
Cours
Ajustement fin avec Llama 3
2 h
3.7K
Dans ce tutoriel, nous explorerons FunctionGemma, un modèle de langage léger pour l'appel de fonctions développé par Google DeepMind, et j'expliquerai pourquoi le réglage fin est essentiel pour obtenir une utilisation fiable et conforme au schéma de l'outil.
Nous commencerons par configurer un environnement Kaggle compatible avec les GPU, puis nous chargerons et préparerons à la fois l'ensemble de données et le modèle FunctionGemma de base.
Ensuite, nous procéderons à des évaluations préalables au réglage fin afin d'établir une base de référence pour la sélection des outils et la précision des appels de fonction. Nous procéderons ensuite à l'ajustement de FunctionGemma à l'aide d'un apprentissage supervisé et évaluerons ses performances après l'apprentissage afin de vérifier que l'ajustement a été correctement appliqué.
Si vous recherchez des exercices pratiques pour vous aider à apprendre le réglage fin, je vous recommande de consulter le cours cours « Fine-Tuning with Llama 3 ».
FunctionGemma est une version spécialisée de modèle ouvert Gemma 3 270M , conçue spécifiquement pour l'appel de fonctions et l'utilisation d'outils plutôt que pour la conversation générale.
Il utilise la même architecture que Gemma 3, mais inclut un format dédié et une approche d'entraînement qui lui permettent de générer des sorties structurées représentant des appels de fonction.
FunctionGemma est disponible en tant que modèle de base que les développeurs peuvent adapter à des cas d'utilisation spécifiques. Sa taille et sa conception le rendent léger, efficace et déployable sur des appareils aux ressources limitées, tels que les ordinateurs portables et le matériel périphérique.
Bien que FunctionGemma soit entraîné pour l'appel de fonctions, les modèles de cette taille fonctionnent mieux lorsqu'ils sont spécialisés grâce à un réglage fin sur des données spécifiques à la tâche.
Le réglage fin aide le modèle à apprendre des modèles stables pour sélectionner la fonction appropriée parmi un ensemble d'outils et formater correctement les arguments correspondants pour des cas d'utilisation réels.
Ce processus permet d'obtenir des résultats structurés plus cohérents et prévisibles, ce qui améliore la fiabilité des flux de travail pratiques.
Veuillez suivre les étapes nécessaires pour optimiser FunctionGemma.
Veuillez commencer par vous rendre sur Kaggle et créer un nouveau notebook. Une fois le bloc-notes ouvert, veuillez localiser le panneau Options de session d' sur le côté droit et régler l'accélérateur sur GPU (T4 ×2).
Cela active l'accélération GPU pour la session et vous permet d'ajuster le modèle à l'aide des ressources de calcul gratuites de Kaggle.
Après avoir activé le GPU, veuillez créer une nouvelle cellule de code et exécuter la commande suivante pour installer toutes les dépendances Python requises. Le noyau peut prendre un certain temps à démarrer, après quoi les paquets seront installés automatiquement.
%pip -q install -U datasets accelerate trl kagglehub sentencepiece huggingface_hub tqdm evaluate jiwerEnsuite, veuillez ajouter votre jeton d'accès Hugging Face de manière sécurisée.
Dans le menu supérieur, veuillez ouvrir Add-ons → Secrets, puis cliquer sur Ajouter un secret. Veuillez définir le nom secret sur HUGGINGFACE_TOKEN et insérer votre clé API Hugging Face comme valeur.
L'utilisation de Kaggle Secrets est plus sécurisée que le codage en dur des variables d'environnement ou des jetons directement dans le notebook.
Une fois le secret enregistré, Kaggle fournira un extrait de code permettant d'y accéder par programmation.
Veuillez utiliser le code suivant pour vous authentifier auprès du Hugging Face Hub :
from kaggle_secrets import UserSecretsClient
from huggingface_hub import login
hf_token = UserSecretsClient().get_secret("HUGGINGFACE_TOKEN")
if not hf_token:
raise ValueError("HUGGINGFACE_TOKEN not found in Kaggle Secrets.")
login(token=hf_token)Une fois l'authentification réussie, vous pourrez accéder aux modèles et ensembles de données protégés, ainsi que transférer votre modèle FunctionGemma optimisé vers le Hugging Face Hub afin de le partager et de le réutiliser.
L' Hermes Reasoning Tool-Use est un ensemble de données ouvert en anglais au format de raisonnement sur l'utilisation d'outils, avec des exemples structurés conçus pour former et évaluer des modèles sur la sélection d'outils et les tâches d'appel de fonctions de type JSON.
Il contient des dizaines de milliers d'exemples de raisonnements sur l'utilisation d'outils, accompagnés d'invites en langage naturel et de schémas d'outils, dans un format adapté au réglage supervisé.
Dans ce tutoriel, nous utiliserons un sous-ensemble de l'ensemble de données afin d'accélérer l'expérimentation.
Tout d'abord, veuillez définir une graine aléatoire et le nombre total d'exemples à utiliser. Veuillez ensuite diviser les données en deux parties distinctes : l'entraînement et l'évaluation.
from datasets import load_dataset
SEED = 40
N_TOTAL = 3000
N_EVAL = 300
N_TRAIN = N_TOTAL - N_EVALEnsuite, chargez l'ensemble de données, mélangez-le et créez les sous-ensembles d'entraînement et d'évaluation :
raw = load_dataset("interstellarninja/hermes_reasoning_tool_use", split="train")
raw = raw.shuffle(seed=SEED).select(range(N_TOTAL))
train_ds = raw.select(range(N_TRAIN))
eval_ds = raw.select(range(N_TRAIN, N_TOTAL))
print("train:", len(train_ds), "eval:", len(eval_ds))
Vous disposez ainsi de 2 700 échantillons d'entraînement et de 300 échantillons d'évaluation, ce qui est suffisant pour démontrer le réglage fin tout en conservant des exigences informatiques gérables.
train: 2700 eval: 300Dans ce tutoriel, nous utilisons KaggleHub pour charger le modèle FunctionGemma directement dans le notebook Kaggle.
KaggleHub détermine automatiquement l'emplacement du modèle et le rend accessible dans l'environnement du notebook, éliminant ainsi le besoin de téléchargements manuels depuis Hugging Face.
import kagglehub
from transformers import AutoProcessor, AutoModelForCausalLM
model_path = kagglehub.model_download("google/functiongemma/transformers/functiongemma-270m-it")Après avoir exécuté la cellule ci-dessus, les fichiers de modèle apparaîtront dans le section Input du notebook Kaggle, confirmant que le modèle a été chargé avec succès et qu'il est disponible localement.
Une fois le modèle disponible, nous chargeons à la fois le processeur et le modèle dans la mémoire du GPU.
Le processeur gère les modèles de chat et le formatage des schémas d'outils, tandis que le modèle est chargé de générer des appels de fonction structurés.
En définissant device_map="auto", vous vous assurez que le modèle est placé sur le GPU disponible, et en sélectionnant dtype="auto", vous choisissez une précision efficace prise en charge par le matériel.
processor = AutoProcessor.from_pretrained(model_path, device_map="auto")
model = AutoModelForCausalLM.from_pretrained(model_path, dtype="auto", device_map="auto")
tokenizer = processor.tokenizer if hasattr(processor, "tokenizer") else processor
print("dtype:", model.dtype, "| device:", model.device)Cela confirme que FunctionGemma est correctement chargé, placé sur le GPU et prêt pour l'évaluation et le réglage fin.
dtype: torch.bfloat16 | device: cuda:1Avant de procéder au réglage fin de FunctionGemma, il est nécessaire de normaliser la représentation des outils et d'extraire de manière fiable les appels de fonction corrects (référentiels) à partir de l'ensemble de données.
L'ensemble de données Hermes Reasoning Tool-Use peut stocker des définitions d'outils dans plusieurs formats. Cette étape permet donc de tout convertir en une structure cohérente que nous pouvons utiliser pour le réglage supervisé.
Nous commençons par normaliser le champ d'tools. Dans l'ensemble de données, tools peut apparaître sous la forme d'une liste Python, d'une chaîne JSON ou être totalement absent.
La fonction d'aide ci-dessous convertit toutes les représentations valides en une liste Python propre et ignore en toute sécurité les entrées mal formées ou vides.
import re, json
def normalize_tools_field(tools):
if tools is None:
return []
if isinstance(tools, list):
return tools
if isinstance(tools, str):
s = tools.strip()
if not s:
return []
try:
parsed = json.loads(s)
return parsed if isinstance(parsed, list) else []
except Exception:
return []
return []Ensuite, nous normalisons les types de paramètres. Les définitions d'outils Hermes utilisent souvent des annotations de type informelles telles que str,int ou des types de conteneurs tels que List[str]. La fonction ci-dessous convertit ces données en types JSON Schema valides, compatibles avec l'appel de fonctions Hugging Face.
def _parse_hermes_type(t) -> dict:
if t is None:
return {"type": "string"}
if isinstance(t, dict):
return t if "type" in t else {"type": "object"}
if isinstance(t, list):
return {"type": "array"}
if not isinstance(t, str):
return {"type": "string"}
t = t.strip()
prim = {
"str": "string", "string": "string",
"int": "integer", "integer": "integer",
"float": "number", "number": "number",
"bool": "boolean", "boolean": "boolean",
"dict": "object", "object": "object",
"list": "array", "array": "array",
}
if t.lower() in prim:
return {"type": prim[t.lower()]}
m = re.match(r"List\[(.+)\]$", t)
if m:
return {"type": "array", "items": _parse_hermes_type(m.group(1).strip())}
m = re.match(r"Dict\[(.+),\s*(.+)\]$", t)
if m:
return {"type": "object", "additionalProperties": _parse_hermes_type(m.group(2).strip())}
return {"type": "string"}À l'aide de ces utilitaires, nous convertissons les définitions d'outils de type Hermes en schémas d'{"type": "function", "function": {...}} s Hugging Face. Cette fonction prend en charge deux formats :
Pour le format par argument, cette implémentation considère les paramètres listés comme obligatoires si aucune liste obligatoire n'est explicitement fournie.
def hermes_tools_to_hf_schema(tools_field):
"""
Handles both:
- Hermes per-arg style: {"parameters": {"x":{"type":"str"}, ...}}
- Already-JSON-schema style: {"parameters":{"type":"object","properties":...,"required":[...]}}
"""
hermes_tools = normalize_tools_field(tools_field)
out = []
for tool in hermes_tools:
if not isinstance(tool, dict):
continue
name = tool.get("name")
desc = tool.get("description", "")
params = tool.get("parameters", {}) or {}
# If params already look like JSON schema (best case)
if isinstance(params, dict) and "type" in params and "properties" in params:
json_schema_params = params
if "required" not in json_schema_params:
json_schema_params["required"] = []
else:
props, req = {}, []
if isinstance(params, dict):
for p_name, p_spec in params.items():
p_spec = p_spec or {}
if isinstance(p_spec, dict):
p_desc = p_spec.get("description", "")
p_type = p_spec.get("type", "str")
else:
p_desc, p_type = "", "str"
frag = dict(_parse_hermes_type(p_type))
if p_desc:
frag["description"] = p_desc
props[p_name] = frag
req.append(p_name)
json_schema_params = {"type": "object", "properties": props, "required": req}
out.append({
"type": "function",
"function": {
"name": name,
"description": desc,
"parameters": json_schema_params,
}
})
return outNous définissons une petite fonction d'aide pour récupérer les schémas d'outils convertis pour chaque exemple d'ensemble de données :
def get_tools_hf(ex):
return hermes_tools_to_hf_schema(ex.get("tools"))Nous extrayons ensuite l'appel de l'outil Gold de la conversation. Les conversations Hermes peuvent comporter plusieurs tours, nous analysons donc les blocs d'{...} s et extrayons le premier objet d'appel d'outil valide (nom + arguments). Cela permet de maintenir une supervision simple et cohérente.
TOOL_CALL_RE = re.compile(r"<tool_call>\s*(\{.*?\})\s*</tool_call>", re.DOTALL)
def extract_first_tool_call_obj(text: str):
if not text:
return None
m = TOOL_CALL_RE.search(text)
if not m:
return None
try:
obj = json.loads(m.group(1))
if isinstance(obj, dict) and "name" in obj and "arguments" in obj:
return obj
except Exception:
return None
return NoneAfin d'aligner l'appel de l'outil avec la tâche utilisateur appropriée, nous analysons l'historique des conversations, identifions le message utilisateur correspondant à l'task du jeu de données, puis sélectionnons la réponse de l'assistant qui suit immédiatement ce message. Si la réponse de l'assistant contient un appel d'outil, nous la renvoyons en tant qu'étiquette dorée.
def _role(turn):
return (turn.get("from") or "").lower().strip()
def get_gold_tool_call_task_aligned(ex):
task = (ex.get("task") or "").strip()
conv = ex.get("conversations") or []
if not conv:
return None
idx = None
if task:
for i, t in enumerate(conv):
if _role(t) in ["human", "user"]:
val = (t.get("value") or "").strip()
if val == task or task in val or val in task:
idx = i
break
if idx is None:
for i in range(len(conv)-1, -1, -1):
if _role(conv[i]) in ["human", "user"]:
idx = i
break
if idx is None:
return None
for j in range(idx+1, len(conv)):
if _role(conv[j]) in ["gpt", "assistant", "model"]:
gold = extract_first_tool_call_obj(conv[j].get("value", ""))
if gold:
return gold
if _role(conv[j]) in ["human", "user"]:
break
return NoneÀ la fin de cette étape, chaque exemple d'ensemble de données utilisable comporte :
Nous devons maintenant les convertir en des échantillons de formation supervisée (SFT) dans le format exact attendu par FunctionGemma, en utilisant les fonctions d'aide ci-dessus.
L'objectif est de créer des exemples où l'entrée contient :
Et la cible est un appel FunctionGemma unique et structuré dans ce format :
<start_function_call>call:TOOL_NAME{args:<escape>{...}<escape>}<end_function_call>Nous commençons par parcourir l'ensemble de données et filtrer tous les exemples qui ne peuvent pas être utilisés pour l'entraînement.
Cette fonction conserve uniquement les exemples où :
from datasets import Dataset
def build_simple_rows(ds, max_rows=None):
rows = []
for ex in ds:
# 1) task-aligned gold tool call
gold = get_gold_tool_call_task_aligned(ex)
if not gold:
continue
# 2) tools -> HF schema
hf_tools = get_tools_hf(ex)
if not hf_tools:
continue
# 3) build required_map: tool_name -> required fields
required_map = {}
for t in hf_tools:
if t.get("type") == "function":
fn = t.get("function", {})
name = fn.get("name")
req = (fn.get("parameters", {}) or {}).get("required", []) or []
if name:
required_map[name] = req
# 4) guard: gold tool must be in tool list
tool_names = set(required_map.keys())
if gold["name"] not in tool_names:
continue
# 5) force {} when no required params
gold_args = gold.get("arguments", {})
if not isinstance(gold_args, dict):
gold_args = {}
req = required_map.get(gold["name"], [])
if len(req) == 0:
gold_args = {} # key fix
rows.append({
"user_content": ex.get("task", ""),
"tool_name": gold["name"],
"tool_arguments": json.dumps(gold_args, ensure_ascii=False),
"hf_tools": hf_tools,
})
if max_rows and len(rows) >= max_rows:
break
return rowsNous générons maintenant des lignes d'entraînement et d'évaluation :
simple_train = build_simple_rows(train_ds, max_rows=N_TRAIN)
simple_eval = build_simple_rows(eval_ds, max_rows=N_EVAL)
print("usable train:", len(simple_train), "usable eval:", len(simple_eval))Dans notre cas, nous obtenons 961 échantillons d'entraînement et 109 échantillons d'évaluation sur les 3 000 initialement disponibles. Cette baisse est prévisible en raison de la rigueur du filtrage. Il supprime les exemples comportant des appels d'outils manquants, des définitions d'outils non valides, des noms d'outils non correspondants ou des arguments mal formés.
usable train: 961 usable eval: 109Cette étape de nettoyage est très importante. Avant son application, l'ensemble de données contenait des échantillons bruités et mal alignés, ce qui entraînait un comportement instable des appels de fonction et des résultats médiocres, même après un réglage fin. Après avoir filtré uniquement les exemples de haute qualité et adaptés à la tâche, FunctionGemma devient beaucoup plus cohérent et les résultats du réglage fin s'améliorent considérablement.
Ensuite, nous formatons chaque ligne selon la structure exacte « prompt-plus-target » requise par FunctionGemma. Nous utilisons l' apply_chat_template du processeur pour insérer correctement les déclarations d'outils, puis nous ajoutons l'appel de fonction gold comme cible.
def format_row_as_text(row):
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": row["user_content"]},
]
prompt = processor.apply_chat_template(
messages,
tools=row["hf_tools"],
add_generation_prompt=True,
tokenize=False,
)
target = (
f"<start_function_call>call:{row['tool_name']}"
f"{{args:<escape>{row['tool_arguments']}<escape>}}"
f"<end_function_call>"
)
return prompt + targetNous convertissons maintenant les lignes en objets Hugging Face Dataset :
train_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_train])
eval_text_ds = Dataset.from_list([{"text": format_row_as_text(r)} for r in simple_eval])Certaines versions TRL exigent que formatting_func renvoie une chaîne de caractères, et l'entraînement peut échouer si un échantillon devient une liste ou une valeur non string. Cette fonction d'aide garantit que text est toujours une chaîne de caractères valide.
# ensure text is always a string
def force_text_string(ds):
def fix(ex):
t = ex.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return {"text": str(t)}
return ds.map(fix)
train_text_ds = force_text_string(train_text_ds)
eval_text_ds = force_text_string(eval_text_ds)Enfin, veuillez imprimer un échantillon afin de vérifier la mise en page :
print(train_text_ds[0]["text"])Vous devriez voir s'afficher une invite entièrement rendue contenant les déclarations d'outils, suivie d'un appel de fonction gold similaire à :
<bos><start_of_turn>developer
You are a model that can do function calling with the following functions<start_function_declaration>declaration:get_pollution_levels{description:<escape>Retrieve pollution levels information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the pollution levels (e.g., Beijing, London, New York)<escape>,type:<escape>STRING<escape>},pollutant:{description:<escape>Specify a pollutant for pollution levels (e.g., PM2.5, PM10, ozone)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><start_function_declaration>declaration:get_water_quality{description:<escape>Retrieve water quality information<escape>,parameters:{properties:{location:{description:<escape>The location for which you want to get the water quality (e.g., river, lake, beach)<escape>,type:<escape>STRING<escape>}},required:[<escape>location<escape>],type:<escape>DICT<escape>}}<end_function_declaration><end_of_turn>
<start_of_turn>user
I'm planning a beach cleanup at Zuma Beach this weekend and need to ensure safety. Can you provide the current water quality and if it's poor, check the pollution level of PM2.5 there?<end_of_turn>
<start_of_turn>model
<start_function_call>call:get_water_quality{args:<escape>{"location": "Zuma Beach"}<escape>}<end_function_call>Avant la formation, il est recommandé de mesurer les performances du modèle FunctionGemma de base lors de l'appel de fonctions. Cette base de référence vous permet de confirmer que le réglage fin améliore réellement la sélection des outils et le formatage des appels de fonction.
Dans cette section, nous évaluons deux éléments :
Nous utilisons deux expressions régulières pour extraire le nom de l'outil prédit et le bloc complet d'appel de fonction à partir de la sortie du modèle, puis nous les comparons aux étiquettes de référence.
import re
import evaluate
import torch
from tqdm.auto import tqdm
cer_metric = evaluate.load("cer")
# Gemma / FunctionGemma-style only
FG_BLOCK_RE = re.compile(r"<start_function_call>.*?<end_function_call>", re.DOTALL)
FG_NAME_RE = re.compile(r"call:([a-zA-Z0-9_]+)\{", re.DOTALL)
def extract_tool_name(gen: str):
gen = gen or ""
m = FG_NAME_RE.search(gen)
return m.group(1) if m else None
def extract_call_block(gen: str):
gen = gen or ""
m = FG_BLOCK_RE.search(gen)
return m.group(0) if m else ""
def gold_call_block(r):
return (
f"<start_function_call>call:{r['tool_name']}"
f"{{args:<escape>{r['tool_arguments']}<escape>}}"
f"<end_function_call>"
)La fonction ci-dessous effectue une inférence sur un sous-ensemble d'exemples d'évaluation et calcule les deux métriques. Nous désactivons l'échantillonnage (do_sample=False) afin de rendre les résultats déterministes et plus faciles à comparer avant et après le réglage fin.
@torch.inference_mode()
def eval_tool_and_cer(proc, mdl, rows, n=50, max_new_tokens=128):
mdl.eval()
n = min(n, len(rows))
tool_ok = 0
preds, refs = [], []
for i in tqdm(range(n)):
r = rows[i]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(out[0][inputs["input_ids"].shape[-1]:], skip_special_tokens=True).strip()
if extract_tool_name(gen) == r["tool_name"]:
tool_ok += 1
preds.append(extract_call_block(gen))
refs.append(gold_call_block(r))
return {
"n_eval": n,
"tool_accuracy": tool_ok / n,
"TC-CER (lower is better)": cer_metric.compute(predictions=preds, references=refs),
}Veuillez procéder à l'évaluation de référence :
pre_metrics = eval_tool_and_cer(processor, model, simple_eval, n=50, max_new_tokens=128)
print("PRE metrics:", pre_metrics)Même avant l'ajustement, FunctionGemma affiche de solides performances de base pour cette tâche.
Sur un sous-ensemble de 50 exemples d'évaluation, le modèle atteint une précision de 88 % dans la reconnaissance des noms d'outils, ce qui signifie qu'il sélectionne la fonction correcte dans la majorité des cas.
De plus, le taux d'erreur de caractère d'appel d'outil (TC-CER) est d'environ 33 % pour l'ensemble du bloc d'appels de fonction, ce qui indique que, bien que l'outil approprié soit souvent sélectionné, les arguments et le formatage générés s'écartent encore de l'objectif visé.
PRE metrics: {'n_eval': 50, 'tool_accuracy': 0.88, 'TC-CER (lower is better)': 0.33399307273626916}Ces résultats confirment que le modèle FunctionGemma de base comprend déjà les mécanismes d'appel de fonction.
Cependant, le taux d'erreur relativement élevé souligne la nécessité d'un ajustement minutieux afin d'améliorer l'exhaustivité des arguments, la cohérence du formatage et l'exactitude structurelle globale des appels de fonction générés.
Les indicateurs sont utiles, mais il est également important d'examiner les résultats qualitatifs. L'assistant ci-dessous effectue une inférence pour un exemple et affiche l'appel de fonction prédit à côté de la référence de référence.
import torch
@torch.inference_mode()
def infer_one(proc, mdl, rows, idx=0, max_new_tokens=128):
r = rows[idx]
messages = [
{"role": "developer", "content": "You are a model that can do function calling with the following functions"},
{"role": "user", "content": r["user_content"]},
]
inputs = proc.apply_chat_template(
messages,
tools=r["hf_tools"],
add_generation_prompt=True,
return_dict=True,
return_tensors="pt",
)
inputs = {k: v.to(mdl.device) for k, v in inputs.items()}
out = mdl.generate(
**inputs,
do_sample=False,
max_new_tokens=max_new_tokens,
pad_token_id=proc.eos_token_id,
)
gen = proc.decode(
out[0][inputs["input_ids"].shape[-1]:],
skip_special_tokens=True
).strip()
pred_tool = extract_tool_name(gen)
return {
"task": r["user_content"],
"tool_match": (pred_tool == r["tool_name"]),
"predicted": extract_call_block(gen),
"gold": gold_call_block(r),
}Veuillez l'exécuter sur un exemple :
pre = infer_one(processor, model, simple_eval, idx=15)
print(f"""
TASK:
{pre['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{pre['predicted']}
--- GOLD ---
{pre['gold']}
""")Résultat :
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{nurse_id:<escape>Ratched<escape>,patient_id:<escape>12345<escape>,procedure_type:<escape>Cardiac Bypass<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>Dans cet exemple, le modèle sélectionne correctement la fonction appropriée, c'est pourquoi la correspondance de l'outil est True.
Cependant, l'appel généré comprend des arguments supplémentaires et ne suit pas exactement la structure cible utilisée lors de la formation.
Bien que ces arguments soient sémantiquement raisonnables, ils ne correspondent pas au format d'appel de fonction gold, ce qui contribue à un taux d'erreur de caractères plus élevé. Cela montre pourquoi un ajustement minutieux est nécessaire pour améliorer la cohérence structurelle et la conformité au schéma, et pas seulement pour la sélection des outils.
Maintenant que nous disposons d'ensembles de données SFT propres, l'étape suivante consiste à configurer le programme d'entraînement qui permettra d'affiner FunctionGemma. Nous utilisons l' SFTTrainer de TRL, qui constitue une méthode simple et fiable pour affiner les modèles de type chat à partir d'exemples textuels.
Nous avons également défini un répertoire de sortie afin que Kaggle enregistre le point de contrôle ajusté dans un emplacement permanent.
from trl import SFTConfig, SFTTrainer
OUT_DIR = "/kaggle/working/functiongemma-hermes-ft"Afin de réduire l'utilisation de la mémoire VRAM pendant l'entraînement, nous activons la vérification des points de contrôle du gradient et désactivons le cache KV.
# VRAM savings
model.gradient_checkpointing_enable()
model.config.use_cache = FalseNous définissons la configuration de formation à l'aide de SFTConfig. Ces paramètres ont été sélectionnés afin d'équilibrer la stabilité et l'efficacité sur les GPU Kaggle, tout en réduisant le temps de formation.
cfg = SFTConfig(
output_dir=OUT_DIR,
max_length=512,
packing=False,
num_train_epochs=1,
per_device_train_batch_size=2,
gradient_accumulation_steps=8,
learning_rate=5e-5,
lr_scheduler_type="cosine",
warmup_ratio=0.03,
logging_steps=10,
eval_strategy="steps",
eval_steps=10,
report_to="none",
fp16=(model.dtype == torch.float16),
bf16=(model.dtype == torch.bfloat16),
optim="adamw_torch_fused",
)La fonction de formatage garantit que chaque exemple d'entraînement est renvoyé sous la forme d'une chaîne unique, comme l'exige la version actuelle de TRL.
def formatting_func(example):
# MUST return a STRING (not list) for your TRL version
t = example.get("text", "")
if isinstance(t, list):
t = "\n".join(map(str, t))
return str(t)Enfin, nous initialisons l'SFTTrainer e avec le modèle, la configuration, les ensembles de données et le tokenizer.
trainer = SFTTrainer(
model=model,
args=cfg,
train_dataset=train_text_ds,
eval_dataset=eval_text_ds,
processing_class=tokenizer,
formatting_func=formatting_func,
)Une fois le formateur configuré, nous pouvons maintenant commencer à affiner le modèle. Cette étape consiste à exécuter un apprentissage supervisé sur l'ensemble de données préparé et à évaluer le modèle périodiquement pendant l'apprentissage.
trainer.train()
trainer.save_model(OUT_DIR)
processor.save_pretrained(OUT_DIR)
print("Saved to:", OUT_DIR)Une fois la formation terminée, nous enregistrons le modèle optimisé et le processeur dans le répertoire de sortie afin qu'ils puissent être réutilisés pour l'inférence ou téléchargés sur le Hugging Face Hub.
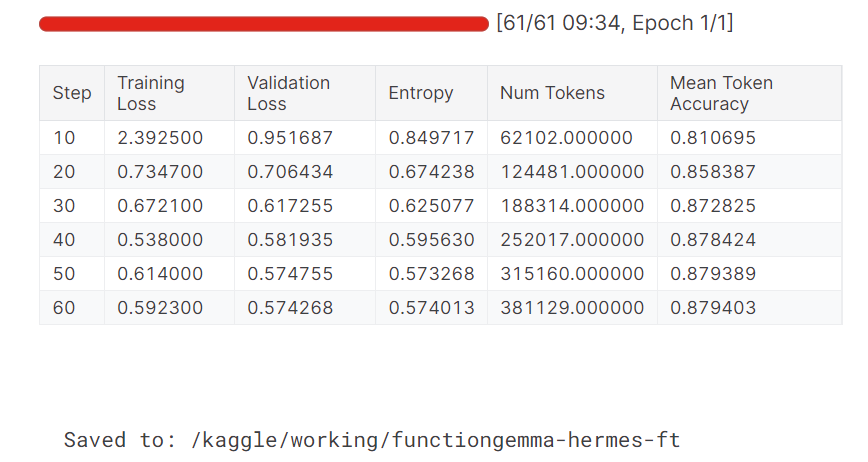
Au cours de l'entraînement, les pertes d'entraînement et de validation diminuent progressivement. La précision moyenne des jetons s'améliore également au fil du temps, ce qui indique que le modèle a réussi à apprendre à produire des résultats d'appels de fonctions plus précis et plus cohérents.
Une fois le réglage terminé, nous pouvons publier le modèle afin qu'il puisse être réutilisé, partagé ou déployé facilement. En transférant le modèle vers Hugging Face Hub, d'autres utilisateurs peuvent le charger directement à l'aide des API Transformers standard.
HF_REPO_ID = "kingabzpro/functiongemma-hermes-3k-ft"
model.push_to_hub(HF_REPO_ID)
processor.push_to_hub(HF_REPO_ID)
print("Pushed to:", HF_REPO_ID)Une fois le téléchargement terminé, le modèle optimisé est accessible au public sur Hugging Face :
Pushed to: kingabzpro/functiongemma-hermes-3k-ft
Source : kingabzpro/functiongemma-hermes-3k-ft · Hugging Face
Une fois le réglage fin terminé, nous rechargeons le modèle et le processeur enregistrés à partir du disque et exécutons le même pipeline d'évaluation que celui utilisé avant l'entraînement. Cela garantit que la comparaison entre les performances avant et après le réglage fin est équitable et cohérente.
from transformers import AutoProcessor, AutoModelForCausalLM
ft_processor = AutoProcessor.from_pretrained(OUT_DIR, device_map="auto")
ft_model = AutoModelForCausalLM.from_pretrained(OUT_DIR, dtype="auto", device_map="auto")Nous évaluons ensuite le modèle affiné sur l'ensemble d'évaluation à l'aide de la précision du nom de l'outil et du TC-CER.
post_metrics = eval_tool_and_cer(ft_processor, ft_model, simple_eval, n=50, max_new_tokens=64)
print("POST metrics:", post_metrics)Les résultats indiquent une nette amélioration par rapport à la situation initiale :
POST metrics: {'n_eval': 50, 'tool_accuracy': 0.98, 'TC-CER (lower is better)': 0.1454725383473528}La précision du nom de l'outil passe de 88 % à 98 %, et le taux d'erreur de caractère pour l'ensemble du bloc d'appel de fonction est réduit de plus de moitié. Cela indique que le modèle non seulement sélectionne l'outil approprié de manière plus fiable, mais produit également des résultats qui correspondent davantage au schéma cible.
Afin de mieux apprécier les améliorations, nous examinons les prévisions individuelles. Dans l'exemple ci-dessous, le modèle sélectionne la fonction appropriée et génère un appel bien structuré avec des arguments plus complets.
post = infer_one(ft_processor, ft_model, simple_eval, idx=15)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Bien que l'appel prévu puisse inclure des arguments supplémentaires qui dépassent l'objectif initial, la structure globale et le formatage des arguments sont nettement plus cohérents qu'avant le réglage fin. Cela reflète une meilleure compréhension du schéma et une meilleure adéquation entre l'intention de l'utilisateur et les appels de fonction générés.
TASK:
I'm reviewing the schedule in the surgical unit. Can you fetch the surgical nursing details for patient ID 12345 undergoing a 'Cardiac Bypass' today? If the procedure is handled by Nurse Ratched, let's record a post-operative care task for this evening.
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass", "nurse_id": "Ratched", "task": "Post-operative care"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:get_surgical_nursing_information{args:<escape>{"patient_id": "12345", "procedure_type": "Cardiac Bypass"}<escape>}<end_function_call>Examinons un autre exemple.
post = infer_one(ft_processor, ft_model, simple_eval, idx=25)
print(f"""
TASK:
{post['task']}
TOOL MATCH: {pre['tool_match']}
--- PREDICTED ---
{post['predicted']}
--- GOLD ---
{post['gold']}
""")Un deuxième exemple présente un appel de fonction propre et correct pour une tâche d'extraction d'URL, démontrant que le modèle optimisé s'adapte bien à différents outils.
TASK:
I would like to extract details from a LinkedIn company page. Could you assist me in fetching the information from this URL: https://www.linkedin.com/company/abc-corporation?
TOOL MATCH: True
--- PREDICTED ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation"}<escape>}<end_function_call>
--- GOLD ---
<start_function_call>call:extract{args:<escape>{"url": "https://www.linkedin.com/company/abc-corporation", "html": true}<escape>}<end_function_call>Dans l'ensemble, ces résultats confirment que le réglage fin améliore avec succès à la fois la précision et l'exactitude structurelle des tâches d'appel de fonctions.
Le cahier Kaggle complet pour ce tutoriel est disponible à l'adresse suivante :https://www.kaggle.com/code/kingabzpro/finetuning-functiongemma
Si vous rencontrez des difficultés, vous pouvez cloner le notebook, ajouter votre clé secrète Hugging Face et l'exécuter de bout en bout.
Si vous envisagez de former FunctionGemma à partir d'ensembles de données génériques de génération de texte, il est préférable de vous abstenir. FunctionGemma n'est pas conçu pour se comporter comme un modèle de langage à usage général.
Pour la génération de texte ouvert, le famille de modèles Gemma 3 est un choix plus approprié.
FunctionGemma est spécialement conçu pour l'appel de fonctions, où l'objectif est de sélectionner l'outil approprié, de produire des arguments conformes au schéma et d'interagir de manière fiable avec des systèmes externes tels que des API, des bases de données et des services.
La petite taille de FunctionGemma est un choix de conception délibéré. Avec 270 millions de paramètres, il est optimisé pour les déploiements à faible latence et économes en ressources, notamment les machines locales, les appareils périphériques et les infrastructures privées. Cela le rend particulièrement adapté aux appels de fonctions en temps réel et aux workflows agentifs, où la précision et la structure sont plus importantes que la fluidité du texte.
Dans ce tutoriel, nous avons appris à affiner FunctionGemma sur l'ensemble de données Hermes Reasoning Tool-Use. Il est essentiel de retenir que la préparation et l'évaluation des données sont plus importantes que le temps de formation brut.
En nettoyant minutieusement l'ensemble de données, en alignant les tâches avec les appels d'outils Gold et en appliquant une cohérence stricte du schéma, nous avons pu améliorer considérablement le comportement du modèle avec un nombre relativement faible d'échantillons de haute qualité.
Les résultats démontrent clairement l'impact du réglage fin. La précision du nom de l'outil est passée de 88 % à 98 %, et le taux d'erreur de caractères pour les blocs d'appel de fonction complets a été réduit de plus de moitié. Plus important encore, le modèle est devenu beaucoup plus cohérent dans la production d'appels de fonctions bien structurés et prévisibles, qui correspondent à l'utilisation réelle.
Meilleurs cours DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Mark Pedigo
Tutoriel
Stephen Gruppetta
Tutoriel
Matt Crabtree
