
Programa
Desenvolvimento de aplicativos de IA
21 h
O ajuste fino de reforço (RFT) é uma técnica para refinar o conhecimento de grandes modelos de linguagem por meio de um loop de treinamento orientado por recompensa.
Os modelos Frontier são modelos de linguagem de uso geral notáveis. Os melhores deles se destacam em uma ampla gama de tarefas, como tradução, assistência, programação e muito mais. No entanto, uma área significativa da pesquisa em andamento se concentra em ajuste fino esses modelos de forma eficiente. O objetivo é adaptá-los para que assumam tons e estilos específicos ou se especializem em campos restritos, como fornecer consultoria médica especializada ou executar tarefas de classificação específicas de um domínio.
O desafio está em realizar esse ajuste fino de forma eficiente. Eficiência significa consumir menos energia computacional e exigir menos conjuntos de dados rotulados e, ao mesmo tempo, obter resultados de alta qualidade. É nesse ponto que a RFT entra em ação, oferecendo uma solução promissora para esse problema.
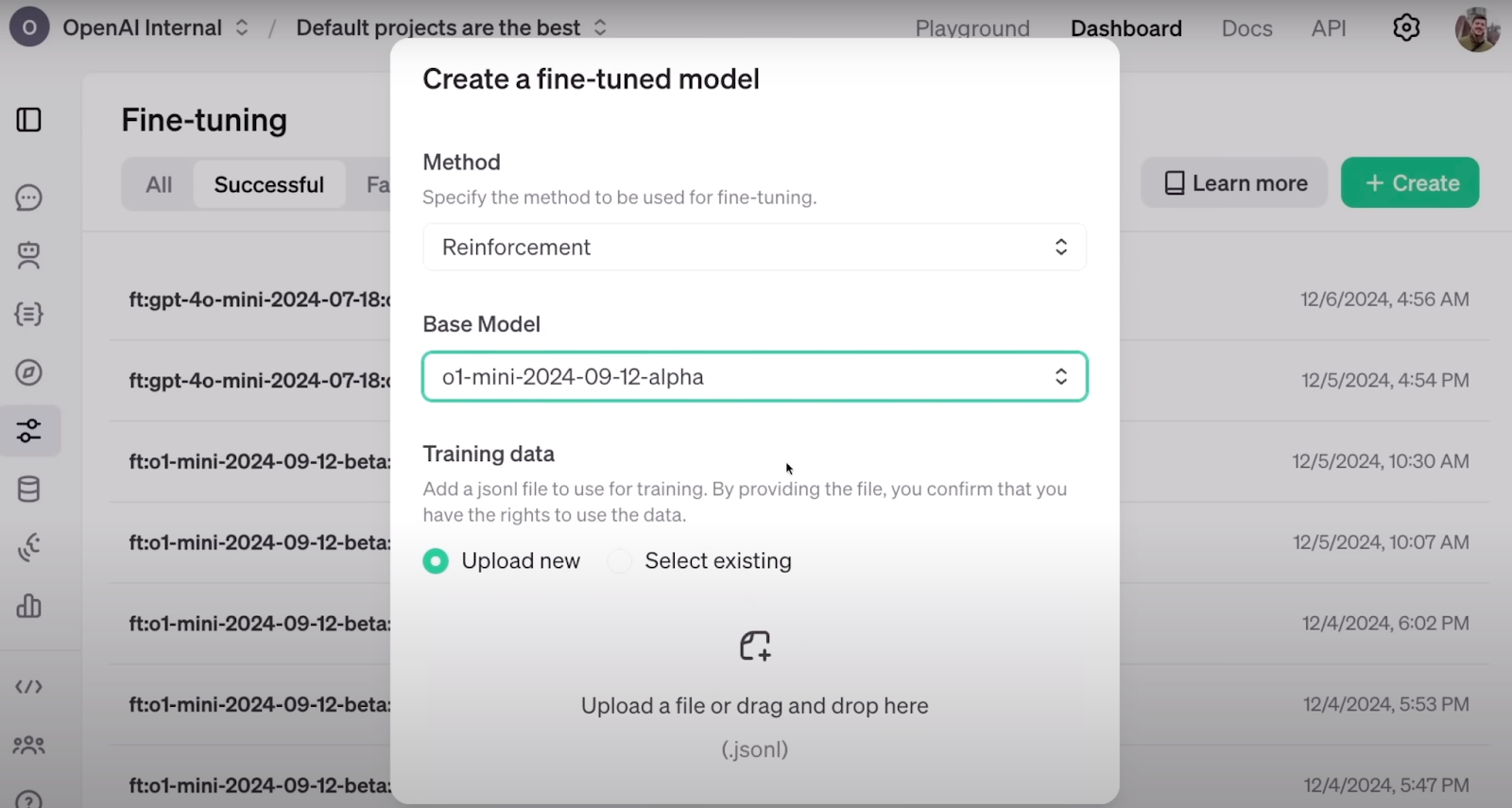
É assim que você configura o RFT no painel da OpenAI. Fonte: OpenAI
De acordo com o anúncio da OpenAI da OpenAIa RFT pode fazer o ajuste fino de um modelo com apenas algumas dezenas de exemplos. Em muitos campos, como o setor médico, em que os dados são escassos e caros, menos dados são muito úteis.
O RFT foi desenvolvido com base na espinha dorsal do aprendizado por reforço (RL), em que os agentes são recompensados positiva ou negativamente com base em suas ações, permitindo que se alinhem com o comportamento que esperamos deles. Isso é feito atribuindo-se uma pontuação ao resultado do agente. Por meio de treinamento iterativo com base nessas pontuações, os agentes aprendem sem precisar entender explicitamente as regras ou memorizar etapas predefinidas para resolver o problema.
Quando combinada com os esforços para aprimorar os LLMs em tarefas especializadas, a RFT emerge da RL e das técnicas de ajuste fino. A ideia é realizar a RFT por meio de um conjunto de etapas:
1. Forneça um conjunto de dados estruturado e rotulado que equipe o modelo com o conhecimento que você deseja que ele aprenda. Como uma tarefa típica de aprendizado de máquina, esse conjunto de dados deve ser dividido em um conjunto de treinamento e um conjunto de validação.
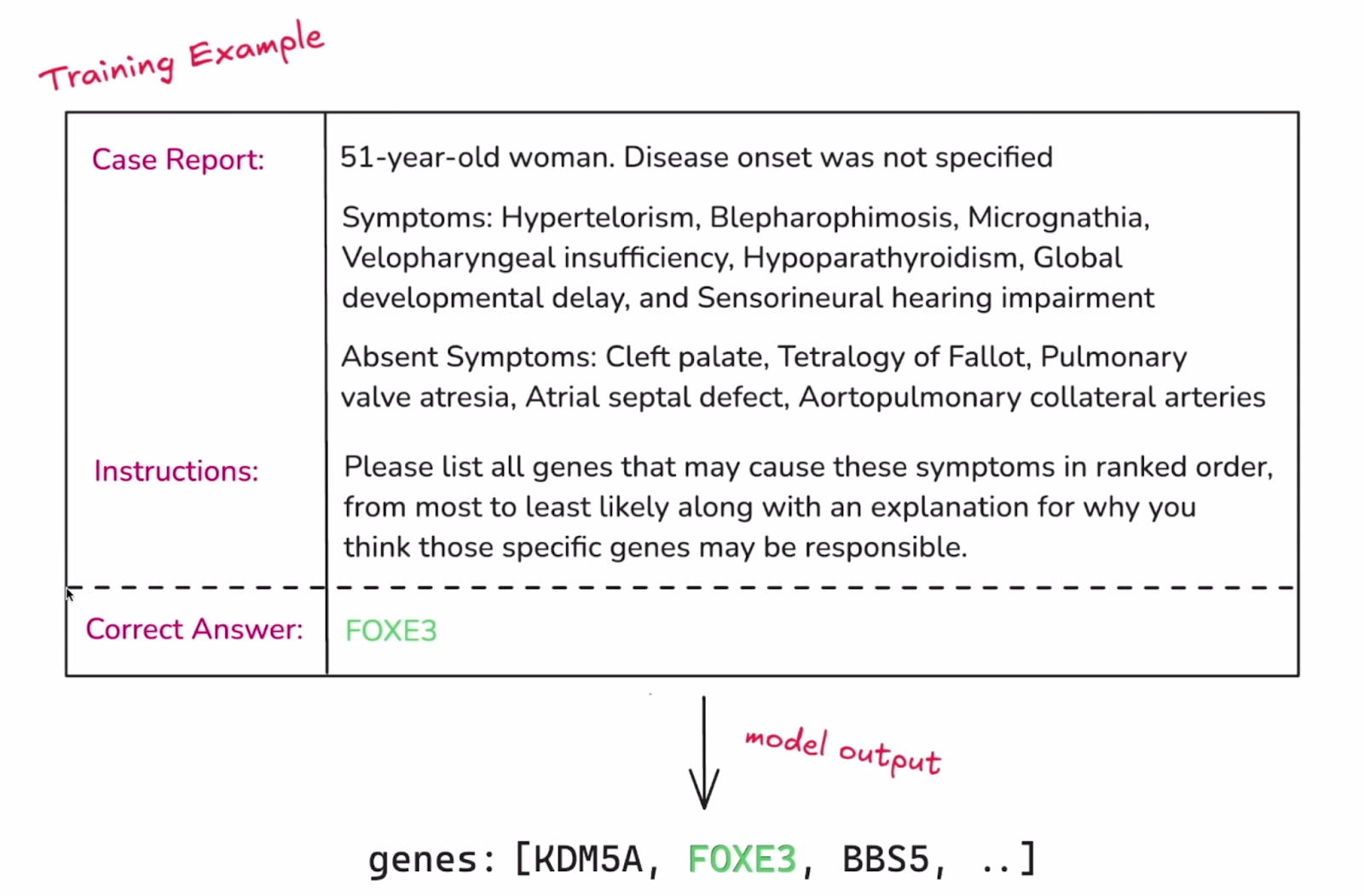
Exemplo de uma única instância do conjunto de dados. Fonte: OpenAI
2. O próximo componente essencial da RFT é estabelecer uma maneira de avaliar os resultados do modelo. Em um processo típico de ajuste fino, o modelo simplesmente tenta reproduzir a resposta alvo rotulada. No entanto, na RFT, o modelo deve desenvolver um processo de raciocínio que leve a essas respostas. A classificação dos resultados do modelo é o que o orienta durante o ajuste fino, e é feita usando os"Graders" do site . A nota pode variar de 0 a 1 ou qualquer outro valor intermediário, e há muitas maneiras de atribuir uma nota ao conjunto de resultados de um modelo. A OpenAI anunciou planos para lançar mais avaliadores e possivelmente introduzir uma maneira de os usuários implementarem seus próprios avaliadores personalizados.
3. Depois que o modelo responde à entrada do conjunto de treinamento, sua saída é pontuada pelo avaliador. Essa pontuação serve como sinal de "recompensa". Os pesos e os parâmetros do modelo são então ajustados para maximizar as recompensas futuras.
4. O modelo é ajustado por meio de etapas repetidas. A cada ciclo, o modelo aprimora sua estratégia e o conjunto de validação (mantido separado do treinamento) é usado periodicamente para verificar se esses aprimoramentos são generalizados para novos exemplos. Quando as pontuações do modelo melhoram nos dados de validação, é um bom sinal de que o modelo está realmente aprendendo estratégias significativas e não simplesmente memorizando soluções.
Essa explicação capta a essência da RFT, mas a implementação e os detalhes técnicos podem ser diferentes.
Observando abaixo os resultados da avaliação do RFT, que comparam um modelo o1-mini ajustado com um modelo o1-mini e o1 padrão, é impressionante que o RFT, usando um conjunto de dados de apenas 1.100 exemplos, tenha obtido maior precisão do que o modelo modelo o1apesar de este último ser maior e mais avançado do que o o1-mini.
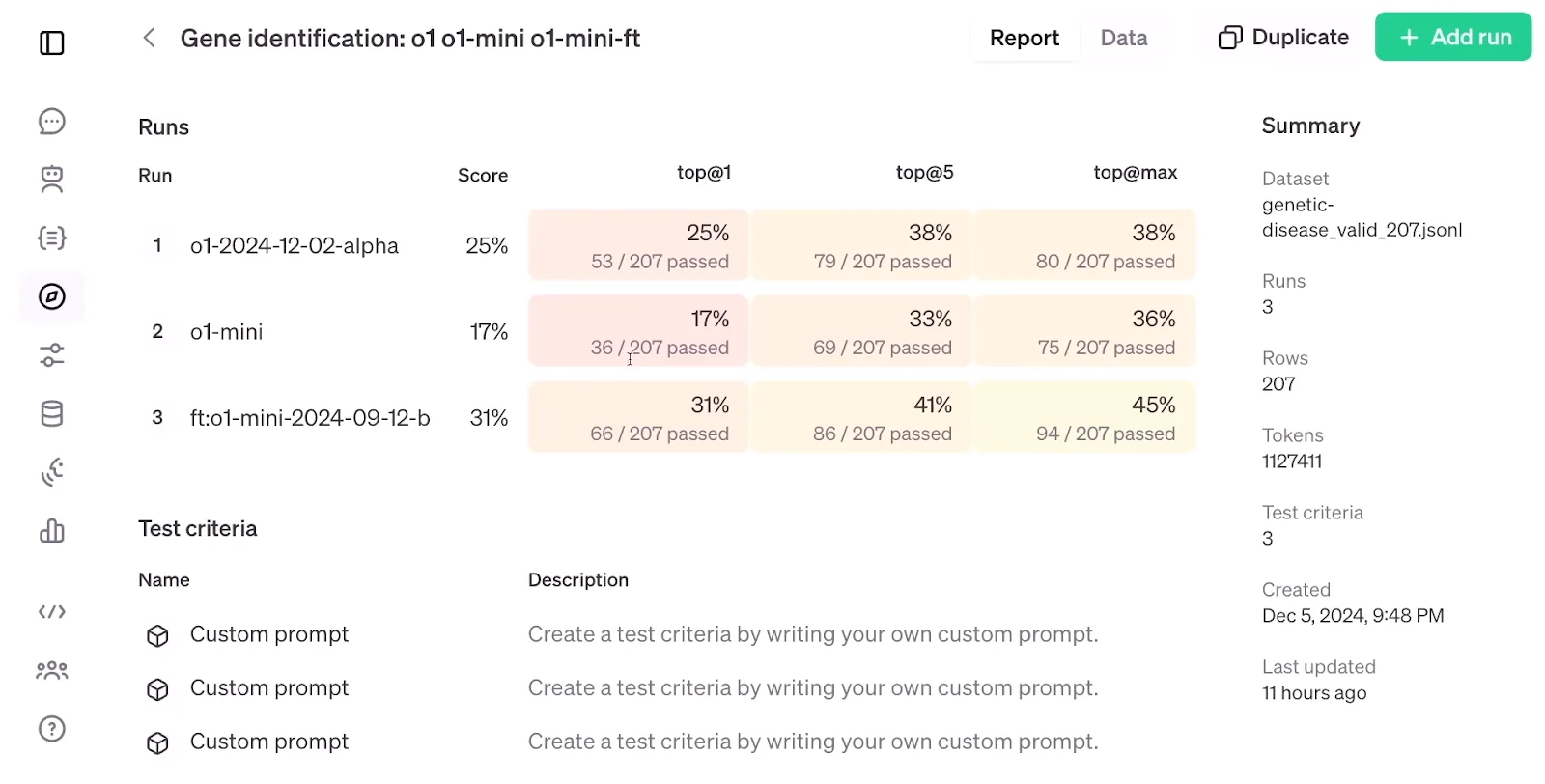
Avaliação da RFT. Fonte: OpenAI
O ajuste fino supervisionado (SFT) envolve pegar um modelo pré-treinado e ajustá-lo com dados adicionais usando técnicas de aprendizado supervisionado. Na prática, o SFT funciona melhor quando o objetivo é alinhar a saída ou o formato do modelo a um conjunto de dados específico ou garantir que o modelo siga determinadas instruções.
Embora tanto o ajuste fino supervisionado quanto o ajuste fino por reforço dependam de dados rotulados, eles os utilizam de forma diferente. No SFT, os dados rotulados orientam diretamente as atualizações do modelo. O modelo vê isso como o resultado desejado e ajusta seus parâmetros para reduzir a diferença entre o resultado previsto e a resposta correta conhecida.
No RFT, a exposição do modelo ao rótulo é indireta, pois ele é usado principalmente para criar o sinal de recompensa em vez de ser um alvo direto. É por isso que se espera que o modelo exija menos dados rotulados na RFT - o modelo tem como objetivo encontrar padrões para produzir o resultado que desejamos, em vez de ter como objetivo direto produzir nossos resultados, e isso promete mais tendência a generalizar.
Vamos resumir as diferençascom esta tabela:
|
Recurso |
Ajuste fino supervisionado (SFT) |
Ajuste fino de reforço (RFT) |
|
Ideia central |
Treine diretamente o modelo em dados rotulados para corresponder à saída desejada. |
Use um "Grader" para fornecer recompensas ao modelo por gerar o resultado desejado. |
|
Uso de rótulos |
Alvo direto para o modelo imitar. |
Usado indiretamente para criar um sinal de recompensa para o modelo. |
|
Eficiência de dados |
Requer mais dados rotulados. |
Potencialmente requer menos dados rotulados devido à generalização. |
|
Envolvimento humano |
Somente na rotulagem inicial de dados. |
Somente ao projetar a função "Grader". |
|
Generalização |
Pode se ajustar excessivamente aos dados de treinamento, limitando a generalização. |
Maior potencial de generalização devido ao foco em padrões e recompensas. |
|
Alinhamento com as preferências humanas |
Limitado, pois se baseia apenas na imitação dos dados rotulados. |
Pode ser mais bem alinhado se o "Grader" refletir com precisão as preferências humanas. |
|
Exemplos |
Ajuste fino de um modelo de linguagem para gerar tipos específicos de formatos de texto (como poemas ou códigos). |
Treinamento de um modelo de linguagem para gerar conteúdo criativo que é avaliado por um "Grader" com base na originalidade e na coerência. |
Ao ler sobre RFT, não pude deixar de pensar em outra técnica eficaz e clássica chamada aprendizagem por reforço a partir de feedback humano (RLHF). No RLHF, os anotadores humanos fornecem feedback sobre como responder às solicitações, e um modelo de recompensa é treinado para converter esse feedback em sinais numéricos de recompensa. Esses sinais são então usados para ajustar os parâmetros do modelo pré-treinado por meio de otimização da política proximal (PPO).
Embora o RFT retire o feedback humano do loop e conte com o Grader para atribuir o sinal de recompensa à resposta do modelo, a ideia de integrar o aprendizado por reforço ao ajuste fino do LLM ainda é consistente com a do RLHF.
É interessante notar que o RLHF foi o método usado anteriormente para alinhar melhor o modelo no processo de treinamento do ChatGPT. De acordo com o vídeo de anúncio, o RFT é o método que a OpenAI usa internamente para treinar seus modelos de fronteira, como GPT-4o ou o1 pro mode.
O aprendizado por reforço foi integrado ao ajuste fino dos LLMs anteriormente, mas o ajuste fino por reforço da OpenAI parece levar isso a um nível mais alto.
Embora a mecânica exata do RFT, sua data de lançamento e uma avaliação científica de sua eficácia ainda não tenham sido divulgadas, podemos cruzar os dedos e esperar que o RFT esteja acessível em breve e seja tão poderoso quanto prometido.
Aprenda IA com estes cursos!
Programa
Programa
Curso
blog
Abid Ali Awan
5 min
blog
Abid Ali Awan
9 min
Tutorial
Josep Ferrer
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Abid Ali Awan


