Cours
Multivariate Probability Distributions in R
4 h
8.8K
Peu de notions sont aussi fondamentales et polyvalentes en statistique et en science des données que la loi gaussienne. Aussi appelée loi normale, ce modèle mathématique est le socle de nombreux méthodes statistiques et techniques d'analyse des données.
Ce guide complet clarifie le concept de loi gaussienne, en explorant ses propriétés, ses applications et son importance dans l'analyse de données moderne. Nous verrons pourquoi elle est si répandue dans les phénomènes naturels et comment elle est utilisée dans des domaines variés, de la finance à l'industrie.
Si vous débutez en statistique ou souhaitez réviser les bases, notre cours Introduction to Statistics constitue un excellent point de départ. Pour mettre ces concepts en pratique dans des langages de programmation spécifiques, nos cours Statistical Thinking in Python (Part 1) et Statistics Fundamentals with R vous aideront à apprécier les nombreuses façons dont la loi gaussienne intervient en statistique descriptive et inférentielle.
Une loi gaussienne, ou loi normale, est une loi de probabilité continue caractérisée par sa courbe en cloche. Elle est définie par deux paramètres :
La fonction de densité de probabilité (PDF) d'une loi gaussienne est donnée par :
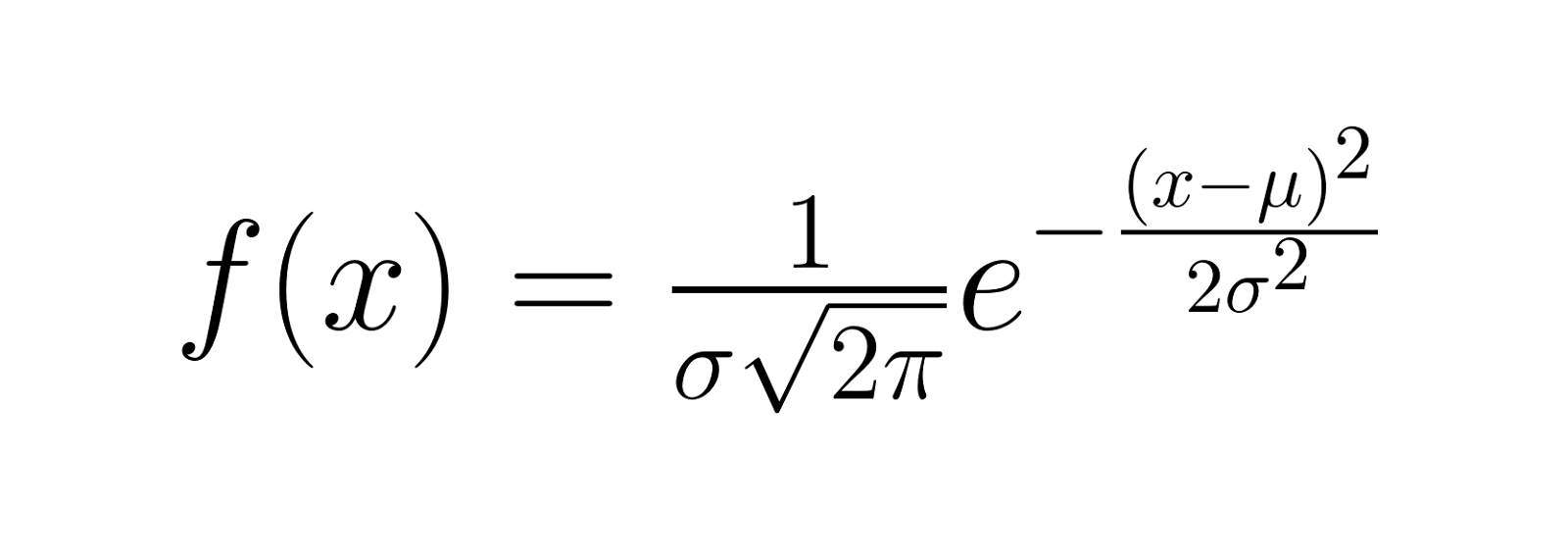
Où :
Pour illustrer le concept, prenons la distribution des poids de naissance des bébés à terme dans une grande population :
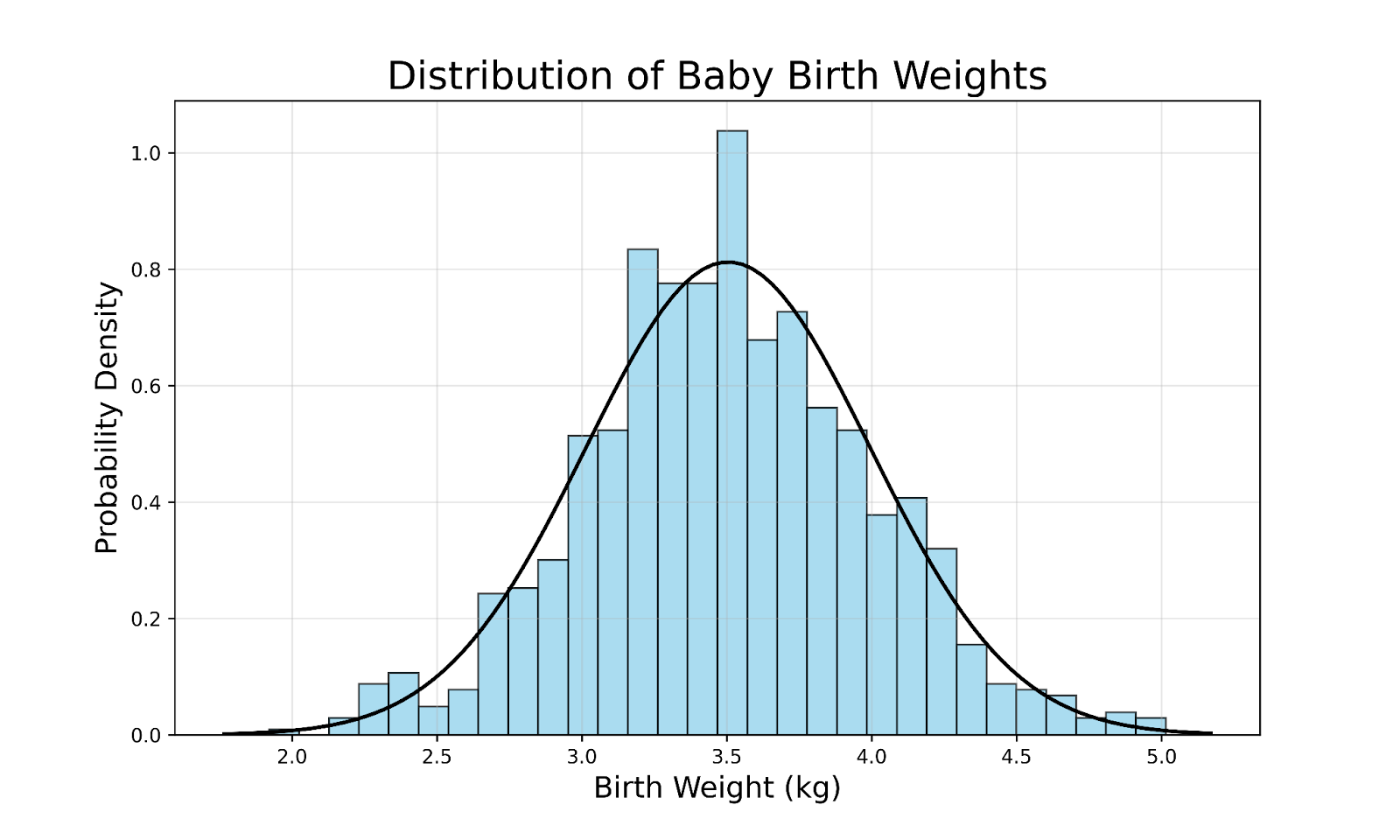
Quelques enseignements clés de ce graphique :
La fréquence des lois gaussiennes dans la nature et en statistique s'explique par le théorème central limite (TCL). Le TCL énonce que la distribution des moyennes d'échantillons tend vers une loi normale à mesure que la taille de l'échantillon augmente (p. ex., n ≥ 30), quelle que soit la distribution de la population d'origine.
Un point clé du TCL est que cette convergence vers la normalité se produit relativement vite quand la taille d'échantillon augmente. Dans la plupart des cas pratiques, des échantillons de taille modérée (p. ex., n ≥ 30) suffisent pour que les moyennes d'échantillons approchent une loi normale, même si la population est asymétrique.
Au sein de la famille des lois gaussiennes, il existe un cas particulier, la loi normale centrée réduite (standard normal distribution). Il s'agit d'une loi gaussienne pour laquelle :
La fonction de densité de probabilité de la loi normale centrée réduite est donnée par la formule suivante.
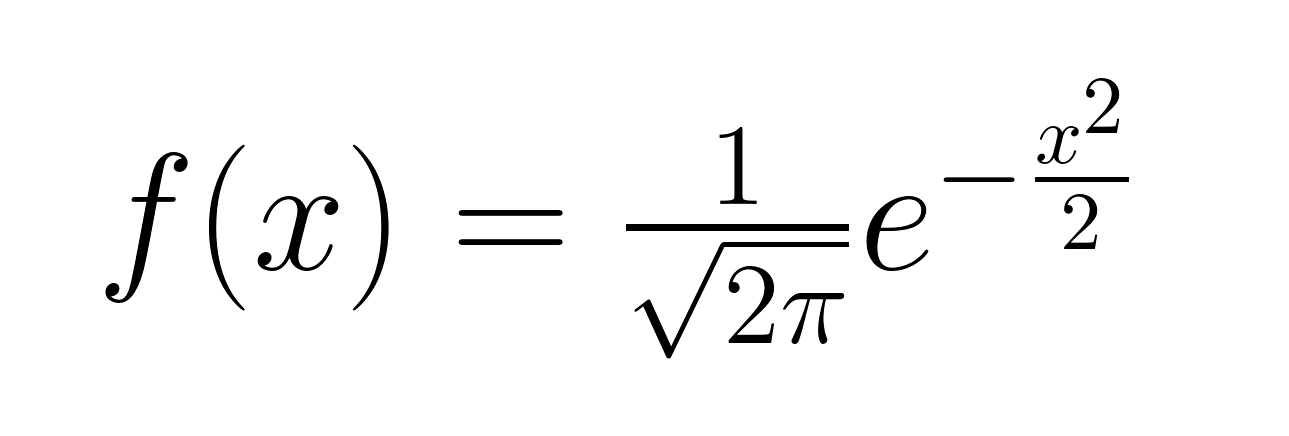
Remarquez que la formule de la densité de probabilité standard se simplifie par rapport à la forme générale grâce aux valeurs particulières de la moyenne et de l'écart type. Visualisons maintenant la loi normale centrée réduite.
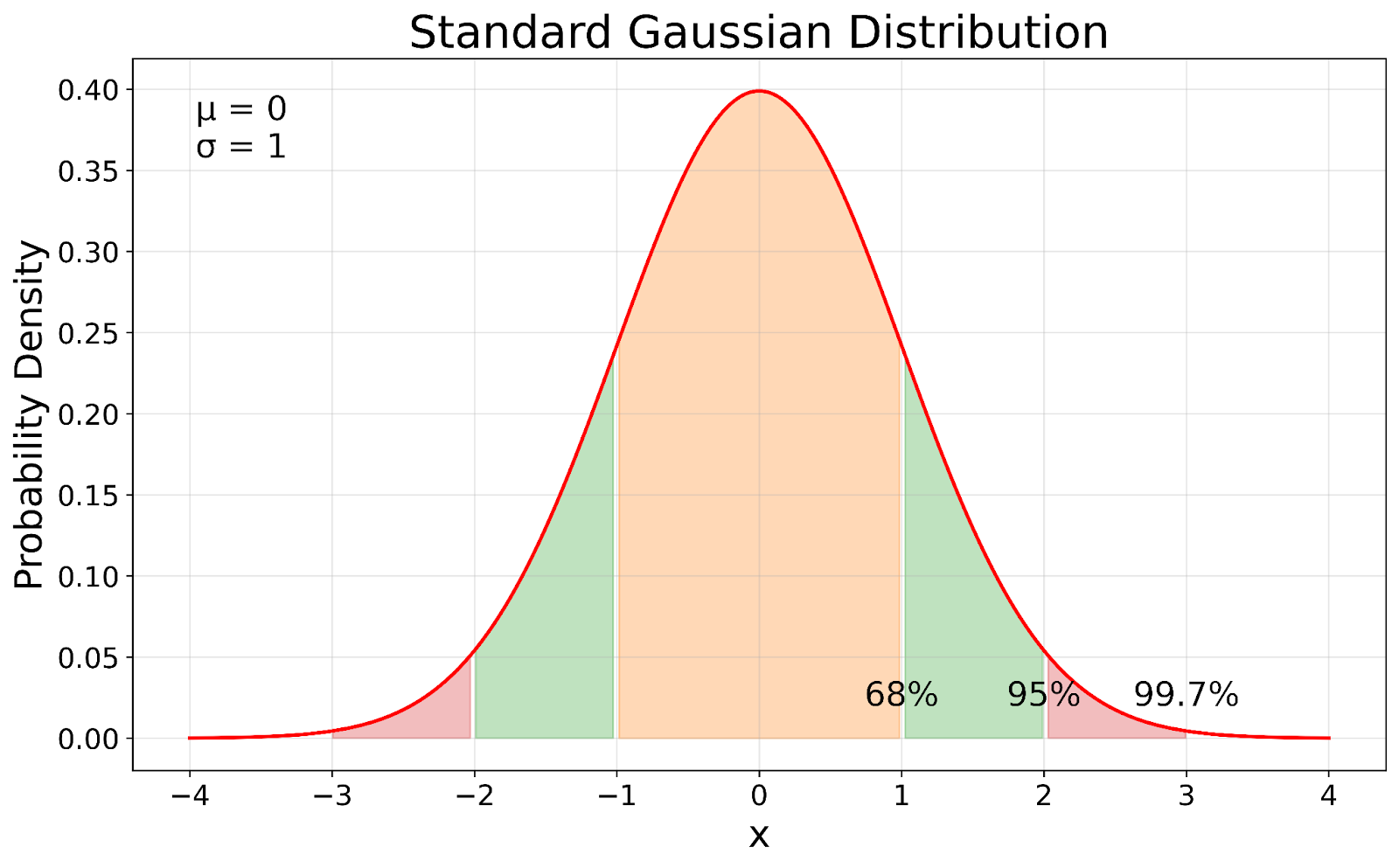 Loi normale centrée réduite. Image de l'auteur
Loi normale centrée réduite. Image de l'auteur
La loi normale centrée réduite, illustrée ici, sert de référence en statistique. Vous pouvez voir comment il s'agit d'une version standardisée de toute loi gaussienne : la standardisation recentre la moyenne à 0 et ramène l'écart type à 1, tout en préservant les propriétés fondamentales de la distribution.
Examinons à présent quelques propriétés des lois gaussiennes.
La signature d'une loi gaussienne est sa forme en cloche symétrique. Cette symétrie implique que les données ont autant de chances d'être au-dessus qu'au-dessous de la moyenne, ce qui est particulièrement utile pour estimer des probabilités et faire des inférences. Comme le montre la visualisation suivante, toutes les lois gaussiennes conservent cette forme en cloche, quelle que soit leur moyenne ou leur écart type.
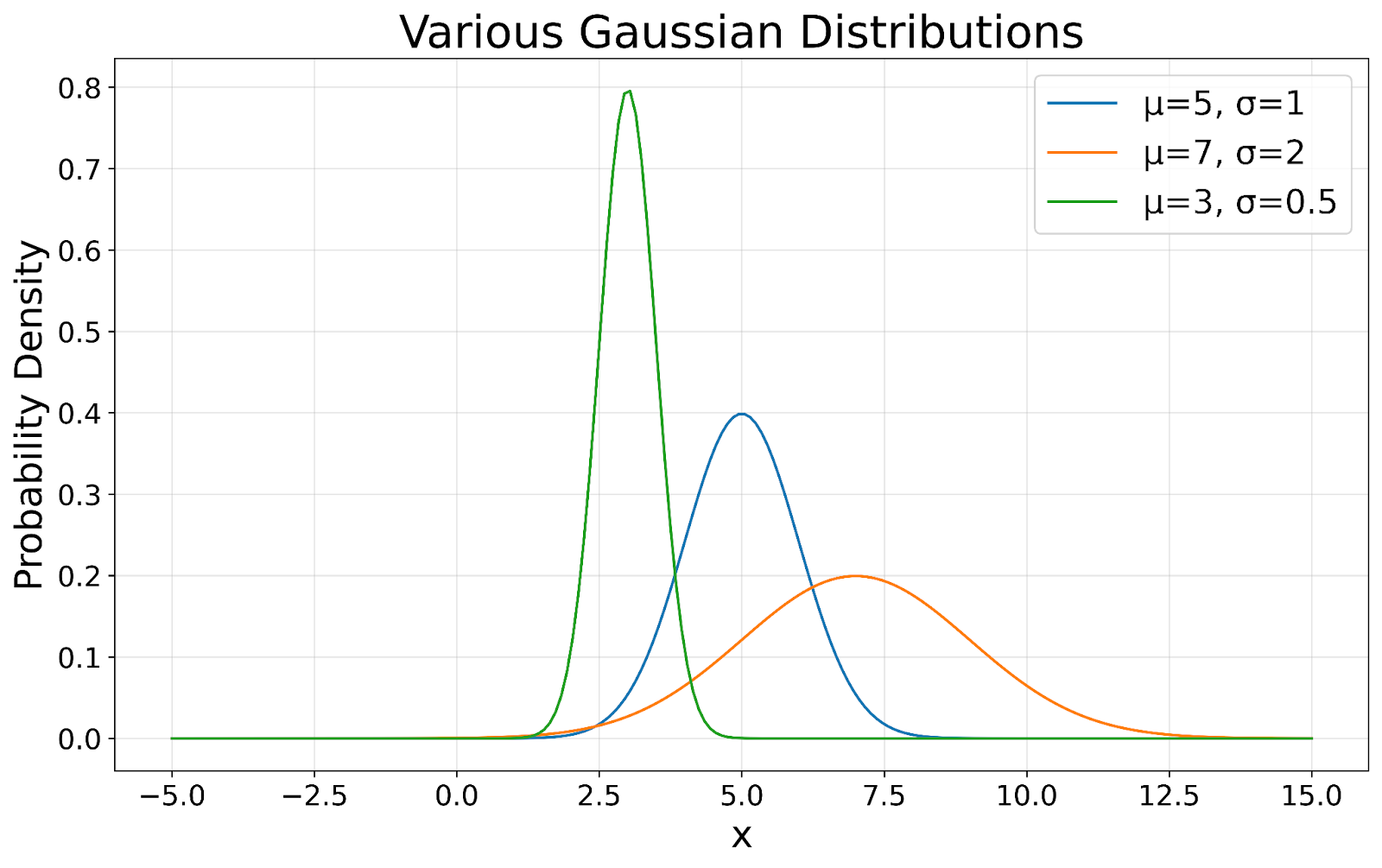 Visualisation de lois gaussiennes. Image de l'auteur
Visualisation de lois gaussiennes. Image de l'auteur
Dans une loi gaussienne idéale, la moyenne (valeur moyenne), la médiane (valeur centrale) et le mode (valeur la plus fréquente) coïncident. Cet alignement renseigne clairement sur la tendance centrale des données, utile pour résumer des jeux de données. Dans notre visuel, le sommet de chaque courbe représente ce point central.
Dans une loi gaussienne, l'écart type indique à quel point les données s'éloignent de la moyenne. Il suit un schéma prévisible :
Cette règle, appelée règle 68-95-99,7, s'applique à toutes les lois gaussiennes, quelle que soit leur moyenne ou leur écart type.
Les lois gaussiennes ne sont pas qu'un concept théorique : elles ont des applications étendues dans de nombreux domaines.
De nombreux tests statistiques, tels que les tests t et l'ANOVA, supposent une distribution normale des données. Ces tests aident à déterminer s'il existe des différences significatives entre des groupes ou si des effets observés sont probablement dus au hasard. L'hypothèse de normalité permet de calculer des p-values et des intervalles de confiance, offrant un cadre pour tirer des conclusions et prendre des décisions éclairées.
Cette hypothèse est si importante que des techniques de rééchantillonnage comme le bootstrap ont été développées pour générer des distributions de rééchantillonnage proches de la normalité à partir de données non normales, facilitant la construction d'intervalles de confiance et d'autres analyses. Notre tutoriel sur les tests d'hypothèse montre comment conduire ces tests dans divers scénarios, y compris lorsque les données sont normalement distribuées.
De nombreuses techniques de machine learning reposent sur des hypothèses de normalité, rendant les lois gaussiennes centrales pour leur fonctionnement et leur interprétation. En régression linéaire, par exemple, on souhaite généralement que les valeurs de y (variable dépendante) suivent une loi normale pour avoir confiance dans les estimations. On vise également des résidus (écarts entre valeurs observées et prédites) distribués normalement. Ces hypothèses soutiennent les tests utilisés pour évaluer la fiabilité du modèle et les intervalles de confiance de ses prédictions.
Par ailleurs, les spécialistes du machine learning préfèrent parfois travailler avec des données gaussiennes pour des raisons d'efficacité de calcul. Une distribution normale peut contribuer indirectement à l'efficience de certains algorithmes, notamment ceux qui supposent ou exploitent la normalité des données.
Apprenez avec DataCamp
Cours
Cours
Cours
Tutoriel
Mark Pedigo
Tutoriel
Satyabrata Pal
Tutoriel
Aditya Sharma
Tutoriel
DataCamp Team
Tutoriel
Matt Crabtree
Tutoriel
Aditya Sharma