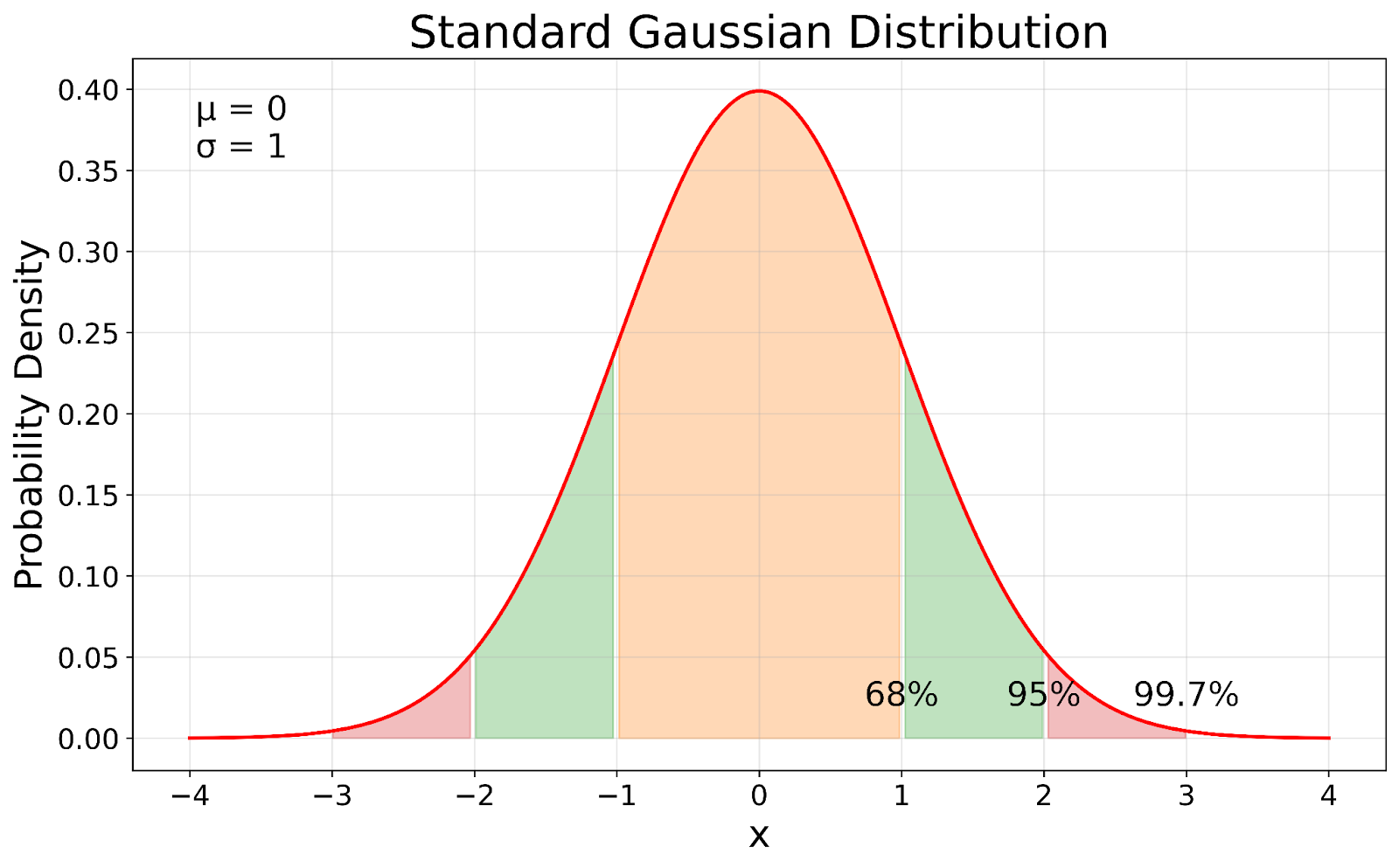 Standaard Gaussische verdeling. Afbeelding door de auteur
Standaard Gaussische verdeling. Afbeelding door de auteur
De standaard Gaussische verdeling, getoond in onze visualisatie, dient als referentiepunt in de statistiek. In onze visual zie je hoe de standaard Gaussische een gestandaardiseerde versie is van elke Gaussische verdeling. Het standaardiseringsproces verschuift het gemiddelde naar 0 en schaalt de standaardafwijking naar 1, terwijl de fundamentele eigenschappen van de verdeling behouden blijven.
Laten we nu enkele eigenschappen van Gaussische verdelingen bekijken.
Het kenmerk van een Gaussische verdeling is de symmetrische klokvorm. Deze symmetrie betekent dat data even waarschijnlijk boven als onder het gemiddelde vallen, wat bijzonder nuttig is bij het voorspellen van kansen en het trekken van conclusies over data. Zoals in de volgende visualisatie te zien is, behouden alle Gaussische verdelingen deze karakteristieke klokvorm, ongeacht hun gemiddelde of standaardafwijking.
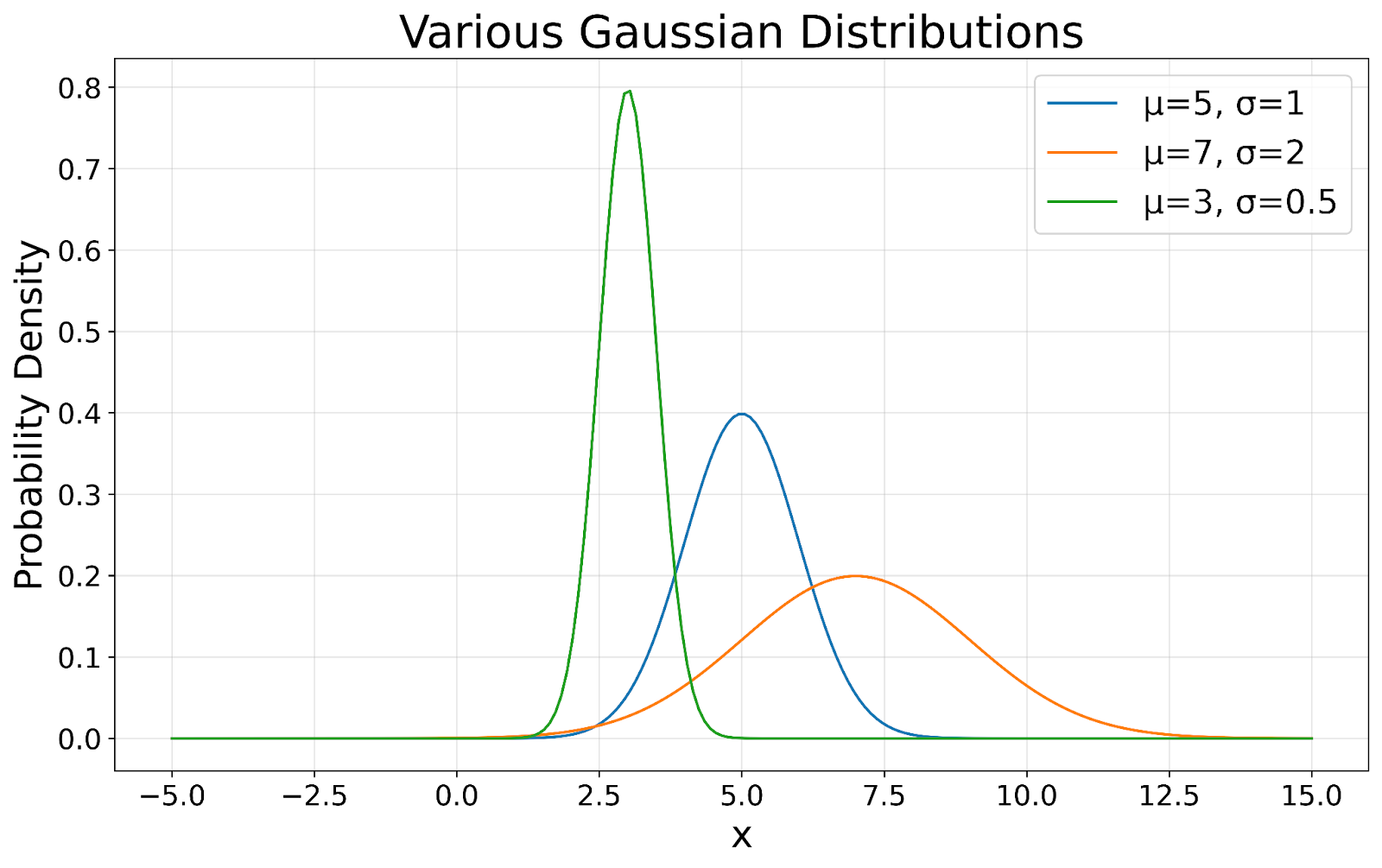 Gaussische verdelingen gevisualiseerd. Afbeelding door de auteur
Gaussische verdelingen gevisualiseerd. Afbeelding door de auteur
In een perfecte Gaussische verdeling vallen het gemiddelde (gemiddelde), de mediaan (middenwaarde) en de modus (meest frequente waarde) samen. Deze uitlijning geeft een duidelijk beeld van de centrale tendens van de data, wat waardevol is voor het samenvatten van datasets. In onze visualisatie zie je hoe de top van elke curve dit centrale punt weergeeft.
De standaardafwijking in een Gaussische verdeling vertelt ons hoe ver de data van het gemiddelde afliggen. Er is een voorspelbaar patroon:
Deze regel, bekend als de 68-95-99,7-regel, geldt voor alle Gaussische verdelingen, ongeacht hun gemiddelde of standaardafwijking.
Gaussische verdelingen zijn meer dan een theoretisch concept – ze hebben een breed scala aan toepassingen in verschillende vakgebieden.
Veel statistische toetsen, zoals t-toetsen en ANOVA, veronderstellen dat data normaal verdeeld zijn. Deze toetsen helpen onderzoekers te bepalen of er significante verschillen tussen groepen zijn of dat waargenomen effecten waarschijnlijk aan toeval te wijten zijn. De aanname van normaliteit stelt onderzoekers in staat p-waarden en betrouwbaarheidsintervallen te berekenen, wat een kader biedt om conclusies uit data te trekken en geïnformeerde beslissingen te nemen.
De aanname van normaliteit is zo belangrijk dat hersteekproeftechnieken zoals bootstrapping zijn ontwikkeld om normaal verdeelde hersteekproefverdelingen te genereren uit niet-normale data, wat het eenvoudiger maakt om betrouwbaarheidsintervallen te construeren en andere statistische analyses uit te voeren. Onze tutorial over hypothesetoetsing laat zien hoe je deze toetsen uitvoert in diverse scenario’s, inclusief situaties waarin data normaal verdeeld zijn.
Veel machine-learningtechnieken steunen op aannames van normaliteit, waardoor Gaussische verdelingen fundamenteel zijn voor hun werking en interpretatie. In lineaire regressie willen we bijvoorbeeld doorgaans dat de y-waarden (afhankelijke variabele) een normale verdeling volgen om vertrouwen te hebben in onze schattingen. Daarnaast streven we ernaar dat de residuen (de verschillen tussen geobserveerde en voorspelde waarden) normaal verdeeld zijn. Deze normaliteitsaannames liggen ten grondslag aan de statistische toetsen die worden gebruikt om de betrouwbaarheid van het model te beoordelen en de betrouwbaarheidsintervallen voor de voorspellingen.
Ook kunnen machine-learningspecialisten de voorkeur geven aan data die een Gaussische verdeling volgen om redenen van rekenefficiëntie. Een Gaussische verdeling kan indirect bijdragen aan rekenefficiëntie in bepaalde algoritmen, vooral die welke uitgaan van of berusten op normaal verdeelde data.
Leer met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
