Curso
Limpeza de dados com o PySpark
4 h
33.2K
Data cleaning takes up 80% of the data science workflow. This is why we created this checklist to help you identify and resolve any quality issues with your data. If you want to learn more about cleaning data, check out our course on Cleaning Data in Python and R respectively.
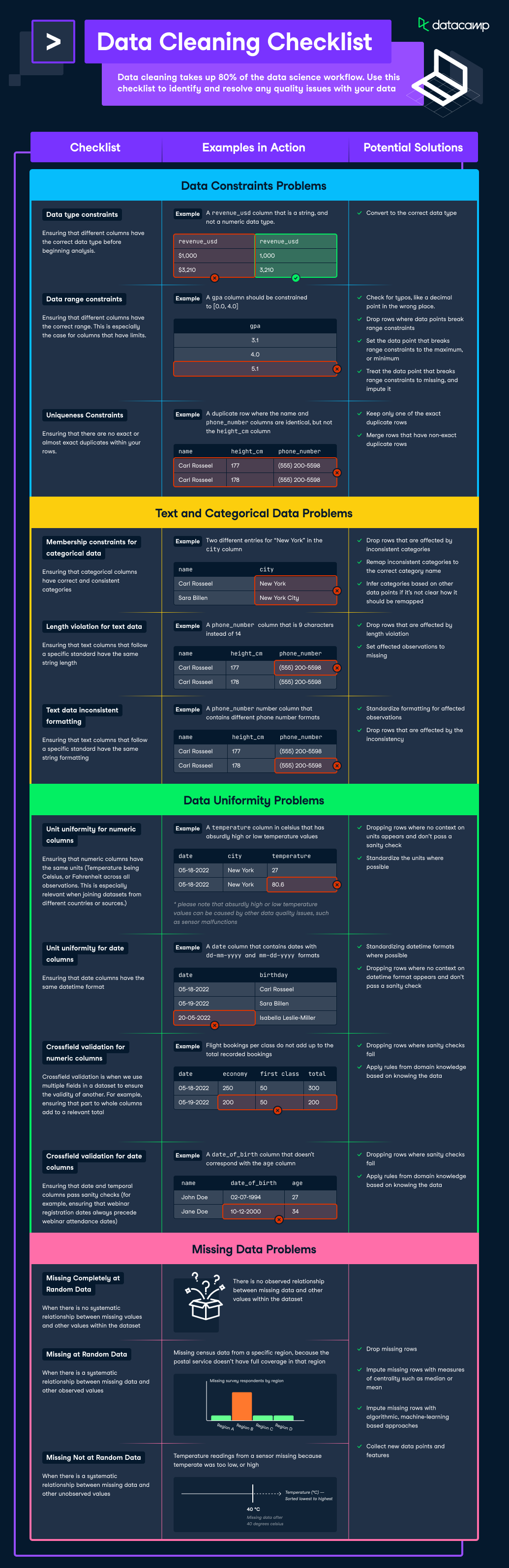
To download this infographic, press on the image above
revenue_usd column that is a string, and not a numeric data type.gpa column should be constrained to [0.0, 4.0]name and phone_number columns are identical, but not the height_cm columncity columnphone_number column that is 9 characters instead of 14phone_number column that is 9 characters instead of 14birthday column where there are dates in dd-mm-yyyy and mm-dd-yyyydate_of_birth column that doesn't correspond with the age columnLearn more about Data Cleaning
Curso
Curso
Curso
blog
DataCamp Team
4 min
blog
Adel Nehme
blog
DataCamp Team
cheat-sheet
Joe Franklin
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui



