Lernpfad
Grundlagen der KI
10 Std.
DeepSeek-R1-Lite-Preview ist ein KI-Tool, ähnlich wie ChatGPTdas von dem chinesischen Unternehmen DeepSeek entwickelt wurde. Das Unternehmen kündigte dieses neue Modell am X am 20. November an (Tweet-Link) und teilte ein paar Details auf einer Dokumentationsseite.
DeepSeek-R1-Lite-Preview soll wirklich gut darin sein, komplexe Denkaufgaben in den Bereichen Mathematik, Codierung und Logik zu lösen. Es zeigt dir Schritt für Schritt, wie es denkt, damit du verstehst, wie es zu den Antworten kommt, was dazu beiträgt, dass die Menschen ihm mehr vertrauen.
Du kannst es auf ihrer Website kostenlos ausprobieren, chat.deepseek.comDu kannst den Chat kostenlos ausprobieren, bist aber auf 50 Nachrichten pro Tag im erweiterten Modus namens "Deep Think" beschränkt. DeepSeek plant auch, Teile dieses Tools mit der Öffentlichkeit zu teilen, damit andere es nutzen oder darauf aufbauen können.
Du kannst DeepSeek-R1-Lite-Preview benutzen, indem du diese beiden Schritte befolgst:
Um zu sehen, was DeepSeek-R1-Lite-Preview alles kann, lass es uns auf die Probe stellen! Ich werde eine Reihe von Herausforderungen durchgehen, die seine Denkfähigkeiten unter Beweis stellen, angefangen mit der einfachen, aber berühmten Erdbeerfrage: Wie oft kommt der Buchstabe "r" in 'Erdbeere' vor?"
Diese Frage mag einfach aussehen, aber LLMs (auch GPT-4o) haben traditionell Schwierigkeiten, sie richtig zu beantworten - sie antworten in der Regel, dass es nur zwei Vorkommen des Buchstabens"r" gibt.
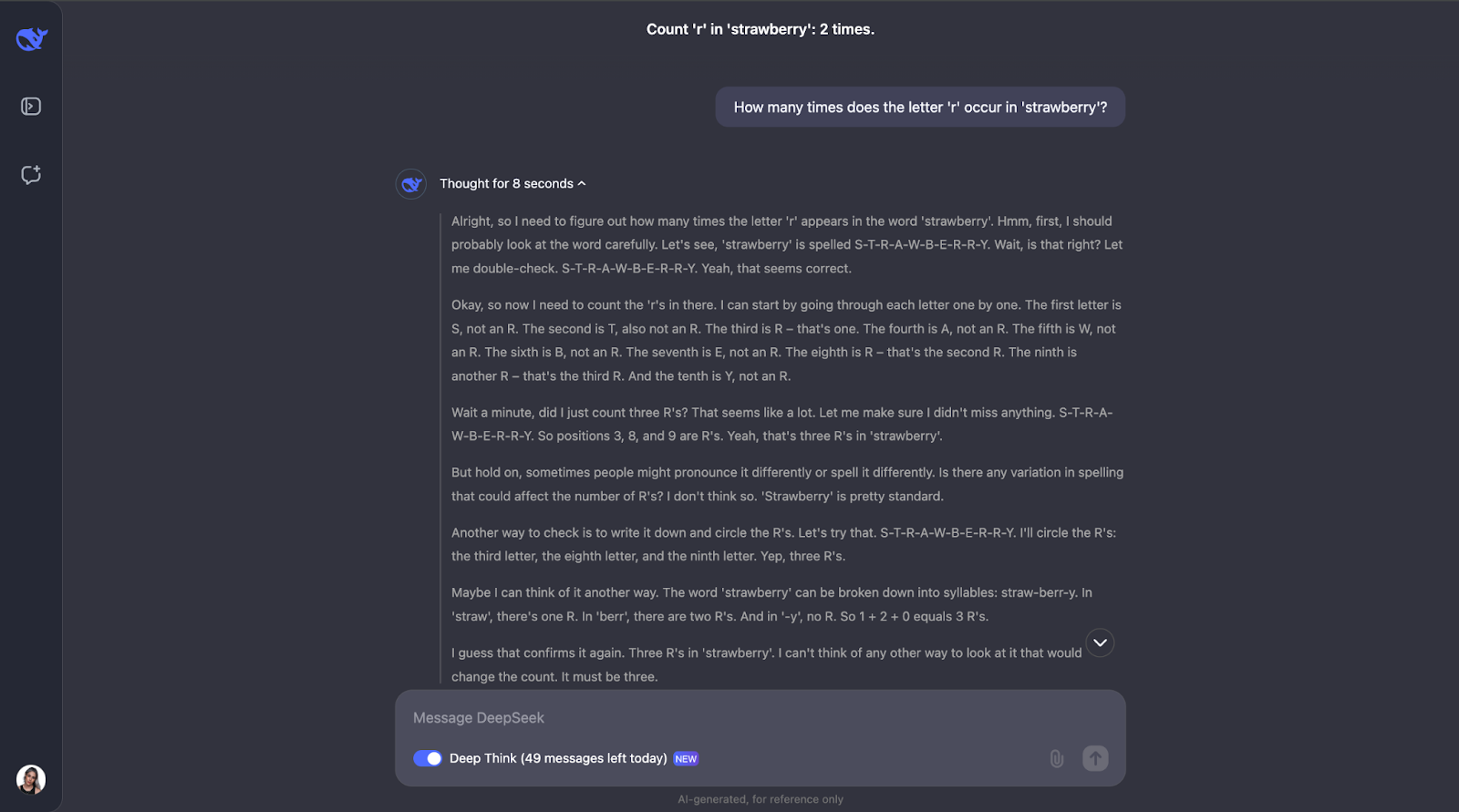
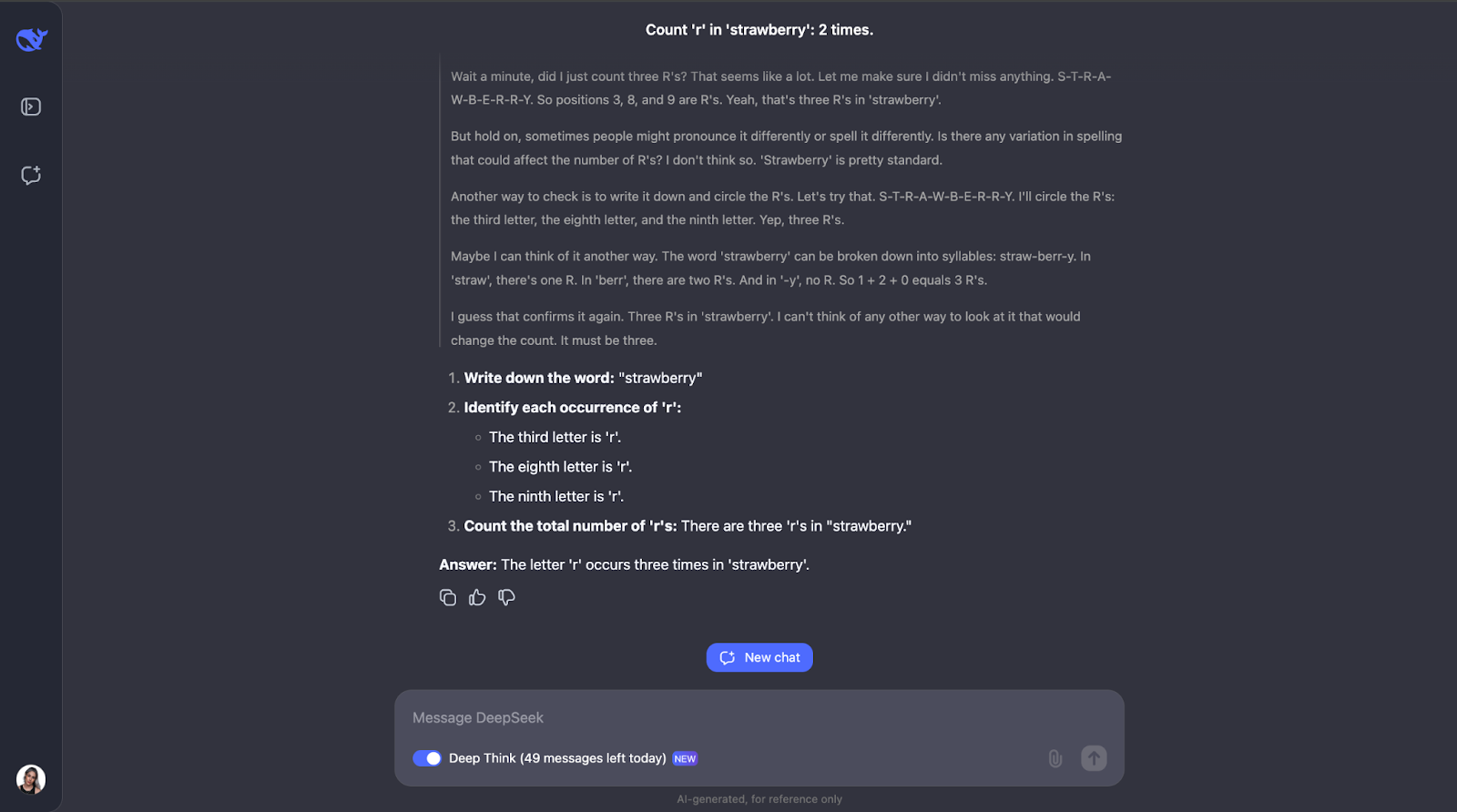
Wow, okay - ich hätte nicht erwartet, dass man für eine scheinbar einfache Aufgabe so lange nachdenken muss. Ich dachte, dass er nach dem Zählen des Buchstabens "r" und der Bestimmung seiner Position im Wort dort aufhören würde. Aber was mich interessiert, ist, dass es dabei nicht geblieben ist. Er hat die Zählung ein paar Mal überprüft und sogar Dinge wie die unterschiedliche Aussprache oder Schreibweise des Wortes berücksichtigt - was ich ein bisschen überflüssig finde, vor allem den Teil mit der Aussprache. Aber das zeigt, wie sorgfältig und durchdacht sie ist! Außerdem wurde jeder Schritt erklärt, so dass ich den Gedankengang nachvollziehen und sehen konnte, wie er zu der Antwort kam.
Ich werde DeepSeek-R1-Lite-Preview an drei Matheaufgaben testen.
Da DeepSeek behauptet, wirklich gut im mathematischen Denken zu sein, lass uns mit einem einfachen geometrischen Problem beginnen.
"Wenn ein Dreieck die Seitenlängen 3, 4 und 5 hat, wie groß ist dann sein Flächeninhalt?"
Diese Aufgabe erfordert die Kenntnis des Satzes des Pythagoras und der Heron-Formel. Ich würde erwarten, dass DeepSeek-R1-Lite-Preview seine Arbeit zeigt, vielleicht so:
Mal sehen, was passiert!
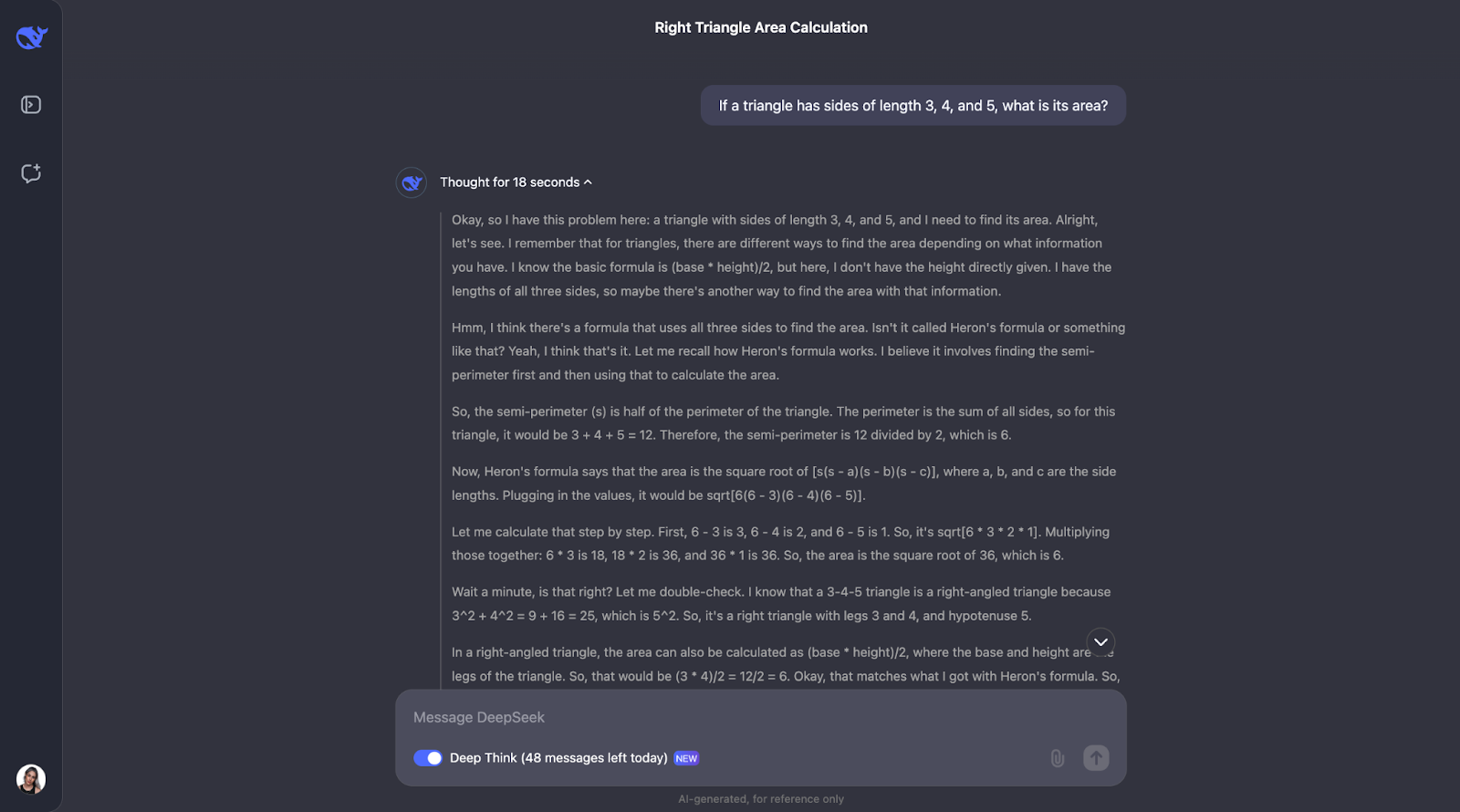
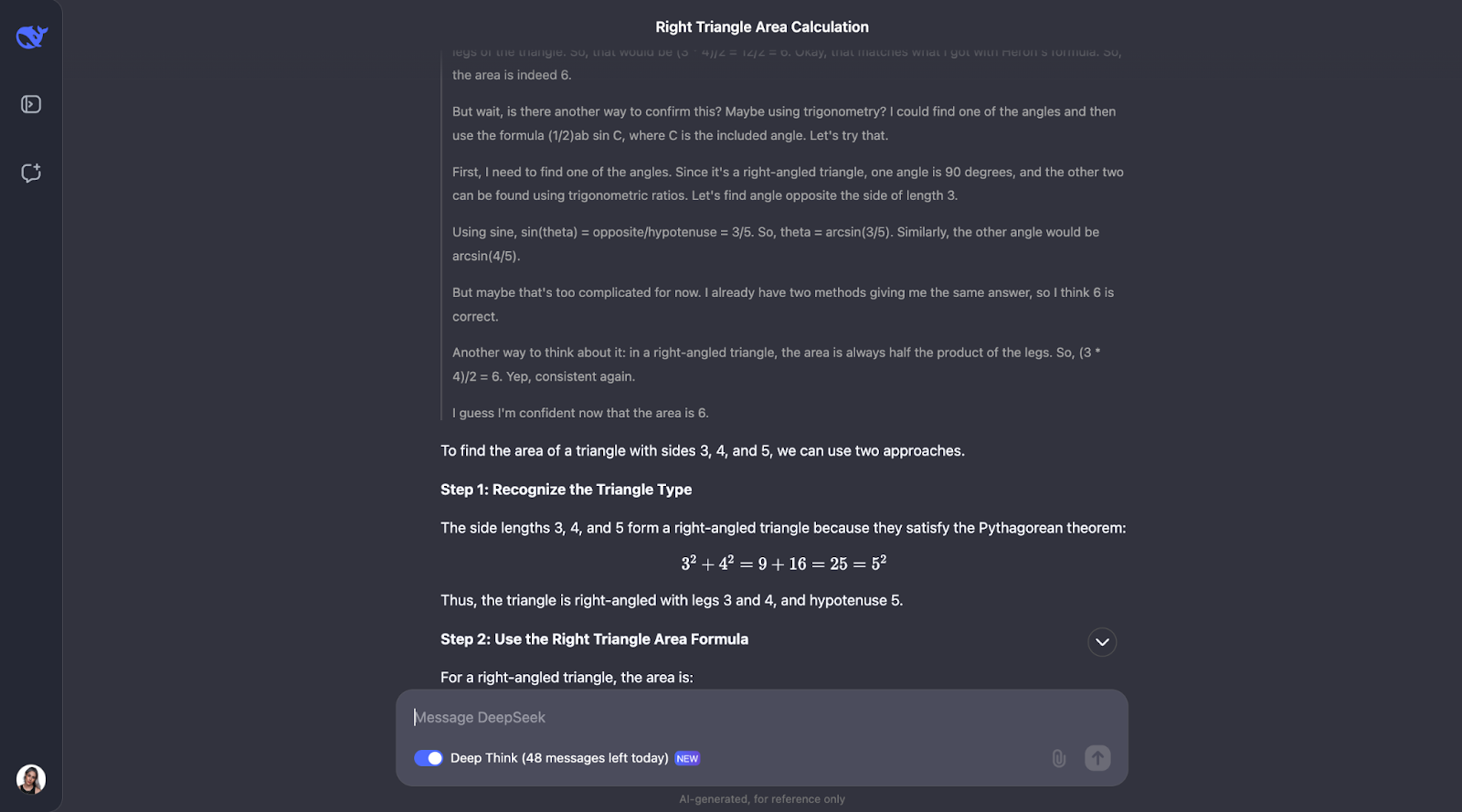
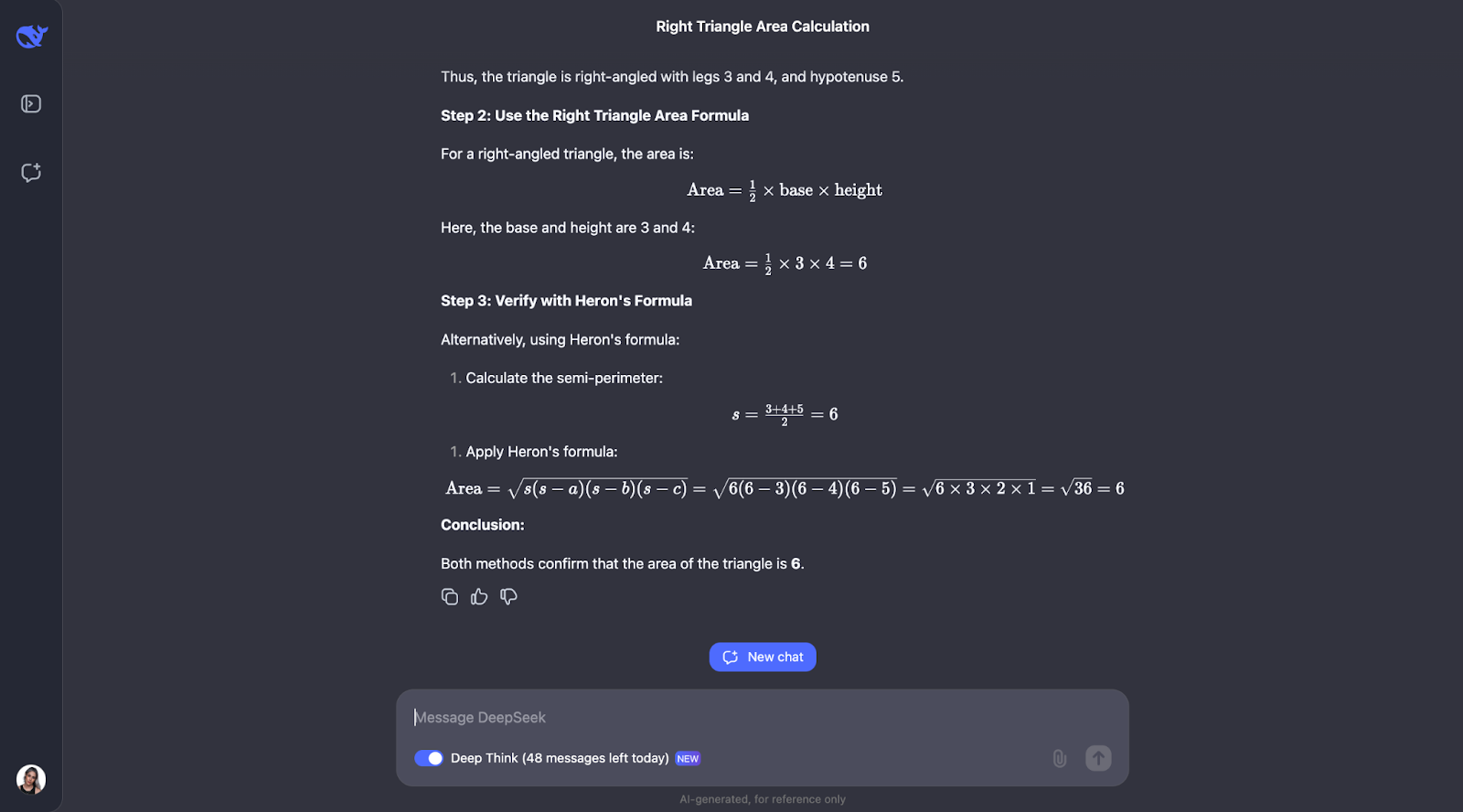
Okay, also interessanterweise führt er die Prüfungen durch, die ich vorhergesagt habe - wenn auch in einer anderen Reihenfolge. Es wurde auch erwogen, die Trigonometrie anzuwenden, indem man Winkel berechnet und eine andere Formel ausprobiert. Ich finde es so interessant, dass am Ende entschieden wurde, dass dies nicht nötig war, da die ersten beiden Methoden die Antwort bereits bestätigt hatten.
Sowohl die Erklärung als auch die Ausgabe waren besonders klar und leicht nachzuvollziehen, weshalb ich denke, dass dies ein fantastisches Modell wäre, um es z.B. in den Assistenten eines Mathematikschülers einzubauen. Für diesen speziellen Anwendungsfall könnte man vielleicht zuerst den Gedankengang zeigen und die Schüler/innen könnten damit interagieren und bestätigen, ob sie ihn verstanden haben oder nicht, bevor sie zur endgültigen Antwort übergehen.
Gehen wir zu einem komplexeren Mathe-Test über, um zu sehen, ob es einen Unterschied in der Leistung und im Denkprozess gibt.
"Beweise, dass die Summe der Kehrwerte der Fibonacci-Zahlen gegen einen endlichen Wert konvergiert."
Dieser Test fordert das Verständnis des Modells für fortgeschrittene mathematische Konzepte wie die Konvergenz von Reihen und die Eigenschaften der Fibonacci-Zahlen. Lass es uns versuchen! Aus Gründen der Lesbarkeit werde ich nur den ersten und den letzten Teil der Antwort posten (du kannst es aber gerne selbst mit demselben Prompt versuchen):
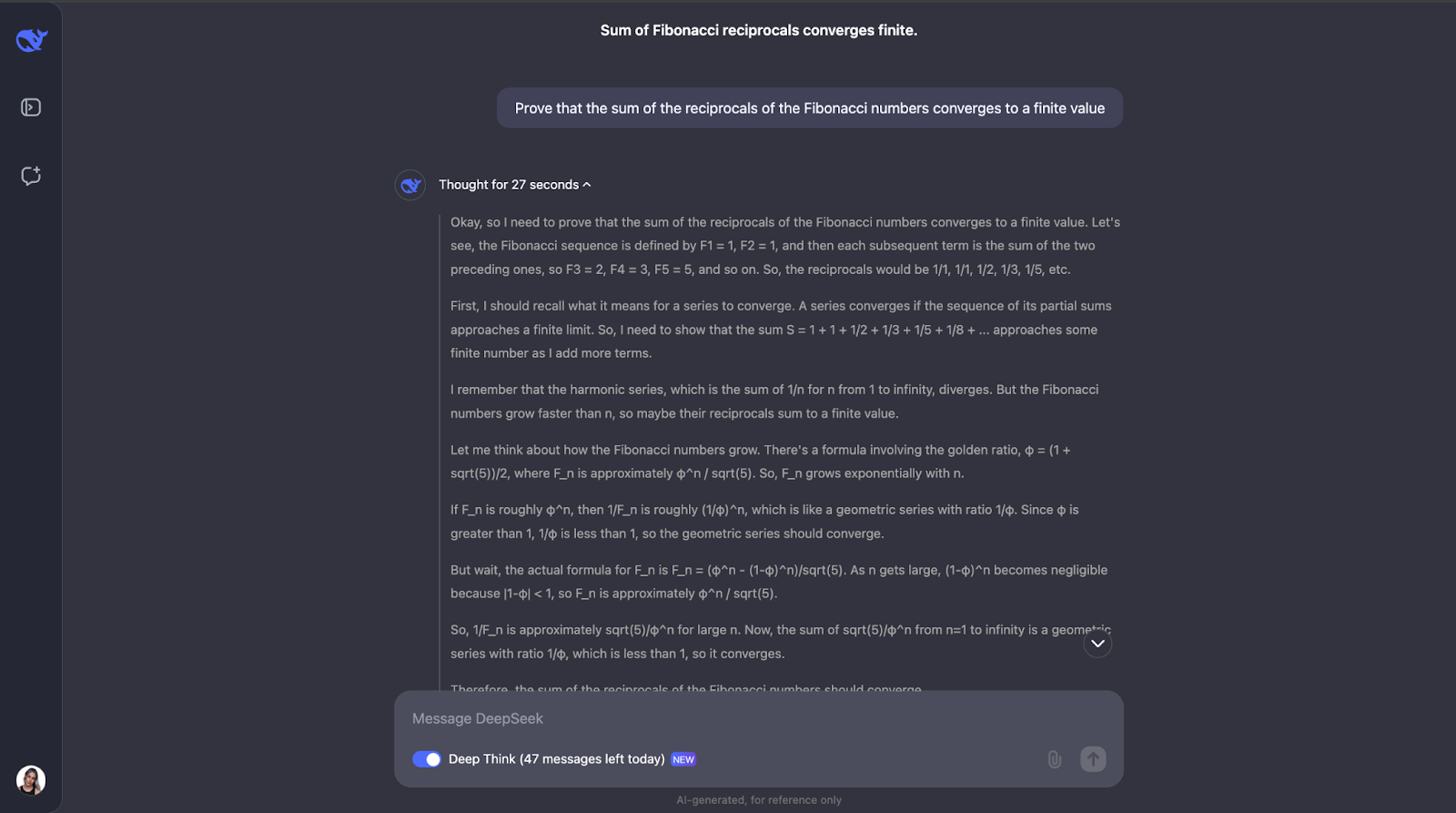

Okay, das ist ein toller Gedankengang - ich finde es wirklich gut, dass er zuerst sicherstellt, dass er die Schlüsselkonzepte wie Kehrwerte und Konvergenz versteht. DeepSeek-R1-Lite-Preview hat sich diesem Problem genähert, indem es sich angeschaut hat, wie die Fibonacci-Zahlen wachsen und einen Vergleichstest verwendet hat, der eine gängige Methode ist, um zu prüfen, ob eine Reihe konvergiert oder nicht.
Er verglich die Kehrwerte der Fibonacci-Zahlen mit einer geometrischen Reihe. Da die Kehrwerte der Fibonacci-Zahlen noch schneller abnehmen als eine geometrische Reihe mit einem gemeinsamen Verhältnis von weniger als 1, schloss das Modell, dass auch die Summe der Kehrwerte zu einem endlichen Wert konvergiert. Um besonders sicher zu sein, wurde ein sogenannter Ratio-Test durchgeführt.
Dieser Test prüft, ob der Grenzwert des Verhältnisses der aufeinanderfolgenden Terme kleiner als 1 ist. Wenn ja, konvergiert die Reihe. Das Modell hat dieses Verhältnis für die Kehrwerte der Fibonacci-Zahlen berechnet und festgestellt, dass es tatsächlich kleiner als 1 ist.
Es wurde sogar erwähnt, dass es einen bekannten Wert für diese Summe gibt, die reziproke Fibonacci-Konstante, die ungefähr 3,3598 beträgt. Aber für dieses Problem mussten wir nur wissen, dass die Summe endlich ist, nicht aber, was sie genau ist - das war also eine zusätzliche Information, die ich auch interessant fand. Mir gefällt sehr, wie die Lösung in der Ausgabe dargestellt wird. Es ist klar und Schritt für Schritt.
Bis jetzt bin ich von den mathematischen Aufgaben beeindruckt.
Ich werde es mit einem Problem aus der Differentialgeometrie versuchen - nur weil ich in diesem Bereich promoviere, konnte ich nicht widerstehen, einen kleinen Test zu machen. Nichts übermäßig Kompliziertes, nur eine klassische Übung, die du im Grundstudium der Mathematik kennenlernst.
"Betrachten Sie eine Fläche S in R³, die wie folgt parametrisiert ist
φ(u,v) = (u cos v, u sin v, ln u)
für u > 0 und 0 ≤ v < 2π.
a) Berechne die erste Grundform von S.
b) Bestimme, ob S eine minimale Fläche ist.
c) Finde die Gaußsche Krümmung K und die mittlere Krümmung H von S."
Von DeepSeek-R1-Lite-Preview würde ich erwarten, dass es eine Schritt-für-Schritt-Lösung bietet, die alle Berechnungen zeigt und die Bedeutung jedes Ergebnisses sowie die Definitionen der wichtigsten Begriffe wie Grundform, minimale Oberfläche und die verschiedenen Krümmungen erklärt.
Um diesen Blog lesbar zu halten, kann ich nur den ersten und letzten Teil der Antwort zeigen, aber ich möchte dich ermutigen, die Aufforderung selbst auszuprobieren :
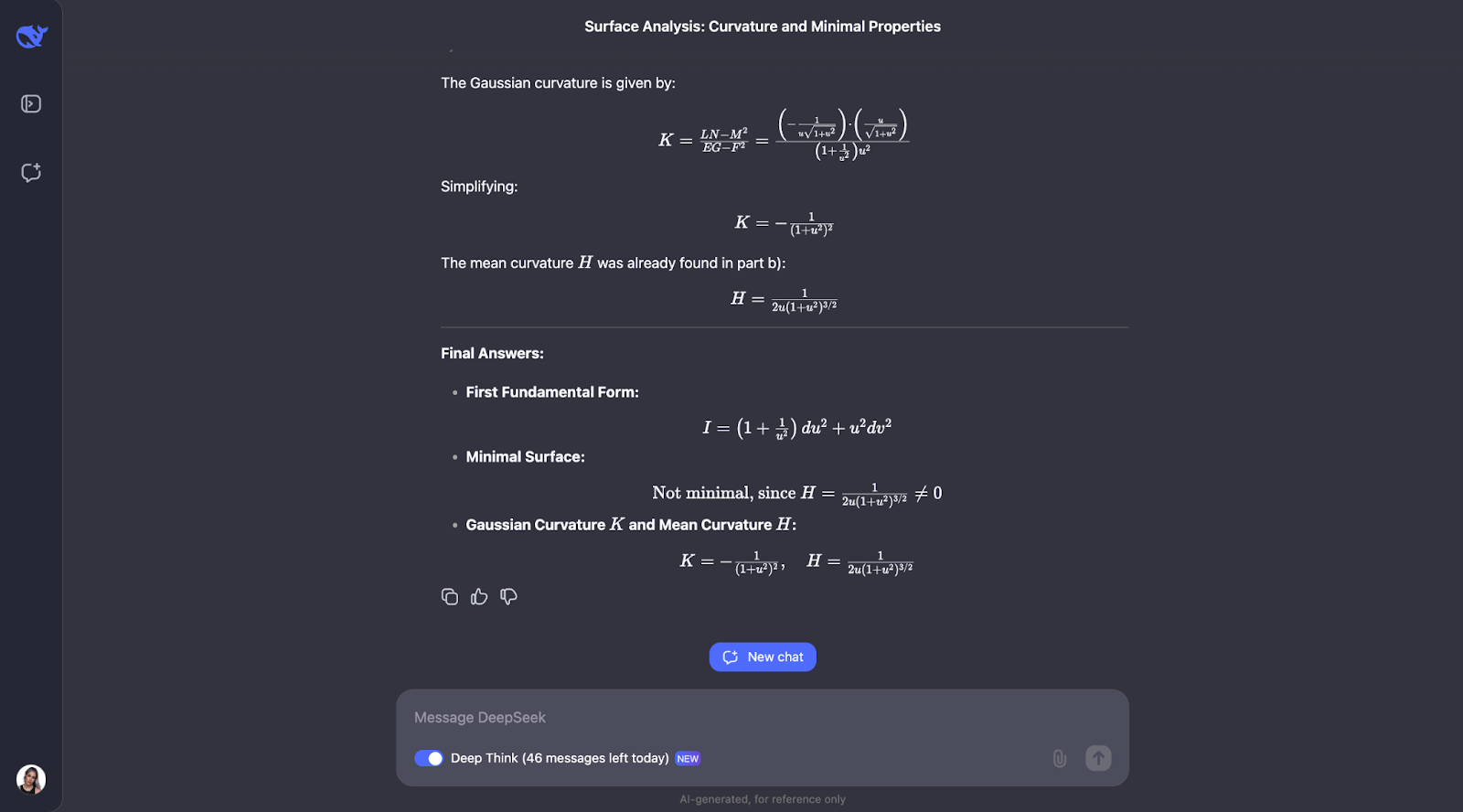
Der schrittweise Ansatz vonverwendet bekannte geometrische Formeln und wendet sie direkt an, sodass die Argumentation leicht nachvollziehbar ist. Ich hätte jedoch erwartet, dass er sein eigenes Verständnis der wichtigsten Begriffe in der Aufgabe überprüft, was nicht Teil des Gedankengangs ist. Für Teil B wählt er einen alternativen Ansatz und stellt fest, dass es sich bei der betroffenen Fläche um eine Rotationsfläche handelt, was eine nette Idee ist.
Es gibt auch einen Moment, in dem er die Rotation kommentiert und feststellt, dass er bereits N, den Normalvektor, hat, was mit der Notation des Koeffizienten für die zweite Grundform in Konflikt geraten könnte. Ich hätte gerne einen Vorschlag für eine bessere Schreibweise gesehen, denn denselben Buchstaben für zwei Dinge zu verwenden, ist keine gute Praxis!
Bei der Berechnung der mittleren Krümmung stellt er fest, dass sie nicht Null ist und fragt sich, ob die Berechnung korrekt ist. Um gründlich zu sein, versucht er eine weitere Methode, um seine Arbeit zu überprüfen.
Auch hier ist die Ausgabe sehr klar und einfach zu verstehen. Bei all diesen Beispielen war es beeindruckend zu sehen, wie es Berechnungen mit verschiedenen Methoden immer wieder überprüft hat. Der Gedankengang ist immer detailliert, logisch und leicht zu verstehen!
Kommen wir nun zum Codieren von Tests.
Die erste, die ich testen werde, ist:
"Implementiere eine Funktion in Python, die die längste palindromische Teilzeichenkette in einer gegebenen Zeichenkette findet. Die Funktion sollte eine Zeitkomplexität besser als O(n^3) haben."
Ich versuche, die Fähigkeit des Modells zu bewerten, effiziente Algorithmen zu entwerfen und sie in Code zu implementieren. Ich würde eine Lösung mit dynamischer Programmierung oder dem Manacher-Algorithmus erwarten, mit einer klaren Erklärung des Ansatzes und der Zeitkomplexität Analyse.
Die Ausgabe ist sehr, sehr lang und ich zeige nur den ersten und letzten Teil:
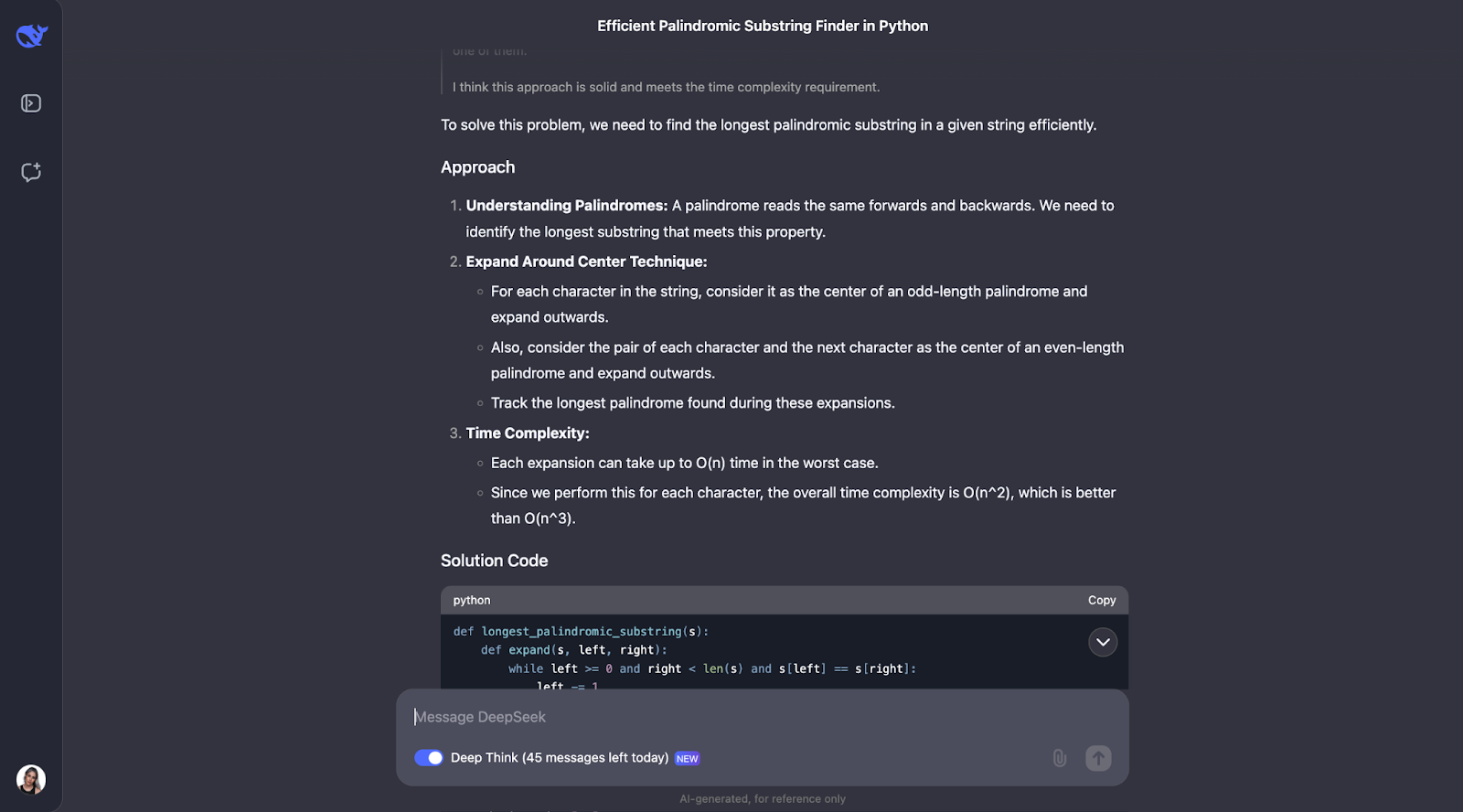
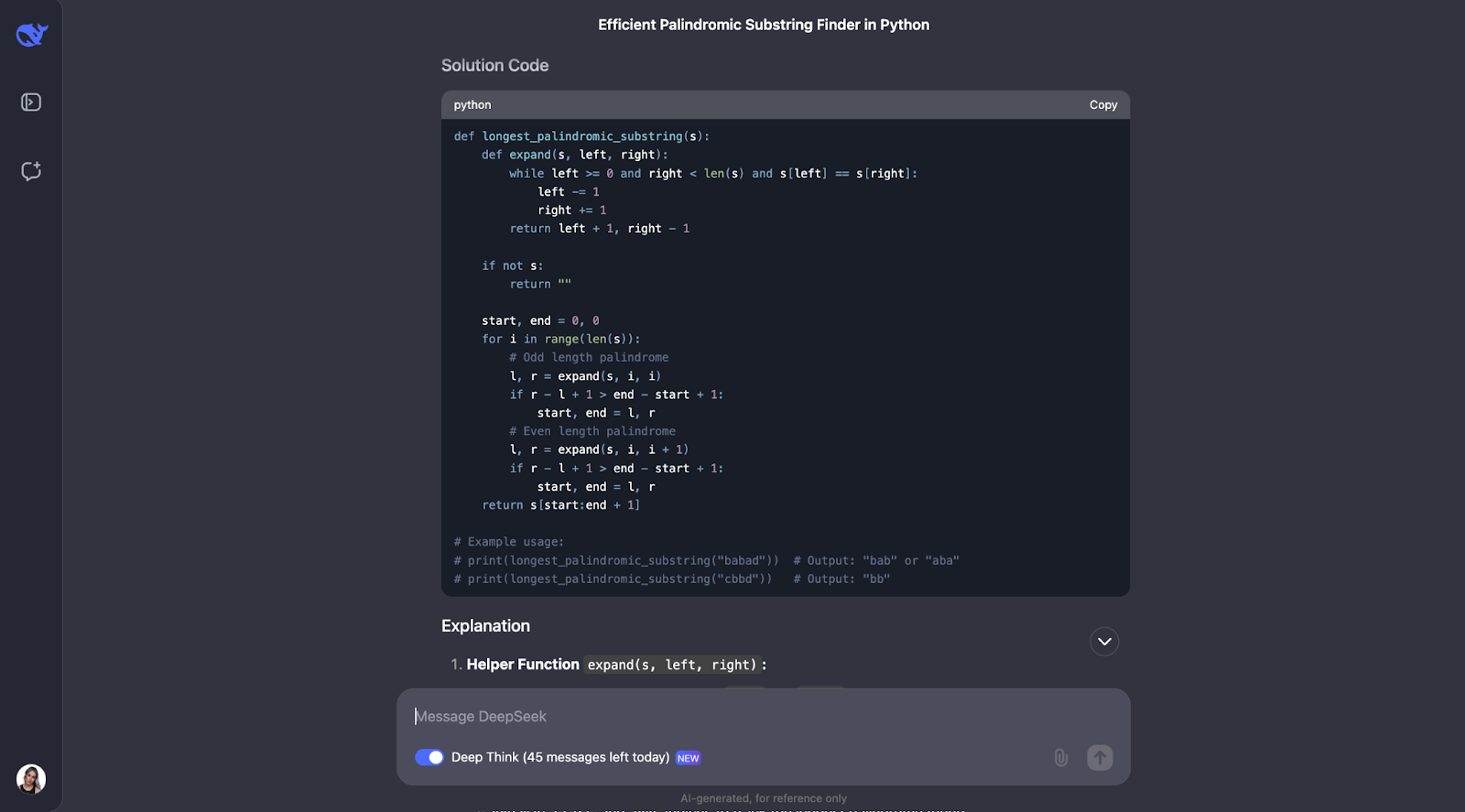
Ich finde, das Modell hat das Problem, die längste palindromische Teilfolge zu finden, gut gelöst. Ihr Ansatz war intelligent, effizient und klar erklärt.
Anstatt jede mögliche Teilzeichenkette zu erzwingen, was sehr langsam wäre, wurde eine clevere Technik verwendet, die um die Zentren herum erweitert wird. Mit dieser Methode wurden sowohl Palindrome mit ungerader Länge wie "aba" als auch solche mit gerader Länge wie "abba" behandelt. Der Lernpfad zeichnete das längste Palindrom auf, das er fand. Das Ergebnis war ein Algorithmus, der in O(n^2)-Zeit läuft, viel schneller als eine O(n^3)-Lösung.
Was mich an dieser Antwort am meisten beeindruckt, ist, wie klar sie formuliert wurde. DeepSeek hat das Problem in verständliche Schritte zerlegt, seinen Gedankengang detailliert erklärt und sogar praktische Beispiele angeführt. Er zeigte zum Beispiel, wie sich der Algorithmus um den Mittelpunkt von "Rennwagen" oder "abba" erweitert, um das richtige Palindrom zu finden. Die Hilfsfunktion zum Erweitern um einen Mittelpunkt war meiner Meinung nach besonders gut - sie machte den Code modular und einfach zu folgen.
Allerdings hätte ich erwartet, dass sie den Manacher-Algorithmus in Betracht zieht, der eine schnellere O(n)-Lösung ist. Es ist definitiv komplexer zu implementieren, aber es ist nützlich für Fälle, in denen die Leistung kritisch ist, und ich hätte erwartet, dass das Modell darauf hingewiesen hätte.
Mir ist auch aufgefallen, dass in der Ausgabe nicht explizit darauf eingegangen wird, wie der Algorithmus mit Sonderfällen umgeht, z. B. mit einer leeren Zeichenkette oder einer Zeichenkette mit allen gleichen Zeichen (z. B. "aaaa"). Diese Fälle würden funktionieren - aber ich hätte erwartet, dass es zumindest diskutiert wird.
Schließlich finde ich es gut, dass die erwartete Ausgabe für die Beispielanwendungen kommentiert wurde. Als ich den Code ausführte, wurde jedoch nur die erste Option für die erste Beispielanwendung gedruckt. Es wäre toll gewesen, wenn der Code alle möglichen Lösungen berücksichtigt hätte und alle gedruckt worden wären.
Versuchen wir es mal mit einem anderen Programmierproblem in einer anderen Programmiersprache.
"Schreibe eine Funktion in JavaScript, die feststellt, ob eine bestimmte Zahl eine Primzahl ist"
Aus Gründen der Lesbarkeit zeige ich nur den ersten und den letzten Teil (obwohl die Gedankenkette dieses Mal etwas kürzer war ):
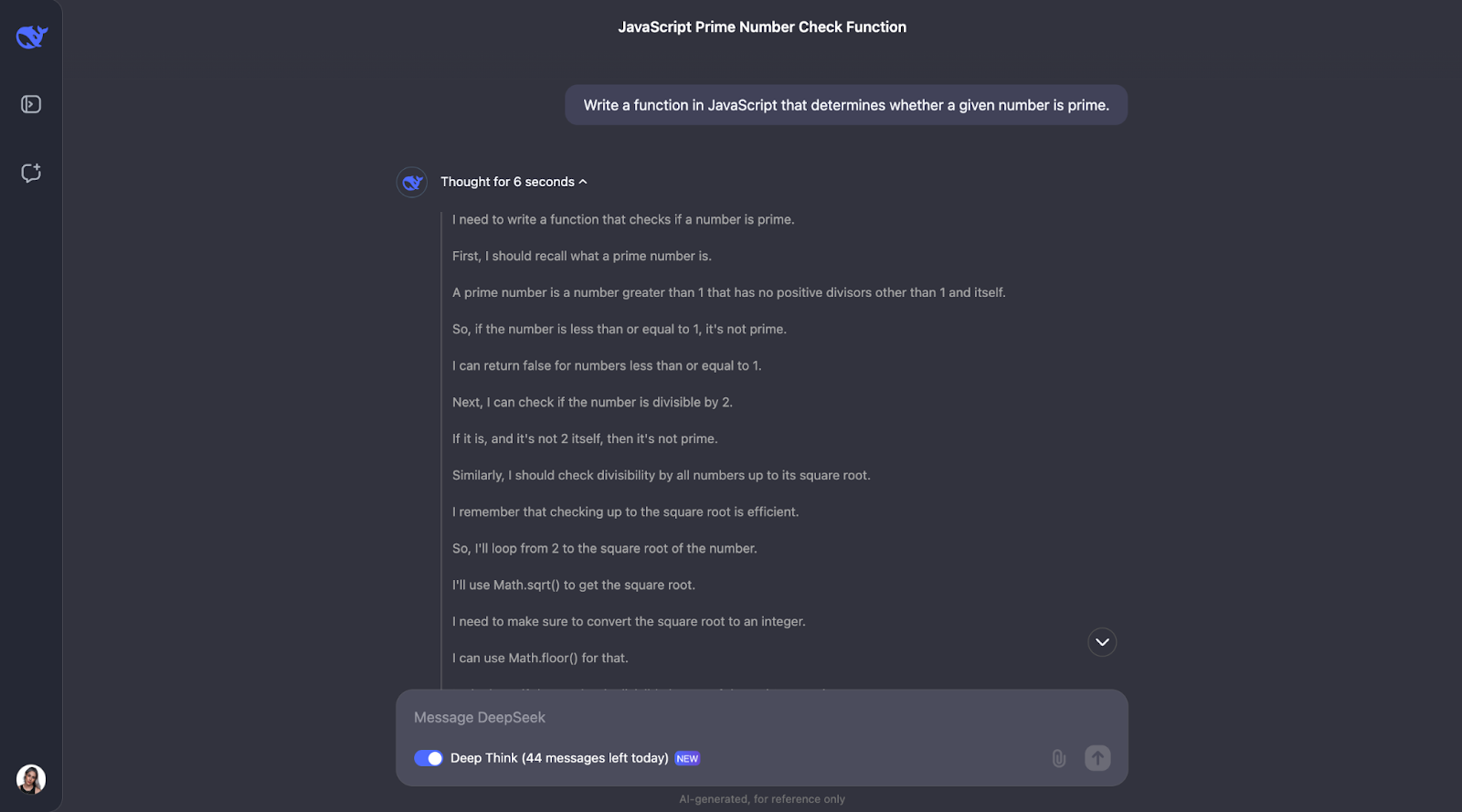
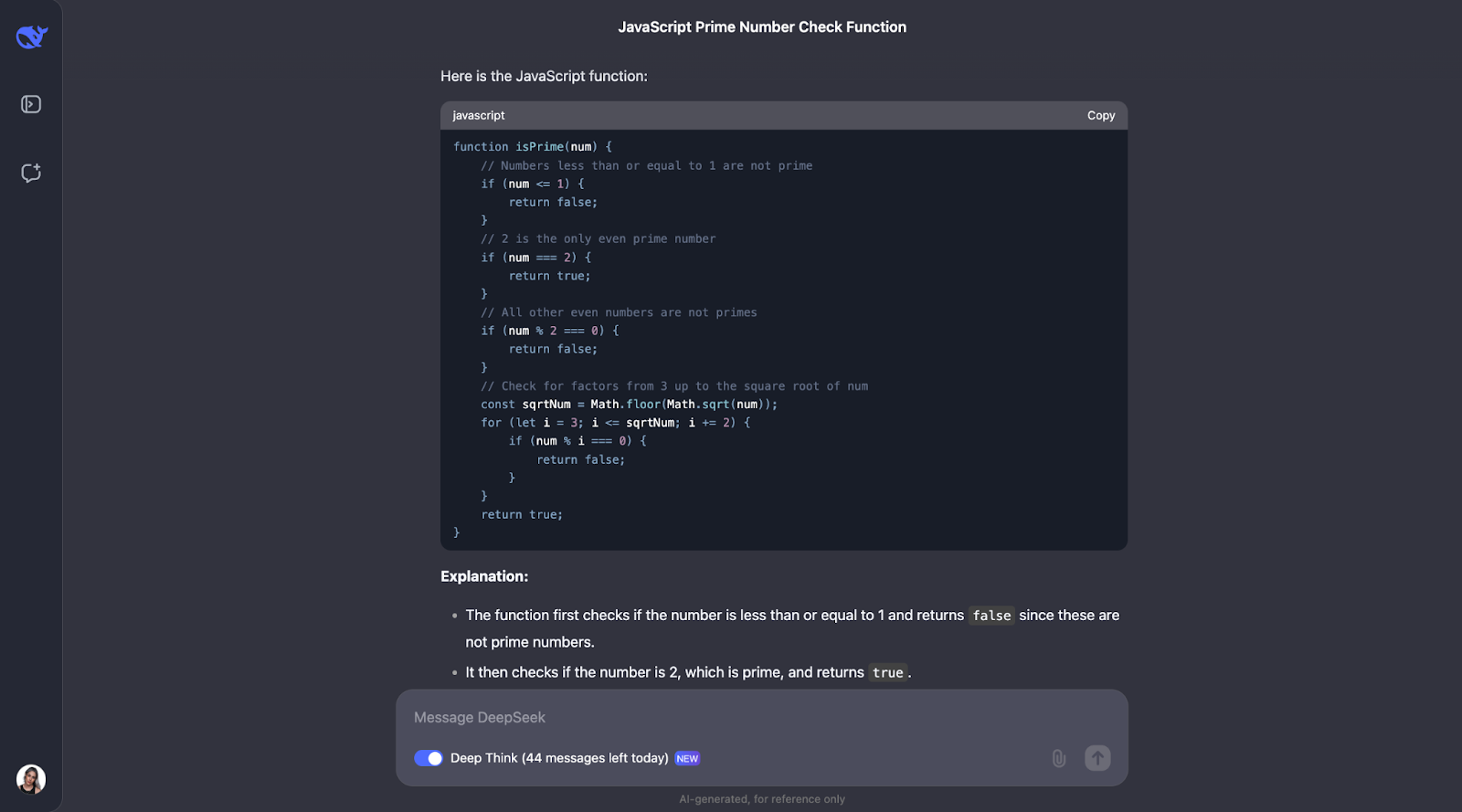
Ich denke, wir können hier ein Muster für den Denkprozess erkennen. Meistens fängt es damit an, die Schlüsselbegriffe zu definieren, die in dem Problem vorkommen. So wird zum Beispiel für dieses Problem definiert, was eine Primzahl ist.
Danach macht der Denkprozess Sinn und führt zu optimierten Schritten. Zunächst geht es um die Grundlagen: Zahlen, die kleiner oder gleich 1 sind, sind keine Primzahlen, und 2 ist die einzige gerade Primzahl. Von dort aus wird geprüft, ob die Zahl durch alle ungeraden Zahlen bis zur Quadratwurzel der Zahl teilbar ist. Das spart Zeit, denn es vermeidet unnötige Berechnungen. Anstatt jede einzelne Zahl zu prüfen, werden alle geraden Zahlen ab 2 übersprungen, was den Prozess noch schneller macht. Die Funktion verwendet Math.sqrt, um die Quadratwurzel zu finden, was die Überprüfung einschränkt und die Funktion effizient und einfach hält.
Auch hier wurde mit kleinen Beispielen getestet, wie im vorherigen Problem, z. B. mit bekannten Primzahlen und Nichtprimzahlen, um sicherzustellen, dass es wie erwartet funktioniert.
Es gibt allerdings noch Raum für Verbesserungen. Die Funktion prüft zum Beispiel nicht, ob die Eingabe tatsächlich eine Zahl ist, und könnte so besser mit Fehlern umgehen. Es könnte auch Abkürzungen für Zahlen enthalten, die auf 0 oder 5 enden, die offensichtlich keine Primzahlen sind (mit Ausnahme der 5 selbst). Ein bisschen mehr Erklärung darüber, warum gerade Zahlen übersprungen werden oder nur bis zur Quadratwurzel geprüft wird, würde Anfängern helfen, es besser zu verstehen, glaube ich.
Schließlich hätte ich erwartet, dass der Code einige Beispielverwendungstests enthält, so wie er uns die für den Python-Code im Test zuvor gegeben hat.
Kommen wir nun zu den Tests zum logischen Denken.
Ich werde ein klassisches Rätsel testen:
"Ein Mann muss mit einem Wolf, einer Ziege und einem Kohlkopf einen Fluss überqueren. Sein Boot kann nur sich selbst und eine andere Sache tragen. Wenn man ihn in Ruhe lässt, würde der Wolf die Ziege fressen, und die Ziege den Kohl. Wie kann er alles sicher transportieren?"
Ich würde erwarten, dass das Modell die folgende Antwort gibt:
Aber mal sehen, wie es mit dem Denkprozess umgeht, denn ich bin mir nicht sicher, was mich erwartet!
Ich muss auch diese Ausgabe kürzen, damit sie lesbar ist:
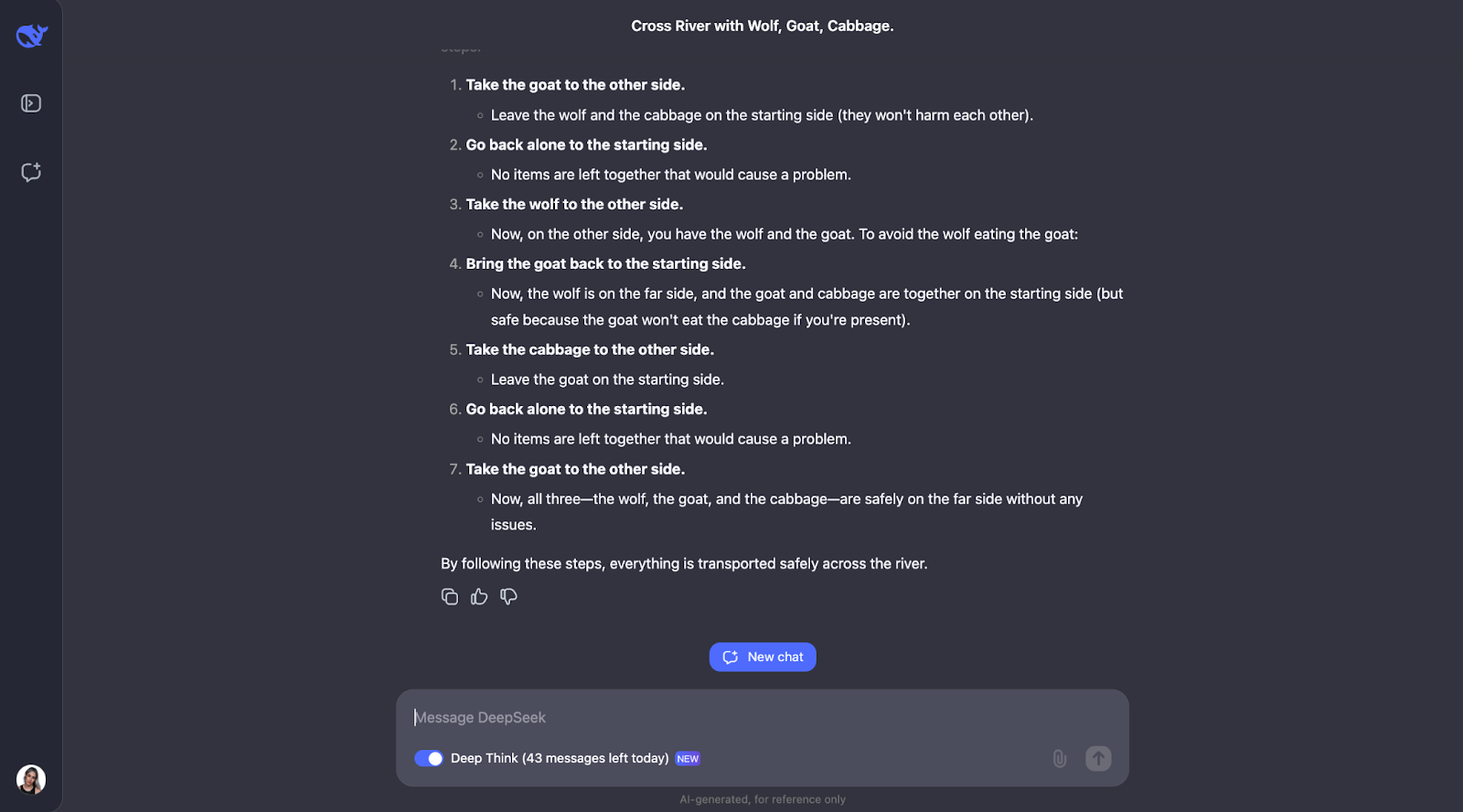
Mit dem Modell lässt sich dieses klassische Flussüberquerungsrätsel gut lösen. Er denkt sorgfältig über die Regeln nach und prüft verschiedene Möglichkeiten. Es versteht, dass einige Paare, wie der Wolf und die Ziege oder die Ziege und der Kohl, nicht allein gelassen werden können. Er überprüft auch die Einschränkungen zu Beginn. Davon ausgehend wird untersucht, was passieren würde, wenn der Mann jeden Gegenstand zuerst über den Fluss bringt, und es wird herausgefunden, ob dies Probleme verursacht.
Was ich wirklich schön finde, ist, wie das Modell seinen Plan anpasst, wenn etwas nicht funktioniert. Zum Beispiel, wenn er zuerst versucht, den Wolf zu nehmen, aber merkt, dass das Probleme verursacht, und dann die Schritte überdenkt. Diese Versuch-und-Irrtum-Methode ähnelt der Art und Weise, wie wir als Menschen das Rätsel selbst lösen könnten.
Am Ende findet das Modell die richtige Lösung und erklärt sie klar und Schritt für Schritt.
Versuchen wir es mit einer anderen:
"Du hast 12 Bälle, die alle gleich aussehen. Ein Ball ist entweder schwerer oder leichter als die anderen. Finde mit einer Waage die ungerade Kugel und bestimme, ob sie schwerer oder leichter ist, indem du sie dreimal wiegst."
Dieses klassische Logikrätsel testet die Fähigkeit des Modells, durch deduktives Denken eine optimale Strategie zu finden. Mal sehen, was passiert. Die Ausgabe war dieses Mal sehr, sehr lang, deshalb muss ich direkt zur Antwort auf springen:
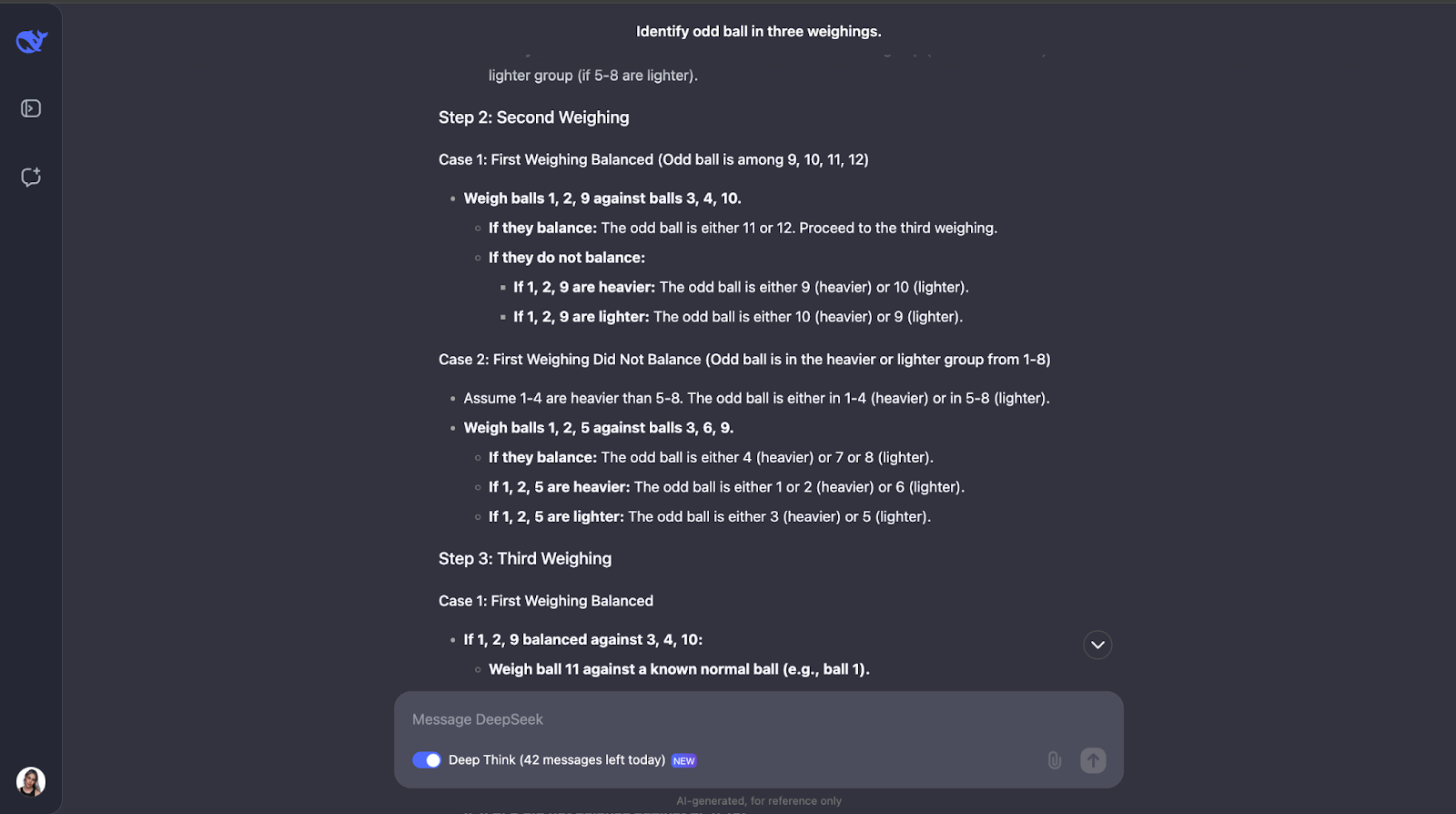

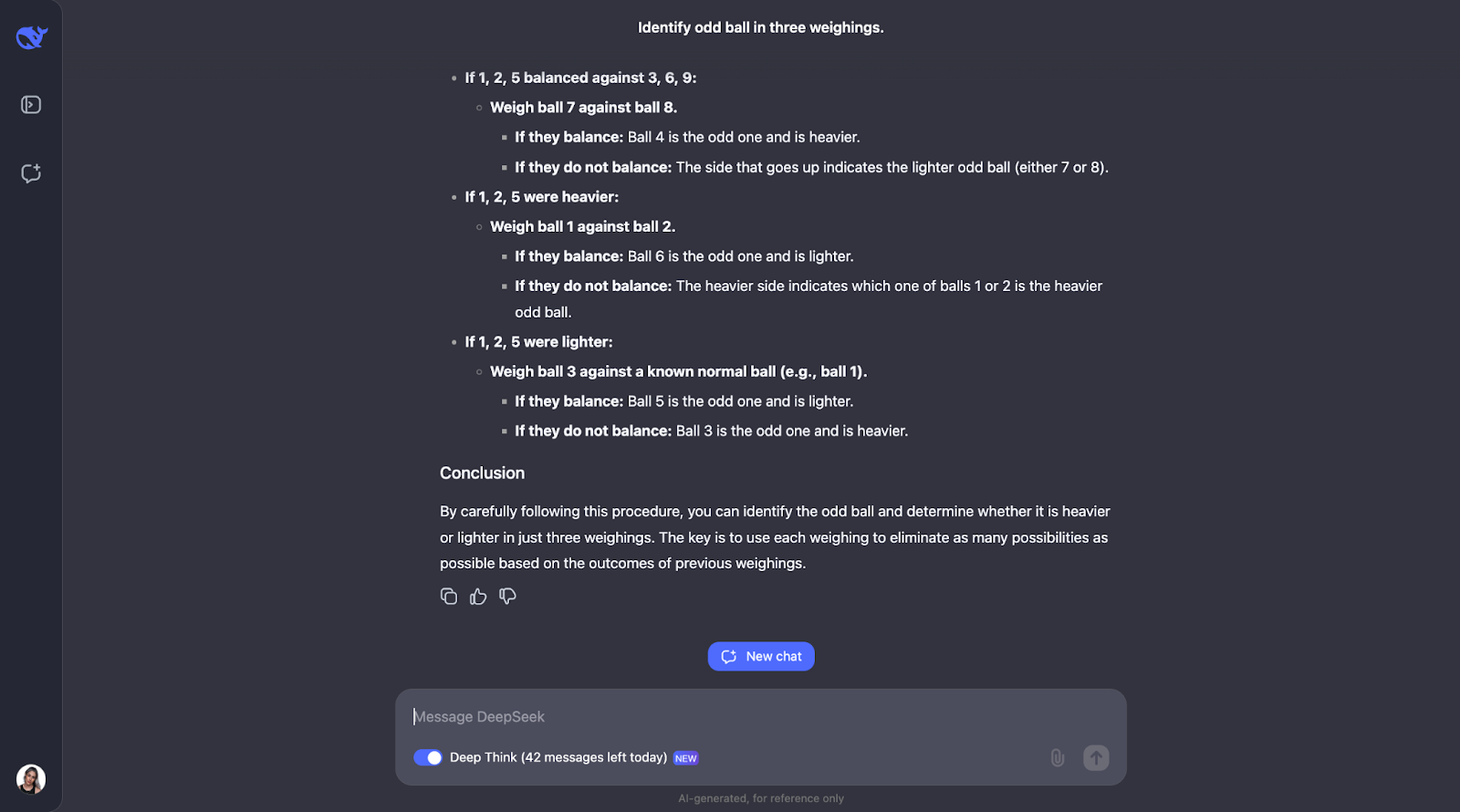
Eine weitere, bei der ich die Länge der Ausgabe völlig unterschätzt habe! Das Modell erkennt, dass das Lösen dieses Rätsels eine sorgfältige Planung erfordert, da du nur drei Versuche hast. Sie berechnet auch die Anzahl der Ergebnisse und Möglichkeiten.
Der Ansatz des Modells ist klug, weil jede Abwägung so viele Möglichkeiten wie möglich ausschließt. Sie plant alle Ergebnisse ein - ob die Waage ausgeglichen ist oder kippt - und passt den nächsten Schritt entsprechend an, wenn etwas passiert. Es ist sehr detailliert, aber die Schritte sind klar und logisch, so dass es sehr leicht zu folgen ist, auch wenn es langwierig ist,
Eine Sache, die mir sehr gut gefallen hat, ist, dass er einen systematischeren oder einfacheren Ansatz anwendet, wenn der Ansatz etwas zu komplex wird. Ich denke jedoch, dass bei Problemen wie diesem, bei dem du verschiedene Fälle, Ergebnisse und Möglichkeiten im Auge behalten musst, ein Diagramm oder eine Tabelle helfen könnte, den Gedankengang zu visualisieren und das Ergebnis besser zu verstehen.
In diesem Abschnitt werde ich DeepSeek mit anderen Modellen wie o1-preview und GPT-4o in Bezug auf die Leistung bei verschiedenen Benchmarks vergleichen. Jeder von ihnen konzentriert sich auf eine andere Fähigkeit, damit wir sehen können, welche Modelle was am besten können. Sehen wir uns die von DeepSeek gemessenen Benchmarks an:
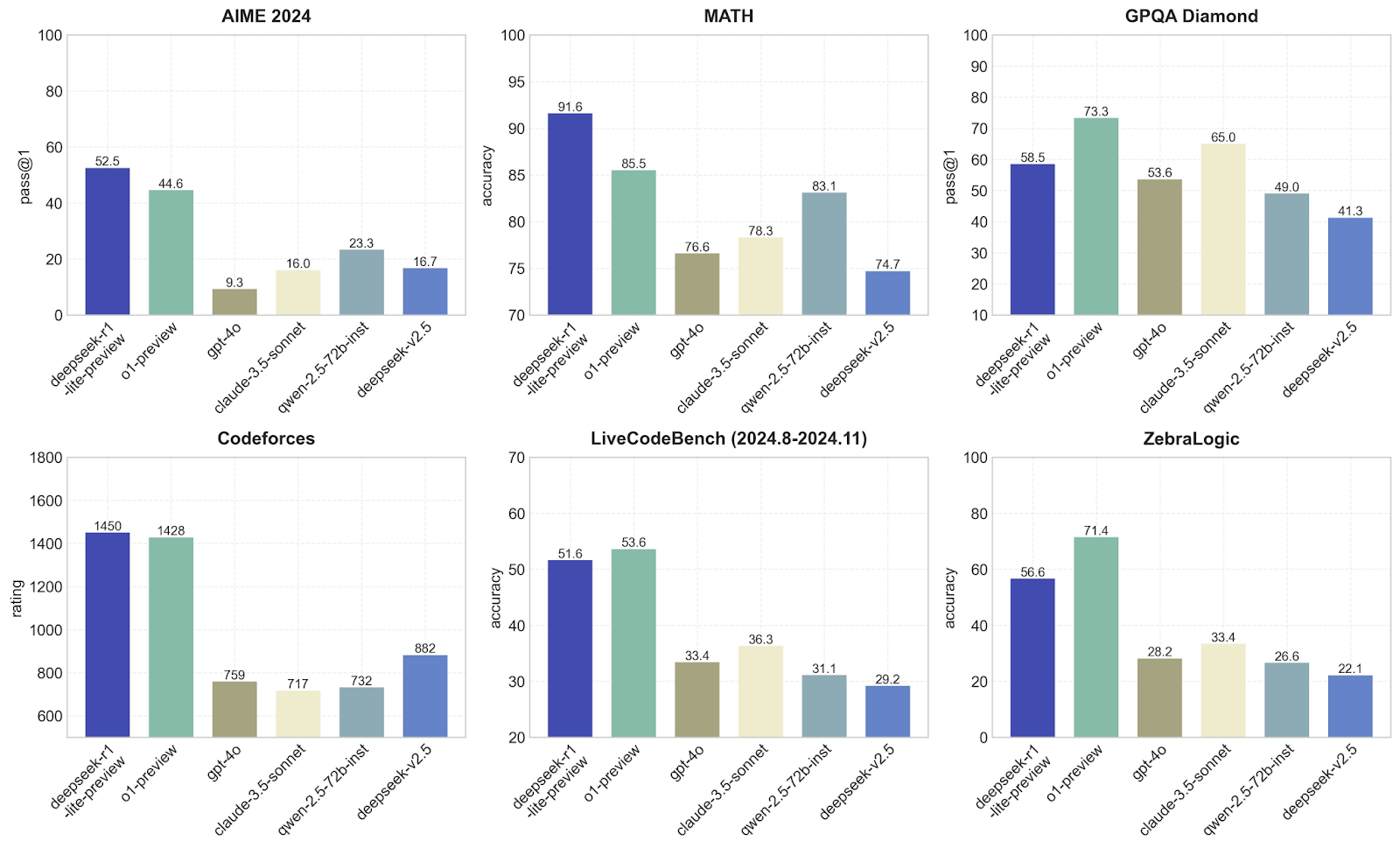
DeepSeek-r1-lite-preview ist hier eindeutig der Beste, mit einem pass@1 von 52,5, gefolgt von o1-preview mit 44,6. Andere Modelle, wie GPT-4o und claude-3.5-sonnet, schneiden mit Werten unter 23 deutlich schlechter ab. Das deutet darauf hin, dass das DeepSeek-r1-lite-preview-Modell die fortgeschrittenen mathematischen oder logischen Probleme der AIME-Benchmarks recht gut bewältigen kann, was mich nach den von mir durchgeführten Tests nicht überrascht.
DeepSeek-v1 dominiert erneut mit einer beeindruckenden Genauigkeit von 91,6, weit vor o1-preview (85,5) und viel besser als andere Modelle wie GPT-4o, die nur 76,6 erreichen. Das zeigt, dass DeepSeek sehr gut darin ist, mathematische Probleme zu lösen. Das bestätigt meine Hypothese aus den empirischen Beweisen in den Tests, die ich zuvor durchgeführt habe - keine Überraschungen bis jetzt!
Hier schneidet o1-preview besser ab als DeepSeek-v1, mit einem pass@1 von 73,3 im Vergleich zu 58,5. Andere Modelle, wie das GPT-4o, fallen mit 53,6 Punkten zurück. Das deutet darauf hin, dass o1-preview besser für Aufgaben geeignet ist, bei denen es darum geht, Fragen zu beantworten oder Probleme zu lösen, die auf logischem Denken basieren. DeepSeek zeigt immer noch eine solide Leistung, ist aber nicht so gut wie o1-preview.
Bei den konkurrierenden Programmen liegen DeepSeek-v1 (1450) und 01-preview (1428) fast gleichauf an der Spitze, während andere Modelle wie GPT-4o nur etwa 759 Punkte erreichen. Wie erwartet, zeigt dies, dass diese beiden Modelle hervorragend geeignet sind, um Programmieraufgaben zu verstehen und Code zu erzeugen.
Dabei werden die Codierfähigkeiten im Laufe der Zeit getestet, und o1-preview liegt leicht vor DeepSeek-v1 (53,6 gegenüber 51.6). Andere Modelle, wie das GPT-4o, fallen mit 33,4 weit zurück. Auch hier zeigt sich, dass sowohl DeepSeek als auch 01-preview gut zum Codieren geeignet sind, aber dass 01-preview bei diesen Aufgaben etwas besser ist.
o1-preview führt hier mit einer Genauigkeit von 71,4 im Vergleich zu 56,6 bei DeepSeek-v1. Andere Modelle schneiden viel schlechter ab. Das zeigt, dass o1-preview besser mit abstrakten Logikaufgaben wie ZebraLogic umgehen kann, die mehr kreatives oder unkonventionelles Denken erfordern, was sich mit meinen Testergebnissen deckt, denn Kreativität war definitiv nicht die Stärke von DeepSeek-v1.
Diese Diagramme bestätigen, dass DeepSeek-v1 bei mathematischen und programmiertechnischen Herausforderungen erstaunlich ist. Ich würde sagen, dass o1-preview ausgewogener ist und ein breiteres Aufgabenspektrum gut abdeckt, was es vielseitiger macht.
Schauen wir uns nun diese Grafik an:
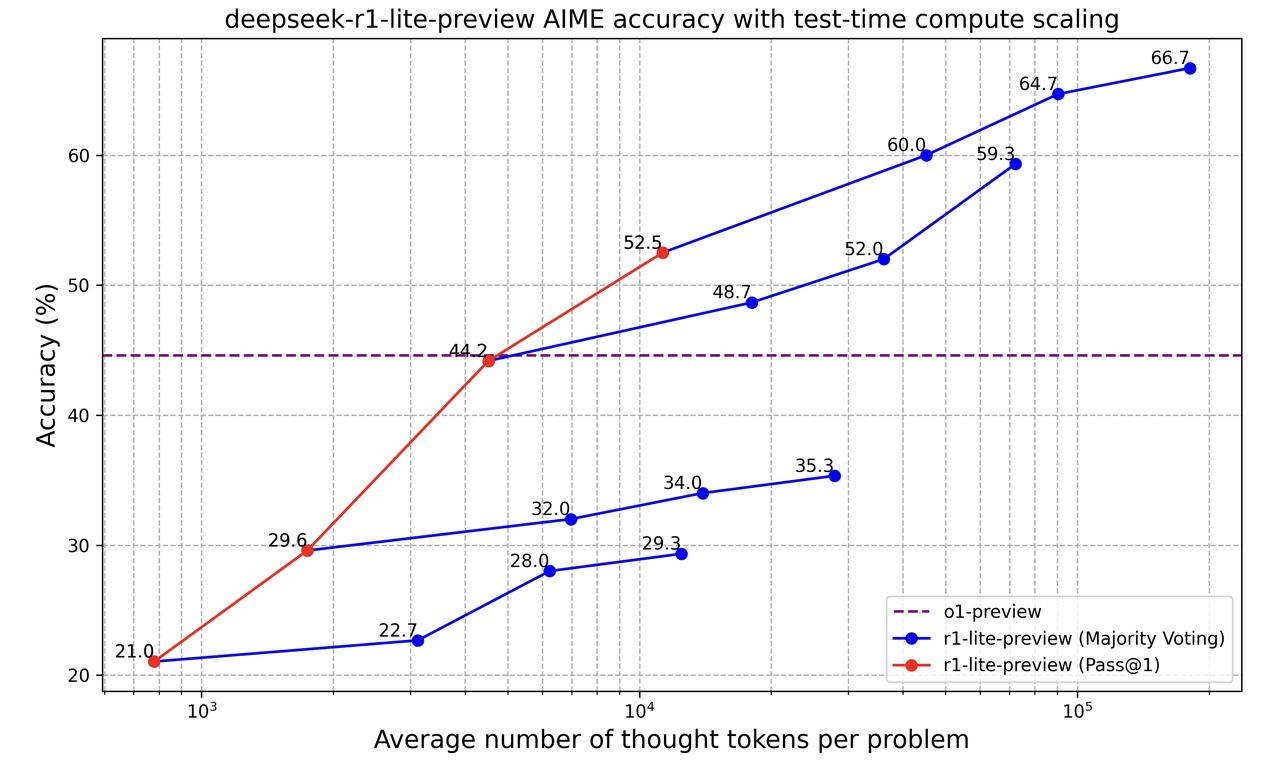
Diese Grafik zeigt, wie das "Deepseek-R1-Lite-Preview"-Modell Probleme besser löst, je mehr Informationen es verarbeitet (gemessen an der Anzahl der "Gedankentoken", die es verwendet). Er vergleicht zwei Arten, wie die Genauigkeit des Modells gemessen wird:
Die gestrichelte lila Linie stellt das o1-Vorschau-Modell dar, das eine gleichbleibende Genauigkeit hat. Am Anfang ist o1-preview besser, aber wenn DeepSeek r1-lite-preview mehr Gedanken-Token verwenden darf, überholt es o1-preview und wird viel genauer.
Diese Grafik zeigt, dass DeepSeek r1-lite-preview mehr nachdenkt und mehrere Versuche unternimmt, um seine Genauigkeit zu verbessern.
Ist DeepSeek-r1-lite-preview besser als OpenAIs o1-preview? Nun, das hängt von der Aufgabe ab. Ich würde sagen, ja, für Mathe- und Codierprobleme. Beim logischen Denken hängt es von der Aufgabe ab.
Was mich wirklich überrascht hat, war, wie er einige der Tests durchdacht hat. Es hat mich wirklich zum Nachdenken darüber gebracht, was es eigentlich bedeutet, dass ein Modell "denkt" und wie es zu den Argumentationsansätzen kommt.
Wenn du neugierig auf dieses Modell bist, kannst du es doch selbst testen. Probiere es bei den Aufgaben aus, die dich interessieren, und sieh, wie es funktioniert - vielleicht findest du es genauso überraschend wie ich!
Lerne KI mit diesen Kursen!
Lernpfad
Kurs
Kurs
Blog
Nisha Arya Ahmed
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Nathaniel Taylor-Leach
Blog
Nathaniel Taylor-Leach
8 Min.
