
Programma
Ingegnere dei dati associato in SQL
30 h
In questo articolo, illustro alcune tecniche che possono aiutarti a imparare dbt e a semplificare la configurazione del progetto e il data modeling, rendendo l’intero processo più gestibile.
Inoltre, entrerò nello specifico dei design pattern dei progetti dbt su cui faccio affidamento nel mio lavoro quotidiano. Questi metodi si sono rivelati preziosi per costruire data platform e data warehouse accurati, intuitivi, facili da esplorare e orientati all’utente.
Applicando questi approcci è più facile creare piattaforme dati che rispettano standard qualitativi elevati riducendo al minimo i potenziali problemi, portando in definitiva a progetti data-driven più efficaci.
dbt (Data Build Tool) è una potente soluzione open source pensata specificamente per il data modeling, che sfrutta template SQL e funzioni ref() (referencing) per stabilire relazioni tra diverse istanze del database come tabelle, viste, schemi e altro. La sua flessibilità è ideale per chi segue il principio DRY (Don’t Repeat Yourself).
Con dbt puoi creare un unico template SQL riutilizzabile e facilmente adattabile a diversi ambienti dati. Una volta scritto il template, può essere "compilato" per generare le query SQL necessarie all’esecuzione in ciascun ambiente specifico.
L’approccio di dbt migliora l’efficienza e assicura coerenza tra le diverse fasi della pipeline dei dati, riducendo ridondanze e potenziali errori e semplificando la manutenzione e la scalabilità dell’infrastruttura dati.
Il data modeling gioca un ruolo centrale nella data engineering, e dbt è uno strumento eccellente. Anzi, sostenerei che padroneggiare dbt è assolutamente essenziale per chiunque aspiri a diventare un professionista dei dati di successo!
Considera il template dbt qui sotto. È una semplice definizione di tabella, ma contiene metadati che indicano all’utente quale database e schema usare:
/*
models/example/table_a.sql
Welcome to your first dbt model!
Did you know that you can also configure models directly within SQL files?
This will override configurations stated in dbt_project.yml
Try changing "table" to "view" below
*/
{{ config(
materialized='table',
alias='table_a',
schema='events',
tags=["example"]
) }}
select
1 as id
, 'Some comments' as comments
union all
2 as id
, 'Some comments' as comments Immaginiamo che a valle, nella pipeline dati, ci sia una vista che deriva dalla tabella (table_a.sql) creata sopra. La lineage della nostra pipeline avrebbe quindi questo aspetto:

Esempio di lineage di una data pipeline. Immagine dell’autore.
Useremo la funzione ref() per collegare due stadi della nostra pipeline e, nel nostro caso, table_b.sql può essere definita così:
-- models/example/table_b.sql
-- Use the ref function to select from other models
{{ config(
materialized='view',
tags=["example"],
schema='events'
) }}
select *
from {{ ref('table_a') }}
where id = 1La funzione ref() indica che il modello table_b viene dopo table_a (downstream). Ora possiamo eseguire l’intera pipeline usando un solo comando dbt: dbt run --select tag:example.
Grazie alle capacità di riuso del codice, dbt offre funzionalità che lo rendono uno strumento eccellente per gestire e ottimizzare i workflow dei dati in vari ambienti (produzione, sviluppo, test, ecc.).
Inoltre, una delle sue funzionalità principali è la generazione automatica di documentazione SQL completa, che migliora notevolmente la trasparenza e rende più facile comprendere i modelli dati per sviluppatori e stakeholder di business.
Una delle sfide del data modeling è costruire pipeline di trasformazione SQL complesse che coinvolgono più layer mantenendo il codice riutilizzabile. Queste pipeline richiedono una progettazione attenta e test meticolosi per garantire efficienza e trasparenza organizzativa, così che tutti possano comprenderne la logica. Anche in questo dbt può aiutare.
Inoltre, dbt supporta test di qualità dei dati e unit test per la logica SQL, permettendoti di validare precisione e affidabilità delle trasformazioni in modo strutturato e automatizzato (workflow CI/CD).
Un’altra funzionalità chiave è la flessibile automazione tramite macro, che consentono snippet di codice personalizzabili e riutilizzabili, semplificando compiti complessi e aumentando la produttività.
Queste funzionalità combinate rendono dbt una soluzione ideale per gestire qualsiasi attività legata a SQL e agli ambienti dati, dall’assicurare l’integrità dei dati all’automazione di processi ripetitivi, mantenendo efficienza e scalabilità.
Passiamo alla pratica ed eseguiamo alcuni esempi con dbt e BigQuery come data platform!
Per questo tutorial useremo Google Cloud BigQuery come data warehouse. Il suo livello gratuito lo rende perfetto per imparare. Puoi attivare BigQuery nel tuo account Google Cloud.
Installeremo dbt in locale usando Python e il gestore pip, creeremo un ambiente virtuale e inizieremo a eseguire modelli e test di esempio.
Esegui i seguenti comandi nella tua riga di comando:
pip install virtualenv
mkdir dbt
cd dbt
virtualenv dbt_env -p python3.9
source dbt_env/bin/activate
pip install -r requirements.txtIl nostro requirements.txt dovrebbe contenere le seguenti dipendenze:
dbt-core==1.8.6
dbt-bigquery==1.8.2
dbt-extractor==0.5.1
dbt-semantic-interfaces==0.5.1Poi, per il resto del tutorial, faremo quanto segue:
Creiamo le credenziali del service account per la nostra applicazione dbt:
Creazione di un service account per BigQuery in Google Cloud. Immagine dell’autore.
Salvataggio della chiave privata del service account in formato JSON. Immagine dell’autore.
dbt init in un terminale per inizializzare il nostro progetto dbt. Una volta completata la configurazione, dovresti vedere un messaggio come questo:
19:18:45 Profile my_dbt written to /Users/mike/.dbt/profiles.yml using target's profile_template.yml and your supplied values. Run 'dbt debug' to validate the connection.E la struttura delle cartelle dovrebbe essere simile a questa:
.
├── my_dbt
│ ├── README.md
│ ├── analyses
│ ├── dbt_project.yml
│ ├── macros
│ ├── models
│ ├── polybox-data-dev.json
│ ├── seeds
│ ├── snapshots
│ └── tests
├── dbt_env
│ ├── bin
│ ├── lib
│ └── pyvenv.cfg
├── logs
│ └── dbt.log
├── readme.md
└── requirements.txtPossiamo vedere che profiles.yml è stato creato nella cartella root della nostra macchina locale, ma idealmente vorremmo averlo nella cartella dell’applicazione, quindi spostiamolo.
cd my_dbt
touch profiles.ymlInfine, adeguiamo il contenuto di profiles.yml per riflettere il nome del nostro progetto e includere le credenziali del service account Google:
my_dbt:
target: dev
outputs:
dev:
type: bigquery
method: service-account-json
project: dbt_bigquery_dev # replace with your-bigquery-project-name
dataset: source
threads: 4 # Must be a value of 1 or greater
# [OPTIONAL_CONFIG](#optional-configurations): VALUE
# These fields come from the service account json keyfile
keyfile_json:
type: service_account
project_id: your-bigquery-project-name-data-dev
private_key_id: bd709bd92708a38ae33abbff0
private_key: "-----BEGIN PRIVATE KEY-----\nMIIEv...
...
...
...q8hw==\n-----END PRIVATE KEY-----\n"
client_email: some@your-bigquery-project-name-data-dev.iam.gserviceaccount.com
client_id: 1234
auth_uri: https://accounts.google.com/o/oauth2/auth
token_uri: https://oauth2.googleapis.com/token
auth_provider_x509_cert_url: https://www.googleapis.com/oauth2/v1/certs
client_x509_cert_url: https://www.googleapis.com/robot/v1/metadata/x509/educative%40bq-shakhomirov.iam.gserviceaccount.comÈ tutto! Siamo pronti a compilare il nostro progetto.
export DBT_PROFILES_DIR='.'
dbt compileL’output dovrebbe essere simile a questo:
(dbt_env) mike@MacBook-Pro my_dbt % dbt compile
19:47:32 Running with dbt=1.8.6
19:47:33 Registered adapter: bigquery=1.8.2
19:47:33 Unable to do partial parsing because saved manifest not found. Starting full parse.
19:47:34 Found 2 models, 4 data tests, 479 macros
19:47:34
19:47:35 Concurrency: 4 threads (target='dev')L’impostazione iniziale del progetto è completata.
Vogliamo progettare il nostro progetto dbt in modo comodo e trasparente, così da riflettere chiaramente l’architettura del data warehouse.
Ti consiglio di usare template e macro nel tuo progetto dbt e di integrare nomi di database personalizzati per separare efficacemente gli ambienti dati in produzione, sviluppo e test.
Questo approccio migliora l’organizzazione e riduce il rischio di modifiche accidentali nell’ambiente sbagliato, aumentando la stabilità complessiva del workflow. In questo modo possiamo gestire e mantenere facilmente tali ambienti, contribuendo a garantire che i dati di produzione rimangano sicuri e non toccati da modifiche sperimentali o di test.
I database nei diversi ambienti possono anche essere nominati in modo strutturato e coerente usando suffissi pertinenti (_prod, _dev, _test), così da distinguere più facilmente gli ambienti e abilitare transizioni e deploy più fluidi.

I diversi layer di data warehouse in un ambiente di produzione. Immagine dell’autore.
Per esempio, possiamo spostare i principali layer del data model nella convenzione di naming del database usando i prefissi raw_ e base_ nella denominazione dei database:
Schema/Dataset Tanle
RAW_DEV SERVER_DB_1 -- mocked data
RAW_DEV SERVER_DB_2 -- mocked data
RAW_DEV EVENTS -- mocked data
RAW_PROD SERVER_DB_1 -- real production data from pipelines
RAW_PROD SERVER_DB_2 -- real production data from pipelines
RAW_PROD EVENTS -- real production data from pipelines
...
BASE_PROD EVENTS -- enriched data
BASE_DEV EVENTS -- enriched data
...
ANALYTICS_PROD REPORTING -- materialized queries and aggregates
ANALYTICS_DEV REPORTING
ANALYTICS_PROD AD_HOC -- ad-hoc queries and viewsPer iniettare dinamicamente questi nomi di database personalizzati, basta creare una macro dbt che gestisca automaticamente questo compito. Sfruttando questo approccio, puoi assicurarti che vengano usati i nomi di database corretti nell’ambiente dati appropriato senza modificare manualmente le configurazioni ogni volta.
Vediamo lo snippet di codice qui sotto, che contiene una macro per impostare schemi diversi a seconda dell’ambiente in cui ci troviamo:
-- cd my_dbt
-- ./macros/generate_schema_name.sql
{% macro generate_schema_name(custom_schema_name, node) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is none -%}
{{ default_schema }}
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- endmacro %}Ora, ogni volta che compiliamo i nostri modelli, dbt applicherà automaticamente il nome del database personalizzato in base alla configurazione specificata nell’impostazione di ciascun modello. Significa che il nome corretto verrà iniettato durante il processo di compilazione, garantendo l’allineamento dei modelli con l’ambiente appropriato — produzione, sviluppo o test.
Integrando questa funzionalità, eliminiamo la necessità di modifiche manuali ai nomi dei database, migliorando ulteriormente efficienza e accuratezza del nostro workflow.
Queste configurazioni richieste possono essere impostate in properties.yml per i nostri modelli:
# my_dbt/models/example/properties.yml
version: 2
models:
- name: table_a
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} raw_dev
{%- elif target.name == "prod" -%} raw_prod
{%- elif target.name == "test" -%} raw_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_null
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullCome vedi, possiamo usare semplici istruzioni condizionali per introdurre logica nei file di configurazione, grazie al supporto di Jinja in dbt.
Le macro non possono essere usate in questo contesto, ma possiamo usare condizioni semplici con espressioni Jinja all’interno dei file .yml. Devono essere racchiuse tra virgolette. Questo garantisce che il linguaggio di templating sia interpretato correttamente in fase di esecuzione.
Eseguiamo un comando dbt compile e vediamo cosa succede:
(dbt_env) mike@Mikes-MacBook-Pro my_dbt % dbt compile -s table_b -t prod
18:43:43 Running with dbt=1.8.6
18:43:44 Registered adapter: bigquery=1.8.2
18:43:44 Unable to do partial parsing because config vars, config profile, or config target have changed
18:43:45 Found 2 models, 480 macros
18:43:45
18:43:46 Concurrency: 4 threads (target='prod')
18:43:46
18:43:46 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from dbt_bigquery_dev.raw_prod.table_a
where id = 1dbt supporta le variabili, una funzionalità di personalizzazione molto potente. Le variabili possono essere usate sia nei template SQL sia nelle macro e possono essere fornite da riga di comando così:
dbt run -m table_b -t dev --vars '{my_var: my_value}'Le variabili devono essere dichiarate nel file principale del progetto dbt_project.yml. Ad esempio, lo snippet qui sotto mostra come fare:
name: 'my_dbt'
version: '1.0.0'
config-version: 2
...
...
...
# In this example config, we tell dbt to build all models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the {{ config(...) }} macro.
models:
polybox_dbt:
# Config indicated by + and applies to all files under models/example/
example:
# +materialized: view
# schema: |
# {%- if target.name == "dev" -%} analytics_dev_mike
# {%- elif target.name == "prod" -%} analytics_prod
# {%- elif target.name == "test" -%} analytics_test
# {%- else -%} invalid_database
# {%- endif -%}
vars:
my_var: ""Usiamo le variabili per creare nomi di tabella personalizzati (alias) in dbt.
Se non è presente alcun alias, il nome originale del modello (nome del file) viene usato come alias per impostazione predefinita. Questa logica semplice assicura che i modelli vengano referenziati dal loro alias configurato o dal loro nome di default, a seconda dell’impostazione. L’implementazione di questa funzionalità è simile alla seguente e garantisce flessibilità nel modo in cui i modelli vengono nominati e referenziati tra ambienti:
-- get_custom_alias.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{%- if custom_alias_name -%}
{{ custom_alias_name | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}
{%- endif -%}
{%- endmacro %}Sovrascriviamo questo comportamento usando le variabili. È un’impostazione comune per gli sviluppatori dati per ridurre il rischio di pestarsi i piedi a vicenda mentre si lavora in staging (sviluppo).
Vogliamo aggiungere il nome dello sviluppatore a tutte le istanze del database (tabelle, viste, ecc.) create dagli ingegneri in sviluppo.
Creiamo una macro generate_alias_name.sql:
--my_dbt/macros/generate_alias_name.sql
{% macro generate_alias_name(custom_alias_name=none, node=none) -%}
{% set apply_alias_suffix = var('apply_alias_suffix') %}
{%- if custom_alias_name -%}
{{ custom_alias_name }}{{ apply_alias_suffix | trim }}
{%- elif node.version -%}
{{ return(node.name ~ "_v" ~ (node.version | replace(".", "_"))) }}
{%- else -%}
{{ node.name }}{{ apply_alias_suffix | trim }}
{%- endif -%}
{%- endmacro %}Non dimenticare di aggiungere la nostra nuova variabile a dbt_project.yml ed eseguire questo comando nella riga di comando:
$ dbt compile -m table_b -t dev --vars '{apply_alias_suffix: _mike}'Dovresti vedere un output come questo:
08:58:06 Running with dbt=1.8.6
08:58:07 Registered adapter: bigquery=1.8.2
08:58:07 Unable to do partial parsing because config vars, config profile, or config target have changed
08:58:07 Unable to do partial parsing because a project config has changed
08:58:08 Found 2 models, 481 macros
08:58:08
08:58:08 Concurrency: 4 threads (target='dev')
08:58:08
08:58:08 Compiled node 'table_b' is:
-- Use the ref function to select from other models
select *
from bigquery-data-dev.raw_dev.table_a_mike
where id = 1Possiamo vedere che la nostra variabile è stata aggiunta al nome della tabella: table_a_mike.
Questa sezione riguarda il modo in cui progettiamo il data warehouse in termini di trasformazione dei dati. Una struttura logica semplificata del progetto in dbt può essere la seguente:
.
└── models
└── some_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml -- raw data table declarations
└── base -- base transformations, e.g. JSON to cols
| ├── base_transactions.sql
| └── base_orders.sql
└── analytics -- deeply enriched data prod grade data, QA'ed
├── _analytics__models.yml
├── some_model.sql
└── some_other_model.sqlPersonalmente, cerco sempre di mantenere il layer dati fondativo (base) il più pulito e lineare possibile, assicurando che le trasformazioni vengano applicate solo quando necessario. Con questo approccio, puntiamo a progettare e implementare un layer dati base_ che comporti un intervento minimo a livello di colonne.
Tuttavia, ci sono casi in cui un certo livello di manipolazione può essere utile, in particolare per ottimizzare le prestazioni delle query. In tali situazioni, piccoli aggiustamenti al layer base possono migliorare sensibilmente l’efficienza, rendendo opportuno bilanciare semplicità e benefici prestazionali. In questo caso, aggiungere una join extra o un filtro di partizionamento sarebbe giustificato.
Una pratica consigliata è implementare le seguenti tecniche per migliorare i modelli e le pipeline di dati:
biz_ e mart_. Questo può migliorare le prestazioni e assicurare una gestione efficiente della logica di business.select * e valuta di suddividere file SQL lunghi e complessi in modelli più piccoli con unit test.Considera la query SQL qui sotto. Spiega come creare una simile materializzazione personalizzata:
-- my_dbt/macros/operation.sql
{%- materialization operation, default -%}
{%- set identifier = model['alias'] -%}
{%- set target_relation = api.Relation.create(
identifier=identifier, schema=schema, database=database,
type='table') -%}
-- ... setup database ...
-- ... run pre-hooks...
-- build model
{% call statement('main') -%}
{{ run_sql_as_simple_script(target_relation, sql) }}
{%- endcall %}
-- ... run post-hooks ...
-- ... clean up the database...
-- COMMIT happens here
{{ adapter.commit() }}
-- Return the relations created in this materialization
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization -%}
-- my_dbt/macros/operation_helper.sql
{%- macro run_sql_as_simple_script(relation, sql) -%}
{{ log("Creating table " ~ relation) }}
{{ sql }}
{%- endmacro -%}Ora, se aggiungiamo un modello extra chiamato table_c per dimostrare questa funzionalità, possiamo usare il seguente SQL:
-- my_dbt/models/example/table_c.sql
{{ config(
materialized='operation',
tags=["example"]
) }}
create or replace table {{this.database}}.{{this.schema}}.{{this.name}} (
id int64
,comments string
);
insert into {{this.database}}.{{this.schema}}.{{this.name}} (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Ora, se lo compiliamo, dovrebbe apparire come uno script SQL:
$ dbt compile -m table_c -t devL’output:
10:45:24 Running with dbt=1.8.6
10:45:25 Registered adapter: bigquery=1.8.2
10:45:25 Found 3 models, 483 macros
10:45:25
10:45:26 Concurrency: 4 threads (target='dev')
10:45:26
10:45:26 Compiled node 'table_c' is:
-- Use the ref function to select from other models
create or replace table bigquery-data-dev.source.table_c (
id int64
,comments string
);
insert into bigquery-data-dev.source.table_c (id, comments)
select
1 as id
, 'Some comments' as comments
union all
select
2 as id
, 'Some comments' as comments
;Il vantaggio di questo approccio è che non dobbiamo più dipendere dall’adapter BigQuery. Se creiamo un’altra tabella o vista che fa riferimento a questa operazione, possiamo semplicemente usare la funzione standard ref().
Facendo così, table_c verrà automaticamente riconosciuta come dipendenza nel lineage dei dati. Questo rende facile tracciare come le tabelle sono correlate e assicura che le relazioni tra i diversi modelli siano documentate correttamente nel tuo ambiente dati.
Questo metodo aiuta a gestire le dipendenze e fornisce una vista chiara del flusso dei dati tra i vari stadi, inclusi passaggi complessi che coinvolgono script. È particolarmente utile per mantenere pipeline dati complesse.
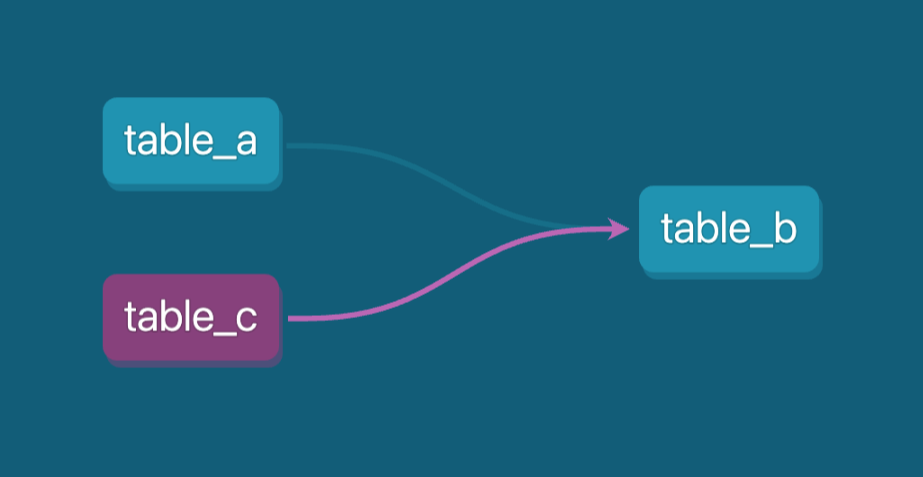
Il DAG (grafo aciclico diretto) in dbt mostra le dipendenze per table_b. Immagine dell’autore
Ora dobbiamo solo aggiungere table_c alla nostra pipeline:
-- models/example/table_b.sql
{{ config(
tags=["example"]
) }}
select *
from {{ ref('table_a') }}
where id = 1
union all
select *
from {{ ref('table_c') }}
where id = 2
-- select 1;La documentazione verrà generata automaticamente se eseguiamo quanto segue nella riga di comando!
dbt docs generate
dbt docs serveUn esempio più avanzato di progetto di data warehousing in dbt può avere la struttura seguente. Contiene più sorgenti dati e trasformazioni attraverso vari layer di modelli (stg, base, mrt, biz) per arrivare a produrre i data mart.
└── models
├── int -- only if required and 100% necessary for reusable logic
│ └── finance
│ ├── _int_finance__models.yml
│ └── int_payments_pivoted_to_orders.sql
├── marts -- deeply enriched, QAed data with complex transformations
│ ├── finance
│ │ ├── _finance__models.yml
│ │ ├── orders.sql
│ │ └── payments.sql
│ └── marketing
│ ├── _marketing__models.yml
│ └── customers.sql
└── src (or staging) -- raw data with basic transformations applied
├── some_data_source
│ ├── _data_source_model__docs.md
│ ├── _data_source__models.yml
│ ├── _sources.yml
│ └── base
│ ├── base_transactions.sql
│ └── base_orders.sql
└── another_data_source
├── _data_source_model__docs.md
├── _data_source__models.yml
├── _sources.yml
└── base
├── base_marketing.sql
└── base_events.sqlIl unit testing è un passaggio cruciale nel processo della pipeline dati, in cui possiamo eseguire test per validare la logica dei nostri modelli. Così come faresti unit test per le funzioni Python per assicurarne il comportamento atteso, applico un approccio simile ai test dei modelli dati.
Eseguendo questi test, possiamo intercettare potenziali problemi in anticipo e garantire che trasformazioni e logica funzionino correttamente. Questa pratica aiuta a mantenere la qualità dei dati e a prevenire che gli errori si propaghino nella pipeline, rendendola un aspetto fondamentale del lavoro di data engineering.
Possiamo aggiungere un unit test a un modello semplicemente modificando il file properties.yml:
# my_dbt/models/example/properties.yml
version: 2
models:
...
unit_tests: # dbt test --select "table_b,test_type:unit"
- name: test_table_b
description: "Check my table_b logic captures all records from table_a and table_c."
model: table_b
given:
- input: ref('table_a')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
- input: ref('table_c')
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}
expect:
rows:
- {id: 1, comments: 'Some comments'}
- {id: 2, comments: 'Some comments'}Ora, eseguendo il comando dbt test nella riga di comando, possiamo lanciare gli unit test:
% dbt test --select "table_b,test_type:unit"Questo è l’output:
11:33:05 Running with dbt=1.8.6
11:33:06 Registered adapter: bigquery=1.8.2
11:33:06 Unable to do partial parsing because config vars, config profile, or config target have changed
11:33:07 Found 3 models, 483 macros, 1 unit test
11:33:07
11:33:07 Concurrency: 4 threads (target='dev')
11:33:07
11:33:07 1 of 1 START unit_test table_b::test_table_b ................................... [RUN]
11:33:12 1 of 1 PASS table_b::test_table_b .............................................. [PASS in 5.12s]
11:33:12
11:33:12 Finished running 1 unit test in 0 hours 0 minutes and 5.77 seconds (5.77s).
11:33:12
11:33:12 Completed successfully
11:33:12 Prova a cambiare la riga id in expect a 3 e otterremo un errore per lo stesso test:
11:33:28 Completed with 1 error and 0 warnings:
11:33:28
11:33:28 Failure in unit_test test_table_b (models/example/properties.yml)
11:33:28
actual differs from expected:
@@ ,id,comments
,1 ,Some comments
+++,2 ,Some comments
---,3 ,Some commentsdbt offre anche il supporto ai controlli di qualità dei dati. Ne ho parlato in precedenza nel post sul data contracts. Possiamo verificare quasi tutto ciò che è rilevante per la qualità dei dati, ad esempio freschezza, condizioni sulle righe, granularità, ecc.
Diamo un’occhiata più da vicino al nostro modello table_b. Ha già alcuni controlli sui dati:
- name: table_b
config:
description: "A starter dbt model"
schema: |
{%- if target.name == "dev" -%} analytics_dev
{%- elif target.name == "prod" -%} analytics_prod
{%- elif target.name == "test" -%} analytics_test
{%- else -%} invalid_database
{%- endif -%}
columns:
- name: id
description: "The primary key for this table"
tests:
- unique
- not_nullQui, nella definizione tests, testiamo la colonna table_b.id materializzata per le condizioni unique e not_null. Per eseguire questo test specifico, funziona il seguente comando:
dbt test -s table_bPossiamo anche testare i nostri dataset per l’integrità referenziale. Questo è essenziale quando si lavora con modelli che prevedono join, perché assicura che le relazioni tra entità siano mantenute correttamente. Questi test aiutano a definire come diverse entità, come tabelle o colonne, si relazionano tra loro.
Per esempio, considera il codice dbt qui sotto, che illustra come ogni refunds.refund_id sia collegato a un transactions.id valido. Questo mapping assicura che tutti i rimborsi siano associati a transazioni legittime, mantenendo l’integrità dei dati ed evitando record orfani o relazioni incoerenti nei tuoi modelli:
- name: refunds
enabled: true
description: An incremental table
columns:
- name: refund_id
tests:
- relationships:
tags: ['relationship']
to: ref('transactions')
field: idI requisiti sui dati spesso prevedono la definizione di aspettative su quando i nuovi dati dovrebbero essere disponibili e la specifica del ritardo massimo consentito per gli aggiornamenti. Questi controlli sono fondamentali per garantire che i dati restino rilevanti per l’analisi (aggiornati).
In dbt, ciò può essere implementato utilizzando test di freschezza, che ti consentono di monitorare se i nuovi dati arrivano entro il periodo atteso.
Ad esempio, puoi configurare un test di freschezza per verificare che il record più recente in una tabella soddisfi i criteri di freschezza definiti. Questo assicura che le pipeline forniscano aggiornamenti tempestivi e costanti, aiutando a mantenere affidabilità e accuratezza dei dati nel rispetto dei requisiti sensibili al tempo.
Considera lo snippet di codice qui sotto. Spiega come impostare un test di freschezza in dbt:
# example model
- name: orders
enabled: true
description: A source table declaration
tests:
- dbt_utils.recency: # https://github.com/dbt-labs/dbt-utils#recency-source
tags: ['freshness']
datepart: day
field: timestamp
interval: 1Tutti questi test dbt sono notevoli e molto utili nel lavoro quotidiano dei data engineer! Aiutano a mantenere il data warehouse in buone condizioni e le pipeline coerenti.
Costruire una soluzione di data warehouse è un compito complesso che richiede pianificazione e organizzazione accurate. dbt, come motore di templating, aiuta a farlo in modo coerente.
In questo articolo ho illustrato diverse tecniche per organizzare le cartelle di trasformazione dati di dbt per migliorarne chiarezza e collaborazione. Archiviando i file SQL in una struttura logica, creiamo un ambiente facile da esplorare anche per chi è nuovo al progetto.
DBT offre un’ampia gamma di funzionalità per semplificare ulteriormente il processo. Per esempio, possiamo arricchire i template SQL incorporando parti di codice riutilizzabili tramite macro, variabili e costanti. Per esperienza, abbinata a pratiche di infrastructure as code, questa funzionalità aiuta a imporre corretti workflow CI/CD, accelerando sensibilmente sviluppo e deploy.
Se vuoi portare le tue conoscenze di dbt al livello successivo, valuta di seguire il corso Introduction to dbt su DataCamp. È una risorsa eccellente che può sicuramente aiutarti a iniziare con ancora più pratica!
Scopri di più su dbt e data engineering con questi corsi!
Programma
Programma
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

