
Leerpad
Associate Data Engineer in SQL
30 Hr
In dit artikel bespreek ik een aantal technieken die je helpen dbt te leren en het opzetten van projecten en datamodellen te stroomlijnen, zodat het hele proces beter beheersbaar wordt.
Daarnaast ga ik in op de specifieke dbt‑projectontwerppatronen waar ik dagelijks op vertrouw. Deze methoden bleken van onschatbare waarde bij het bouwen van dataplatforms en datawarehouses die accuraat, intuïtief, makkelijk te navigeren en gebruiksvriendelijk zijn.
Door deze aanpakken toe te passen wordt het makkelijker om dataplatforms te realiseren die aan hoge kwaliteitsnormen voldoen en mogelijke problemen te minimaliseren, wat uiteindelijk leidt tot succesvollere datagedreven projecten.
dbt (Data Build Tool) is een krachtige open‑sourceoplossing die speciaal is ontworpen voor datamodellering. Het maakt gebruik van SQL‑templates en ref()‑ (referentie)functies om relaties vast te leggen tussen verschillende database‑objecten zoals tabellen, views, schema’s en meer. De flexibiliteit is ideaal voor wie het DRY‑principe (Don’t Repeat Yourself) volgt.
Met dbt kun je één SQL‑template maken dat opnieuw te gebruiken is en eenvoudig kan worden aangepast aan verschillende dataomgevingen. Zodra de template is geschreven, kan deze worden "gecompileerd" om de SQL‑queries te genereren die nodig zijn voor uitvoering in elke specifieke omgeving.
De aanpak van dbt verhoogt de efficiëntie en zorgt voor consistentie in verschillende fasen van de datapijplijn. Het vermindert redundantie en potentiële fouten, terwijl het onderhoud en opschalen van de datainfrastructuur eenvoudiger wordt.
Datamodellering speelt een centrale rol in data‑engineering, en dbt is daarvoor een uitstekend hulpmiddel. Sterker nog, ik zou stellen dat dbt beheersen absoluut essentieel is voor iedereen die een succesvolle dataprofessional wil worden!
Bekijk de onderstaande dbt‑template. Het is een eenvoudige tabeldefinitie, maar bevat metadata die aangeeft welke database en welk schema je moet gebruiken:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Stel dat we verderop in de datapijplijn een view hebben die voortkomt uit de tabel (table_a.sql) die we hierboven hebben gemaakt. Onze datapijplijn‑afstamming ziet er dan zo uit:

Voorbeeld van datapijplijn‑afstamming. Afbeelding door de auteur.
We gebruiken de functie ref() om twee stappen in onze pijplijn te verbinden. In ons geval kan table_b.sql zo worden gedefinieerd:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1De functie ref() geeft aan dat het model table_b na table_a komt (downstream). Nu kunnen we de hele pijplijn uitvoeren met één dbt‑commando: dbt run --select tag:example.
Dankzij de herbruikbaarheid van code biedt dbt features die het een uitstekend hulpmiddel maken voor het beheren en optimaliseren van dataprocessen in verschillende omgevingen (productie, ontwikkeling, testen, enz.).
Een van de kernmogelijkheden is bovendien het automatisch genereren van uitgebreide SQL‑documentatie, wat de transparantie sterk verbetert en het begrijpen van datamodellen voor data‑ontwikkelaars en business‑stakeholders eenvoudiger maakt.
Een van de uitdagingen bij datamodellering is het bouwen van complexe SQL‑transformatiepijplijnen met meerdere lagen, terwijl je code herbruikbaar blijft. Deze pijplijnen vragen om zorgvuldig nadenken en nauwgezet testen om efficiënt te functioneren en organisatiebrede transparantie te behouden, zodat iedereen de logica kan begrijpen. Ook hierbij kan dbt helpen.
Daarnaast ondersteunt dbt data‑kwaliteitstests en unit‑tests voor SQL‑logica, waarmee je de nauwkeurigheid en betrouwbaarheid van je transformaties gestructureerd en geautomatiseerd kunt valideren (CI/CD‑workflows).
Een andere belangrijke feature is de flexibele automatisering met macro’s, waarmee je aanpasbare en herbruikbare code‑snippets kunt inzetten, complexe taken stroomlijnt en de productiviteit verhoogt.
Deze gecombineerde functionaliteiten maken dbt een ideale oplossing voor alle SQL‑gerelateerde taken en dataomgevingen: van het waarborgen van dataintegriteit tot het automatiseren van repetitieve processen, en dat alles met behoud van efficiëntie en schaalbaarheid.
Laten we aan de slag gaan met voorbeelden in dbt en BigQuery als dataplatform!
Voor deze tutorial gebruiken we Google Cloud BigQuery als datawarehouse‑oplossing. Dankzij de gratis laag is het perfect om te leren. Je kunt BigQuery activeren in je Google Cloud‑account.
We installeren dbt lokaal met Python en pip, maken een virtual environment en gaan voorbeeldmodellen en tests draaien.
Voer de volgende commando’s uit in je command line:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtOns requirements.txt moet de volgende dependencies bevatten:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Voor de rest van de tutorial doen we het volgende:
Laten we service‑accountgegevens maken voor onze dbt‑applicatie:
Een serviceaccount voor BigQuery maken in Google Cloud. Afbeelding door de auteur.
De private key van het service‑account opslaan in JSON‑formaat. Afbeelding door de auteur.
dbt init uit in een terminal om ons dbt‑project te initialiseren. Als je klaar bent met de setup, krijg je een bericht als dit:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.En de mapstructuur zou er ongeveer zo uit moeten zien:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtWe zien dat profiles.yml is aangemaakt in de rootmap van onze lokale machine, maar idealiter willen we die in onze applicatiemap hebben, dus laten we hem verplaatsen.
cd my_dbt
touch profiles.ymlLaten we tot slot de inhoud van profiles.yml aanpassen zodat de projectnaam klopt en de Google‑service‑accountgegevens zijn opgenomen:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comDat is het! We zijn klaar om ons project te compileren.
export DBT_PROFILES_DIR='.'
dbt compileDe output zou er ongeveer zo uitzien:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')De initiële projectsetup is klaar.
We willen ons dbt‑project zo inrichten dat het handig en transparant de datawarehouse‑architectuur weerspiegelt.
Ik raad aan om templates en macro’s in je dbt‑project te gebruiken en aangepaste databasenamen op te nemen om je dataomgevingen effectief te scheiden in productie, ontwikkeling en testen.
Deze aanpak verbetert de organisatie en verkleint het risico op onbedoelde wijzigingen in de verkeerde omgeving, wat de algehele databeheersing en workflowstabiliteit vergroot. Zo beheren en onderhouden we deze omgevingen eenvoudig, en blijft productiedata beschermd en onaangetast door experimentele of testwijzigingen.
Databases in verschillende omgevingen kun je ook gestructureerd en consistent benoemen met relevante suffixen (_prod, _dev, _test), zodat je omgevingen makkelijk onderscheidt en soepel kunt migreren en deployen.

De verschillende datawarehouse‑lagen in een productieomgeving. Afbeelding door de auteur.
Zo kunnen we de belangrijkste datamodellagen verplaatsen naar de naamgevingsconventie voor databases met raw_‑ en base_‑prefixen in de databasenaamgeving:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsOm deze aangepaste databasenamen dynamisch in te voegen hoef je alleen een dbt‑macro te maken die dit automatisch afhandelt. Met deze aanpak worden de juiste databasenamen in de juiste dataomgeving gebruikt zonder elke keer handmatig configuraties te hoeven wijzigen.
Bekijk de onderstaande code‑snippet met een macro om verschillende schema’s in te stellen afhankelijk van de omgeving waarin we werken:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Wanneer we onze modellen compileren, past dbt nu automatisch de aangepaste databasenaam toe op basis van de configuratie binnen de setup van elk model. Dat betekent dat tijdens het compileren de juiste databasenaam wordt ingevoegd, zodat de modellen aansluiten op de juiste omgeving — productie, ontwikkeling of testen.
Door dit in te bouwen, zijn handmatige wijzigingen aan de databasenaam niet meer nodig, wat onze workflow efficiënter en nauwkeuriger maakt.
Deze benodigde configuraties kun je instellen in properties.yml voor onze modellen:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullZoals je ziet, kunnen we dankzij de Jinja‑ondersteuning in dbt eenvoudige voorwaardelijke statements gebruiken om logica in de configuratiebestanden te introduceren.
Macro’s kun je hier niet gebruiken, maar je kunt wel eenvoudige conditionals toepassen met Jinja‑expressies binnen .yml‑bestanden. Ze moeten tussen aanhalingstekens staan, zodat de templating‑taal tijdens uitvoering correct wordt geïnterpreteerd.
Laten we een dbt compile‑commando draaien en kijken wat er gebeurt:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt ondersteunt variabelen, een zeer krachtige manier om te customizen. Variabelen kun je zowel in SQL‑templates als in macro’s gebruiken en je kunt ze vanaf de command line meegeven zoals hier:
dbt run -m table_b -t dev --vars '{my_var: my_value}'Variabelen moeten worden gedeclareerd in het hoofdbestand dbt_project.yml. Hieronder zie je hoe dat kan:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Laten we variabelen gebruiken om aangepaste tabelnamen (aliassen) in dbt te maken.
Als er geen alias is ingesteld, wordt standaard de oorspronkelijke modelnaam (bestandsnaam) als alias gebruikt. Deze eenvoudige logica zorgt ervoor dat modellen worden verwezen met hun geconfigureerde alias of hun standaardnaam, afhankelijk van de setup. De implementatie hiervoor ziet er als volgt uit en biedt flexibiliteit in hoe modellen over omgevingen worden benoemd en gebruikt:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Laten we dit gedrag overschrijven met variabelen. Dit is een veelgebruikte setup voor data‑developers om te voorkomen dat ze elkaar in de weg zitten tijdens staging (ontwikkeling).
We willen de naam van de developer toevoegen aan alle database‑objecten (tabellen, views, enz.) die door ontwikkelaars in de ontwikkelomgeving worden aangemaakt.
Maak een macro generate_alias_name.sql:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}Vergeet niet onze nieuwe variabele toe te voegen aan dbt_project.yml en voer dit uit in je command line:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Je zou dan zoiets moeten zien:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1We zien dat onze variabele is toegevoegd aan een tabelnaam: table_a_mike.
In deze sectie gaat het om hoe we ons datawarehouse ontwerpen qua datatransformatie. Een vereenvoudigde logische projectstructuur in dbt kan er zo uitzien:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlZelf houd ik de funderende (base) datamodellaag het liefst zo schoon en eenvoudig mogelijk, en pas ik transformaties alleen toe wanneer dat nodig is. Met deze aanpak streven we ernaar een base_‑laag te ontwerpen en te implementeren met minimale datamanipulatie op kolomniveau.
Toch kan in sommige gevallen een beperkte bewerking voordelen bieden, met name om queryprestaties te optimaliseren. Kleine aanpassingen in de base‑laag kunnen de efficiëntie aanzienlijk verbeteren, waardoor het de moeite loont eenvoud en performance in balans te brengen. In dat geval zijn een extra join of een partitioneringsfilter te rechtvaardigen.
Een aanbevolen praktijk is om de volgende technieken toe te passen om je datamodellen en pijplijnen te verbeteren:
biz_- en mart_‑lagen. Dit kan de prestaties verbeteren en zorgt ervoor dat businesslogica efficiënt wordt beheerd.select * en overweeg lange, complexe SQL‑bestanden op te splitsen in kleinere modellen met unit‑tests.Bekijk de onderstaande SQL‑query. Die laat zien hoe je zo’n custom materialization maakt:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Als we nu een extra model table_c toevoegen om deze feature te demonstreren, kunnen we onderstaande SQL gebruiken:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Als we dit compileren, ziet het eruit als een SQL‑script:
$ dbt compile -m table_c -t devDe output:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Het voordeel hiervan is dat we niet meer afhankelijk zijn van de BigQuery‑adapter. Als we een andere tabel of view maken die naar deze operation verwijst, kunnen we gewoon de standaardfunctie ref() gebruiken.
Zo wordt table_c automatisch herkend als een dependency in de data‑lineage. Dit maakt het makkelijk om relaties tussen tabellen te volgen en zorgt dat de relaties tussen verschillende modellen goed zijn gedocumenteerd binnen je dataomgeving.
Deze methode helpt bij het beheren van dependencies en biedt een helder beeld van hoe data door verschillende stadia stroomt, inclusief complexe verwerkingsstappen met scripts. Dit is vooral nuttig bij het onderhouden van complexe datapijplijnen.
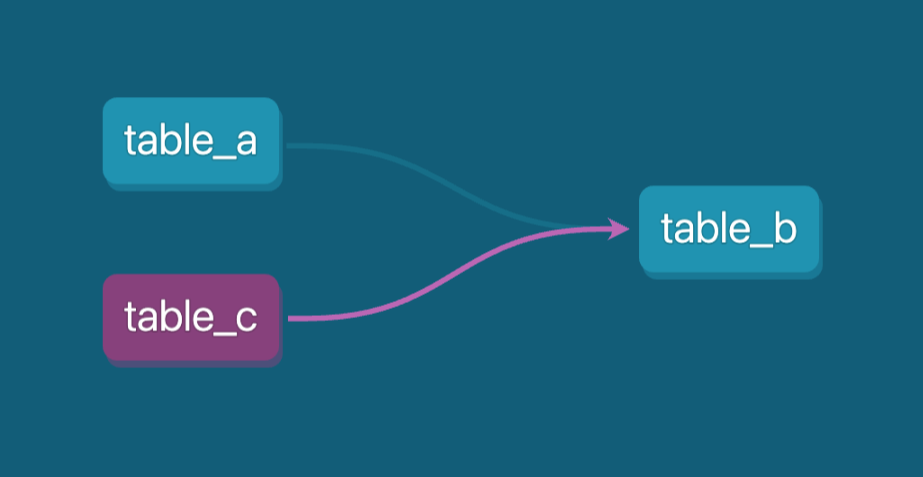
DAG (directed acyclic graph) in dbt toont de dependencies voor table_b. Afbeelding door de auteur
Nu hoeven we alleen nog table_c toe te voegen aan onze pijplijn:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;Documentatie wordt automatisch gegenereerd als we het volgende uitvoeren in onze command line!
dbt docs generate
dbt docs serveEen geavanceerder voorbeeld van een datawarehouse‑project in dbt kan eruitzien als de onderstaande structuur. Het bevat meerdere databronnen en transformaties via diverse modellagen (stg, base, mrt, biz) om uiteindelijk datamart‑modellen op te leveren.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlUnit‑testing is een cruciale stap in het datapijplijnproces, waarbij we tests draaien om de logica achter onze datamodellen te valideren. Zoals je unit‑tests voor Python‑functies zou uitvoeren om te controleren of ze naar verwachting werken, pas ik een vergelijkbare aanpak toe op datamodellen.
Door deze tests uit te voeren, kunnen we potentiële problemen vroegtijdig opsporen en zekerstellen dat de transformaties en logica correct functioneren. Deze praktijk helpt de datakwaliteit te behouden en voorkomt dat fouten door de pijplijn heen sluipen — een essentieel onderdeel van data‑engineering.
We kunnen eenvoudig een unit‑test voor een model toevoegen door het bestand properties.yml te wijzigen:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Als we nu het commando dbt test draaien in onze command line, voeren we de unit‑tests uit:
% dbt test --select "table_b,test_type:unit"Dit is de output:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Probeer de rij‑id in expect te wijzigen naar 3, dan krijgen we voor dezelfde test een foutmelding:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt biedt ook ondersteuning voor controles op datakwaliteit. Eerder schreef ik hierover in de blogpost over datacontracten. We kunnen vrijwel alles testen wat relevant is voor datakwaliteit, zoals versheid van data, rij‑condities, granulariteit, enzovoort.
Kijk eens naar ons model table_b. Daar staan al wat datacontroles op:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullHier testen we onder de definitie tests onze gematerialiseerde table_b.id op unique en not_null. Om deze specifieke test te draaien, gebruik je het volgende commando:
dbt test -s table_bWe kunnen onze datasets ook testen op referentiële integriteit. Dat is essentieel bij datamodellen met joins, omdat het garandeert dat relaties tussen entiteiten correct blijven. Deze tests helpen te bepalen hoe verschillende entiteiten, zoals tabellen of kolommen, zich tot elkaar verhouden.
Bekijk bijvoorbeeld onderstaande dbt‑code, die illustreert hoe elke refunds.refund_id is gekoppeld aan een geldige transactions.id. Deze mapping zorgt ervoor dat alle refunds aan legitieme transacties zijn verbonden, waardoor de integriteit van je data behouden blijft en verweesde records of inconsistente relaties in je datamodellen worden voorkomen:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idData‑eisen hebben vaak betrekking op verwachtingen over wanneer nieuwe data beschikbaar moet zijn en welke maximale vertraging voor updates is toegestaan. Deze controles zijn cruciaal om te zorgen dat data relevant blijft voor analyses (up‑to‑date).
In dbt kun je dit implementeren met freshness‑tests, waarmee je kunt monitoren of nieuwe data binnen het verwachte tijdsbestek arriveert.
Je kunt bijvoorbeeld een freshness‑test configureren die controleert of het meest recente record in een tabel voldoet aan je gedefinieerde criteria voor versheid. Zo leveren je datapijplijnen tijdige en consistente updates, blijft je data betrouwbaar en accuraat, en voldoe je aan tijdsgevoelige vereisten.
Bekijk de onderstaande code‑snippet. Die laat zien hoe je in dbt een freshness‑test instelt:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1Al deze dbt‑tests zijn geweldig en heel nuttig in het dagelijkse werk van data‑engineers! Ze helpen het datawarehouse goed beheerd te houden en de datapijplijnen consistent.
Een datawarehouse‑oplossing bouwen is complex en vereist zorgvuldige planning en organisatie. dbt, als templating‑engine, helpt dit consequent te doen.
In dit artikel heb ik verschillende technieken beschreven om dbt‑mappen voor datatransformatie te organiseren, zodat helderheid en samenwerking verbeteren. Door SQL‑bestanden logisch te structureren, creëren we een omgeving die ook voor nieuwkomers in het project gemakkelijk te verkennen is.
DBT biedt een breed scala aan features om het proces verder te stroomlijnen. Zo kunnen we onze SQL‑templates verrijken met herbruikbare stukjes code via macro’s, variabelen en constanten. Uit mijn ervaring helpt dit — in combinatie met infrastructure‑as‑code — om goede CI/CD‑workflows af te dwingen, wat ontwikkeling en deployment aanzienlijk versnelt.
Wil je je dbt‑kennis verder uitbouwen? Volg dan de cursus Introduction to dbt op DataCamp. Een uitstekende bron om met nog meer hands‑on oefening succesvol van start te gaan!
Leer meer over dbt en data‑engineering met deze cursussen!
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
