Recursos do Torchchat
O Torchchat oferece quatro funcionalidades principais:
- Executando LLMs utilizando Python com PyTorch.
- Operar modelos independentes em um aplicativo de desktop ou servidor sem Python.
- Execução de modelos em um dispositivo móvel.
- Avaliação do desempenho de um modelo.
Execute LLMs usando Python com PyTorch
Esse modo permite que você execute um LLM em uma máquina que tenha o Python e o PyTorch instalados. Podemos interagir com o modelo diretamente no terminal ou configurando um servidor com uma API REST. É nisso que vamos nos concentrar para configurar neste artigo.
Operação de modelos autônomos
O Torchchat usa o AOT Inductor (Ahead-of-Time Inductor) para criar um executável autônomo e distribuível para programas de inferência do PyTorch, especificamente na forma de uma biblioteca dinâmica sem dependência do Python e do PyTorch.
Essa abordagem atende à necessidade de implantar modelos em um ambiente de produção em que há um requisito de estabilidade do tempo de execução do modelo em relação a atualizações e alterações no ambiente de serviço, garantindo que os modelos permaneçam operacionais sem a necessidade de recompilação.
O AOT Inductor se concentra na otimização da implantação do modelo, permitindo formatos de distribuição binários eficientes que são rápidos de carregar e prontos para executar, abordando as limitações e a sobrecarga associadas a formatos de texto como o TorchScript. Ele utiliza técnicas de geração e otimização de código para o desempenho da CPU e da GPU, com o objetivo de reduzir a sobrecarga e melhorar a velocidade de execução.
Execução em dispositivos móveis
Para a execução em dispositivos móveis, o Torchchat utiliza o ExecuTorch. Da mesma forma que o AOT Inductor, o ExecuTorch otimiza o modelo para execução em um dispositivo móvel ou incorporado. Ele produz um artefato PTE que pode ser usado posteriormente para executar o modelo.
Avaliação de um modelo
O modo de avaliação do Torchchat pode ser usado para avaliar o desempenho de um LLM em várias tarefas disponíveis no site lm_eval. Esse é um recurso importante para pessoas que fazem pesquisas e desejam avaliar seus novos modelos em benchmarks comumente usados.
Por que usar o Torchchat
Executar um LLM localmente em vez de depender de uma API de nuvem de terceiros, como a API do API da Open AI apresenta uma variedade de casos de uso e benefícios, atendendo a diferentes necessidades e cenários.
- Aplicativos sensíveis à privacidade: Para os setores que lidam com dados confidenciais, como saúde, finanças e jurídico, a execução de LLMs localmente garante que as informações confidenciais não saiam da infraestrutura da organização, em conformidade com as normas de proteção de dados.
- Aplicativos em tempo real: Os aplicativos que exigem respostas de baixa latência, como chatbots interativos, geração de conteúdo em tempo real e sistemas de monitoramento ao vivo, podem se beneficiar da execução de LLMs localmente, eliminando a latência introduzida pela transmissão de rede de e para uma API na nuvem.
- Cenários off-line ou de baixa conectividade: Em ambientes com pouca ou nenhuma conectividade com a Internet, a implantação local permite o uso de aplicativos LLM, como pesquisa de campo, educação remota e sistemas de entretenimento a bordo.
- Controle e otimização de custos: Para casos de alto volume ou de uso contínuo, a implementação local pode ser mais econômica, evitando os modelos de preços por solicitação das APIs de nuvem e potencialmente aproveitando os recursos computacionais existentes.
Se você estiver interessado em saber mais sobre como executar um modelo de IA localmente em um dispositivo em vez de na nuvem, recomendo esta postagem do blog sobre IA de borda.
Configuração local com Python
Vamos configurar o Torchchat localmente, passo a passo. Começaremos com a clonagem do repositório Torcchat.
Clonar ou baixar o código
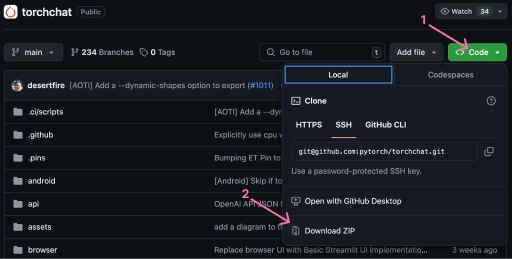
A primeira etapa para configurar o Torchchat localmente é clonar o repositório o repositório do Torchchat. Tendo Git instalado, podemos clonar o repositório abrindo um terminal e executando o comando:
git clone git@github.com:pytorch/torchchat.gitComo alternativa, podemos fazer o download do repositório usando a interface do Github.
Instalação
Vamos supor que você já tenha o Python 3.10 instalado. Para obter um guia sobre como instalar o Python, confira este artigo.
Para instalar o Torchchat, abra um terminal na pasta Torchchat. Começamos criando um ambiente virtual:
python -m venv .venvEm resumo, um ambiente virtual é um diretório independente para um projeto, contendo seus diretórios de instalação para bibliotecas Python, pacotes e, às vezes, até mesmo uma versão específica do próprio Python. Isso garante que cada projeto tenha exatamente as versões do software que precisa para ser executado, sem interferência de outros projetos e seus requisitos.
Com o ambiente virtual criado, precisamos ativá-lo. Você pode usar o ambiente virtual para criar um ambiente virtual. Você pode fazer isso com o comando:
source .venv/bin/activatePor fim, precisamos configurar o ambiente instalando todas as dependências necessárias para que o Torchchat seja executado. O Torchchat fornece um script de instalação, install_requirements.sh, que pode ser executado com o comando:
./install_requirements.shAgora o Torchchat deve estar instalado e pronto para ser usado. Podemos verificar a instalação listando os comandos do Torchchat disponíveisdisponíveis, assim:
python torchchat.py --helpUsando o Torchchat localmente com Python
Com o Torchchat instalado, podemos começar a executar LLMs em nossa máquina local.
Listagem de todos os modelos suportados
O TorchChat suporta uma grande variedade de LLMs. Você pode listar os modelos compatíveis usando o comando list:
python torchchat.py listA lista lista completa de modelos pode ser encontrada em seu repositório no GitHub.
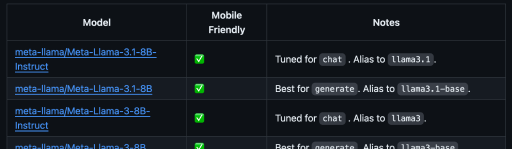
A seção "Notas" fornece informações úteis sobre o modelo, como o melhor caso de uso e o alias do modelo usado para especificar o modelo ao usar os comandos do Torchchat.
Download de um modelo
A Torchchat usa o Hugging Face como um canal de distribuição para os modelos. Hugging Face é uma plataforma colaborativa com ferramentas que permitem que qualquer pessoa crie, treine e implemente modelos de PNL e ML usando código-fonte aberto. Para saber mais sobre isso, confira esta postagem do blog sobre O que é Hugging Face?.
Antes de fazer o download de um modelo, você precisa:
- Se você não tiver uma interface de linha de comando para Hugging Face, poderá instalá-la.
- Criar uma conta no Hugging Face
- Criar um token de acesso
- Faça login usando a interface de linha de comando do Hugging Face
Para instalar a interface de linha de comando do Hugging Face, usamos pip:
pip install huggingface_hubEm seguida, podemos navegar até a seção Hugging Face para criar uma conta. Depois de criar uma conta, você pode criar um token de acesso acessando as configurações do perfil:
No perfil, podemos abrir o menu "Access Tokens" para criar um novo token:
Com relação às permissões de token, as permissões de leitura são suficientes para este artigo. Observe que, quando o token é criado, precisamos copiá-lo para a área de transferência, pois não poderemos vê-lo novamente mais tarde.
Usando o token, podemos fazer login usando o seguinte comando:
huggingface-cli loginQuando estivermos conectados, poderemos fazer o download de um modelo usando o comando download. Observe que alguns desses modelos podem ser bem grandes, portanto, certifique-se de que você tenha espaço suficiente em disco. Para fins ilustrativos, usaremos o modelo stories15M, um modelo de geração de pequenas histórias. Esse é um bom modelo para você começar, pois o download é rápido e não requer permissões especiais.
Para fazer o download, você precisa:
python torchchat.py download stories15MExecução de um modelo
Depois de fazer o download do modelo, você pode usar os comandos chat ou generate. Para gerar texto, precisamos fornecer um prompt usando o argumento --prompt. Aqui está um exemplo:
python torchchat.py generate stories15M --prompt “Once upon a time”O comando acima instruirá o Torchchat a gerar texto usando o modelo stories15M com o prompt ”Once upon a time”.
Para executar o modelo no modo de bate-papo, usamos o comando chat sem um prompt.
python torchchat.py chat stories15M O comando chat iniciará um chat interativo no terminal, no qual você poderá conversar com o LLM. Observe que alguns dos modelos são mais adequados para serem usados com o modo generate, enquanto outros são mais adequados para o modo chat. Essas informações estão disponíveis na seção "Notas" da da documentação do modelo.
Solicitação de acesso a um modelo
Alguns modelos, como o llama3, exigem acesso especial para que você possa fazer o download. Se tentarmos fazer o download desse modelo, receberemos uma mensagem de erro:
Access to model meta-llama/Meta-Llama-3-8B-Instruct is restricted and you are not in the authorized list. Visit https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct to ask for access.Você pode solicitar o acesso seguindo o URL fornecido na mensagem de erro. Precisamos preencher um pequeno formulário com informações pessoais e concordar com os termos de serviço. Você receberá um e-mail quando o acesso for concedido.
Uso avançado
O Torchchat fornece algumas opções adicionais ao executar LLMs localmente, possibilitando adaptá-los às nossas necessidades e ao nosso hardware. Vamos explorar algumas dessas opções.
Controle da precisão
Os LLMs dependem muito da multiplicação de matrizes, que envolve a multiplicação de muitos números de ponto flutuante. Vários tipos de dados tipos de dados existem para representar números de ponto flutuante no computador com precisão variável.
Uma precisão maior pode garantir que as nuances capturadas durante o treinamento sejam fielmente representadas durante a inferência, especialmente em tarefas complexas ou na compreensão de nuances de linguagem. No entanto, o uso de números de alta precisão pode tornar a inferência significativamente mais lenta. O tipo de dados correto depende do equilíbrio entre velocidade e precisão.
Para definir o tipo de dados ao executar o LLM, você pode usar o parâmetro --dtype, por exemplo:
python torchchat.py chat --dtype fast stories15MCompilação Just-In-Time
O sinalizador --compile ativa a compilação Just-In-Time (JIT) do modelo. JIT refere-se a uma técnica usada para otimizar o desempenho da inferência, compilando dinamicamente partes do modelo em código de nível de máquina no tempo de execução, em vez de interpretá-las sempre que forem executadas. Essa abordagem pode melhorar significativamente a eficiência e a velocidade dos modelos executados em várias plataformas de hardware.
O uso do JIT resultará em tempos de inicialização mais altos devido à etapa extra de compilação, mas a inferência será executada mais rapidamente. Veja como usaríamos o chat junto com o JIT:
python torchchat.py chat --compile stories15MObserve que essa opção pode não ser compatível com todos os tipos de hardware. Nesse caso, o Torchchat ignorará a etapa de compilação e executará o LLM sem ela.
Quantização
Quantização é uma técnica usada para reduzir o tamanho do modelo e aumentar sua velocidade de inferência sem comprometer significativamente seu desempenho ou precisão. Isso é particularmente importante para implantação de LLMs em dispositivos de borda ou em ambientes em que os recursos computacionais, a memória e a largura de banda são limitados.
Em resumo, a quantização envolve a conversão dos pesos e das ativações de uma rede neural de uma representação de ponto flutuante (geralmente floats de 32 bits) para representações de bits inferiores, como inteiros de 16 bits, inteiros de 8 bits ou até mesmo representações binárias em alguns casos.
Isso é diferente de definir a precisão com --dtype. A quantização atua diretamente sobre os pesos do modelo, criando um modelo menor, enquanto o tipo de dados especifica o tipo de dados usados nos cálculos de inferência.
O uso da quantização no Torchchat requer um arquivo de configuração JSON e pode ser usado da seguinte forma:
python torchchat.py chat --quantize config.json stories15MPara obter mais detalhes sobre o formato do arquivo de configuração config.json ou sobre como a quantização funciona no Torchchat, você pode consultar a página de documentação de quantização do Torchat, consulte a página de documentação de quantização.
Especificação do dispositivo
Você pode especificar o dispositivo usado para executar o LLM usando a opção --device. Por exemplo, para executá-lo no CUDA, usaríamos:
python torchchat.py chat --device cuda stories15MConclusão
O Torchchat é um grande passo para a democratização da inferência LLM. Ele facilita a execução eficiente de LLMs em uma ampla variedade de dispositivos.
O Torchchat oferece muito mais recursos do que os que apresentamos neste artigo. Fornecemos as explicações necessárias para que você possa começar a executar LLMs localmente em seu computador usando Python e PyTorch. Eu recomendo fortemente que você explore mais o Torchchat.



