
Track
AI Fundamentals
10 hr
DeepSeek-R1-Lite-Preview is an AI tool, similar to ChatGPT, created by the Chinese company DeepSeek. The company announced this new model on X on November 20th (tweet link) and shared a few details on a documentation page.
DeepSeek-R1-Lite-Preview is meant to be really good at solving complex reasoning problems in math, coding, and logic. It shows you how it thinks step-by-step so you can understand how it comes up with answers, which helps people trust it more.
You can try it out for free on their website, chat.deepseek.com, but you’re limited to 50 messages a day in its advanced mode called “Deep Think”. DeepSeek also plans to share parts of this tool with the public so others can use or build on it.
You can start using DeepSeek-R1-Lite-Preview by following these two steps:
To see what DeepSeek-R1-Lite-Preview can do, let’s put it to the test! I'll go through a series of challenges that show off its reasoning skills, starting with the simple but famous strawberry question: How many times does the letter “r” occur in 'strawberry'?"
This question might look simple, but LLMs (even GPT-4o) have traditionally struggled with answering it correctly—they typically answer that there are only two occurrences of the letter “r.”
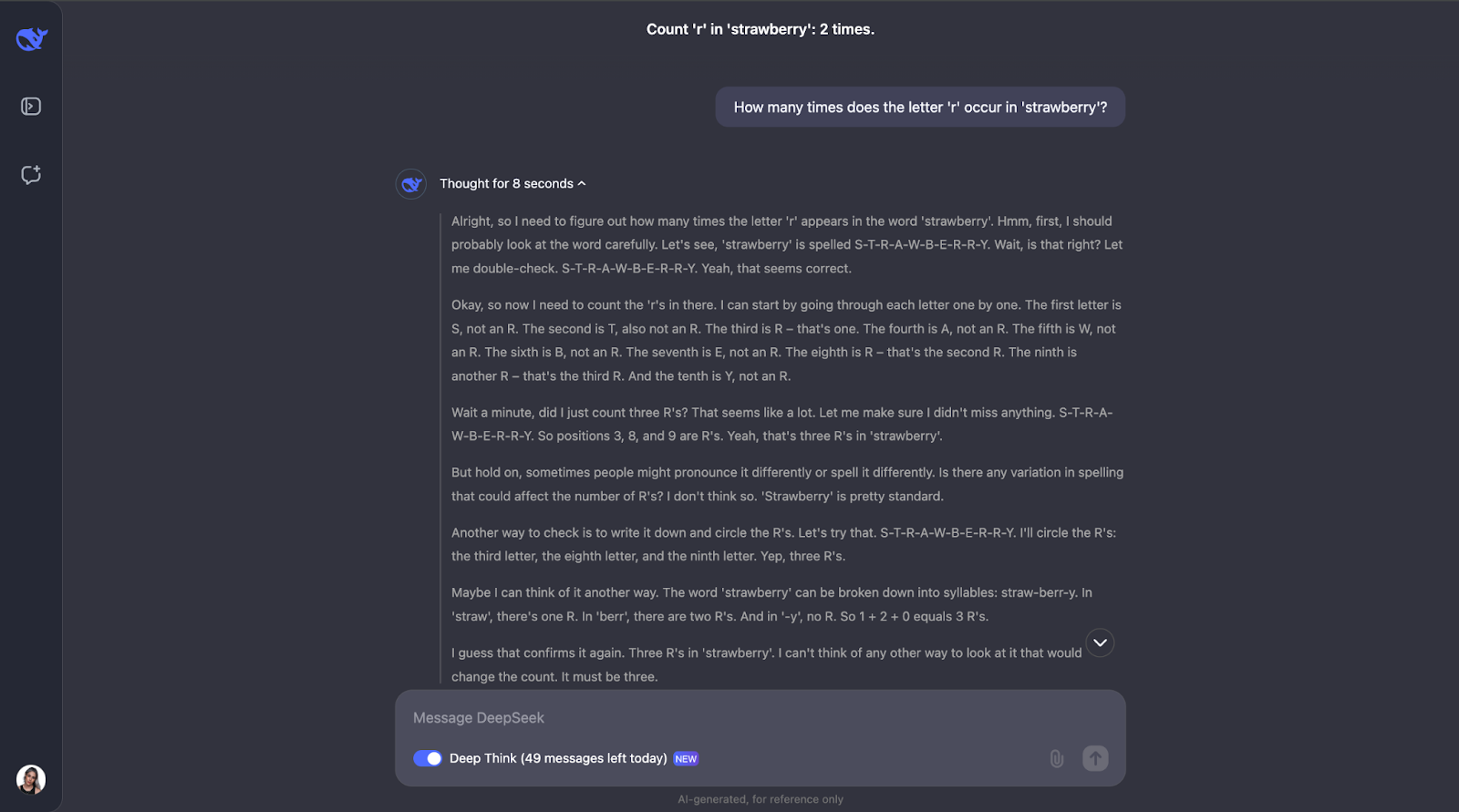
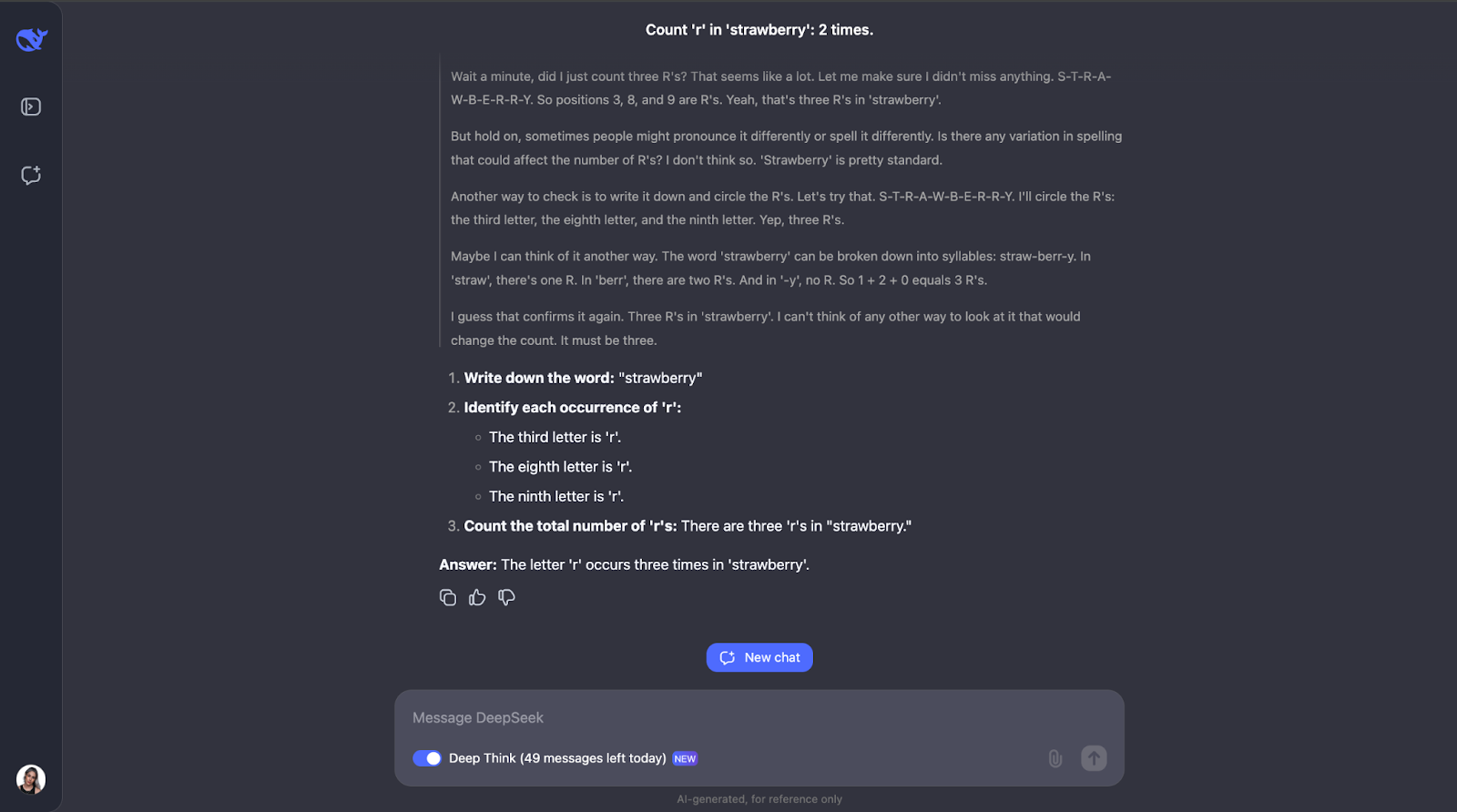
Wow, okay – I didn’t expect such a long reasoning process for what seems like a straightforward task. I thought that after counting the letter 'r' and identifying its position in the word, it would have stopped there. But what’s interesting to me is that it didn’t stop there. It double-checked the counting a couple of times and even considered things like how people might pronounce or spell the word differently – which I think is a bit redundant, especially the pronunciation part. But that does show how careful and thoughtful it is! It also explained every step so I could follow its thought process and see how it got to the answer.
I’ll be testing DeepSeek-R1-Lite-Preview on three math problems.
Given DeepSeek's claims to be really good at mathematical reasoning, let's start with a simple geometric problem.
"If a triangle has sides of length 3, 4, and 5, what is its area?"
This problem requires knowledge of the Pythagorean theorem and Heron's formula. I'd expect DeepSeek-R1-Lite-Preview to show its work, perhaps like this:
Let’s see what happens!
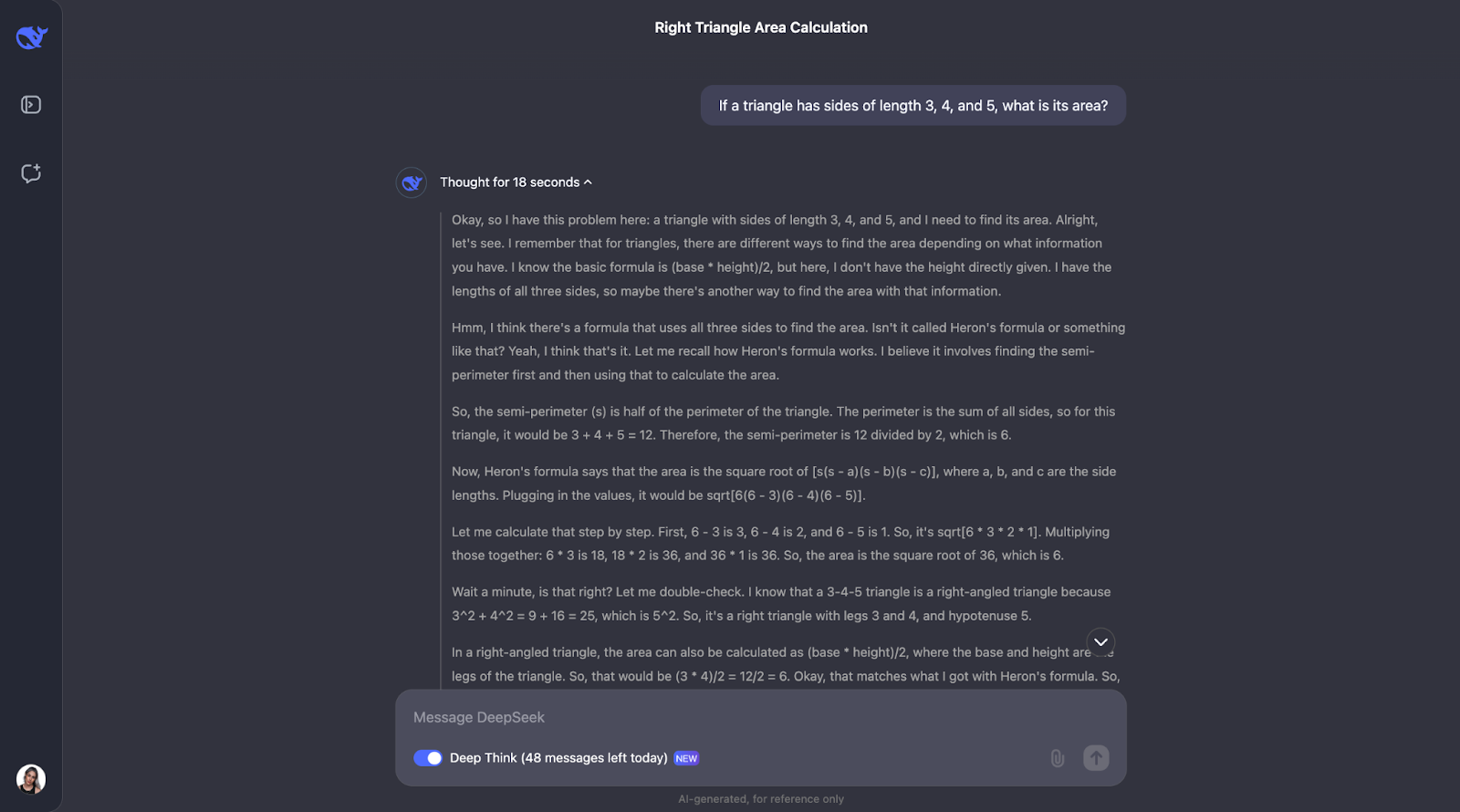
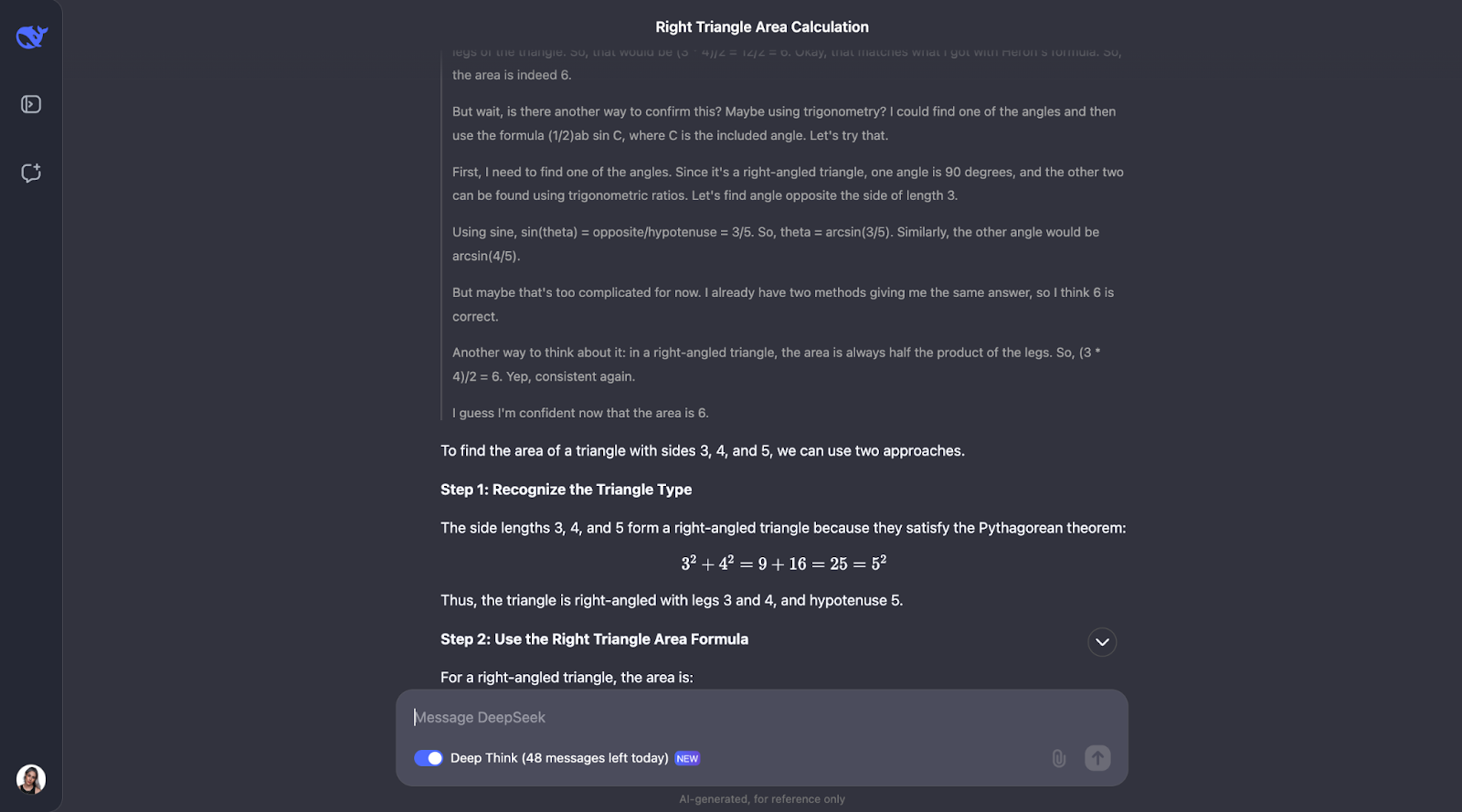
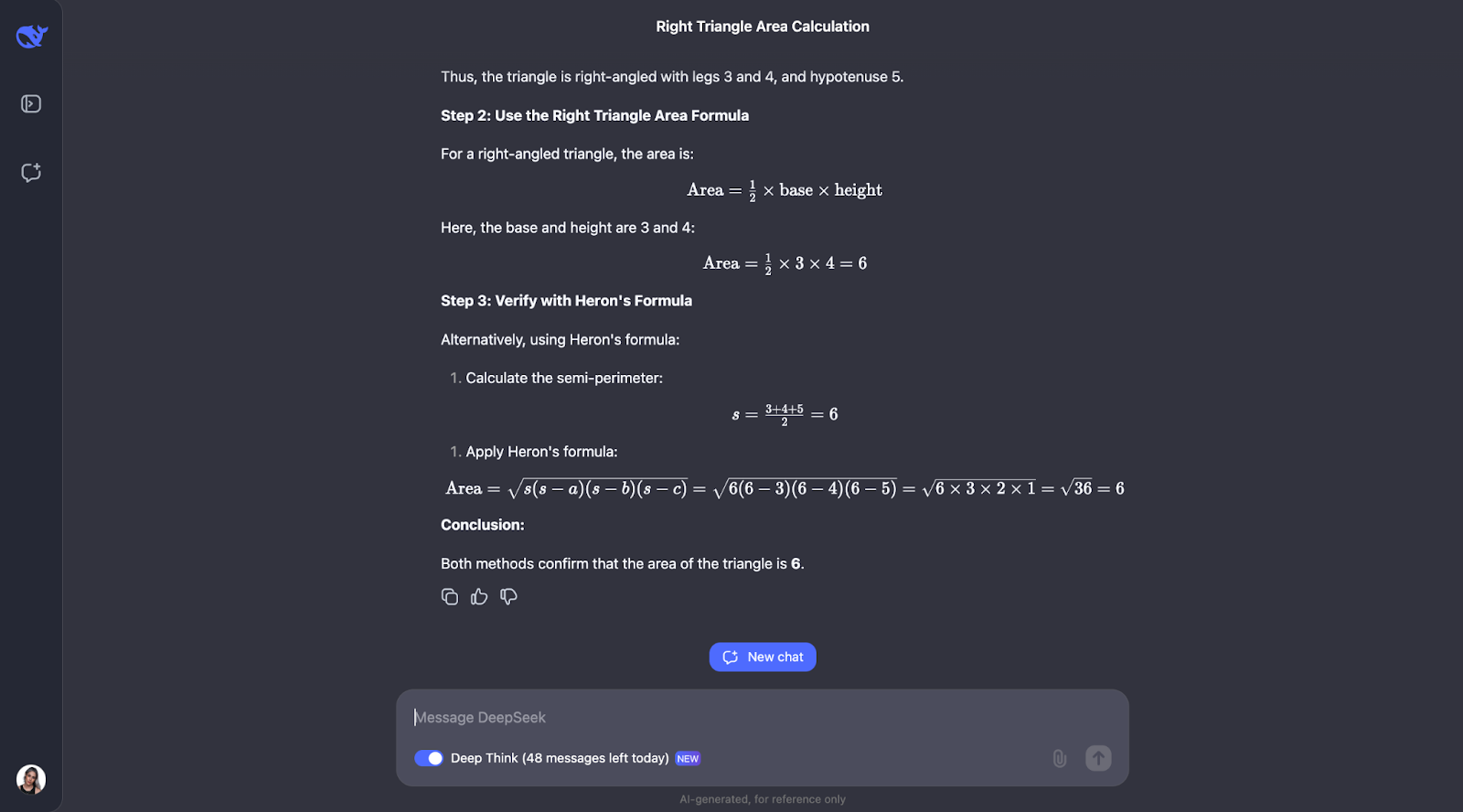
Okay, so interestingly enough, it performs the checks I predicted—although in a different order. It also considered using trigonometry by calculating angles and trying another formula. I think it’s so interesting that, in the end, it decided this wasn’t needed since the first two methods had already confirmed the answer.
Both the explanation and the output were particularly clear and easy to follow, which makes me think this would be a fantastic model to embed in a math student’s assistant, for example. For this particular use case, maybe the thought process could be shown first, and the student could interact with it, acknowledging whether they understood it or not before proceeding to the final answer.
Let’s move on to a more complex math test to see if there is any difference in the performance and thought process.
“Prove that the sum of the reciprocals of the Fibonacci numbers converges to a finite value.”
This test challenges the model's understanding of advanced mathematical concepts, such as series convergence and the properties of Fibonacci numbers. Let’s try it! For the sake of readability, I’ll only post the first and the last part of the answer (but feel free to try it yourself with the same prompt):
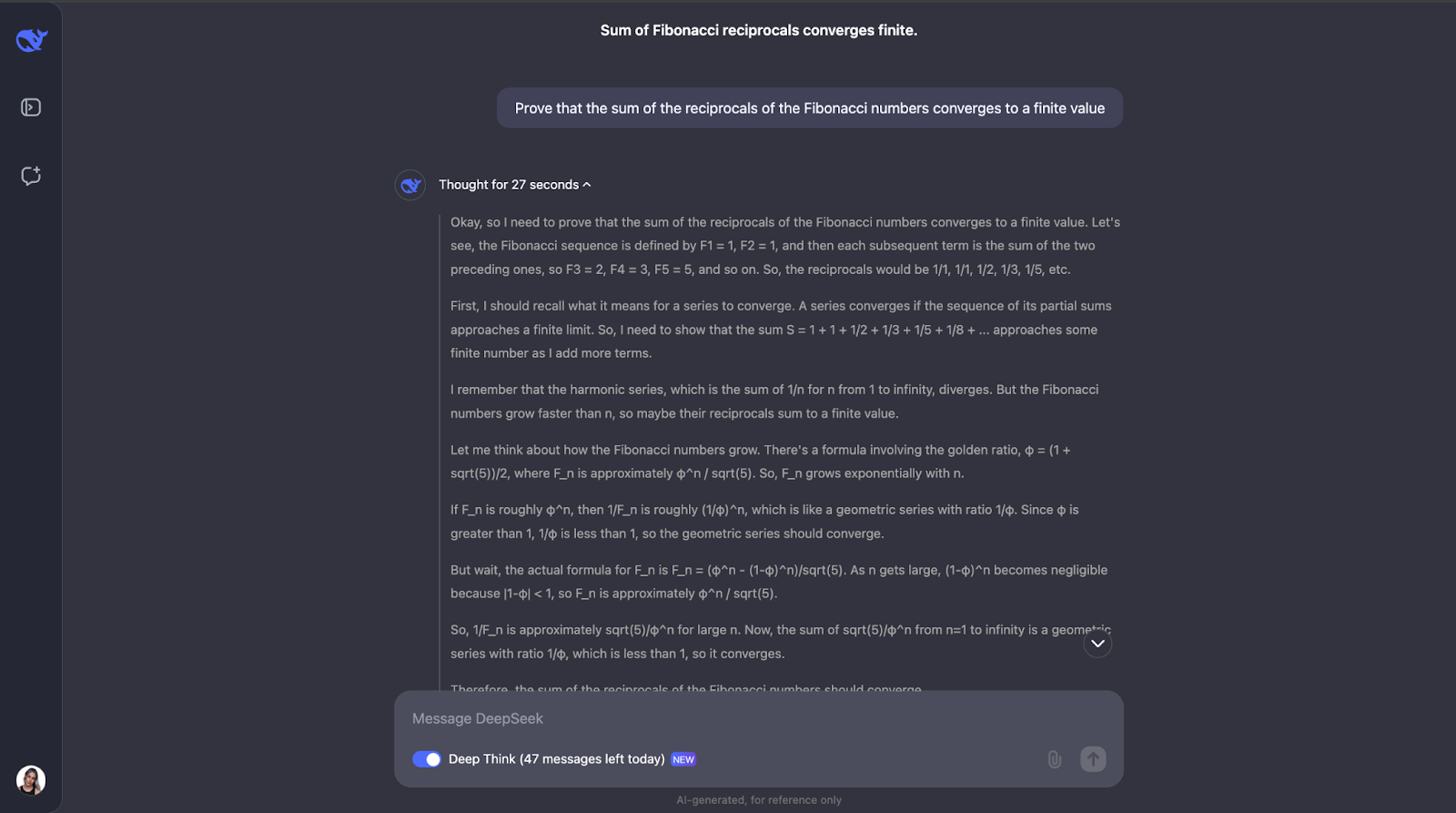
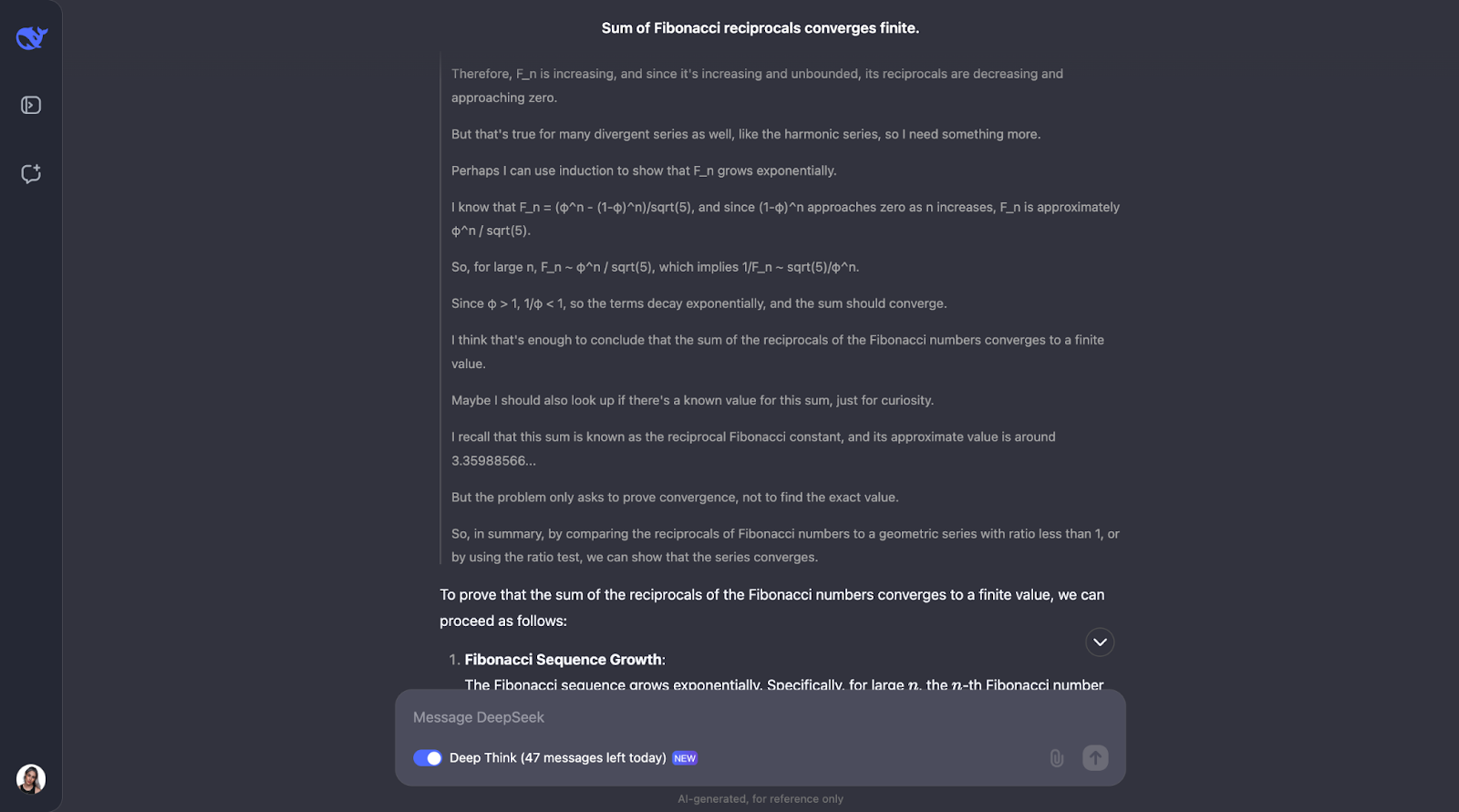

Okay, so this is a great train of thought—I really like how it first makes sure that it understands the key concepts, such as reciprocals and convergence. Then, DeepSeek-R1-Lite-Preview approached this problem by looking at how the Fibonacci numbers grow and using a comparison test, which is a common way to test if a series converges or not.
It compared the reciprocals of the Fibonacci numbers to a geometric series. Since the reciprocals of the Fibonacci numbers decrease even faster than a geometric series with a common ratio of less than 1, the model concluded that the sum of the reciprocals also converges to a finite value. To be extra sure, it used something called the ratio test.
This test checks if the limit of the ratio of consecutive terms is less than 1. If it is, the series converges. The model calculated this ratio for the reciprocals of the Fibonacci numbers and found that it is indeed less than 1.
It even mentioned that there's a known value for this sum called the reciprocal Fibonacci constant, which is approximately 3.3598. But for this problem, we just needed to know that the sum is finite, not exactly what it is—so this was extra information that I found interesting too. I really like how the solution is presented in the output. It is clear and step-by-step.
So far, I am impressed with the mathematical tasks.
I am going to try a differential geometry problem—just because my PhD is in this field so I couldn’t resist doing a little test. Nothing overly complex, just a classic exercise you might encounter in undergraduate mathematics.
“Consider a surface S in R³ parameterized by
φ(u,v) = (u cos v, u sin v, ln u)
for u > 0 and 0 ≤ v < 2π.
a) Calculate the first fundamental form of S.
b) Determine whether S is a minimal surface.
c) Find the Gaussian curvature K and the mean curvature H of S.”
What I would expect DeepSeek-R1-Lite-Preview to do is to provide a step-by-step solution, showing all calculations and explaining the significance of each result as well as the definitions of the main concepts such as fundamental form, minimal surface, and the different curvatures.
To keep this blog readable, I’ll only be able to show only the first and last part of the answer, but I encourage you to try the prompt yourself:
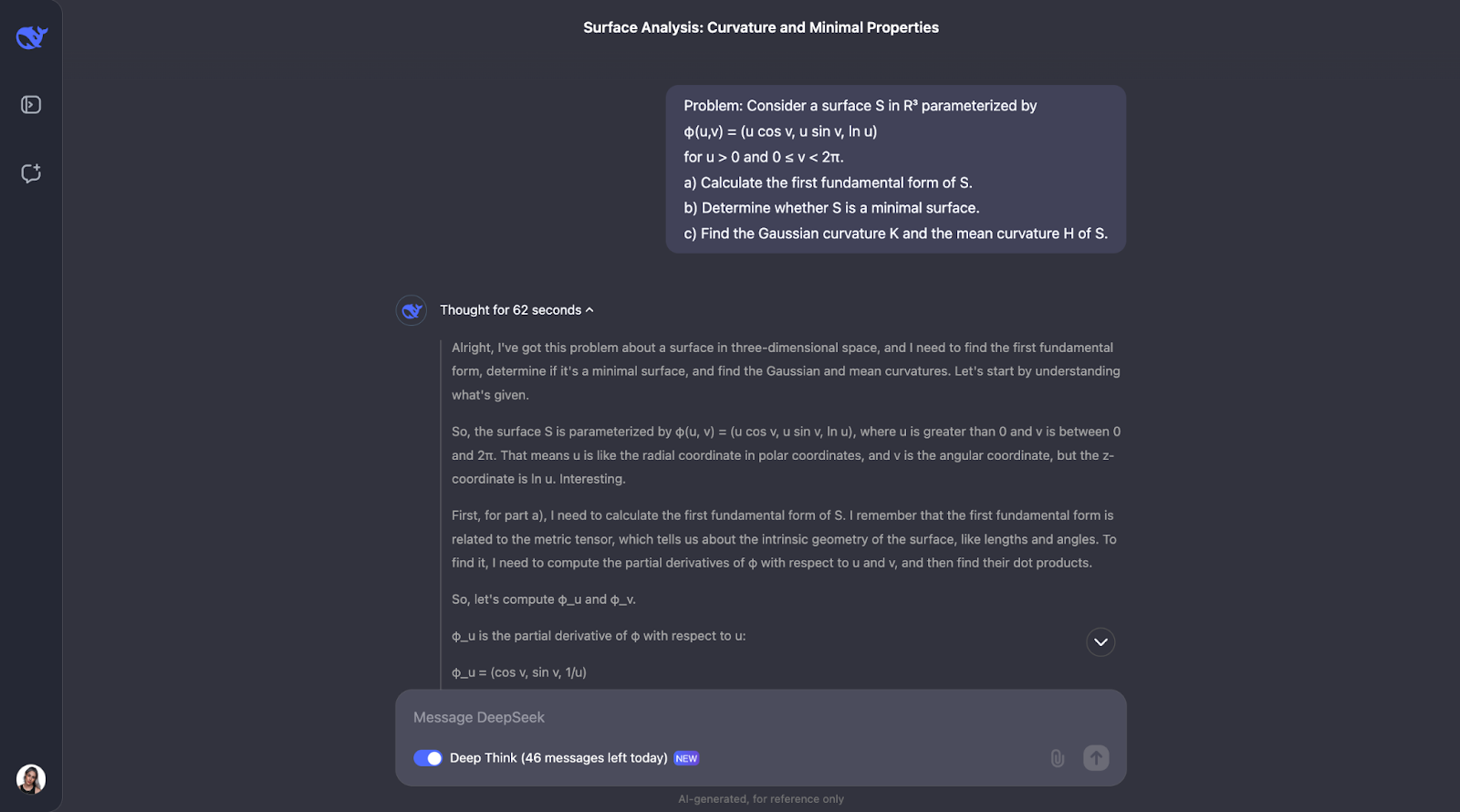
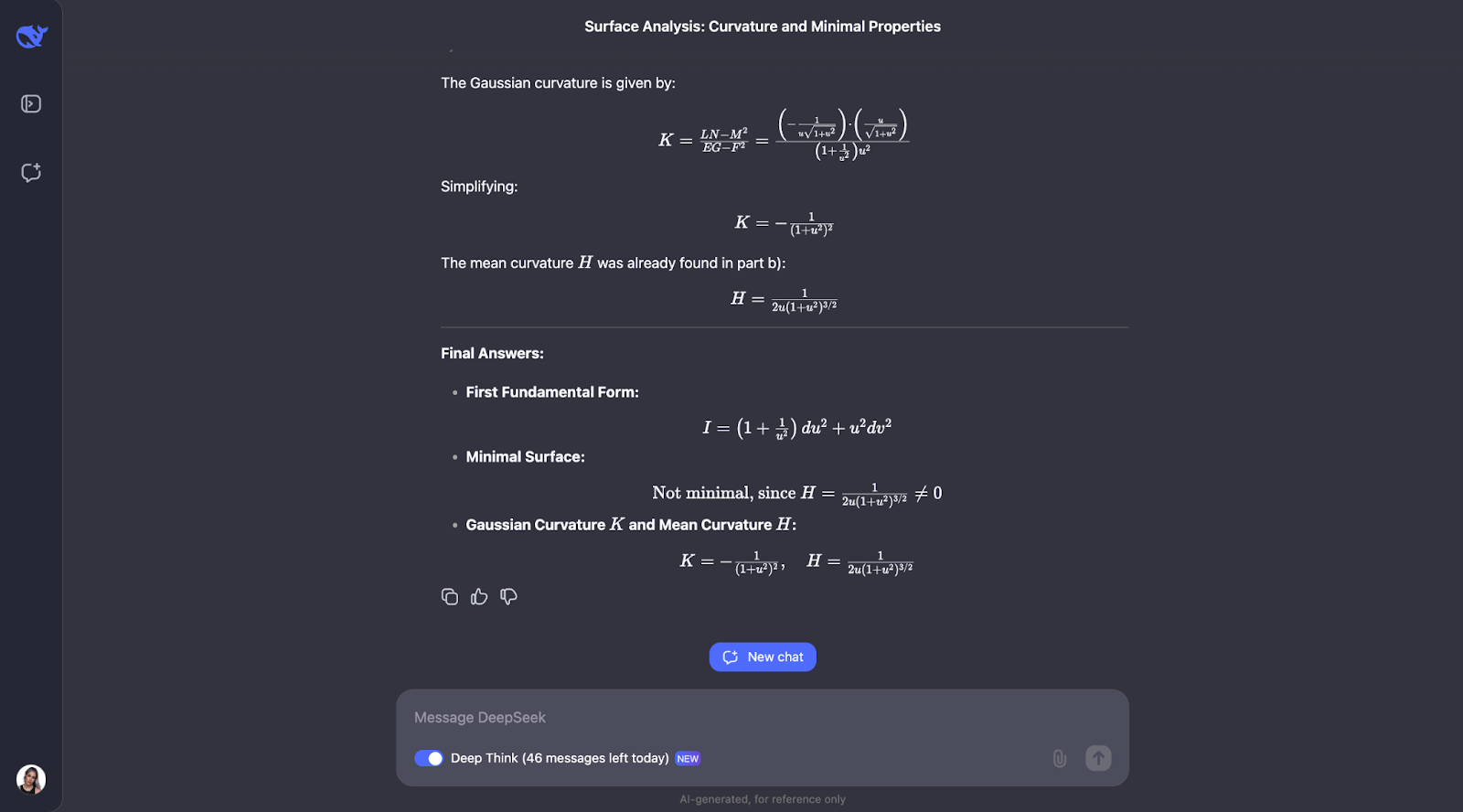
The step-by-step approach uses well-known geometric formulas and applies them directly, which makes the reasoning easy to follow. However, I would have expected it to check for its own understanding of the main concepts in the problem, which is not part of the train of thought. For part B, it takes an alternative approach and identifies that the surface involved is a surface of revolution, which is a nice touch.
There’s also a moment when it comments on rotation and realizes it already has N, the normal vector, which could conflict with the notation of the coefficient for the second fundamental form. I would have liked to see a suggestion on better notation, as using the same letter for two things is not good practice!
When it calculates the mean curvature, it notices it isn't zero and questions whether the computation is correct. To be thorough, it tries another method to double-check its work.
Once again, the output is very clear and easy to follow. Across all these examples, it’s been impressive to see how it consistently double-checks calculations using different methods. The thought process is always detailed, logical, and easy to understand!
Let’s move now into coding tests.
The first one I am going to test is:
“Implement a function in Python that finds the longest palindromic substring in a given string. The function should have a time complexity better than O(n^3).”
I’m trying to evaluate the model's ability to design efficient algorithms and implement them in code. I'd expect a solution using dynamic programming or Manacher's algorithm, with a clear explanation of the approach and time complexity analysis.
The output is very-very long, and I’m only showing the first and last parts:
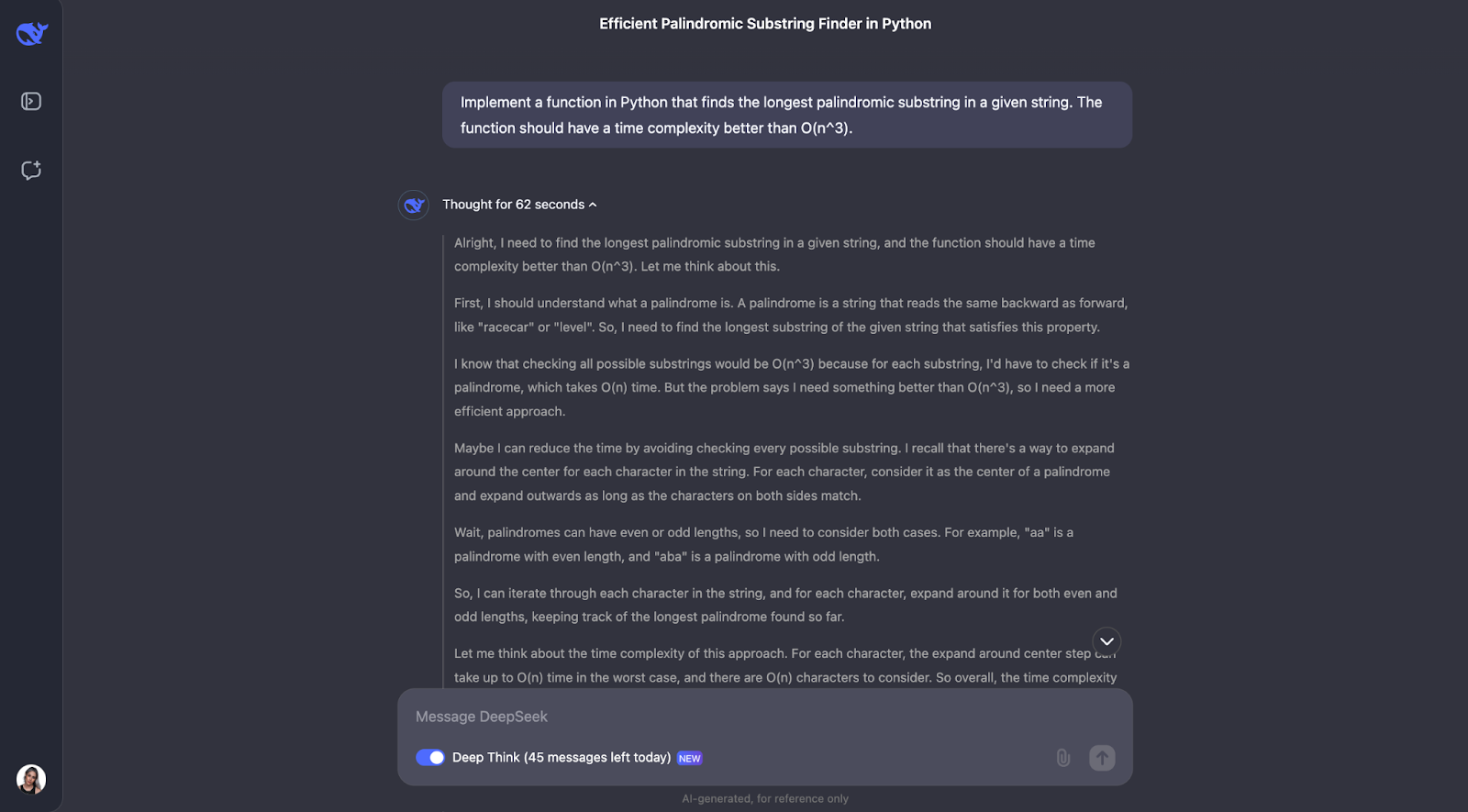
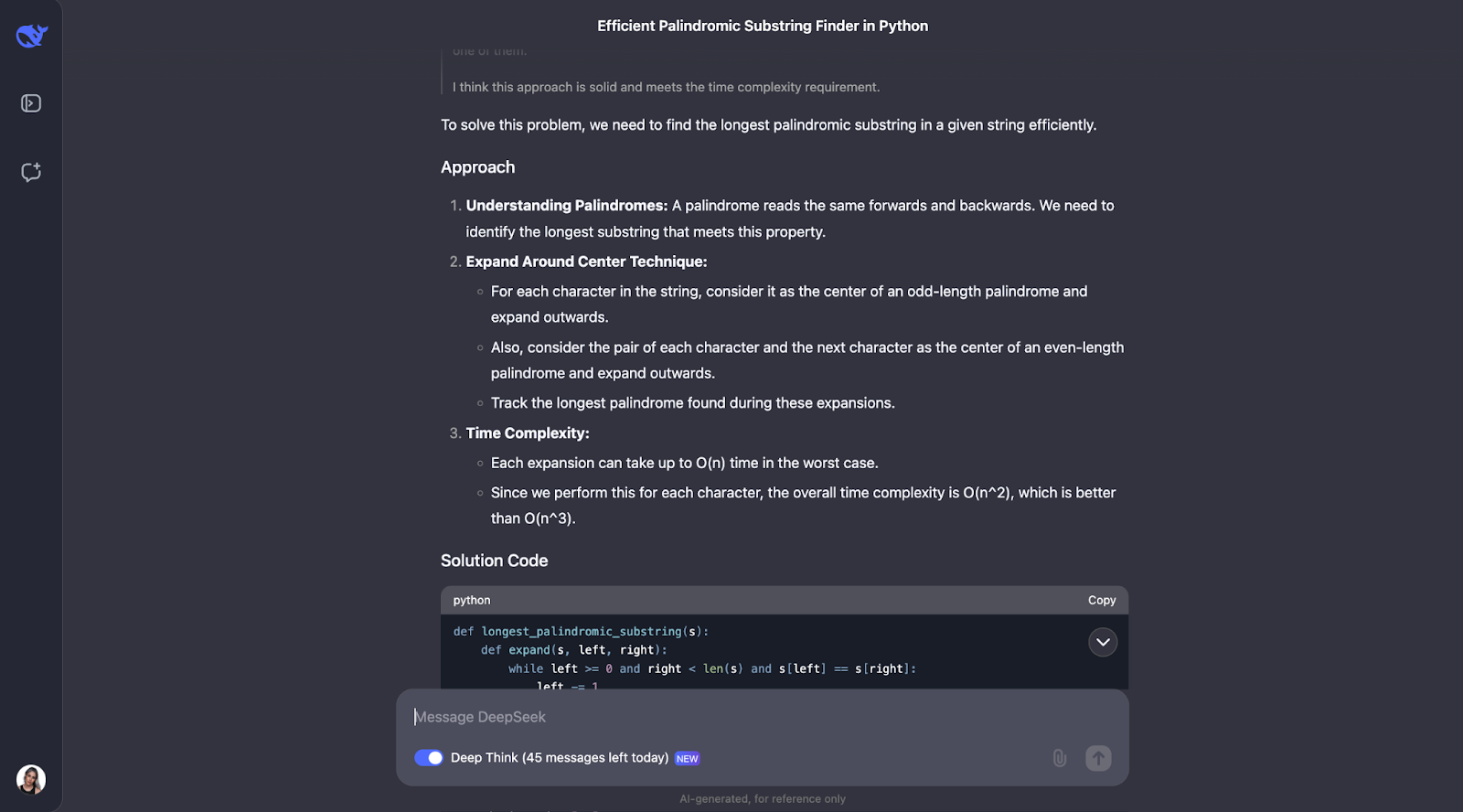
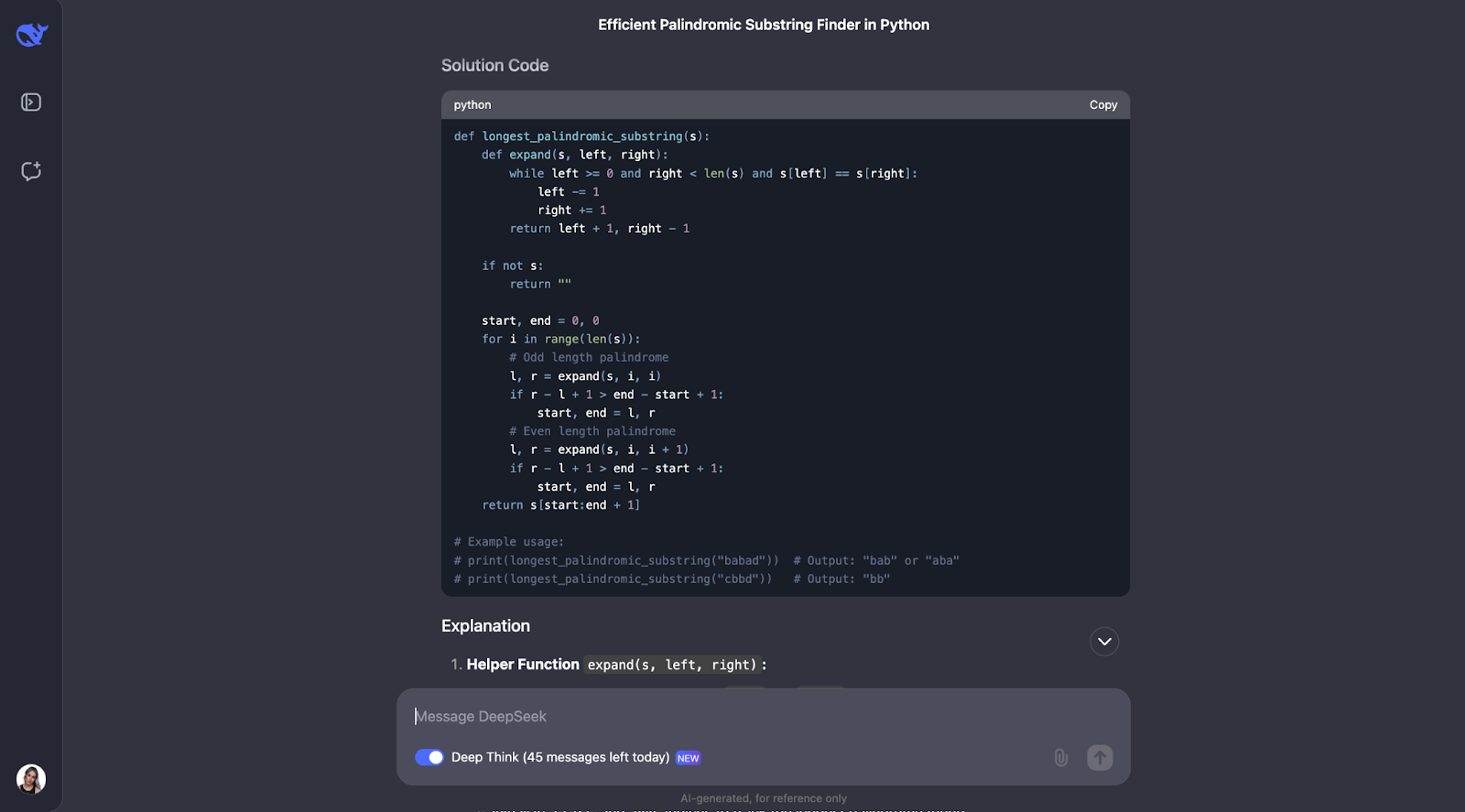
I think that the model did a great job solving the problem of finding the longest palindromic substring. Its approach was smart, efficient, and clearly explained.
Instead of brute-forcing every possible substring, which would be slow, it used a clever "expand around centers" technique. This method handled both odd-length palindromes like "aba" and even-length ones like "abba." It kept track of the longest palindrome it found as it went. The result was an algorithm that runs in O(n^2) time, much faster than an O(n^3) solution.
What impresses me the most about this answer is how clearly it was presented. DeepSeek broke the problem down into understandable steps, explained its thought process in detail, and even included practical examples. For instance, it showed how the algorithm expands around the center of "racecar" or "abba" to find the correct palindrome. The helper function for expanding around a center was particularly nice in my opinion—it made the code modular and easy to follow.
That said, I would have expected it to consider Manacher’s algorithm, which is a faster O(n) solution. It is definitely more complex to implement, but it’s useful for cases where performance is critical, and I would have expected the model to have pointed it out.
I also noticed that the output didn’t explicitly discuss how the algorithm handles special cases, like an empty string or a string with all identical characters (e.g., "aaaa"). These cases would work–but I would have expected it to discuss it at least.
Finally, I think it’s nice that it commented on the expected output for the example usages. However, when I ran the code, just the first option for the first example usage was printed. It would have been great if the code considered all the possible solutions and that all of them were printed.
Let’s try a different coding problem in another programming language.
“Write a function in JavaScript that determines whether a given number is prime”
For readability, I’m only showing the first and the last part (although the chain of thought was a bit shorter this time):
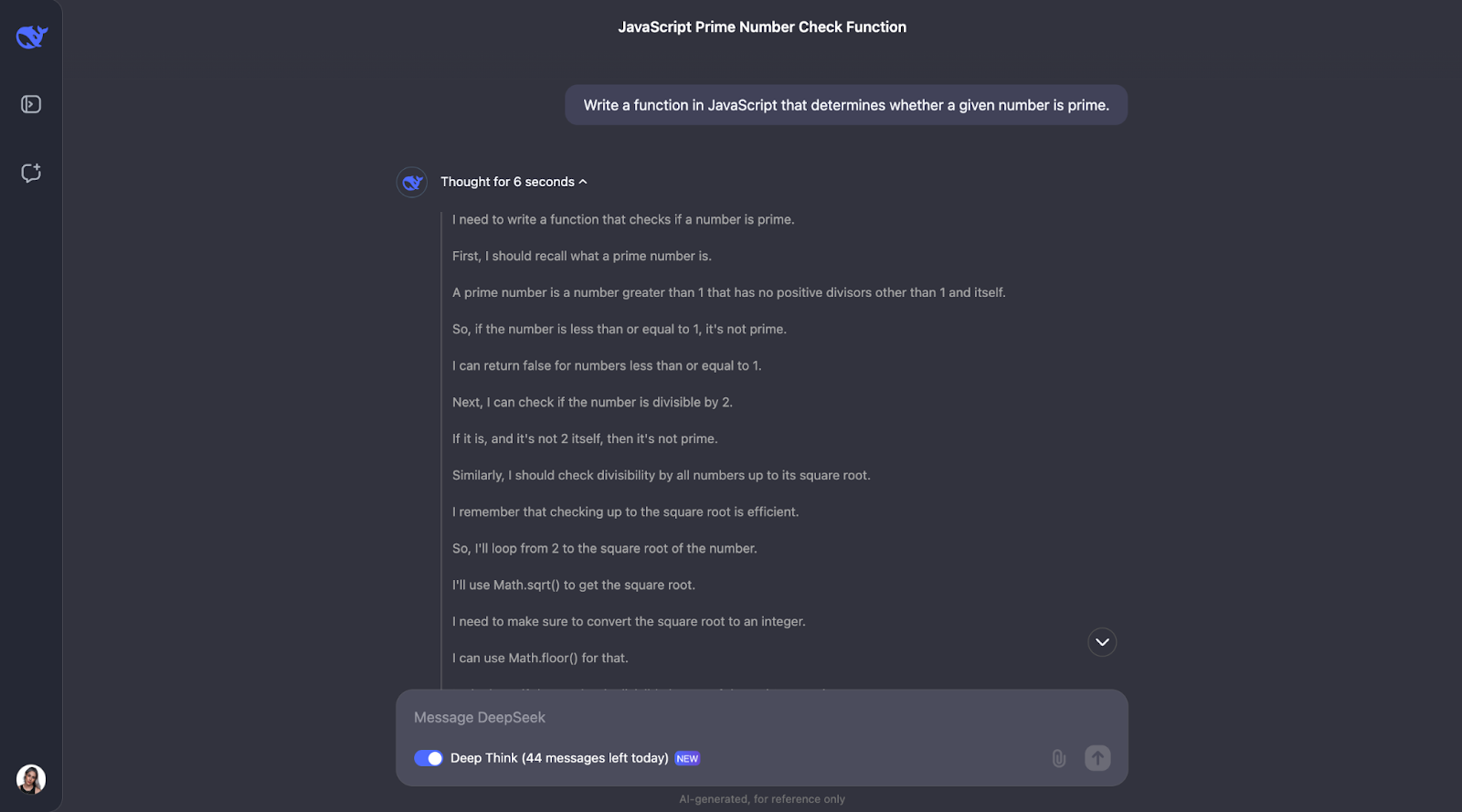
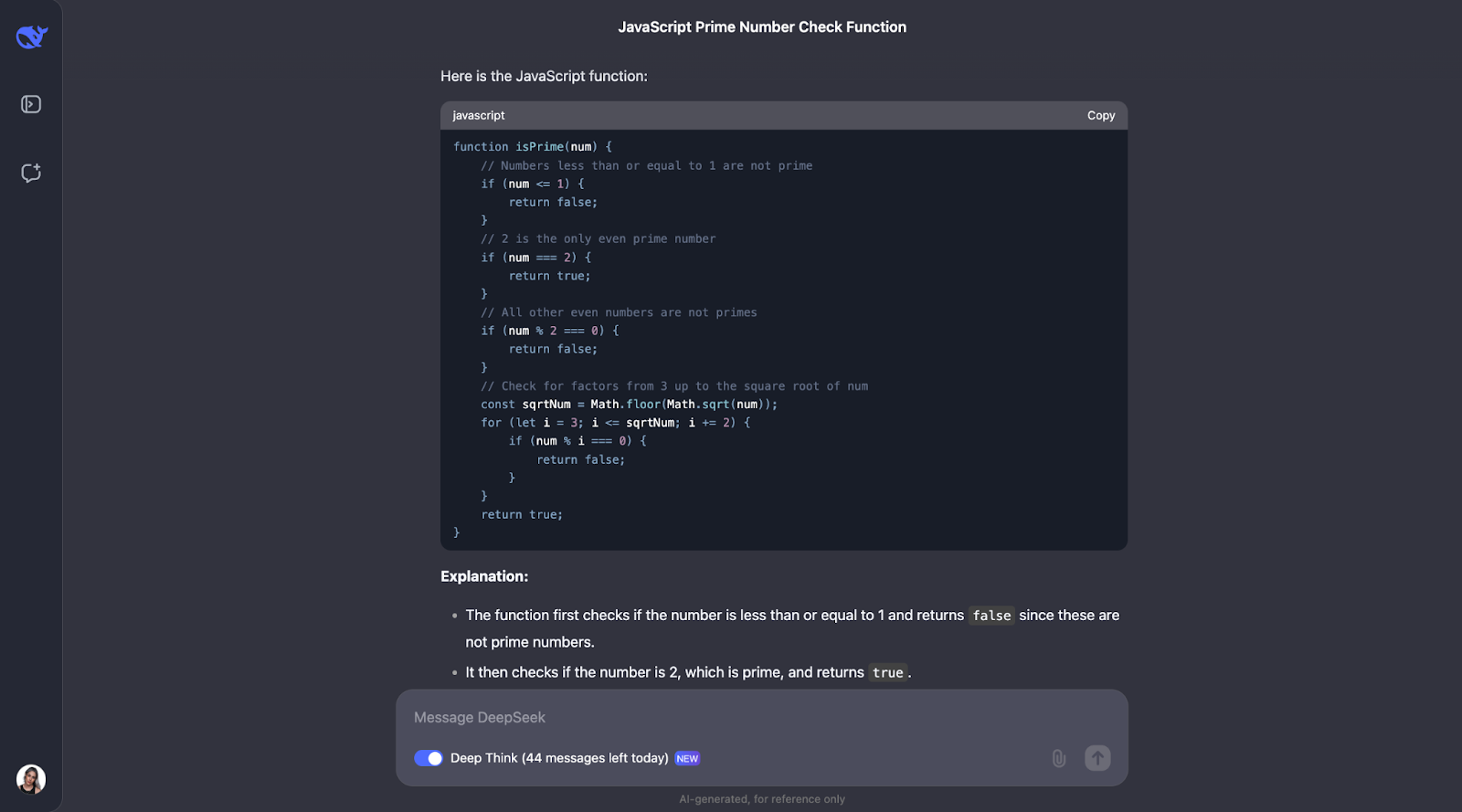
I think we can see a pattern here for the thought process. Most of the time, it starts by defining the key concepts that appear in the problem. So, for example, for this problem, it defines what a prime number is.
After that, the thought process makes sense and arrives at optimized steps. First, it covers the basics: numbers less than or equal to 1 aren’t prime, and 2 is the only even prime number. From there, it checks if the number is divisible by any odd numbers up to the square root of the number. This saves time because it avoids unnecessary calculations. Also, instead of testing every single number, it skips all even numbers beyond 2, making the process even faster. The function uses Math.sqrt to find the square root, which limits how far it needs to check, keeping it efficient and simple.
Again, it also tested with small examples, like in the previous problem, like known prime and non-prime numbers, to make sure it works as expected.
There’s some room for improvement, though. For example, the function doesn’t check if the input is actually a number, so it could handle errors better. It could also include shortcuts for numbers like those ending in 0 or 5, which are obviously not prime (except for 5 itself). Adding a bit more explanation about why it skips even numbers or only checks up to the square root would also help beginners understand it better, I believe.
Finally, I would have expected the code to have some example usage tests, the same way it gave us those for the Python code in the test before.
Let’s move now to logical reasoning tests.
I am going to test a classic puzzle:
"A man has to cross a river with a wolf, a goat, and a cabbage. His boat can only carry himself and one other thing. If left alone, the wolf would eat the goat, and the goat would eat the cabbage. How can he get everything across safely?"
I would expect the model to provide the following answer:
But let’s see how it handles the thought process, as I am not sure what to expect!
I need to truncate this output, too, for readability:
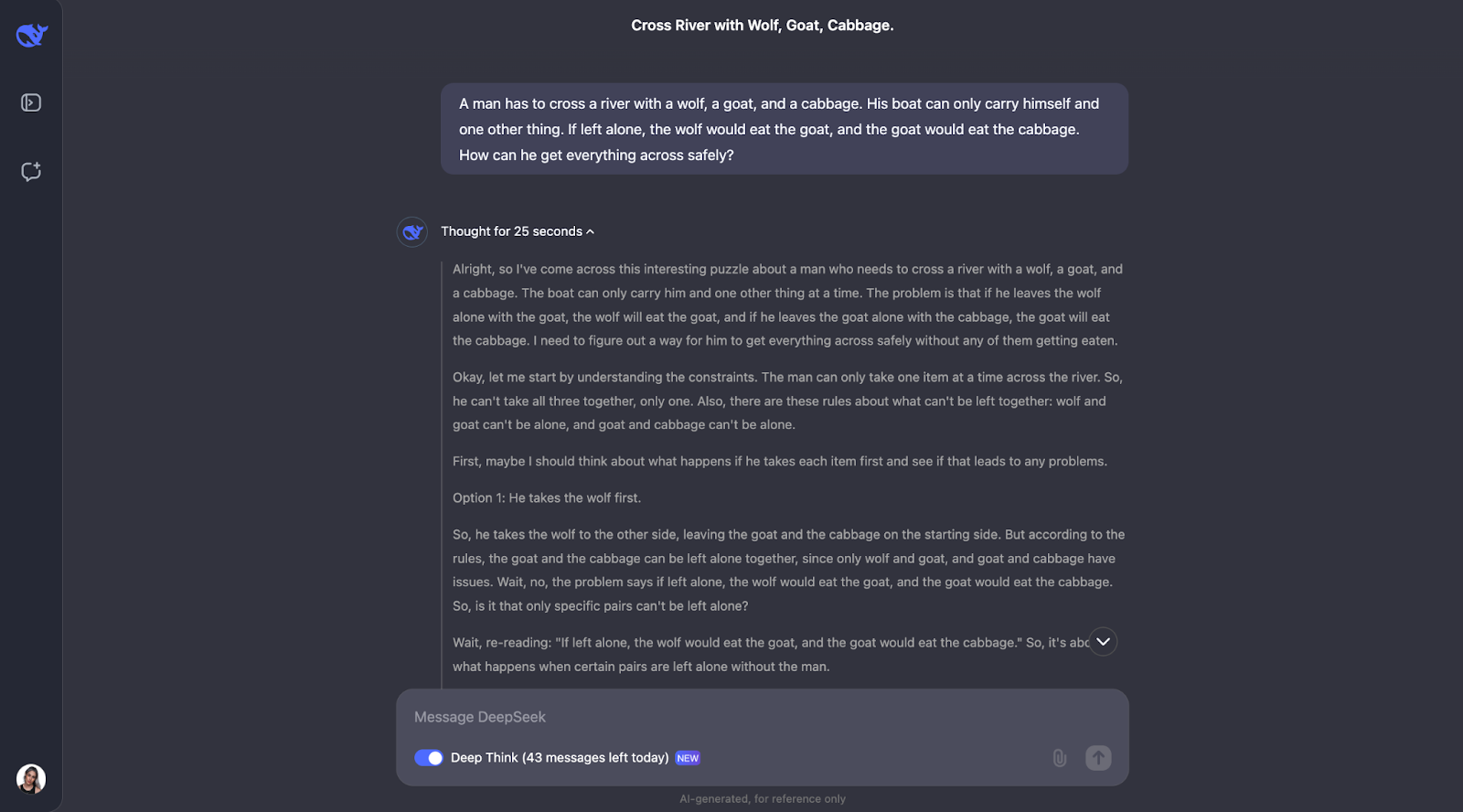
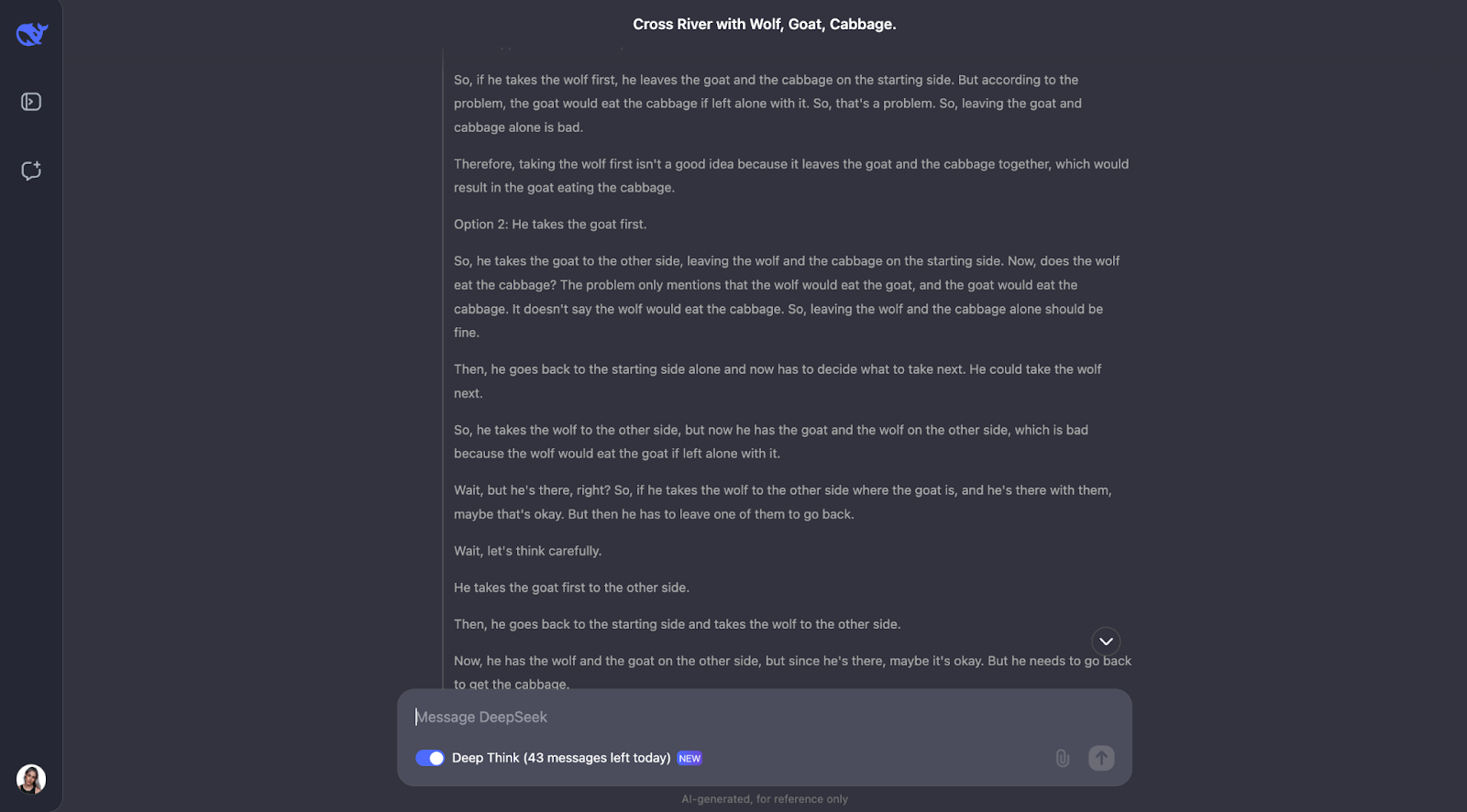
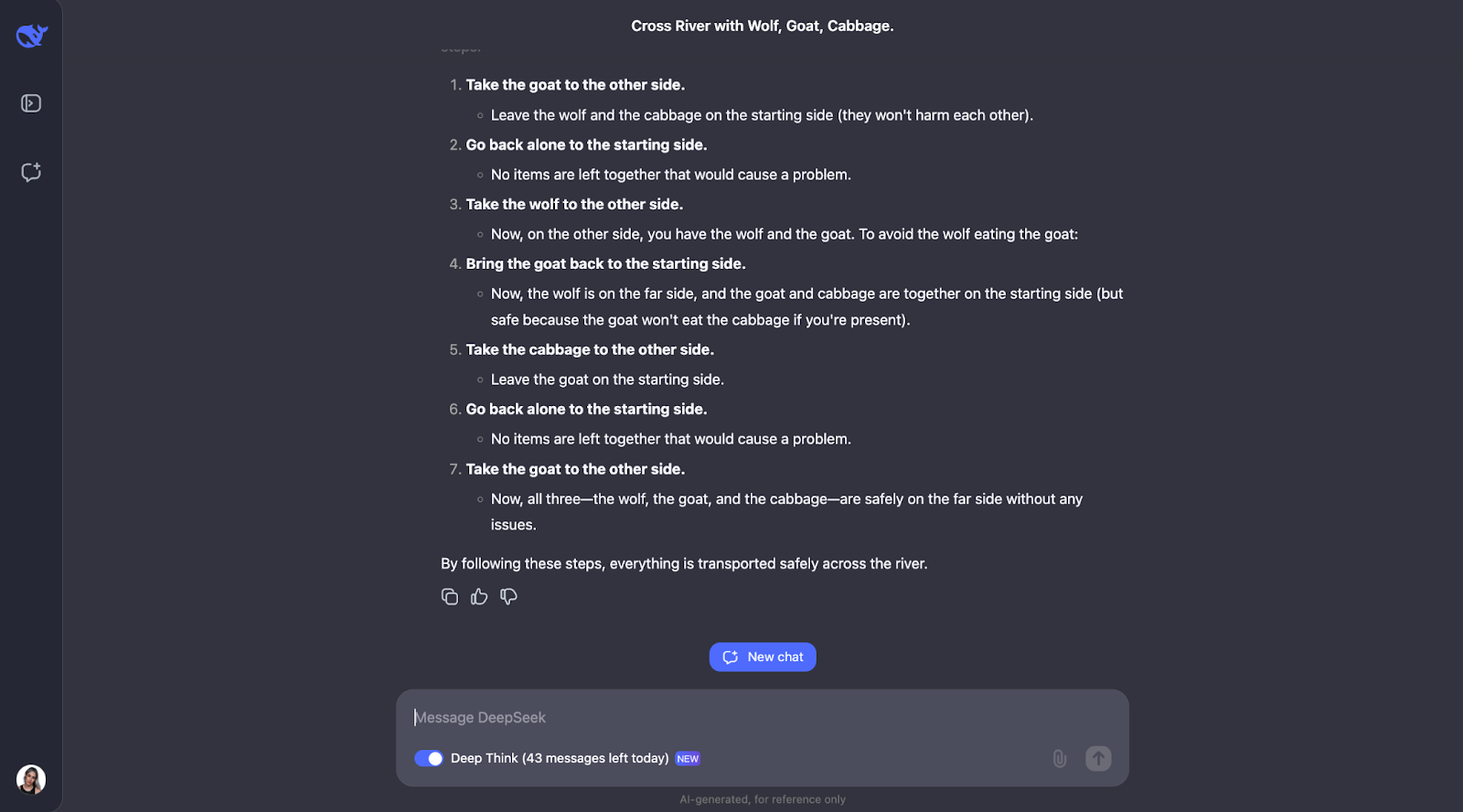
The model does a great job of solving this classic river crossing puzzle. It thinks carefully about the rules and checks different possibilities. It understands that some pairs, like the wolf and the goat or the goat and the cabbage, can’t be left alone. It also reviews the constraints at the start. Starting from this, it looks at what would happen if the man takes each item across the river first and works out if it creates any problems.
What I find really nice is how the model adjusts its plan when something doesn’t work. For example, when it tries taking the wolf first, but realizes that this causes trouble, and then rethinks the steps. This trial-and-error method feels very similar to how we, as humans, might solve the puzzle ourselves.
In the end, the model comes up with the right solution and explains it in a clear, step-by-step way.
Let’s try another one:
“You have 12 balls, all identical in appearance. One ball is either heavier or lighter than the rest. Using a balance scale, find the odd ball and determine whether it's heavier or lighter in just three weighings.”
This classic logic puzzle tests the model's ability to come up with an optimal strategy using deductive reasoning. Let’s see what happens. The output was very-very long this time, so I’ll need to jump straight to the answer:
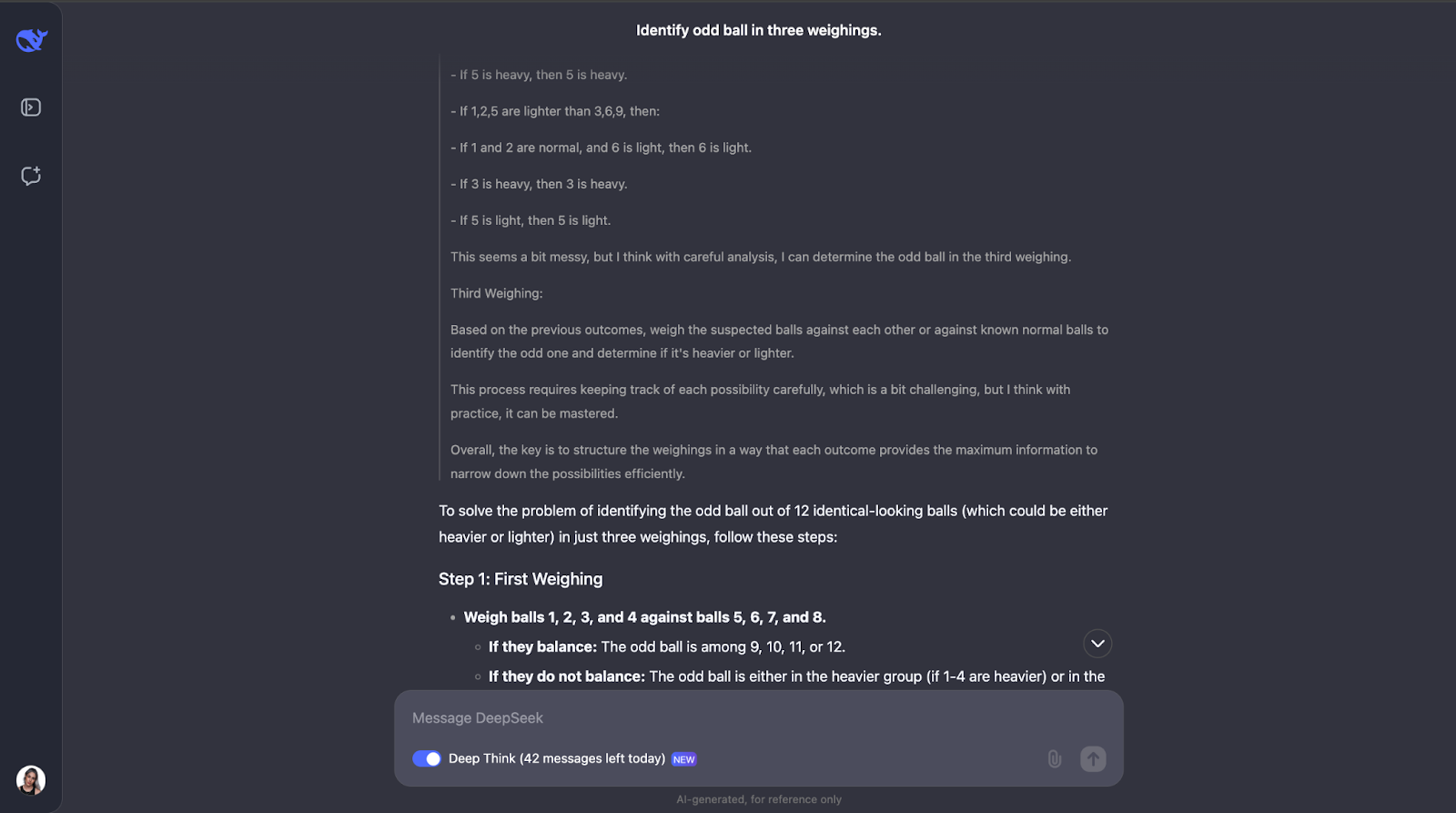
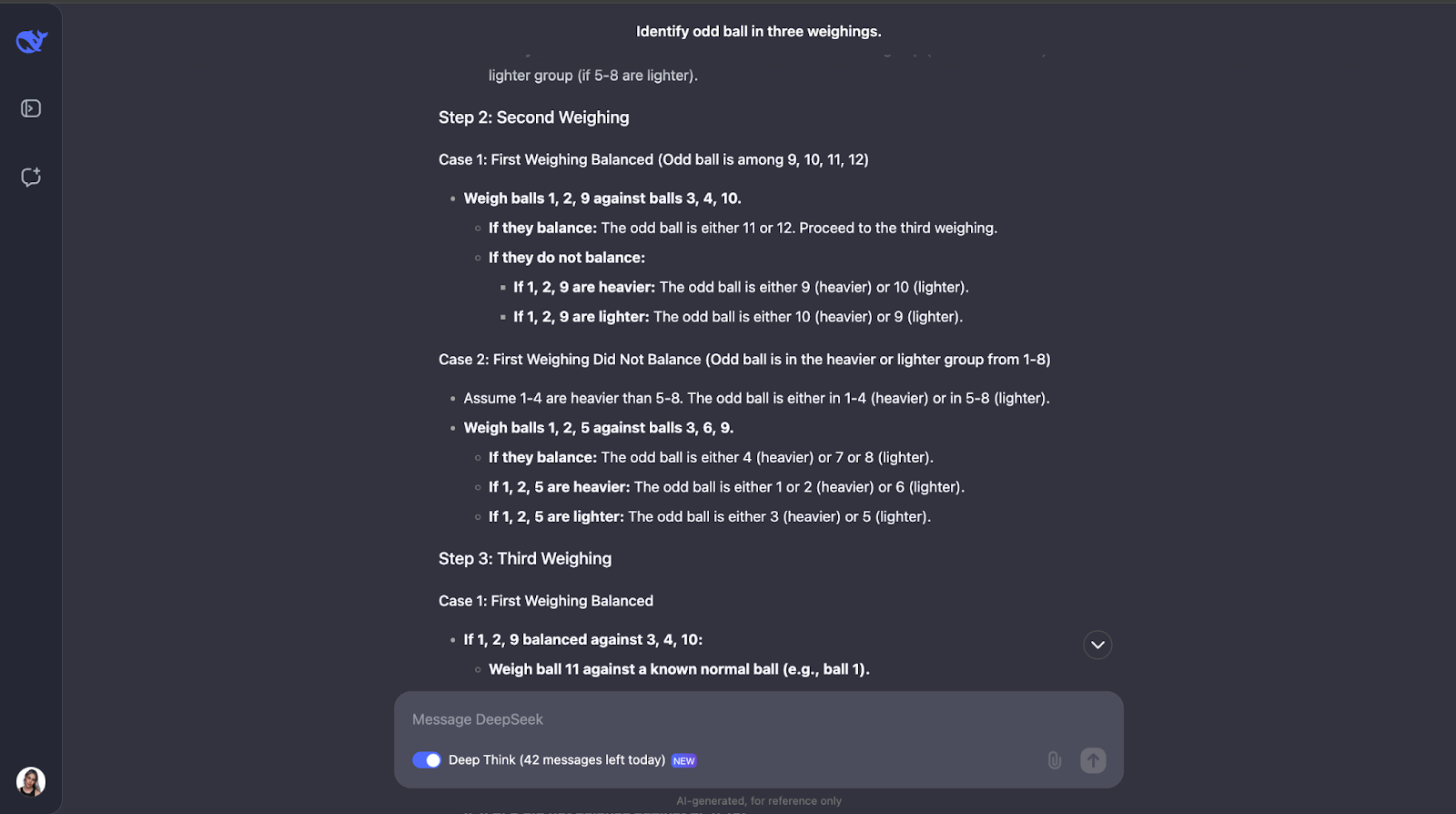

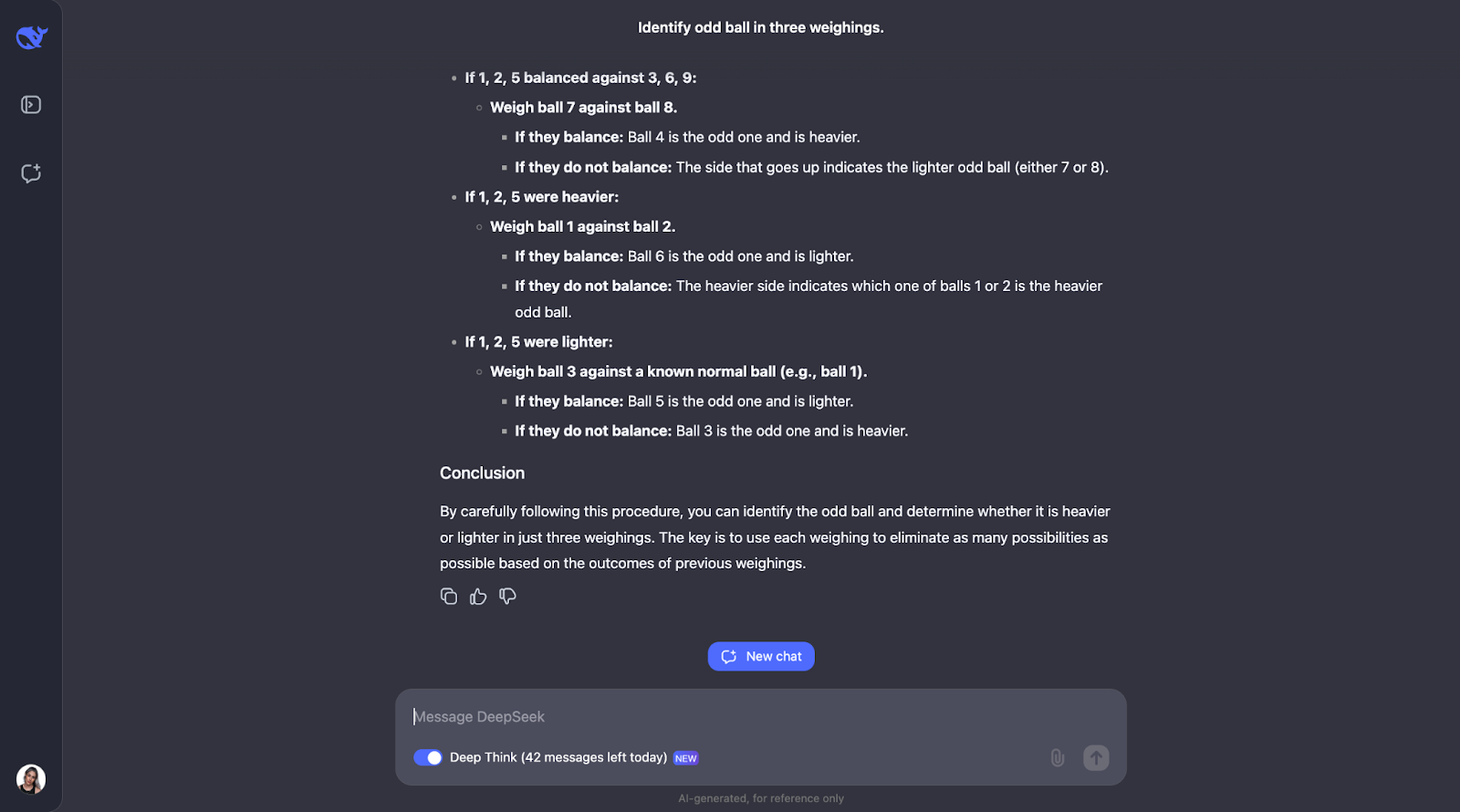
Another one in which I have totally underestimated the length of the output! The model realizes that solving this puzzle needs careful planning because you only get three tries. It also computes the number of outcomes and possibilities.
The model’s approach is smart because every weighing eliminates as many possibilities as possible. It plans for all outcomes—whether the scale balances or tips—and adjusts the next step based on what happens. It is very detailed but the steps are clear and logical, which makes it very easy to follow, even if its lengthy,
One thing I really liked is that when the approach starts getting a bit too complex, it applies a more systematic or simpler approach. However, I think for problems like this, where you need to keep track of different cases, outcomes, and possibilities, adding a diagram or chart might help people visualize the train of thought and understand the output better.
In this section, I will compare DeepSeek to other models like o1-preview and GPT-4o in terms of performance on different benchmarks. Each one focuses on a different skill, so we can see which models are best at what. Let’s see the benchmarks measured by DeepSeek:
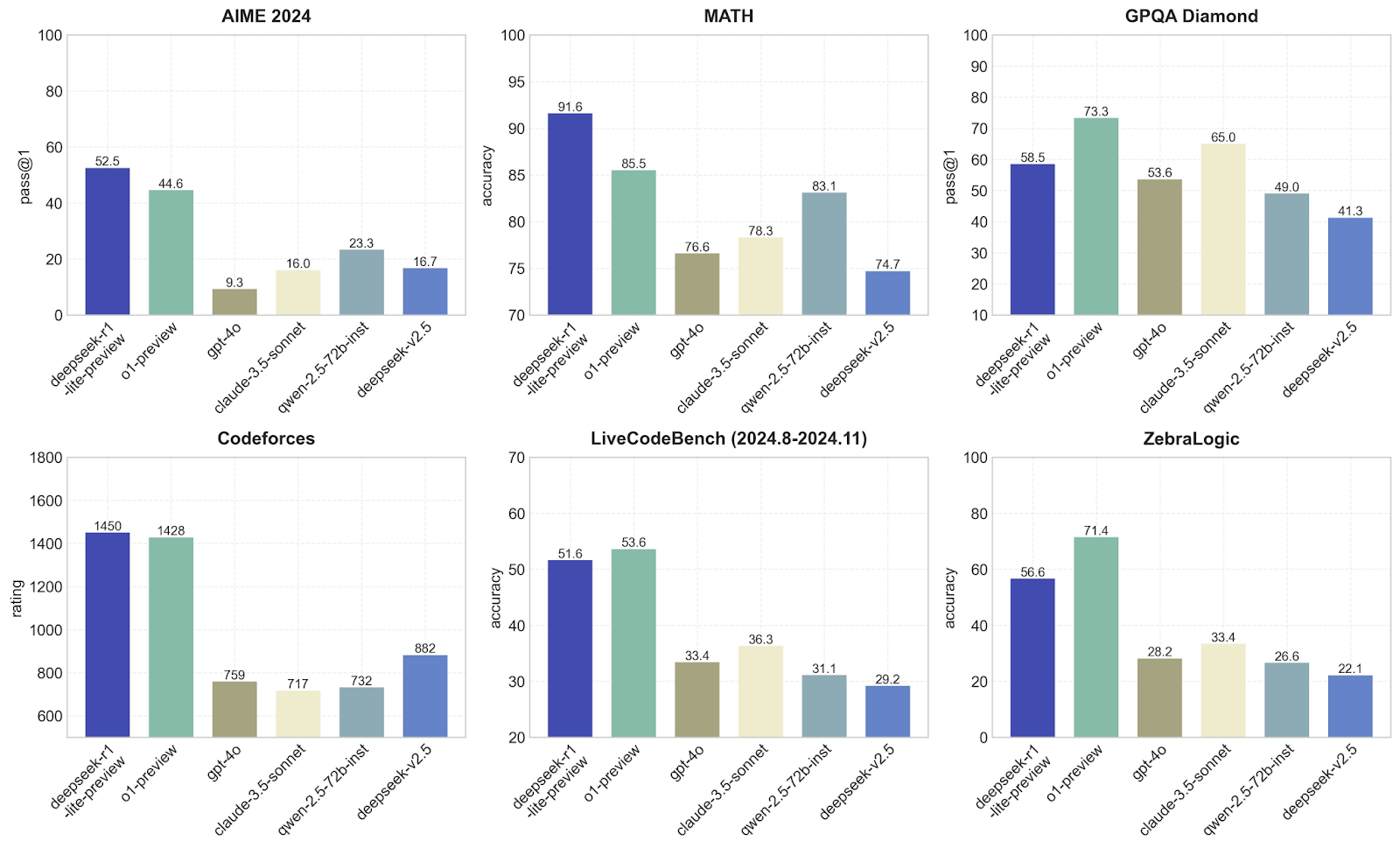
DeepSeek-r1-lite-preview is clearly the best here, with a pass@1 of 52.5, followed by o1-preview at 44.6. Other models, like GPT-4o and claude-3.5-sonnet, perform much worse, with scores below 23. This suggests that the DeepSeek-r1-lite-preview model is quite good at handling the kind of advanced math or logic problems specific to the AIME benchmarks, which I am not surprised after the tests I have performed.
DeepSeek-v1 dominates again with an impressive accuracy of 91.6, far ahead of o1-preview (85.5) and much better than other models like GPT-4o, which struggle to hit 76.6. This shows that DeepSeek is great at solving math problems, which confirms my hypothesis from the empirical evidence in the tests I performed before–no surprises so far!
Here, o1-preview does better than DeepSeek-v1, with a pass@1 of 73.3 compared to 58.5. Other models, like GPT-4o, fall behind at 53.6. This suggests that o1-preview is better suited for tasks that involve answering questions or solving problems based on logical reasoning. DeepSeek still performs solidly but is not as good at o1-preview.
For competitive programming, DeepSeek-v1 (1450) and 01-preview (1428) are almost tied for the top spot, while other models like GPT-4o only score around 759. As expected, this shows that these two models are excellent at understanding and generating code for programming challenges.
This tests coding abilities over time, and o1-preview slightly edges out DeepSeek-v1 (53.6 vs. 51.6). Other models, like GPT-4o, fall far behind at 33.4. Again, this shows that both DeepSeek and 01-preview are well-suited for coding but that 01-preview is a bit better at these tasks.
o1-preview takes the lead here with a 71.4 accuracy, compared to 56.6 for DeepSeek-v1. Other models do much worse. This shows that o1-preview is better at handling abstract logic tasks like ZebraLogic, which require more creative or out-of-the-box thinking, which aligns with the results I got from the tests as creativity was definitely not DeepSeek-v1’s forte.
These graphs corroborate that DeepSeek-v1 is amazing at math and programming challenges. I would say that o1-preview is more balanced and performs well across a wider range of tasks, which makes it more versatile.
Let’s look now at this graph:
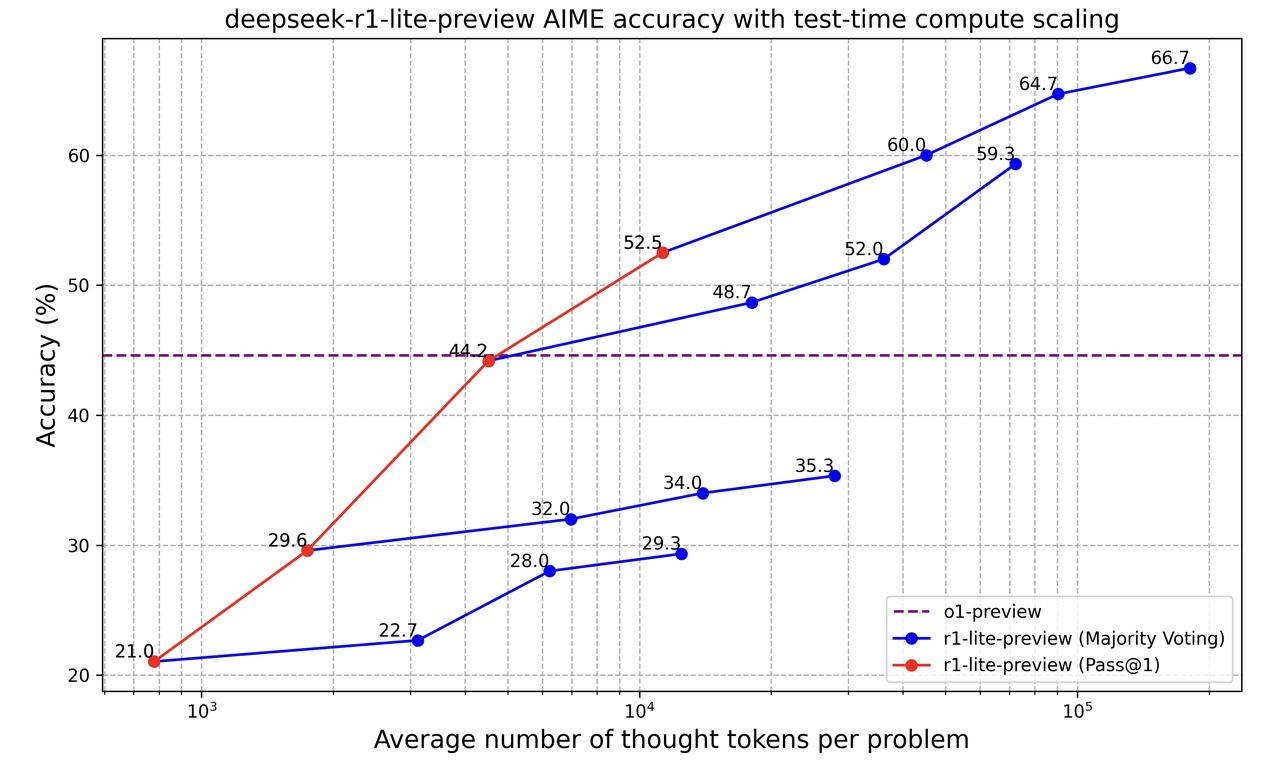
This graph shows how the "deepseek-r1-lite-preview" model gets better at solving problems as it processes more information (measured by the number of "thought tokens" it uses). It compares two ways the model's accuracy is measured:
The dashed purple line represents the o1-preview model that has a steady accuracy. At first, o1-preview is better, but as DeepSeek r1-lite-preview is allowed to use more thought tokens, it overtakes o1-preview and becomes much more accurate.
So basically, this graph shows that letting DeepSeek r1-lite-preview think more and try multiple times improves its accuracy.
Is DeepSeek-r1-lite-preview better than OpenAI’s o1-preview? Well, it depends on the task. I'd say yes for math and coding problems. For logical reasoning, it depends on the task.
What really surprised me was how it reasoned through some of the tests. It really made me think about what it actually means for a model to “think” and how it comes up with the reasoning approaches.
If you’re curious about this model, why not test it yourself? Try it on the tasks you’re interested in and see how it performs—you might find it just as surprising as I did!
Learn AI with these courses!
Track
Course
Course
blog
Alex Olteanu
8 min
blog
Alex Olteanu
8 min
blog
Dr Ana Rojo-Echeburúa
8 min
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
