
Curso
Fine-Tuning with Llama 3
2 h
3.7K
Neste tutorial, vamos dar uma olhada no FunctionGemma, um modelo de linguagem leve para chamada de funções do Google DeepMind, e vou explicar por que o ajuste fino é essencial para usar a ferramenta de forma confiável e em conformidade com o esquema.
Vamos começar configurando um ambiente Kaggle habilitado para GPU e, em seguida, carregar e preparar o conjunto de dados e o modelo FunctionGemma básico.
Depois, vamos fazer algumas avaliações antes do ajuste fino pra definir uma base pra escolher as ferramentas e ver se as chamadas de função estão certas. Depois, vamos ajustar o FunctionGemma usando treinamento supervisionado e avaliar seu desempenho após o treinamento para ver se o ajuste foi feito corretamente.
Se você está procurando exercícios práticos para ajudá-lo a aprender o ajuste fino, recomendo conferir o curso curso Ajustes finos com Llama 3.
A FunctionGemma é uma versão especializada do modelo aberto Gemma 3 270M , feita especialmente para chamar funções e usar ferramentas, em vez de conversas gerais.
Ele usa a mesma arquitetura do Gemma 3, mas inclui um formato dedicado e foco em treinamento que permite gerar resultados estruturados representando chamadas de função.
O FunctionGemma é lançado como um modelo básico que os desenvolvedores podem ajustar para casos de uso específicos. Seu tamanho e design o tornam leve, eficiente e implantável em dispositivos com recursos limitados, como laptops e hardware de ponta.
Embora o FunctionGemma seja treinado para chamadas de função, modelos desse tamanho funcionam melhor quando são especializados por meio de ajustes em dados específicos da tarefa.
O ajuste fino ajuda o modelo a aprender padrões estáveis para escolher a função certa de um conjunto de ferramentas e formatar os argumentos certos para casos de uso reais.
Esse processo leva a resultados estruturados mais consistentes e previsíveis, o que, por sua vez, melhora a confiabilidade nos fluxos de trabalho práticos.
Vamos ver os passos necessários para ajustar a FunctionGemma.
Comece acessando o Kaggle e criando um novo caderno. Depois de abrir o notebook, localize o painel de opções da sessão no lado direito e defina o acelerador como GPU (T4 ×2).
Isso ativa a aceleração da GPU para a sessão e permite que você ajuste o modelo usando os recursos de computação gratuitos do Kaggle.
Depois de ativar a GPU, crie uma nova célula de código e execute o seguinte comando para instalar todas as dependências Python necessárias. O kernel pode demorar um pouco para iniciar, após o que os pacotes serão instalados automaticamente.
%pip -q install -U datasets accelerate trl kagglehub sentencepiece huggingface_hub tqdm evaluate jiwerDepois, adicione seu token de acesso ao Hugging Face com segurança.
No menu superior, abra Complementos → Segredos e clique em Adicionar Segredo. Defina o nome secreto como HUGGINGFACE_TOKEN e cole sua chave API do Hugging Face como valor.
Usar o Kaggle Secrets é mais seguro do que codificar variáveis de ambiente ou tokens diretamente no notebook.
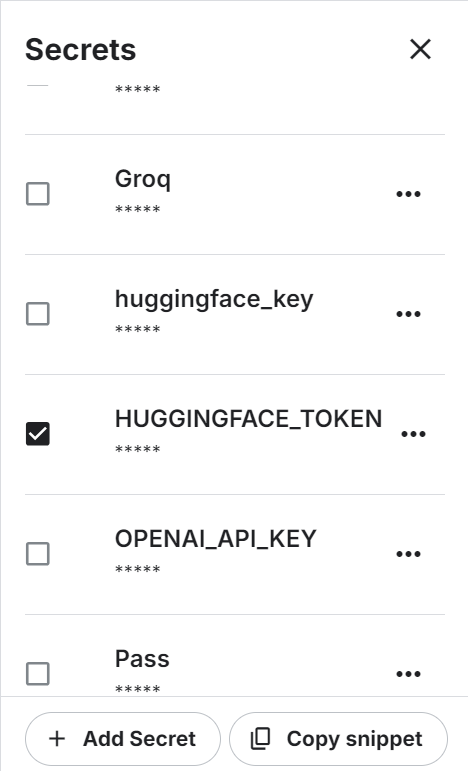
Depois que o segredo for salvo, o Kaggle vai te dar um trecho de código pra acessá-lo programaticamente.
Use o código a seguir para fazer a autenticação no Hugging Face Hub:
from kaggle_secrets import UserSecretsClient
from huggingface_hub import login
hf_token = UserSecretsClient().get_secret("HUGGINGFACE_TOKEN")
if not hf_token:
raise ValueError("HUGGINGFACE_TOKEN not found in Kaggle Secrets.")
login(token=hf_token)Depois de passar na autenticação, você vai poder acessar modelos e conjuntos de dados restritos, além de enviar seu modelo FunctionGemma ajustado para o Hugging Face Hub para compartilhar e reutilizar.
A Hermes Reasoning Tool-Use é um conjunto de dados aberto em inglês no formato de raciocínio sobre o uso de ferramentas, com exemplos estruturados projetados para treinar e avaliar modelos em tarefas de seleção de ferramentas e chamada de funções no estilo JSON.
Tem um monte de exemplos de raciocínio sobre o uso de ferramentas com prompts em linguagem natural e esquemas de ferramentas num formato que dá pra ajustar com supervisão.
Neste tutorial, vamos usar um subconjunto do conjunto de dados para fazer experimentos mais rápidos.
Primeiro, defina uma semente aleatória e o número total de exemplos a serem usados. Depois, divide os dados em partes para treinamento e avaliação:
from datasets import load_dataset
SEED = 40
N_TOTAL = 3000
N_EVAL = 300
N_TRAIN = N_TOTAL - N_EVALDepois, carregue o conjunto de dados, embaralhe-o e crie os subconjuntos de treinamento e avaliação:
raw = load_dataset("interstellarninja/hermes_reasoning_tool_use", split="train")
raw = raw.shuffle(seed=SEED).select(range(N_TOTAL))
train_ds = raw.select(range(N_TRAIN))
eval_ds = raw.select(range(N_TRAIN, N_TOTAL))
print("train:", len(train_ds), "eval:", len(eval_ds))
Isso te dá 2.700 amostras de treinamento e 300 amostras de avaliação, que são suficientes para mostrar o ajuste fino, mantendo os requisitos de computação sob controle.
train: 2700 eval: 300Neste tutorial, a gente usa o KaggleHub para carregar o modelo FunctionGemma direto no notebook do Kaggle.
O KaggleHub resolve automaticamente a localização do modelo e o disponibiliza no ambiente do notebook, eliminando a necessidade de downloads manuais do Hugging Face.
import kagglehub
from transformers import AutoProcessor, AutoModelForCausalLM
model_path = kagglehub.model_download("google/functiongemma/transformers/functiongemma-270m-it")Depois de rodar a célula acima, os arquivos do modelo vão aparecer no seção Input do notebook Kaggle, confirmando que o modelo foi carregado com sucesso e está disponível localmente.
Assim que o modelo estiver disponível, carregamos o processador e o modelo na memória da GPU.
O processador cuida dos modelos de bate-papo e da formatação do esquema da ferramenta, enquanto o modelo é responsável por gerar chamadas de função estruturadas.
Definir device_map="auto" garante que o modelo seja colocado na GPU disponível, e dtype="auto" escolhe uma precisão eficiente que o hardware suporta.
processor = AutoProcessor.from_pretrained(model_path, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="auto", device_map="auto")
tokenizer = processor.tokenizer if hasattr(processor, "tokenizer") else processor
print("dtype:", model.dtype, "| device:", model.device)Isso confirma que a FunctionGemma foi carregada corretamente, colocada na GPU e está pronta para avaliação e ajuste fino.
dtype: torch.bfloat16 | device: cuda:1Antes de ajustar o FunctionGemma, precisamos padronizar como as ferramentas são representadas e extrair de forma confiável as chamadas de função corretas (gold) do conjunto de dados.
O conjunto de dados Hermes Reasoning Tool-Use pode guardar definições de ferramentas em vários formatos, então essa etapa transforma tudo em uma estrutura consistente que a gente pode usar para o ajuste supervisionado.
Começamos normalizando o campo tools. No conjunto de dados, tools pode aparecer como uma lista Python, uma string JSON ou pode estar completamente ausente.
A função auxiliar abaixo transforma todas as representações válidas numa lista Python limpa e ignora com segurança entradas malformadas ou vazias.
import re, json
def normalize_tools_field(tools):
if tools is None:
return []
if isinstance(tools, list):
return tools
if isinstance(tools, str):
s = tools.strip()
if not s:
return []
try:
parsed = json.loads(s)
return parsed if isinstance(parsed, list) else []
except Exception:
return []
return []Depois, a gente normaliza os tipos de parâmetros. As definições de ferramentas Hermes costumam usar anotações de tipo informais, como str,int ou tipos de contêiner, como List[str]. A função abaixo transforma isso em tipos JSON Schema válidos que são compatíveis com a chamada de função Hugging Face.
def _parse_hermes_type(t) -> dict:
if t is None:
return {"type": "string"}
if isinstance(t, dict):
return t if "type" in t else {"type": "object"}
if isinstance(t, list):
return {"type": "array"}
if not isinstance(t, str):
return {"type": "string"}
t = t.strip()
prim = {
"str": "string", "string": "string",
"int": "integer", "integer": "integer",
"float": "number", "number": "number",
"bool": "boolean", "boolean": "boolean",
"dict": "object", "object": "object",
"list": "array", "array": "array",
}
if t.lower() in prim:
return {"type": prim[t.lower()]}
m = re.match(r"List\[(.+)\]$", t)
if m:
return {"type": "array", "items": _parse_hermes_type(m.group(1).strip())}
m = re.match(r"Dict\[(.+),\s*(.+)\]$", t)
if m:
return {"type": "object", "additionalProperties": _parse_hermes_type(m.group(2).strip())}
return {"type": "string"}Usando esses utilitários, a gente transforma as definições de ferramentas no estilo Hermes em esquemas de Hugging Face {"type": "function", "function": {...}}. Essa função aceita dois formatos:
Para o formato por argumento, essa implementação trata os parâmetros listados como obrigatórios se uma lista obrigatória não for explicitamente fornecida.
def hermes_tools_to_hf_schema(tools_field):
"""
Handles both:
- Hermes per-arg style: {"parameters": {"x":{"type":"str"}, ...}}
- Already-JSON-schema style: {"parameters":{"type":"object","properties":...,"required":[...]}}
"""
hermes_tools = normalize_tools_field(tools_field)
out = []
for tool in hermes_tools:
if not isinstance(tool, dict):
continue
name = tool.get("name")
desc = tool.get("description", "")
params = tool.get("parameters", {}) or {}
# If params already look like JSON schema (best case)
if isinstance(params, dict) and "type" in params and "properties" in params:
json_schema_params = params
if "required" not in json_schema_params:
json_schema_params["required"] = []
else:
props, req = {}, []
if isinstance(params, dict):
for p_name, p_spec in params.items():
p_spec = p_spec or {}
if isinstance(p_spec, dict):
p_desc = p_spec.get("description", "")
p_type = p_spec.get("type", "str")
else:
p_desc, p_type = "", "str"
frag = dict(_parse_hermes_type(p_type))
if p_desc:
frag["description"] = p_desc
props[p_name] = frag
req.append(p_name)
json_schema_params = {"type": "object", "properties": props, "required": req}
out.append({
"type": "function",
"function": {
"name": name,
"description": desc,
"parameters": json_schema_params,
}
})
return outA gente define um pequeno auxiliar para pegar os esquemas de ferramentas convertidos para cada exemplo de conjunto de dados:
def get_tools_hf(ex):
return hermes_tools_to_hf_schema(ex.get("tools"))Depois, a gente pega a chamada da ferramenta ouro da conversa. As conversas do Hermes podem ter várias voltas, então analisamos blocos {...} e pegamos o primeiro objeto de chamada de ferramenta válido (nome + argumentos). Isso mantém a supervisão simples e consistente.
TOOL_CALL_RE = re.compile(r"<tool_call>\s*(\{.*?\})\s*</tool_call>", re.DOTALL)
def extract_first_tool_call_obj(text: str):
if not text:
return None
m = TOOL_CALL_RE.search(text)
if not m:
return None
try:
obj = json.loads(m.group(1))
if isinstance(obj, dict) and "name" in obj and "arguments" in obj:
return obj
except Exception:
return None
return NonePara alinhar a chamada da ferramenta com a tarefa correta do usuário, a gente analisa o histórico de conversas, encontra a mensagem do usuário que combina com o conjunto de dados task e, em seguida, pega a resposta do assistente logo depois dela. Se a resposta do assistente tiver uma chamada de ferramenta, a gente devolve como rótulo de ouro.
def _role(turn):
return (turn.get("from") or "").lower().strip()
def get_gold_tool_call_task_aligned(ex):
task = (ex.get("task") or "").strip()
conv = ex.get("conversations") or []
if not conv:
return None
idx = None
if task:
for i, t in enumerate(conv):
if _role(t) in ["human", "user"]:
val = (t.get("value") or "").strip()
if val == task or task in val or val in task:
idx = i
break
if idx is None:
for i in range(len(conv)-1, -1, -1):
if _role(conv[i]) in ["human", "user"]:
idx = i
break
if idx is None:
return None
for j in range(idx+1, len(conv)):
if _role(conv[j]) in ["gpt", "assistant", "model"]:
gold = extract_first_tool_call_obj(conv[j].get("value", ""))
if gold:
return gold
if _role(conv[j]) in ["human", "user"]:
break
return NoneNo final desta etapa, cada exemplo de conjunto de dados utilizável tem:
Agora precisamos converter esses valores em Ajustes supervisionados (SFT) no formato exato que o FunctionGemma espera, usando as funções auxiliares acima.
O objetivo é criar exemplos em que a entrada contenha:
E o alvo é uma única chamada FunctionGemma estruturada neste formato:
<start_function_call>call:TOOL_NAME{args:<escape>{...}<escape>}<end_function_call>Começamos iterando pelo conjunto de dados e filtrando todos os exemplos que não podem ser usados para treinamento.
Essa função só guarda exemplos em que:
from datasets import Dataset
def build_simple_rows(ds, max_rows=None):
rows = []
for ex in ds:
# 1) task-aligned gold tool call
gold = get_gold_tool_call_task_aligned(ex)
if not gold:
continue
# 2) tools -> HF schema
hf_tools = get_tools_hf(ex)
if not hf_tools:
continue
# 3) build required_map: tool_name -> required fields
required_map = {}
for t in hf_tools:
if t.get("type") == "function":
fn = t.get("function", {})
name = fn.get("name")
req = (fn.get("parameters", {}) or {}).get("required", []) or []
if name:
required_map[name] = req
# 4) guard: gold tool must be in tool list
tool_names = set(required_map.keys())
if gold["name"] not in tool_names:
continue
# 5) force {} when no required params
gold_args = gold.get("arguments", {})
if not isinstance(gold_args, dict):
gold_args = {}
req = required_map.get(gold["name"], [])
if len(req) == 0:
gold_args = {} # key fix
rows.append({
"user_content": ex.get("task", ""),
"tool_name": gold["name"],
"tool_arguments": json.dumps(gold_args, ensure_ascii=False),
"hf_tools": hf_tools,
})
if max_rows and len(rows) >= max_rows:
break
return rowsAgora vamos criar linhas de treinamento e avaliação:
simple_train = build_simple_rows(train_ds, max_rows=N_TRAIN)
simple_eval = build_simple_rows(eval_ds, max_rows=N_EVAL)
print("usable train:", len(simple_train), "usable eval:", len(simple_eval))No nosso caso, acabamos com 961 amostras de treinamento e 109 amostras de avaliação das 3.000 originais. Essa queda é esperada porque a filtragem é rigorosa. Ele tira os exemplos com chamadas de ferramentas que estão faltando, definições de ferramentas inválidas, nomes de ferramentas que não batem ou argumentos malformados.
usable train: 961 usable eval: 109Essa etapa de limpeza é super importante. Antes de aplicar isso, o conjunto de dados tinha amostras com ruído e desalinhadas, o que causava um comportamento instável na chamada de funções e resultados ruins, mesmo depois do ajuste fino. Depois de filtrar só os exemplos de alta qualidade e alinhados com a tarefa, o FunctionGemma fica bem mais consistente e os resultados do ajuste fino melhoram bastante.
Depois, a gente formata cada linha na estrutura exata de prompt-mais-alvo que o FunctionGemma precisa. Usamos o processador apply_chat_template para injetar declarações de ferramentas corretamente e, em seguida, anexamos a chamada da função gold como destino.
def format_row_as_text(row):
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": row["user_content"]},
]
prompt = processor.apply_chat_template(
messages,
tools=row["hf_tools"],
add_generation_prompt=True,
tokenize=False,
)
target = (
f"<start_function_call>call:{row['tool_name']}"
f"{{args:<escape>{row['tool_arguments']}<escape>}}"
f"<end_function_call>"
)
return prompt + targetAgora vamos transformar as linhas em objetos do Hugging Face Dataset:
train_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_train])
eval_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_eval])Algumas versões do TRL precisam que formatting_func retorne uma string, e o treinamento pode dar errado se alguma amostra virar uma lista ou um valor que não seja uma string. Esse auxiliar faz com que text seja sempre uma string limpa.
# ensure text is always a string
def force_text_string(ds):
def fix(ex):
t = ex.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return {"text": str(t)}
return ds.map(fix)
train_text_ds = force_text_string(train_text_ds)
eval_text_ds = force_text_string(eval_text_ds)Por fim, imprima uma amostra para confirmar a formatação:
print(train_text_ds[0]["text"])Você deve ver um prompt totalmente renderizado contendo declarações de ferramentas, seguido por uma chamada de função dourada semelhante a:
<bos><start_of_turn>developer
You are a model that can do function calling with the following functions<start_function_declaration>declaration:get_pollution_levels{description:<escape>Retrieve pollution levels information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the pollution levels (e.g., Beijing, London, New York)<escape>,type:<escape>STRING<escape>},pollutant:{description:<escape>Specify a pollutant for pollution levels (e.g., PM2.5, PM10, ozone)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><start_function_declaration>declaration:get_water_quality{description:<escape>Retrieve water quality information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the water quality (e.g., river, lake, beach)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><end_of_turn>
<start_of_turn>user
I'm planning a beach cleanup at Zuma Beach this weekend and need to ensure safety. Can you provide the current water quality and if it's poor, check the pollution level of PM2.5 there?<end_of_turn>
<start_of_turn>model
<start_function_call>call:get_water_quality{args:<escape>{"location": "Zuma Beach"}<escape>}<end_function_call>Antes do treinamento, você deve medir o desempenho do modelo base FunctionGemma na chamada de funções. Essa linha de base ajuda você a confirmar que o ajuste fino realmente melhora a seleção de ferramentas e a formatação de chamadas de função.
Nesta seção, vamos avaliar duas coisas:
Usamos duas expressões regulares para extrair o nome da ferramenta prevista e o bloco completo de chamada de função da saída do modelo e, em seguida, comparamos com os rótulos de referência.
import re
import evaluate
import torch
from tqdm.auto import tqdm
cer_metric = evaluate.load("cer")
# Gemma / FunctionGemma-style only
FG_BLOCK_RE = re.compile(r"<start_function_call>.*?<end_function_call>", re.DOTALL)
FG_NAME_RE = re.compile(r"call:([a-zA-Z0-9_]+)\{", re.DOTALL)
def extract_tool_name(gen: str):
gen = gen or ""
m = FG_NAME_RE.search(gen)
return m.group(1) if m else None
def extract_call_block(gen: str):
gen = gen or ""
m = FG_BLOCK_RE.search(gen)
return m.group(0) if m else ""
def gold_call_block(r):
return (
f"<start_function_call>call:{r['tool_name']}"
f"{{args:<escape>{r['tool_arguments']}<escape>}}"
f"<end_function_call>"
)A função abaixo faz a inferência em um subconjunto de exemplos de avaliação e calcula as duas métricas. A gente mantém a amostragem desativada (do_sample=False) pra deixar os resultados mais certinhos e fáceis de comparar antes e depois do ajuste fino.
@torch.inference_mode()
def eval_tool_and_cer(proc, mdl, rows, n=50, max_new_tokens=128):
mdl.eval()
n = min(n, len(rows))
tool_ok = 0
preds, refs = [], []
for i in tqdm(range(n)):
r = rows[i]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(out[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True).strip()
if extract_tool_name(gen) == r["tool_name"]:
tool_ok += 1
preds.append(extract_call_block(gen))
refs.append(gold_call_block(r))
return {
"n_eval": n,
"tool_accuracy": tool_ok / n,
"TC-CER (lower is better)": cer_metric.compute(predictions=preds, references=refs),
}Faça a avaliação inicial:
pre_metrics = eval_tool_and_cer(processor, model, simple_eval, n=50, max_new_tokens=128)
print("PRE metrics:", pre_metrics)Mesmo antes do ajuste fino, o FunctionGemma mostra um desempenho básico forte nessa tarefa.
Em um subconjunto de 50 exemplos de avaliação, o modelo atinge 88% de precisão no nome da ferramenta, o que significa que ele escolhe a função certa na maioria dos casos.
Além disso, a Taxa de Erros de Chamada de Ferramenta (TC-CER) é de aproximadamente 33% para o bloco completo de chamadas de função, mostrando que, embora a ferramenta certa seja frequentemente escolhida, os argumentos e a formatação gerados ainda não são exatamente como deveriam ser.
PRE metrics: {'n_eval': 50, 'tool_accuracy': 0.88, 'TC-CER (lower is better)': 0.33399307273626916}Esses resultados mostram que o modelo básico FunctionGemma já entende como funciona a chamada de funções.
Mas, a taxa de erros relativamente alta mostra que é preciso ajustar as coisas para melhorar a completude dos argumentos, a consistência da formatação e a correção estrutural geral das chamadas de função geradas.
As métricas são úteis, mas também é importante olhar para os resultados qualitativos. O auxiliar abaixo faz a inferência para um exemplo e mostra a chamada de função prevista junto com a referência padrão.
import torch
@torch.inference_mode()
def infer_one(proc, mdl, rows, idx=0, max_new_tokens=128):
r = rows[idx]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(
out[0][inputs["input_ids"].shape[-1]:],
skip_special_tokens=True
).strip()
pred_tool = extract_tool_name(gen)
return {
"task": r["user_content"],
"tool_match": (pred_tool == r["tool_name"]),
"predicted": extract_call_block(gen),
"gold": gold_call_block(r),
}Execute em um exemplo:
pre = infer_one(processor, model, simple_eval, idx=15)
print(f"""
TASK:
{pre['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{pre['predicted']}
--- GOLD ---
{pre['gold']}
""")Resultado:
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{nurse_id:<escape>Ratched<escape>,patient_id:<escape>12345<escape>,procedure_type:<escape>Cardiac Bypass<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>Neste exemplo, o modelo escolhe a função certa, e é por isso que a correspondência da ferramenta é Verdadeira.
Mas, a chamada gerada inclui argumentos extras e não segue exatamente a estrutura de destino usada no treinamento.
Embora esses argumentos sejam razoáveis em termos semânticos, eles não correspondem ao formato da chamada de função gold, o que contribui para uma taxa de erro de caracteres mais alta. Isso mostra por que é preciso ajustar tudo direitinho para melhorar a consistência estrutural e a conformidade do esquema, não só escolher as ferramentas certas.
Agora que temos conjuntos de dados SFT limpos, o próximo passo é configurar o treinador que vai ajustar o FunctionGemma. Usamos o TRL ( SFTTrainer), que é uma maneira leve e confiável de ajustar modelos do tipo chat em exemplos de texto.
Também definimos um diretório de saída para que o Kaggle salve o ponto de verificação ajustado em um local permanente.
from trl import SFTConfig, SFTTrainer
OUT_DIR = "/kaggle/working/functiongemma-hermes-ft"Para reduzir o uso de VRAM durante o treinamento, ativamos a verificação de gradiente e desativamos o cache KV.
# VRAM savings
model.gradient_checkpointing_enable()
model.config.use_cache = FalseA gente define a configuração do treinamento usando o SFTConfig. Essas configurações são escolhidas para equilibrar estabilidade e eficiência nas GPUs Kaggle, mantendo o tempo de treinamento curto.
cfg = SFTConfig(
output_dir=OUT_DIR,
max_length=512,
packing=False,
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=5e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
logging_steps=10,
eval_strategy="steps",
eval_steps=10,
report_to="none",
fp16=(model.dtype == torch.float16),
bf16=(model.dtype == torch.bfloat16),
optim="adamw_torch_fused",
)A função de formatação garante que cada exemplo de treinamento seja retornado como uma única string, o que é exigido pela versão atual do TRL.
def formatting_func(example):
# MUST return a STRING (not list) for your TRL version
t = example.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return str(t)Por fim, a gente inicializa o SFTTrainer com o modelo, a configuração, os conjuntos de dados e o tokenizador.
trainer = SFTTrainer(
model=model,
args=cfg,
train_dataset=train_text_ds,
eval_dataset=eval_text_ds,
processing_class=tokenizer,
formatting_func=formatting_func,
)Com o treinador configurado, agora podemos começar a ajustar o modelo. Essa etapa faz um treinamento supervisionado no conjunto de dados preparado e avalia o modelo de vez em quando durante o treinamento.
trainer.train()
trainer.save_model(OUT_DIR)
processor.save_pretrained(OUT_DIR)
print("Saved to:", OUT_DIR)Depois que o treinamento terminar, a gente salva o modelo ajustado e o processador no diretório de saída pra que possam ser reutilizados pra inferência ou enviados pro Hugging Face Hub.
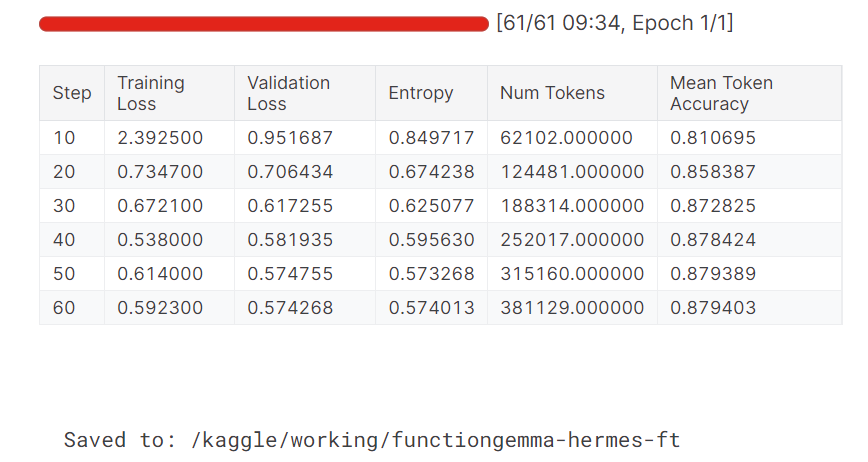
Durante o treinamento, tanto a perda de treinamento quanto a perda de validação diminuem de forma constante. A precisão média dos tokens também melhora com o tempo, mostrando que o modelo aprendeu a gerar resultados de chamadas de função mais precisos e consistentes.
Depois que o ajuste fino estiver pronto, a gente pode publicar o modelo pra que ele possa ser reutilizado, compartilhado ou implementado facilmente. Colocar o modelo no Hugging Face Hub permite que outras pessoas carreguem ele direto usando as APIs padrão do Transformers.
HF_REPO_ID = "kingabzpro/functiongemma-hermes-3k-ft"
model.push_to_hub(HF_REPO_ID)
processor.push_to_hub(HF_REPO_ID)
print("Pushed to:", HF_REPO_ID)Depois que o upload terminar, o modelo ajustado vai ficar disponível pra todo mundo no Hugging Face:
Pushed to: kingabzpro/functiongemma-hermes-3k-ft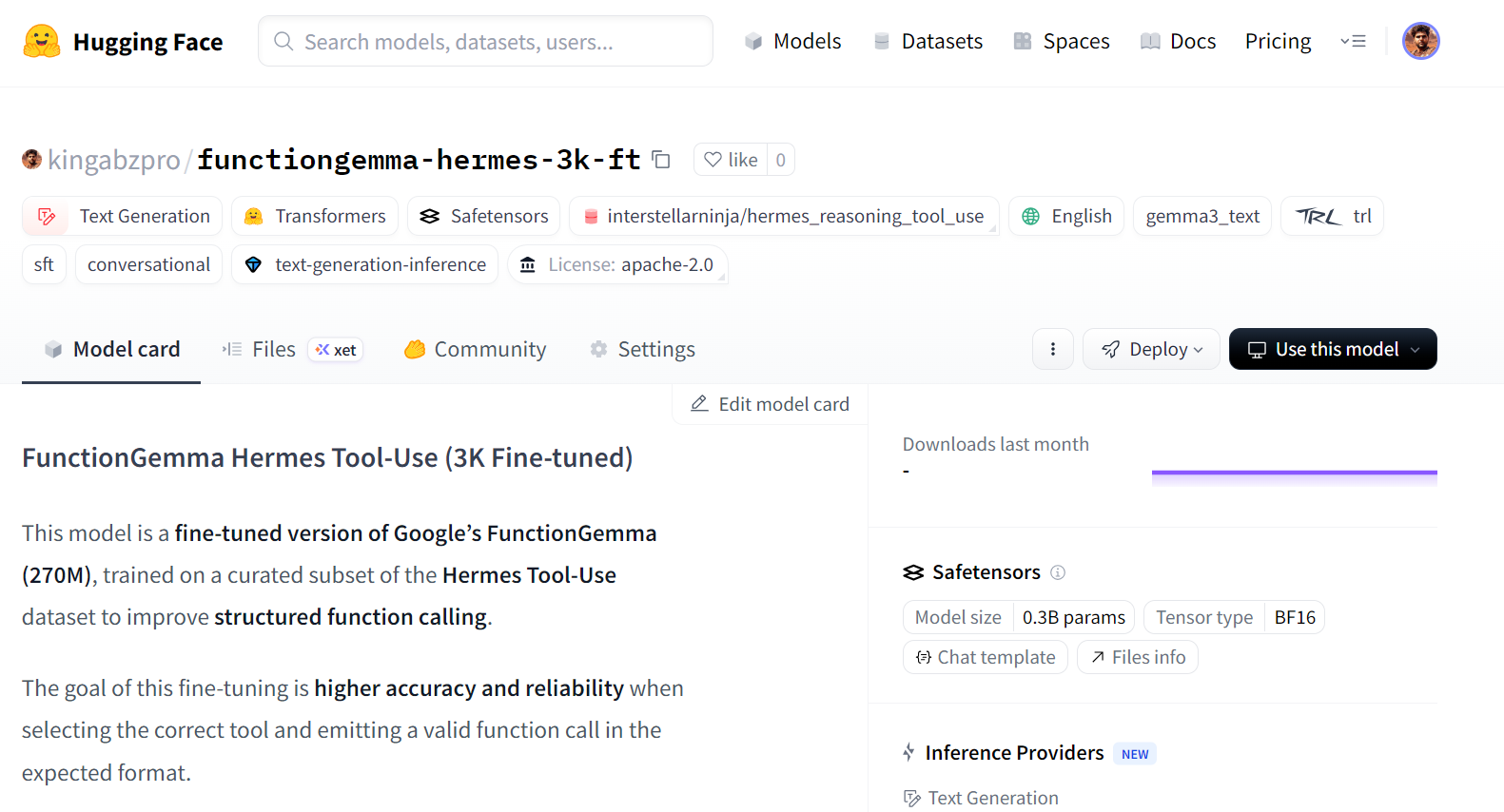
Fonte: kingabzpro/functiongemma-hermes-3k-ft · Hugging Face
Depois que o ajuste fino estiver pronto, a gente recarrega o modelo e o processador salvos do disco e usa o mesmo pipeline de avaliação que usamos antes do treinamento. Isso garante que a comparação entre o desempenho antes e depois do ajuste fino seja justa e consistente.
from transformers import AutoProcessor, AutoModelForCausalLM
ft_processor = AutoProcessor.from_pretrained(OUT_DIR, device_map="auto")
ft_model = AutoModelForCausalLM.from_pretrained(OUT_DIR, dtype="auto", device_map="auto")Depois, a gente avalia o modelo ajustado no conjunto de avaliação usando a precisão do nome da ferramenta e o TC-CER.
post_metrics = eval_tool_and_cer(ft_processor, ft_model, simple_eval, n=50, max_new_tokens=64)
print("POST metrics:", post_metrics)Os resultados mostram uma clara melhoria em relação à linha de base:
POST metrics: {'n_eval': 50, 'tool_accuracy': 0.98, 'TC-CER (lower is better)': 0.1454725383473528}A precisão do nome da ferramenta melhora de 88% para 98%, e a taxa de erro de caracteres para o bloco completo de chamadas de função é reduzida em mais da metade. Isso mostra que o modelo não só escolhe a ferramenta certa de forma mais confiável, mas também gera resultados que se aproximam mais do esquema desejado.
Para entender melhor as melhorias, a gente dá uma olhada nas previsões individuais. No exemplo abaixo, o modelo escolhe a função certa e cria uma chamada bem estruturada com argumentos mais completos.
post = infer_one(ft_processor, ft_model, simple_eval, idx=15)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Embora a chamada prevista possa incluir argumentos adicionais que vão além da meta principal, a estrutura geral e a formatação dos argumentos estão bem mais consistentes do que antes do ajuste fino. Isso mostra que o esquema ficou mais legal e que a gente entende melhor o que o usuário quer e as chamadas de função geradas.
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass", "nurse_id": "Ratched", "task": "Post-operative care"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>Vamos ver outro exemplo.
post = infer_one(ft_processor, ft_model, simple_eval, idx=25)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Um segundo exemplo mostra uma chamada de função limpa e correta para uma tarefa de extração de URL, mostrando que o modelo ajustado funciona bem em diferentes ferramentas.
TASK:
I would like to extract details from a LinkedIn company page. Could you assist me in fetching the information from this URL: https://www.linkedin.com/company/abc-corporation?
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation", "html": true}<escape>}<end_function_call>No geral, esses resultados mostram que o ajuste fino melhora tanto a precisão quanto a correção estrutural nas tarefas de identificação de funções.
O caderno completo do Kaggle para este tutorial está disponível em:https://www.kaggle.com/code/kingabzpro/finetuning-functiongemma
Se você tiver algum problema, pode clonar o notebook, adicionar sua chave secreta do Hugging Face e executá-lo do início ao fim.
Se você está tentando treinar o FunctionGemma em conjuntos de dados genéricos de geração de texto, é melhor parar logo. A FunctionGemma não foi feita pra funcionar como um modelo de linguagem de uso geral.
Para geração de texto aberto, o família de modelos Gemma 3 é a melhor escolha.
O FunctionGemma foi feito especialmente para chamar funções, onde o objetivo é escolher a ferramenta certa, criar argumentos que sigam o esquema e interagir de forma confiável com sistemas externos, como APIs, bancos de dados e serviços.
O tamanho pequeno da FunctionGemma é uma escolha de design bem pensada. Com 270 milhões de parâmetros, ele é otimizado para implantações de baixa latência e eficientes em termos de recursos, incluindo máquinas locais, dispositivos de borda e infraestrutura privada. Isso o torna ideal para chamadas de funções em tempo real e fluxos de trabalho de agentes, onde a precisão e a estrutura são mais importantes do que uma prosa fluente.
Neste tutorial, a gente aprendeu como ajustar o FunctionGemma no conjunto de dados Hermes Reasoning Tool-Use. Uma lição importante é que a preparação e a avaliação dos dados são mais importantes do que o tempo de treinamento em si.
Limpar bem o conjunto de dados, alinhar as tarefas com as chamadas de ferramentas gold e garantir uma consistência rigorosa do esquema nos permitiu melhorar bastante o comportamento do modelo com um número relativamente pequeno de amostras de alta qualidade.
Os resultados mostram claramente o impacto do ajuste fino. A precisão do nome da ferramenta melhorou de 88% para 98%, e a taxa de erro de caracteres para blocos de chamada de função completos foi reduzida em mais da metade. Mais importante ainda, o modelo ficou bem mais consistente na produção de chamadas de função bem estruturadas e previsíveis, que se alinham com o uso no mundo real.
Cursos mais populares do DataCamp
Curso
Curso
Curso