
Kurs
Feinabstimmung mit Llama 3
2 Std.
3.7K
In diesem Tutorial schauen wir uns FunctionGemma an, ein leichtes Sprachmodell für Funktionsaufrufe von Google DeepMind, und ich erkläre, warum Feinabstimmung wichtig ist, um zuverlässige und schemakonforme Tools zu nutzen.
Zuerst richten wir eine GPU-fähige Kaggle-Umgebung ein, dann laden und bereiten wir den Datensatz und das Basis-FunctionGemma-Modell vor.
Als Nächstes machen wir Vorabbewertungen, um eine Basis für die Toolauswahl und die Genauigkeit der Funktionsaufrufe zu schaffen. Dann optimieren wir FunctionGemma mit überwachtem Training und schauen uns nach dem Training an, wie gut es funktioniert, um sicherzugehen, dass die Optimierung richtig gemacht wurde.
Wenn du nach praktischen Übungen suchst, die dir beim Erlernen der Feinabstimmung helfen, empfehle ich dir den Kurs Kurs „Fine-Tuning mit Llama 3”.
FunctionGemma ist eine spezielle Version von Googles Gemma 3 270M von Google, die speziell für Funktionsaufrufe und den Einsatz von Werkzeugen und nicht für allgemeine Gespräche entwickelt wurde.
Es nutzt die gleiche Architektur wie Gemma 3, hat aber ein spezielles Format und einen Trainingsfokus, der es ermöglicht, strukturierte Ausgaben zu generieren, die Funktionsaufrufe darstellen.
FunctionGemma kommt als Basismodell raus, das Entwickler für bestimmte Anwendungsfälle anpassen können. Dank seiner Größe und seinem Design ist es leicht, effizient und kann auf Geräten mit begrenzten Ressourcen wie Laptops und Edge-Hardware eingesetzt werden.
Obwohl FunctionGemma für Funktionsaufrufe trainiert wurde, funktionieren Modelle dieser Größe am besten, wenn sie durch Feinabstimmung auf aufgabenspezifische Daten spezialisiert sind.
Die Feinabstimmung hilft dem Modell, stabile Muster zu lernen, um die richtige Funktion aus einer Reihe von Tools auszuwählen und die entsprechenden Argumente für echte Anwendungsfälle richtig zu formatieren.
Dieser Prozess sorgt für einheitlichere und besser vorhersehbare Ergebnisse, was wiederum die Zuverlässigkeit in der Praxis verbessert.
Schauen wir uns mal die Schritte an, die nötig sind, um FunctionGemma richtig einzustellen.
Geh zuerst auf Kaggle und leg ein neues Notizbuch an. Wenn das Notebook offen ist, such das Optionsfeld „ -Sitzung“ auf der rechten Seite und stell den Beschleuniger auf GPU (T4 ×2) ein .
Damit schaltest du die GPU-Beschleunigung für die Sitzung frei und kannst das Modell mit den kostenlosen Rechenressourcen von Kaggle optimieren.
Nachdem du die GPU aktiviert hast, machst du eine neue Codezelle und führst den folgenden Befehl aus, um alle benötigten Python-Abhängigkeiten zu installieren. Der Kernel braucht vielleicht ein bisschen Zeit zum Starten, danach werden die Pakete automatisch installiert.
%pip -q install -U datasets accelerate trl kagglehub sentencepiece huggingface_hub tqdm evaluate jiwerAls Nächstes fügst du deinen Hugging Face-Zugriffstoken sicher hinzu.
Öffne im oberen Menü „Add-ons“ → „Geheimnisse“ und klicke dann auf „Geheimnis hinzufügen“. Mach den geheimen Namen zu „ HUGGINGFACE_TOKEN “ und füge deinen Hugging Face API-Schlüssel als Wert ein.
Die Verwendung von Kaggle Secrets ist sicherer als das direkte Festcodieren von Umgebungsvariablen oder Tokens im Notebook.
Sobald das Geheimnis gespeichert ist, gibt Kaggle einen Codeausschnitt, mit dem du programmgesteuert drauf zugreifen kannst.
Benutz den folgenden Code, um dich beim Hugging Face Hub anzumelden:
from kaggle_secrets import UserSecretsClient
from huggingface_hub import login
hf_token = UserSecretsClient().get_secret("HUGGINGFACE_TOKEN")
if not hf_token:
raise ValueError("HUGGINGFACE_TOKEN not found in Kaggle Secrets.")
login(token=hf_token)Nach erfolgreicher Anmeldung kannst du auf geschützte Modelle und Datensätze zugreifen und dein optimiertes FunctionGemma-Modell zum Teilen und Wiederverwenden auf den Hugging Face Hub hochladen.
Das Hermes Reasoning Tool-Use ist ein offener englischer Datensatz im Format „Tool-Use Reasoning” mit strukturierten Beispielen, der zum Trainieren und Bewerten von Modellen für die Werkzeugauswahl und Aufgaben zum Aufrufen von Funktionen im JSON-Stil entwickelt wurde.
Es hat Zehntausende Beispiele für das Denken beim Werkzeuggebrauch mit natürlichen Sprachaufforderungen und Werkzeugschemata in einem Format, das für überwachtes Fine-Tuning gut passt.
In diesem Tutorial nehmen wir nur einen Teil des Datensatzes, damit wir schneller experimentieren können.
Zuerst legst du einen Zufallsstartwert und die Gesamtzahl der zu verwendenden Beispiele fest. Dann teil die Daten in Trainings- und Evaluierungssätze auf:
from datasets import load_dataset
SEED = 40
N_TOTAL = 3000
N_EVAL = 300
N_TRAIN = N_TOTAL - N_EVALAls Nächstes laden wir den Datensatz, mischen ihn und erstellen die Teilmengen „train“ und „eval“:
raw = load_dataset("interstellarninja/hermes_reasoning_tool_use", split="train")
raw = raw.shuffle(seed=SEED).select(range(N_TOTAL))
train_ds = raw.select(range(N_TRAIN))
eval_ds = raw.select(range(N_TRAIN, N_TOTAL))
print("train:", len(train_ds), "eval:", len(eval_ds))
Damit hast du 2.700 Trainingsbeispiele und 300 Bewertungsbeispiele, was genug ist, um die Feinabstimmung zu zeigen, ohne dass die Rechenanforderungen zu groß werden.
train: 2700 eval: 300In diesem Tutorial laden wir das FunctionGemma-Modell mit KaggleHub direkt ins Kaggle-Notebook.
KaggleHub findet automatisch den Speicherort des Modells und macht es in der Notebook-Umgebung verfügbar, sodass man es nicht mehr manuell von Hugging Face runterladen muss.
import kagglehub
from transformers import AutoProcessor, AutoModelForCausalLM
model_path = kagglehub.model_download("google/functiongemma/transformers/functiongemma-270m-it")Nachdem du die obige Zelle ausgeführt hast, werden die Modelldateien im Eingabe des Kaggle-Notebooks, was zeigt, dass das Modell erfolgreich geladen wurde und lokal verfügbar ist.
Sobald das Modell da ist, laden wir sowohl den Prozessor und das Modell in den GPU-Speicher.
Der Prozessor kümmert sich um Chat-Vorlagen und die Formatierung von Tool-Schemas, während das Modell dafür zuständig ist, strukturierte Funktionsaufrufe zu generieren.
Wenn du „ device_map="auto" “ einstellst, wird das Modell auf der verfügbaren GPU platziert, und „ dtype="auto" “ wählt eine effiziente Präzision, die von der Hardware unterstützt wird.
processor = AutoProcessor.from_pretrained(model_path, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="auto", device_map="auto")
tokenizer = processor.tokenizer if hasattr(processor, "tokenizer") else processor
print("dtype:", model.dtype, "| device:", model.device)Das zeigt, dass FunctionGemma richtig geladen, auf der GPU platziert und bereit für die Auswertung und Feinabstimmung ist.
dtype: torch.bfloat16 | device: cuda:1Bevor wir FunctionGemma optimieren können, müssen wir erst mal vereinheitlichen, wie Tools dargestellt werden, und zuverlässig die richtigen (Gold-)Funktionsaufrufe aus dem Datensatz herausziehen.
Der Hermes Reasoning Tool-Use-Datensatz kann Tool-Definitionen in verschiedenen Formaten speichern. Deshalb wandelt dieser Schritt alles in eine einheitliche Struktur um, die wir für die überwachte Feinabstimmung nutzen können.
Wir fangen damit an, das Feld „ tools “ zu normalisieren. Im Datensatz kann „ tools “ als Liste in Python oder JSON-Zeichenfolge auftauchen oder komplett fehlen.
Die unten stehende Hilfsfunktion wandelt alle gültigen Darstellungen in eine saubere Python-Liste um und ignoriert fehlerhafte oder leere Einträge.
import re, json
def normalize_tools_field(tools):
if tools is None:
return []
if isinstance(tools, list):
return tools
if isinstance(tools, str):
s = tools.strip()
if not s:
return []
try:
parsed = json.loads(s)
return parsed if isinstance(parsed, list) else []
except Exception:
return []
return []Als Nächstes machen wir die Parametertypen einheitlich. Hermes-Tool-Definitionen verwenden oft informelle Typ-Annotationen wie „ str “, „int “ oder Containertypen wie „ List[str] “. Die Funktion unten wandelt diese in gültige JSON-Schema-Typen um, die mit dem Aufruf von Hugging Face-Funktionen kompatibel sind.
def _parse_hermes_type(t) -> dict:
if t is None:
return {"type": "string"}
if isinstance(t, dict):
return t if "type" in t else {"type": "object"}
if isinstance(t, list):
return {"type": "array"}
if not isinstance(t, str):
return {"type": "string"}
t = t.strip()
prim = {
"str": "string", "string": "string",
"int": "integer", "integer": "integer",
"float": "number", "number": "number",
"bool": "boolean", "boolean": "boolean",
"dict": "object", "object": "object",
"list": "array", "array": "array",
}
if t.lower() in prim:
return {"type": prim[t.lower()]}
m = re.match(r"List\[(.+)\]$", t)
if m:
return {"type": "array", "items": _parse_hermes_type(m.group(1).strip())}
m = re.match(r"Dict\[(.+),\s*(.+)\]$", t)
if m:
return {"type": "object", "additionalProperties": _parse_hermes_type(m.group(2).strip())}
return {"type": "string"}Mit diesen Tools machen wir Tool-Definitionen im Hermes-Stil in Hugging Face-Schemas vom Typ „ {"type": "function", "function": {...}} ” um. Diese Funktion unterstützt zwei Formate:
Beim Format pro Argument behandelt diese Implementierung die aufgelisteten Parameter als erforderlich, wenn keine erforderliche Liste explizit angegeben ist.
def hermes_tools_to_hf_schema(tools_field):
"""
Handles both:
- Hermes per-arg style: {"parameters": {"x":{"type":"str"}, ...}}
- Already-JSON-schema style: {"parameters":{"type":"object","properties":...,"required":[...]}}
"""
hermes_tools = normalize_tools_field(tools_field)
out = []
for tool in hermes_tools:
if not isinstance(tool, dict):
continue
name = tool.get("name")
desc = tool.get("description", "")
params = tool.get("parameters", {}) or {}
# If params already look like JSON schema (best case)
if isinstance(params, dict) and "type" in params and "properties" in params:
json_schema_params = params
if "required" not in json_schema_params:
json_schema_params["required"] = []
else:
props, req = {}, []
if isinstance(params, dict):
for p_name, p_spec in params.items():
p_spec = p_spec or {}
if isinstance(p_spec, dict):
p_desc = p_spec.get("description", "")
p_type = p_spec.get("type", "str")
else:
p_desc, p_type = "", "str"
frag = dict(_parse_hermes_type(p_type))
if p_desc:
frag["description"] = p_desc
props[p_name] = frag
req.append(p_name)
json_schema_params = {"type": "object", "properties": props, "required": req}
out.append({
"type": "function",
"function": {
"name": name,
"description": desc,
"parameters": json_schema_params,
}
})
return outWir machen uns einen kleinen Helfer, um die konvertierten Werkzeugschemata für jedes Datensatzbeispiel abzurufen:
def get_tools_hf(ex):
return hermes_tools_to_hf_schema(ex.get("tools"))Dann holen wir den Gold-Tool-Aufruf aus dem Gespräch raus. Hermes-Konversationen können mehrere Durchgänge haben, also analysieren wir die Blöcke „ {...} “ und holen das erste gültige Toolaufrufobjekt (Name + Argumente) raus. Das macht die Überwachung einfach und einheitlich.
TOOL_CALL_RE = re.compile(r"<tool_call>\s*(\{.*?\})\s*</tool_call>", re.DOTALL)
def extract_first_tool_call_obj(text: str):
if not text:
return None
m = TOOL_CALL_RE.search(text)
if not m:
return None
try:
obj = json.loads(m.group(1))
if isinstance(obj, dict) and "name" in obj and "arguments" in obj:
return obj
except Exception:
return None
return NoneUm den Tool-Aufruf mit der richtigen Benutzeraufgabe abzugleichen, schauen wir uns den Gesprächsverlauf an, suchen die Benutzernachricht, die zum Datensatz task passt, und nehmen dann die Antwort des Assistenten direkt danach. Wenn die Antwort des Assistenten einen Tool-Aufruf enthält, geben wir ihn als Gold-Label zurück.
def _role(turn):
return (turn.get("from") or "").lower().strip()
def get_gold_tool_call_task_aligned(ex):
task = (ex.get("task") or "").strip()
conv = ex.get("conversations") or []
if not conv:
return None
idx = None
if task:
for i, t in enumerate(conv):
if _role(t) in ["human", "user"]:
val = (t.get("value") or "").strip()
if val == task or task in val or val in task:
idx = i
break
if idx is None:
for i in range(len(conv)-1, -1, -1):
if _role(conv[i]) in ["human", "user"]:
idx = i
break
if idx is None:
return None
for j in range(idx+1, len(conv)):
if _role(conv[j]) in ["gpt", "assistant", "model"]:
gold = extract_first_tool_call_obj(conv[j].get("value", ""))
if gold:
return gold
if _role(conv[j]) in ["human", "user"]:
break
return NoneAm Ende dieses Schritts hat jedes brauchbare Datensatzbeispiel:
Jetzt müssen wir diese in überwachte Feinabstimmung (SFT) Trainingsbeispiele im genauen Format, das FunctionGemma erwartet, umwandeln, und zwar mit den oben genannten Hilfsfunktionen.
Das Ziel ist, Beispiele zu erstellen, bei denen die Eingabe Folgendes enthält:
Und das Ziel ist ein einzelner, strukturierter FunctionGemma-Aufruf in diesem Format:
<start_function_call>call:TOOL_NAME{args:<escape>{...}<escape>}<end_function_call>Wir fangen damit an, den Datensatz durchzugehen und alle Beispiele rauszufiltern, die nicht fürs Training genutzt werden können.
Diese Funktion behält nur Beispiele, bei denen:
from datasets import Dataset
def build_simple_rows(ds, max_rows=None):
rows = []
for ex in ds:
# 1) task-aligned gold tool call
gold = get_gold_tool_call_task_aligned(ex)
if not gold:
continue
# 2) tools -> HF schema
hf_tools = get_tools_hf(ex)
if not hf_tools:
continue
# 3) build required_map: tool_name -> required fields
required_map = {}
for t in hf_tools:
if t.get("type") == "function":
fn = t.get("function", {})
name = fn.get("name")
req = (fn.get("parameters", {}) or {}).get("required", []) or []
if name:
required_map[name] = req
# 4) guard: gold tool must be in tool list
tool_names = set(required_map.keys())
if gold["name"] not in tool_names:
continue
# 5) force {} when no required params
gold_args = gold.get("arguments", {})
if not isinstance(gold_args, dict):
gold_args = {}
req = required_map.get(gold["name"], [])
if len(req) == 0:
gold_args = {} # key fix
rows.append({
"user_content": ex.get("task", ""),
"tool_name": gold["name"],
"tool_arguments": json.dumps(gold_args, ensure_ascii=False),
"hf_tools": hf_tools,
})
if max_rows and len(rows) >= max_rows:
break
return rowsJetzt machen wir Trainings- und Bewertungsreihen:
simple_train = build_simple_rows(train_ds, max_rows=N_TRAIN)
simple_eval = build_simple_rows(eval_ds, max_rows=N_EVAL)
print("usable train:", len(simple_train), "usable eval:", len(simple_eval))In unserem Fall haben wir am Ende 961 Trainingsbeispiele und 109 Bewertungsbeispiele von den ursprünglichen 3.000. Dieser Rückgang ist zu erwarten, weil die Filterung streng ist. Es entfernt Beispiele mit fehlenden Tool-Aufrufen, ungültigen Tool-Definitionen, nicht übereinstimmenden Tool-Namen oder fehlerhaften Argumenten.
usable train: 961 usable eval: 109Dieser Reinigungsschritt ist echt wichtig. Vor der Anwendung hatte der Datensatz verrauschte und falsch ausgerichtete Proben, was zu einem unbeständigen Funktionsaufrufverhalten und schlechten Ergebnissen führte, selbst nach einer Feinabstimmung. Nachdem nur noch hochwertige, aufgabenbezogene Beispiele übrig sind, wird FunctionGemma viel konsistenter und die Feinabstimmungsergebnisse werden deutlich besser.
Als Nächstes formatieren wir jede Zeile so, dass sie genau die von FunctionGemma benötigte Struktur aus Eingabeaufforderung und Ziel hat. Wir nutzen die Funktion „ apply_chat_template ” des Prozessors, um Tool-Deklarationen richtig einzufügen, und fügen dann den Gold-Funktionsaufruf als Ziel hinzu.
def format_row_as_text(row):
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": row["user_content"]},
]
prompt = processor.apply_chat_template(
messages,
tools=row["hf_tools"],
add_generation_prompt=True,
tokenize=False,
)
target = (
f"<start_function_call>call:{row['tool_name']}"
f"{{args:<escape>{row['tool_arguments']}<escape>}}"
f"<end_function_call>"
)
return prompt + targetJetzt machen wir aus den Zeilen Hugging Face Dataset-Objekte:
train_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_train])
eval_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_eval])Einige TRL-Versionen brauchen „ formatting_func “, um eine Zeichenfolge zurückzugeben, und das Training kann abstürzen, wenn ein Beispiel zu einer Liste oder einem Nicht-Zeichenfolgenwert wird. Dieser Helfer sorgt dafür, dass „ text ” immer ein sauberer String ist.
# ensure text is always a string
def force_text_string(ds):
def fix(ex):
t = ex.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return {"text": str(t)}
return ds.map(fix)
train_text_ds = force_text_string(train_text_ds)
eval_text_ds = force_text_string(eval_text_ds)Druck zum Schluss ein Muster aus, um die Formatierung zu checken:
print(train_text_ds[0]["text"])Du solltest eine komplett gerenderte Eingabeaufforderung mit Tool-Deklarationen sehen, gefolgt von einem goldenen Funktionsaufruf, der so aussieht:
<bos><start_of_turn>developer
You are a model that can do function calling with the following functions<start_function_declaration>declaration:get_pollution_levels{description:<escape>Retrieve pollution levels information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the pollution levels (e.g., Beijing, London, New York)<escape>,type:<escape>STRING<escape>},pollutant:{description:<escape>Specify a pollutant for pollution levels (e.g., PM2.5, PM10, ozone)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><start_function_declaration>declaration:get_water_quality{description:<escape>Retrieve water quality information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the water quality (e.g., river, lake, beach)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><end_of_turn>
<start_of_turn>user
I'm planning a beach cleanup at Zuma Beach this weekend and need to ensure safety. Can you provide the current water quality and if it's poor, check the pollution level of PM2.5 there?<end_of_turn>
<start_of_turn>model
<start_function_call>call:get_water_quality{args:<escape>{"location": "Zuma Beach"}<escape>}<end_function_call>Vor dem Training solltest du checken, wie gut das Basis-Modell FunctionGemma beim Aufruf von Funktionen funktioniert. Mit dieser Ausgangsbasis kannst du überprüfen, ob die Feinabstimmung die Werkzeugauswahl und die Formatierung von Funktionsaufrufen wirklich verbessert.
In diesem Abschnitt schauen wir uns zwei Sachen an:
Wir nehmen zwei reguläre Ausdrücke, um den vorhergesagten Werkzeugnamen und den kompletten Funktionsaufrufblock aus der Modellausgabe zu holen, und vergleichen sie dann mit den Gold-Labels.
import re
import evaluate
import torch
from tqdm.auto import tqdm
cer_metric = evaluate.load("cer")
# Gemma / FunctionGemma-style only
FG_BLOCK_RE = re.compile(r"<start_function_call>.*?<end_function_call>", re.DOTALL)
FG_NAME_RE = re.compile(r"call:([a-zA-Z0-9_]+)\{", re.DOTALL)
def extract_tool_name(gen: str):
gen = gen or ""
m = FG_NAME_RE.search(gen)
return m.group(1) if m else None
def extract_call_block(gen: str):
gen = gen or ""
m = FG_BLOCK_RE.search(gen)
return m.group(0) if m else ""
def gold_call_block(r):
return (
f"<start_function_call>call:{r['tool_name']}"
f"{{args:<escape>{r['tool_arguments']}<escape>}}"
f"<end_function_call>"
)Die Funktion unten macht eine Inferenz für einen Teil der Bewertungsbeispiele und berechnet beide Metriken. Wir lassen die Stichprobenauswahl deaktiviert (do_sample=False), damit die Ergebnisse vorhersagbar sind und man sie vor und nach der Feinabstimmung besser vergleichen kann.
@torch.inference_mode()
def eval_tool_and_cer(proc, mdl, rows, n=50, max_new_tokens=128):
mdl.eval()
n = min(n, len(rows))
tool_ok = 0
preds, refs = [], []
for i in tqdm(range(n)):
r = rows[i]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(out[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True).strip()
if extract_tool_name(gen) == r["tool_name"]:
tool_ok += 1
preds.append(extract_call_block(gen))
refs.append(gold_call_block(r))
return {
"n_eval": n,
"tool_accuracy": tool_ok / n,
"TC-CER (lower is better)": cer_metric.compute(predictions=preds, references=refs),
}Mach die Basisbewertung:
pre_metrics = eval_tool_and_cer(processor, model, simple_eval, n=50, max_new_tokens=128)
print("PRE metrics:", pre_metrics)Schon vor der Feinabstimmung zeigt FunctionGemma bei dieser Aufgabe eine starke Basisleistung.
Bei 50 Testbeispielen hat das Modell eine Genauigkeit von 88 % bei der Erkennung von Werkzeugnamen, was bedeutet, dass es meistens die richtige Funktion auswählt.
Außerdem liegt die Tool-Call-Zeichenfehlerrate (TC-CER) für den kompletten Funktionsaufrufblock bei etwa 33 %, was bedeutet, dass zwar oft das richtige Tool ausgewählt wird, die generierten Argumente und die Formatierung aber trotzdem vom Goldstandard abweichen.
PRE metrics: {'n_eval': 50, 'tool_accuracy': 0.88, 'TC-CER (lower is better)': 0.33399307273626916}Diese Ergebnisse zeigen, dass das Basis-Modell von FunctionGemma schon die Mechanismen des Funktionsaufrufs versteht.
Die ziemlich hohe Fehlerquote zeigt aber, dass noch Feinarbeit nötig ist, um die Vollständigkeit der Argumente, die Konsistenz der Formatierung und die allgemeine strukturelle Korrektheit der generierten Funktionsaufrufe zu verbessern.
Metriken sind nützlich, aber es ist auch wichtig, qualitative Ergebnisse zu betrachten. Der folgende Helfer führt eine Inferenz für ein Beispiel durch und zeigt den vorhergesagten Funktionsaufruf zusammen mit der Goldreferenz an.
import torch
@torch.inference_mode()
def infer_one(proc, mdl, rows, idx=0, max_new_tokens=128):
r = rows[idx]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(
out[0][inputs["input_ids"].shape[-1]:],
skip_special_tokens=True
).strip()
pred_tool = extract_tool_name(gen)
return {
"task": r["user_content"],
"tool_match": (pred_tool == r["tool_name"]),
"predicted": extract_call_block(gen),
"gold": gold_call_block(r),
}Probier's mal an einem Beispiel aus:
pre = infer_one(processor, model, simple_eval, idx=15)
print(f"""
TASK:
{pre['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{pre['predicted']}
--- GOLD ---
{pre['gold']}
""")Ausgabe:
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{nurse_id:<escape>Ratched<escape>,patient_id:<escape>12345<escape>,procedure_type:<escape>Cardiac Bypass<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>In diesem Beispiel wählt das Modell die richtige Funktion aus, deshalb ist die Tool-Übereinstimmung „True“.
Der generierte Aufruf hat aber zusätzliche Argumente und passt nicht genau zur Zielstruktur, die beim Training benutzt wurde.
Obwohl diese Argumente semantisch gesehen Sinn machen, passen sie nicht zum Format des Gold-Funktionsaufrufs, was zu einer höheren Fehlerquote bei den Zeichen führt. Das zeigt, warum Feinabstimmung nötig ist, um die strukturelle Konsistenz und die Schema-Konformität zu verbessern, und nicht nur die Auswahl der Tools.
Jetzt, wo wir saubere SFT-Datensätze haben, müssen wir als Nächstes den Trainer einrichten, der FunctionGemma optimieren wird. Wir nutzen TRLs „ SFTTrainer “, eine einfache und zuverlässige Methode, um Chat-Modelle anhand von Textbeispielen zu optimieren.
Wir legen auch ein Ausgabeverzeichnis fest, damit Kaggle den fein abgestimmten Checkpoint an einem dauerhaften Speicherort speichert.
from trl import SFTConfig, SFTTrainer
OUT_DIR = "/kaggle/working/functiongemma-hermes-ft"Um den VRAM-Verbrauch während des Trainings zu senken, aktivieren wir Gradienten-Checkpointing und deaktivieren den KV-Cache.
# VRAM savings
model.gradient_checkpointing_enable()
model.config.use_cache = FalseWir legen die Trainingskonfiguration mit SFTConfig fest. Diese Einstellungen sind so gewählt, dass sie Stabilität und Effizienz auf Kaggle-GPUs ausbalancieren und gleichzeitig die Trainingszeit kurz halten.
cfg = SFTConfig(
output_dir=OUT_DIR,
max_length=512,
packing=False,
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=5e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
logging_steps=10,
eval_strategy="steps",
eval_steps=10,
report_to="none",
fp16=(model.dtype == torch.float16),
bf16=(model.dtype == torch.bfloat16),
optim="adamw_torch_fused",
)Die Formatierungsfunktion sorgt dafür, dass jedes Trainingsbeispiel als einzelne Zeichenfolge zurückgegeben wird, was von der aktuellen TRL-Version verlangt wird.
def formatting_func(example):
# MUST return a STRING (not list) for your TRL version
t = example.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return str(t)Zum Schluss starten wir die „ SFTTrainer “ mit dem Modell, der Konfiguration, den Datensätzen und dem Tokenizer.
trainer = SFTTrainer(
model=model,
args=cfg,
train_dataset=train_text_ds,
eval_dataset=eval_text_ds,
processing_class=tokenizer,
formatting_func=formatting_func,
)Nachdem der Trainer eingerichtet ist, können wir jetzt mit der Feinabstimmung des Modells anfangen. Dieser Schritt führt ein überwachtes Training mit dem vorbereiteten Datensatz durch und checkt das Modell regelmäßig während des Trainings.
trainer.train()
trainer.save_model(OUT_DIR)
processor.save_pretrained(OUT_DIR)
print("Saved to:", OUT_DIR)Nach dem Training speichern wir sowohl das fein abgestimmte Modell als auch den Prozessor im Ausgabeverzeichnis, damit sie für die Inferenz wiederverwendet oder auf den Hugging Face Hub hochgeladen werden können.
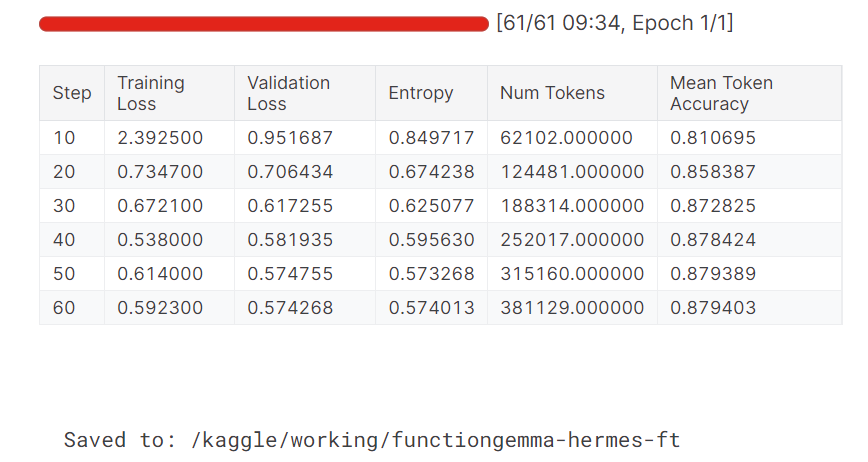
Während des Trainings sinken sowohl der Trainings- als auch der Validierungsverlust stetig. Die durchschnittliche Token-Genauigkeit wird mit der Zeit auch besser, was zeigt, dass das Modell erfolgreich gelernt hat, genauere und konsistentere Funktionsaufruf-Ausgaben zu erzeugen.
Sobald die Feinabstimmung fertig ist, können wir das Modell veröffentlichen, damit es einfach wiederverwendet, geteilt oder eingesetzt werden kann. Wenn du das Modell auf den Hugging Face Hub hochlädst, können andere es direkt über Standard-Transformers-APIs laden.
HF_REPO_ID = "kingabzpro/functiongemma-hermes-3k-ft"
model.push_to_hub(HF_REPO_ID)
processor.push_to_hub(HF_REPO_ID)
print("Pushed to:", HF_REPO_ID)Sobald der Upload fertig ist, ist das optimierte Modell auf Hugging Face öffentlich zugänglich:
Pushed to: kingabzpro/functiongemma-hermes-3k-ft
Quelle: kingabzpro/functiongemma-hermes-3k-ft · Hugging Face
Nachdem die Feinabstimmung fertig ist, laden wir das gespeicherte Modell und den Prozessor von der Festplatte und lassen dieselbe Evaluierungspipeline laufen, die wir vor dem Training benutzt haben. So stellen wir sicher, dass der Vergleich zwischen der Leistung vor und nach dem Fine-Tuning fair und konsistent ist.
from transformers import AutoProcessor, AutoModelForCausalLM
ft_processor = AutoProcessor.from_pretrained(OUT_DIR, device_map="auto")
ft_model = AutoModelForCausalLM.from_pretrained(OUT_DIR, dtype="auto", device_map="auto")Dann checken wir das fein abgestimmte Modell anhand des Bewertungssatzes mit der Genauigkeit der Werkzeugbezeichnung und TC-CER.
post_metrics = eval_tool_and_cer(ft_processor, ft_model, simple_eval, n=50, max_new_tokens=64)
print("POST metrics:", post_metrics)Die Ergebnisse zeigen eine deutliche Verbesserung gegenüber dem Ausgangswert:
POST metrics: {'n_eval': 50, 'tool_accuracy': 0.98, 'TC-CER (lower is better)': 0.1454725383473528}Die Genauigkeit der Tool-Namen steigt von 88 Prozent auf 98 Prozent, und die Zeichenfehlerrate für den gesamten Funktionsaufrufblock wird um mehr als die Hälfte reduziert. Das heißt, das Modell findet nicht nur zuverlässiger das richtige Tool, sondern liefert auch Ergebnisse, die besser zum Zielschema passen.
Um die Verbesserungen besser zu verstehen, schauen wir uns einzelne Vorhersagen genauer an. Im Beispiel unten findet das Modell die richtige Funktion und macht einen gut strukturierten Aufruf mit kompletteren Argumenten.
post = infer_one(ft_processor, ft_model, simple_eval, idx=15)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Auch wenn der vorhergesagte Aufruf vielleicht noch mehr Argumente hat, die über das Goldziel hinausgehen, sind die Gesamtstruktur und die Argumentformate viel einheitlicher als vor der Feinabstimmung. Das zeigt, dass das Schema besser verstanden wird und die Absicht des Benutzers und die generierten Funktionsaufrufe besser aufeinander abgestimmt sind.
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass", "nurse_id": "Ratched", "task": "Post-operative care"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>Schauen wir uns ein weiteres Beispiel an.
post = infer_one(ft_processor, ft_model, simple_eval, idx=25)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Ein zweites Beispiel zeigt einen sauberen und korrekten Funktionsaufruf für eine URL-Extraktionsaufgabe und zeigt, dass das fein abgestimmte Modell gut auf verschiedene Tools übertragbar ist.
TASK:
I would like to extract details from a LinkedIn company page. Could you assist me in fetching the information from this URL: https://www.linkedin.com/company/abc-corporation?
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation", "html": true}<escape>}<end_function_call>Insgesamt zeigen diese Ergebnisse, dass die Feinabstimmung sowohl die Genauigkeit als auch die strukturelle Korrektheit bei der Funktionserkennung verbessert.
Das komplette Kaggle-Notebook für dieses Tutorial findest du unter:https://www.kaggle.com/code/kingabzpro/finetuning-functiongemma
Wenn du Probleme hast, kannst du das Notizbuch kopieren, deinen Hugging Face-Schlüssel hinzufügen und es von Anfang bis Ende ausführen.
Wenn du FunctionGemma mit allgemeinen Datensätzen zur Textgenerierung trainieren willst, solltest du lieber frühzeitig aufhören. FunctionGemma ist nicht dafür gemacht, sich wie ein allgemeines Sprachmodell zu verhalten.
Für die Generierung von offenem Text ist das Gemma 3 Modellfamilie die bessere Wahl.
FunctionGemma wurde extra für Funktionsaufrufe entwickelt, wo es darum geht, das richtige Tool auszuwählen, schemakonforme Argumente zu erstellen und zuverlässig mit externen Systemen wie APIs, Datenbanken und Diensten zu interagieren.
Die kleine Größe von FunctionGemma ist so gewollt. Mit 270 Millionen Parametern ist es für Einsätze mit geringer Latenz und effizienter Ressourcennutzung optimiert, zum Beispiel auf lokalen Rechnern, Edge-Geräten und privater Infrastruktur. Das macht es super für Echtzeit-Funktionsaufrufe und agentenbasierte Workflows, wo es mehr auf Genauigkeit und Struktur als auf flüssige Prosa ankommt.
In diesem Tutorial haben wir gelernt, wie man FunctionGemma auf dem Hermes Reasoning Tool-Use-Datensatz optimiert. Eine wichtige Erkenntnis ist, dass die Datenaufbereitung und -auswertung wichtiger sind als die reine Trainingszeit.
Durch sorgfältige Bereinigung des Datensatzes, die Abstimmung der Aufgaben mit Gold-Tool-Aufrufen und die Durchsetzung strenger Schemakonsistenz konnten wir das Modellverhalten mit einer relativ geringen Anzahl hochwertiger Stichproben deutlich verbessern.
Die Ergebnisse zeigen echt, wie wichtig die Feinabstimmung ist. Die Genauigkeit der Tool-Namen wurde von 88 Prozent auf 98 Prozent verbessert, und die Zeichenfehlerrate für Blöcke mit vollständigen Funktionsaufrufen wurde um mehr als die Hälfte reduziert. Noch wichtiger ist, dass das Modell viel konsequenter gut strukturierte, vorhersehbare Funktionsaufrufe erzeugt, die der realen Nutzung entsprechen.
Die besten DataCamp-Kurse
Kurs
Kurs
Kurs
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Mark Pedigo
Tutorial
Laiba Siddiqui
Tutorial
Matt Crabtree
Tutorial
Stephen Gruppetta

