Programa
Desenvolvimento de aplicativos de IA
21 h
A avaliação dos LLMs requer uma abordagem abrangente, empregando uma série de medidas para avaliar vários aspectos de seu desempenho. Nesta discussão, exploramos os principais critérios de avaliação dos LLMs, incluindo precisão e desempenho, parcialidade e justiça, além de outras métricas importantes.
Medir com precisão o desempenho é uma etapa importante para compreender as capacidades de um LLM. Esta seção analisa as principais métricas utilizadas para avaliara precisão e o desempenho do .
A perplexidade é uma métrica fundamental para avaliar e medir a capacidade de um LLM de prever a próxima palavra em uma sequência. É assim que você pode calculá-lo:
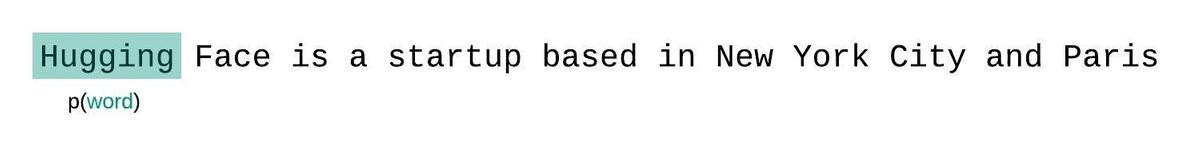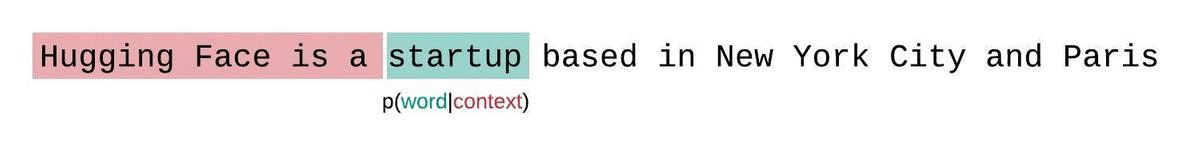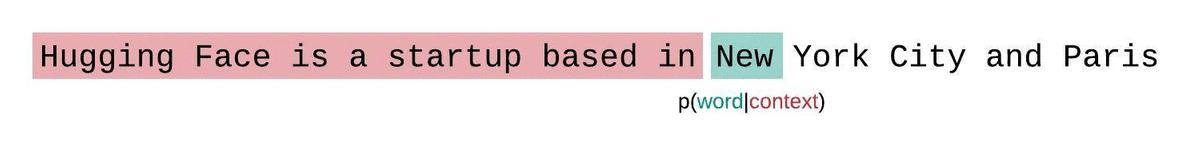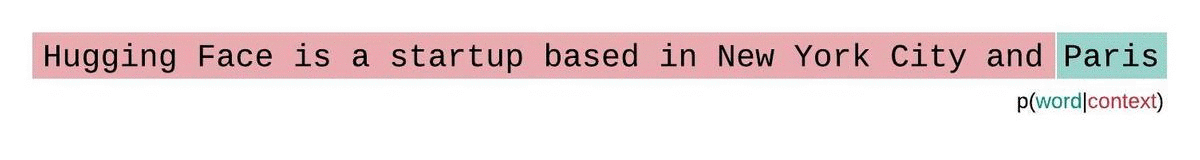
Pontuações de perplexidade mais baixas indicam que o modelo prevê a próxima palavra com mais precisão, refletindo um melhor desempenho. Essencialmente, ele quantifica a capacidade de uma distribuição de probabilidade ou modelo preditivo prever uma amostra.
Para os LLMs, uma perplexidade menor significa que o modelo é mais confiante em suas previsões de palavras, o que leva a uma geração de texto mais coerente e contextualmente apropriada.
A precisão é uma métrica amplamente usada para tarefas de classificaçãorepresentando a proporção de previsões corretas feitas pelo modelo. Embora essa seja uma métrica normalmente intuitiva, no contexto de tarefas de geração abertas, muitas vezes ela pode ser enganosa.
Por exemplo, ao gerar textos criativos ou com nuances contextuais, a "correção" do resultado não é tão simples de definir quanto em tarefas como análise de sentimentos ou classificação de tópicos. Portanto, embora a precisão seja útil para tarefas específicas, ela deve ser complementada com outras métricas ao avaliar LLMs.
As pontuações BLEU (Bilingual Evaluation Understudy) e ROUGE (Recall-Oriented Understudy for Gisting Evaluation) são usadas para avaliar a qualidade do texto gerado, comparando-o com textos de referência.
O BLEU tem tudo a ver com precisão: se uma tradução automática usa exatamente as mesmas palavras que uma tradução humana, ela obtém uma pontuação alta no BLEU. Por exemplo, se a referência humana for "O gato está no tapete" e a saída da máquina for "O gato está sentado no tapete", a pontuação BLEU será alta porque muitas palavras se sobrepõem.
O ROUGE se concentra na recuperação: ele verifica se o texto gerado por máquina captura todas as ideias importantes da referência humana. Digamos que um resumo escrito por humanos seja "O estudo descobriu que as pessoas que se exercitam regularmente tendem a ter pressão arterial mais baixa". Se o resumo gerado pela IA for "Exercício ligado à redução da pressão arterial", o ROUGE atribuiria uma pontuação alta porque ele capta o ponto principal, embora a redação seja diferente.
Essas métricas são úteis para tarefas como tradução automáticaresumos e geração de textos, fornecendo uma avaliação quantitativa da proximidade entre o resultado do modelo e os textos de referência gerados por humanos.
Garantir a justiça e redução de preconceitos nos LLMs é essencial para que você tenha candidaturas equitativas. Aqui, abordamos as principais métricas para avaliar a parcialidade e a justiça nos LLMs.
A paridade demográfica indica se o desempenho de um modelo é consistente em diferentes grupos demográficos. Ele avalia a proporção de resultados positivos entre grupos definidos por atributos como raça, gênero ou idade.
Alcançar a paridade demográfica significa que as previsões do modelo não são tendenciosas em relação a nenhum grupo específico, garantindo justiça e equidade em suas aplicações.
A igualdade de oportunidades se concentra no fato de os erros do modelo serem distribuídos igualmente entre diferentes grupos demográficos. Ele avalia as taxas de falsos negativos para cada grupo, validando que o modelo não falha desproporcionalmente em determinados dados demográficos.
Essa métrica é fundamental para aplicativos em que a justiça e a igualdade de acesso são essenciais, como algoritmos de contratação ou processos de aprovação de empréstimos.
A imparcialidade contrafactual avalia se as previsões de um modelo seriam alteradas se determinados atributos sensíveis fossem diferentes. Isso envolve a geração de exemplos contrafactuais em que o atributo sensível (por exemplo, gênero ou raça) é alterado, mantendo outros recursos constantes.
Se a previsão do modelo mudar com base nessa alteração, isso indica um viés relacionado ao atributo sensível. A imparcialidade contrafactual é vital para identificar e mitigar vieses que podem não ser aparentes por meio de outras métricas.
Além do desempenho e da imparcialidade, outros critérios são úteis para uma avaliação abrangente dos LLMs. Esta seção destaca esses aspectos.
A fluência avalia a naturalidade e a correção gramatical do texto gerado. Um LLM fluente produz resultados que são fáceis de ler e entender, imitando o fluxo da linguagem humana.
Isso pode ser avaliado por meio de ferramentas automatizadas ou julgamento humano, com foco em aspectos como gramática, sintaxe e legibilidade geral.
A coerência ajuda a analisar o fluxo lógico e a consistência do texto gerado. Um texto coerente mantém uma estrutura clara e uma progressão lógica de ideias, tornando-o fácil de ser seguido pelos leitores. A coerência é particularmente importante para textos mais longos, como ensaios ou artigos, em que é fundamental manter uma narrativa consistente.
A factualidade avalia a precisão das informações fornecidas pelo LLM, especialmente em tarefas de busca de informações. Essa métrica confirma que o modelo gera texto que não é apenas plausível, mas também factualmente correto.
A factualidade é indispensável para aplicativos como geração de notícias, conteúdo educacional e suporte ao cliente, em que o objetivo principal é fornecer informações precisas.

Uma avaliação robusta dos LLMs envolve a integração de abordagens quantitativas e qualitativas. Esta seção detalha uma série de metodologias, como conjuntos de dados de referência, técnicas de avaliação humana e métodos de avaliação automatizada, para avaliar completamente o desempenho do LLM.
Os conjuntos de dados de referência são ferramentas valiosas para avaliar LLMs, fornecendo tarefas padronizadas que permitem a análise comparativa entre diferentes modelos. Esses conjuntos de dados ajudam a estabelecer uma linha de base para o desempenho do modelo e facilitam o benchmarking.
Os conjuntos de dados de referência são ferramentas importantes para avaliar os LLMs, fornecendo tarefas padronizadas que permitem a análise comparativa entre diferentes modelos. Alguns dos conjuntos de dados de referência mais populares para várias tarefas de processamento de linguagem natural (NLP) incluem:
Embora os benchmarks existentes sejam valiosos, a criação de conjuntos de dados personalizados é vital para a avaliação específica do domínio. Os conjuntos de dados personalizados nos permitem adaptar o processo de avaliação aos requisitos e desafios exclusivos do aplicativo ou setor específico.
Por exemplo, um saúde poderia criar um conjunto de dados de registros médicos e anotações clínicas para avaliar a capacidade de um LLM de lidar com a terminologia e o contexto médicos. Os conjuntos de dados personalizados garantem que o desempenho do modelo esteja alinhado com os casos de uso do mundo real, fornecendo insights mais relevantes e acionáveis.
Os métodos de avaliação humana são indispensáveis para avaliar os aspectos sutis dos resultados do LLM que as métricas automatizadas podem deixar passar. Essas técnicas envolvem feedback direto de juízes humanos, oferecendo percepções qualitativas sobre o desempenho do modelo.
A avaliação humana continua sendo um padrão de ouro para avaliar a qualidade dos resultados do LLM. Os métodos de avaliação direta envolvem a coleta de feedback de juízes humanos usando pesquisas e escalas de classificação.
Esses métodos podem capturar aspectos diferenciados da qualidade do texto, como fluência, coerência e relevância, que as métricas automatizadas podem ignorar. Os juízes humanos podem fornecer feedback qualitativo sobre pontos fortes e fracos específicos, ajudando a identificar áreas específicas para aprimoramento.
O julgamento comparativo envolve técnicas como a comparação entre pares, em que os avaliadores humanos comparam diretamente os resultados de diferentes modelos. Esse método pode ser mais confiável do que as escalas de classificação absoluta, pois reduz a subjetividade associada às classificações individuais.
Os avaliadores são solicitados a escolher o melhor resultado entre os pares de textos gerados, fornecendo uma classificação relativa do desempenho do modelo. O julgamento comparativo é particularmente útil para modelos de ajuste fino e selecionar as variantes com melhor desempenho.
Os métodos de avaliação automatizados oferecem uma maneira rápida e objetiva de avaliar o desempenho do LLM. Esses métodos empregam várias métricas para quantificar diferentes aspectos dos resultados do modelo, garantindo uma avaliação abrangente.
As métricas automatizadas oferecem uma maneira rápida e objetiva de avaliar o desempenho do LLM. Métricas como perplexidade e BLEU são amplamente usadas para avaliar vários aspectos da geração de texto.
Conforme discutido anteriormente, a perplexidade mede a capacidade de previsão do modelo, com pontuações mais baixas indicando melhor desempenho. O BLEU, por outro lado, avalia a qualidade do texto gerado comparando-o com textos de referência, concentrando-se na precisão de n-gramas.
A avaliação adversarial envolve submeter os LLMs a ataques adversários para testar sua robustez. Esses ataques são projetados para explorar os pontos fracos e as tendências do modelo, revelando vulnerabilidades que podem não ser aparentes por meio de métodos de avaliação padrão.
Um ataque adversário pode envolver a entrada de dados ligeiramente alterados ou enganosos para analisar como o modelo responde. Essa abordagem é útil para aplicativos em que a confiabilidade e a segurança são tidas em alta conta, pois ajuda a identificar e atenuar os possíveis riscos.

Para avaliar efetivamente as capacidades dos LLMs, deve-se seguir uma abordagem estratégica. A adoção de práticas recomendadas garante que seu processo de avaliação seja completo, transparente e adaptado às suas necessidades específicas. Aqui, abordamos as práticas recomendadas que você deve seguir.
|
Melhores práticas |
Descrição |
Exemplo de caso |
Métrica(s) relevante(s) |
|
Definir objetivos claros |
Identifique as tarefas e as metas que o LLM deve atingir antes de iniciar o processo de avaliação. |
Melhorar o desempenho da tradução automática de um LLM |
Pontuações BLEU/ROUGE |
|
Considere seu público-alvo |
Adapte a avaliação aos usuários pretendidos do LLM, considerando suas expectativas e necessidades. |
LLM para gerar texto |
Perplexidade, fluência, coerência |
|
Transparência e reprodutibilidade |
Assegure-se de que o processo de avaliação seja bem documentado e possa ser reproduzido por outras pessoas para verificação e aprimoramento. |
Divulgar publicamente o conjunto de dados de avaliação e o código usado para avaliar os recursos do LLM |
Qualquer métrica relevante, dependendo da tarefa e dos objetivos específicos da avaliação |
Este guia oferece uma visão geral abrangente das métricas e metodologias essenciais para avaliar os LLMs, desde a perplexidade e a precisão até as medidas de parcialidade e imparcialidade.
Ao empregar técnicas de avaliação quantitativas e qualitativas e aderir às práticas recomendadas, podemos garantir uma avaliação completa e confiável desses modelos.
Com esse conhecimento, estamos mais bem equipados para selecionar e implementar LLMs que melhor atendam às nossas necessidades, garantindo seu desempenho e confiabilidade ideais nos aplicativos escolhidos.
Principais cursos de IA
Programa
Curso
Curso
blog
Nisha Arya Ahmed
12 min
blog
Abid Ali Awan
8 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan
