
Programa
Fundamentos da IA
10 h
O DeepSeek-R1-Lite-Preview é uma ferramenta de IA, semelhante ao ChatGPTcriada pela empresa chinesa DeepSeek. A empresa anunciou esse novo modelo no X em 20 de novembro (link do tuíte) e compartilhou alguns detalhes em uma página de documentação.
O DeepSeek-R1-Lite-Preview foi projetado para ser muito bom para resolver problemas complexos de raciocínio em matemática, programação e lógica. Ele mostra como pensa, passo a passo, para que você possa entender como ele chega às respostas, o que ajuda as pessoas a confiarem mais nele.
Você pode experimentá-lo gratuitamente no site deles, chat.deepseek.commas você está limitado a 50 mensagens por dia em seu modo avançado chamado "Deep Think". A DeepSeek também planeja compartilhar partes dessa ferramenta com o público para que outros possam usá-la ou desenvolver a partir dela.
Você pode começar a usar o DeepSeek-R1-Lite-Preview seguindo estas duas etapas:
Para ver o que o DeepSeek-R1-Lite-Preview pode fazer, vamos testá-lo! Vou apresentar uma série de desafios que mostram suas habilidades de raciocínio, começando com a simples, mas famosa, pergunta do strawberry (morango): Quantas vezes a letra "r" aparece na palavra 'strawberry'?"
Essa pergunta pode parecer simples, mas os LLMs (mesmo o GPT-4o) tradicionalmente têm dificuldade em respondê-la corretamente. Eles geralmente respondem que só há duas ocorrências da letra"r".
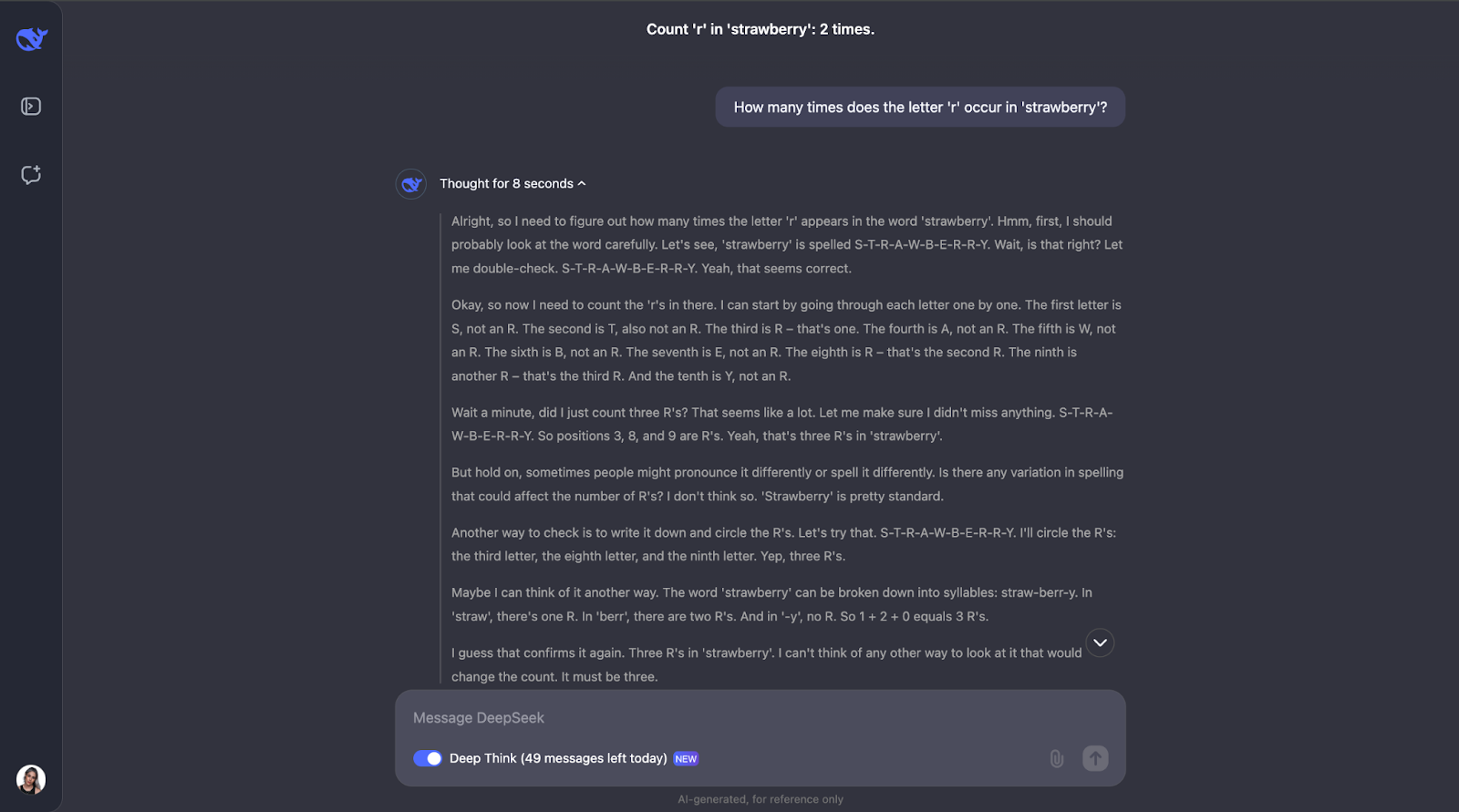
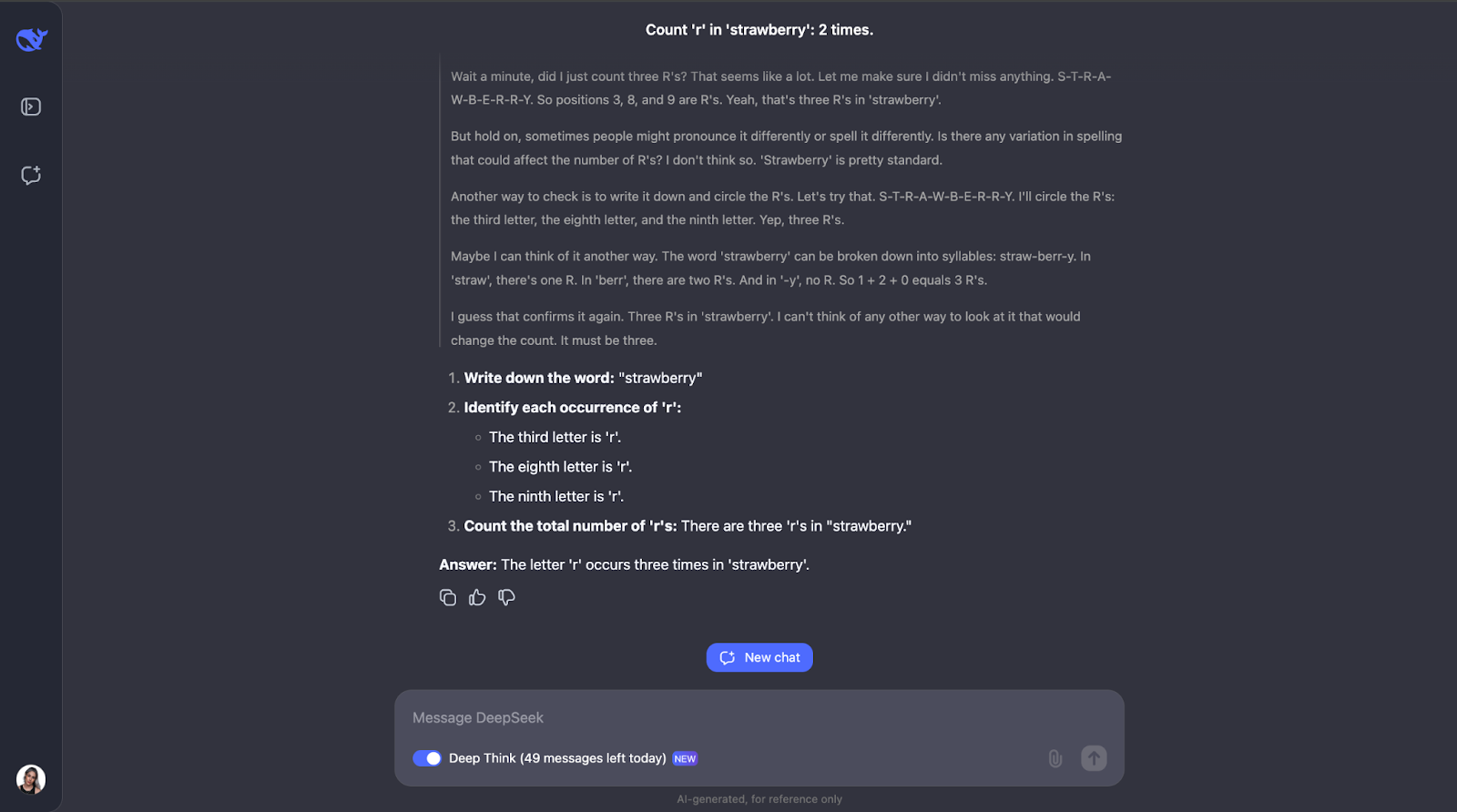
Uau, ok, eu não esperava um processo de raciocínio tão longo para o que parece ser uma tarefa simples. Achei que, depois de contar a letra "r" e identificar sua posição na palavra, ele teria parado por aí. Mas o que achei interessante foi que ele não parou por aí. Ele verificou a contagem algumas vezes e até considerou coisas como a forma como as pessoas poderiam pronunciar ou soletrar a palavra de forma diferente, o que acho um pouco redundante, especialmente a parte da pronúncia. Mas isso mostra o quanto ele é cuidadoso e atencioso! Ele também explicou cada etapa para que eu pudesse acompanhar o raciocínio e ver como ele chegou à resposta.
Vou testar o DeepSeek-R1-Lite-Preview em três problemas de matemática.
Já que o DeepSeek alega ser muito bom em raciocínio matemático, vamos começar com um problema geométrico simples.
"Se um triângulo tem lados de comprimento 3, 4 e 5, qual é sua área?"
Esse problema requer conhecimento do teorema de Pitágoras e da fórmula de Heron. Eu esperaria que o DeepSeek-R1-Lite-Preview mostrasse seu trabalho, talvez dessa forma:
Vamos ver o que acontece!
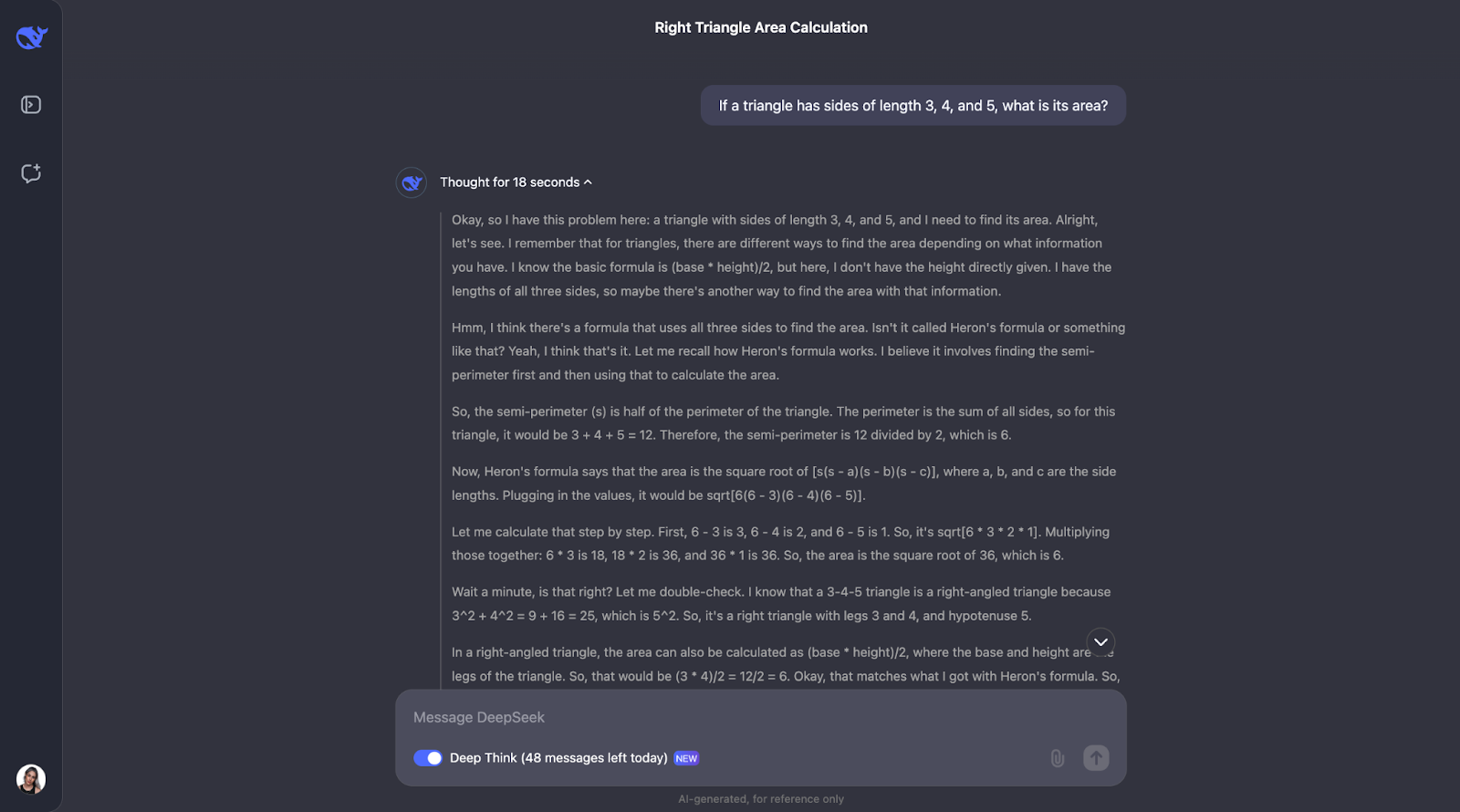
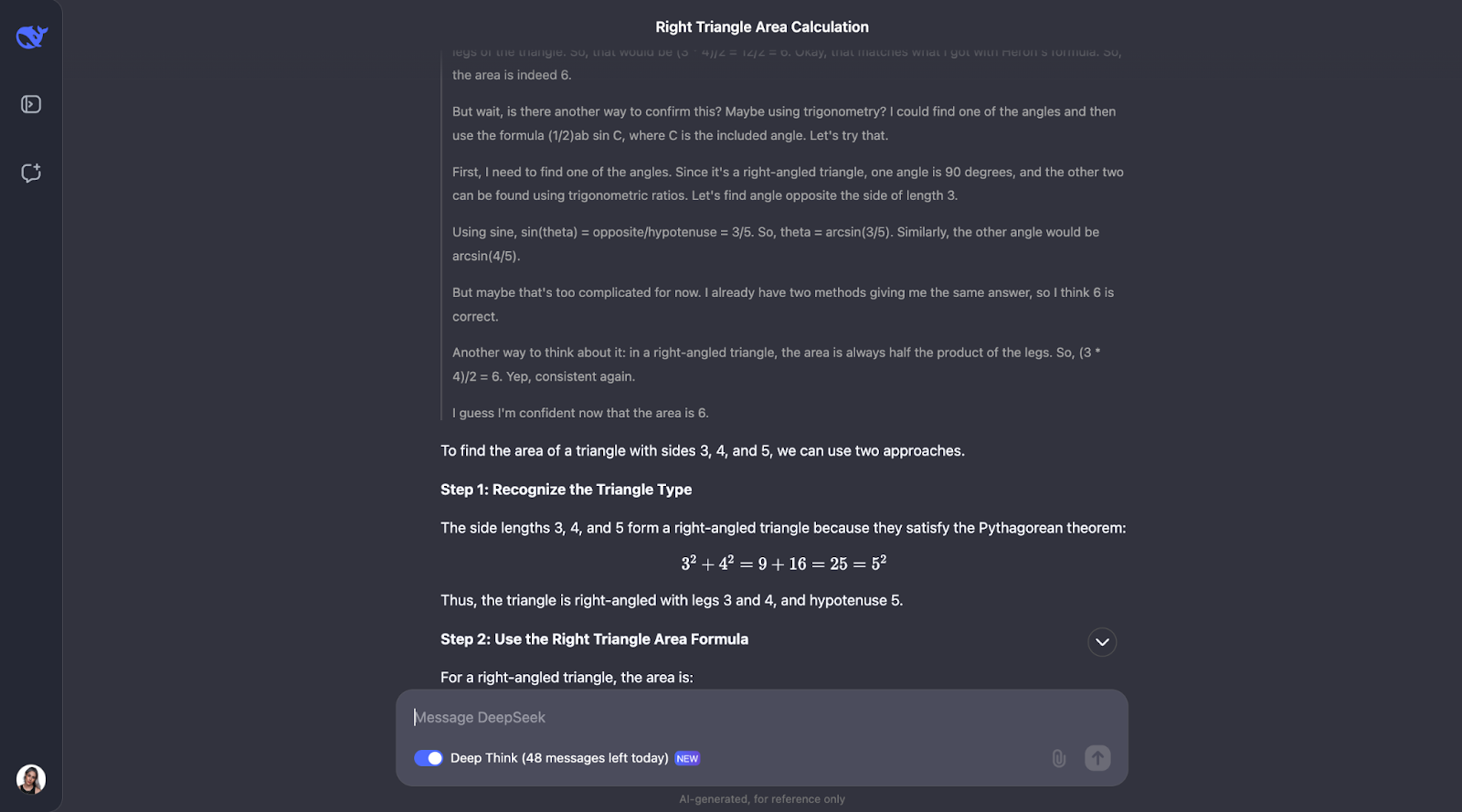
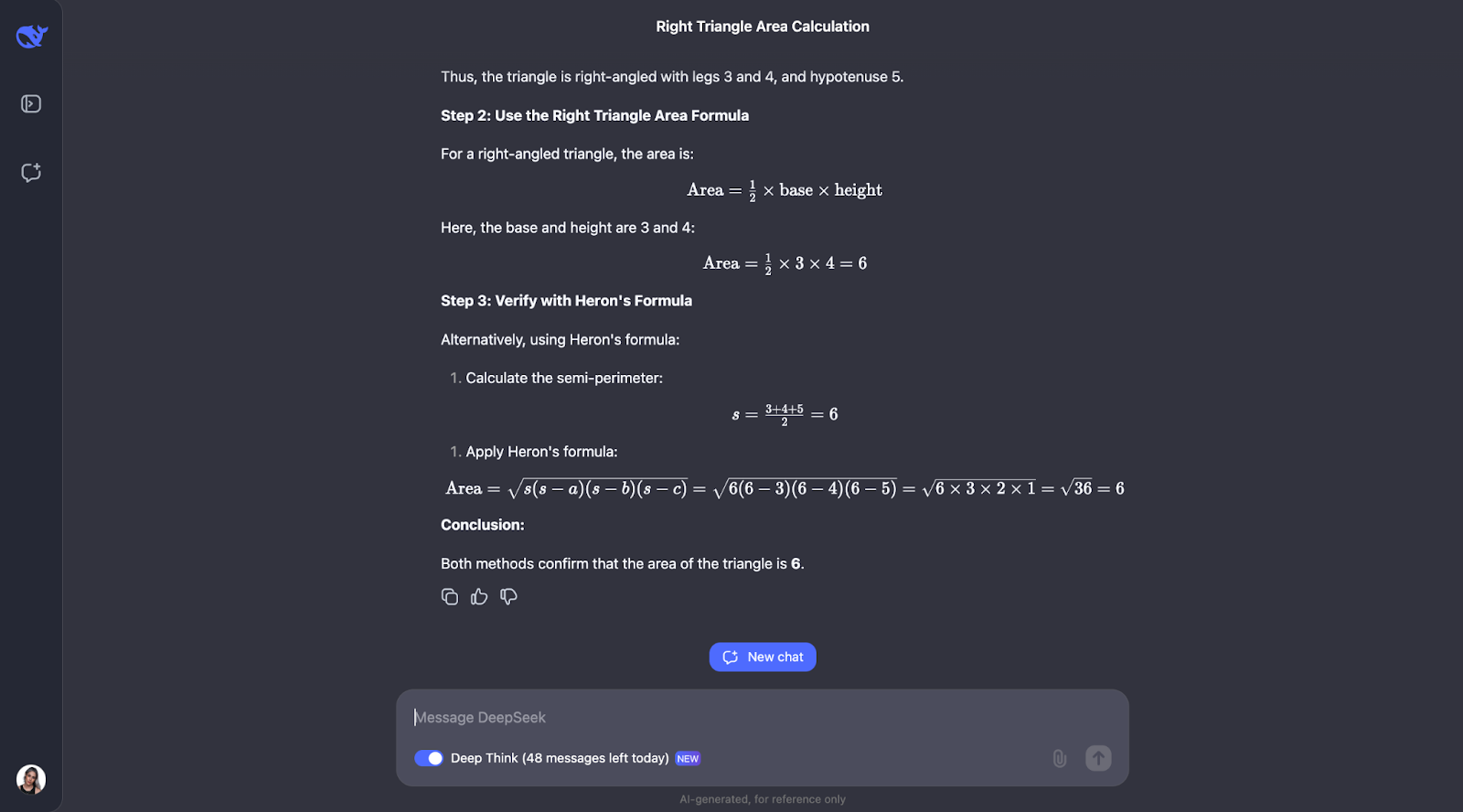
Ok, então, curiosamente, ele executa as verificações que eu previ, embora em uma ordem diferente. Ele também considerou usar a trigonometria calculando ângulos e tentando outra fórmula. Acho muito interessante que, no final, ele tenha decidido que isso não era necessário, pois os dois primeiros métodos já haviam confirmado a resposta.
Tanto a explicação quanto o resultado foram particularmente claros e fáceis de acompanhar, o que me faz pensar que esse seria um modelo fantástico para ser incorporado ao assistente de um aluno de matemática, por exemplo. Nesse caso de uso específico, talvez o processo de raciocínio pudesse ser mostrado primeiro, e o aluno poderia interagir com ele, reconhecendo se entendeu ou não, antes de prosseguir para a resposta final.
Vamos passar para um teste de matemática mais complexo para ver se há alguma diferença no desempenho e no processo de pensamento.
"Prove que a soma dos inversos dos números de Fibonacci converge para um valor finito."
Esse teste desafia a compreensão do modelo sobre conceitos matemáticos avançados, como a convergência de séries e as propriedades dos números de Fibonacci. Vamos experimentar! Para facilitar a leitura, publicarei apenas a primeira e a última parte da resposta (mas fique à vontade para tentar você mesmo com o mesmo prompt):
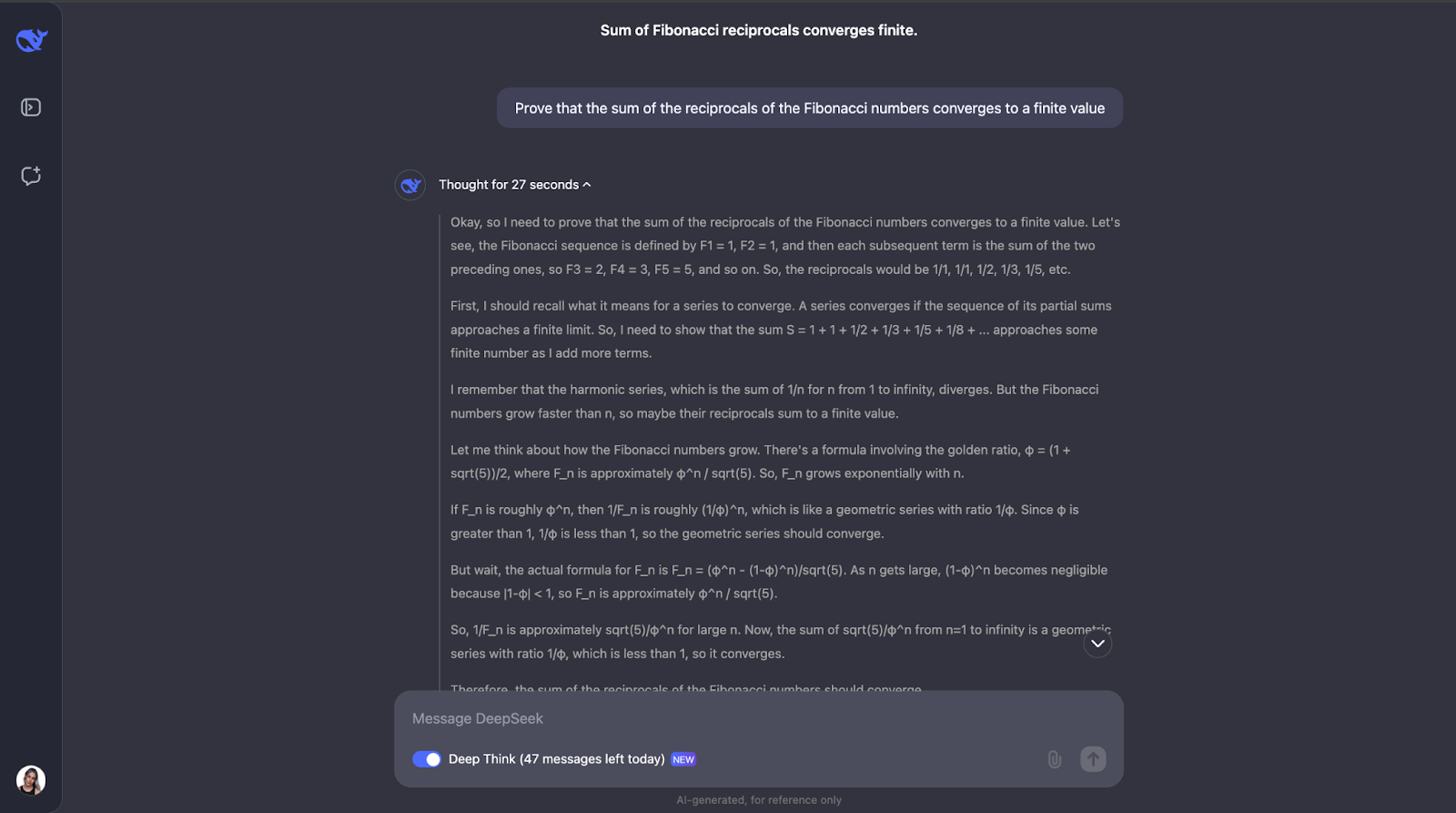

Ok, essa é uma ótima linha de raciocínio. Gostei muito de como ele primeiro se certifica de que entende os conceitos-chave, como inversos e convergência. Em seguida, o DeepSeek-R1-Lite-Preview abordou esse problema observando como os números de Fibonacci aumentam e usando um teste de comparação, que é uma forma comum de testar se uma série converge ou não.
Ele comparou números inversos de Fibonacci a uma série geométrica. Como os inversos dos números de Fibonacci diminuem ainda mais rápido do que os termos de uma progressão geométrica cuja razão é menor que 1, o modelo concluiu que a soma dos inversos também converge para um valor finito. Para ter ainda mais certeza, ele usou algo chamado teste de proporção.
Esse teste verifica se o limite da proporção de termos consecutivos é menor que 1. Se for, a série converge. O modelo calculou essa razão para os inversos dos números de Fibonacci e descobriu que ela é de fato menor que 1.
Ele até mencionou que há um valor conhecido para essa soma, chamado de constante recíproca de Fibonacci, que é aproximadamente 3,3598. Mas, para esse problema, só precisávamos saber que a soma é finita, e não exatamente o que ela é; portanto, essa foi uma informação adicional que também achei interessante. Gosto muito de como a solução é apresentada no resultado. Ela é clara e passo a passo.
Até o momento, estou impressionada com as tarefas matemáticas.
Vou tentar um problema de geometria diferencial, só porque meu doutorado é nessa área, então não pude resistir a fazer um pequeno teste. Nada muito complexo, apenas um exercício clássico que você pode encontrar na graduação em matemática.
"Considere uma superfície S em R³ parametrizada por
φ(u,v) = (u cos v, u sin v, ln u)
para u > 0 e 0 ≤ v < 2π.
a) Calcule a primeira forma fundamental de S.
b) Determine se S é uma superfície mínima.
c) Encontre a curvatura gaussiana K e a curvatura média H de S."
O que eu esperava que o DeepSeek-R1-Lite-Preview fizesse era fornecer uma solução passo a passo, mostrando todos os cálculos e explicando o significado de cada resultado, bem como as definições dos principais conceitos, como forma fundamental, superfície mínima e as diferentes curvaturas.
Para manter a legibilidade deste artigo, só poderei mostrar a primeira e a última parte da resposta, mas encorajo você a experimentar esse prompt por conta própria:
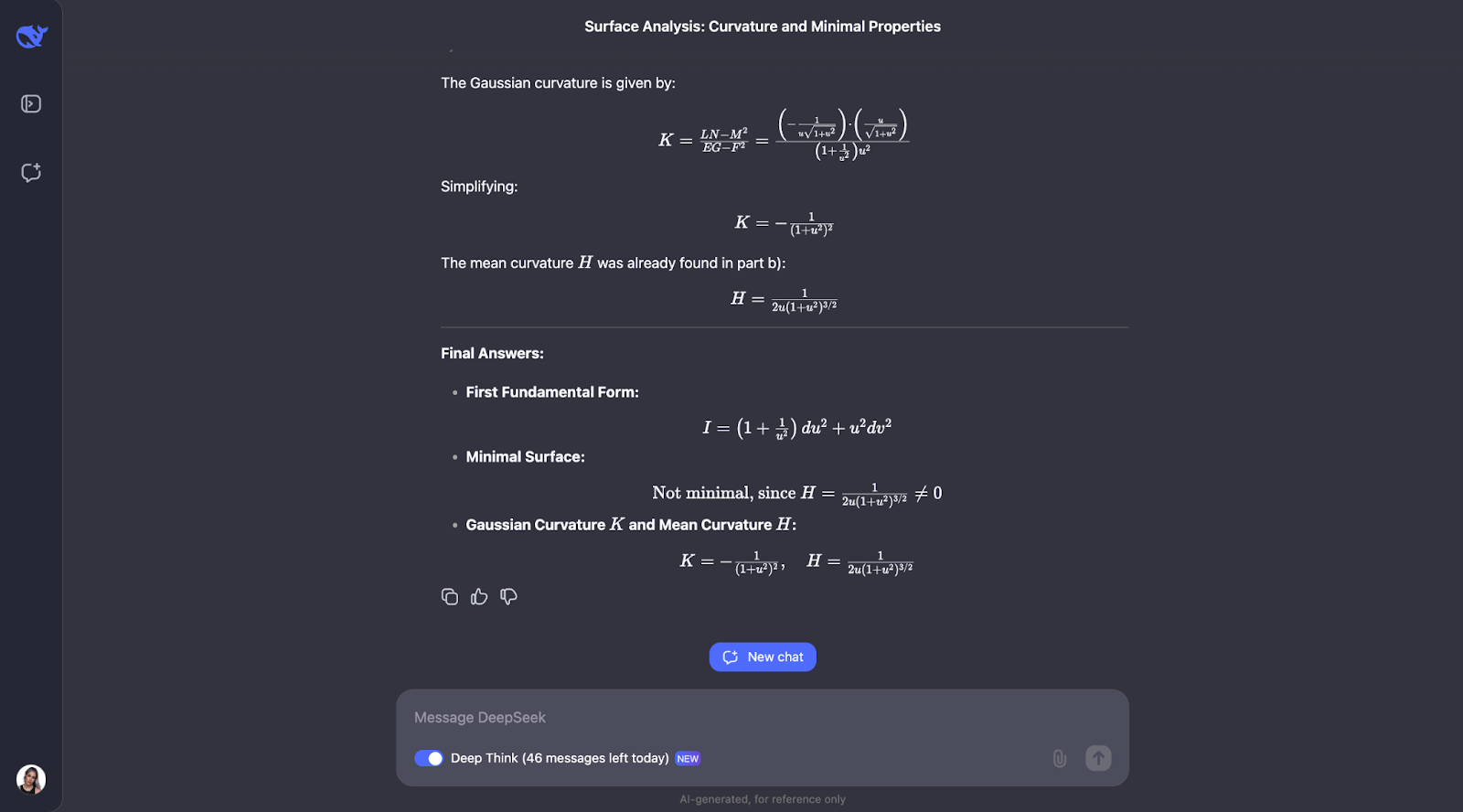
A abordagem passo a passo usa fórmulas geométricas bem conhecidas e as aplica diretamente, o que torna o raciocínio fácil de acompanhar. No entanto, eu esperava que ele verificasse a própria compreensão dos principais conceitos do problema, o que não faz parte da linha de raciocínio. Na parte B, ele adota uma abordagem alternativa e identifica que a superfície envolvida é uma superfície de revolução, o que é um detalhe interessante.
Há também um momento em que ele comenta sobre a rotação e percebe que já tem N, o vetor normal, o que poderia entrar em conflito com a notação do coeficiente da segunda forma fundamental. Eu gostaria de ver uma sugestão de uma notação melhor, pois usar a mesma letra para duas coisas não é uma boa prática!
Quando ele calcula a curvatura média, percebe que ela não é zero e questiona se o cálculo está correto. Para garantir a precisão, ele tenta outro método para verificar novamente seu trabalho.
Mais uma vez, o resultado é muito claro e fácil de acompanhar. Em todos esses exemplos, é impressionante ver como ele verifica consistentemente os cálculos usando diferentes métodos. O processo de pensamento é sempre detalhado, lógico e fácil de entender!
Vamos passar agora para os testes de programação.
A primeira coisa que vou testar é:
"Implemente uma função em Python que encontre a substring palindrômica mais longa em uma determinada string. A função deve ter uma complexidade de tempo melhor que O(n^3).”
Estou tentando avaliar a capacidade do modelo de criar algoritmos eficientes e implementá-los no código. Eu esperaria uma solução usando programação dinâmica ou o algoritmo de Manacher, com uma explicação clara da abordagem e análise da complexidade de tempo.
O resultado é muito longo, e estou mostrando apenas a primeira e a última partes:
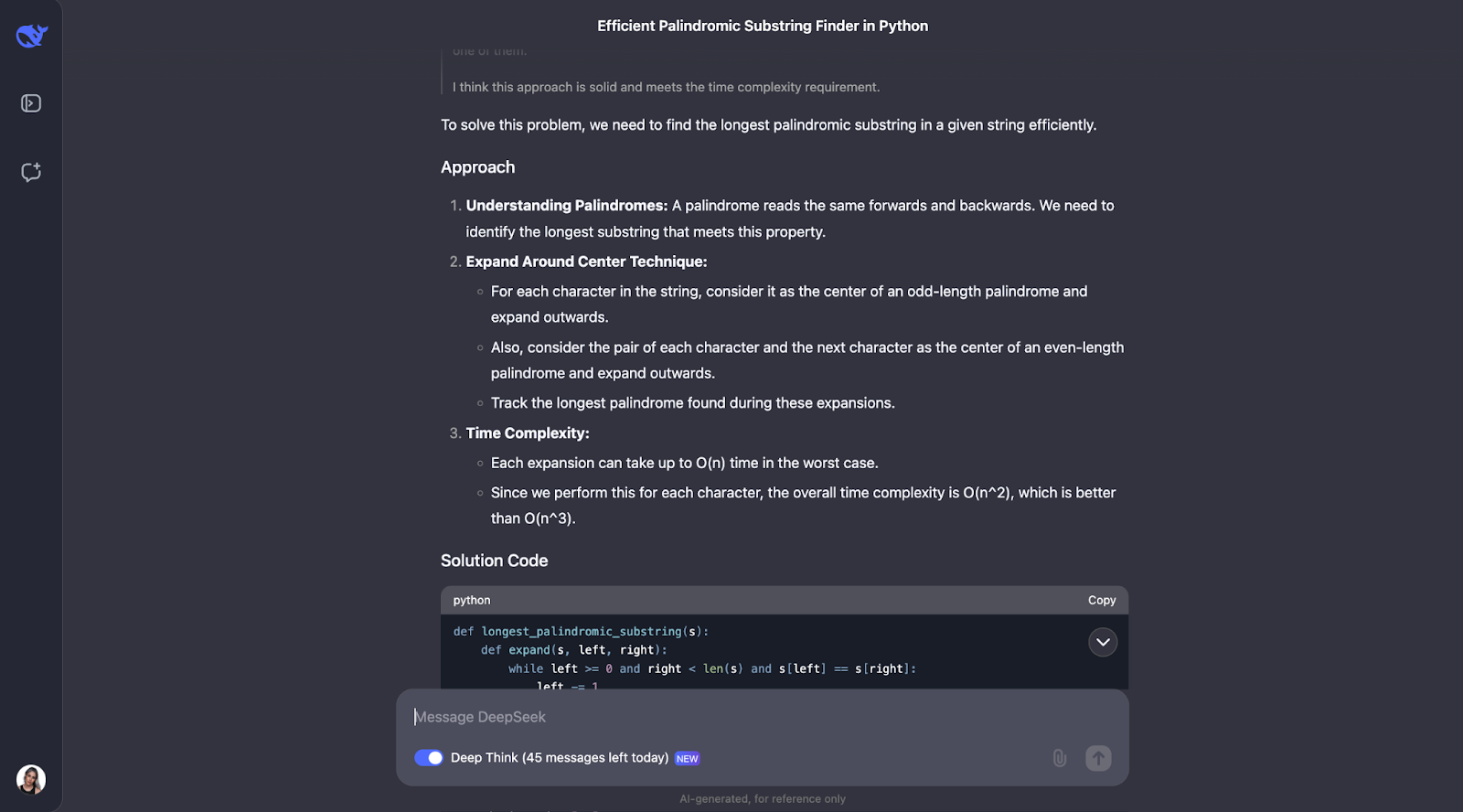
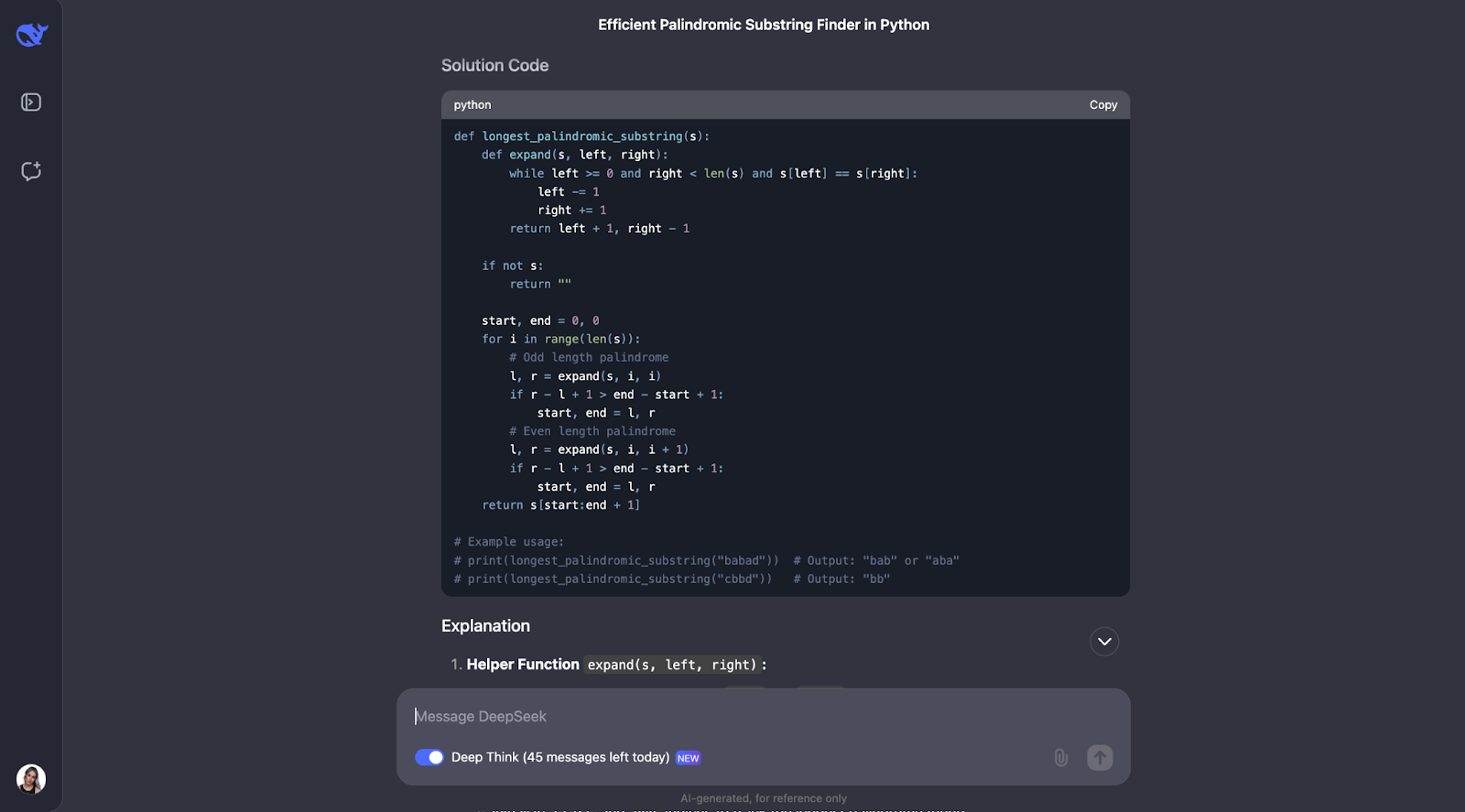
Acho que o modelo fez um ótimo trabalho ao resolver o problema de encontrar a substring palindrômica mais longa. Sua abordagem foi inteligente, eficiente e explicada com clareza.
Em vez de aplicar força bruta em cada substring possível, o que seria lento, ele usou uma técnica inteligente de "expansão a partir dos centros". Esse método lidou com palíndromos de comprimento ímpar, como "aba", e de comprimento par, como "abba". Ele registrava o palíndromo mais longo que encontrava à medida que avançava. O resultado foi um algoritmo que é executado em tempo O(n^2), muito mais rápido do que uma solução O(n^3).
O que mais me impressiona nessa resposta é a clareza com que ela foi apresentada. O DeepSeek dividiu o problema em etapas compreensíveis, explicou seu processo de pensamento em detalhes e até incluiu exemplos práticos. Por exemplo, ele mostrou como o algoritmo se expande a partir do centro de "racecar" ou "abba" para encontrar o palíndromo correto. A função auxiliar para expandir a partir de um centro foi particularmente boa na minha opinião; ela tornou o código modular e fácil de acompanhar.
Dito isso, eu esperava que ele considerasse o algoritmo de Manacher, que é uma solução O(n) mais rápida. Definitivamente, a implementação é mais complexa, mas é útil para casos em que o desempenho é crítico, e eu esperava que o modelo tivesse apontado isso.
Também notei que o resultado não discutiu explicitamente como o algoritmo lida com casos especiais, como uma cadeia vazia ou uma cadeia com todos os caracteres idênticos (por exemplo, "aaaa"). Esses casos funcionariam, mas eu esperava que ele pelo menos discutisse o assunto.
Por fim, achei legal que ele comentou sobre o resultado esperado para os exemplos de uso. No entanto, quando executei o código, apenas a primeira opção do primeiro exemplo de uso foi impressa. Teria sido ótimo se o código considerasse todas as soluções possíveis e que todas elas fossem impressas.
Vamos tentar um problema diferente em outra linguagem de programação.
"Escreva uma função em JavaScript que determine se um determinado número é primo"
Para facilitar a leitura, estou mostrando apenas a primeira e a última parte (embora a cadeia de pensamento tenha sido um pouco mais curta dessa vez):
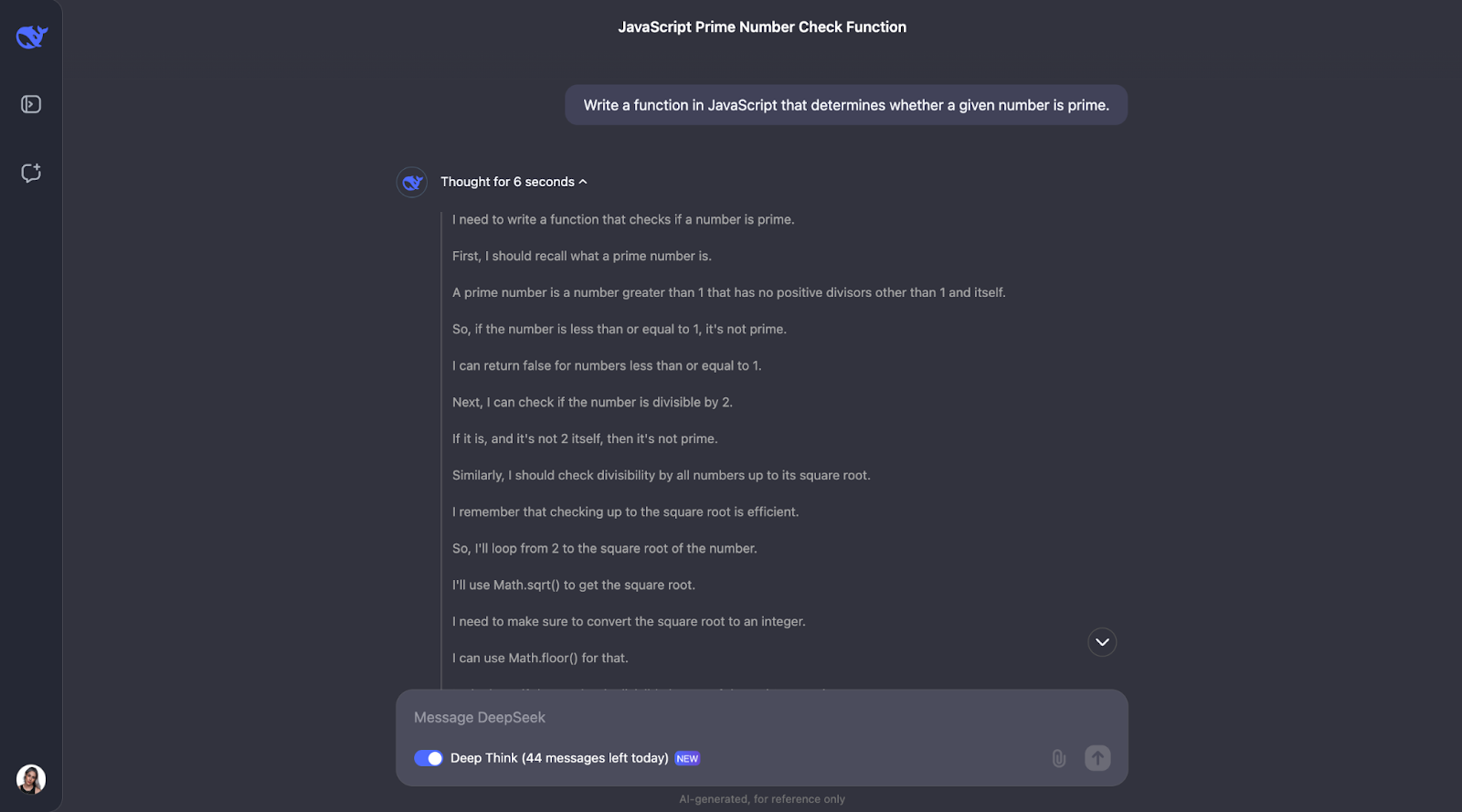
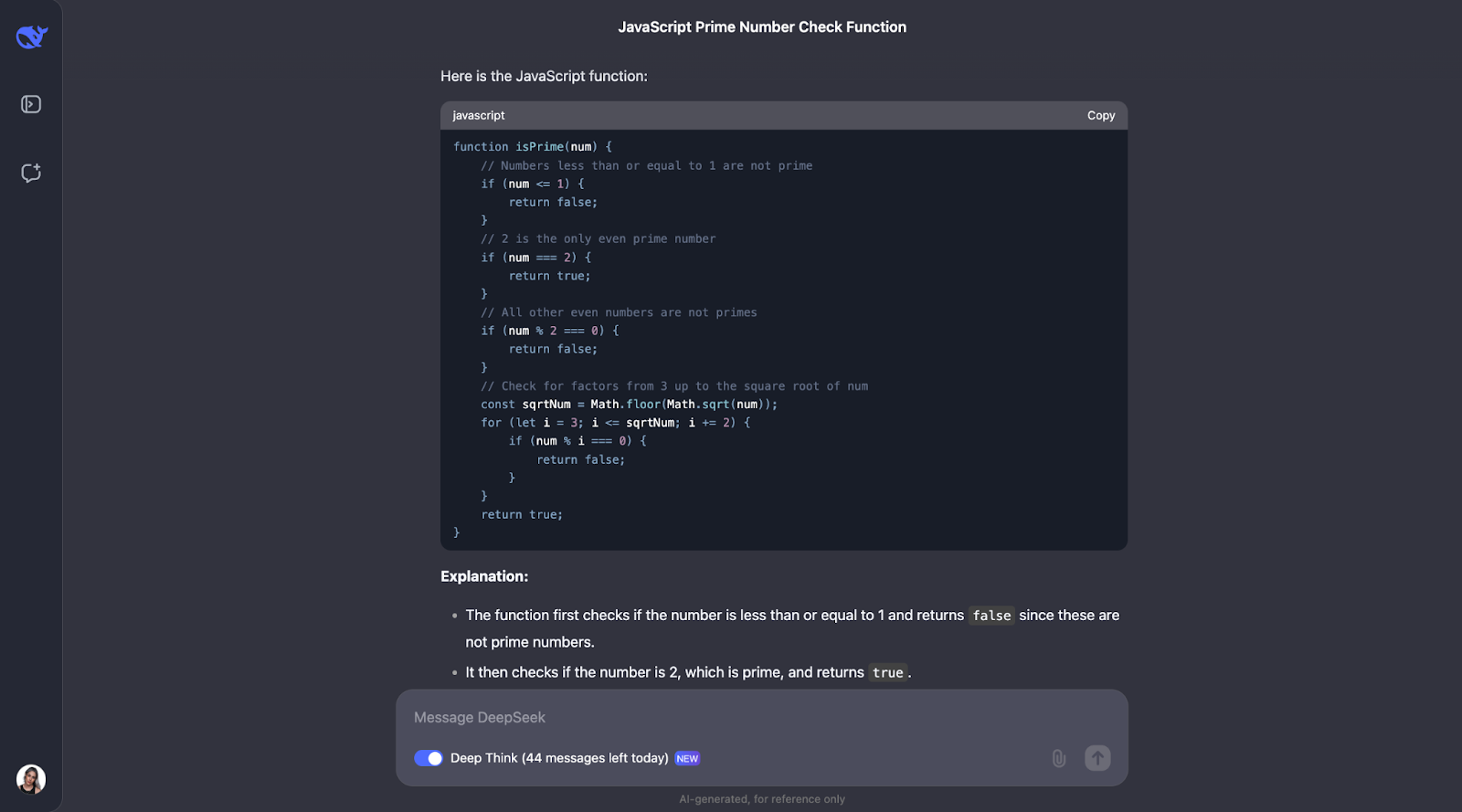
Acho que podemos ver um padrão aqui para o processo de pensamento. Na maioria das vezes, ele começa definindo os principais conceitos que aparecem no problema. Assim nesse problema, por exemplo, ele define o que é um número primo.
Depois disso, o processo de pensamento faz sentido e chega a etapas otimizadas. Primeiro, ele aborda o básico: números menores ou iguais a 1 não são primos, e 2 é o único número primo par. A partir daí, ele verifica se o número é divisível por qualquer número ímpar até a raiz quadrada do número. Isso economiza tempo porque evita cálculos desnecessários. Além disso, em vez de testar cada número, ele pula todos os números pares depois de 2, tornando o processo ainda mais rápido. A função usa Math.sqrt para encontrar a raiz quadrada, o que limita a extensão da verificação, mantendo-a eficiente e simples.
Novamente, ele também testou com pequenos exemplos, como no problema anterior, como números primos e não primos conhecidos, para garantir que funcione conforme o esperado.
No entanto, há espaço para melhorias. Por exemplo, a função não verifica se a entrada é realmente um número, portanto, ele poderia lidar melhor com os erros. Ele também poderia incluir atalhos para números como os que terminam em 0 ou 5, que obviamente não são primos (exceto o próprio 5). Adicionar um pouco mais de explicação sobre por que ele ignora os números pares ou verifica somente até a raiz quadrada também ajudaria os iniciantes a entender melhor, eu acho.
Por fim, eu esperava que o código tivesse alguns exemplos de testes de uso, da mesma forma que ele forneceu aqueles para o código em Python no teste anterior.
Vamos passar agora para os testes de raciocínio lógico.
Vou testar um quebra-cabeça clássico:
"Um homem tem que atravessar um rio com um lobo, uma cabra e um repolho. Seu barco só pode transportar a si mesmo e mais alguma outra coisa. Se ficassem sozinhos, o lobo comeria a cabra e a cabra comeria o repolho. Como ele pode atravessar tudo com segurança?"
Eu esperava que o modelo fornecesse a seguinte resposta:
Mas vamos ver como ele lida com o processo de pensamento, pois não tenho certeza do que esperar!
Também preciso truncar essa saída para facilitar a leitura:
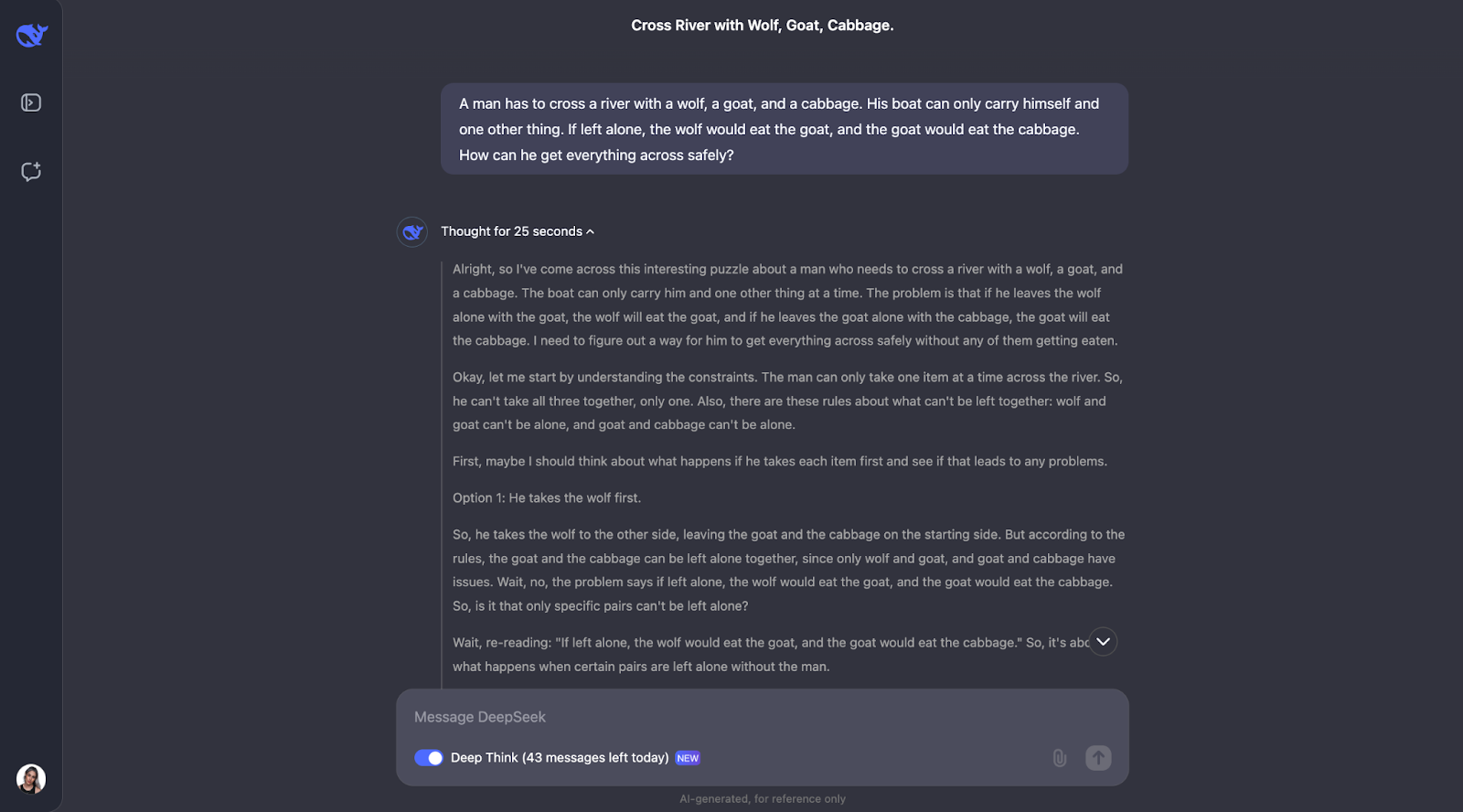
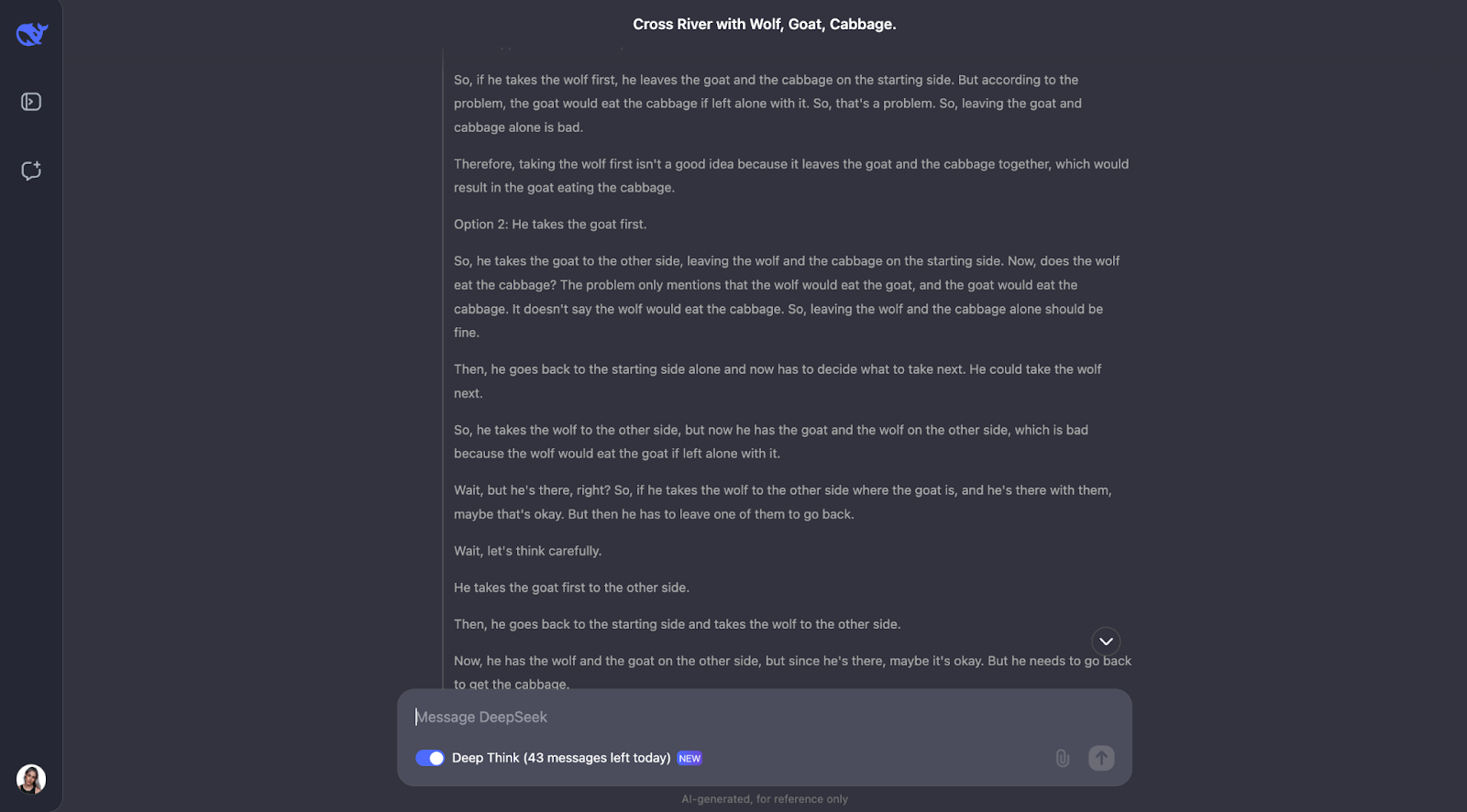
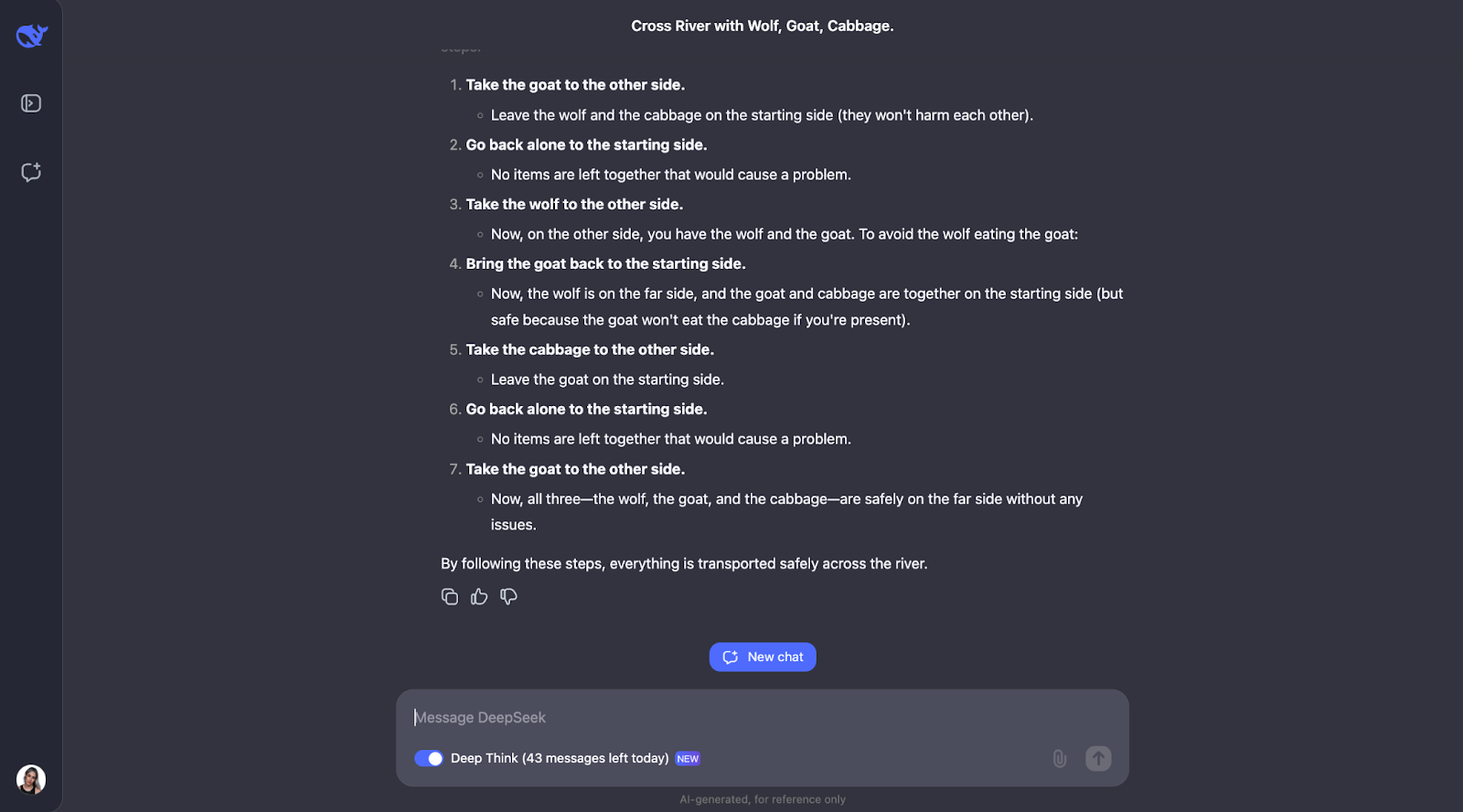
O modelo faz um ótimo trabalho ao resolver esse quebra-cabeça clássico de travessia de rios. Ele pensa cuidadosamente sobre as regras e verifica diferentes possibilidades. Ele entende que alguns pares, como o lobo e a cabra ou a cabra e o repolho, não podem ser deixados sozinhos. Ele também analisa as restrições no início. A partir disso, ele considera o que aconteceria se o homem levasse cada item para o outro lado do rio primeiro e vê se isso criaria algum problema.
O que eu acho muito bom é como o modelo ajusta seu plano quando algo não funciona. Por exemplo, quando ele tenta pegar o lobo primeiro, mas percebe que isso causa problemas e repensa as etapas. Esse método de tentativa e erro parece muito semelhante à forma como nós, seres humanos, podemos resolver o quebra-cabeça.
No final, o modelo apresenta a solução correta e a explica de forma clara e passo a passo.
Vamos tentar outra:
"Você tem 12 bolas, todas com a mesma aparência. Uma bola é mais pesada ou mais leve que as demais. Usando uma balança, encontre a bola diferente e determine se ela é mais pesada ou mais leve em apenas três pesagens."
Esse clássico quebra-cabeça lógico testa a capacidade do modelo de criar uma estratégia ideal usando o raciocínio dedutivo. Vamos ver o que acontece. O resultado foi muito longo desta vez, portanto, por isso vou direto para a resposta :
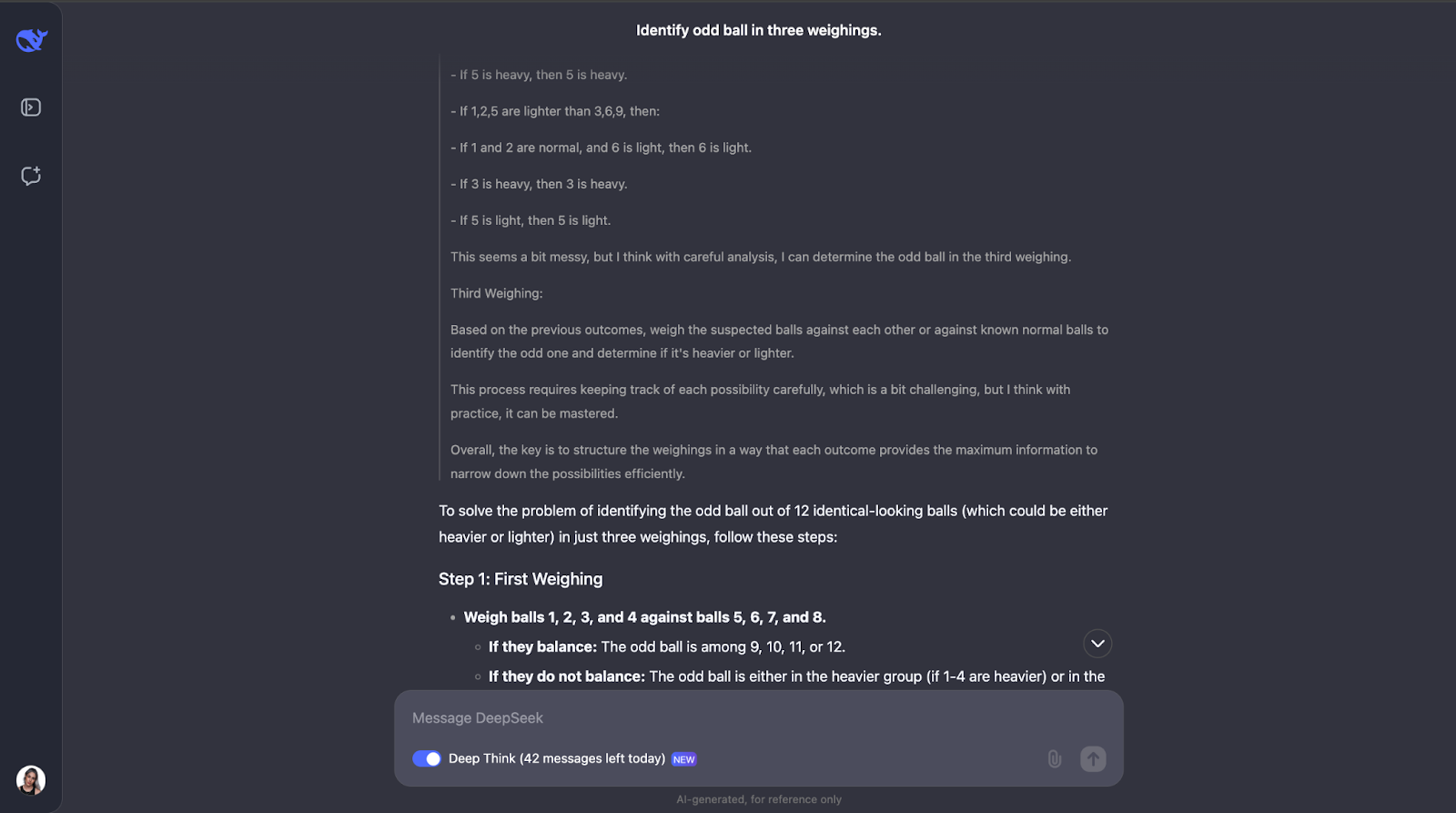
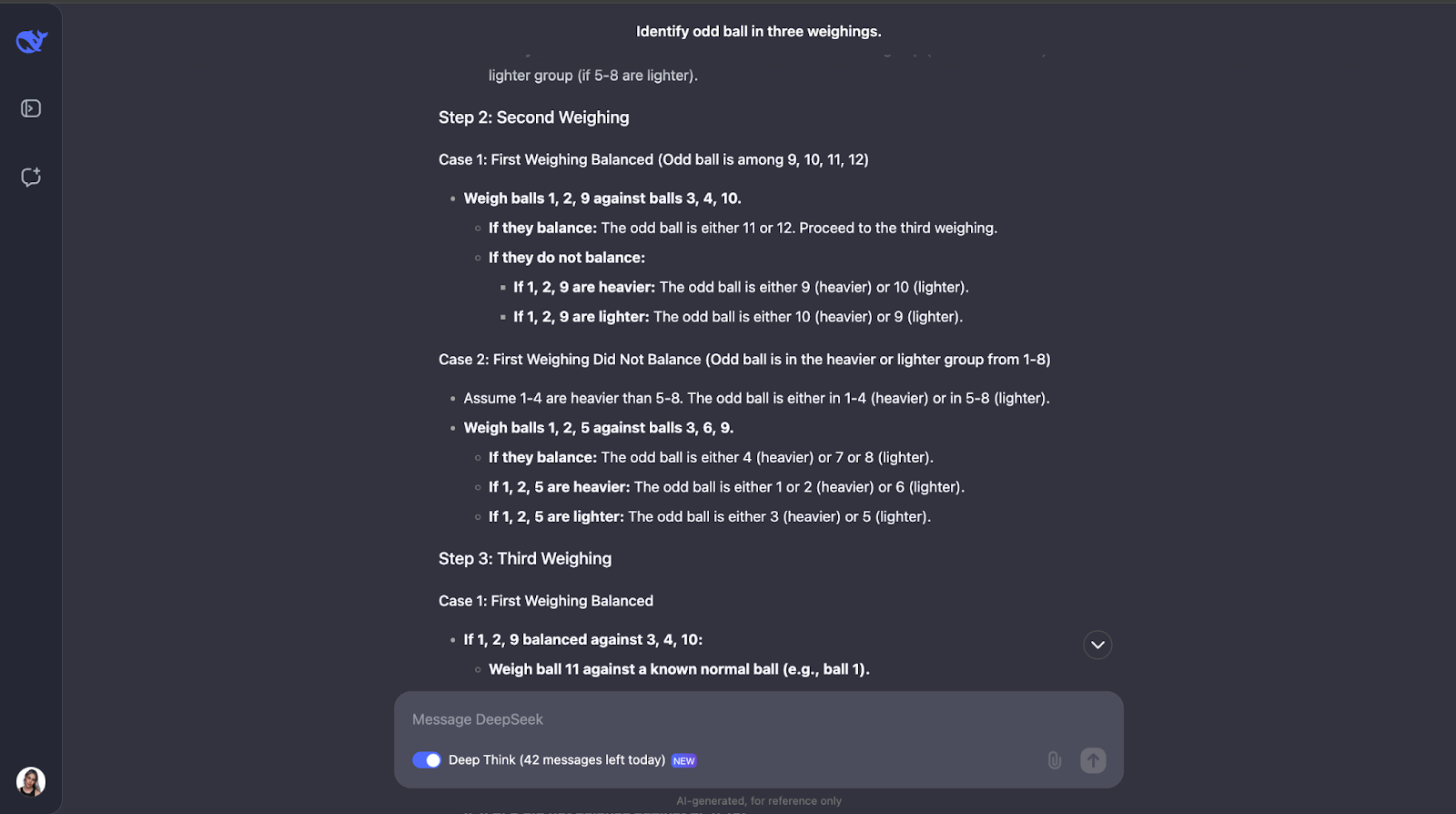

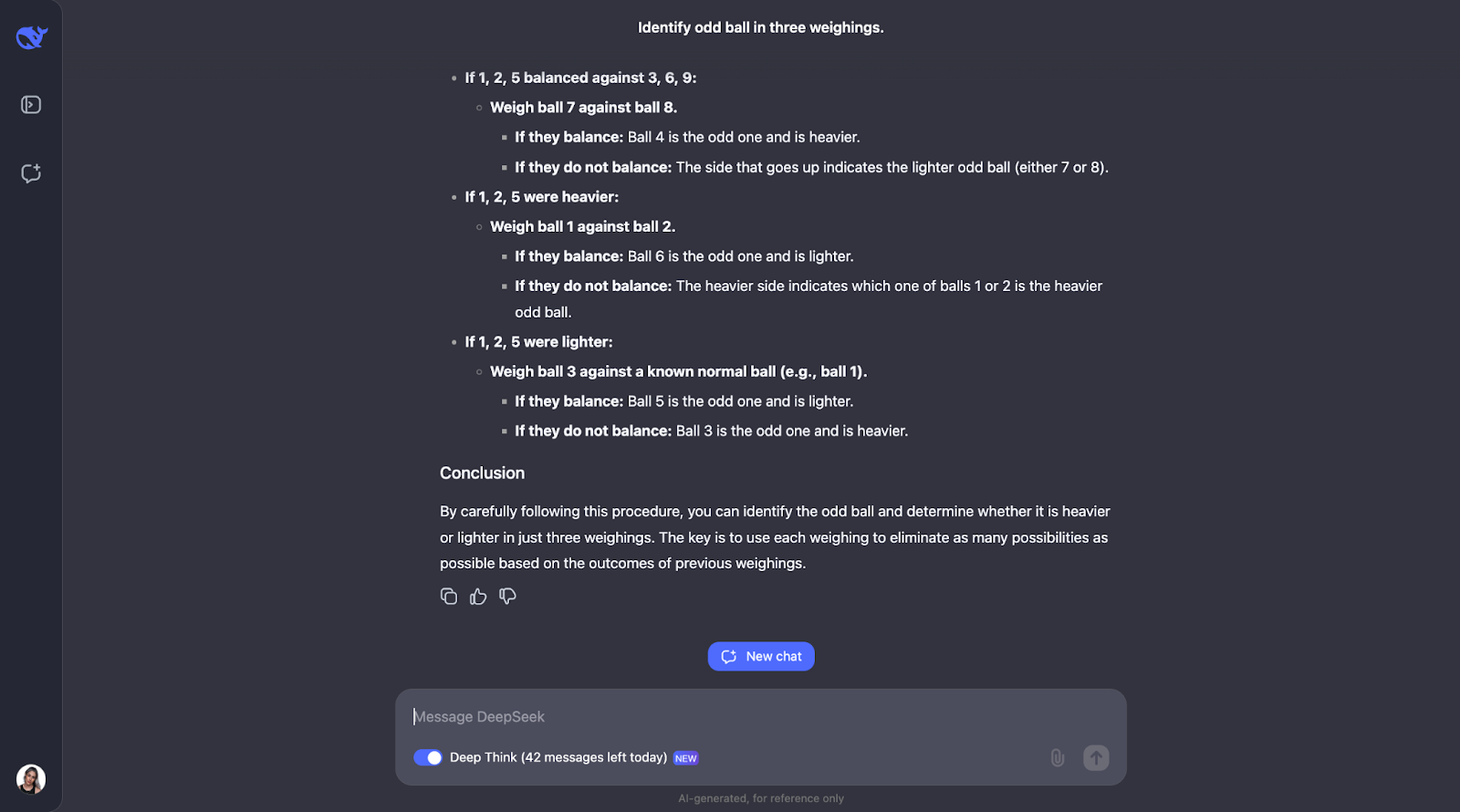
Outro em que subestimei totalmente o tamanho da saída! O modelo percebe que para resolver esse quebra-cabeça é necessário um planejamento cuidadoso, pois só tem três tentativas. Ele também calcula o número de resultados e possibilidades.
A abordagem do modelo é inteligente porque cada pesagem elimina o maior número possível de possibilidades. Ele considera todos os resultados possíveis, considerando a inclinação ou o equilíbrio da balança, e modifica o próximo curso de ação de acordo. Ele é muito detalhado, mas as etapas são claras e lógicas, o que o torna muito fácil de acompanhar, mesmo que seja longo,
Um aspecto de que realmente gostei é que, quando a abordagem começa a ficar um pouco complexa demais, ela aplica uma abordagem mais sistemática ou mais simples. No entanto, acho que para problemas como esse, em que você precisa acompanhar diferentes casos, resultados e possibilidades, adicionar um diagrama ou gráfico pode ajudar as pessoas a visualizar a linha de pensamento e entender melhor o resultado.
Nesta seção, compararei o DeepSeek com outros modelos, como o1-preview e GPT-4o, em termos de desempenho em diferentes benchmarks. Cada um deles se concentra em uma habilidade diferente, para que você possa ver quais modelos são melhores em quê. Vamos ver os benchmarks medidos pelo DeepSeek:
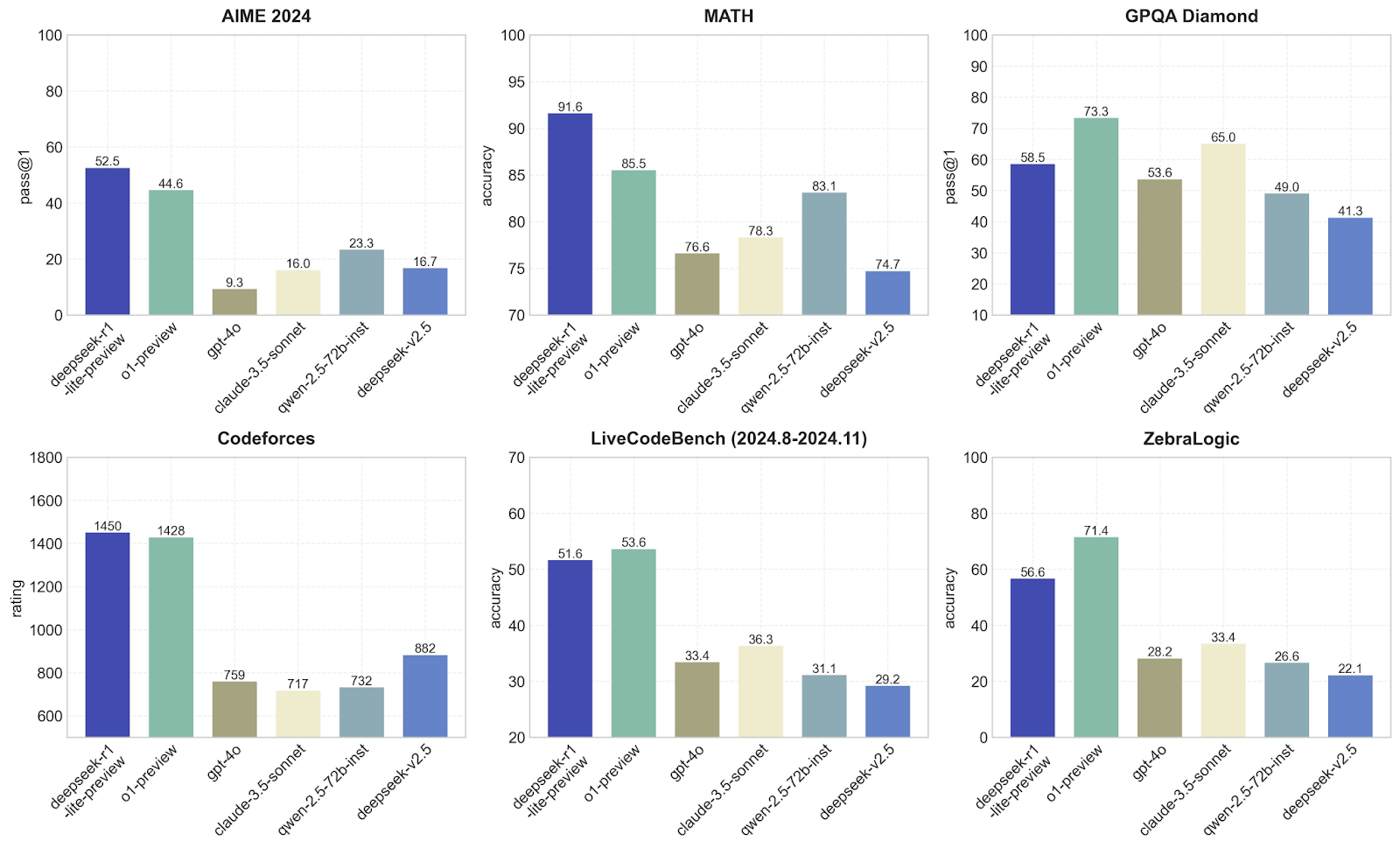
O DeepSeek-r1-lite-preview é claramente o melhor aqui, com um pass@1 de 52,5, seguido pelo o1-preview com 44,6. Outros modelos, como GPT-4o e claude-3.5-sonnet, têm desempenho muito pior, com pontuações abaixo de 23. Isso sugere que o modelo DeepSeek-r1-lite-preview é muito bom em lidar com o tipo de matemática avançada ou problemas lógicos específicos dos benchmarks AIME, o que não me surpreende depois dos testes que realizei.
O DeepSeek-v1 domina novamente com uma precisão impressionante de 91,6, muito à frente do o1-preview (85,5) e muito melhor do que outros modelos, como o GPT-4o, que tem dificuldade para atingir 76,6. Isso mostra que o DeepSeek é excelente para resolver problemas de matemática, o que confirma minha hipótese a partir da evidência empírica nos testes que realizei anteriormente; nenhuma surpresa até agora!
Aqui, o o1-preview se sai melhor do que o DeepSeek-v1, com um pass@1 de 73,3 em comparação com 58,5. Outros modelos, como o GPT-4o, ficam atrás, com 53,6. Isso sugere que a o1-preview é mais adequado para tarefas que envolvem responder a perguntas ou resolver problemas com base no raciocínio lógico. O DeepSeek tem um desempenho sólido, mas não é tão bom quanto o o1-preview.
Em programação competitiva, o DeepSeek-v1 (1450) e o 01-preview (1428) estão quase empatados na primeira posição, enquanto outros modelos, como o GPT-4o, têm uma pontuação de apenas 759. Como esperado, isso mostra que esses dois modelos são excelentes para entender e gerar códigos para desafios de programação.
Isso testa as habilidades de programação ao longo do tempo, e o o1-preview fica um pouco à frente do DeepSeek-v1 (53,6 vs. 53,5 vs. 53,5). 51.6). Outros modelos, como o GPT-4o, ficam bem atrás, com 33,4. Novamente, isso mostra que tanto o DeepSeek quanto o 01-preview são adequados para programação, mas que o 01-preview é um pouco melhor nessas tarefas.
O o1-preview assume a liderança aqui com uma precisão de 71,4, em comparação com 56,6 do DeepSeek-v1. Outros modelos se saem muito pior. Isso mostra que o o1-preview é melhor para lidar com tarefas lógicas abstratas como ZebraLogic, que exigem um pensamento mais criativo ou inovador, o que está alinhado com os resultados que obtive nos testes, pois a criatividade definitivamente não é o forte do DeepSeek-v1.
Esses gráficos confirmam que o DeepSeek-v1 é incrível em desafios de matemática e programação. Eu diria que o o1-preview é mais equilibrado e tem bom desempenho em uma variedade maior de tarefas, o que o torna mais versátil.
Vamos dar uma olhada nesse gráfico:
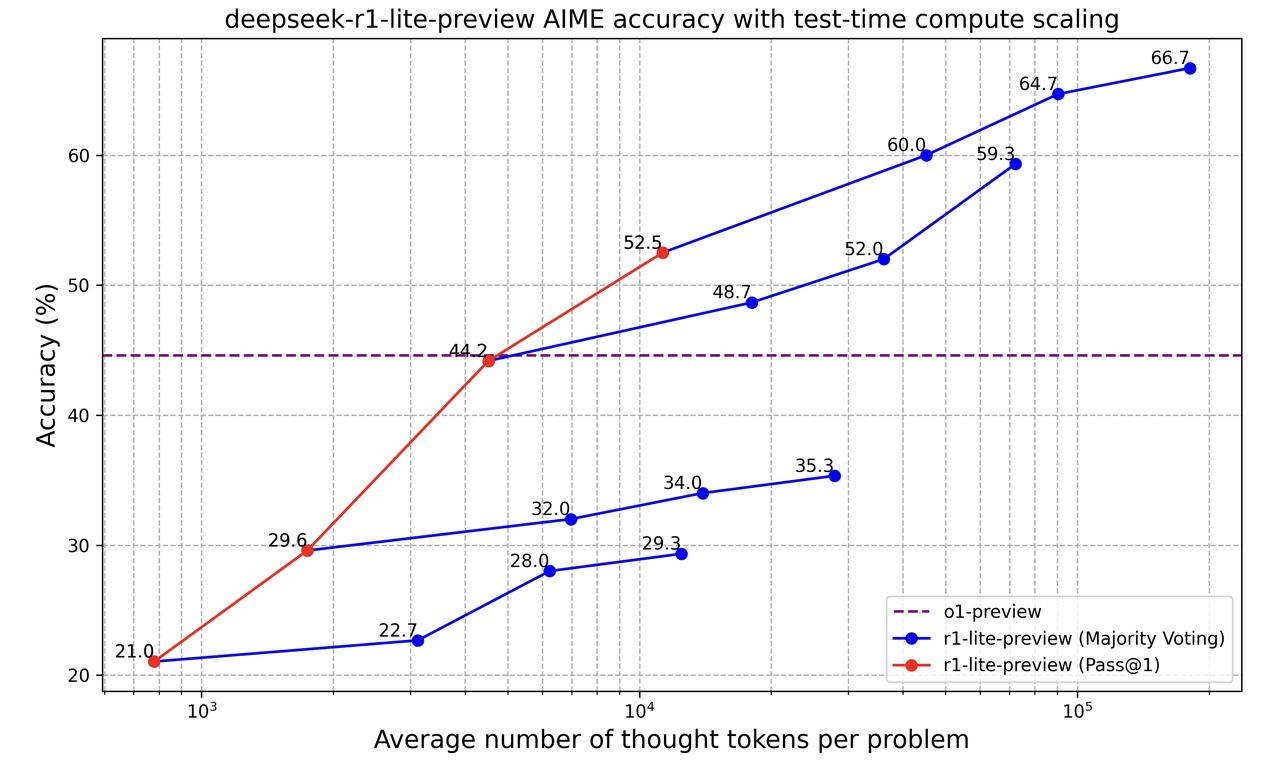
Este gráfico mostra como o modelo "deepseek-r1-lite-preview" se torna melhor na solução de problemas à medida que processa mais informações (medido pelo número de "tokens de pensamento" que usa). Ele compara duas maneiras de medir a precisão do modelo:
A linha roxa tracejada representa o modelo o1-preview que tem uma precisão estável. No início, a o1-preview é melhor, mas como o DeepSeek r1-lite-preview pode usar mais tokens de pensamento, ele ultrapassa a o1-preview e se torna muito mais preciso.
Então, basicamente, esse gráfico mostra que deixar o DeepSeek r1-lite-preview pensar mais e tentar várias vezes melhora sua precisão.
O DeepSeek-r1-lite-preview é melhor do que o o1-preview da OpenAI? Bem, isso depende da tarefa. Eu diria que sim para problemas de matemática e programação. Para o raciocínio lógico, depende da tarefa.
O que realmente me surpreendeu foi como ele raciocinou em alguns dos testes. Isso realmente me fez pensar sobre o que realmente significa para um modelo "pensar" e como ele chega às abordagens de raciocínio.
Se você está curioso sobre esse modelo, por que não testá-lo você mesmo? Experimente-o nas tarefas de seu interesse e veja como ele se comporta - você pode achar tão surpreendente quanto eu!
Aprenda IA com estes cursos!
Programa
Curso
Curso