Cursus
Gegevens manipuleren in SQL
4 Hr
324.3K
In SQL zijn datasets vaak niet geordend, wat de analyse lastiger kan maken. Om te begrijpen hoe rijen zich binnen een dataset tot elkaar verhouden, kunnen we de functie ROW_NUMBER() gebruiken.
Deze functie kent opeenvolgende nummers toe aan rijen binnen een resultaatset, waardoor je een duidelijke volgorde krijgt voor verdere bewerking en analyse. Dit kan voor de dataset als geheel of voor verschillende groepen binnen de dataset.
Dit artikel gaat uit van voorkennis van de basisprincipes van SQL. We behandelen de basis van de veelgebruikte functie ROW_NUMBER() en geven voorbeelden met oplopende moeilijkheidsgraad.
ROW_NUMBER() SyntaxDit is de basissyntax voor de functie ROW_NUMBER():
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Laten we de belangrijkste onderdelen doornemen:
ROW_NUMBER(): Dit is de functie zelf, die opeenvolgende rijnummers genereert.OVER (...): Deze clausule is verplicht voor vensterfuncties zoals ROW_NUMBER(). Ze definieert de context waarin rijnummers worden berekend.PARTITION BY value_expression: Deze optionele clausule verdeelt de resultaatset in partities op basis van de opgegeven kolom(men) of expressie(s). Rijnummers worden dan onafhankelijk binnen elke partitie berekend.ORDER BY order_by_clause: Deze optionele clausule bepaalt de volgorde waarin rijnummers binnen elke partitie worden toegekend (of binnen de gehele resultaatset als geen PARTITION BY wordt gebruikt).Ter illustratie, zo kunnen we ROW_NUMBER() gebruiken binnen een bredere SQL-query:
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() VoorbeeldenIn de volgende drie voorbeelden gebruiken we de gratis DataLab-IDE. We gebruiken de voorbeelddataset Employees (al opgenomen in DataLab), die de volgende vier kolommen heeft:
first_name: tekenreeksveldlast_name: tekenreeksveldgender: tekenreeksveld met twee waarden (“M” of “F”)hire_date: de datum waarop de medewerker is aangenomenWe kunnen de dataset opvragen met de volgende SQL-code:
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output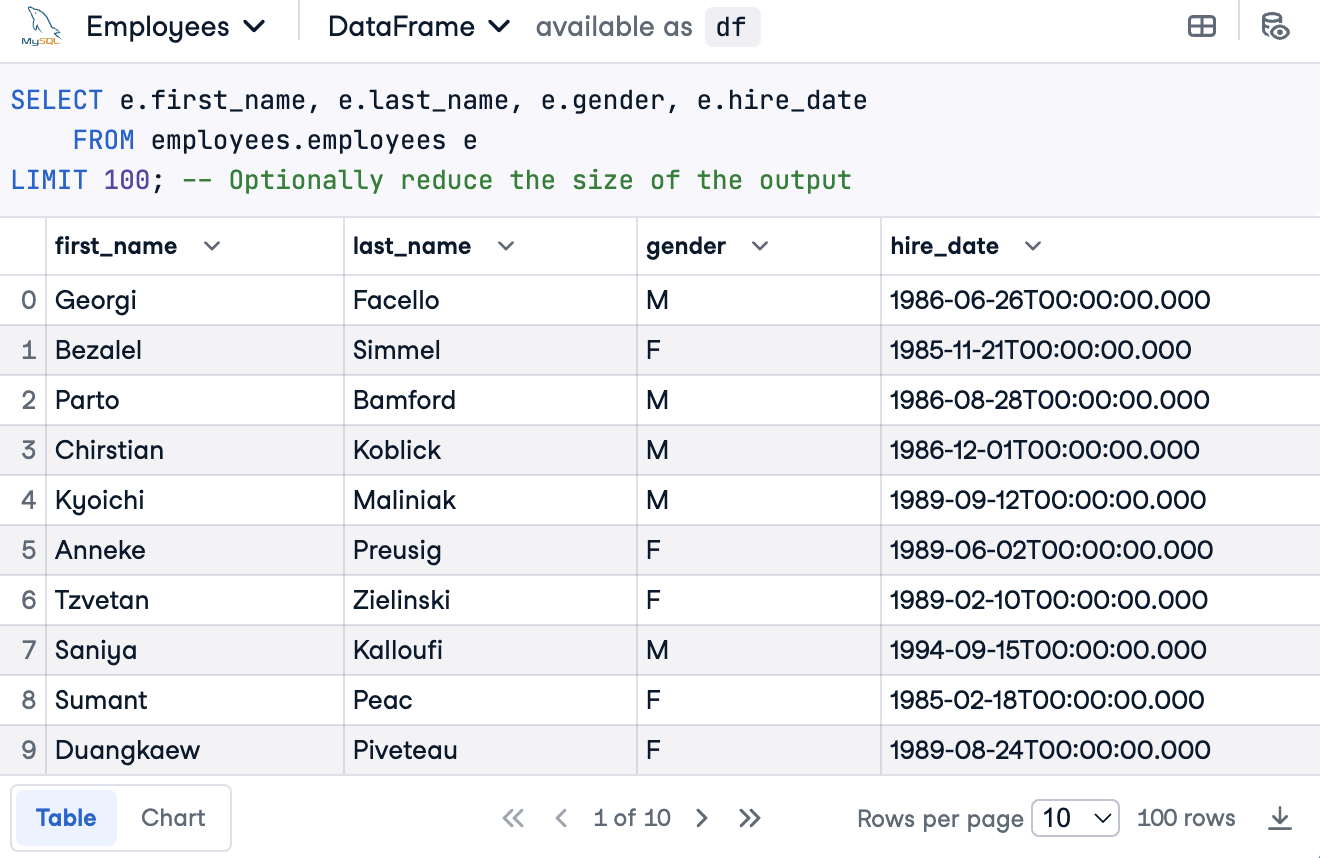
Voordat je ROW_NUMBER() gebruikt, is het belangrijk je doel te bepalen—dat maakt duidelijk of en hoe je wilt partititioneren en ordenen. In dit voorbeeld willen we alle medewerkers alfabetisch ordenen. We hebben geen PARTITION BY-clausule nodig omdat we alle medewerkers in de dataset ordenen. We ordenen klanten op hun achternaam (last_name). We noemen onze nummering name_row_number.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;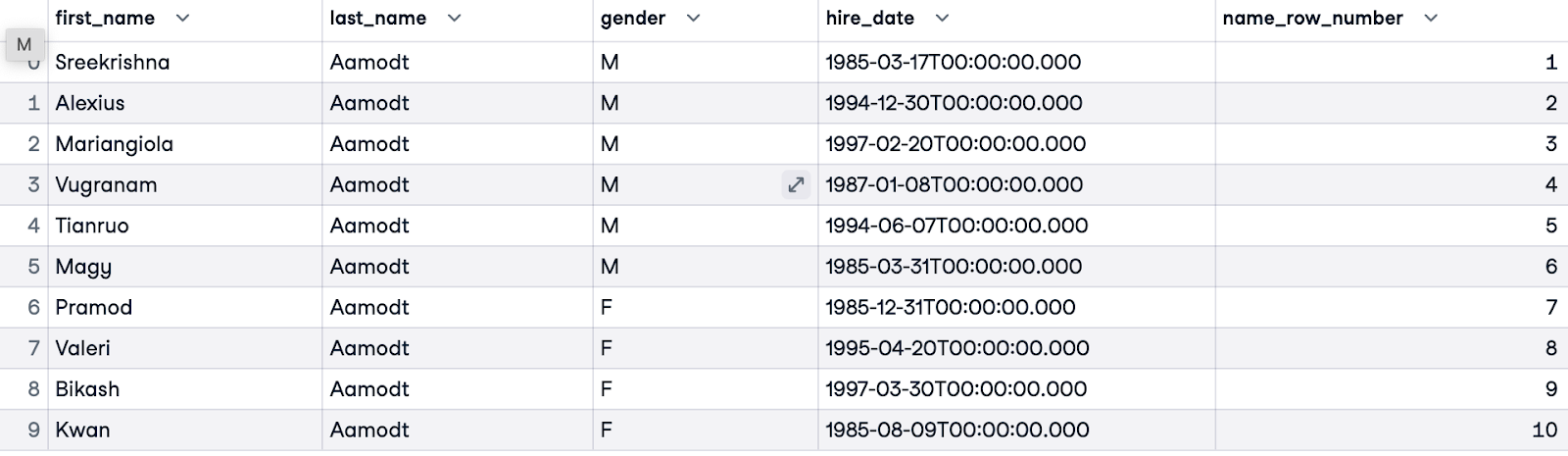
Om gelijke waarden (medewerkers met dezelfde achternaam) aan te pakken, kunnen we de ordening verfijnen door meer kolommen toe te voegen. In het onderstaande voorbeeld ordenen we eerst op last_name en, wanneer een medewerker dezelfde achternaam heeft als iemand anders, vervolgens op voornaam (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;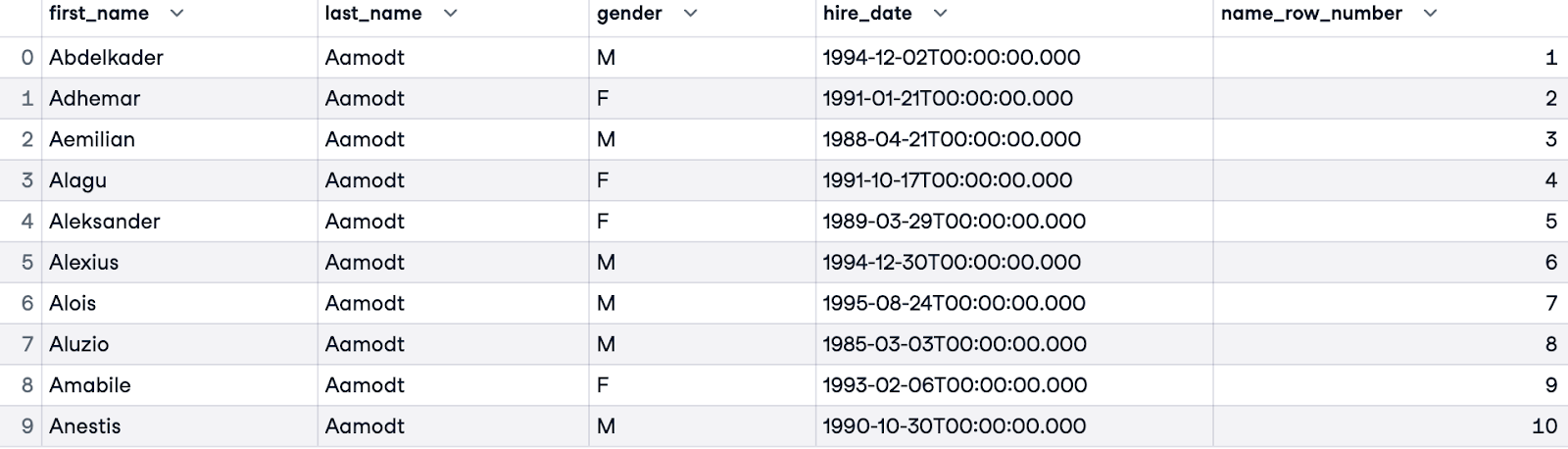
Laten we nu medewerkers ordenen van nieuwste naar oudste indiensttredingsdatum binnen hun respectieve genders. We gebruiken opnieuw de clausule ORDER BY om te sorteren op hire_date, maar dit keer in aflopende volgorde (met DESC) om de meest recente aanstellingen te prioriteren.
Om aparte nummering per gender te krijgen, voegen we de clausule PARTITION BY gender toe. Dit betekent dat rijnummers voor elk afzonderlijk gender weer bij 1 beginnen.
Dit is de volledige query:
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;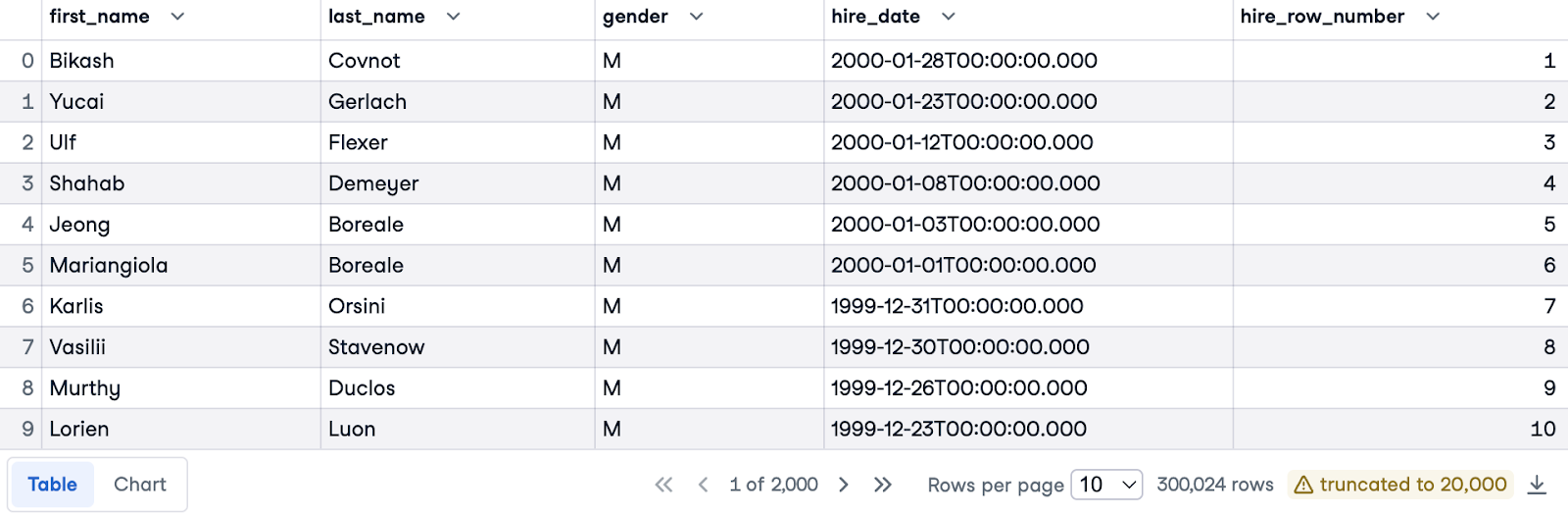
We kunnen deze data vervolgens opvragen met een WHERE-clausule om de meest ervaren medewerker binnen elk gender te vinden:
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
In ons laatste voorbeeld rangschikken we medewerkers op hun salaris, rekening houdend met hun gender. Hiervoor joinen we de tabel employees met de tabel salaries op basis van de kolom emp_no:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;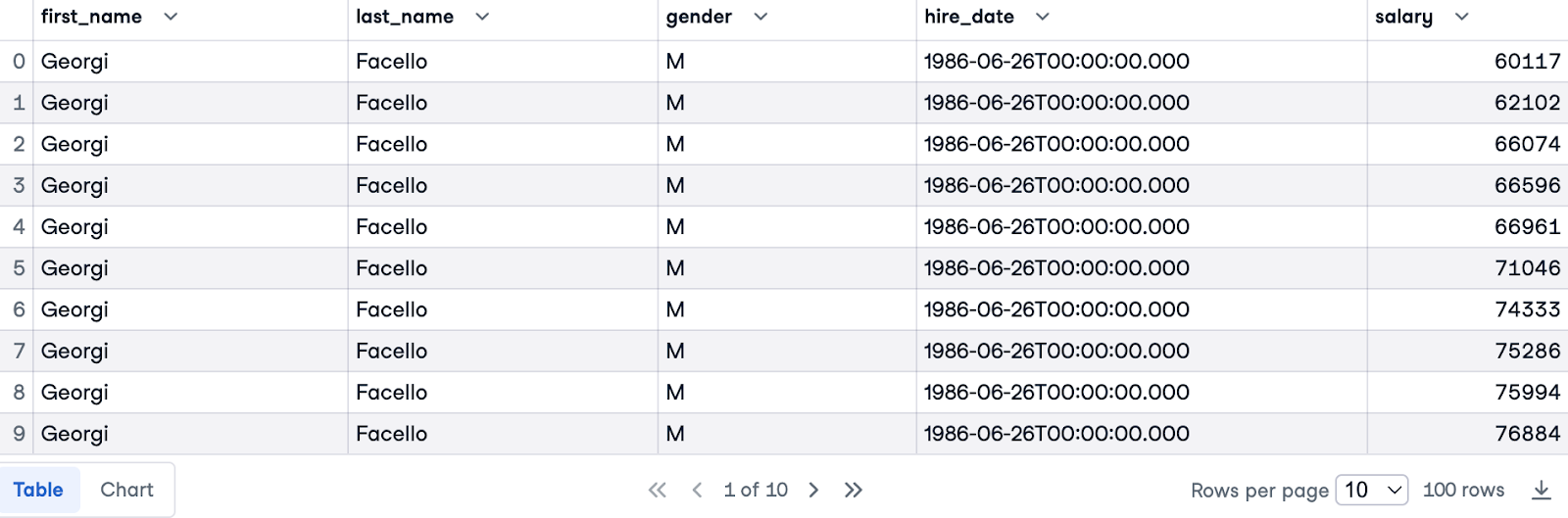
Nu gebruiken we zowel PARTITION BY als ORDER BY. We partitioneren op gender om aparte rankings per gender te krijgen en ordenen op salary in aflopende volgorde om de hoogste inkomens eerst te rangschikken.
Dit is de volledige query:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;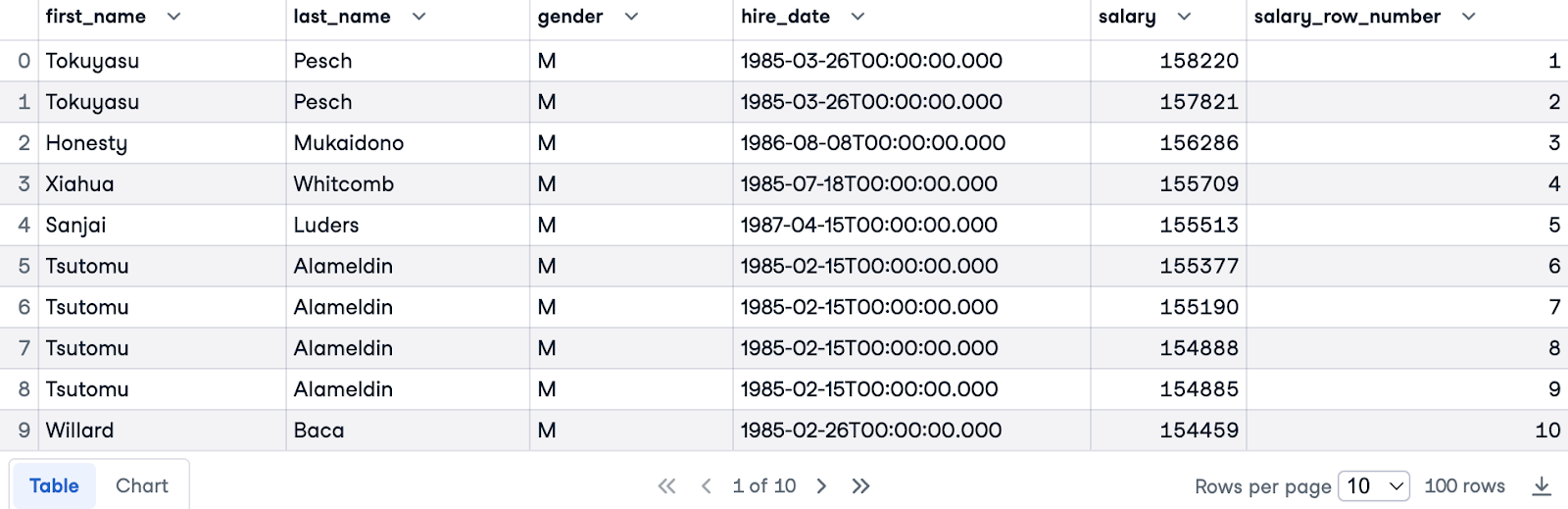
Om de hoogste salarissen per gender te vergelijken, kunnen we de resultaten filteren met een WHERE-clausule. De onderstaande query geeft de top 5 verdieners per gender terug, geordend op hun rang binnen hun gendergroep. Zulke query’s kunnen inzicht geven in loonrechtvaardigheid binnen de dataset.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;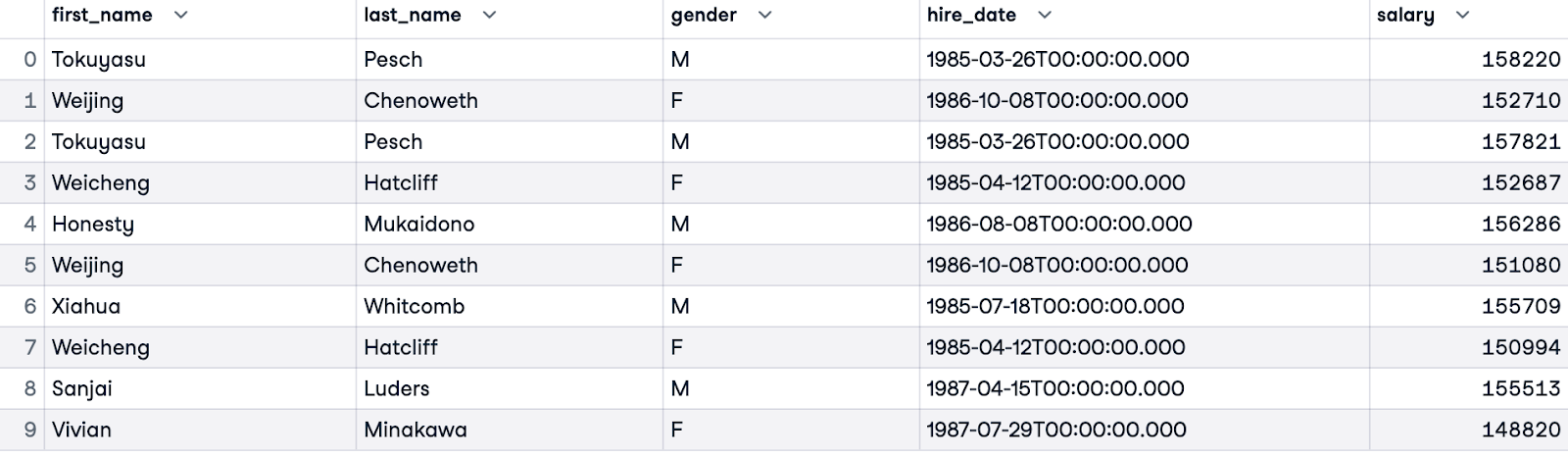
De functie ROW_NUMBER() is handig wanneer we een ongesorteerde dataset hebben en een duidelijke opeenvolgende nummering aan de rijen willen toekennen voor verdere analyse. We bepalen de specifieke volgorde van deze nummers met ORDER BY en definiëren aparte nummerreeksen voor verschillende groepen binnen de data met PARTITION BY.
Vond je dit artikel nuttig en wil je meer leren over SQL? Bekijk dan onze andere SQL-cursussen.
Leer meer over SQL met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
