Cursus
Principes fondamentaux de l'IA
10 h
DeepSeek-R1-Lite-Preview est un outil d'IA, similaire à ChatGPTcréé par la société chinoise DeepSeek. L'entreprise a annoncé ce nouveau modèle le X le 20 novembre (lien twitter) et a partagé quelques détails sur une page de documentation.
DeepSeek-R1-Lite-Preview est conçu pour être très performant dans la résolution de problèmes de raisonnement complexes en mathématiques, en codage et en logique. Il vous montre son raisonnement étape par étape afin que vous puissiez comprendre comment il aboutit à des réponses, ce qui permet aux gens de lui faire davantage confiance.
Vous pouvez l'essayer gratuitement sur leur site web, chat.deepseek.commais vous êtes limité à 50 messages par jour dans son mode avancé appelé "Deep Think". DeepSeek prévoit également de partager certaines parties de cet outil avec le public afin que d'autres puissent l'utiliser ou le développer.
Vous pouvez commencer à utiliser DeepSeek-R1-Lite-Preview en suivant ces deux étapes :
Pour voir ce que DeepSeek-R1-Lite-Preview peut faire, mettons-le à l'épreuve ! Je vais vous présenter une série de défis qui mettent en évidence ses capacités de raisonnement, en commençant par la simple mais célèbre question de la fraise : Combien de fois la lettre "r" se retrouve-t-elle dans "fraise" ?"
Cette question peut paraître simple, mais les LLM (même les GPT-4o) ont toujours eu du mal à y répondre correctement - ils répondent généralement qu'il n'y a que deux occurrences de la lettre"r".
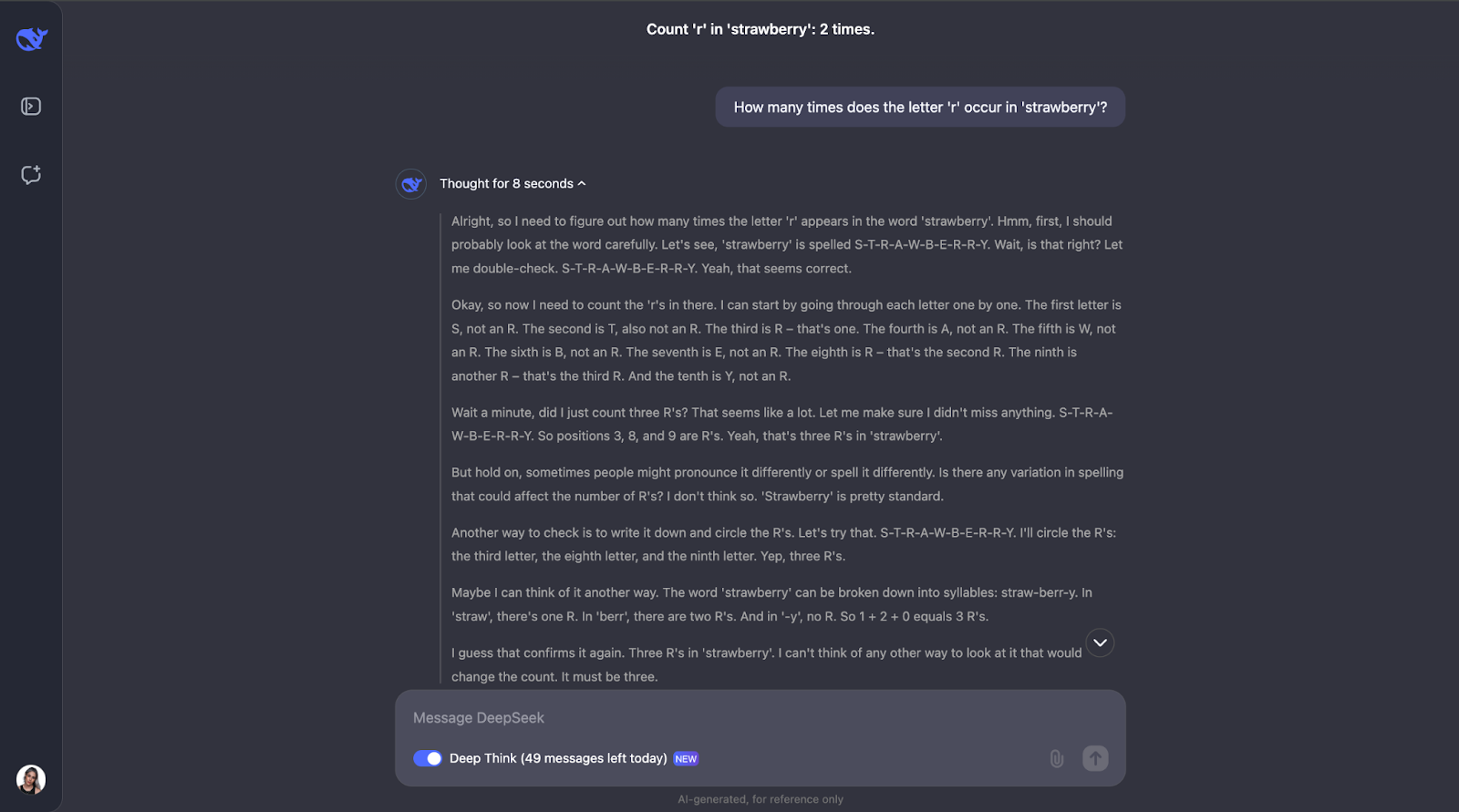
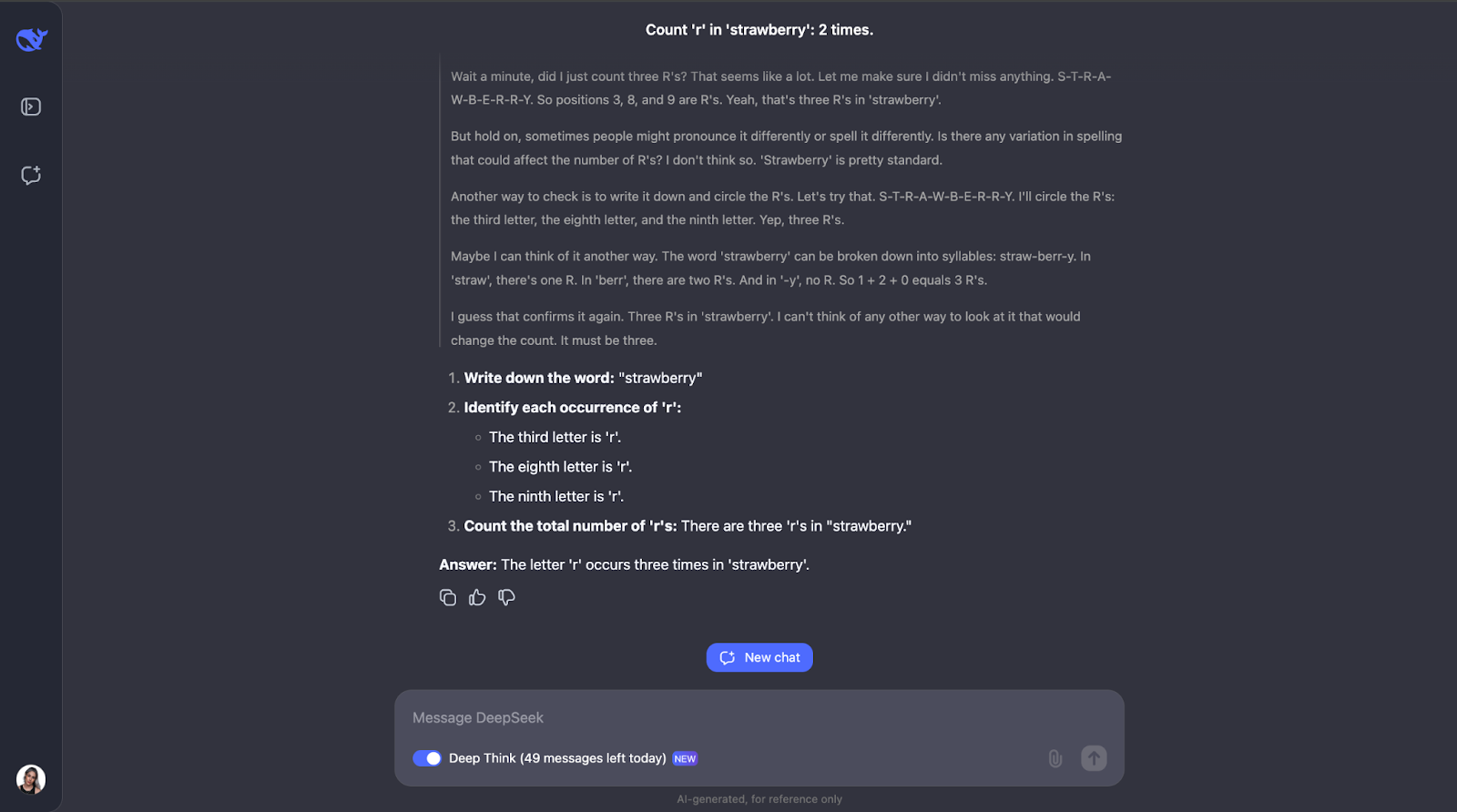
Wow, ok - Je ne m'attendais pas à un processus de raisonnement aussi long pour ce qui semble être une tâche simple. Je pensais qu'après avoir compté la lettre "r" et identifié sa position dans le mot, il se serait arrêté là. Mais ce qui est intéressant pour moi, c'est que cela ne s'est pas arrêté là. Il a revérifié le comptage à plusieurs reprises et a même pris en compte des éléments tels que la prononciation ou l'orthographe différente du mot - ce qui me semble un peu redondant, en particulier pour la partie relative à la prononciation. Mais cela montre à quel point il est prudent et réfléchi ! Il a également expliqué chaque étape afin que je puisse suivre son processus de réflexion et voir comment il est parvenu à la réponse.
Je testerai DeepSeek-R1-Lite-Preview sur trois problèmes mathématiques.
Étant donné que DeepSeek prétend être très performant en matière de raisonnement mathématique, commençons par un problème géométrique simple.
"Si un triangle a des côtés de longueur 3, 4 et 5, quelle est sa surface ?
Ce problème nécessite la connaissance du théorème de Pythagore et de la formule de Héron. Je m'attends à ce que DeepSeek-R1-Lite-Preview montre son travail, peut-être comme ceci :
Voyons ce qu'il en est!
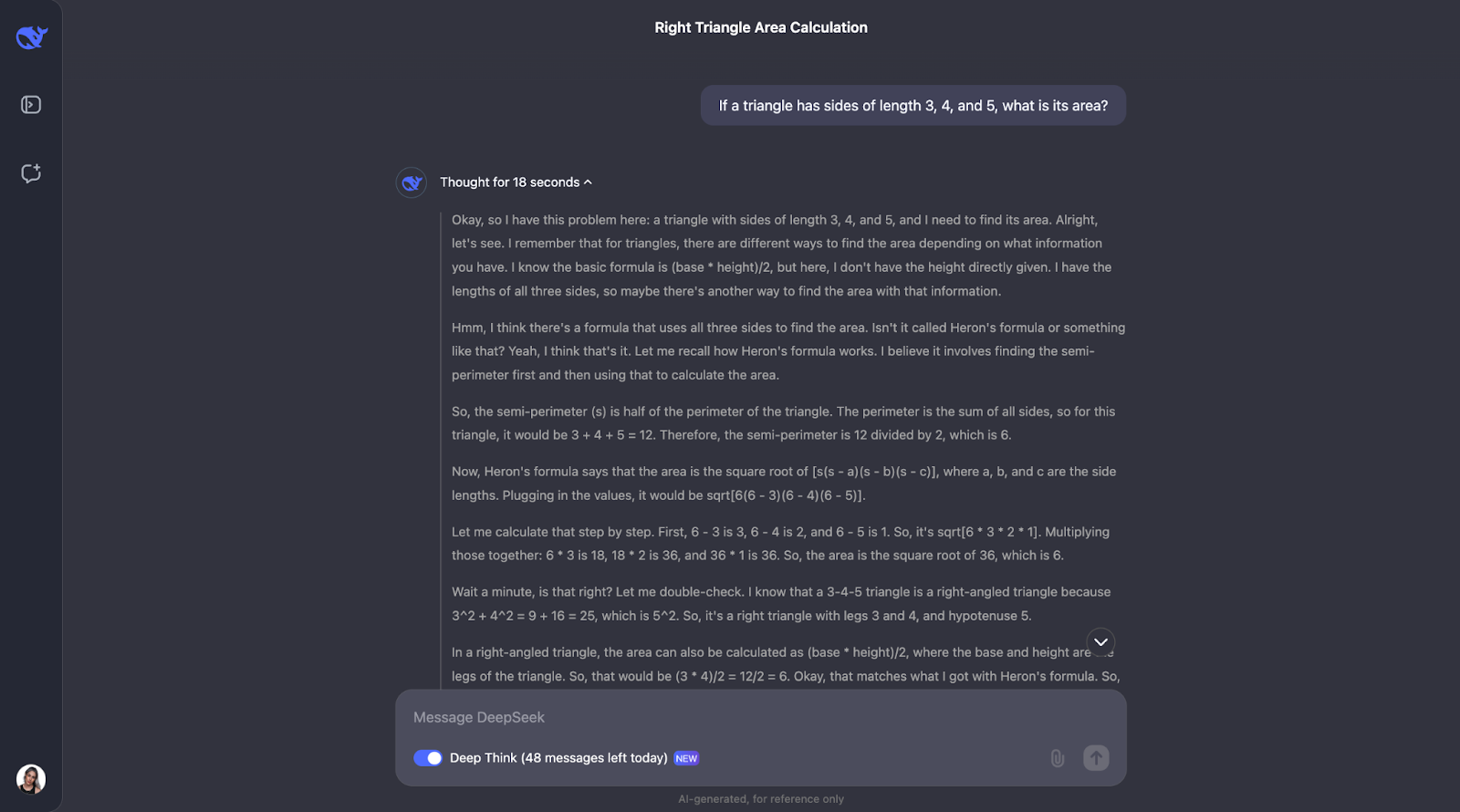
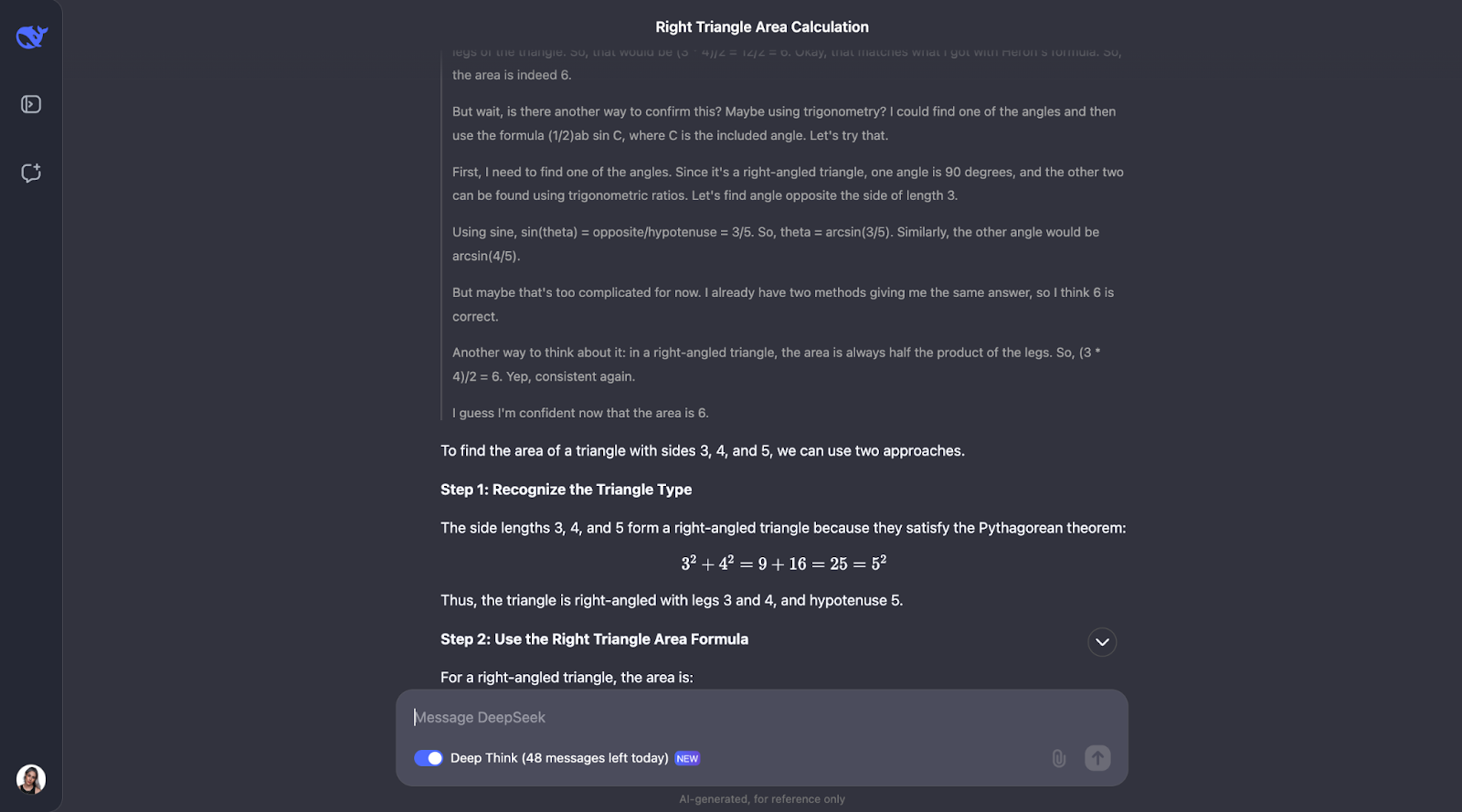
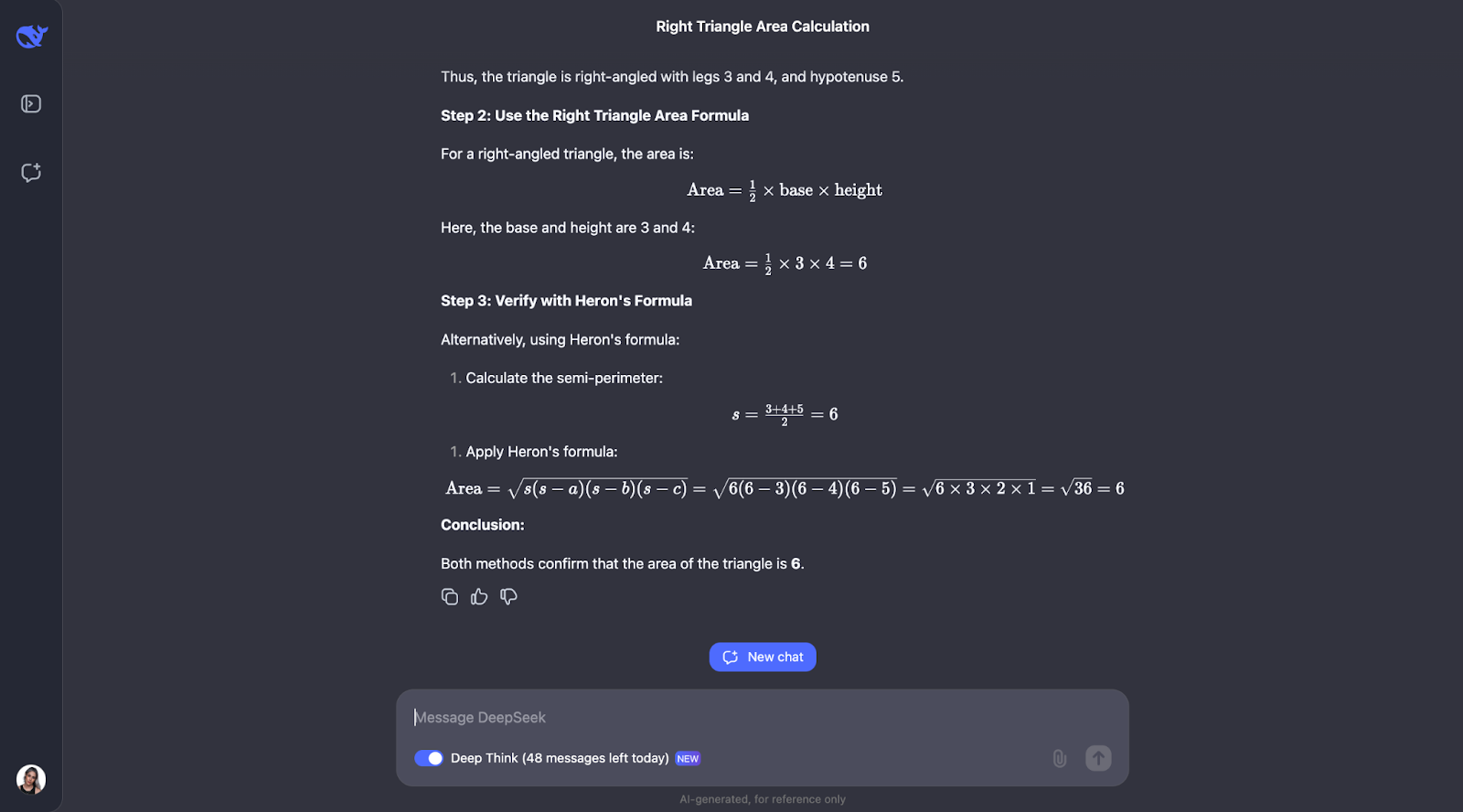
Okay, il est intéressant de noter qu'il effectue les vérifications que j'avais prédites, mais dans un ordre différent. Il a également envisagé d'utiliser la trigonométrie en calculant les angles et en essayant une autre formule. Je pense qu'il est très intéressant que, finalement, il ait décidé que cela n'était pas nécessaire puisque les deux premières méthodes avaient déjà confirmé la réponse.
L'explication et le résultat étaient particulièrement clairs et faciles à suivre, ce qui me fait penser qu'il s'agirait d'un modèle fantastique à intégrer dans l'assistant d'un étudiant en mathématiques, par exemple. Pour ce cas d'utilisation particulier, le processus de réflexion pourrait peut-être être montré en premier, et l'étudiant pourrait interagir avec lui, en reconnaissant s'il l'a compris ou non, avant de passer à la réponse finale.
Passons à un test de mathématiques plus complexe pour voir s'il y a une différence dans les performances et le processus de réflexion.
"Prouvez que la somme des réciproques des nombres de Fibonacci converge vers une valeur finie".
Ce test met à l'épreuve la compréhension du modèle de concepts mathématiques avancés, tels que la convergence des séries et les propriétés des nombres de Fibonacci. Essayons-le ! Pour des raisons de lisibilité, je ne publierai que la première et la dernière partie de la réponse (mais n'hésitez pas à essayer vous-même avec la même promotionpt) :
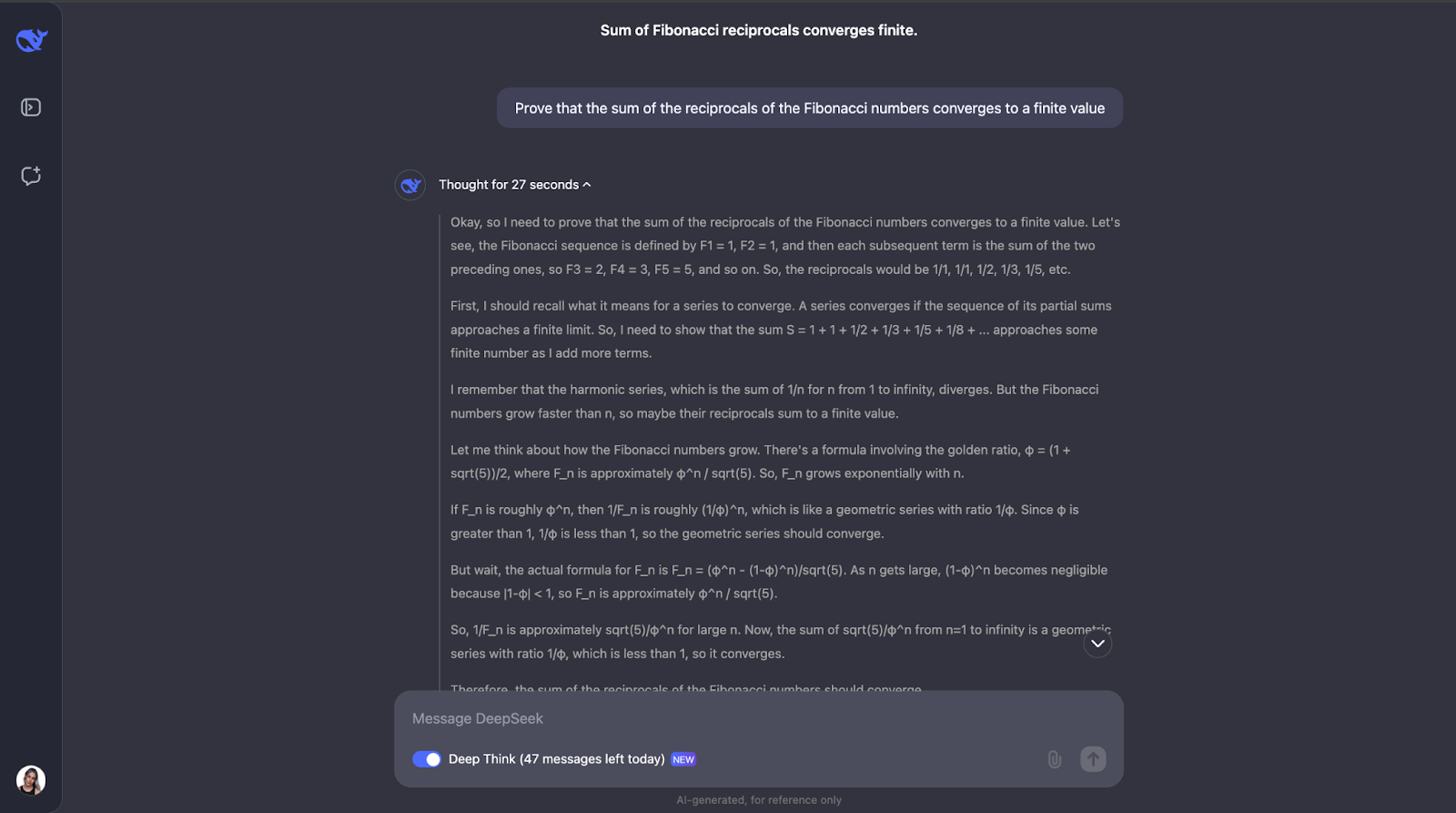
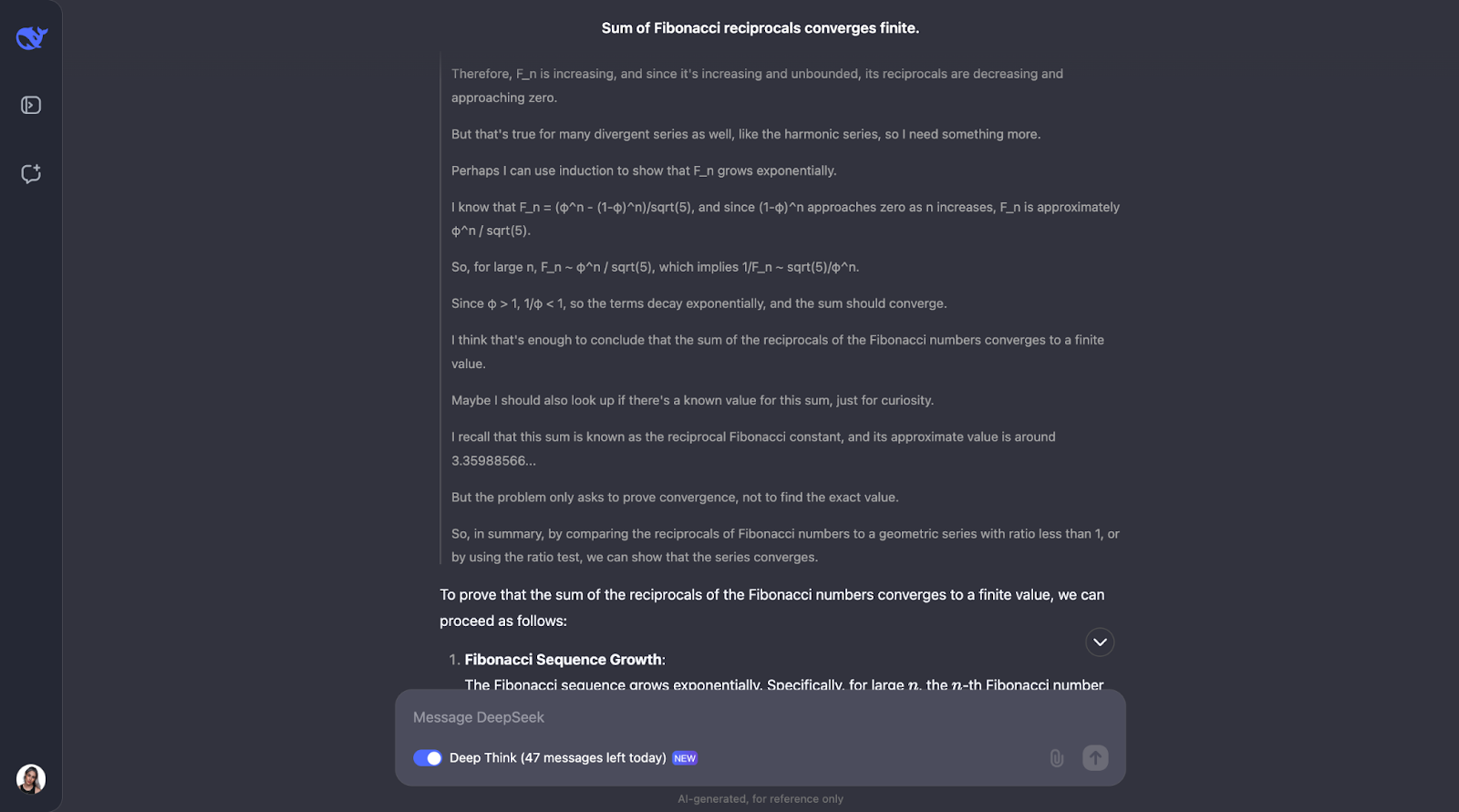

D'accord,. C'est une excellente piste de réflexion. J'aime beaucoup la façon dont on s'assure d'abord de la compréhension des concepts clés, tels que les réciproques et la convergence. Ensuite, DeepSeek-R1-Lite-Preview a abordé ce problème en examinant la façon dont les nombres de Fibonacci croissent et en utilisant un test de comparaison, qui est un moyen courant de vérifier si une série converge ou non.
Il comparait les réciproques des nombres de Fibonacci à une série géométrique. Comme les réciproques des nombres de Fibonacci diminuent encore plus vite qu'une série géométrique dont le rapport commun est inférieur à 1, le modèle a conclu que la somme des réciproques converge également vers une valeur finie. Pour plus de certitude, elle a utilisé ce que l'on appelle le test du ratio.
Ce test vérifie si la limite du rapport des termes consécutifs est inférieure à 1. Si c'est le cas, la série converge. Le modèle a calculé ce rapport pour les réciproques des nombres de Fibonacci et a trouvé qu'il est effectivement inférieur à 1.
Il mentionne même qu'il existe une valeur connue pour cette somme, appelée la constante réciproque de Fibonacci, qui est d'environ 3,3598. Mais pour ce problème, nous avions juste besoin de savoir que la somme est finie, et non de savoir exactement ce qu'elle est. J'aime beaucoup la façon dont la solution est présentée dans le résultat. Il est clair et progressif.
Jusqu'à présent, je suis impressionné par les tâches mathématiques.
Je vais essayer un problème de géométrie différentielle - simplement parce que mon doctorat porte sur ce domaine et que je n'ai pas pu résister à l'envie de faire un petit test. Rien de très complexe, juste un exercice classique que l'on peut rencontrer en mathématiques au niveau licence.
"Considérons une surface S dans R³ paramétrée par
φ(u,v) = (u cos v, u sin v, ln u)
pour u > 0 et 0 ≤ v < 2π.
a) Calculez la première forme fondamentale de S.
b) Déterminez si S est une surface minimale.
c) Trouvez la courbure gaussienne K et la courbure moyenne H de S."
Ce que j'attendrais de DeepSeek-R1-Lite-Preview, c'est qu'il fournisse une solution étape par étape, en montrant tous les calculs et en expliquant la signification de chaque résultat ainsi que les définitions des principaux concepts tels que la forme fondamentale, la surface minimale et les différentes courbures.
Pour que ce blog reste lisible, je ne montrerai que la première et la dernière partie de la réponse, mais je vous encourage à essayer le message vous-même :
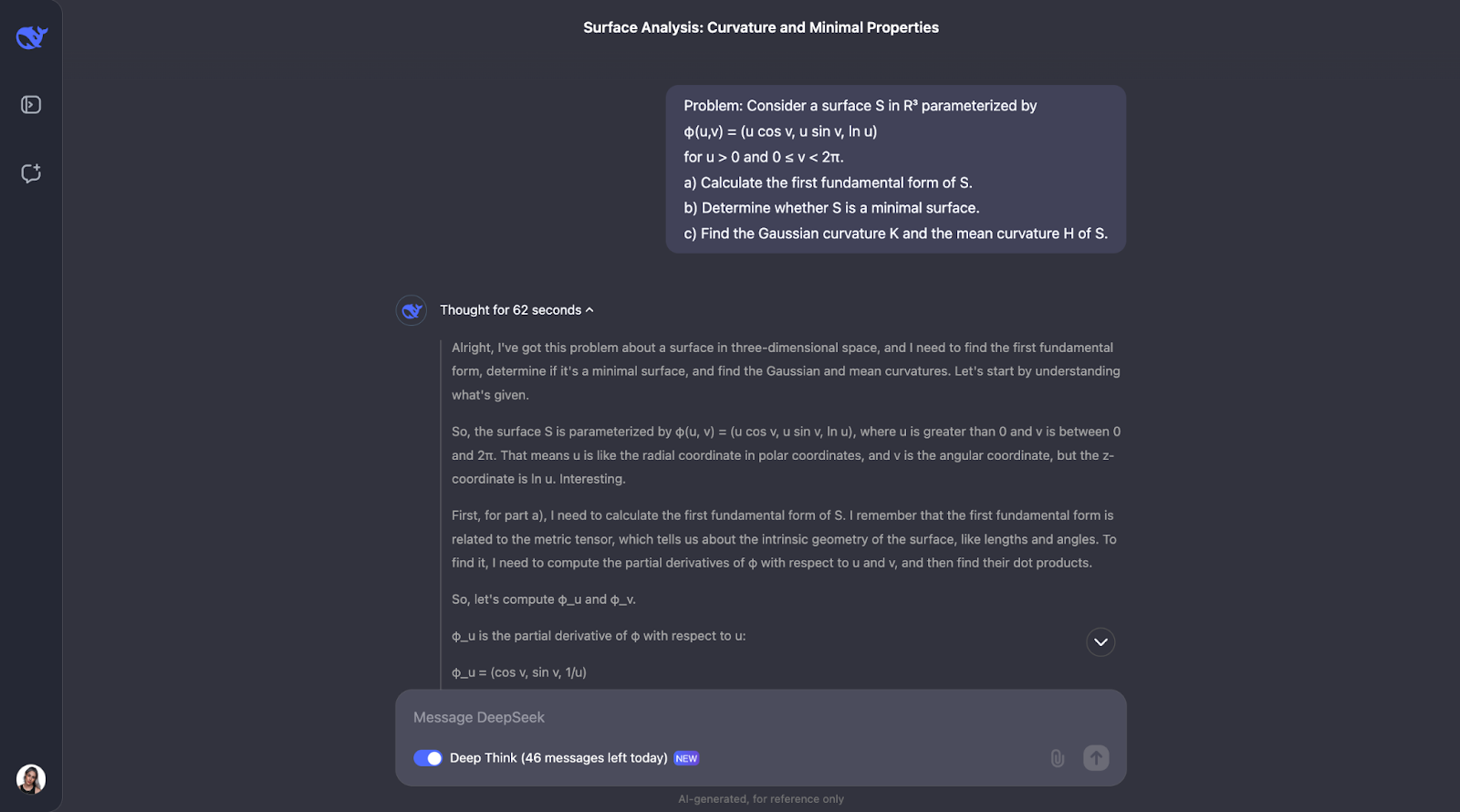
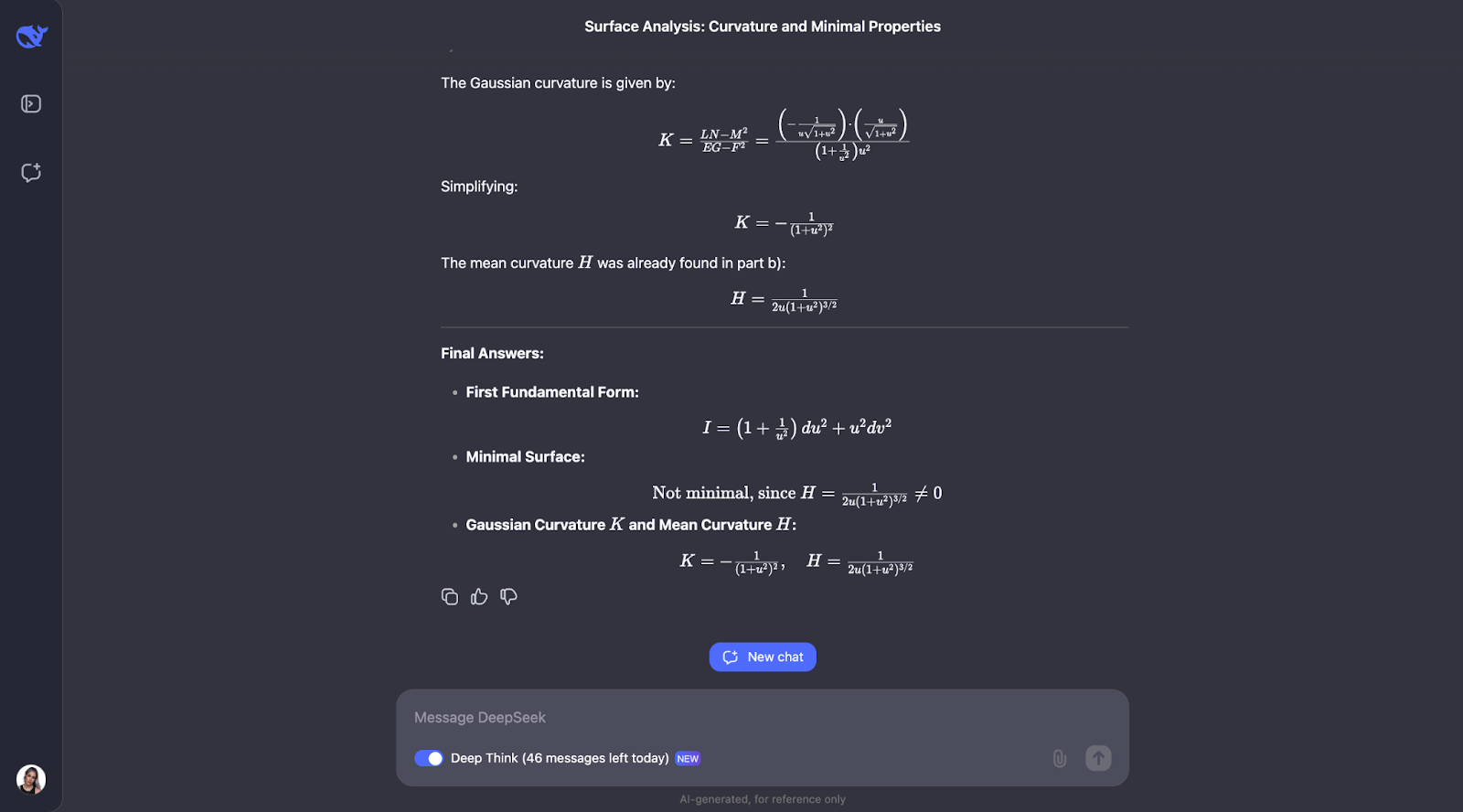
L'approche sétape par étape utilise des formules géométriques bien connues et les applique directement, ce qui rend le raisonnement facile à suivre. Cependant, j'aurais attendu qu'il vérifie sa propre compréhension des principaux concepts du problème, ce qui ne fait pas partie du train de pensée. Pour la partie B, il adopte une approche alternative et identifie que la surface concernée est une surface de révolution, ce qui est une bonne chose.
Il y a aussi un moment où il commente la rotation et se rend compte qu'il a déjà N, le vecteur normal, ce qui pourrait entrer en conflit avec la notation du coefficient de la deuxième forme fondamentale. J'aurais aimé que l'on suggère une meilleure notation, car utiliser la même lettre pour deux choses n'est pas une bonne pratique !
Lorsqu'il calcule la courbure moyenne, il remarque qu'elle n'est pas nulle et se demande si le calcul est correct. Par souci d'exhaustivité, il essaie une autre méthode pour revérifier son travail.
Une fois de plus, les résultats sont très clairs et faciles à suivre. Dans tous ces exemples, il est impressionnant de constater qu'il revérifie systématiquement les calculs effectués à l'aide de différentes méthodes. Le processus de réflexion est toujours détaillé, logique et facile à comprendre !
Passons maintenant aux tests de codage.
Le premier que je vais tester est le suivant :
" Implémentez une fonction en Python qui trouve la sous-chaîne palindromique la plus longue dans une chaîne donnée. La fonction doit avoir une complexité temporelle meilleure que O(n^3)."
J'essaie d'évaluer la capacité du modèle à concevoir des algorithmes efficaces et à les mettre en œuvre dans le code. Je m'attends à une solution utilisant la programmation dynamique ou l'algorithme de Manacher, avec une explication claire de l'approche et de la complexité temporelle l'analyse.
La sortie est très, très longue, et je ne montre que la première et la dernière partie :
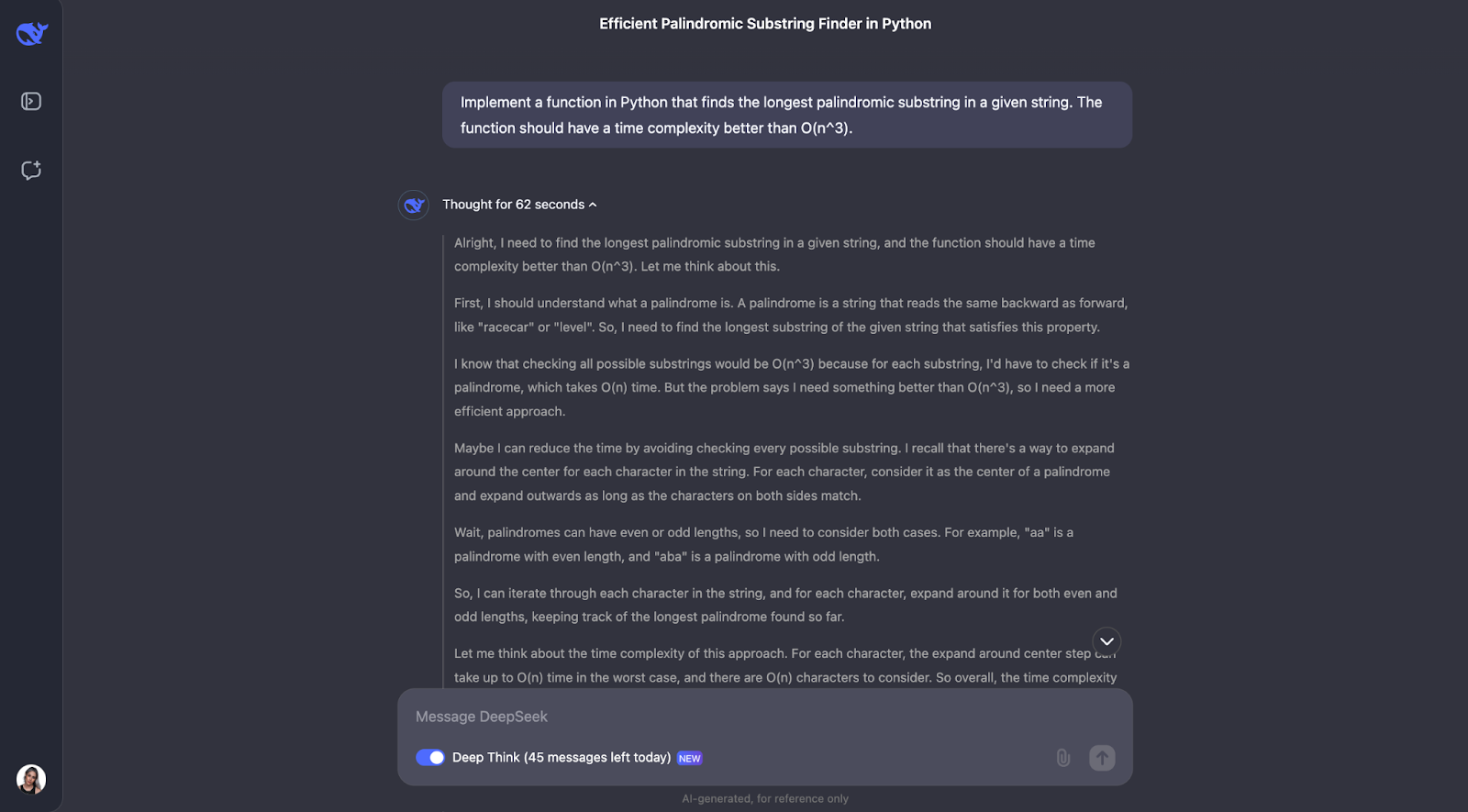
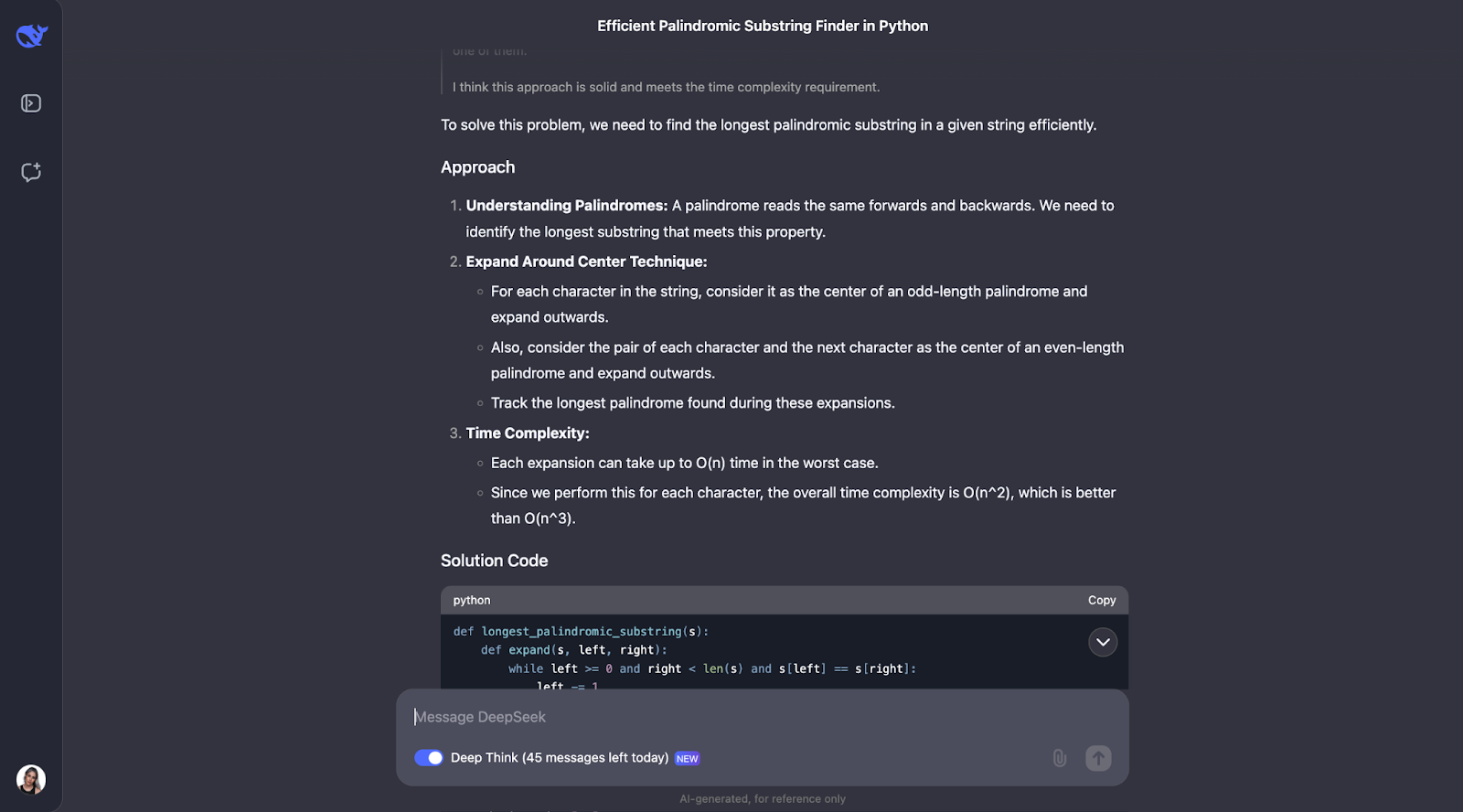
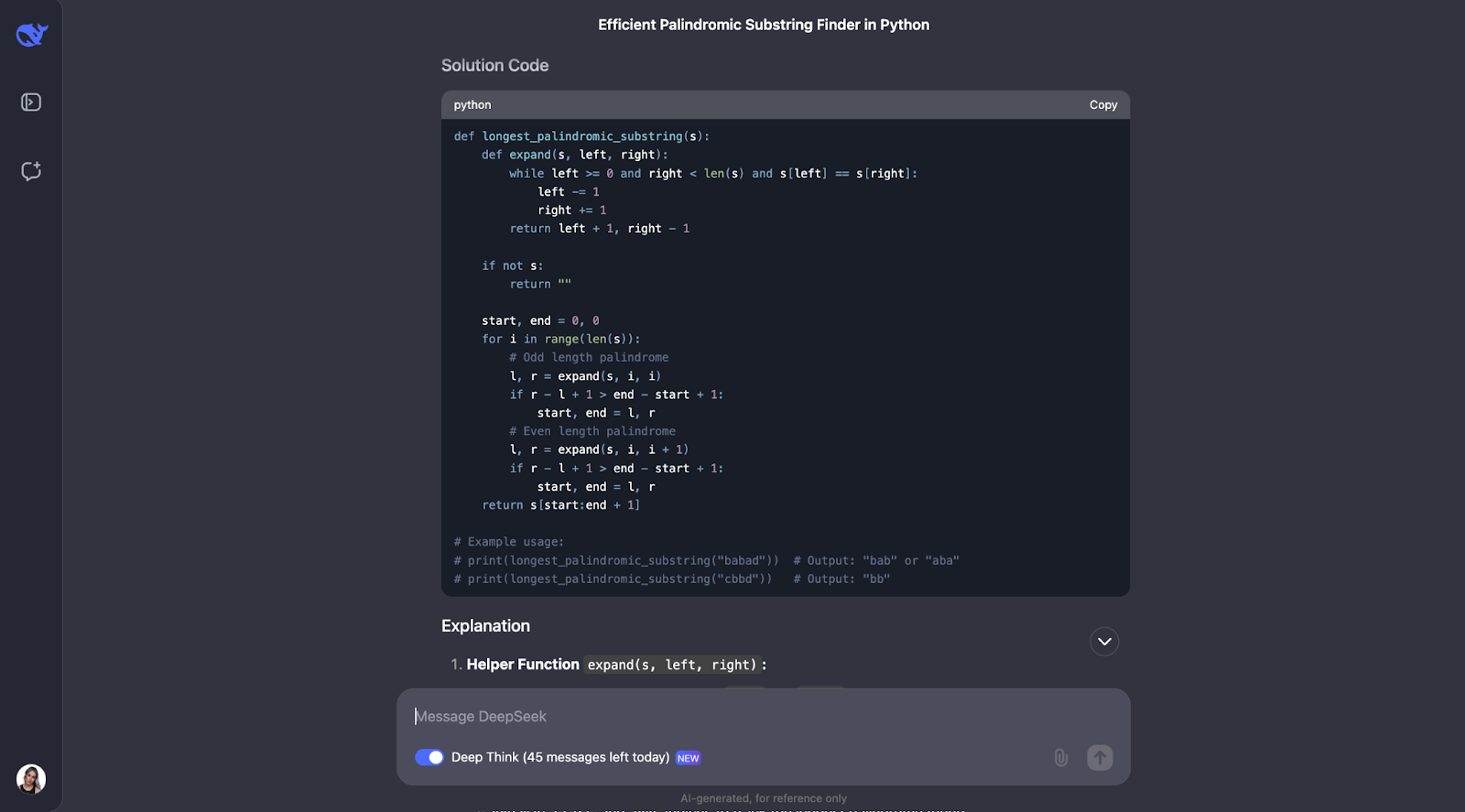
Je pense que le modèle a très bien résolu le problème de la recherche de la plus longue sous-chaîne palindromique. Son approche était intelligente, efficace et clairement expliquée.
Au lieu de forcer brutalement toutes les sous-chaînes possibles, ce qui serait lent, il a utilisé une technique astucieuse d'"expansion autour des centres". Cette méthode a permis de traiter à la fois les palindromes de longueur impaire comme "aba" et les palindromes de longueur paire comme "abba". Il a enregistré le plus long palindrome qu'il a trouvé au fur et à mesure. Le résultat est un algorithme qui s'exécute en O(n^2) temps, beaucoup plus rapidement qu'une solution O(n^3).
Ce qui m'impressionne le plus dans cette réponse, c'est la clarté avec laquelle elle est présentée. DeepSeek a décomposé le problème en étapes compréhensibles, a expliqué son processus de réflexion en détail et a même inclus des exemples pratiques. Par exemple, il a montré comment l'algorithme se développe autour du centre de "racecar" ou de "abba" pour trouver le palindrome correct. La fonction d'aide pour l'expansion autour d'un centre était particulièrement intéressante à mon avis - elle a rendu le code modulaire et facile à suivre.
Cela dit, j'aurais espéré qu'il prenne en compte l'algorithme de Manacher, qui est une solution O(n) plus rapide. Il est certainement plus complexe à mettre en œuvre, mais il est utile dans les cas où les performances sont critiques, et j'aurais attendu du modèle qu'il le signale.
J'ai également remarqué que la sortie n'expliquait pas explicitement comment l'algorithme traitait les cas particuliers, tels qu'une chaîne vide ou une chaîne contenant tous les caractères identiques (par exemple, "aaaa"). Ces cas fonctionneraient, mais j'aurais attendu qu'il en soit au moins question.
Enfin, je pense qu'il est bon de commenter les résultats attendus pour les exemples d'utilisation. Cependant, lorsque j'ai exécuté le code, seule la première option du premier exemple d'utilisation a été imprimée. Il aurait été bon que le code envisage toutes les solutions possibles et qu'elles soient toutes imprimées.
Essayons de résoudre un problème de codage différent dans un autre langage de programmation.
"Ecrivez une fonction en JavaScript qui détermine si un nombre donné est premier.
Pour des raisons de lisibilité, je ne montre que la première et la dernière partie (bien que la chaîne de pensée ait été un peu plus courte cette fois-ci) :
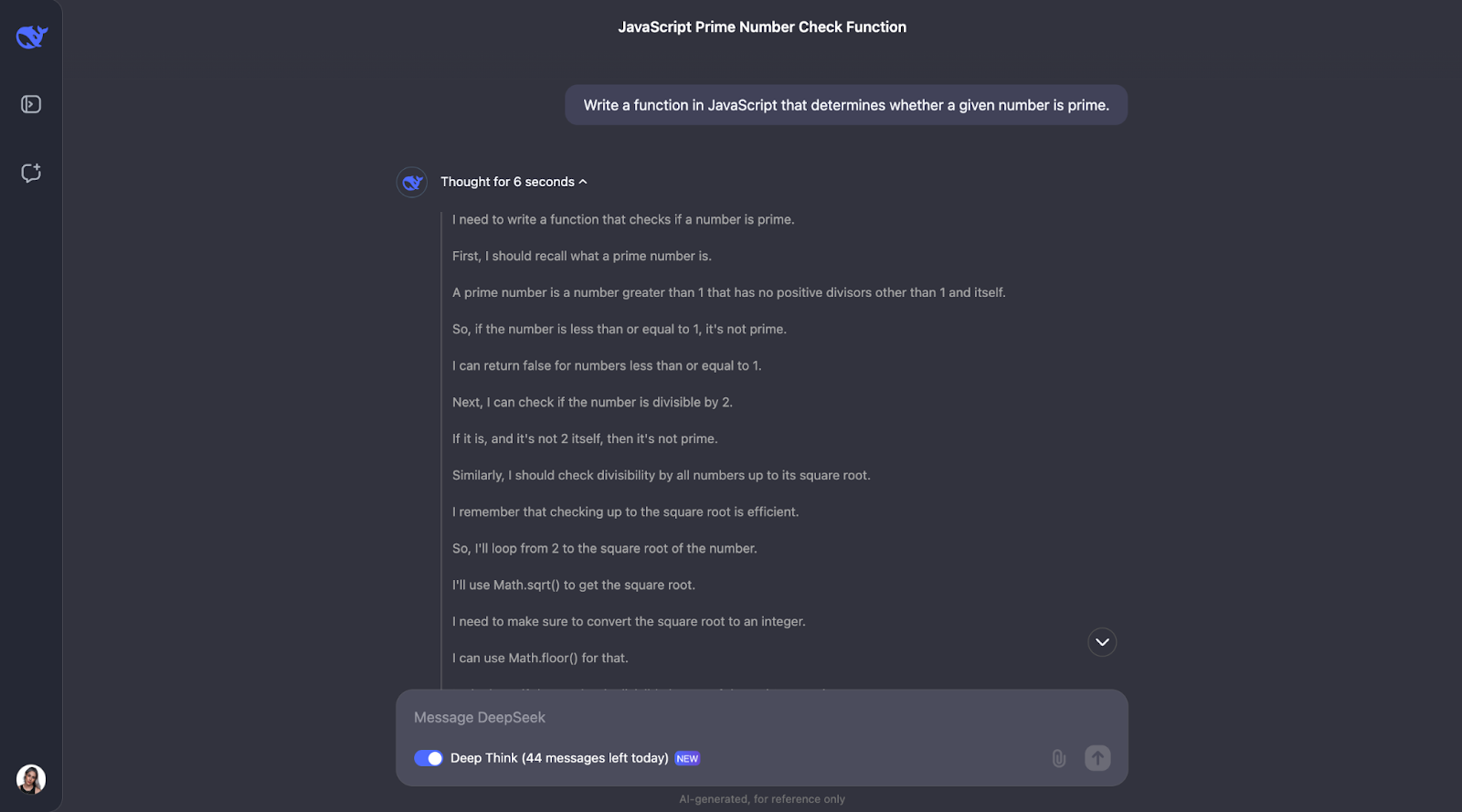
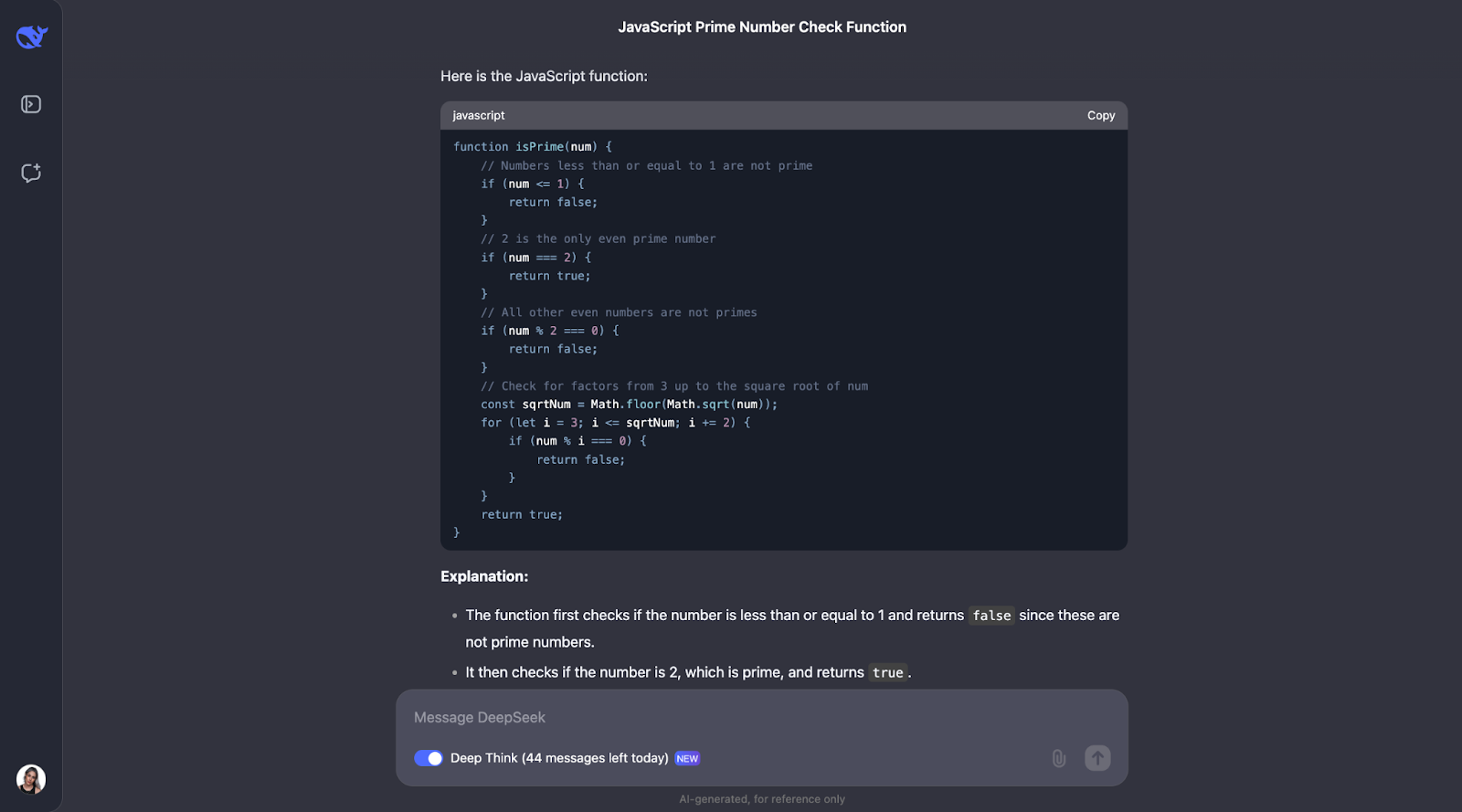
Je pense qu'à l'adresse, nous pouvons voir un modèle de processus de pensée. La plupart du temps, elle commence par définir les concepts clés qui apparaissent dans le problème. Ainsi, par exemple, pour ce problème, il définit ce qu'est un nombre premier.
Ensuite, le processus de réflexion prend tout son sens et aboutit à des étapes optimisées. Tout d'abord, il couvre les principes de base : les nombres inférieurs ou égaux à 1 ne sont pas premiers, et 2 est le seul nombre premier pair. Il vérifie ensuite si le nombre est divisible par tous les nombres impairs jusqu'à la racine carrée du nombre. Cela permet de gagner du temps en évitant les calculs inutiles. De plus, au lieu de tester chaque nombre, il saute tous les nombres pairs au-delà de 2, ce qui rend le processus encore plus rapide. La fonction utilise Math.sqrt pour trouver la racine carrée, ce qui limite la portée de la vérification et la rend efficace et simple.
Une fois encore, il a également été testé avec de petits exemples, comme dans le problème précédent, tels que des nombres premiers et non premiers connus, afin de s'assurer qu'il fonctionne comme prévu.
Il y a cependant une marge d'amélioration. Par exemple, la fonction ne vérifie pas si l'entrée est réellement un nombre, de sorte qu'elle pourrait mieux gérer les erreurs. Il pourrait également inclure des raccourcis pour les nombres se terminant par 0 ou 5, qui ne sont évidemment pas premiers (à l'exception de 5 lui-même). L'ajout d'un peu plus d'explications sur la raison pour laquelle il saute les nombres pairs ou ne vérifie que jusqu'à la racine carrée aiderait également les débutants à mieux le comprendre, je pense.
Enfin, j'aurais attendu que le code comporte des exemples de tests d'utilisation, de la même manière qu'il nous a donné ceux du code Python dans le test précédent.
Passons maintenant aux tests de raisonnement logique.
Je vais tester un puzzle classique :
"Un homme doit traverser une rivière avec un loup, une chèvre et un chou. Son bateau ne peut transporter que lui-même et une autre chose. S'il était laissé à lui-même, le loup mangerait la chèvre, et la chèvre mangerait le chou. Comment peut-il tout faire passer en toute sécurité ?"
Je m'attends à ce que le modèle fournisse la réponse suivante :
Mais voyons comment il gère le processus de réflexion, car je ne sais pas trop à quoi m'attendre !
Je dois également tronquer cette sortie pour des raisons de lisibilité :
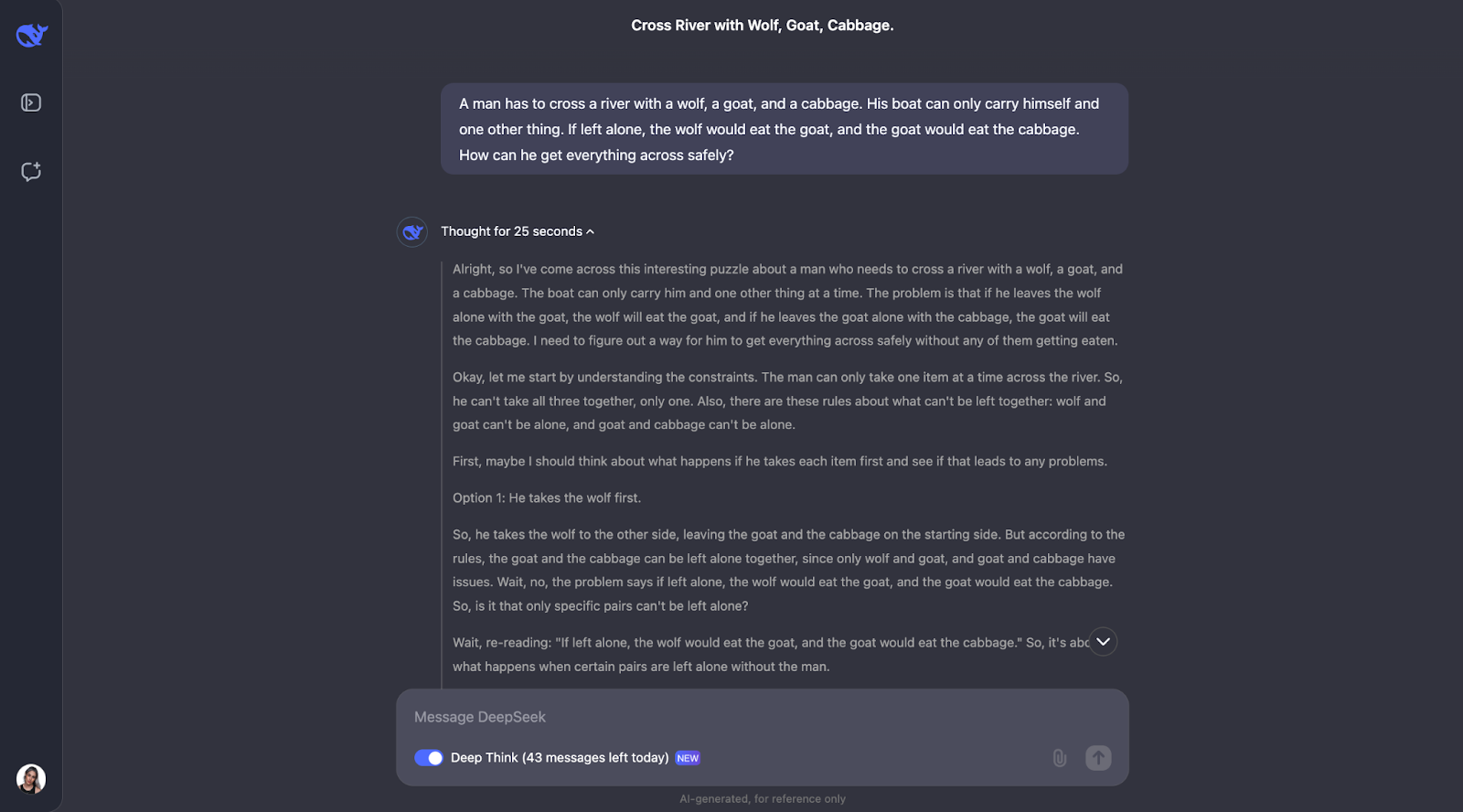
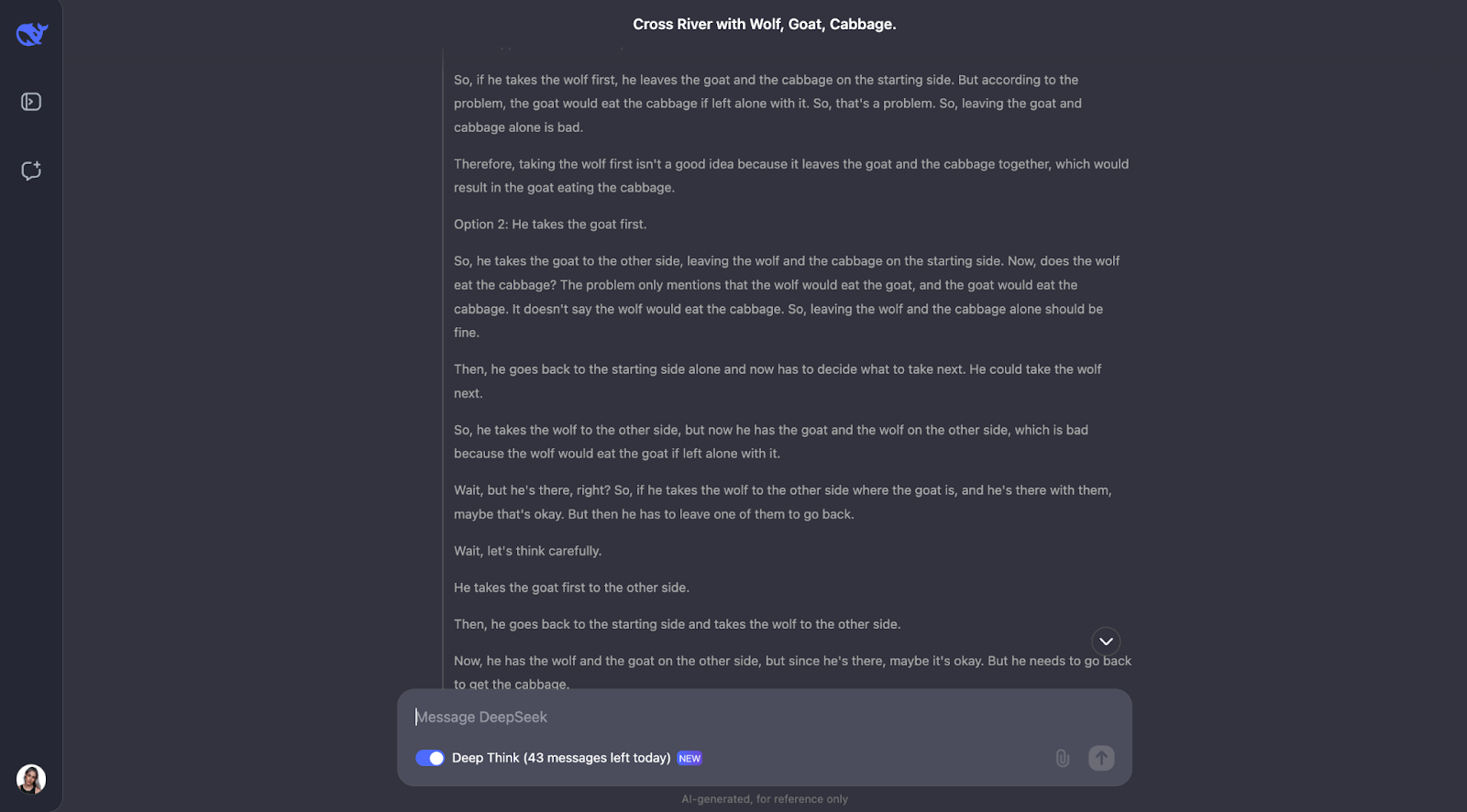
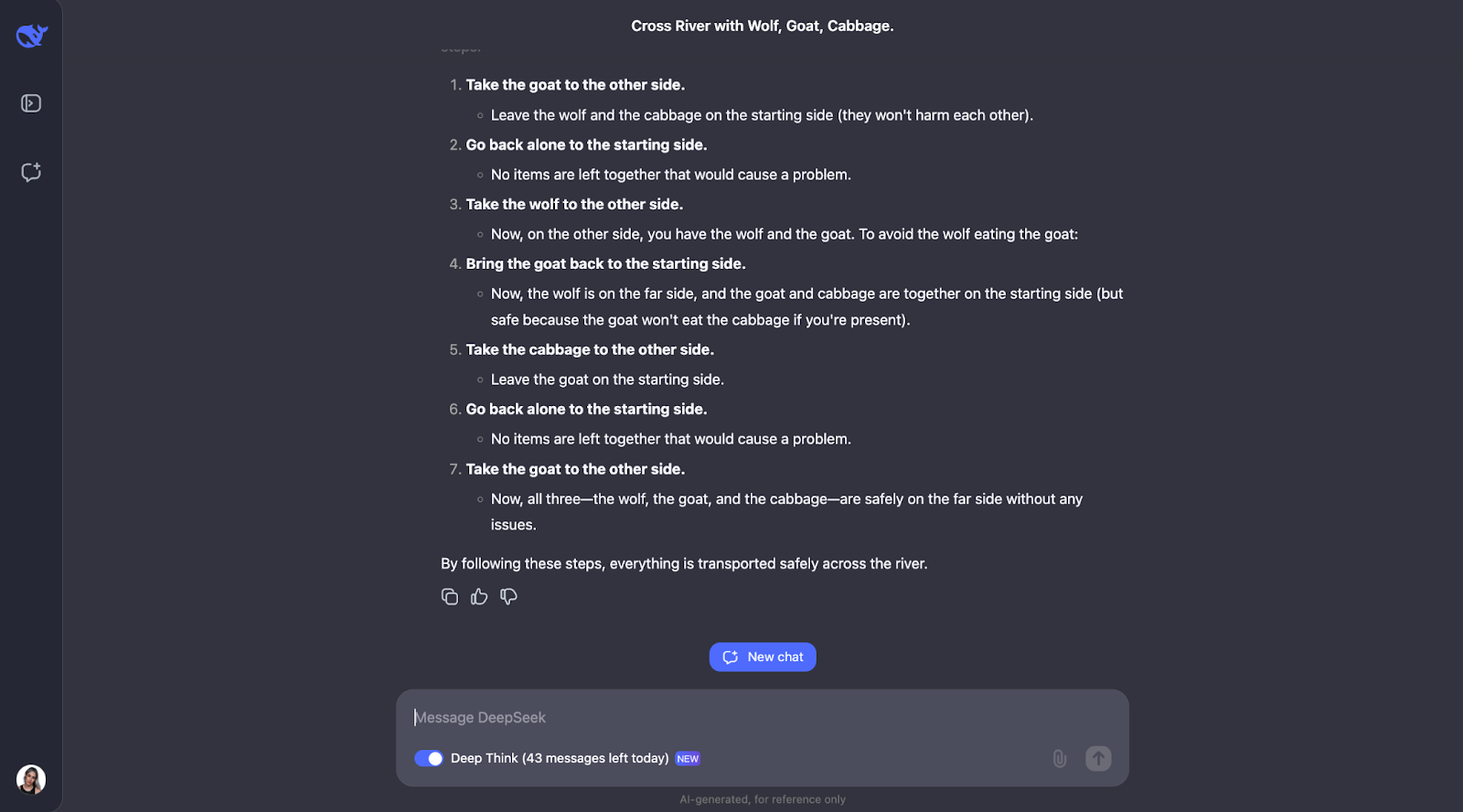
Le modèle permet de résoudre avec brio cette énigme classique de la traversée d'une rivière. Il réfléchit attentivement aux règles et vérifie les différentes possibilités. Il comprend que certains couples, comme le loup et la chèvre ou la chèvre et le chou, ne peuvent être laissés seuls. Il passe également en revue les contraintes de départ. À partir de là, il examine ce qui se passerait si l'homme faisait d'abord traverser la rivière à chaque objet et détermine si cela pose des problèmes.
Ce que je trouve vraiment bien, c'est la façon dont le modèle ajuste son plan lorsque quelque chose ne fonctionne pas. Par exemple, lorsqu'il essaie de prendre le loup en premier, mais qu'il se rend compte que cela pose des problèmes et qu'il repense alors les étapes. Cette méthode d'essai et d'erreur ressemble beaucoup à la façon dont nous, en tant qu'humains, pourrions résoudre le puzzle nous-mêmes.
Au final, le modèle propose la bonne solution et l'explique de manière claire, étape par étape.
Essayons-en un autre :
"Vous avez 12 boules, toutes identiques en apparence. Une balle est plus lourde ou plus légère que les autres. À l'aide d'une balance, trouvez la boule bizarre et déterminez si elle est plus lourde ou plus légère en seulement trois pesées."
Cette énigme logique classique teste la capacité du modèle à élaborer une stratégie optimale à l'aide d'un raisonnement déductif. Voyons ce qu'il en est. La sortie était très longue cette fois-ci, je vais donc devoir passer directement à la réponse :
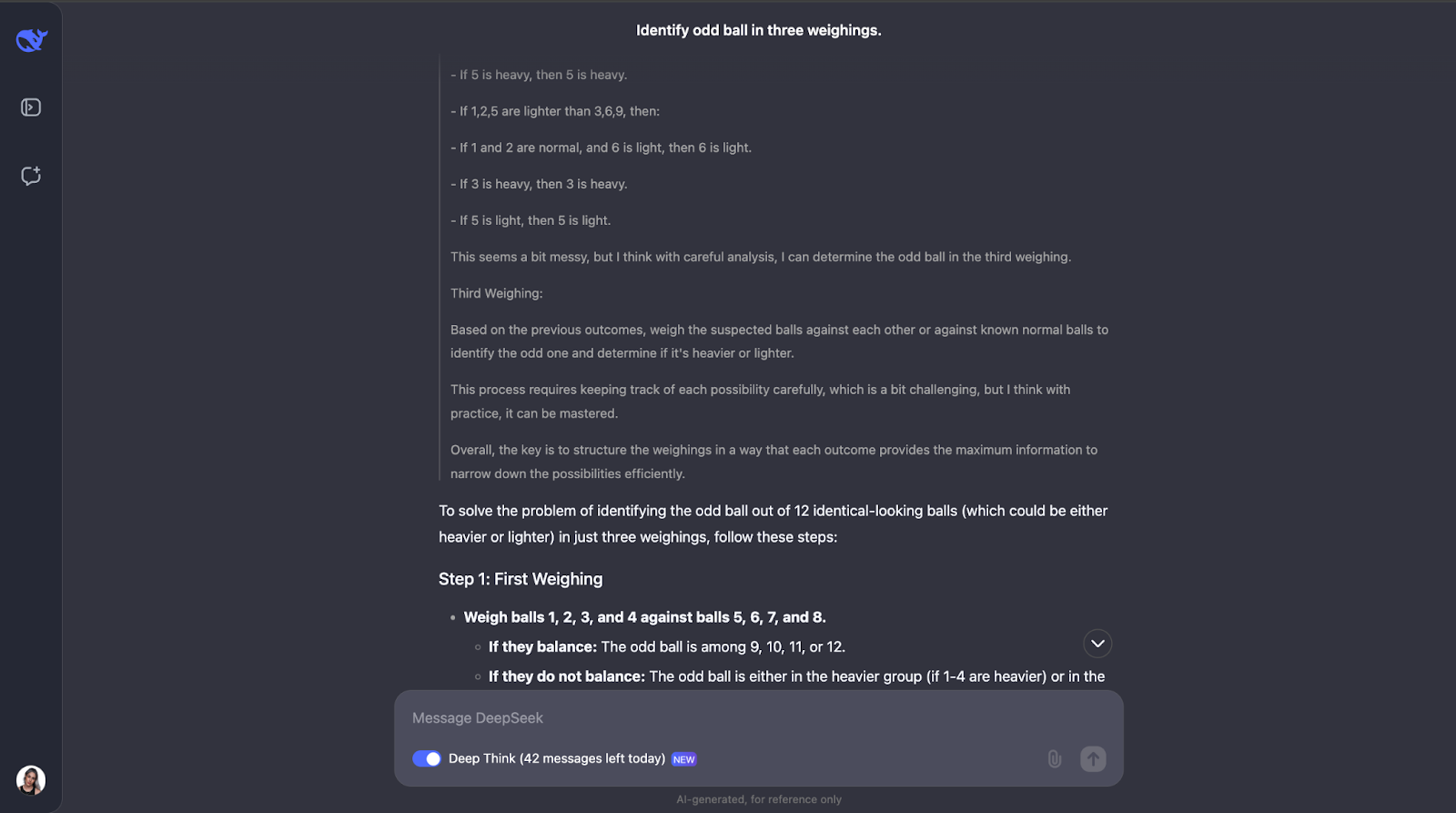
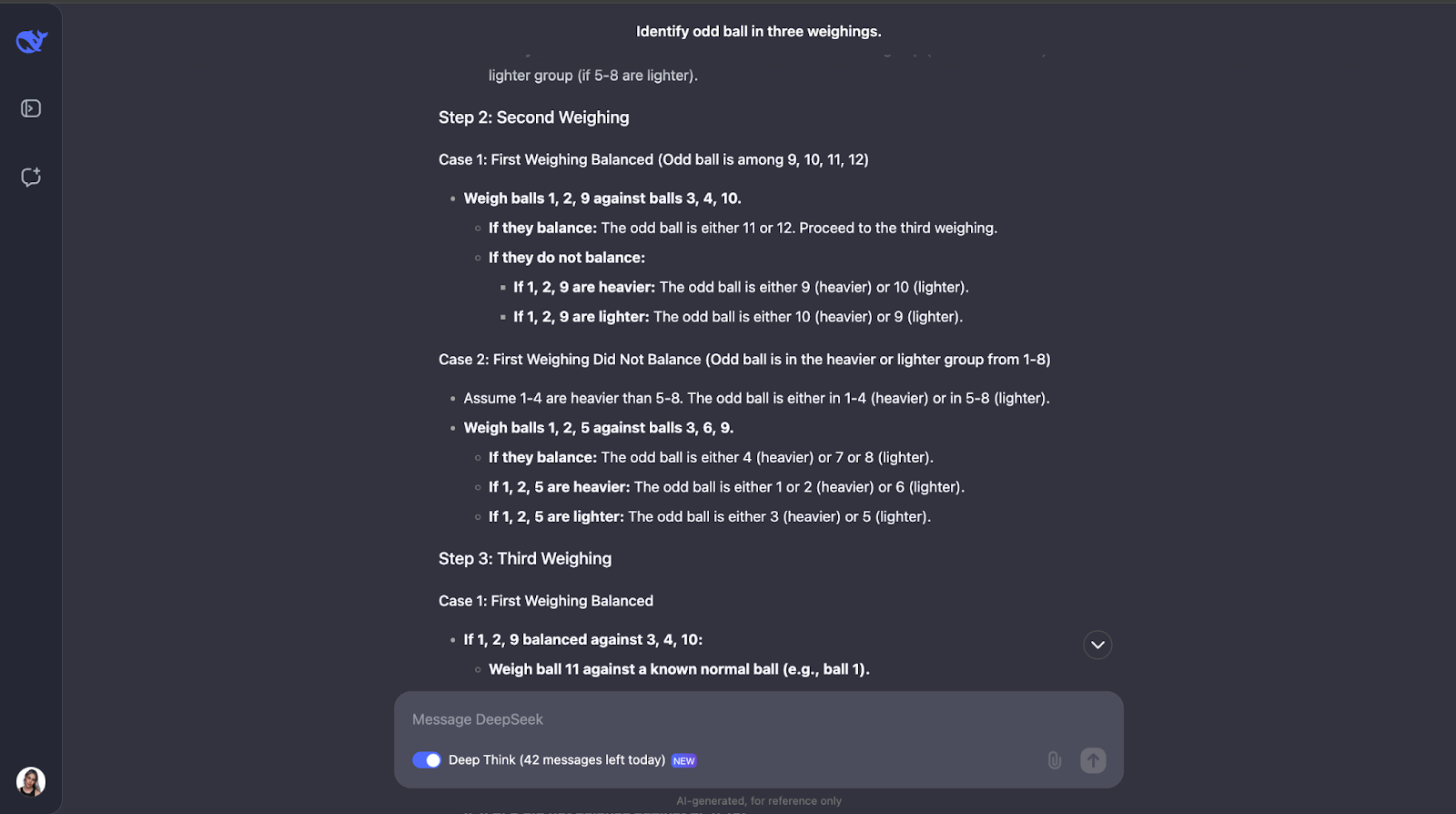

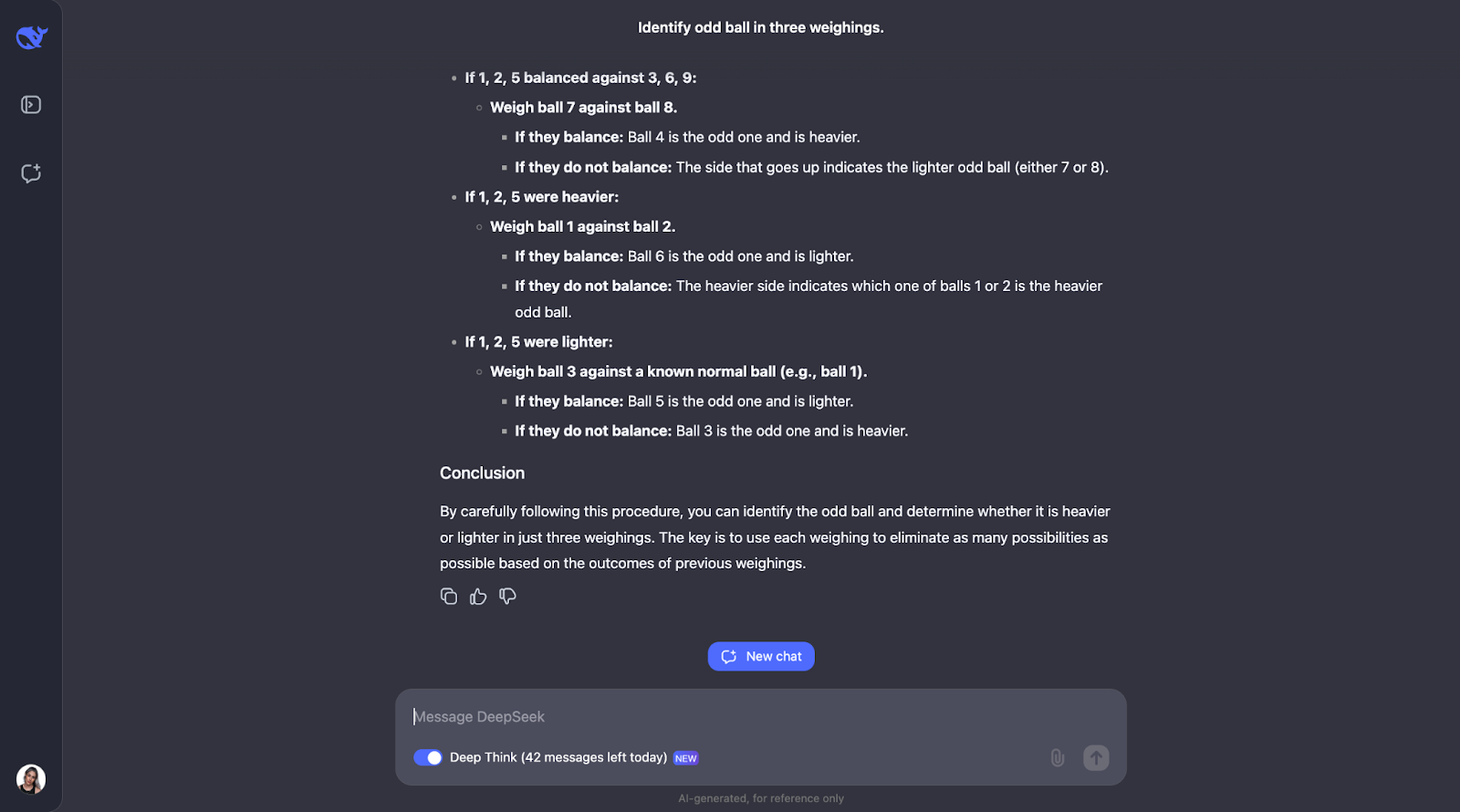
Encore une fois où j'ai totalement sous-estimé la longueur de la sortie ! Le modèle se rend compte que la résolution de ce puzzle nécessite une planification minutieuse, car vous n'avez droit qu'à trois essais. Il calcule également le nombre de résultats et de possibilités.
L'approche du modèle est intelligente car chaque pesée élimine autant de possibilités que possible. Il prévoit tous les résultats - que la balance s'équilibre ou penche - et ajuste l'étape suivante en fonction de ce qui se passe. Il est très détaillé, mais les étapes sont claires et logiques, ce qui le rend très facile à suivre, même s'il est long,
Ce qui m'a beaucoup plu, c'est que lorsque l'approche devient un peu trop complexe, elle applique une approche plus systématique ou plus simple. Cependant, je pense que pour des problèmes comme celui-ci, où vous devez garder une trace des différents cas, résultats et possibilités, l'ajout d'un diagramme ou d'un graphique pourrait aider les gens à visualiser le cheminement de la pensée et à mieux comprendre le résultat.
Dans cette section, je vais comparer DeepSeek à d'autres modèles comme o1-preview et GPT-4o en termes de performances sur différents benchmarks. Chacun d'entre eux se concentre sur une compétence différente, ce qui nous permet de voir quels sont les modèles les plus performants. Voyons les points de référence mesurés par DeepSeek :
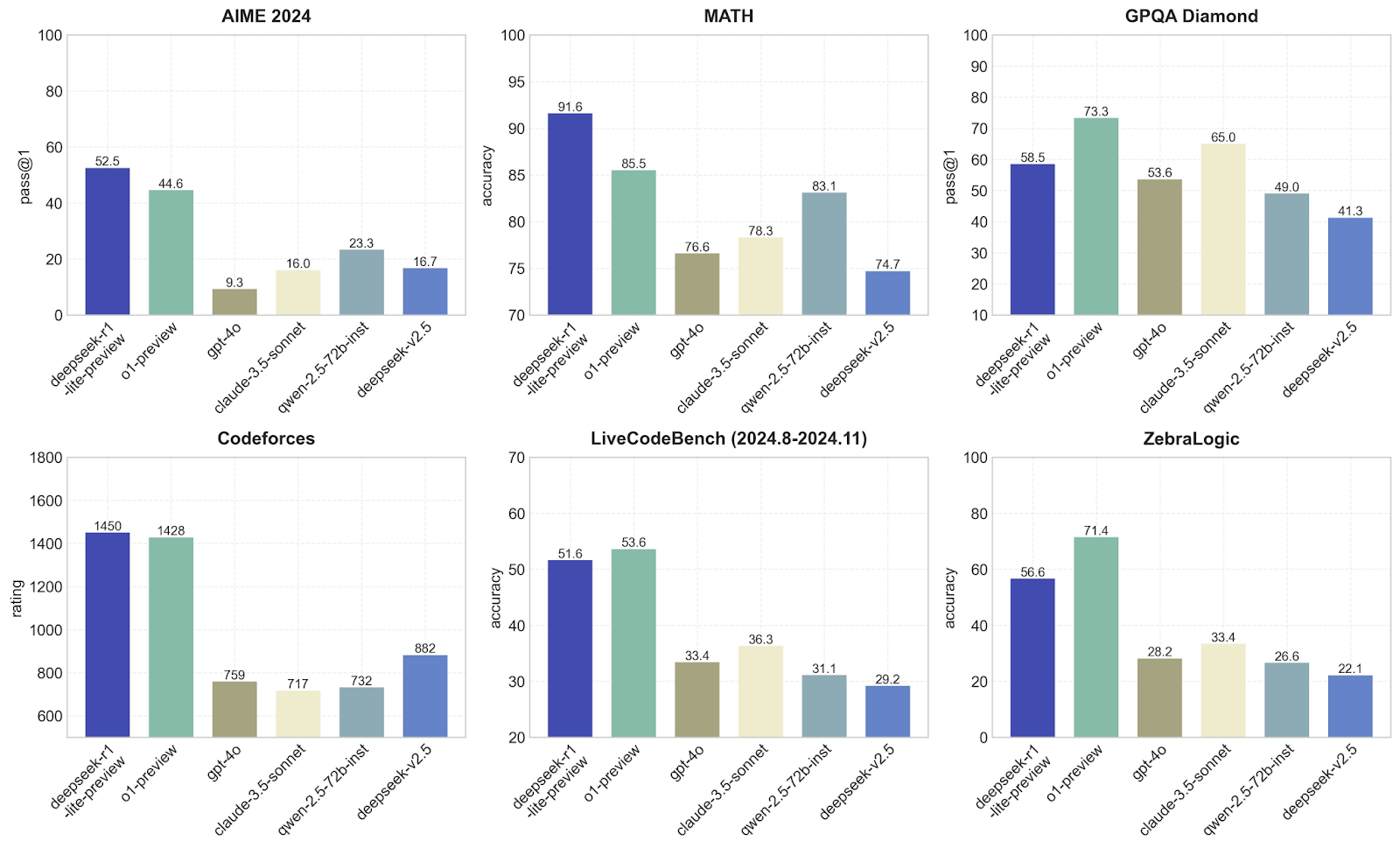
DeepSeek-r1-lite-preview est clairement le meilleur ici, avec un pass@1 de 52,5, suivi par o1-preview à 44,6. D'autres modèles, comme GPT-4o et claude-3.5-sonnet, obtiennent des résultats bien moins bons, avec des scores inférieurs à 23. Cela suggère que le modèle DeepSeek-r1-lite-preview est tout à fait capable de traiter le type de problèmes mathématiques ou logiques avancés spécifiques aux benchmarks AIME, ce qui ne me surprend pas après les tests que j'ai effectués.
DeepSeek-v1 domine à nouveau avec une précision impressionnante de 91,6, loin devant o1-preview (85,5) et bien mieux que d'autres modèles comme GPT-4o, qui peine à atteindre 76,6. Cela montre que DeepSeek est excellent pour résoudre les problèmes mathématiques, ce qui confirme mon hypothèse à partir des preuves empiriques des tests que j'ai effectués auparavant - pas de surprise jusqu'à présent !
Ici, o1-preview fait mieux que DeepSeek-v1, avec un pass@1 de 73,3 contre 58,5. D'autres modèles, comme le GPT-4o, se situent derrière avec 53,6. Cela suggère que o1-preview est mieux adapté aux tâches qui impliquent de répondre à des questions ou de résoudre des problèmes basés sur un raisonnement logique. DeepSeek est toujours très performant mais n'est pas aussi bon que o1-preview.
En ce qui concerne les programmes concurrents, DeepSeek-v1 (1450) et 01-preview (1428) sont presque à égalité pour la première place, tandis que d'autres modèles comme le GPT-4o n'obtiennent qu'un score d'environ 759. Comme prévu, cela montre que ces deux modèles sont excellents pour comprendre et générer du code pour les défis de programmation.
Cela permet de tester les capacités de codage dans le temps, et o1-preview devance légèrement DeepSeek-v1 (53.6 vs. 51.6). D'autres modèles, comme le GPT-4o, sont loin derrière avec 33,4. Encore une fois, cela montre que DeepSeek et 01-preview sont tous deux bien adaptés au codage, mais que 01-preview est un peu plus performant dans ces tâches.
o1-preview prend la tête avec une précision de 71,4, contre 56,6 pour DeepSeek-v1. D'autres modèles font bien pire. Cela montre que o1-preview est meilleur pour gérer des tâches logiques abstraites comme ZebraLogic, qui requièrent plus de créativité ou d'imagination, ce qui correspond aux résultats que j'ai obtenus lors des tests, la créativité n'étant définitivement pas le point fort de DeepSeek-v1.
Ces graphiques corroborent le fait que DeepSeek-v1 est extraordinaire dans les défis mathématiques et de programmation. Je dirais que o1-preview est plus équilibré et qu'il est performant dans un plus grand nombre de tâches, ce qui le rend plus polyvalent.
Examinons maintenant ce graphique :
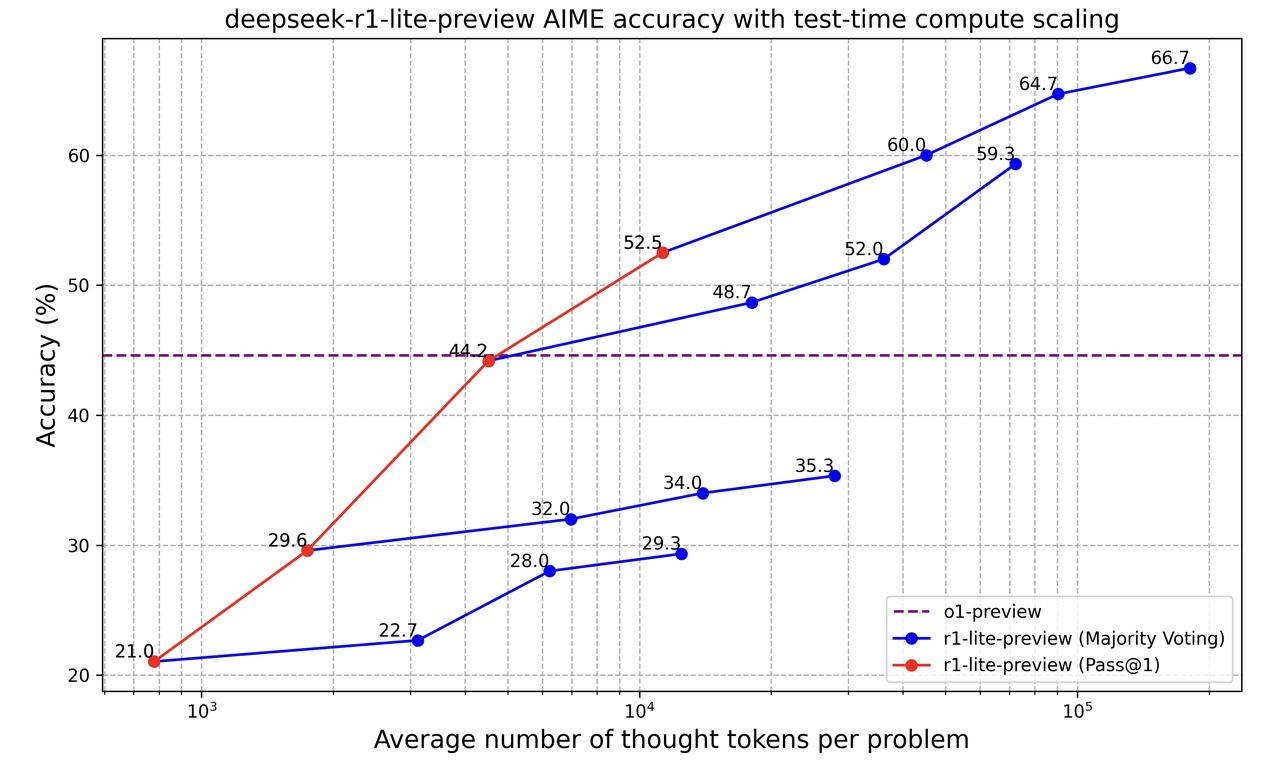
Ce graphique montre comment le modèle "deepseek-r1-lite-preview" parvient à mieux résoudre les problèmes à mesure qu'il traite davantage d'informations (mesurées par le nombre de "jetons de pensée" qu'il utilise). Il compare deux façons de mesurer la précision du modèle :
La ligne violette en pointillés représente le modèle o1-preview dont la précision est stable. Au début, o1-preview est meilleur, mais lorsque DeepSeek r1-lite-preview est autorisé à utiliser plus de jetons de pensée, il dépasse o1-preview et devient beaucoup plus précis.
Ce graphique montre donc que le fait de laisser DeepSeek r1-lite-preview réfléchir davantage et essayer plusieurs fois améliore sa précision.
DeepSeek-r1-lite-preview est-il meilleur que o1-preview d'OpenAI ? Cela dépend de la tâche à accomplir. Je dirais oui pour les problèmes de mathématiques et de codage. Pour le raisonnement logique, cela dépend de la tâche.
Ce qui m'a vraiment surpris, c'est la façon dont il a raisonné à travers certains des tests. Cela m'a vraiment fait réfléchir à ce que signifie réellement "penser" pour un modèle et à la manière dont il parvient à des approches de raisonnement.
Si ce modèle vous intrigue, pourquoi ne pas le tester vous-même ? Essayez-le sur les tâches qui vous intéressent et voyez ce qu'il donne. Vous pourriez être aussi surpris que moi !
Apprenez l'IA avec ces cours !
Cursus
Cours
Cours
blog
Nathaniel Taylor-Leach
8 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
blog
Fereshteh Forough
4 min
blog
Nathaniel Taylor-Leach