Curso
Biomedical Image Analysis in Python
4 h
23.4K
No centro dos modelos de linguagem de visão está a integração da visão computacional e do processamento de linguagem natural.
O foco da visão computacional é permitir que as máquinas interpretem e analisem dados visuais, como imagens e vídeos, reconhecendo objetos, padrões e outros elementos visuais.
Por outro lado, o processamento de linguagem natural se preocupa com a compreensão e a geração de linguagem humana, permitindo que as máquinas compreendam, analisem e produzam textos.
Os VLMs preenchem a lacuna entre esses dois campos, criando modelos que podem processar e compreender simultaneamente entradas visuais e textuais. Isso é obtido por meio de arquiteturas avançadas de arquiteturas de aprendizagem profundaparticularmente modelos transformadores, que têm sido fundamentais para o sucesso de grandes modelos de linguagem, como o GPT-4o, Llama, Geminie Gemma.
Essas arquiteturas baseadas em transformadores foram adaptadas para lidar com entradas multimodaispermitindo que os VLMs capturem as relações complexas entre dados visuais e linguísticos.
O modelo de transformador, inicialmente introduzido para tarefas de PNL, tornou-se a espinha dorsal de muitos sistemas avançados de IA devido à sua capacidade de lidar com dependências de longo alcance e capturar relações contextuais nos dados.
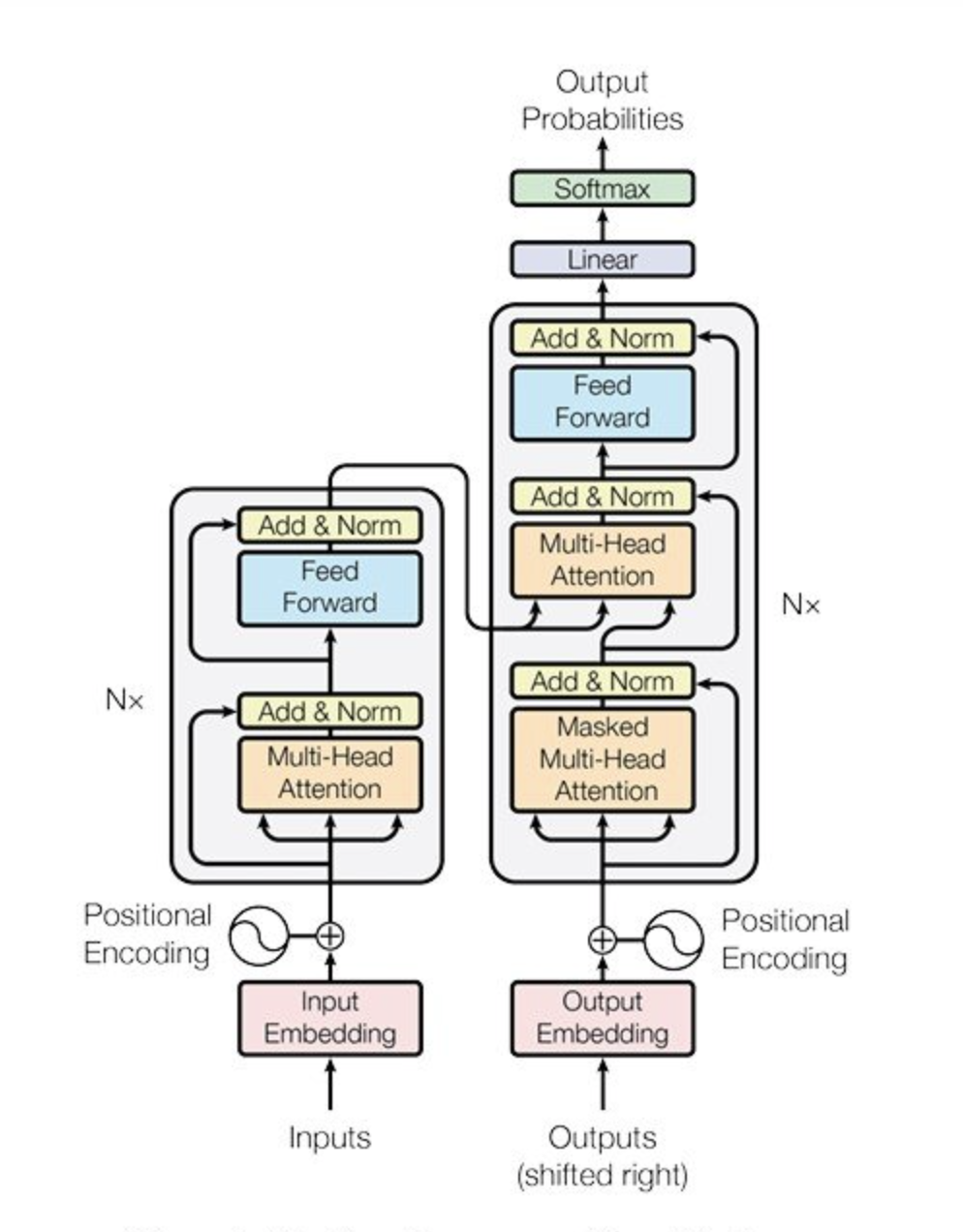
Fonte: Vaswani et al., 2017
No contexto dos VLMs, os transformadores foram adaptados para processar imagens e textos, permitindo uma integração perfeita dessas duas modalidades.
Uma arquitetura VLM típica envolve dois componentes principais: um codificador de imagem e um decodificador de texto:
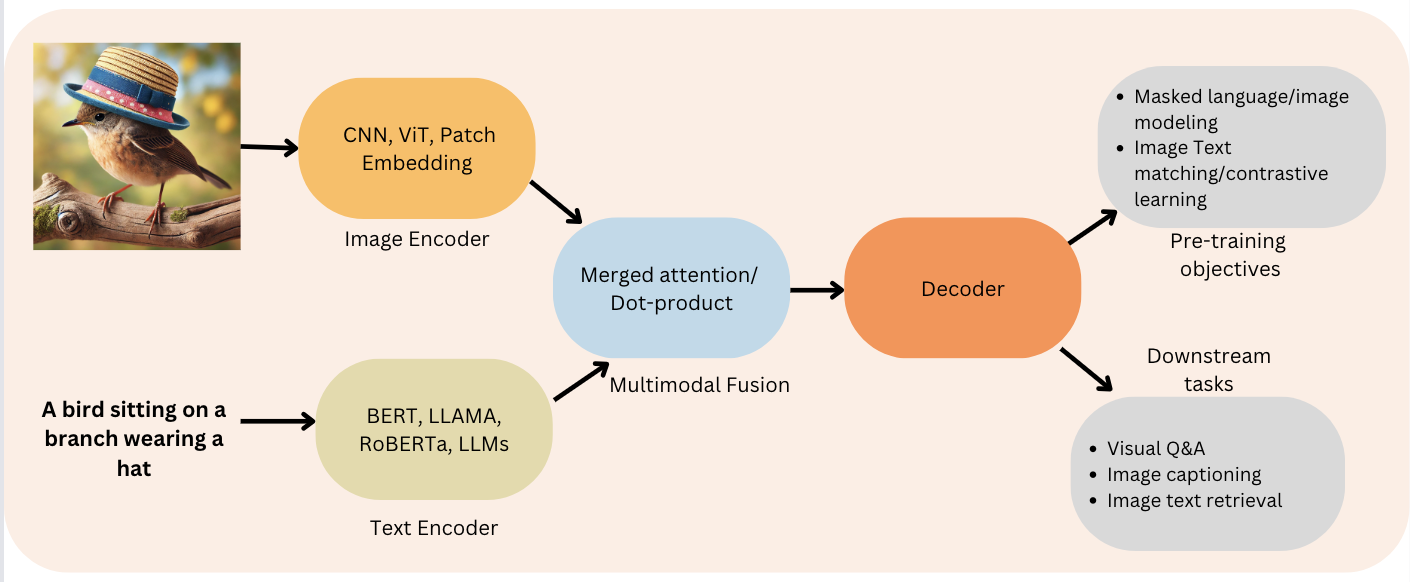
Figura 2: Função codificador-decodificador (Fonte: Viso.ai)
Ao combinar essas duas partes, os VLMs podem fazer coisas incríveis, como descrever imagens em detalhes, responder a perguntas sobre o que você vê e até mesmo gerar novas imagens com base em descrições de texto! O processo que os VLMs seguem segue as seguintes etapas:
A maioria dos VLMs utiliza um Vision Transformer (ViT) como codificador de imagem, que foi pré-treinado em conjuntos de dados de imagens em grande escala para garantir que ele possa capturar efetivamente os recursos visuais necessários para tarefas multimodais.
O decodificador de texto é baseado no modelo de linguagem, que foi ajustado com precisão para lidar com as complexidades da geração de linguagem no contexto de dados visuais. Essa combinação de recursos avançados de processamento visual e linguístico torna o VLM altamente versátil e avançado.
Um dos desafios mais significativos no desenvolvimento de VLMs é a necessidade de conjuntos de dados grandes e diversificados que contenham informações visuais e textuais. Esses conjuntos de dados são essenciais para treinar os modelos para entender e gerar conteúdo multimodal.
O processo de treinamento de um VLM envolve alimentar o modelo com pares de imagens e suas descrições textuais correspondentes, permitindo que o modelo aprenda as relações complexas entre elementos visuais e expressões linguísticas.
Para lidar com esses dados, os VLMs geralmente usam camadas de incorporação que transformam as entradas visuais e textuais em um espaço de alta dimensão, onde elas podem ser comparadas e combinadas.
Esse processo de incorporação permite que o modelo compreenda as conexões entre as duas modalidades e gere resultados coerentes e contextualmente relevantes.
O cenário dos modelos de linguagem de visão (VLMs) é vasto, com vários modelos de código aberto disponíveis na Internet. Hugging Face Hub. Esses modelos variam em tamanho, recursos e licenciamento, oferecendo aos usuários uma gama de opções adaptadas a diferentes aplicações. A seguir, você encontrará uma visão geral de alguns dos VLMs de código aberto mais importantes, destacando seus principais recursos:
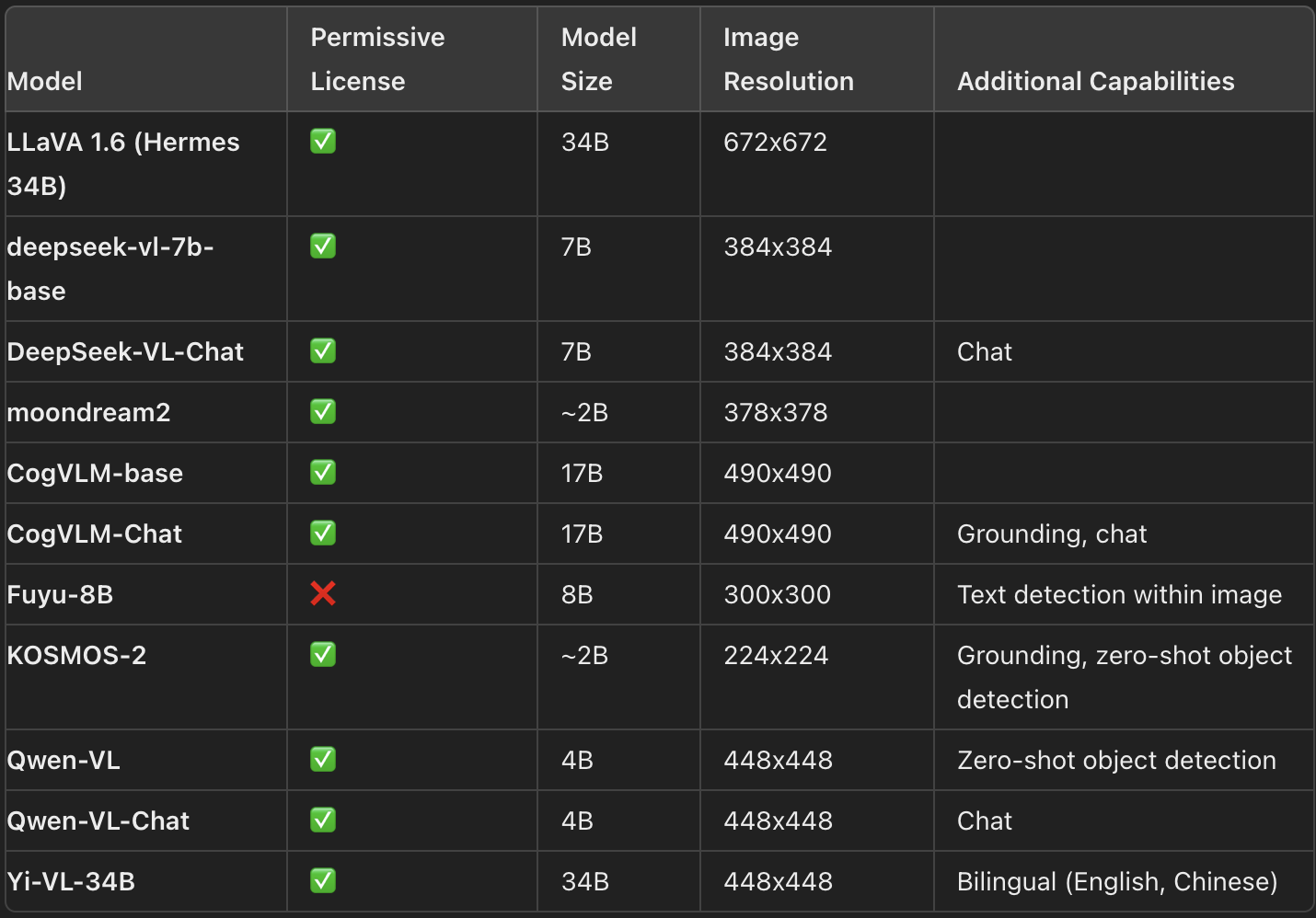
VLMs mais recentes e seus principais recursos (Fonte: HuggingFace)
Selecionar o VLM mais adequado para o seu caso de uso específico pode ser um desafio, dada a variedade de opções disponíveis. Várias ferramentas e recursos podem ajudar nesse processo de seleção:
Embora o Vision Arena e o Open VLM Leaderboard ofereçam informações valiosas, eles se limitam aos modelos que foram enviados e exigem atualizações regulares para incluir novos modelos.
Vários benchmarks são comumente usados para avaliar o desempenho dos VLMs:
O pré-treinamento de VLMs envolve a unificação de representações de imagem e texto para alimentá-las em um decodificador de texto para geração. A estrutura normalmente inclui um codificador de imagem, um projetor de incorporação para alinhar as representações de imagem e texto e um decodificador de texto. No entanto, diferentes modelos empregam diferentes estratégias de pré-treinamento.
Em muitos casos, o pré-treinamento de um VLM é até desnecessário se você puder ajustar os modelos existentes para o seu caso de uso específico. Ferramentas como Transformers e SFTTrainer simplificam o processo de ajuste fino dos modelos para tarefas específicas, tornando-o acessível até mesmo para aqueles com recursos limitados.
Aqui você encontra uma implementação do HuggingFace para usar o modelo de código aberto VLM LlavaNext gratuitamente em seu Colab ou máquina local com a biblioteca Transformers do HuggingFace.
from transformers import LlavaNextProcessor, LlavaNextForConditionalGeneration
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
processor = LlavaNextProcessor.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf"
)
model = LlavaNextForConditionalGeneration.from_pretrained(
"llava-hf/llava-v1.6-mistral-7b-hf",
torch_dtype=torch.float16,
low_cpu_mem_usage=True
)
model.to(device)Os recursos dos modelos de linguagem de visão vão muito além da legenda de imagens. Os VLMs abriram as portas para muitos aplicativos que usam sua capacidade de preencher a lacuna entre as informações visuais e textuais. Vamos explorar algumas das aplicações mais impactantes dos VLMs em vários setores.
A resposta a perguntas visuais (VQA) é uma tarefa que envolve responder a perguntas sobre o conteúdo de uma imagem.
Esse aplicativo exige que o modelo compreenda os elementos visuais da imagem e o contexto linguístico da pergunta. Por exemplo, com uma imagem de uma paisagem urbana movimentada, um VLM pode responder a perguntas como "Qual é a cor do edifício mais alto?" ou "Quantas pessoas são visíveis na imagem?".
O VQA tem inúmeras aplicações práticas, especialmente nos setores em que os dados visuais desempenham um papel fundamental. Em saúdepor exemplo, o VQA pode ser usado para analisar imagens médicas e fornecer respostas a perguntas que ajudam no diagnóstico e no planejamento do tratamento. No varejoNo varejo, o VQA pode aprimorar a experiência de compra, permitindo que os clientes interajam com as imagens dos produtos de maneira mais natural e intuitiva.
Um dos recursos mais interessantes dos VLMs é a geração de texto para imagem. Essa tarefa envolve a geração de uma representação visual de uma cena ou objeto com base em uma descrição textual. Por exemplo, um VLM pode receber uma solicitação como "Um pôr do sol sereno sobre uma cadeia de montanhas com um rio fluindo pelo vale" e gerar uma imagem correspondente.
A geração de texto para imagem tem um imenso potencial em áreas criativas, como design e publicidade. Designers e publicitários podem usar essa tecnologia para gerar rapidamente ideias visuais com base em avisos textuais. A geração de texto para imagem pode simplificar o processo de criação de conteúdo visual que se alinha a mensagens de marketing específicas.
A recuperação de imagens é o processo de encontrar imagens relevantes com base em uma consulta textual. Os VLMs se destacam nessa tarefa usando sua capacidade de entender tanto o conteúdo visual das imagens quanto o contexto linguístico da consulta.
Esse recurso faz com que os mecanismos de pesquisa mais eficientes e precisos, permitindo que os usuários encontrem as imagens exatas que estão procurando com mais facilidade.
A recuperação de imagens tem aplicações em vários domínios, desde o comércio eletrônico até a análise de imagens médicas. No comércio eletrônico, a recuperação de imagens pode ajudar os clientes a encontrar produtos que correspondam às suas preferências com base em descrições visuais e textuais. No setor de saúde, a recuperação de imagens pode ajudar os profissionais da área médica a encontrar imagens médicas relevantes para fins de pesquisa ou diagnóstico.
Embora os exemplos acima se concentrem em imagens, os VLMs também podem ser estendidos para entender e gerar legendas para vídeos. A compreensão de vídeo envolve a análise do conteúdo visual de um vídeo e a geração de um texto descritivo que capture a essência das cenas retratadas.
A compreensão de vídeo tem aplicações em pesquisa de vídeo, resumo e moderação de conteúdo. Na pesquisa de vídeo, os VLMs podem ajudar os usuários a encontrar clipes de vídeo específicos com base em consultas textuais. Em tarefas de resumo, os VLMs podem gerar resumos concisos de vídeos longos, facilitando a compreensão rápida do conteúdo pelos usuários. Na moderação de conteúdo, os VLMs podem ajudar a identificar conteúdo inadequado ou prejudicial nos vídeos, garantindo que as plataformas mantenham um ambiente seguro e amigável.
Vamos agora considerar os desafios associados aos VLMs, bem como os aspectos éticos.
O treinamento e a implementação de VLMs requerem recursos computacionais significativosespecialmente para modelos grandes como o PaliGemma. Isso pode ser uma barreira para organizações com acesso limitado à infraestrutura de computação de alto desempenho.
Para enfrentar esse desafio, os pesquisadores estão explorando maneiras de tornar os VLMs mais eficientes, por exemplo, usando técnicas de compactação de modelos, otimizando a arquitetura do modelo e aproveitando aceleradores de hardware como GPUs e TPUs.
O desenvolvimento de VLMs levanta várias preocupações éticas, especialmente em relação ao potencial de viés nos resultados do modelo. Os VLMs treinados em dados de texto e imagem do mundo real em grande escala podem refletir preconceitos socioculturais incorporados no material de treinamento. Essas tendências podem se manifestar nos resultados do modelo, levando a conteúdo prejudicial ou ofensivo.
Para lidar com essas preocupações, os pesquisadores estão implementando várias técnicas de atenuação de vieses, como o uso de conjuntos de dados de treinamento equilibrados, a incorporação de algoritmos de aprendizado com consciência de justiça e a realização de avaliações rigorosas dos resultados do modelo para identificar e lidar com possíveis vieses.
Além disso, organizações como o Google estão implementando filtros de segurança de conteúdo para garantir que os dados de treinamento usados por modelos como o PaliGemma sejam limpos e livres de conteúdo prejudicial.
Outra consideração importante no desenvolvimento de VLMs é a privacidade e segurança dos dados. Os VLMs geralmente exigem acesso a grandes quantidades de dados, incluindo informações potencialmente confidenciais. Garantir que esses dados sejam tratados com segurança e em conformidade com as normas de privacidade é fundamental para manter a confiança dos usuários e das partes interessadas.
Para abordar as preocupações com a privacidade, os pesquisadores estão explorando técnicas como a aprendizagem federada, que permite que os modelos sejam treinados em dados descentralizados sem a necessidade de transferir informações confidenciais para um servidor central.
Além disso, organizações como o Google estão implementando medidas de responsabilidade de dados, como a filtragem de informações pessoais e dados confidenciais dos conjuntos de dados de treinamento, para proteger a privacidade dos indivíduos.
Os modelos de linguagem visual representam um avanço significativo na inteligência artificial, oferecendo o potencial de aprimorar vários aplicativos por meio de sua capacidade de processar dados visuais e textuais.
Com o avanço das pesquisas nesse campo, podemos prever o desenvolvimento de VLMs mais sofisticados, capazes de executar tarefas complexas e fornecer percepções valiosas.
A integração da compreensão visual e textual abre novas possibilidades de inovação, tornando os VLMs uma área promissora de pesquisa e desenvolvimento.
Aprenda IA com estes cursos!
Curso
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Stanislav Karzhev
9 min
blog
Dimitri Didmanidze
7 min
blog
Abid Ali Awan
8 min
blog
Tutorial
Josep Ferrer
