Programa
Fundamentos da IA
10 h
De acordo com os exemplos da Meta, os modelos podem analisar gráficos incorporados em documentos e resumir as principais tendências. Eles também podem interpretar mapas, determinar qual parte de uma trilha de caminhada é a mais íngreme ou calcular a distância entre dois pontos.
Essa integração de raciocínio de texto e imagem oferece uma ampla gama de possíveis aplicações, incluindo:
Os modelos de visão do Llama 3.2 são abertos e personalizáveis. Os desenvolvedores podem fazer o ajuste fino tanto as versões pré-treinadas quanto as alinhadas desses modelos usando o Meta's Torchtune da Meta.
Além disso, esses modelos podem ser implantados localmente por meio do Torchchatreduzindo a dependência da nuvem e fornecendo uma solução para os desenvolvedores que desejam implantar implantar sistemas de IA no local ou em ambientes com recursos limitados.
Os modelos de visão também estão disponíveis para teste por meio do Meta AI, o assistente inteligente do Meta.
Para permitir que os modelos de visão do Llama 3.2 compreendam textos e imagens, o Meta integrou um codificador de imagem codificador de imagem no modelo de linguagem existente usando adaptadores especiais. Esses adaptadores vinculam os dados de imagem às partes de processamento de texto do modelo, permitindo que ele manipule os dois tipos de entrada.
O processo de treinamento começou com o modelo de linguagem Llama 3.1. Primeiro, a equipe o treinou em grandes conjuntos de imagens combinadas com descrições de texto para ensinar o modelo a conectar os dois. Em seguida, eles o refinaram usando dados mais limpos e específicos para melhorar sua capacidade de entender e raciocinar sobre o conteúdo visual.
Nos estágios finais, o Meta usou técnicas como ajuste fino e dados sintéticos para garantir que o modelo forneça respostas úteis e se comporte de forma segura.
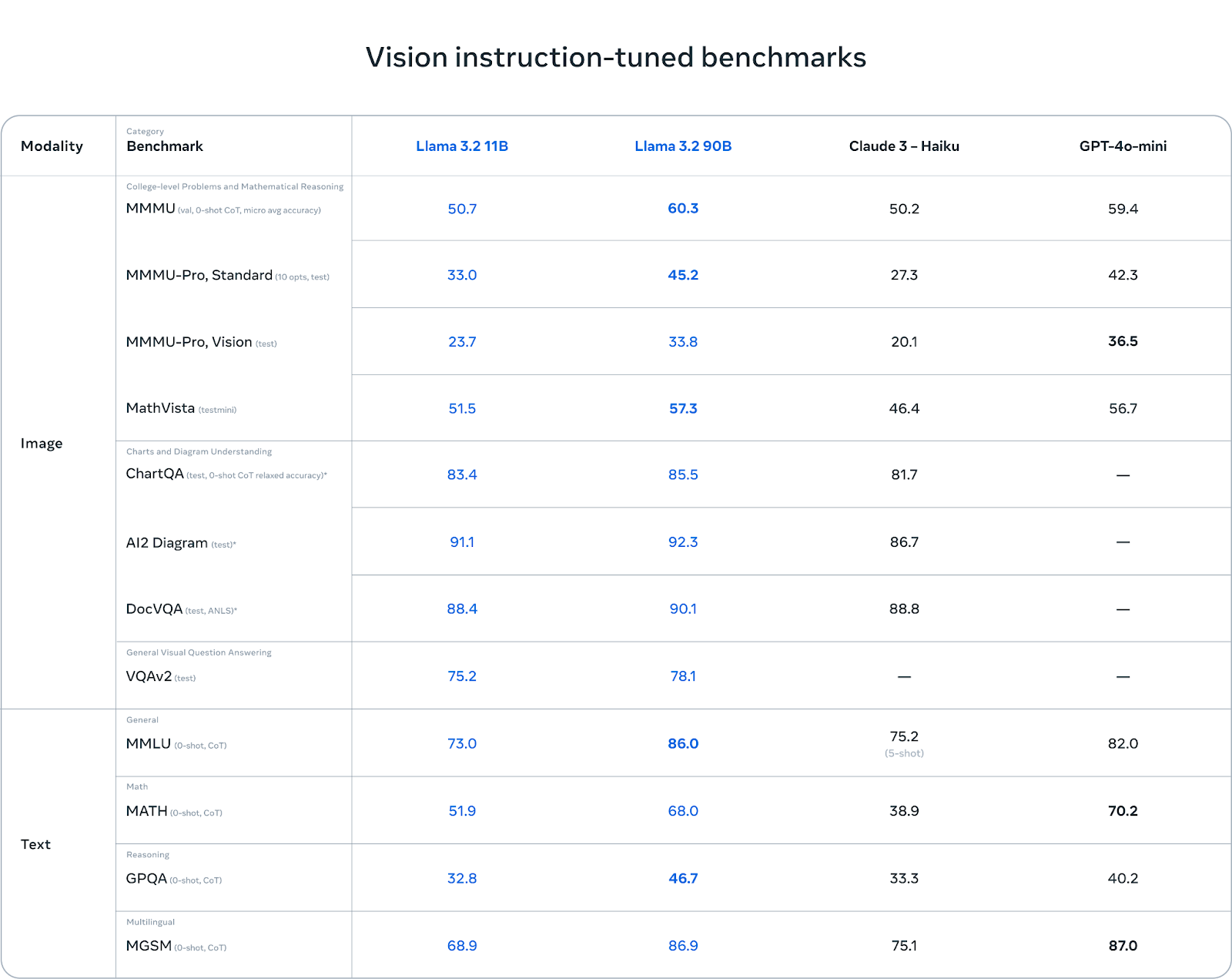
Os modelos de visão do Llama 3.2 brilham na compreensão de gráficos e diagramas. Em benchmarks como AI2 Diagram (92,3) e DocVQA (90,1), o Llama 3.2 supera o Claude 3 Haiku. Isso o torna uma excelente opção para tarefas que envolvem compreensão em nível de documento, resposta a perguntas visuais e extração de dados de gráficos.
Em tarefas multilíngues (MGSM), o Llama 3.2 também tem um bom desempenho, quase igualando o GPT-4o-mini com uma pontuação de 86,9, o que o torna uma opção sólida para desenvolvedores que trabalham com vários idiomas.
Fonte: Meta AI
Embora o Llama 3.2 tenha um bom desempenho em tarefas baseadas em visão, ele enfrenta desafios em outras áreas. No MMMU-Pro Vision, que testa o raciocínio matemático com base em dados visuais, o GPT-4o-mini supera o Llama 3.2 com uma pontuação de 36,5 em comparação com 33,8 do Llama.
Da mesma forma, no benchmark MATH, o desempenho do GPT-4o-mini (70,2) supera significativamente o do Llama 3.2 (51,9), mostrando que o Llama ainda pode ser aprimorado em tarefas de raciocínio matemático.
Outro avanço significativo no Llama 3.2 é a introdução de modelos leves projetados para dispositivos móveis e de borda. Esses modelos, com 1 bilhão e 3 bilhões de parâmetros, são otimizados para serem executados em hardware menor, mantendo um compromisso razoável com o desempenho.
Esses modelos são projetados para serem executados em dispositivos móveis, proporcionando processamento local rápido, sem a necessidade de enviar dados para a nuvem. A execução de modelos localmente em dispositivos de borda oferece dois benefícios principais:
Os modelos leves do Llama 3.2 são otimizados para processadores Arm e estão habilitados no hardware da Qualcomm e da MediaTek, que alimentam muitos dispositivos móveis e de ponta atualmente.
Os modelos leves são projetados para uma variedade de aplicações práticas no dispositivo, como:
1. Resumo: Os usuários podem resumir grandes quantidades de texto, como e-mails ou anotações de reuniões, diretamente em seus dispositivos, sem depender de serviços de nuvem.
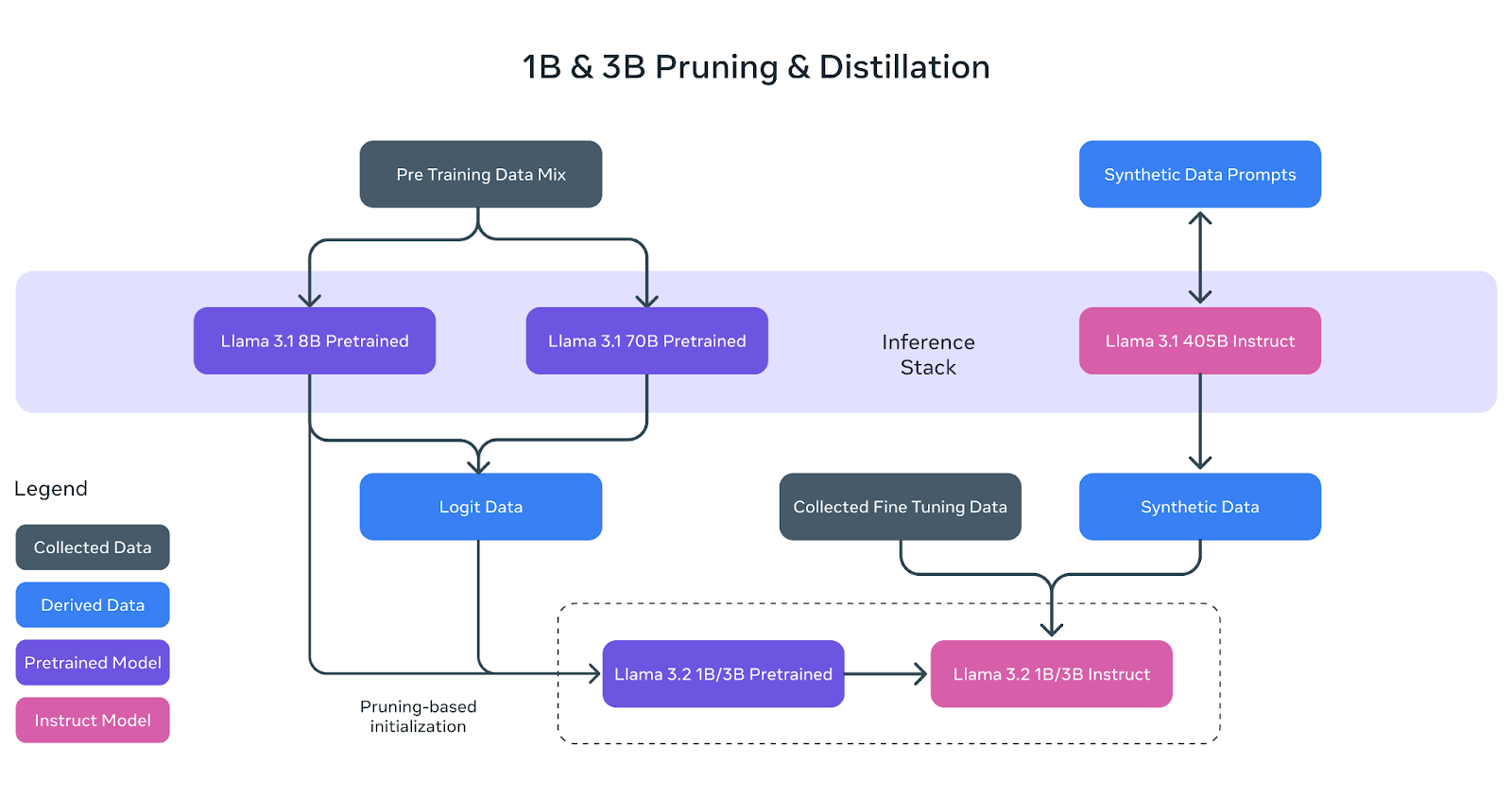
Os modelos leves do Llama 3.2 (1B e 3B) foram criados para se adaptarem de forma eficiente a dispositivos móveis e de borda, mantendo um desempenho sólido. Para isso, o Meta usou duas técnicas principais: poda e destilação.
Fonte: Meta AI
A poda ajuda a reduzir o tamanho dos modelos originais da Llama, removendo partes menos críticas da rede e mantendo o máximo de conhecimento possível. No caso dos modelos 1B e 3B da Llama 3.2, esse processo começou com o modelo pré-treinado 8B maior da Llama 3.1.
Com a poda sistemática, a equipe do Meta AI conseguiu criar versões menores e mais eficientes do modelo sem perda significativa de desempenho. Isso é representado no diagrama acima, em que o modelo pré-treinado 8B (caixa roxa) é podado e refinado para se tornar a base dos modelos menores Llama 3.2 1B/3B.
A destilação é o processo de transferência de conhecimento de um modelo maior e mais poderoso (o "professor") para um modelo menor (o "aluno"). Na Llama 3.2, os logits (previsões) dos modelos maiores Llama 3.1 8B e Llama 3.1 70B foram usados para ensinar os modelos menores.
Dessa forma, os modelos menores 1B e 3B poderiam aprender a executar tarefas com mais eficiência, apesar de seu tamanho reduzido. O diagrama acima mostra como esse processo usa dados de logits dos modelos maiores para orientar os modelos 1B e 3B durante o pré-treinamento.
Após a poda e a destilação, os modelos 1B e 3B foram submetidos ao pós-treinamento, semelhante aos modelos anteriores da Llama. Isso envolveu técnicas como ajuste fino supervisionado, amostragem de rejeição e otimização direta de preferências para alinhar os resultados dos modelos com as expectativas do usuário.
Também foram gerados dados sintéticos para garantir que os modelos pudessem lidar com uma ampla gama de tarefas, como resumo, reescrita e acompanhamento de instruções.
Conforme mostrado no diagrama, os modelos finais de instrução da Llama 3.2 1B/3B são o resultado de poda, destilação e pós-treinamento extensivo.
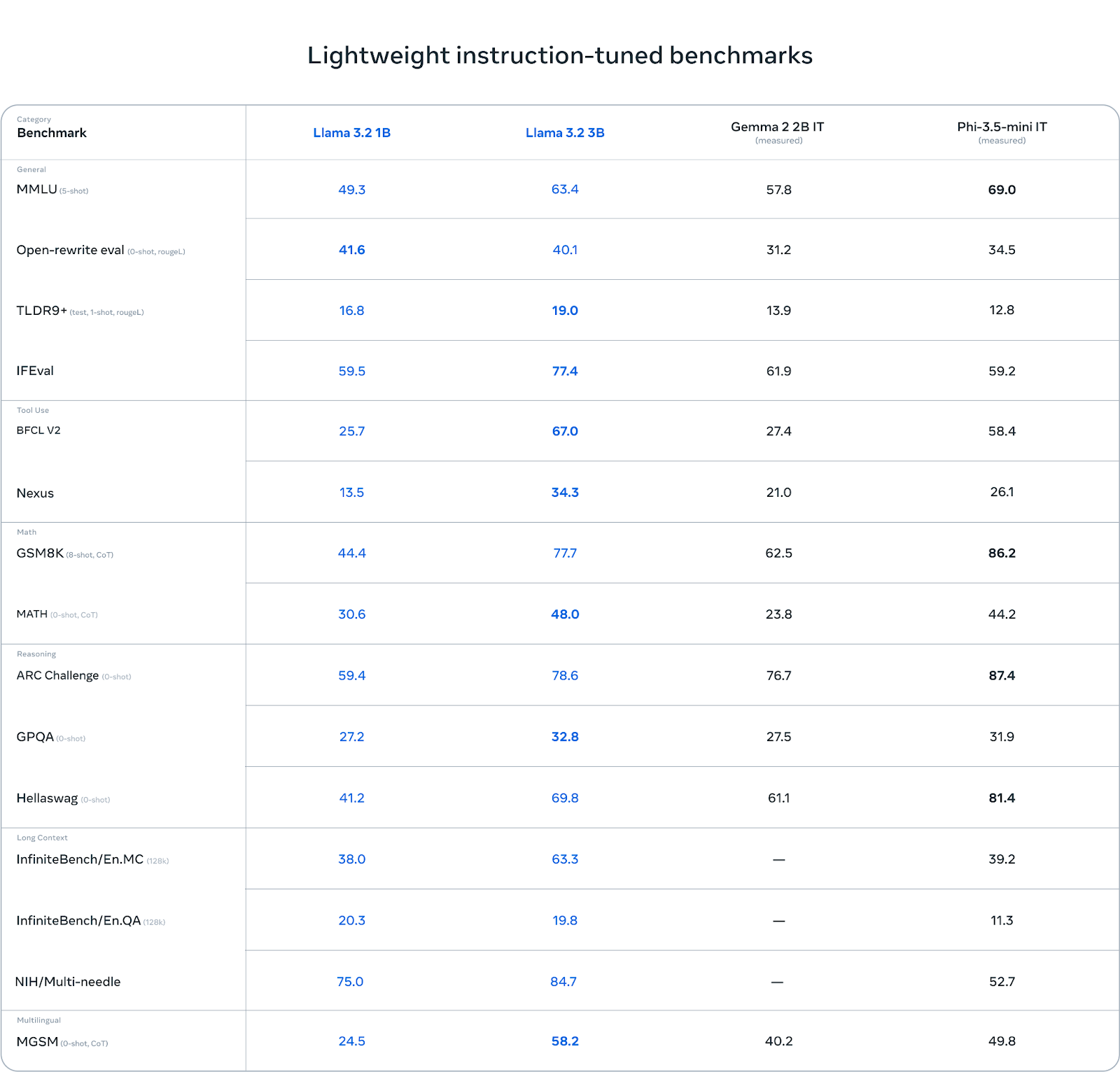
A Llama 3.2 3B se destaca em algumas categorias, especialmente em tarefas que envolvem raciocínio. Por exemplo, no ARC Challenge, ele obteve 78,6 pontos, superando o Gemma (76,7) e ficando um pouco atrás do Phi-3.5-mini (87,4). Da mesma forma, ele se sai bem no benchmark Hellawag, atingindo 69,8, superando o Gemma e permanecendo competitivo com o Phi.
Em tarefas de uso de ferramentas como o BFCL V2, o Llama 3.2 3B também se destaca com uma pontuação de 67,0, à frente de ambos os concorrentes. Isso mostra que o modelo 3B lida com o acompanhamento de instruções e tarefas relacionadas a ferramentas de forma eficaz.
Fonte: Meta AI
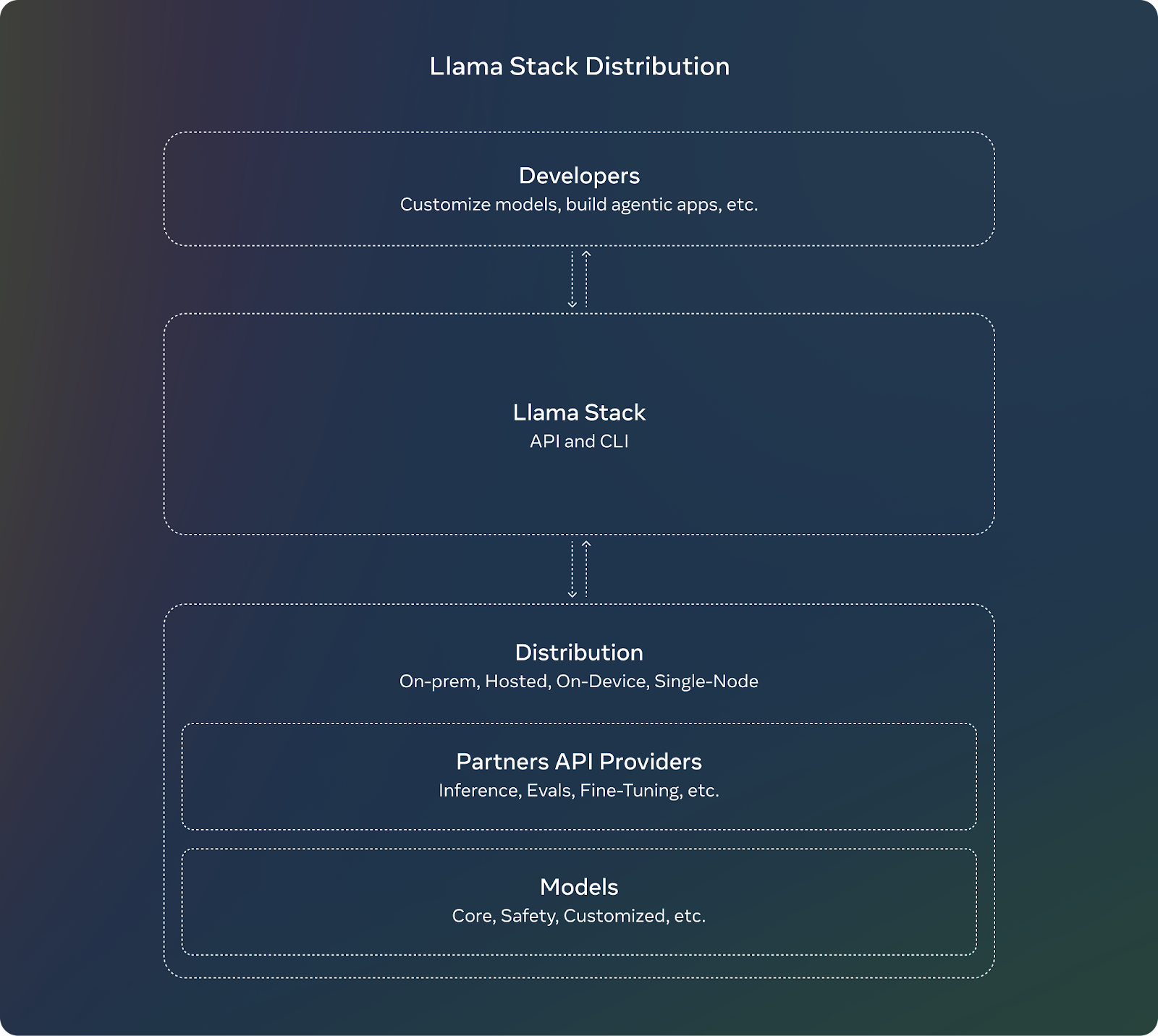
Para complementar o lançamento do Llama 3.2, a Meta está introduzindo o Llama Stack. Para os desenvolvedores, usar o Llama Stack significa que eles não precisam se preocupar com os detalhes complexos da configuração ou implantação de modelos grandes. Eles podem se concentrar na criação de seus aplicativos e confiar que o Llama Stack cuidará de grande parte do trabalho pesado.
Esses são os principais recursos do Llama Stack:
Fonte: Meta AI
A Meta continua seu foco em IA responsável com o Llama 3.2. O Llama Guard 3 foi atualizado para incluir uma versão habilitada para visão que suporta os novos recursos multimodais do Llama 3.2. Isso garante que os aplicativos que usam os novos recursos de compreensão de imagem permaneçam seguros e em conformidade com diretrizes éticas.
Além disso, o Llama Guard 3 1B foi otimizado para ser implantado em ambientes com recursos mais limitados, tornando-o menor e mais eficiente do que as versões anteriores.
O acesso e o download dos modelos do Llama 3.2 são bastante simples. A Meta disponibilizou esses modelos em várias plataformas, incluindo seu próprio site e a Hugging Face, uma plataforma popular para hospedagem e compartilhamento de modelos de IA.
Você pode baixar os modelos Llama 3.2 diretamente do site oficial da Llama. A Meta oferece tanto os modelos menores e leves (1B e 3B) quanto os modelos maiores habilitados para visão (11B e 90B) para uso dos desenvolvedores.
Cara de Abraço é outra plataforma em que os modelos Llama 3.2 estão disponíveis. Ele oferece acesso fácil e é comumente usado por desenvolvedores na comunidade de IA.
Os modelos Llama 3.2 estão disponíveis para desenvolvimento imediato em nosso amplo ecossistema de plataformas de parceiros, incluindo AMD, AWS, Databricks, Dell, Google Cloud, Groq, IBM, Intel, Microsoft Azure, NVIDIA, Oracle Cloud, Snowflake e outros.
O lançamento do Llama 3.2 pela Meta apresenta os primeiros modelos multimodais da série, com foco em duas áreas principais: modelos habilitados para visão e modelos leves para dispositivos móveis e de borda.
Os modelos multimodais 11B e 90B agora podem lidar com processamento de texto e imagem, enquanto os modelos 1B e 3B são otimizados para uso local eficiente em dispositivos menores.
Neste artigo, apresentei o essencial: como esses modelos funcionam, suas aplicações práticas e como você pode acessá-los.
Aprenda IA com estes cursos!
Programa
Curso
Curso
blog
Ryan Ong
8 min
blog
Abid Ali Awan
8 min
Tutorial
Abid Ali Awan
Tutorial
Zoumana Keita
Tutorial
Josep Ferrer
Tutorial
Ryan Ong

