
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
A nova família de modelos de código aberto do Google, Gemma 3, está ganhando popularidade rapidamente devido ao seu desempenho impressionante, comparável ao de alguns dos modelos proprietários mais recentes. O Gemma 3 apresenta recursos multimodais, habilidades de raciocínio aprimoradas e suporta mais de 140 idiomas.
Neste tutorial, exploraremos os recursos do Gemma 3 e aprenderemos a ajustá-lo em um conjunto de dados de perguntas e respostas de raciocínio financeiro. Esse processo de ajuste fino aumentará significativamente a precisão do modelo na compreensão de questões financeiras complexas e permitirá que ele forneça respostas precisas e contextualmente relevantes.
Você é novo no ajuste fino de LLMs? Não se preocupe; nós ajudamos você! Siga nosso tutorial fácil de entender, Fine-Tuning LLMs: A Guide With Examples, para que você saiba como funciona o ajuste fino .
Você também pode fazer o curso Introdução aos LLMs em Python para saber mais sobre como os LLMs funcionam, como ajustá-los e como avaliar seu desempenho.

Imagem do autor
A família Gemma de modelos abertos representa um avanço significativo ao tornar a tecnologia de IA de ponta acessível a todos. Criado com base na pesquisa e na tecnologia dos modelos Gemini 2.0, o Gemma 3 oferece desempenho de última geração, mantendo-se leve e eficiente.
Com tamanhos que variam de 1 bilhão a 27 bilhões de parâmetros, o Gemma 3 oferece flexibilidade nos requisitos de hardware e desempenho, tornando mais fácil do que nunca a integração de IA avançada em aplicativos do mundo real.
O Gemma 3 estabelece uma nova referência de desempenho em sua classe, superando concorrentes como Llama3-405B, DeepSeek-V3e o o3-mini em avaliações de preferência humana na tabela de classificação do LMArena. Seu design leve não compromete a potência, permitindo que os desenvolvedores alcancem resultados líderes do setor e mantenham a eficiência.
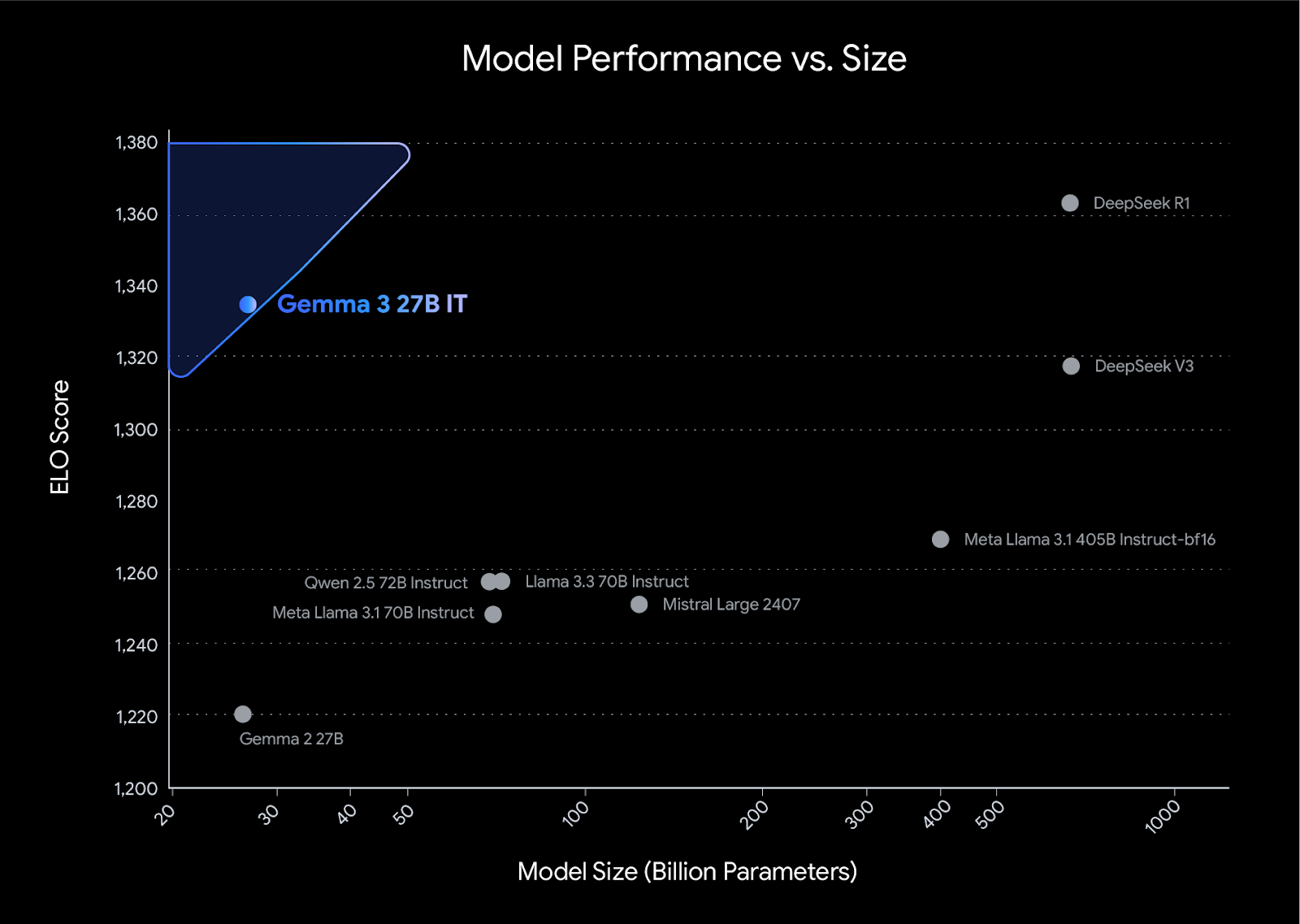
Fonte: Apresentando a Gemma 3
Neste projeto, carregaremos o Gemma 3 do Kaggle e recuperaremos os dados do Hugging Face. Em seguida, usaremos as bibliotecas Transformers e TRL para ajustar nosso modelo. Para fins de comparação, geraremos a resposta antes e depois do ajuste fino.
Se você quiser saber como usar a biblioteca Unsloth para ajustar seu modelo em dados de raciocínio, confira o artigo Guia de ajuste fino do DeepSeek R1 (modelo de raciocínio) para você.
Instale todas as bibliotecas Python necessárias, garantindo que você atualize a biblioteca transformer biblioteca.
%%capture
!pip install -U datasets
!pip install -U accelerate
!pip install -U peft
!pip install -U trl
!pip install -U bitsandbytes
!pip install git+https://github.com/huggingface/transformers@v4.49.0-Gemma-3Faça login no cliente Hugging Face usando sua chave de API. A chave da API é armazenada com segurança nos segredos do Kaggle, e nós a extrairemos e aplicaremos ao cliente Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(hf_token)Adicione o modelo Gemma 3 4B IT ao notebook do Kaggle da mesma forma que você adicionou o conjunto de dados, clicando no botão "+ Add Input".
Carregue o modelo e o tokenizador usando a biblioteca transformers. Certifique-se de que o modelo esteja definido como device_map="auto" para usar efetivamente uma configuração de GPU dupla.
from transformers import AutoTokenizer, Gemma3ForConditionalGeneration
import torch
GEMMA_PATH = "/kaggle/input/gemma-3/transformers/gemma-3-4b-it/1"
model = Gemma3ForConditionalGeneration.from_pretrained(
GEMMA_PATH, device_map="auto",attn_implementation='eager'
).eval()
tokenizer = AutoTokenizer.from_pretrained(GEMMA_PATH)Antes de carregar o conjunto de dados, criaremos o estilo do prompt de treinamento e forneceremos três espaços reservados que preencheremos com as colunas do conjunto de dados. Esse estilo de prompt nos ajudará a gerar um texto de raciocínio.
train_prompt_style="""
Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
</think>
{}
"""Em seguida, criaremos a função de formatação que usa as colunas do conjunto de dados e as aplica ao estilo do prompt de treinamento para criar a coluna "texto". Certifique-se de que você está adicionando o token EOS no final da resposta.
def formatting_prompts_func(examples):
inputs = examples["Open-ended Verifiable Question"]
complex_cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for question, cot, response in zip(inputs, complex_cots, outputs):
# Append the EOS token to the response if it's not already there
if not response.endswith(tokenizer.eos_token):
response += tokenizer.eos_token
text = train_prompt_style.format(question, cot, response)
texts.append(text)
return {"text": texts}Agora, carregaremos o arquivo TheFinAI/Fino1_Reasoning_Path_FinQA que é um conjunto de dados de raciocínio financeiro baseado no FinQA, aprimorado com caminhos de raciocínio gerados pelo GPT-4o para responder a perguntas financeiras estruturadas. Depois disso, aplicaremos a função de formatação ao conjunto de dados e criaremos a nova coluna de texto moldada pelo estilo de prompt.
from datasets import load_dataset
dataset = load_dataset("TheFinAI/Fino1_Reasoning_Path_FinQA", split = "train[0:500]",trust_remote_code=True)
dataset = dataset.map(formatting_prompts_func, batched = True,)
dataset["text"][0]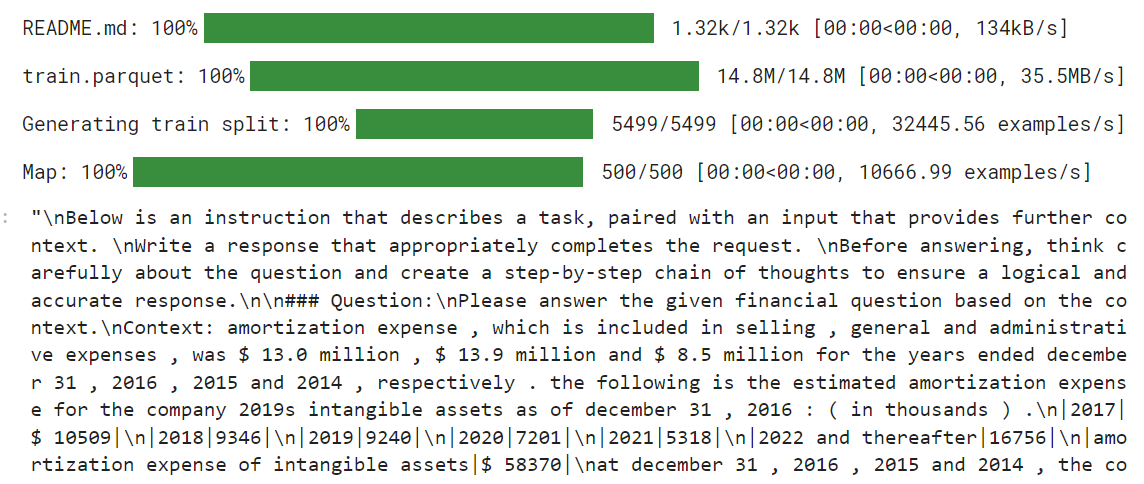
O novo instrutor do STF não aceita os tokenizadores, portanto, temos que criar nossa coleção de dados usando o tokenizador e fornecê-la ao instrutor posteriormente.
from transformers import DataCollatorForLanguageModeling
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False # we're doing causal LM, not masked LM
)Antes de começarmos a ajustar o modelo, testaremos nosso modelo original para ver se ele é bom em gerar respostas. Criaremos o estilo de prompt com dois espaços reservados em vez de três.
prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context.
Write a response that appropriately completes the request.
Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Question:
{}
### Response:
<think>
{}
"""Em seguida, aplicaremos o estilo de prompt à pergunta, convertendo-a em tokens e fornecendo-a ao modelo. Depois disso, geraremos a resposta e converteremos os tokens novamente em texto.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])A resposta é curta e está longe de ser precisa.
<think>
The question asks for the portion of the estimated amortization expense that will be recognized in 2017.
The provided table shows the estimated amortization expense for intangible assets for the years 2017, 2018, 2019, 2020, 2021, and 2022 and thereafter.
The amortization expense for 2017 is $10,509.
</think>
$10,509Aqui está a resposta do conjunto de dados. A resposta deve ser uma proporção, não a quantidade.
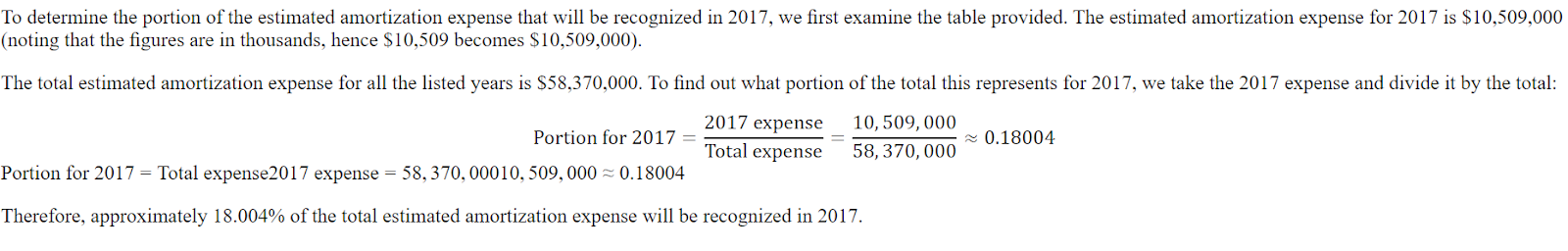
Até mesmo o ChatGPT errou, e tivemos que pedir a ele que corrigisse o erro. Depois disso, ele entendeu que cometeu um erro e o corrigiu.

Agora, forneceremos o conjunto de dados, o modelo, a coleta de dados, os argumentos de treinamento e a configuração do LoRA para o SFTTrainer.
from trl import SFTTrainer
from transformers import TrainingArguments
from peft import LoraConfig
# LoRA Configuration
peft_config = LoraConfig(
lora_alpha=16, # Scaling factor for LoRA
lora_dropout=0.05, # Add slight dropout for regularization
r=64, # Rank of the LoRA update matrices
bias="none", # No bias reparameterization
task_type="CAUSAL_LM", # Task type: Causal Language Modeling
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj",
], # Target modules for LoRA
)
# Training Arguments
training_arguments = TrainingArguments(
output_dir="output",
per_device_train_batch_size=1,
per_device_eval_batch_size=1,
gradient_accumulation_steps=2,
optim="paged_adamw_32bit",
num_train_epochs=1,
logging_steps=0.2,
warmup_steps=10,
logging_strategy="steps",
learning_rate=2e-4,
fp16=False,
bf16=False,
group_by_length=True,
report_to="none"
)
# Initialize the Trainer
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=dataset,
peft_config=peft_config,
data_collator=data_collator,
)Limpe o cache do CUDA antes de iniciar o processo de filtragem.
torch.cuda.empty_cache()
trainer_stats = trainer.train()Você levou quase 1 hora e 20 minutos para concluir uma época. Como você pode ver, a perda foi reduzida gradualmente.
Agora, vamos testar nosso modelo ajustado fornecendo um exemplo de pergunta, como fizemos anteriormente.
question = dataset[0]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])A parte do raciocínio agora está detalhada e correta. A resposta também é precisa.
<think>
Alright, let's figure out what portion of the estimated amortization expense will be recognized in 2017. First, I need to see what the total estimated amortization expense is for the years 2017 through 2022. Looking at the numbers, it's $58,370.
Now, I need to find out how much of that is specifically for 2017. The table shows that the estimated amortization expense for 2017 is $10,509.
So, to find out what portion of the total expense is for 2017, I'll divide the 2017 expense by the total expense. That's $10,509 divided by $58,370.
Let's do the math: $10,509 divided by $58,370 gives me approximately 0.1805.
Now, to express this as a percentage, I'll multiply by 100. So, 0.1805 times 100 gives me 18.05%.
Therefore, about 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.
</think>
About 18.05% of the estimated amortization expense for the years 2017 through 2022 will be recognized in 2017.Vamos fazer outra pergunta.
question = dataset[10]['Open-ended Verifiable Question']
inputs = tokenizer(
[prompt_style.format(question, "") + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])Como podemos ver, conseguimos ajustar o modelo com sucesso no novo conjunto de dados. Agora ela é precisa e segue o raciocínio e o estilo de resposta.
<think>
Alright, let's figure out the total purchase price of Impella Cardiosystems. First, we know the purchase price was $45.1 million, but there's a contingent payment of $5.6 million that could be earned. So, we need to see if we can figure out how much of that $5.6 million is actually likely to be paid.
Now, the question mentions that the contingent payment is triggered by FDA approvals. Since we're dealing with a medical device, getting FDA clearance is pretty important. Let's assume that the FDA approval for the Impella 2.5 is a good sign that the contingent payments will be made.
Okay, so if we assume all the contingent payments are earned, we just need to add the $5.6 million to the original $45.1 million. Let's do the math: $45.1 million plus $5.6 million equals $50.7 million.
Hmm, let's double-check our work. We're adding $45.1 million to $5.6 million, which gives us $50.7 million. Yep, that seems right.
So, if we assume all the contingent payments are earned, the total purchase price of Impella Cardiosystems would be $50.7 million.
</think>
The total purchase price of Impella Cardiosystems, assuming all contingent consideration is earned, would be $50.7 million.O ajuste fino de um modelo requer conhecimento especializado, dinheiro e tempo. Em alguns casos, você pode precisar apenas de um pipeline RAG melhor para atender às suas necessidades. Leia o guia RAG vs. Fine-Tuning: A Comprehensive Tutorial with Practical Examples para entender seus requisitos.
Primeiro, salvaremos o modelo e o tokenizador localmente.
new_model_online = "kingabzpro/Gemma-3-4B-Fin-QA-Reasoning"
new_model_local = "Gemma-3-4B-Fin-QA-Reasoning"
model.save_pretrained(new_model_local) # Local saving
tokenizer.save_pretrained(new_model_local)Em seguida, enviaremos o modelo para o Hugging Face Hub.
model.push_to_hub(new_model_online) # Online saving
tokenizer.push_to_hub(new_model_online) # Online savingEsse processo criará primeiro o repositório de modelos e, em seguida, enviará todos os campos de modelo, tokenizador e configuração para o servidor remoto.
Fonte: kingabzpro/Gemma-3-4B-Fin-QA-Reasoning - Hugging Face
Se você estiver enfrentando problemas para executar o código acima, criamos um notebook do Kaggle para que qualquer pessoa possa clonar e executar por conta própria para entender melhor o processo.
O ajuste fino do modelo Gemma 3 vem com desafios; você pode encontrar problemas de hardware, problemas de biblioteca, problemas de fragmentação de memória e muito mais. Este guia fornece uma implementação mais simples de como você pode converter qualquer modelo em um modelo de raciocínio e evitar problemas futuros relacionados a software e hardware.
Neste tutorial, abordamos os recursos do modelo Gemma 3 e como podemos ajustá-lo facilmente ao conjunto de dados de raciocínio usando recursos gratuitos de GPU disponíveis no Kaggle.
Faça o Ajuste fino com Llama 3 para que você possa lidar com tarefas de ajuste fino usando o TorchTune e aprender técnicas eficientes de ajuste fino, como a quantização.
Principais cursos da DataCamp
Programa
Curso
Curso
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Abid Ali Awan
Tutorial
Aashi Dutt
Tutorial
Josep Ferrer
Tutorial
Dimitri Didmanidze

