
Program
Yardımcı Veri Mühendisi SQL içinde
30 sa
Bu yazıda, dbt’yi öğrenmeye ve proje kurulumunu ile veri modellemeyi düzene koymaya yardımcı olacak bazı teknikleri özetliyorum; böylece genel süreç daha yönetilebilir hale geliyor.
Ayrıca, günlük işlerimde güvendiğim belirli dbt proje tasarım kalıplarına da değineceğim. Bu yöntemler; doğru, sezgisel, gezmesi kolay ve kullanıcı dostu veri platformları ile veri ambarları inşa etme çabalarımda paha biçilmez oldu.
Bu yaklaşımları uygulamak, potansiyel sorunları en aza indirirken yüksek kalite standartlarını karşılayan veri platformları oluşturmayı kolaylaştırır ve sonuçta daha başarılı veri odaklı projelere yol açar.
dbt (Data Build Tool), özellikle veri modelleme için tasarlanmış güçlü bir açık kaynaklı çözümdür; SQL şablonlarından ve tablolar, görünümler, şemalar ve daha fazlası gibi çeşitli veritabanı örnekleri arasında ilişkiler kurmak için ref() (referans verme) işlevlerinden yararlanır. Esnekliği, DRY (Kendini Tekrarlama) ilkesini benimseyenler için uygundur.
dbt ile tek bir SQL şablonu oluşturabilir, bunu yeniden kullanabilir ve farklı veri ortamlarına kolayca uyarlayabilirsiniz. Şablon yazıldıktan sonra, her bir spesifik ortamda çalıştırma için gerekli SQL sorgularını üretmek üzere "derlenebilir".
dbt’nin benimsediği yaklaşım, verimliliği artırır ve farklı veri hatlarının aşamalarında tutarlılık sağlar; yinelenmeyi ve olası hataları azaltırken veri altyapısını sürdürme ve ölçeklendirme sürecini basitleştirir.
Veri modelleme veri mühendisliğinin merkezinde yer alır ve dbt bunun için mükemmel bir araçtır. Hatta, başarılı bir veri profesyoneli olmak isteyen herkes için dbt’de ustalaşmanın kesinlikle olmazsa olmaz olduğunu iddia ederim!
Aşağıdaki dbt şablonunu düşünün. Basit bir tablo tanımıdır, ancak hangi veritabanı ve şemanın kullanılacağını kullanıcıya söyleyen yerleşik metaveriler taşır:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Aşağı yönde, veri hattında, yukarıda oluşturduğumuz tablodan (table_a.sql) çıkan bir görünüm olduğunu hayal edelim. Dolayısıyla, veri hattı soy kütüğümüz şöyle görünecektir:

Örnek veri hattı soy kütüğü. Görsel: Yazar.
Boru hattımızın iki aşamasını birbirine bağlamak için ref() işlevini kullanacağız ve bizim durumda table_b.sql şu şekilde tanımlanabilir:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1ref() işlevi, table_b modelinin table_a’dan sonra (downstream) geldiğini belirtir. Artık yalnızca tek bir dbt komutuyla tüm hattı çalıştırabiliriz: dbt run --select tag:example.
Yeniden kullanılabilir kod yetenekleri sayesinde dbt, çeşitli veri ortamlarında veri iş akışlarını yönetmek ve optimize etmek için mükemmel bir araç haline getiren özellikler sunar (canlı, geliştirme, test vb.).
Ayrıca temel yeteneklerinden biri, kapsamlı SQL dokümantasyonunu otomatik olarak üretmektur; bu da şeffaflığı önemli ölçüde artırır ve veri geliştiricilerin ve iş paydaşlarının veri modellerini anlamasını kolaylaştırır.
Veri modelleme alanında karşılaşılan zorluklardan biri, kodunuzu yeniden kullanılabilir kılarken birden çok katman içeren karmaşık SQL dönüşüm hatları oluşturmaktır. Bu hatlar, verimli çalıştıklarından emin olmak ve herkesin mantığı anlayabilmesi için kurumsal şeffaflığı korumak adına dikkatli düşünme ve titiz testler gerektirir. dbt bu konuda da yardımcı olabilir.
Ayrıca dbt, veri kalitesi testlerini ve SQL mantığı için birim testlerini destekler; böylece dönüşümlerinizin doğruluğunu ve güvenilirliğini yapılandırılmış ve otomatik bir biçimde (CI/CD iş akışları) doğrulamanızı sağlar.
Bir diğer önemli özellik ise makrolar kullanarak esnek otomasyon sağlamasıdır; makrolar özelleştirilebilir ve yeniden kullanılabilir kod parçacıkları sunarak karmaşık görevleri kolaylaştırır ve üretkenliği artırır.
Bu işlevlerin birleşimi, dbt’yi veri bütünlüğünü sağlamaktan tekrarlayan süreçleri otomatikleştirmeye kadar tüm SQL ile ilgili görevler ve veri ortamları için ideal bir çözüm haline getirir; üstelik verimlilik ve ölçeklenebilirliği koruyarak.
Hadi işe koyulalım ve dbt ile veri platformu olarak BigQuery kullanarak bazı örnekler çalıştıralım!
Bu eğitimde, veri ambarı çözümü olarak Google Cloud BigQuery’yi kullanacağız. Ücretsiz katmanı öğrenme için onu ideal bir aday yapar. BigQuery’yi Google Cloud hesabınızda etkinleştirebilirsiniz.
dbt’yi yerel olarak Python ve pip yöneticisi ile kuracak, bir sanal ortam oluşturacak ve örnek modeller ile testleri çalıştırmaya başlayacağız.
Komut satırınızda aşağıdaki komutları çalıştırın:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtrequirements.txt dosyamız aşağıdaki bağımlılıkları içermelidir:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Daha sonra, eğitimin geri kalanında şunları yapacağız:
dbt uygulamamız için hizmet hesabı kimlik bilgilerini oluşturalım:
Google Cloud’da BigQuery için hizmet hesabı oluşturma. Görsel: Yazar.
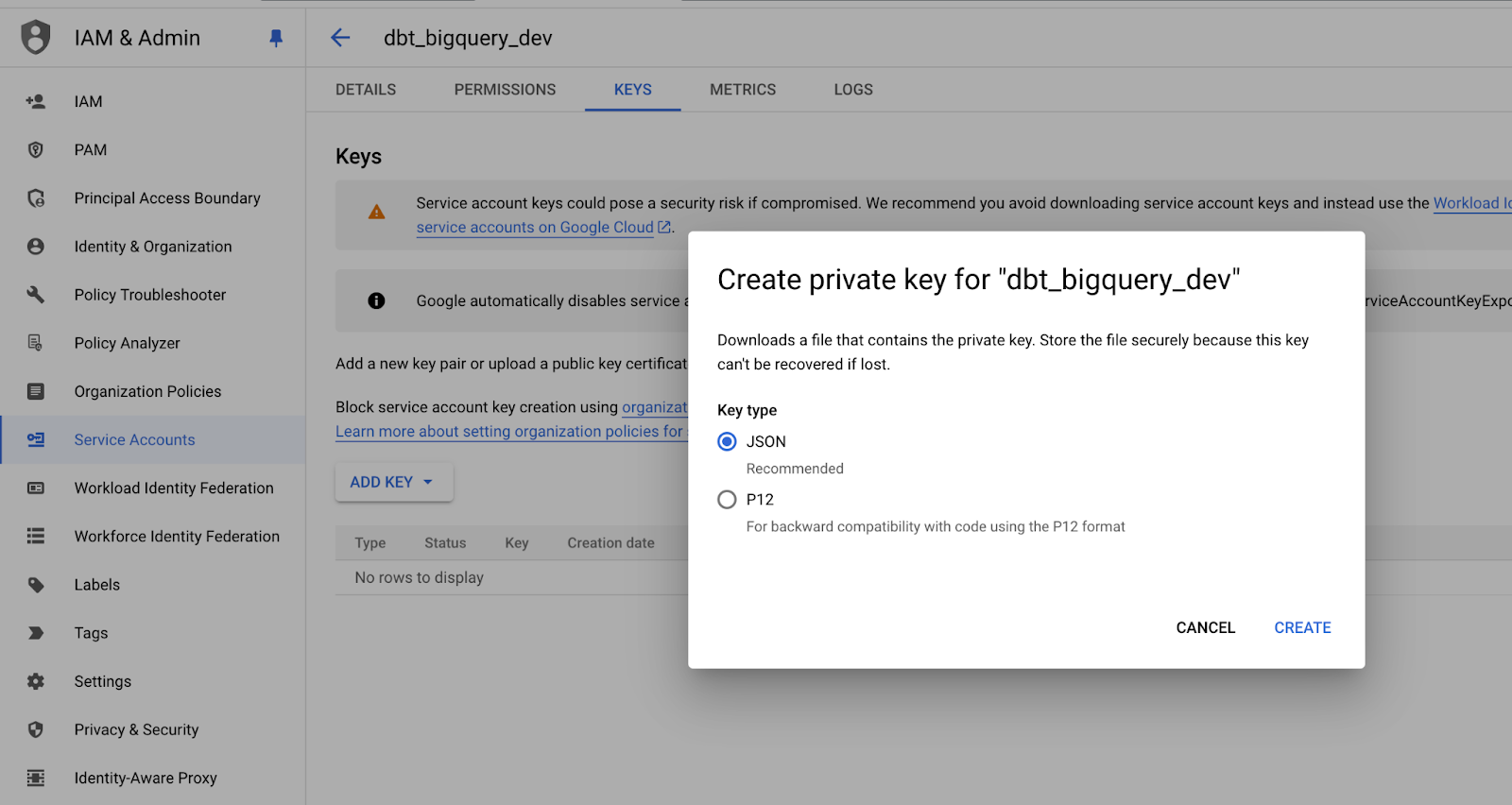
Hizmet hesabı özel anahtarını JSON formatında kaydetme. Görsel: Yazar.
dbt init komutunu bir terminalde çalıştırarak dbt projemizi nihayet başlatalım. Kurulumu tamamladığınızda, buna benzer bir mesaj almalısınız:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.Ve klasör yapısı buna benzer görünmelidir:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtprofiles.yml’in yerel makinemizin kök klasöründe oluşturulduğunu görebiliriz; ancak ideal olarak bunun uygulama klasörümüzde olmasını isteriz, o halde taşıyalım.
cd my_dbt
touch profiles.ymlSon olarak, profiles.yml içeriğini proje adımızı yansıtacak ve Google hizmet hesabı kimlik bilgilerini içerecek şekilde ayarlayalım:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comHepsi bu! Projemizi derlemeye hazırız.
export DBT_PROFILES_DIR='.'
dbt compileÇıktı aşağıdakine benzer olmalıdır:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')İlk proje kurulumumuz tamamlandı.
dbt projemizi, veri ambarı mimarisini net bir şekilde yansıtacak şekilde, pratik ve şeffaf biçimde tasarlamak istiyoruz.
dbt projenizde şablonlar ve makrolar kullanmanızı ve veri ortamlarınızı üretim, geliştirme ve test olarak etkin biçimde ayırmak için özel veritabanı adlarını dahil etmenizi öneririm.
Bu yaklaşım, düzenlemeyi iyileştirir ve yanlış ortamda kazara değişiklik yapılması riskini en aza indirerek genel veri yönetimini ve iş akışı istikrarını artırır. Bunu yaparak bu ortamları kolayca yönetip sürdürebilir, üretim verilerinin deneme veya test değişikliklerinden etkilenmeden güvenli kalmasını sağlayabiliriz.
Farklı ortamlardaki veritabanları ayrıca ilgili sonekler (_prod, _dev, _test) kullanılarak yapılandırılmış ve tutarlı bir şekilde adlandırılabilir; bu da ortamları ayırt etmeyi kolaylaştırırken daha sorunsuz geçiş ve dağıtımları mümkün kılar.

Canlı ortamda farklı veri ambarı katmanları. Görsel: Yazar.
Örneğin, temel veri model katmanlarını veritabanı adlandırma kuralına raw_ ve base_ öneklerini kullanarak taşıyabiliriz:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsBu özel veritabanı adlarını dinamik olarak eklemek için yalnızca bu görevi otomatik olarak yöneten bir dbt makrosu oluşturmanız yeterlidir. Bu yaklaşımdan yararlanarak, her seferinde yapılandırmaları manuel düzenlemeden doğru veri ortamında doğru veritabanı adlarının kullanılmasını sağlayabilirsiniz.
Aşağıdaki kod parçasına bakalım; içinde, bulunduğumuz ortama bağlı olarak farklı şemalar ayarlayan bir makro var:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Artık modellerimizi her derlediğimizde dbt, her modelin kurulumunda belirtilen yapılandırmaya dayalı olarak özel veritabanı adını otomatik olarak uygulayacaktır. Bu, doğru veritabanı adının derleme sırasında enjekte edileceği ve modellerin uygun ortamla — üretim, geliştirme veya test — hizalanmasını sağlayacağı anlamına gelir.
Bu özelliği dahil ederek veritabanı adlarında manuel değişiklik yapma ihtiyacını ortadan kaldırıyor, iş akışımızın verimliliğini ve doğruluğunu daha da artırıyoruz.
Gerekli bu yapılandırmalar, modellerimiz için properties.yml içinde ayarlanabilir:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullGördüğünüz gibi, dbt’nin Jinja desteği sayesinde, yapılandırma dosyalarına mantık eklemek için temel koşullu ifadeleri kullanabiliriz.
Makrolar bu bağlamda kullanılamaz, ancak .yml dosyaları içinde Jinja ifadeleriyle basit koşullular kullanabiliriz. Tırnak işaretleri içine alınmaları gerekir. Bu, şablonlama dilinin yürütme sırasında doğru şekilde yorumlanmasını sağlar.
Bir dbt compile komutu çalıştıralım ve ne olduğuna bakalım:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt, çok güçlü bir özelleştirme özelliği olan değişkenleri destekler. Değişkenler hem SQL şablonlarında hem makrolarda kullanılabilir ve komut satırından şu şekilde iletilebilir:
dbt run -m table_b -t dev --vars '{my_var: my_value}'Değişkenler ana proje dosyası dbt_project.yml içinde tanımlanmalıdır. Örneğin, aşağıdaki parça bunun nasıl yapılacağını gösterir:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""dbt’de değişkenleri kullanarak özel tablo adları (takma adlar) oluşturalım.
Herhangi bir takma ad yoksa, varsayılan olarak modelin orijinal adı (dosya adı) takma ad olarak kullanılır. Bu basit mantık, modellere yapılandırılmış takma adlarıyla veya kurulumuna bağlı olarak varsayılan adlarıyla atıfta bulunulmasını sağlar. Bu işlevselliğin uygulaması aşağıdaki gibidir ve ortamlar arasında modellerin nasıl adlandırılıp referans verildiği konusunda esneklik sunar:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Bu davranışı değişkenler kullanarak geçersiz kılalım. Bu, veri geliştiricilerin hazırlık (geliştirme) ortamında çalışırken birbirlerinin alanına girmesini önlemek için yaygın bir kurulumdur.
Geliştirme mühendisleri tarafından oluşturulan tüm veritabanı örneklerine (tablolar, görünümler vb.) geliştiricinin adını eklemek istiyoruz.
generate_alias_name.sql adında bir makro oluşturalım:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}dbt_project.yml dosyamıza yeni değişkenimizi eklemeyi unutmayın ve komut satırınızda şunu çalıştırın:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Şuna benzer bir çıktı görmelisiniz:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1Değişkenimizin tablo adına eklendiğini görebiliyoruz: table_a_mike.
Bu bölüm, veri dönüşümü açısından veri ambarımızı nasıl tasarladığımızla ilgilidir. dbt’de basitleştirilmiş mantıksal bir proje yapısı aşağıdakine benzeyebilir:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlBen şahsen, temel (base) veri model katmanını olabildiğince sade ve anlaşılır tutmaya, dönüşümlerin yalnızca gerektiğinde uygulanmasına odaklanırım. Bu yaklaşımla, sütun düzeyinde minimum veri manipülasyonu içeren bir base_ veri model katmanı tasarlamayı ve uygulamayı hedefleriz.
Bununla birlikte, özellikle sorgu performansını optimize etmek söz konusu olduğunda, belirli bir düzeyde manipülasyonun faydalı olabileceği durumlar vardır. Bu gibi durumlarda, temel katmanda yapılacak küçük ayarlamalar verimliliği önemli ölçüde artırabilir; dolayısıyla sadelik ile performans kazanımları arasında denge kurmaya değer. Bu durumda ekstra bir join veya bölümleme filtresi eklemek gerekçelendirilebilir.
Veri modellerinizi ve hatlarınızı güçlendirmek için aşağıdaki tekniklerin uygulanması önerilir:
biz_ ve mart_ katmanlarındaki nesneler için kalıcı malzemeleştirme ve kümelendirme kullanın. Bu, performansı iyileştirmeye ve iş mantığının verimli bir şekilde yönetilmesine yardımcı olabilir.select * kalıplarından kaçının ve uzun, karmaşık SQL dosyalarını birim testleriyle daha küçük modellere bölmeyi düşünün.Aşağıdaki SQL sorgusunu göz önünde bulundurun. Bu tür bir özel malzemeleştirmenin nasıl oluşturulacağını açıklar:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Şimdi, bu özelliği göstermek için table_c adında ekstra bir model eklerseniz, aşağıdaki SQL’i kullanabiliriz:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Bunu derlersek, bir SQL betiği gibi görünmelidir:
$ dbt compile -m table_c -t devÇıktı:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Bu yaklaşımın faydası, artık BigQuery bağdaştırıcısına güvenmek zorunda olmamamızdır. Bu işlemi referans alan başka bir tablo veya görünüm oluşturursak, standart ref() işlevini basitçe kullanabiliriz.
Bunu yaparak table_c, veri soy kütüğünde otomatik olarak bir bağımlılık olarak tanınacaktır. Bu, tabloların nasıl ilişkili olduğunu izlemeyi kolaylaştırır ve farklı modeller arasındaki ilişkilerin veri ortamınızda düzgün şekilde belgelendiğinden emin olur.
Bu yöntem, bağımlılıkların yönetilmesine yardımcı olur ve verinin komut dosyalarını içeren karmaşık işleme adımları da dahil olmak üzere çeşitli aşamalarda nasıl aktığına dair net bir görünüm sağlar. Bu, karmaşık veri hatlarını sürdürmek için özellikle kullanışlıdır.
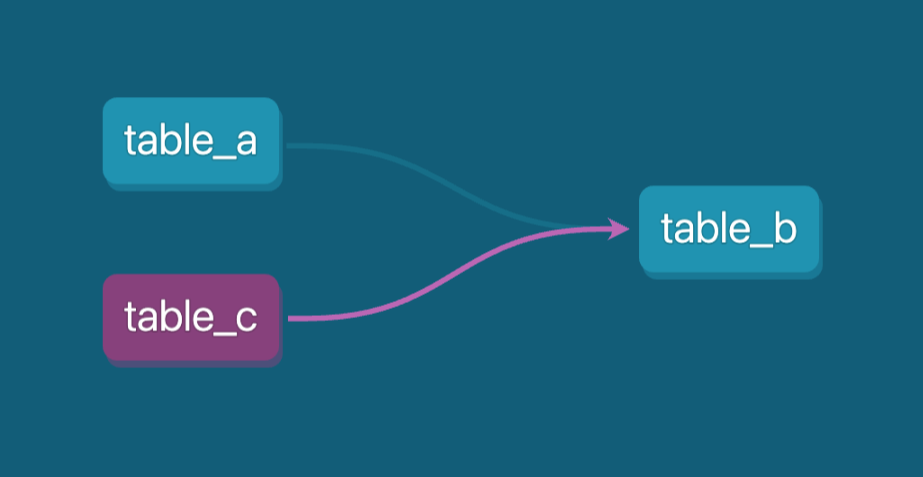
dbt’de DAG (yönlü çevrimsiz grafik), table_b için bağımlılıkları gösterir. Görsel: Yazar
Şimdi, table_c’yi sadece hattımıza eklememiz gerekiyor:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;Komut satırımızda aşağıdakileri çalıştırırsak dokümantasyon otomatik olarak üretilecektir!
dbt docs generate
dbt docs servedbt’de daha gelişmiş bir veri ambarı projesi aşağıdaki yapıya benzeyebilir. Birden çok veri kaynağı ve çeşitli model katmanları (stg, base, mrt, biz) boyunca dönüşümler içerir ve sonunda veri mart modelleri üretir.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlBirim testi, veri modellerimizin arkasındaki mantığı doğrulamak için testleri çalıştırabildiğimiz veri hattı sürecinde kritik bir adımdır. Python işlevleriniz için bekledikleri gibi davrandıklarından emin olmak amacıyla nasıl birim testleri yapıyorsanız, ben de benzer bir yaklaşımı veri modellerini test etmek için uygularım.
Bu testleri çalıştırarak olası sorunları erken yakalayabilir ve dönüşümlerin ile mantığın doğru şekilde çalıştığından emin olabiliriz. Bu uygulama, veri kalitesini korumaya ve hataların hat boyunca yayılmasını önlemeye yardımcı olur; bu da veri mühendisliği sürecinin hayati bir yönüdür.
Bir model için birim testini, properties.yml dosyasını değiştirerek kolayca ekleyebiliriz:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Şimdi komut satırımızda dbt test komutunu çalıştırırsak, birim testleri yürütebiliriz:
% dbt test --select "table_b,test_type:unit"Çıktı şöyledir:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 expect içindeki satır id’yi 3 olarak değiştirin; aynı test için bir hata alacağız:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt, veri kalitesi kontrolleri için de destek sunar. Bunu daha önce veri sözleşmeleri blog yazısında ele almıştım. Veri tazeliği, satır koşulları, ayrıntı düzeyi (granularity) vb. veri kalitesiyle ilgili hemen her şeyi kontrol edebiliriz.
table_b modelimize daha yakından bakalım. Halihazırda bazı veri kontrolleri mevcut:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullBurada, tests tanımı altında, malzemeleştirilmiş table_b.id için unique ve not_null koşullarını test ediyoruz. Bu belirli testi çalıştırmak için şu komut iş görecektir:
dbt test -s table_bVeri kümelerimizi başvuru bütünlüğü açısından da test edebiliriz. Bu, join içeren veri modelleriyle çalışırken, varlıklar arasındaki ilişkilerin doğru bir şekilde korunmasını sağladığından esastır. Bu testler, tablolar veya sütunlar gibi farklı varlıkların birbirleriyle nasıl ilişkili olduğunu tanımlamaya yardımcı olur.
Örneğin, aşağıdaki dbt kodu, her refunds.refund_id’nin geçerli bir transactions.id’ye bağlı olduğunu gösterir. Bu eşleştirme, tüm iadelerin meşru işlemlerle ilişkili olmasını sağlayarak verinizin bütünlüğünü korur ve veri modellerinizde sahipsiz kayıtlar veya tutarsız ilişkileri önler:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idVeri gereksinimleri genellikle yeni verilerin ne zaman kullanılabilir olması gerektiğine dair beklentiler belirlemeyi ve güncellemeler için izin verilen maksimum gecikmeyi tanımlamayı içerir. Bu kontroller, verinin analiz için geçerli kalmasını (güncel olmasını) sağlamak açısından kritik önemdedir.
dbt’de bu, tazelik testlerinden yararlanılarak uygulanabilir; bu testler, yeni verinin beklenen zaman aralığında gelip gelmediğini izlemenizi sağlar.
Örneğin, bir tablodaki en son kaydın tanımladığınız tazelik kriterlerini karşıladığını doğrulamak için bir tazelik testi yapılandırabilirsiniz. Bu, veri hatlarınızın güncellemeleri zamanında ve tutarlı bir şekilde sunmasını sağlayarak verinizin güvenilirliğini ve doğruluğunu sürdürmeye yardımcı olur ve zaman duyarlı gereksinimlere uyumu sağlar.
Aşağıdaki kod parçasını düşünün. dbt’de bir tazelik testinin nasıl kurulacağını açıklar:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1Tüm bu dbt testleri dikkat çekici ve veri mühendislerinin günlük işlerinde son derece kullanışlıdır! Veri ambarının iyi bakımlı ve veri hatlarının tutarlı kalmasına yardımcı olurlar.
Bir veri ambarı çözümü inşa etmek, dikkatli planlama ve organizasyon gerektiren karmaşık bir görevdir. dbt, bir şablonlama motoru olarak bunu tutarlı bir şekilde yapmaya yardımcı olur.
Bu yazıda, netliği ve işbirliğini artırmak için dbt veri dönüşüm klasörlerini düzenlemeye yönelik birkaç tekniği özetledim. SQL dosyalarını mantıksal bir yapıda saklayarak, projeye yeni olanlar için bile keşfetmesi kolay bir ortam oluştururuz.
DBT, süreci daha da düzene koymak için çok çeşitli özellikler sunar. Örneğin, makrolar, değişkenler ve sabitler aracılığıyla yeniden kullanılabilir kod parçaları dahil ederek SQL şablonlarımızı zenginleştirebiliriz. Deneyimlerime göre, altyapı-kod olarak uygulamalarıyla birlikte kullanıldığında bu işlevsellik, uygun CI/CD iş akışlarını uygulamaya yardımcı olur ve geliştirme ile dağıtımı önemli ölçüde hızlandırır.
dbt bilginizi bir üst seviyeye taşımak istiyorsanız, DataCamp’teki Introduction to dbt kursunu düşünün. Daha fazla uygulamalı pratikle başarılı bir başlangıç yapmanızı kesinlikle sağlayabilecek mükemmel bir kaynaktır!
Bu kurslarla dbt ve veri mühendisliği hakkında daha fazlasını öğrenin!
Program
Program
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
