Courses
Xử lý dữ liệu trong SQL
4 giờ
324.2K
Trong SQL, các tập dữ liệu thường không có thứ tự, điều này có thể khiến việc phân tích trở nên khó khăn. Để hiểu cách các dòng liên hệ với nhau trong một tập dữ liệu, chúng ta có thể dùng hàm ROW_NUMBER().
Hàm này gán số thứ tự tuần tự cho các dòng trong một tập kết quả, cung cấp một thứ tự rõ ràng để thao tác và phân tích tiếp theo. Việc này có thể thực hiện cho toàn bộ tập dữ liệu hoặc cho các nhóm dữ liệu khác nhau bên trong tập dữ liệu.
Bài viết này giả định bạn đã nắm những kiến thức nền tảng về SQL. Chúng tôi sẽ trình bày những điều cơ bản về hàm ROW_NUMBER() thường dùng và cung cấp các ví dụ với độ khó tăng dần.
ROW_NUMBER() SyntaxĐây là cú pháp cơ bản cho hàm ROW_NUMBER():
ROW_NUMBER() OVER([PARTITION BY value expression, ... ] [ORDER BY order_by_clause])Hãy cùng phân tích các thành phần chính:
ROW_NUMBER(): Bản thân hàm, dùng để tạo số thứ tự dòng tuần tự.OVER (...): Mệnh đề bắt buộc cho các hàm cửa sổ như ROW_NUMBER(). Nó xác định ngữ cảnh để tính số thứ tự dòng.PARTITION BY value_expression: Mệnh đề tùy chọn, chia tập kết quả thành các phân vùng dựa trên cột hoặc biểu thức chỉ định. Số thứ tự dòng được tính độc lập trong từng phân vùng.ORDER BY order_by_clause: Mệnh đề tùy chọn, chỉ định thứ tự gán số trong mỗi phân vùng (hoặc toàn bộ tập kết quả nếu không dùng PARTITION BY).Để minh họa, đây là cách chúng ta có thể dùng ROW_NUMBER() trong một truy vấn SQL tổng quát:
SELECT Val_1,
ROW_NUMBER() OVER(PARTITION BY group_1, ORDER BY number DESC) AS rn
FROM Data;ROW_NUMBER() ExamplesTrong ba ví dụ sau, chúng ta sẽ dùng IDE DataLab miễn phí. Chúng ta sẽ dùng tập dữ liệu mẫu Employees (đã có sẵn trong DataLab), gồm bốn cột sau:
first_name: trường kiểu chuỗilast_name: trường kiểu chuỗigender: trường kiểu chuỗi với hai giá trị (“M” hoặc “F”)hire_date: ngày nhân viên được tuyển dụngChúng ta có thể truy vấn tập dữ liệu bằng đoạn SQL sau:
SELECT e.first_name, e.last_name, e.gender, e.hire_date
FROM employees.employees e
LIMIT 100; -- Optionally reduce the size of the output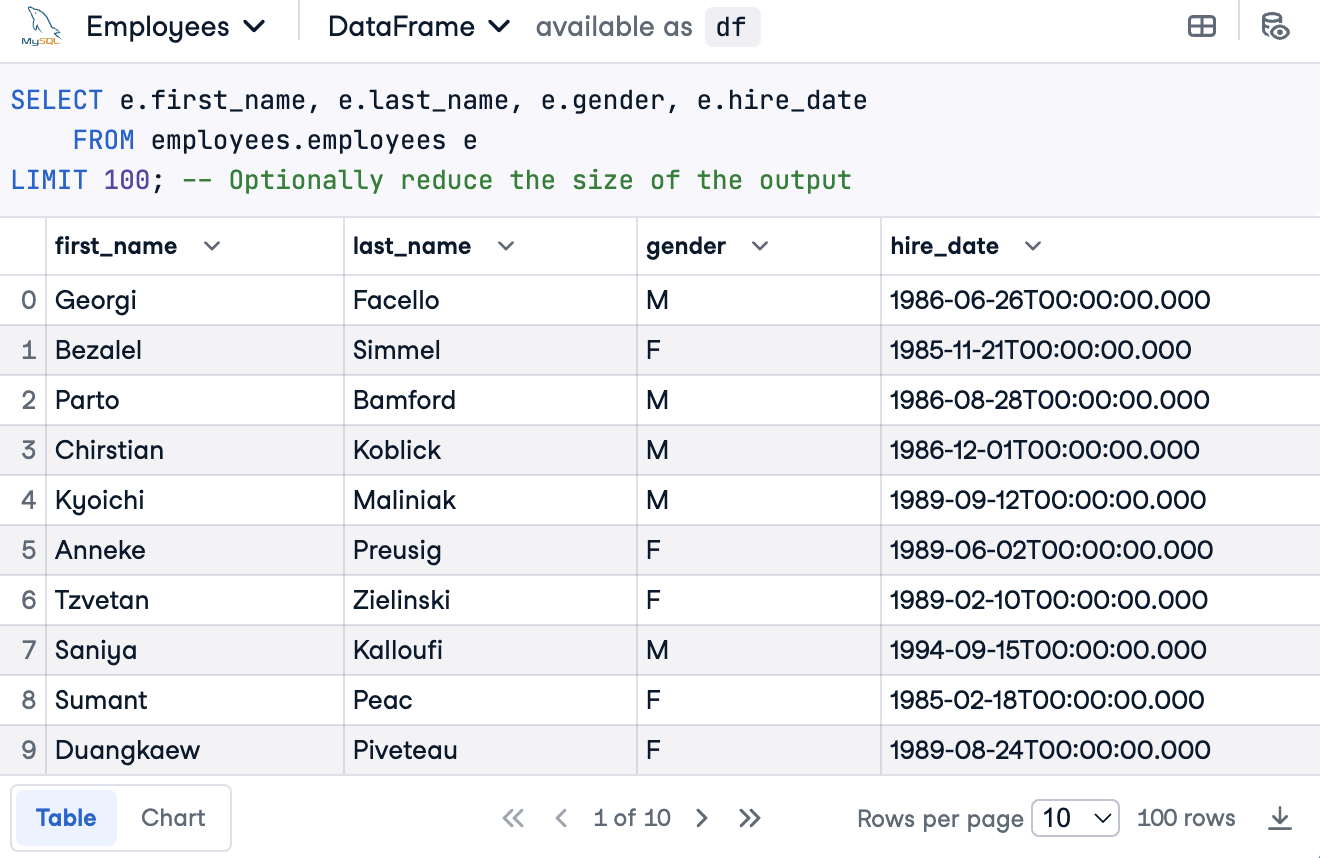
Trước khi dùng ROW_NUMBER(), điều quan trọng là xác định mục tiêu—điều này sẽ làm rõ việc chúng ta có cần phân vùng và sắp xếp hay không và làm thế nào. Ở ví dụ này, chúng ta muốn sắp xếp tất cả nhân viên theo thứ tự chữ cái. Chúng ta không cần mệnh đề PARTITION BY vì đang sắp xếp toàn bộ nhân viên trong tập dữ liệu. Chúng ta sẽ sắp xếp khách hàng theo họ (last_name). Chúng ta sẽ đặt tên cho cột đánh số là name_row_number.
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name) AS name_row_number
FROM employees.employees e;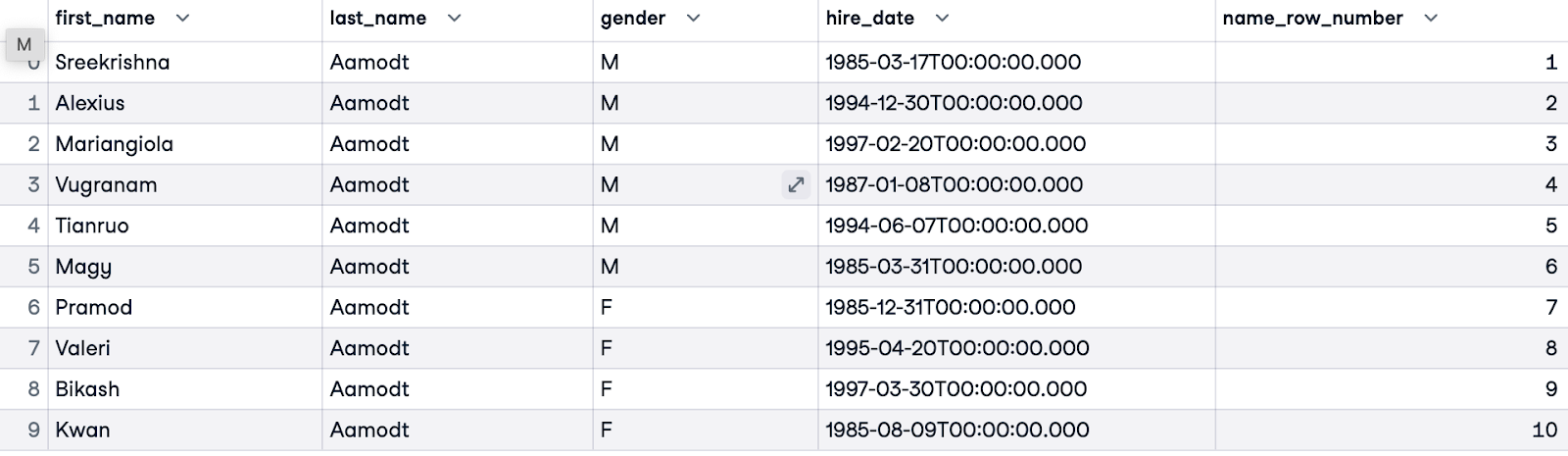
Để xử lý trường hợp trùng (nhân viên có cùng họ), chúng ta có thể tinh chỉnh thứ tự bằng cách thêm nhiều cột. Trong ví dụ dưới đây, chúng ta sắp xếp trước theo last_name, và khi họ của một nhân viên trùng với người khác, chúng ta sẽ sắp xếp tiếp theo tên (first_name).
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(ORDER BY e.last_name, e.first_name) AS name_row_number
FROM employees.employees e;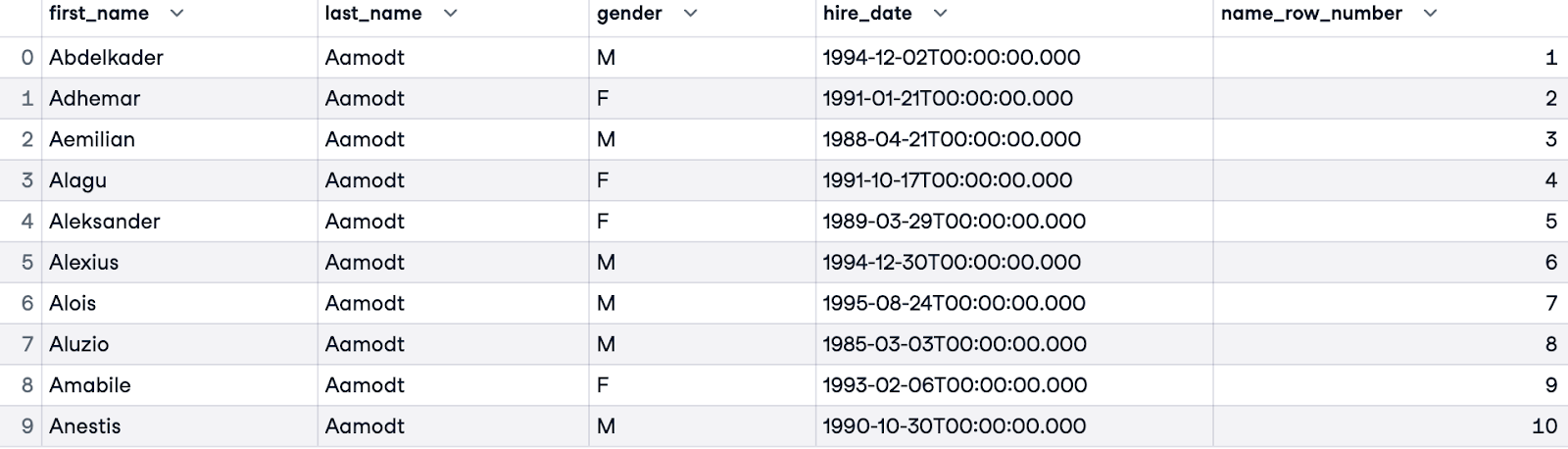
Bây giờ, hãy sắp xếp nhân viên từ ngày tuyển gần nhất đến xa nhất trong từng giới tính tương ứng. Chúng ta tiếp tục dùng mệnh đề ORDER BY để sắp xếp theo hire_date, nhưng lần này theo thứ tự giảm dần (dùng DESC) để ưu tiên các trường hợp tuyển gần đây nhất.
Để có đánh số riêng cho từng giới tính, chúng ta sẽ thêm mệnh đề PARTITION BY gender. Điều này có nghĩa là số thứ tự sẽ bắt đầu lại từ 1 cho mỗi giới tính khác nhau.
Đây là truy vấn hoàn chỉnh:
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e;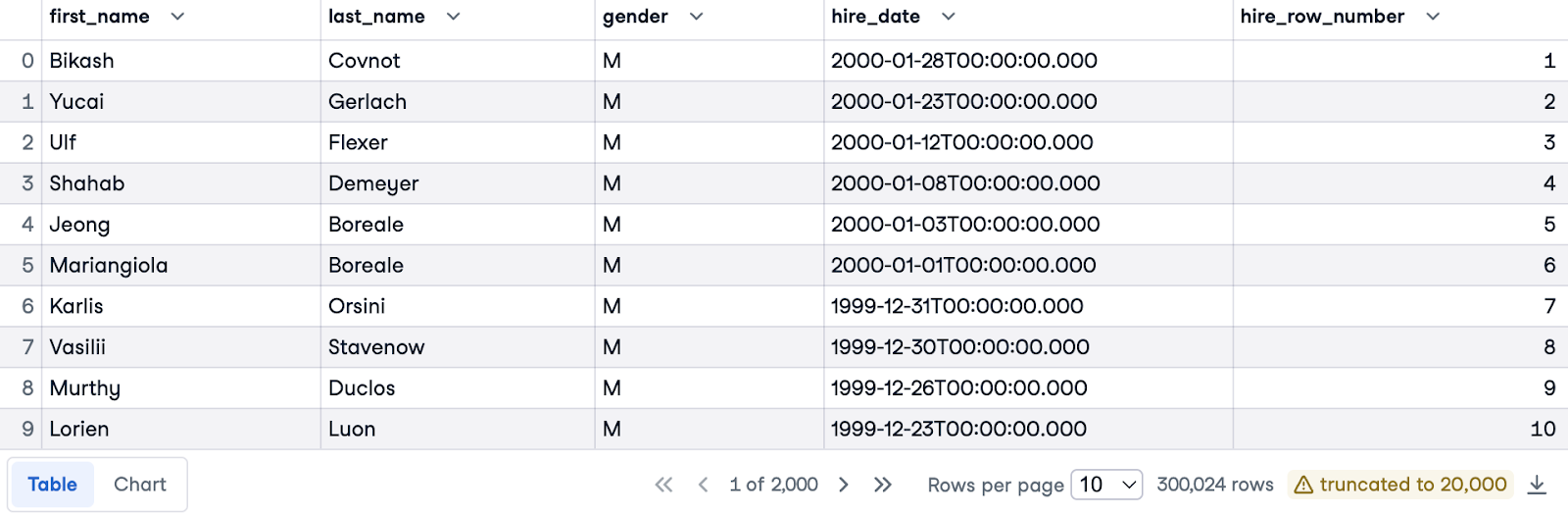
Sau đó, chúng ta có thể truy vấn dữ liệu này bằng mệnh đề WHERE để tìm nhân viên có thâm niên cao nhất trong mỗi giới tính:
WITH RankedEmployees AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date,
ROW_NUMBER() OVER(PARTITION BY gender ORDER BY hire_date DESC) AS hire_row_number
FROM employees.employees e
)
SELECT first_name, last_name, gender, hire_date
FROM RankedEmployees
WHERE hire_row_number = 1;
Ở ví dụ cuối, chúng ta sẽ xếp hạng nhân viên theo mức lương, xét theo giới tính. Để làm được điều này, chúng ta sẽ nối bảng employees với bảng salaries dựa trên cột emp_no:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;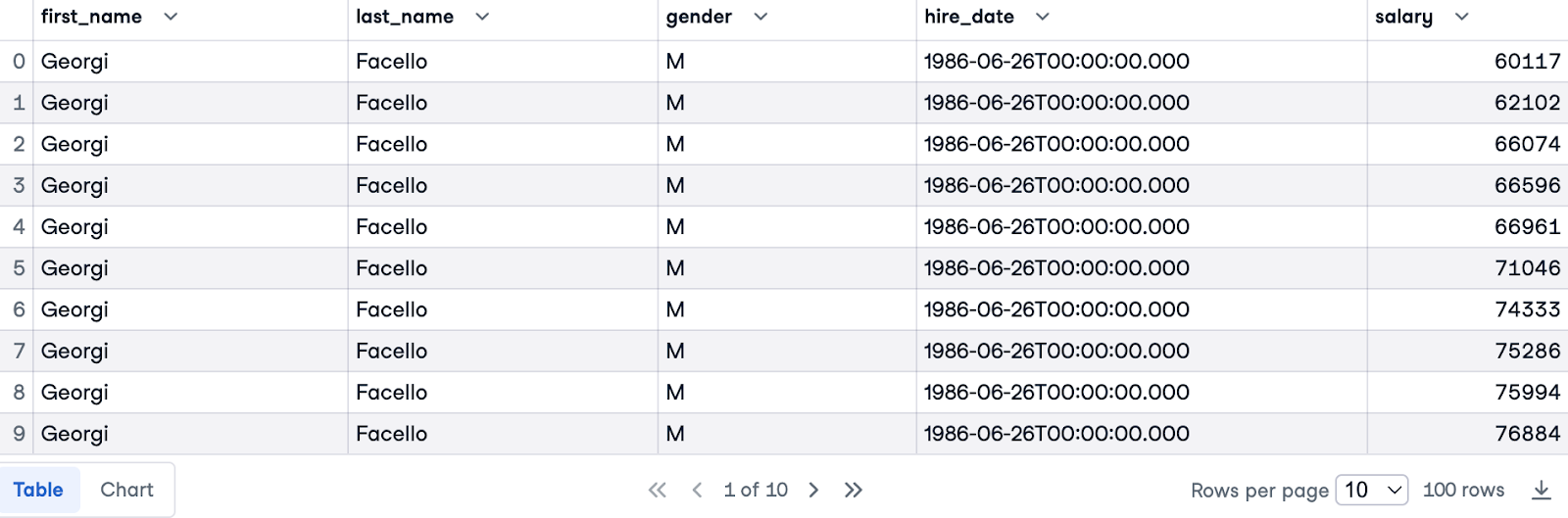
Bây giờ, chúng ta sẽ dùng cả PARTITION BY và ORDER BY. Chúng ta phân vùng theo gender để có xếp hạng riêng cho từng giới tính và sắp xếp theo salary giảm dần để ưu tiên người có thu nhập cao nhất trước.
Đây là truy vấn hoàn chỉnh:
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER () OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
LIMIT 100;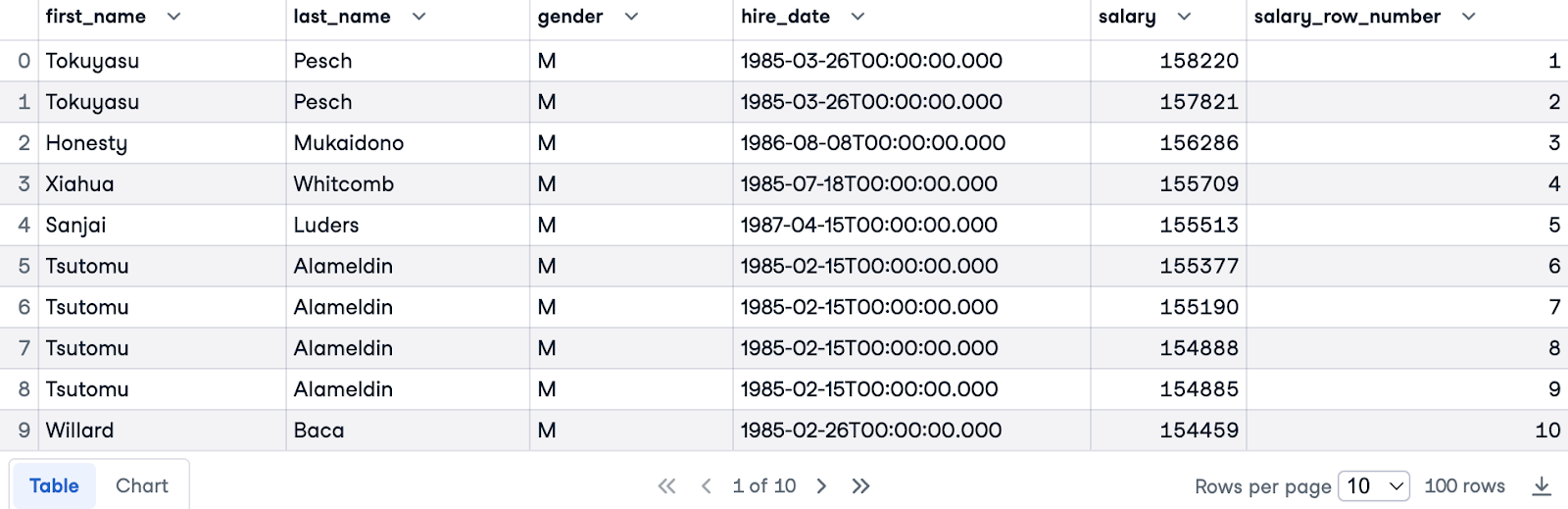
Để so sánh các mức lương cao nhất của mỗi giới tính, chúng ta có thể lọc kết quả bằng mệnh đề WHERE. Truy vấn dưới đây sẽ trả về 5 người có thu nhập cao nhất cho mỗi giới tính, được sắp xếp theo thứ hạng trong nhóm giới tính của họ. Những truy vấn như vậy có thể cung cấp góc nhìn về bình đẳng tiền lương trong tập dữ liệu.
WITH RankedSalaries AS (
SELECT e.first_name, e.last_name, e.gender, e.hire_date, s.salary,
ROW_NUMBER() OVER(PARTITION BY e.gender ORDER BY s.salary DESC) AS salary_row_number
FROM employees.employees e
JOIN employees.salaries s ON e.emp_no = s.emp_no
)
SELECT first_name, last_name, gender, hire_date, salary
FROM RankedSalaries
WHERE salary_row_number <= 5
ORDER BY salary_row_number, gender;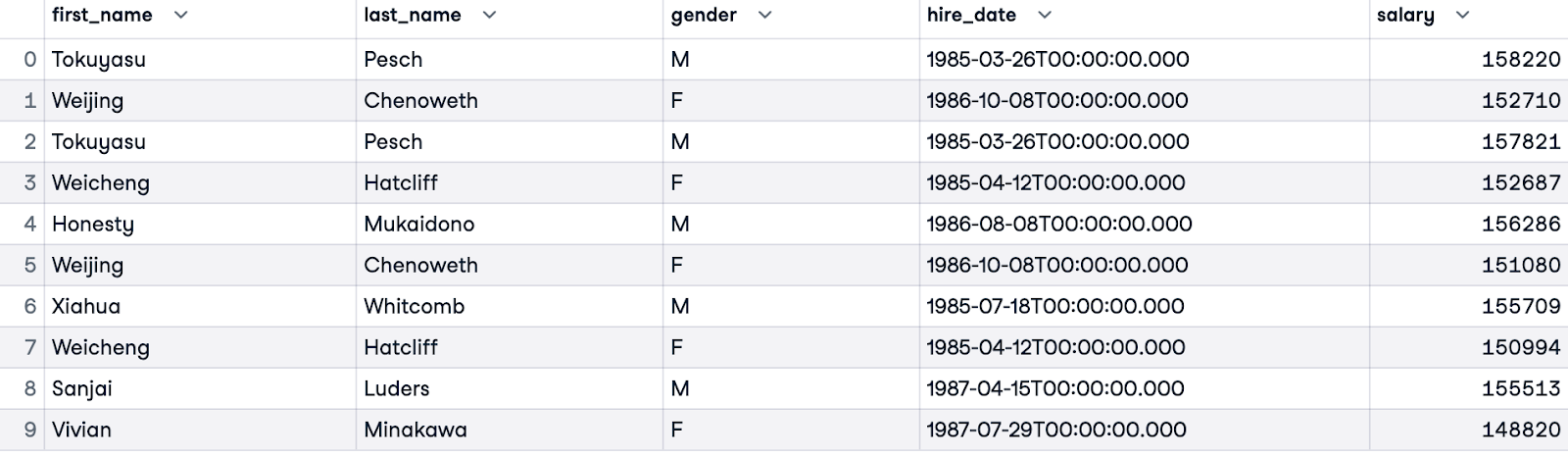
Hàm ROW_NUMBER() hữu ích khi chúng ta có một tập dữ liệu không có thứ tự và muốn gán số thứ tự tuần tự rõ ràng cho các dòng để phục vụ phân tích tiếp theo. Chúng ta xác định thứ tự cụ thể của các số này bằng ORDER BY và xác định các chuỗi đánh số riêng cho từng nhóm trong dữ liệu bằng PARTITION BY.
Nếu bạn thấy bài viết này hữu ích và muốn học thêm về SQL, hãy xem các khóa học SQL khác của chúng tôi.
Học thêm về SQL với các khóa học này!
Courses
Courses
Courses