Curso
Multivariate Probability Distributions in R
4 h
8.8K
Poucos conceitos são tão fundamentais e amplamente aplicáveis em estatística e ciência de dados quanto a distribuição gaussiana. Também conhecido como distribuição normal, esse modelo matemático é a base de inúmeros métodos estatísticos e técnicas de análise de dados.
Este guia abrangente revela o conceito de distribuições gaussianas, explorando suas propriedades, aplicações e importância na análise de dados moderna. Examinaremos por que eles são tão predominantes nos fenômenos naturais e como são usados em vários campos, de finanças a produção.
Se você é iniciante em estatística ou deseja aprimorar os conceitos básicos, nosso curso Introduction to Statistics oferece uma excelente base. Para aqueles que estão prontos para aplicar esses conceitos em linguagens de programação específicas, nossos cursos Statistical Thinking in Python (Parte 1) e Statistics Fundamentals with R ajudarão você a apreciar as diversas formas em que a distribuição gaussiana aparece nas estatísticas descritivas e inferenciais.
A distribuição gaussiana, também conhecida como distribuição normal, é uma distribuição de probabilidade contínua caracterizada por sua curva em forma de sino. Ele é definido por dois parâmetros:
A função de densidade de probabilidade (PDF) de uma distribuição gaussiana é dada por:
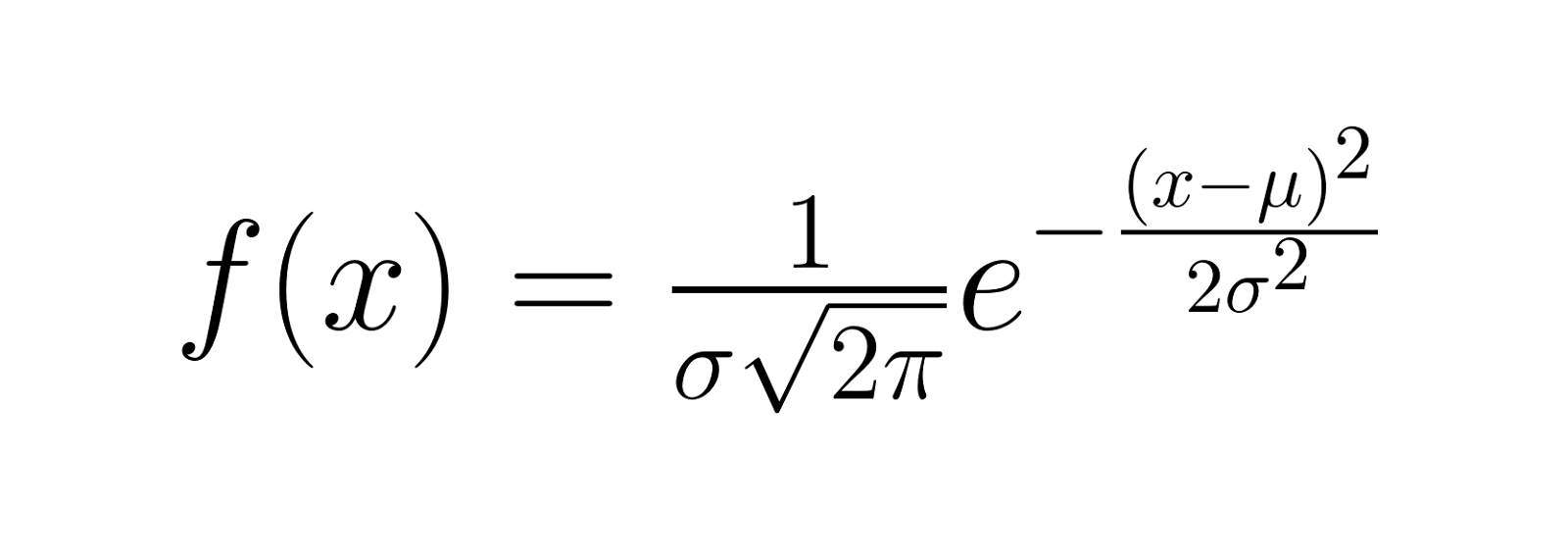
Onde:
Para ilustrar o conceito de uma distribuição gaussiana, considere a distribuição do peso ao nascer de bebês nascidos a termo em uma grande população:
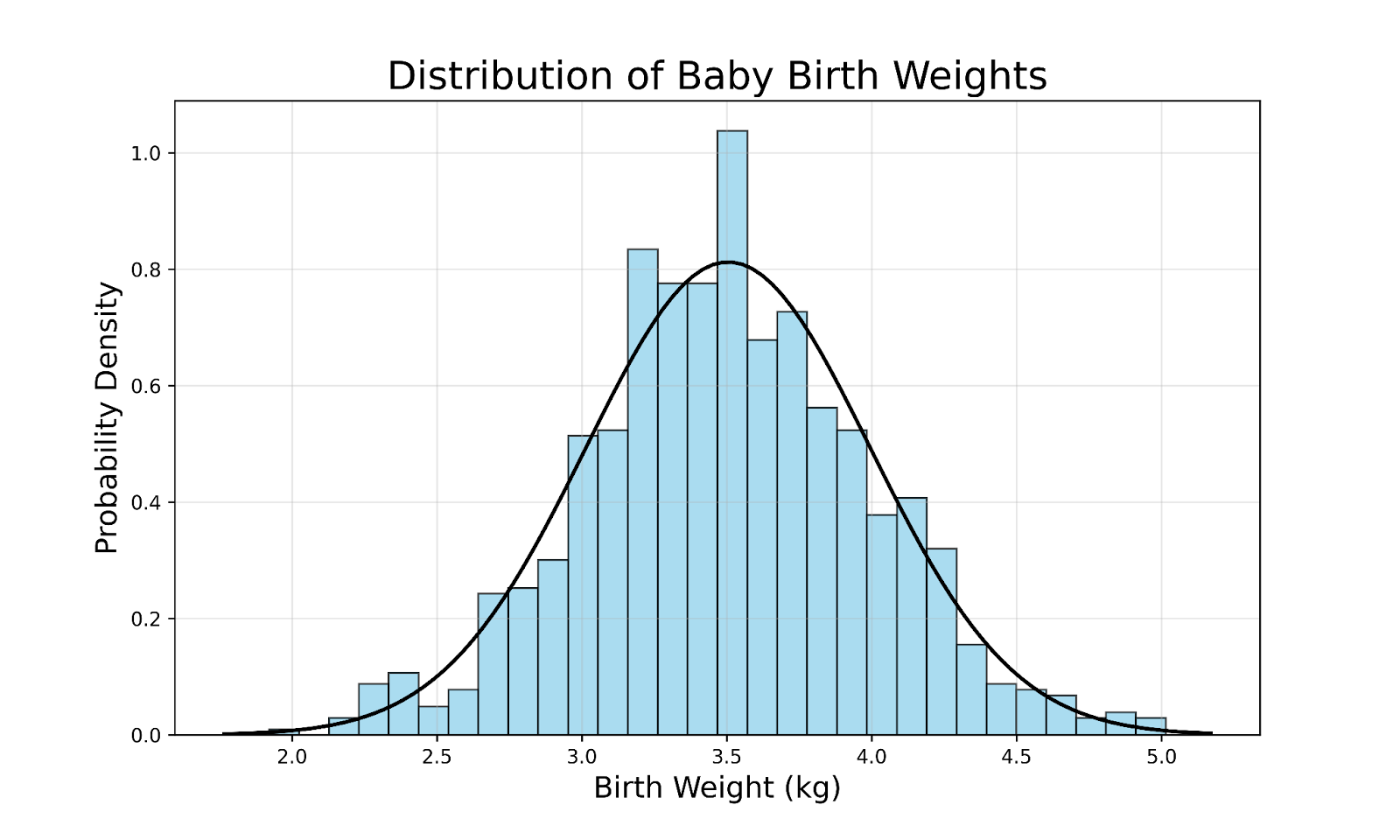
Algumas observações importantes desse gráfico incluem:
A prevalência de distribuições gaussianas na natureza e na estatística pode ser explicada pelo teorema do limite central (CLT). A CLT afirma que a distribuição das médias das amostras se aproxima de uma distribuição normal à medida que o tamanho da amostra aumenta (por exemplo, n ≥ 30), independentemente da distribuição da população subjacente.
Um aspecto importante do CLT é que essa convergência para uma distribuição normal ocorre de forma relativamente rápida à medida que o tamanho da amostra aumenta. Para a maioria dos fins práticos, mesmo amostras de tamanho moderado (por exemplo, n ≥ 30) são suficientes para que as médias das amostras se aproximem de uma distribuição normal. Isso é verdade mesmo que a população em si seja distorcida.
Dentro da classe de distribuições gaussianas, há um caso especial conhecido como distribuição gaussiana padrão, também conhecida mais comumente como distribuição normal padrão. Essa é uma distribuição gaussiana em que:
A função de densidade de probabilidade de uma distribuição gaussiana padrão é dada pela seguinte fórmula.
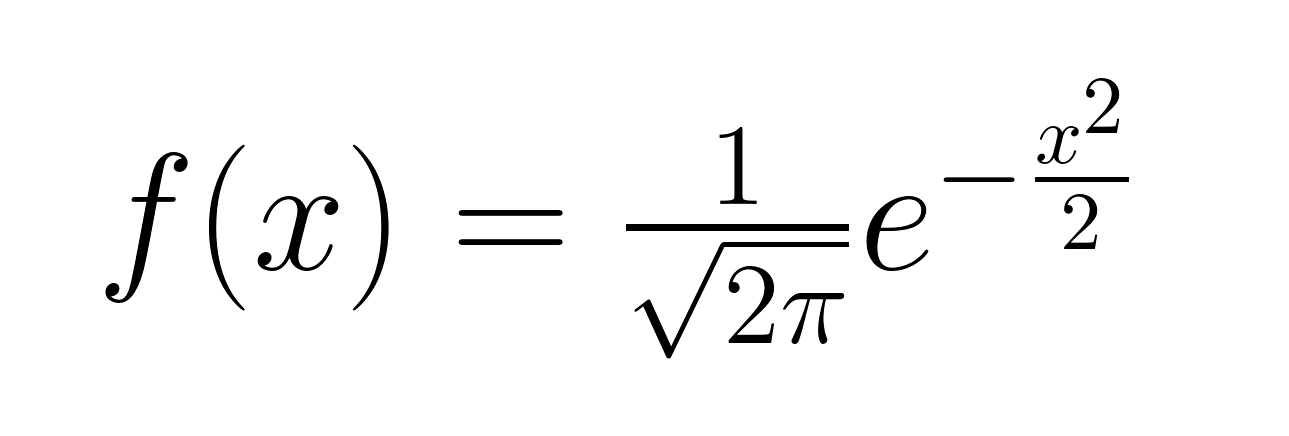
Observe que a fórmula da função de densidade de probabilidade gaussiana padrão é simplificada a partir da forma geral devido aos valores específicos atribuídos à média e ao desvio padrão. Agora, vamos visualizar a distribuição gaussiana padrão.
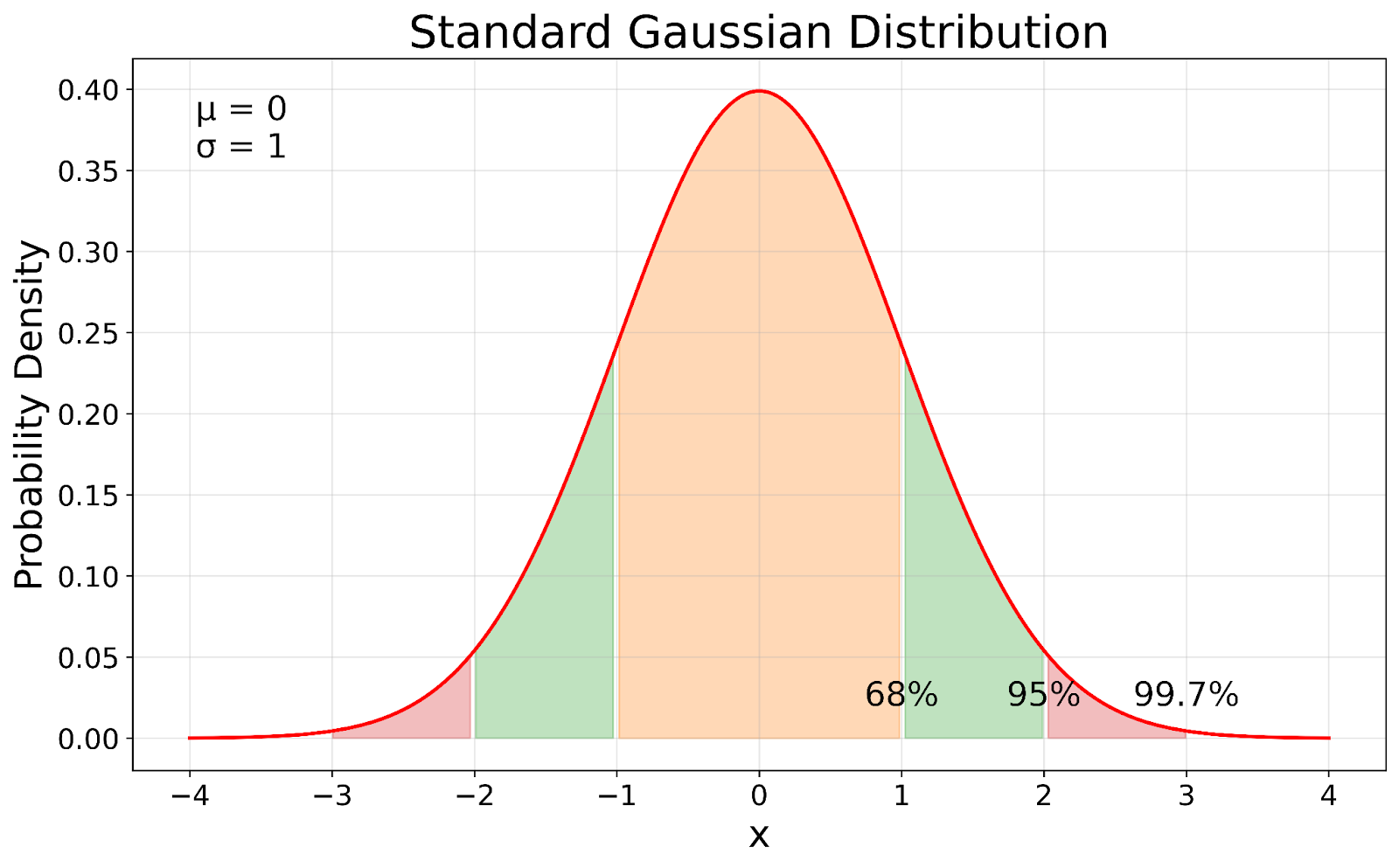 Distribuição Gaussiana padrão. Imagem do autor
Distribuição Gaussiana padrão. Imagem do autor
A distribuição Gaussiana padrão, mostrada em nossa visualização, serve como ponto de referência em estatística. Em nosso visual, você pode ver como a Gaussiana padrão é uma versão padronizada de qualquer distribuição Gaussiana. O processo de padronização desloca a média para 0 e dimensiona o desvio padrão para 1, preservando as propriedades fundamentais da distribuição.
Vejamos agora algumas das propriedades das distribuições gaussianas.
A marca registrada de uma distribuição gaussiana é sua forma simétrica de sino. Essa simetria significa que os dados têm a mesma probabilidade de ficar acima ou abaixo da média, o que é particularmente útil para prever probabilidades e fazer inferências sobre os dados. Conforme mostrado na visualização a seguir, todas as distribuições gaussianas mantêm essa forma de sino característica, independentemente de sua média ou desvio padrão.
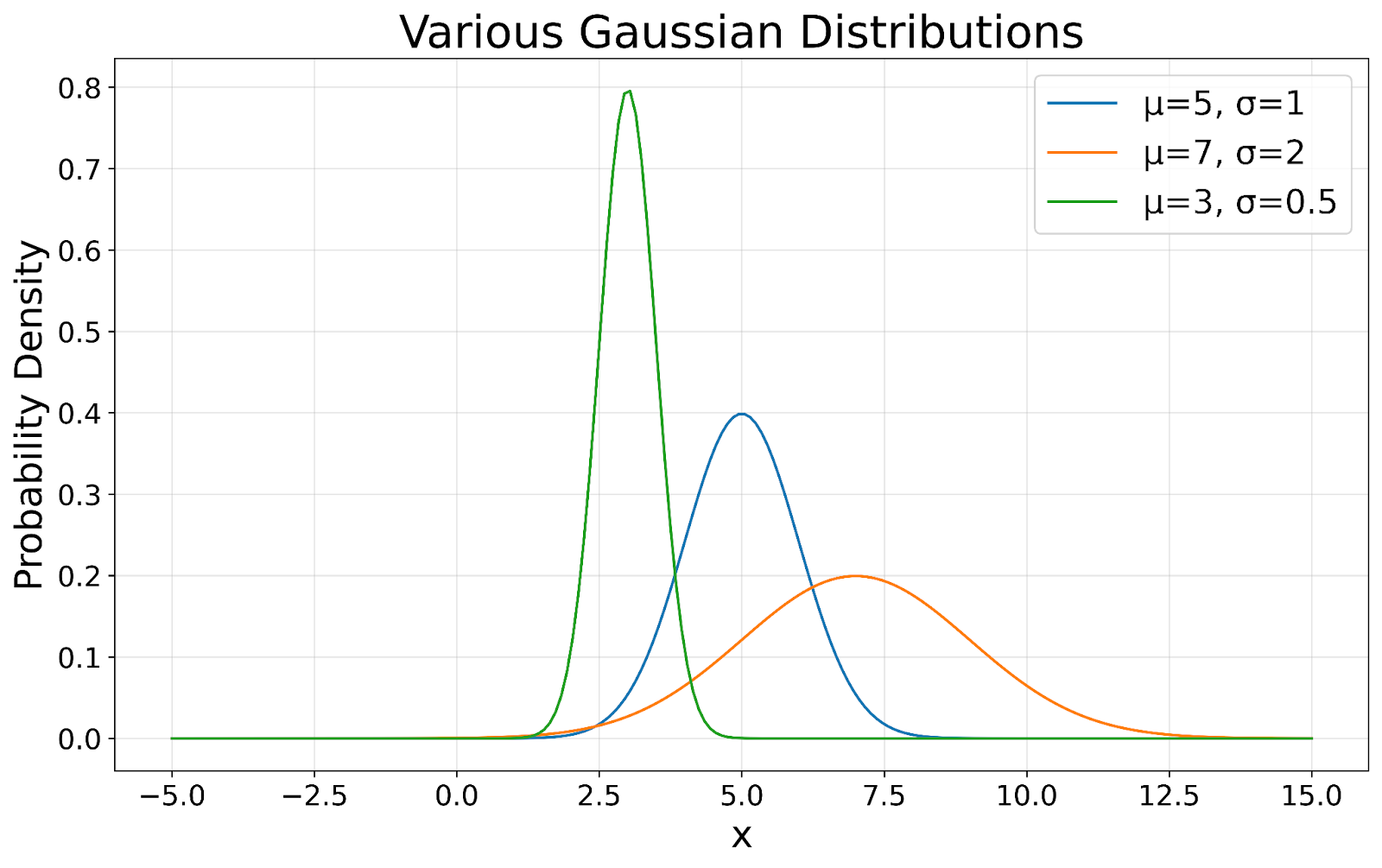 Distribuições Gaussianas visualizadas. Imagem do autor
Distribuições Gaussianas visualizadas. Imagem do autor
Em uma distribuição gaussiana perfeita, a média (average), a mediana (middle value) e a moda (most frequent value) são todas iguais. Esse alinhamento fornece uma indicação clara da tendência central dos dados, o que é valioso para resumir conjuntos de dados. Em nossa visualização, você pode ver como o pico de cada curva representa esse ponto central.
O desvio padrão em uma distribuição gaussiana nos diz o quanto os dados estão espalhados em relação à média. Ele segue um padrão previsível:
Essa regra, conhecida como regra regra 68-95-99,7aplica-se a todas as distribuições gaussianas, independentemente de sua média ou desvio padrão.
As distribuições gaussianas são mais do que apenas um conceito teórico - elas têm uma ampla gama de aplicações em vários campos.
Muitos testes estatísticos, como os testes t e ANOVA, pressupõem que os dados são normalmente distribuídos. Esses testes ajudam os pesquisadores a determinar se há diferenças significativas entre os grupos ou se os efeitos observados são provavelmente devidos ao acaso. A suposição de normalidade permite que os pesquisadores calculem os valores de p e os intervalos de confiança, fornecendo uma estrutura para tirar conclusões dos dados e tomar decisões informadas.
A suposição de normalidade é tão importante que técnicas de reamostragem, como o bootstrapping, foram desenvolvidas para gerar distribuições de reamostragem normalmente distribuídas a partir de dados não normais, facilitando a construção de intervalos de confiança e a realização de outras análises estatísticas. Nosso tutorial sobre testes de hipóteses mostra como você pode realizar esses testes em vários cenários, incluindo situações em que os dados são normalmente distribuídos.
Muitas técnicas de aprendizado de máquina dependem de suposições de normalidade, o que torna as distribuições gaussianas fundamentais para sua operação e interpretação. Na regressão linear, por exemplo, normalmente queremos que os valores y (variável dependente) sigam uma distribuição normal para termos confiança em nossas estimativas. Além disso, queremos que os resíduos (as diferenças entre os valores observados e previstos) tenham uma distribuição normal. Essas premissas de normalidade sustentam os testes estatísticos usados para avaliar a confiabilidade do modelo e os intervalos de confiança de suas previsões.
Além disso, os cientistas de aprendizado de máquina podem preferir trabalhar com dados que seguem uma distribuição gaussiana por motivos de eficiência computacional. Uma distribuição gaussiana pode contribuir indiretamente para a eficiência computacional em determinados algoritmos, especialmente aqueles que pressupõem ou dependem da distribuição normal dos dados.
Aprenda com a DataCamp
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Avinash Navlani
Tutorial
Kevin Babitz
Tutorial
DataCamp Team
Tutorial
Moez Ali
Tutorial
Abid Ali Awan

