
Curso
Ajuste fino con Llama 3
2 h
3.7K
En este tutorial, exploraremos FunctionGemma, un modelo de lenguaje ligero para la invocación de funciones de Google DeepMind, y explicaré por qué el ajuste fino es esencial para lograr un uso fiable y conforme al esquema de la herramienta.
Comenzaremos configurando un entorno Kaggle habilitado para GPU, luego cargaremos y prepararemos tanto el conjunto de datos como el modelo FunctionGemma base.
A continuación, realizaremos evaluaciones previas al ajuste fino para establecer una base de referencia para la selección de herramientas y la precisión de las llamadas a funciones. A continuación, ajustaremos FunctionGemma mediante entrenamiento supervisado y evaluaremos su rendimiento tras el entrenamiento para verificar que el ajuste se ha aplicado correctamente.
Si buscas ejercicios prácticos que te ayuden a aprender a realizar ajustes, te recomiendo que eches un vistazo al curso curso Ajuste fino con Llama 3.
FunctionGemma es una versión especializada de Gemma 3 270M , diseñada específicamente para llamar a funciones y utilizar herramientas, en lugar de para mantener conversaciones generales.
Utiliza la misma arquitectura que Gemma 3, pero incluye un formato específico y un enfoque de entrenamiento que te permite generar resultados estructurados que representan llamadas a funciones.
FunctionGemma se lanza como un modelo base que los programadores pueden ajustar para casos de uso específicos. Su tamaño y diseño lo hacen ligero, eficiente y fácil de implementar en dispositivos con recursos limitados, como ordenadores portátiles y hardware periférico.
Aunque FunctionGemma está entrenado para la llamada de funciones, los modelos de este tamaño funcionan mejor cuando se especializan mediante el ajuste fino de datos específicos para cada tarea.
El ajuste fino ayuda al modelo a aprender patrones estables para seleccionar la función correcta de un conjunto de herramientas y dar formato a los argumentos correspondientes de forma correcta para casos de uso reales.
Este proceso da lugar a resultados estructurados más coherentes y predecibles, lo que a su vez mejora la fiabilidad en los flujos de trabajo prácticos.
Veamos los pasos necesarios para ajustar FunctionGemma.
Empieza por ir a Kaggle y crear un nuevo cuaderno. Una vez abierto el cuaderno, busca el panel de opciones de sesión « »(Aceleración deGPU) en la parte derecha y configura el acelerador en GPU (T4 ×2).
Esto habilita la aceleración de la GPU para la sesión y te permite ajustar el modelo utilizando los recursos informáticos gratuitos de Kaggle.
Después de habilitar la GPU, crea una nueva celda de código y ejecuta el siguiente comando para instalar todas las dependencias de Python necesarias. El núcleo puede tardar un poco en iniciarse, tras lo cual los paquetes se instalarán automáticamente.
%pip -q install -U datasets accelerate trl kagglehub sentencepiece huggingface_hub tqdm evaluate jiwerA continuación, añade tu token de acceso a Hugging Face de forma segura.
En el menú superior, abre Complementos → Secretos y, a continuación, haz clic en Añadir secreto. Establece el nombre secreto en HUGGINGFACE_TOKEN y pega tu clave API de Hugging Face como valor.
Usar Kaggle Secrets es más seguro que codificar directamente las variables de entorno o los tokens en el cuaderno.
Una vez guardado el secreto, Kaggle proporcionará un fragmento de código para acceder a él mediante programación.
Utiliza el siguiente código para autenticarte en Hugging Face Hub:
from kaggle_secrets import UserSecretsClient
from huggingface_hub import login
hf_token = UserSecretsClient().get_secret("HUGGINGFACE_TOKEN")
if not hf_token:
raise ValueError("HUGGINGFACE_TOKEN not found in Kaggle Secrets.")
login(token=hf_token)Tras completar con éxito el proceso de autenticación, podrás acceder a modelos y conjuntos de datos restringidos, así como enviar tu modelo FunctionGemma ajustado al Hugging Face Hub para compartirlo y reutilizarlo.
La conjunto de datos Hermes Reasoning Tool-Use es un conjunto de datos abierto en inglés con un formato de razonamiento sobre el uso de herramientas y ejemplos estructurados, diseñado para entrenar y evaluar modelos en tareas de selección de herramientas y llamada a funciones de estilo JSON.
Contiene decenas de miles de ejemplos de razonamiento sobre el uso de herramientas con indicaciones en lenguaje natural y esquemas de herramientas en un formato adecuado para el ajuste supervisado.
En este tutorial, utilizaremos un subconjunto del conjunto de datos para acelerar la experimentación.
En primer lugar, define una semilla aleatoria y el número total de ejemplos que se van a utilizar. A continuación, divide los datos en dos partes: entrenamiento y evaluación:
from datasets import load_dataset
SEED = 40
N_TOTAL = 3000
N_EVAL = 300
N_TRAIN = N_TOTAL - N_EVALA continuación, carga el conjunto de datos, barájalo y crea los subconjuntos de entrenamiento y evaluación:
raw = load_dataset("interstellarninja/hermes_reasoning_tool_use", split="train")
raw = raw.shuffle(seed=SEED).select(range(N_TOTAL))
train_ds = raw.select(range(N_TRAIN))
eval_ds = raw.select(range(N_TRAIN, N_TOTAL))
print("train:", len(train_ds), "eval:", len(eval_ds))
Esto te proporciona 2700 muestras de entrenamiento y 300 muestras de evaluación, suficientes para demostrar el ajuste fino sin que los requisitos informáticos sean excesivos.
train: 2700 eval: 300En este tutorial, utilizamos KaggleHub para cargar el modelo FunctionGemma directamente en el cuaderno de Kaggle.
KaggleHub resuelve automáticamente la ubicación del modelo y lo pone a disposición en el entorno del cuaderno, lo que elimina la necesidad de descargas manuales desde Hugging Face.
import kagglehub
from transformers import AutoProcessor, AutoModelForCausalLM
model_path = kagglehub.model_download("google/functiongemma/transformers/functiongemma-270m-it")Después de ejecutar la celda anterior, los archivos del modelo aparecerán en el sección Input del cuaderno de Kaggle, lo que confirma que el modelo se ha cargado correctamente y está disponible localmente.
Una vez que el modelo está disponible, cargamos tanto el procesador y el modelo en la memoria de la GPU.
El procesador gestiona las plantillas de chat y el formato del esquema de herramientas, mientras que el modelo se encarga de generar llamadas a funciones estructuradas.
Al establecer device_map="auto", te aseguras de que el modelo se coloque en la GPU disponible, y al seleccionar dtype="auto", eliges una precisión eficiente compatible con el hardware.
processor = AutoProcessor.from_pretrained(model_path, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="auto", device_map="auto")
tokenizer = processor.tokenizer if hasattr(processor, "tokenizer") else processor
print("dtype:", model.dtype, "| device:", model.device)Esto confirma que FunctionGemma se ha cargado correctamente, se ha colocado en la GPU y está lista para su evaluación y ajuste.
dtype: torch.bfloat16 | device: cuda:1Antes de ajustar FunctionGemma, necesitamos estandarizar la forma en que se representan las herramientas y extraer de forma fiable las llamadas de función correctas (oro) del conjunto de datos.
El conjunto de datos Hermes Reasoning Tool-Use puede almacenar definiciones de herramientas en múltiples formatos, por lo que este paso convierte todo en una estructura coherente que podemos utilizar para el ajuste supervisado.
Empezamos normalizando el campo tools. En el conjunto de datos, tools puede aparecer como una lista de Python, una cadena JSON o puede faltar por completo.
La función auxiliar siguiente convierte todas las representaciones válidas en una lista Python limpia e ignora de forma segura las entradas malformadas o vacías.
import re, json
def normalize_tools_field(tools):
if tools is None:
return []
if isinstance(tools, list):
return tools
if isinstance(tools, str):
s = tools.strip()
if not s:
return []
try:
parsed = json.loads(s)
return parsed if isinstance(parsed, list) else []
except Exception:
return []
return []A continuación, normalizamos los tipos de parámetros. Las definiciones de herramientas de Hermes suelen utilizar anotaciones de tipos informales, como str,int, o tipos de contenedores como List[str]. La siguiente función convierte estos tipos en tipos JSON Schema válidos que son compatibles con las llamadas a funciones de Hugging Face.
def _parse_hermes_type(t) -> dict:
if t is None:
return {"type": "string"}
if isinstance(t, dict):
return t if "type" in t else {"type": "object"}
if isinstance(t, list):
return {"type": "array"}
if not isinstance(t, str):
return {"type": "string"}
t = t.strip()
prim = {
"str": "string", "string": "string",
"int": "integer", "integer": "integer",
"float": "number", "number": "number",
"bool": "boolean", "boolean": "boolean",
"dict": "object", "object": "object",
"list": "array", "array": "array",
}
if t.lower() in prim:
return {"type": prim[t.lower()]}
m = re.match(r"List\[(.+)\]$", t)
if m:
return {"type": "array", "items": _parse_hermes_type(m.group(1).strip())}
m = re.match(r"Dict\[(.+),\s*(.+)\]$", t)
if m:
return {"type": "object", "additionalProperties": _parse_hermes_type(m.group(2).strip())}
return {"type": "string"}Con estas utilidades, convertimos las definiciones de herramientas al estilo Hermes en esquemas de Hugging Face {"type": "function", "function": {...}}. Esta función admite dos formatos:
Para el formato por argumento, esta implementación trata los parámetros enumerados como obligatorios si no se proporciona explícitamente una lista de requisitos.
def hermes_tools_to_hf_schema(tools_field):
"""
Handles both:
- Hermes per-arg style: {"parameters": {"x":{"type":"str"}, ...}}
- Already-JSON-schema style: {"parameters":{"type":"object","properties":...,"required":[...]}}
"""
hermes_tools = normalize_tools_field(tools_field)
out = []
for tool in hermes_tools:
if not isinstance(tool, dict):
continue
name = tool.get("name")
desc = tool.get("description", "")
params = tool.get("parameters", {}) or {}
# If params already look like JSON schema (best case)
if isinstance(params, dict) and "type" in params and "properties" in params:
json_schema_params = params
if "required" not in json_schema_params:
json_schema_params["required"] = []
else:
props, req = {}, []
if isinstance(params, dict):
for p_name, p_spec in params.items():
p_spec = p_spec or {}
if isinstance(p_spec, dict):
p_desc = p_spec.get("description", "")
p_type = p_spec.get("type", "str")
else:
p_desc, p_type = "", "str"
frag = dict(_parse_hermes_type(p_type))
if p_desc:
frag["description"] = p_desc
props[p_name] = frag
req.append(p_name)
json_schema_params = {"type": "object", "properties": props, "required": req}
out.append({
"type": "function",
"function": {
"name": name,
"description": desc,
"parameters": json_schema_params,
}
})
return outDefinimos un pequeño ayudante para recuperar los esquemas de herramientas convertidos para cada ejemplo de conjunto de datos:
def get_tools_hf(ex):
return hermes_tools_to_hf_schema(ex.get("tools"))A continuación, extraemos la llamada a la herramienta Gold de la conversación. Las conversaciones de Hermes pueden contener múltiples turnos, por lo que analizamos bloques {...} y extraemos el primer objeto de llamada de herramienta válido (nombre + argumentos). Esto hace que la supervisión sea sencilla y coherente.
TOOL_CALL_RE = re.compile(r"<tool_call>\s*(\{.*?\})\s*</tool_call>", re.DOTALL)
def extract_first_tool_call_obj(text: str):
if not text:
return None
m = TOOL_CALL_RE.search(text)
if not m:
return None
try:
obj = json.loads(m.group(1))
if isinstance(obj, dict) and "name" in obj and "arguments" in obj:
return obj
except Exception:
return None
return NonePara alinear la llamada a la herramienta con la tarea correcta del usuario, escaneamos el historial de conversaciones, buscamos el mensaje del usuario que coincide con el conjunto de datos task y, a continuación, tomamos la respuesta del asistente inmediatamente después. Si la respuesta del asistente contiene una llamada a una herramienta, la devolvemos como etiqueta dorada.
def _role(turn):
return (turn.get("from") or "").lower().strip()
def get_gold_tool_call_task_aligned(ex):
task = (ex.get("task") or "").strip()
conv = ex.get("conversations") or []
if not conv:
return None
idx = None
if task:
for i, t in enumerate(conv):
if _role(t) in ["human", "user"]:
val = (t.get("value") or "").strip()
if val == task or task in val or val in task:
idx = i
break
if idx is None:
for i in range(len(conv)-1, -1, -1):
if _role(conv[i]) in ["human", "user"]:
idx = i
break
if idx is None:
return None
for j in range(idx+1, len(conv)):
if _role(conv[j]) in ["gpt", "assistant", "model"]:
gold = extract_first_tool_call_obj(conv[j].get("value", ""))
if gold:
return gold
if _role(conv[j]) in ["human", "user"]:
break
return NoneAl final de este paso, cada ejemplo de conjunto de datos utilizable tiene:
Ahora tenemos que convertirlos en muestras de entrenamiento de ajuste fino supervisado (SFT) en el formato exacto que espera FunctionGemma, utilizando las funciones auxiliares anteriores.
El objetivo es crear ejemplos en los que la entrada contenga:
Y el objetivo es una única llamada estructurada a FunctionGemma con este formato:
<start_function_call>call:TOOL_NAME{args:<escape>{...}<escape>}<end_function_call>Empezamos iterando a través del conjunto de datos y filtrando cualquier ejemplo que no pueda utilizarse para el entrenamiento.
Esta función solo conserva los ejemplos en los que:
from datasets import Dataset
def build_simple_rows(ds, max_rows=None):
rows = []
for ex in ds:
# 1) task-aligned gold tool call
gold = get_gold_tool_call_task_aligned(ex)
if not gold:
continue
# 2) tools -> HF schema
hf_tools = get_tools_hf(ex)
if not hf_tools:
continue
# 3) build required_map: tool_name -> required fields
required_map = {}
for t in hf_tools:
if t.get("type") == "function":
fn = t.get("function", {})
name = fn.get("name")
req = (fn.get("parameters", {}) or {}).get("required", []) or []
if name:
required_map[name] = req
# 4) guard: gold tool must be in tool list
tool_names = set(required_map.keys())
if gold["name"] not in tool_names:
continue
# 5) force {} when no required params
gold_args = gold.get("arguments", {})
if not isinstance(gold_args, dict):
gold_args = {}
req = required_map.get(gold["name"], [])
if len(req) == 0:
gold_args = {} # key fix
rows.append({
"user_content": ex.get("task", ""),
"tool_name": gold["name"],
"tool_arguments": json.dumps(gold_args, ensure_ascii=False),
"hf_tools": hf_tools,
})
if max_rows and len(rows) >= max_rows:
break
return rowsAhora generamos filas de entrenamiento y evaluación:
simple_train = build_simple_rows(train_ds, max_rows=N_TRAIN)
simple_eval = build_simple_rows(eval_ds, max_rows=N_EVAL)
print("usable train:", len(simple_train), "usable eval:", len(simple_eval))En nuestro caso, terminamos con 961 muestras de entrenamiento y 109 muestras de evaluación de las 3000 originales. Esta caída es previsible debido a que el filtrado es estricto. Elimina los ejemplos con llamadas a herramientas que faltan, definiciones de herramientas no válidas, nombres de herramientas que no coinciden o argumentos mal formados.
usable train: 961 usable eval: 109Este paso de limpieza es muy importante. Antes de aplicarlo, el conjunto de datos contenía muestras ruidosas y desalineadas, lo que provocaba un comportamiento inestable en la llamada a funciones y resultados deficientes incluso después del ajuste fino. Tras filtrar solo los ejemplos de alta calidad y alineados con las tareas, FunctionGemma se vuelve mucho más coherente y los resultados del ajuste fino mejoran significativamente.
A continuación, formateamos cada fila con la estructura exacta de indicaciones y objetivos que necesita FunctionGemma. Utilizamos el procesador apply_chat_template para inyectar correctamente las declaraciones de herramientas y, a continuación, añadimos la llamada a la función gold como destino.
def format_row_as_text(row):
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": row["user_content"]},
]
prompt = processor.apply_chat_template(
messages,
tools=row["hf_tools"],
add_generation_prompt=True,
tokenize=False,
)
target = (
f"<start_function_call>call:{row['tool_name']}"
f"{{args:<escape>{row['tool_arguments']}<escape>}}"
f"<end_function_call>"
)
return prompt + targetAhora convertimos las filas en objetos del conjunto de datos Hugging Face:
train_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_train])
eval_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_eval])Algunas versiones de TRL requieren que formatting_func devuelva una cadena, y el entrenamiento puede fallar si alguna muestra se convierte en una lista o en un valor que no sea una cadena. Este ayudante obliga a text a ser siempre una cadena limpia.
# ensure text is always a string
def force_text_string(ds):
def fix(ex):
t = ex.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return {"text": str(t)}
return ds.map(fix)
train_text_ds = force_text_string(train_text_ds)
eval_text_ds = force_text_string(eval_text_ds)Por último, imprime una muestra para confirmar el formato:
print(train_text_ds[0]["text"])Deberías ver un mensaje completamente renderizado que contiene declaraciones de herramientas, seguido de una llamada a la función gold similar a:
<bos><start_of_turn>developer
You are a model that can do function calling with the following functions<start_function_declaration>declaration:get_pollution_levels{description:<escape>Retrieve pollution levels information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the pollution levels (e.g., Beijing, London, New York)<escape>,type:<escape>STRING<escape>},pollutant:{description:<escape>Specify a pollutant for pollution levels (e.g., PM2.5, PM10, ozone)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><start_function_declaration>declaration:get_water_quality{description:<escape>Retrieve water quality information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the water quality (e.g., river, lake, beach)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><end_of_turn>
<start_of_turn>user
I'm planning a beach cleanup at Zuma Beach this weekend and need to ensure safety. Can you provide the current water quality and if it's poor, check the pollution level of PM2.5 there?<end_of_turn>
<start_of_turn>model
<start_function_call>call:get_water_quality{args:<escape>{"location": "Zuma Beach"}<escape>}<end_function_call>Antes del entrenamiento, debes medir el rendimiento del modelo base FunctionGemma en la llamada de funciones. Esta línea de base te ayuda a confirmar que el ajuste fino realmente mejora la selección de herramientas y el formato de las llamadas a funciones.
En esta sección, evaluamos dos cosas:
Utilizamos dos expresiones regulares para extraer el nombre de la herramienta predicha y el bloque completo de llamada a la función de la salida del modelo, y luego los comparamos con las etiquetas de referencia.
import re
import evaluate
import torch
from tqdm.auto import tqdm
cer_metric = evaluate.load("cer")
# Gemma / FunctionGemma-style only
FG_BLOCK_RE = re.compile(r"<start_function_call>.*?<end_function_call>", re.DOTALL)
FG_NAME_RE = re.compile(r"call:([a-zA-Z0-9_]+)\{", re.DOTALL)
def extract_tool_name(gen: str):
gen = gen or ""
m = FG_NAME_RE.search(gen)
return m.group(1) if m else None
def extract_call_block(gen: str):
gen = gen or ""
m = FG_BLOCK_RE.search(gen)
return m.group(0) if m else ""
def gold_call_block(r):
return (
f"<start_function_call>call:{r['tool_name']}"
f"{{args:<escape>{r['tool_arguments']}<escape>}}"
f"<end_function_call>"
)La función siguiente ejecuta la inferencia en un subconjunto de ejemplos de evaluación y calcula ambas métricas. Mantenemos desactivado el muestreo (do_sample=False) para que los resultados sean deterministas y más fáciles de comparar antes y después del ajuste fino.
@torch.inference_mode()
def eval_tool_and_cer(proc, mdl, rows, n=50, max_new_tokens=128):
mdl.eval()
n = min(n, len(rows))
tool_ok = 0
preds, refs = [], []
for i in tqdm(range(n)):
r = rows[i]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(out[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True).strip()
if extract_tool_name(gen) == r["tool_name"]:
tool_ok += 1
preds.append(extract_call_block(gen))
refs.append(gold_call_block(r))
return {
"n_eval": n,
"tool_accuracy": tool_ok / n,
"TC-CER (lower is better)": cer_metric.compute(predictions=preds, references=refs),
}Ejecuta la evaluación de referencia:
pre_metrics = eval_tool_and_cer(processor, model, simple_eval, n=50, max_new_tokens=128)
print("PRE metrics:", pre_metrics)Incluso antes del ajuste, FunctionGemma muestra un sólido rendimiento básico en esta tarea.
En un subconjunto de 50 ejemplos de evaluación, el modelo alcanza una precisión del 88 % en el nombre de la herramienta, lo que significa que selecciona la función correcta en la mayoría de los casos.
Además, la tasa de error de caracteres de llamada a herramientas (TC-CER) es de aproximadamente el 33 % para el bloque completo de llamadas a funciones, lo que indica que, aunque a menudo se elige la herramienta correcta, los argumentos y el formato generados siguen desviándose del objetivo deseado.
PRE metrics: {'n_eval': 50, 'tool_accuracy': 0.88, 'TC-CER (lower is better)': 0.33399307273626916}Estos resultados confirman que el modelo básico FunctionGemma ya comprende la mecánica de la invocación de funciones.
Sin embargo, la tasa de error relativamente alta pone de manifiesto la necesidad de realizar ajustes para mejorar la integridad de los argumentos, la coherencia del formato y la corrección estructural general de las llamadas a funciones generadas.
Las métricas son útiles, pero también es importante tener en cuenta los resultados cualitativos. El asistente que aparece a continuación ejecuta la inferencia para un ejemplo e imprime la llamada a la función predicha junto con la referencia de oro.
import torch
@torch.inference_mode()
def infer_one(proc, mdl, rows, idx=0, max_new_tokens=128):
r = rows[idx]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(
out[0][inputs["input_ids"].shape[-1]:],
skip_special_tokens=True
).strip()
pred_tool = extract_tool_name(gen)
return {
"task": r["user_content"],
"tool_match": (pred_tool == r["tool_name"]),
"predicted": extract_call_block(gen),
"gold": gold_call_block(r),
}Ejecuta un ejemplo:
pre = infer_one(processor, model, simple_eval, idx=15)
print(f"""
TASK:
{pre['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{pre['predicted']}
--- GOLD ---
{pre['gold']}
""")Salida:
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{nurse_id:<escape>Ratched<escape>,patient_id:<escape>12345<escape>,procedure_type:<escape>Cardiac Bypass<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>En este ejemplo, el modelo selecciona correctamente la función adecuada, por lo que la coincidencia de la herramienta es True.
Sin embargo, la llamada generada incluye argumentos adicionales y no sigue exactamente la estructura de destino utilizada en el entrenamiento.
Aunque estos argumentos son semánticamente razonables, no coinciden con el formato de llamada a la función gold, lo que contribuye a una mayor tasa de errores de caracteres. Esto ilustra por qué es necesario realizar ajustes para mejorar la coherencia estructural y el cumplimiento del esquema, y no solo la selección de herramientas.
Ahora que tenemos conjuntos de datos SFT limpios, el siguiente paso es configurar el entrenador que ajustará FunctionGemma. Utilizamos el modelo de TRL « SFTTrainer », que es una forma ligera y fiable de ajustar modelos de estilo chat en ejemplos de texto.
También establecemos un directorio de salida para que Kaggle guarde el punto de control ajustado en una ubicación persistente.
from trl import SFTConfig, SFTTrainer
OUT_DIR = "/kaggle/working/functiongemma-hermes-ft"Para reducir el uso de VRAM durante el entrenamiento, habilitamos el control de puntos de verificación de gradientes y deshabilitamos la caché KV.
# VRAM savings
model.gradient_checkpointing_enable()
model.config.use_cache = FalseDefinimos la configuración de entrenamiento utilizando SFTConfig. Estos ajustes se eligen para equilibrar la estabilidad y la eficiencia en las GPU de Kaggle, al tiempo que se mantiene un tiempo de entrenamiento breve.
cfg = SFTConfig(
output_dir=OUT_DIR,
max_length=512,
packing=False,
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=5e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
logging_steps=10,
eval_strategy="steps",
eval_steps=10,
report_to="none",
fp16=(model.dtype == torch.float16),
bf16=(model.dtype == torch.bfloat16),
optim="adamw_torch_fused",
)La función de formateo garantiza que cada ejemplo de entrenamiento se devuelva como una sola cadena, tal y como exige la versión actual de TRL.
def formatting_func(example):
# MUST return a STRING (not list) for your TRL version
t = example.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return str(t)Por último, inicializamos el modelo de lenguaje grande ( SFTTrainer ) con el modelo, la configuración, los conjuntos de datos y el tokenizador.
trainer = SFTTrainer(
model=model,
args=cfg,
train_dataset=train_text_ds,
eval_dataset=eval_text_ds,
processing_class=tokenizer,
formatting_func=formatting_func,
)Una vez configurado el entrenador, ya podemos empezar a ajustar el modelo. Este paso ejecuta el entrenamiento supervisado en el conjunto de datos preparado y evalúa el modelo periódicamente durante el entrenamiento.
trainer.train()
trainer.save_model(OUT_DIR)
processor.save_pretrained(OUT_DIR)
print("Saved to:", OUT_DIR)Una vez completado el entrenamiento, guardamos tanto el modelo ajustado como el procesador en el directorio de salida para que puedan reutilizarse para la inferencia o cargarse en Hugging Face Hub.
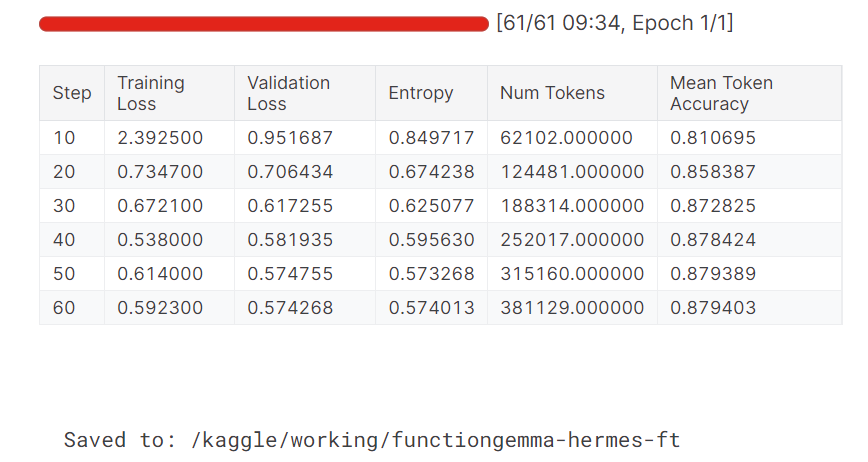
Durante el entrenamiento, tanto la pérdida de entrenamiento como la de validación disminuyen de forma constante. La precisión media de los tokens también mejora con el tiempo, lo que indica que el modelo ha aprendido con éxito a producir resultados de llamadas a funciones más precisos y coherentes.
Una vez completado el ajuste, podemos publicar el modelo para que pueda reutilizarse, compartirse o implementarse fácilmente. Al enviar el modelo al Hugging Face Hub, otros usuarios pueden cargarlo directamente utilizando las API estándar de Transformers.
HF_REPO_ID = "kingabzpro/functiongemma-hermes-3k-ft"
model.push_to_hub(HF_REPO_ID)
processor.push_to_hub(HF_REPO_ID)
print("Pushed to:", HF_REPO_ID)Una vez completada la carga, el modelo ajustado estará disponible públicamente en Hugging Face:
Pushed to: kingabzpro/functiongemma-hermes-3k-ft
Fuente: kingabzpro/functiongemma-hermes-3k-ft · Hugging Face
Una vez completado el ajuste, volvemos a cargar el modelo y el procesador guardados desde el disco y ejecutamos el mismo proceso de evaluación utilizado antes del entrenamiento. Esto garantiza que la comparación entre el rendimiento antes y después del ajuste sea justa y coherente.
from transformers import AutoProcessor, AutoModelForCausalLM
ft_processor = AutoProcessor.from_pretrained(OUT_DIR, device_map="auto")
ft_model = AutoModelForCausalLM.from_pretrained(OUT_DIR, dtype="auto", device_map="auto")A continuación, evaluamos el modelo ajustado en el conjunto de evaluación utilizando la precisión del nombre de la herramienta y el TC-CER.
post_metrics = eval_tool_and_cer(ft_processor, ft_model, simple_eval, n=50, max_new_tokens=64)
print("POST metrics:", post_metrics)Los resultados muestran una clara mejora con respecto al punto de referencia:
POST metrics: {'n_eval': 50, 'tool_accuracy': 0.98, 'TC-CER (lower is better)': 0.1454725383473528}La precisión del nombre de la herramienta mejora del 88 % al 98 %, y la tasa de error de caracteres para el bloque completo de llamadas a funciones se reduce a más de la mitad. Esto indica que el modelo no solo selecciona la herramienta correcta de forma más fiable, sino que también produce resultados que se ajustan mejor al esquema objetivo.
Para comprender mejor las mejoras, inspeccionamos las predicciones individuales. En el ejemplo siguiente, el modelo selecciona la función correcta y genera una llamada bien estructurada con argumentos más completos.
post = infer_one(ft_processor, ft_model, simple_eval, idx=15)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Aunque la llamada prevista puede incluir argumentos adicionales que van más allá del objetivo principal, la estructura general y el formato de los argumentos son mucho más coherentes que antes del ajuste. Esto refleja una mayor conciencia del esquema y una mayor alineación entre la intención del usuario y las llamadas a funciones generadas.
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass", "nurse_id": "Ratched", "task": "Post-operative care"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>Veamos otro ejemplo.
post = infer_one(ft_processor, ft_model, simple_eval, idx=25)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Un segundo ejemplo muestra una llamada de función limpia y correcta para una tarea de extracción de URL, lo que demuestra que el modelo ajustado se generaliza bien en diferentes herramientas.
TASK:
I would like to extract details from a LinkedIn company page. Could you assist me in fetching the information from this URL: https://www.linkedin.com/company/abc-corporation?
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation", "html": true}<escape>}<end_function_call>En general, estos resultados confirman que el ajuste fino mejora con éxito tanto la precisión como la corrección estructural de las tareas de identificación de funciones.
El cuaderno completo de Kaggle para este tutorial está disponible en:https://www.kaggle.com/code/kingabzpro/finetuning-functiongemma
Si tienes algún problema, puedes clonar el cuaderno, añadir tu clave secreta de Hugging Face y ejecutarlo de principio a fin.
Si estás intentando entrenar FunctionGemma con conjuntos de datos genéricos para la generación de texto, es mejor que lo dejes cuanto antes. FunctionGemma no está diseñado para comportarse como un modelo de lenguaje de uso general.
Para la generación de texto abierto, el familia de modelos Gemma 3 es una mejor opción.
FunctionGemma está especialmente diseñado para la llamada de funciones, donde el objetivo es seleccionar la herramienta correcta, producir argumentos que cumplan con el esquema e interactuar de forma fiable con sistemas externos como API, bases de datos y servicios.
La pequeña tamaño de FunctionGemma es una elección de diseño deliberada. Con 270 millones de parámetros, está optimizado para implementaciones de baja latencia y eficientes en cuanto a recursos, incluyendo máquinas locales, dispositivos periféricos e infraestructura privada. Esto lo hace muy adecuado para llamadas de funciones en tiempo real y flujos de trabajo agenticos, donde la corrección y la estructura son más importantes que la fluidez del lenguaje.
En este tutorial, hemos aprendido a ajustar FunctionGemma en el conjunto de datos Hermes Reasoning Tool-Use. Una conclusión clave es que la preparación y la evaluación de los datos son más importantes que el tiempo de entrenamiento en bruto.
Mediante una limpieza minuciosa del conjunto de datos, la alineación de las tareas con las llamadas de herramientas de referencia y la aplicación de una estricta coherencia en el esquema, logramos mejorar considerablemente el comportamiento del modelo con un número relativamente pequeño de muestras de alta calidad.
Los resultados muestran claramente el impacto del ajuste fino. La precisión del nombre de la herramienta mejoró del 88 % al 98 %, y la tasa de error de caracteres para bloques de llamadas de función completos se redujo a más de la mitad. Más importante aún, el modelo se volvió mucho más consistente en la producción de llamadas a funciones bien estructuradas y predecibles que se ajustan al uso en el mundo real.
Los mejores cursos de DataCamp
Curso
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Abid Ali Awan


