Corso
Manipolazione dei dati in SQL
4 h
324.3K
In SQL, è comune che i dataset non siano ordinati, cosa che può rendere l’analisi più complessa. Per capire come le righe si relazionano all’interno di un dataset, possiamo usare la funzione ROW_NUMBER().
Questa funzione assegna numeri sequenziali alle righe di un result set, fornendo un ordine chiaro per successive manipolazioni e analisi. Puoi applicarla all’intero dataset o a diversi gruppi di dati all’interno del dataset.
Questo articolo presuppone la conoscenza preliminare dei fondamenti di SQL. Vedremo le basi della funzione ROW_NUMBER(), comunemente utilizzata, e forniremo esempi di difficoltà crescente.
ROW_NUMBER() SyntaxEcco la sintassi di base della funzione ROW_NUMBER():
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Analizziamo i componenti chiave:
ROW_NUMBER(): è la funzione vera e propria, che genera numeri di riga sequenziali.OVER (...): clausola obbligatoria per le funzioni di finestra come ROW_NUMBER(). Definisce il contesto in cui vengono calcolati i numeri di riga.PARTITION BY value_expression: clausola opzionale che divide il result set in partizioni in base alle colonne o espressioni specificate. I numeri di riga vengono poi calcolati in modo indipendente all’interno di ciascuna partizione.ORDER BY order_by_clause: clausola opzionale che specifica l’ordine in cui vengono assegnati i numeri di riga all’interno di ogni partizione (o dell’intero result set se non si usa PARTITION BY).Per illustrare, ecco come potremmo usare ROW_NUMBER() all’interno di una query SQL più ampia:
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() ExamplesNei tre esempi seguenti useremo l’IDE gratuito DataLab. Utilizzeremo il dataset di esempio Employees (già disponibile in DataLab), che contiene le seguenti quattro colonne:
first_name: campo stringalast_name: campo stringagender: campo stringa con due valori (“M” o “F”)hire_date: la data di assunzione del dipendentePossiamo interrogare il dataset con il seguente codice SQL:
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output
Prima di usare ROW_NUMBER(), è importante definire l’obiettivo: questo chiarirà se e come vogliamo partizionare e ordinare. In questo esempio, vogliamo ordinare tutti i dipendenti in ordine alfabetico. Non abbiamo bisogno di una clausola PARTITION BY perché ordiniamo tutti i dipendenti del dataset. Ordineremo i record per cognome (last_name). Chiameremo la nostra numerazione name_row_number.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;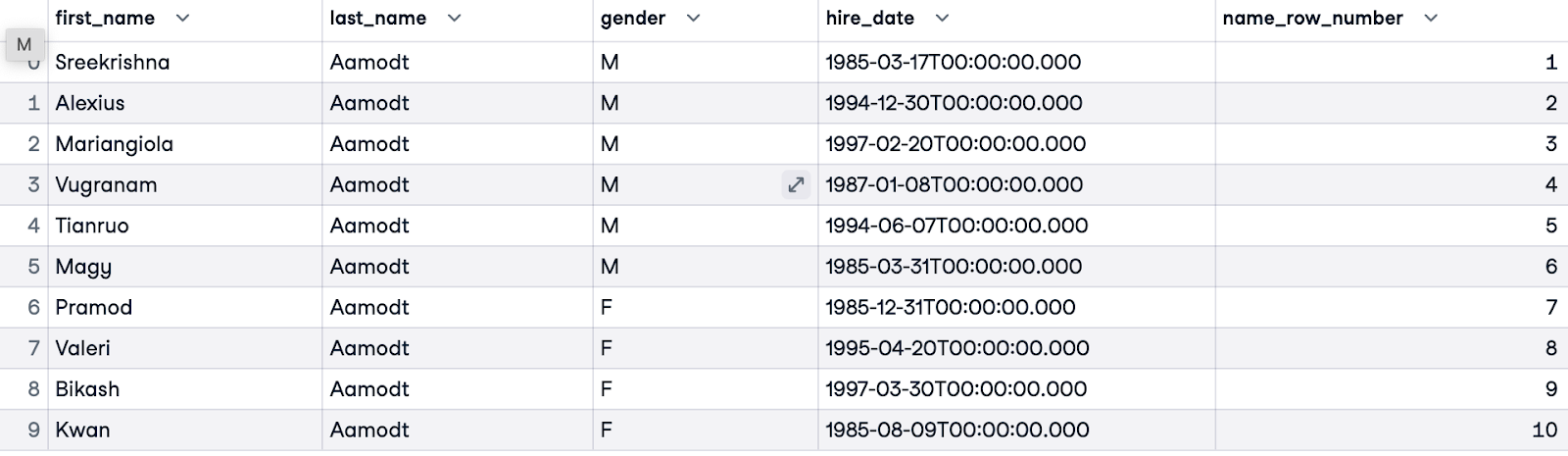
Per gestire i casi di parità (dipendenti con lo stesso cognome), possiamo affinare l’ordinamento aggiungendo altre colonne. Nell’esempio seguente, ordiniamo prima per last_name e poi, quando il cognome è uguale tra più dipendenti, ordiniamo per nome (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;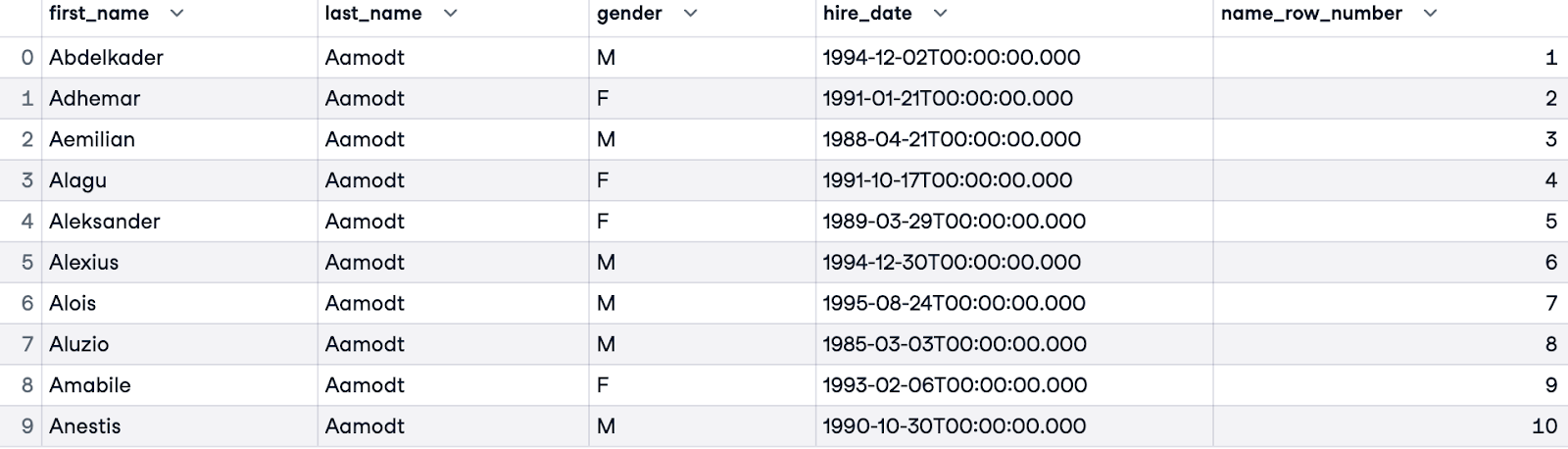
Ora ordiniamo i dipendenti dalla data di assunzione più recente alla meno recente all’interno dei rispettivi generi. Useremo di nuovo la clausola ORDER BY per ordinare per hire_date, ma questa volta in ordine decrescente (con DESC) per dare priorità alle assunzioni più recenti.
Per ottenere una numerazione separata per ciascun genere, introdurremo la clausola PARTITION BY gender. In questo modo i numeri di riga ripartono da 1 per ogni genere distinto.
Ecco la query completa:
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;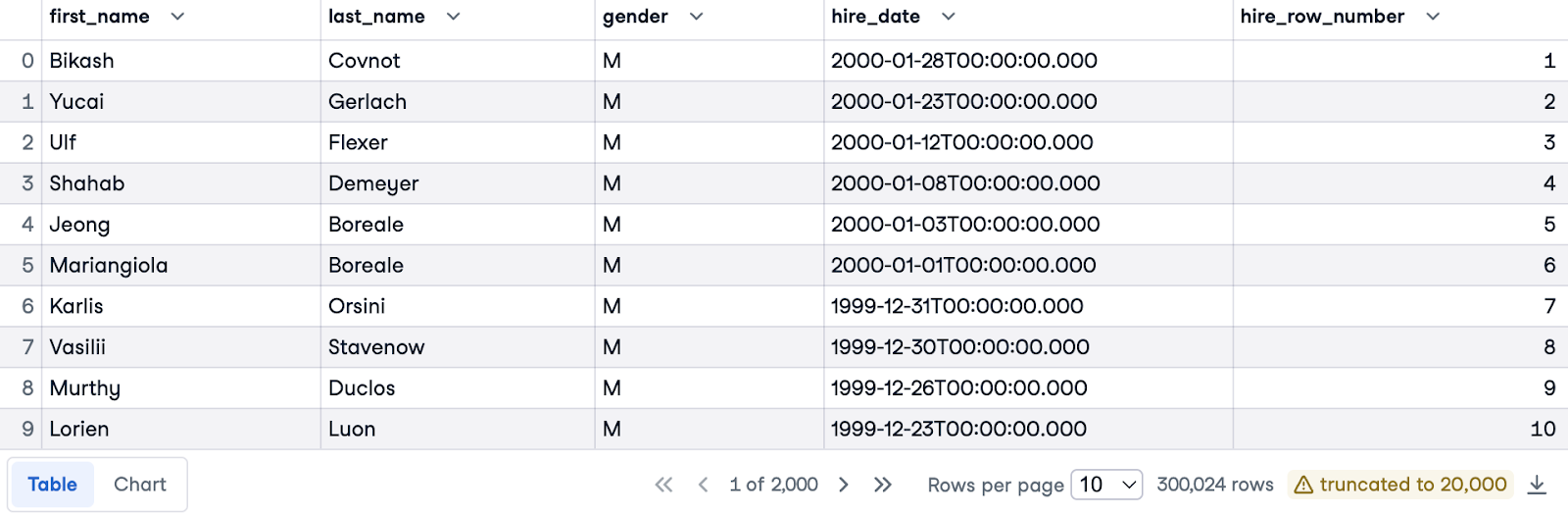
Possiamo poi interrogare questi dati usando una clausola WHERE per trovare il dipendente più esperto in ciascun genere:
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
Nel nostro ultimo esempio classificheremo i dipendenti in base allo stipendio, tenendo conto del loro genere. Per farlo, uniremo la tabella employees con la tabella salaries in base alla colonna emp_no:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;
Ora useremo sia PARTITION BY sia ORDER BY. Partizioneremo per gender per avere classifiche separate per ciascun genere e ordineremo per salary in ordine decrescente per mettere in cima i redditi più alti.
Ecco la query completa:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;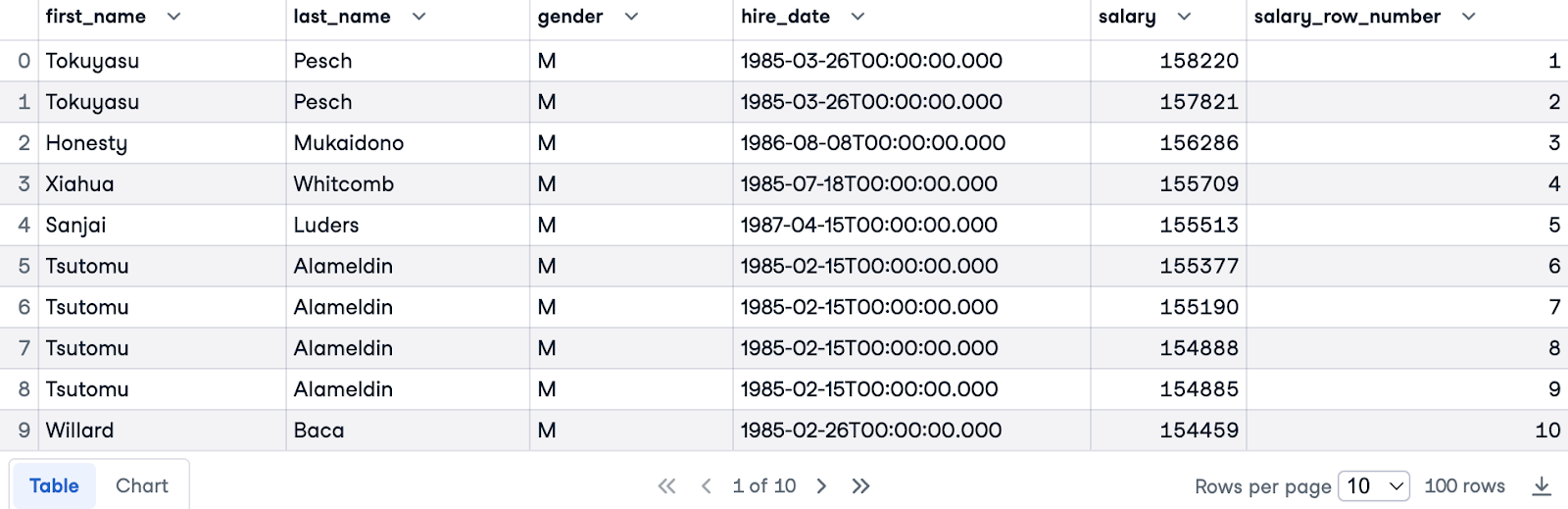
Per confrontare gli stipendi più alti per ciascun genere, possiamo filtrare i risultati usando una clausola WHERE. La query seguente restituisce i primi 5 percettori per ciascun genere, ordinati in base al rango all’interno del rispettivo gruppo. Query di questo tipo possono fornire spunti sull’equità retributiva nel dataset.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;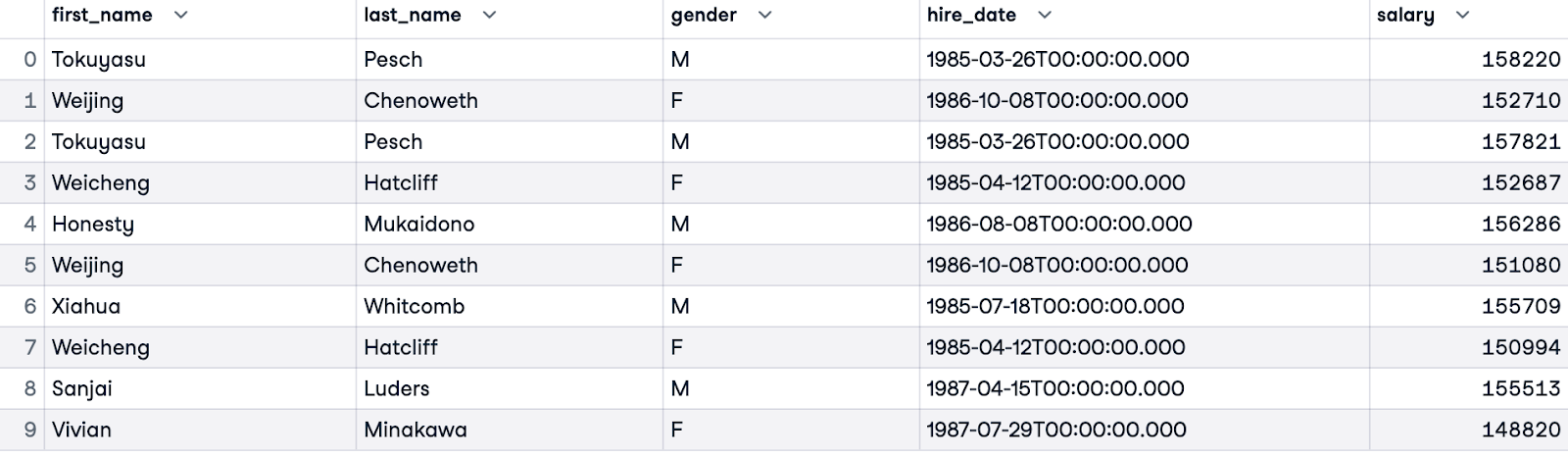
La funzione ROW_NUMBER() è utile quando abbiamo un dataset non ordinato e vogliamo assegnare una numerazione sequenziale chiara alle righe per successive analisi. Definiamo l’ordine specifico di questi numeri con ORDER BY e impostiamo sequenze di numerazione separate per gruppi distinti nei dati con PARTITION BY.
Se hai trovato utile questo articolo e vuoi imparare di più su SQL, dai un’occhiata agli altri nostri corsi SQL.
Approfondisci SQL con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

