
Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Antes de começarmos, apenas uma observação: ao abordar os casos de uso de IA na área da saúde, é extremamente importante estar atento aos resultados potencialmente prejudiciais para os pacientes. O exemplo abaixo, embora abrangente, destina-se apenas a ilustrar o ajuste fino em um conjunto de dados do mundo real. Se você estiver buscando casos de uso de IA na área da saúde ou em outros domínios sensíveis, recomendamos a leitura do nosso guia de Ética em IA.
Neste tutorial, você aprenderá sobre os modelos Llama 3.1 e fará o ajuste fino do modelo Llama-3.1-8b-It na análise de sentimentos do conjunto de dados de saúde mental. Nosso objetivo é personalizar o modelo para que ele possa prever o estado de saúde mental do paciente com base no texto. Também mesclaremos o adaptador com o modelo baseado e salvaremos o modelo completo no hub Hugging Face.
Aprenderemos sobre os modelos do Llama 3.1, como acessá-los no Kaggle e como usar a biblioteca Transformer para executar a inferência do modelo. Também faremos o ajuste fino do modelo Llama-3.1-8b-It no conjunto de dados de classificação de saúde mental. Por fim, mesclaremos o adaptador salvo com o modelo básico e enviaremos o modelo completo para o Hugging Face Hub.
Se você é novo no assunto, pode aprender sobre a teoria por trás do ajuste fino lendo nosso artigo, Guia introdutório para LLMs de ajuste fino.

Imagem do autor
O Llama 3.1 é a mais recente série de modelos multilíngues de grande porte (LLMs) desenvolvidos pela Meta AI, que estão ampliando os limites da compreensão e da geração de idiomas. Ele vem em três tamanhos: Parâmetros 8B, 70B e 405B.
Os modelos da Llama 3.1 são criados com base em uma arquitetura de modelo de linguagem auto-regressiva com transformadores otimizados e podem ser ajustados para várias tarefas de processamento de linguagem natural e conjuntos de dados. Eles são treinados em um conjunto de dados diversificado de dados on-line disponíveis publicamente, suportam oito idiomas (inglês, alemão, francês, italiano, português, hindi, espanhol e tailandês) e vêm com um comprimento de contexto de 128k.
Os modelos Llama 3.1 estão disponíveis para todos sob licenças comerciais personalizadas e exigem informações mínimas sobre o indivíduo para que você possa fazer o download dos pesos do modelo.
O Llama 3.1 foi otimizado para o diálogo multilíngue e superou o Gemma 2, o GPT 3.5 turbo e o GPT-4o em vários benchmarks, incluindo bate-papo geral, codificação, matemática, raciocínio e muito mais. Ele é, de longe, o modelo de código aberto mais rápido e preciso disponível.
Fonte: Llama 3.1 (meta.com)
Você pode saber mais sobre o modelo Llama 3.1 lendo O que é o Llama 3.1 405B da Meta? Como funciona, casos de uso e muito mais.
Para este tutorial, usaremos o Kaggle Notebook como um ambiente de desenvolvimento, pois ele oferece GPUs e TPUs gratuitas. Para usar o modelo Llama 3.1 no notebook do Kaggle, siga estas etapas:
1. Preencha o formulário em meta.com com o mesmo endereço de e-mail da sua conta do Kaggle.
2. Acesse o Meta | Llama 3.1 no repositório de modelos do Kaggle e clique no botão "acessar o modelo". Aceite todos os termos e, após alguns segundos, você terá acesso ao modelo.
3. Inicie o notebook do Kaggle com os modelos do Llama 3.1 clicando no botão "Code" disponível no canto superior direito da página do modelo.
4. Selecione a estrutura, a variação e a versão e pressione o botão "Add Model" (Adicionar modelo).
5. Instale os pacotes Python necessários no notebook da Kaggle usando o seguinte comando:
%pip install -U transformers accelerate6. Carregue o modelo e o tokenizador usando a biblioteca Transformers do diretório local.
7. Crie o pipeline de geração de texto com o modelo, o tokenizador, o tipo de tocha e o mapa do dispositivo.
from transformers import AutoTokenizer,AutoModelForCausalLM,pipeline
import torch
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
tokenizer = AutoTokenizer.from_pretrained(base_model)
model = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)8. Escreva a mensagem e converta-a no prompt adequado usando o modelo de bate-papo.
9. Execute o pipeline usando o prompt e imprima a saída gerada.
messages = [{"role": "user", "content": "What is the tallest building in the world?"}]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipe(prompt, max_new_tokens=120, do_sample=True)
print(outputs[0]["generated_text"])A resposta é precisa e detalhada.

Se você tiver dificuldades para executar a inferência do modelo, consulte o Kaggle Notebook em Llama 3.1 Inferência de modelo simples.
Agora, precisamos carregar o conjunto de dados, processá-lo e ajustar o modelo Llama 3.1. Também compararemos o desempenho do modelo antes e depois do ajuste fino.
Se você é novo em LLMs, recomendo que faça o curso Conceitos de modelos de linguagem grandes (LLMs) antes de mergulhar na parte de ajuste fino do tutorial.
Primeiro, iniciaremos o novo notebook do Kaggle e o modelo Llama 3.1, como fizemos na seção anterior.
Em seguida, instalaremos os pacotes Python necessários, conforme descrito abaixo:
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peft
%pip install -U trlEm seguida, adicionamos a Análise de sentimento para saúde mental no notebook do Kaggle. Para fazer isso, clique no botão "Add Input" (Adicionar entrada) localizado na parte superior direita e cole o link do modelo na barra de pesquisa. Em seguida, para adicionar o modelo, basta clicar no botão de adição (+).
Acompanharemos o desempenho do modelo usando a API Weights and Biases. Para acessar a API, precisamos da chave da API. Configure a chave de API no Kaggle usando Secrets e ative-a, conforme mostrado abaixo.
Em seguida, podemos iniciar o projeto Weights and Biases usando a chave da API.
import wandb
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
wb_token = user_secrets.get_secret("wandb")
wandb.login(key=wb_token)
run = wandb.init(
project='Fine-tune llama-3.1-8b-it on Sentiment Analysis Dataset',
job_type="training",
anonymous="allow"
)Em seguida, precisamos importar todos os pacotes e funções Python necessários.
import numpy as np
import pandas as pd
import os
from tqdm import tqdm
import bitsandbytes as bnb
import torch
import torch.nn as nn
import transformers
from datasets import Dataset
from peft import LoraConfig, PeftConfig
from trl import SFTTrainer
from trl import setup_chat_format
from transformers import (AutoModelForCausalLM,
AutoTokenizer,
BitsAndBytesConfig,
TrainingArguments,
pipeline,
logging)
from sklearn.metrics import (accuracy_score,
classification_report,
confusion_matrix)
from sklearn.model_selection import train_test_splitAgora é hora de carregarmos o conjunto de dados, realizarmos a limpeza dos dados e eliminarmos três categorias ambíguas.
Para simplificar, eliminaremos a categoria "Suicidal" porque o Llama 3.1 tem mecanismos de segurança para evitar certas palavras desencadeadoras. O "estresse" não é considerado um transtorno mental, e o "transtorno de personalidade" tem muitas semelhanças com o "transtorno bipolar".
Como resultado, ficaremos com apenas quatro categorias: "Normal", "Depressão", "Ansiedade" e "Bipolar".
df = pd.read_csv("/kaggle/input/sentiment-analysis-for-mental-health/Combined Data.csv",index_col = "Unnamed: 0")
df.loc[:,'status'] = df.loc[:,'status'].str.replace('Bi-Polar','Bipolar')
df = df[(df.status != "Personality disorder") & (df.status != "Stress") & (df.status != "Suicidal")]
df.head()
Para economizar tempo de treinamento, faremos o ajuste fino do modelo com apenas 3.000 amostras. Para isso, embaralharemos o conjunto de dados e selecionaremos 3.000 linhas.
Em seguida, dividiremos o conjunto de dados em conjuntos de treinamento, avaliação e teste para treinamento e teste do modelo.
Também queremos criar a coluna "text" nos conjuntos de treinamento e avaliação usando a função generate_prompt, que combina os dados das colunas "statement" e "status".
Por fim, criaremos a coluna "text" no conjunto de teste usando a função generate_test_prompt e a y_true usando a coluna "status". Nós o usaremos para gerar o relatório de avaliação do modelo, conforme mostrado abaixo.
# Shuffle the DataFrame and select only 3000 rows
df = df.sample(frac=1, random_state=85).reset_index(drop=True).head(3000)
# Split the DataFrame
train_size = 0.8
eval_size = 0.1
# Calculate sizes
train_end = int(train_size * len(df))
eval_end = train_end + int(eval_size * len(df))
# Split the data
X_train = df[:train_end]
X_eval = df[train_end:eval_end]
X_test = df[eval_end:]
# Define the prompt generation functions
def generate_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: {data_point["status"]}""".strip()
def generate_test_prompt(data_point):
return f"""
Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {data_point["statement"]}
label: """.strip()
# Generate prompts for training and evaluation data
X_train.loc[:,'text'] = X_train.apply(generate_prompt, axis=1)
X_eval.loc[:,'text'] = X_eval.apply(generate_prompt, axis=1)
# Generate test prompts and extract true labels
y_true = X_test.loc[:,'status']
X_test = pd.DataFrame(X_test.apply(generate_test_prompt, axis=1), columns=["text"])Neste ponto, queremos verificar a distribuição das categorias no conjunto de treinamento.
X_train.status.value_counts()Você pode ver abaixo que temos uma distribuição quase igual das categorias "Normal" e "Depressão". O restante dos rótulos é minoria. Isso significa que nosso conjunto de dados é desequilibrado, e o modelo será melhor na previsão de rótulos majoritários em comparação com os minoritários.
Podemos equilibrar o conjunto de dados, mas esse não é o objetivo deste tutorial.
status
Normal 1028
Depression 938
Anxiety 258
Bipolar 176
Name: count, dtype: int64Portanto, em seguida, queremos converter o conjunto de treinamento e avaliação nos conjuntos de dados do Hugging Face.
# Convert to datasets
train_data = Dataset.from_pandas(X_train[["text"]])
eval_data = Dataset.from_pandas(X_eval[["text"]])Em seguida, exibimos a quarta amostra da coluna "texto".
train_data['text'][3]Vemos que a coluna "texto" tem um prompt do sistema, a declaração e os status como rótulos.

Em seguida, queremos carregar o modelo Llama-3.1-8b-instruct em 4 bits quantização para economizar a memória da GPU.
Em seguida, carregaremos o tokenizador e definiremos o ID do token do pad.
base_model_name = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=False,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype="float16",
)
model = AutoModelForCausalLM.from_pretrained(
base_model_name,
device_map="auto",
torch_dtype="float16",
quantization_config=bnb_config,
)
model.config.use_cache = False
model.config.pretraining_tp = 1
tokenizer = AutoTokenizer.from_pretrained(base_model_name)
tokenizer.pad_token_id = tokenizer.eos_token_idAqui, criamos a função predict, que usará o pipeline de geração de texto para prever rótulos da coluna "text". A execução da função retornará uma lista de categorias de transtornos mentais com base em várias amostras no conjunto de testes.
def predict(test, model, tokenizer):
y_pred = []
categories = ["Normal", "Depression", "Anxiety", "Bipolar"]
for i in tqdm(range(len(test))):
prompt = test.iloc[i]["text"]
pipe = pipeline(task="text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=2,
temperature=0.1)
result = pipe(prompt)
answer = result[0]['generated_text'].split("label:")[-1].strip()
# Determine the predicted category
for category in categories:
if category.lower() in answer.lower():
y_pred.append(category)
break
else:
y_pred.append("none")
return y_pred
y_pred = predict(X_test, model, tokenizer)100%|██████████| 300/300 [02:54<00:00, 1.72it/s]Depois, criamos a função evaluate que usará os rótulos previstos e os rótulos verdadeiros para calcular a precisão geral do modelo e a precisão por categoria, gerar um relatório de classificação e imprimir uma matriz de confusão. A execução da função nos fornecerá um resumo detalhado da avaliação do modelo.
def evaluate(y_true, y_pred):
labels = ["Normal", "Depression", "Anxiety", "Bipolar"]
mapping = {label: idx for idx, label in enumerate(labels)}
def map_func(x):
return mapping.get(x, -1) # Map to -1 if not found, but should not occur with correct data
y_true_mapped = np.vectorize(map_func)(y_true)
y_pred_mapped = np.vectorize(map_func)(y_pred)
# Calculate accuracy
accuracy = accuracy_score(y_true=y_true_mapped, y_pred=y_pred_mapped)
print(f'Accuracy: {accuracy:.3f}')
# Generate accuracy report
unique_labels = set(y_true_mapped) # Get unique labels
for label in unique_labels:
label_indices = [i for i in range(len(y_true_mapped)) if y_true_mapped[i] == label]
label_y_true = [y_true_mapped[i] for i in label_indices]
label_y_pred = [y_pred_mapped[i] for i in label_indices]
label_accuracy = accuracy_score(label_y_true, label_y_pred)
print(f'Accuracy for label {labels[label]}: {label_accuracy:.3f}')
# Generate classification report
class_report = classification_report(y_true=y_true_mapped, y_pred=y_pred_mapped, target_names=labels, labels=list(range(len(labels))))
print('\nClassification Report:')
print(class_report)
# Generate confusion matrix
conf_matrix = confusion_matrix(y_true=y_true_mapped, y_pred=y_pred_mapped, labels=list(range(len(labels))))
print('\nConfusion Matrix:')
print(conf_matrix)
evaluate(y_true, y_pred)O Llama 3.1 teve um desempenho excepcional, mesmo sem o ajuste fino. 79% de precisão é bom o suficiente. Vamos ver como nosso modelo melhora quando o ajustamos no conjunto de dados.
Accuracy: 0.790
Accuracy for label Normal: 0.741
Accuracy for label Depression: 0.939
Accuracy for label Anxiety: 0.556
Accuracy for label Bipolar: 0.533
Classification Report:
precision recall f1-score support
Normal 0.92 0.74 0.82 143
Depression 0.70 0.94 0.80 115
Anxiety 0.68 0.56 0.61 27
Bipolar 0.89 0.53 0.67 15
accuracy 0.79 300
macro avg 0.80 0.69 0.73 300
weighted avg 0.81 0.79 0.79 300
Confusion Matrix:
[[106 33 4 0]
[ 3 108 3 1]
[ 4 8 15 0]
[ 2 5 0 8]]Ao criar o modelo, começamos extraindo os nomes dos módulos lineares do modelo usando a biblioteca bits and bytes.
Em seguida, configuramos o LoRA usando os módulos de destino, o tipo de tarefa e outros argumentos antes de definir os argumentos de treinamento. Esses argumentos de treinamento são otimizados para o notebook do Kaggle. Talvez seja necessário alterá-los se você estiver usando-os localmente.
Em seguida, criaremos o treinador de modelos usando argumentos de treinamento, um modelo, um tokenizador, uma configuração de LoRA e um conjunto de dados.
import bitsandbytes as bnb
def find_all_linear_names(model):
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16 bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
modules = find_all_linear_names(model)
modules['down_proj', 'gate_proj', 'o_proj', 'v_proj', 'up_proj', 'q_proj', 'k_proj']output_dir="llama-3.1-fine-tuned-model"
peft_config = LoraConfig(
lora_alpha=16,
lora_dropout=0,
r=64,
bias="none",
task_type="CAUSAL_LM",
target_modules=modules,
)
training_arguments = TrainingArguments(
output_dir=output_dir, # directory to save and repository id
num_train_epochs=1, # number of training epochs
per_device_train_batch_size=1, # batch size per device during training
gradient_accumulation_steps=8, # number of steps before performing a backward/update pass
gradient_checkpointing=True, # use gradient checkpointing to save memory
optim="paged_adamw_32bit",
logging_steps=1,
learning_rate=2e-4, # learning rate, based on QLoRA paper
weight_decay=0.001,
fp16=True,
bf16=False,
max_grad_norm=0.3, # max gradient norm based on QLoRA paper
max_steps=-1,
warmup_ratio=0.03, # warmup ratio based on QLoRA paper
group_by_length=False,
lr_scheduler_type="cosine", # use cosine learning rate scheduler
report_to="wandb", # report metrics to w&b
eval_strategy="steps", # save checkpoint every epoch
eval_steps = 0.2
)
trainer = SFTTrainer(
model=model,
args=training_arguments,
train_dataset=train_data,
eval_dataset=eval_data,
peft_config=peft_config,
dataset_text_field="text",
tokenizer=tokenizer,
max_seq_length=512,
packing=False,
dataset_kwargs={
"add_special_tokens": False,
"append_concat_token": False,
}
)Agora é hora de iniciar o treinamento do modelo:
trainer.train()Levou 1,5 horas para ajustar o modelo, e nossa perda de validação diminuiu gradualmente. Para obter um desempenho ainda melhor, tente treinar o modelo no conjunto de dados completo por pelo menos cinco épocas.
Em seguida, concluímos a execução dos pesos e das tendências.
wandb.finish()
model.config.use_cache = TrueVocê poderá visualizar o resumo da execução, incluindo todas as métricas necessárias para o desempenho do modelo.
Para visualizar um resumo detalhado, acesse sua conta do Weights and Biases e visualize a execução em seu navegador. Ele vem com visualizações interativas.
Em seguida, podemos salvar o adaptador de modelo e o tokenizador localmente. Na próxima seção, usaremos isso para mesclar o adotante com o modelo básico.
# Save trained model and tokenizer
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)Agora vem a parte mais importante. Nosso modelo terá um desempenho melhor após o ajuste fino ou ficará pior? Para descobrir, devemos executar a função "predict" no conjunto de teste e, em seguida, a função "evaluate" para gerar um relatório de avaliação do modelo.
y_pred = predict(X_test, model, tokenizer)
evaluate(y_true, y_pred)Como você pode ver nos resultados abaixo, isso representa uma grande melhoria no desempenho do modelo, de 79% para 91,3% de precisão. Até mesmo as pontuações da F1 estão parecendo boas.
100%|██████████| 300/300 [03:24<00:00, 1.47it/s]
Accuracy: 0.913
Accuracy for label Normal: 0.972
Accuracy for label Depression: 0.913
Accuracy for label Anxiety: 0.667
Accuracy for label Bipolar: 0.800
Classification Report:
precision recall f1-score support
Normal 0.92 0.97 0.95 143
Depression 0.93 0.91 0.92 115
Anxiety 0.75 0.67 0.71 27
Bipolar 1.00 0.80 0.89 15
accuracy 0.91 300
macro avg 0.90 0.84 0.87 300
weighted avg 0.91 0.91 0.91 300
Confusion Matrix:
[[139 3 1 0]
[ 5 105 5 0]
[ 6 3 18 0]
[ 1 2 0 12]]Agora você pode salvar o notebook do Kaggle para salvar os resultados e os arquivos de modelo. Para fazer isso, clicamos no botão "Save Version" (Salvar versão) no canto superior direito, selecionamos o tipo de versão "Quick Save" (Salvamento rápido) e selecionamos o tipo de saída de salvamento "Always save output when creating a Quick Save" (Sempre salvar a saída ao criar um salvamento rápido).
Se você estiver tendo problemas para ajustar o modelo, consulte o notebook do Kaggle notebook para obter mais assistência.
Você também pode aprender a fazer o ajuste fino dos modelos da Llama 3.0 seguindo o nosso guia, Como fazer o ajuste fino da Llama 3 e usá-la localmente.
Nesta seção, mesclaremos o adaptador com o modelo básico e salvaremos a versão completa no hub Hugging Face.
Primeiro, lançamos um novo notebook do Kaggle com aceleração de GPU e adicionamos o notebook salvo para acessar os arquivos de modelo. Você também pode incluir outros notebooks do Kaggle como entrada, da mesma forma que adiciona um conjunto de dados.
Em seguida, podemos instalar os pacotes Python necessários.
%%capture
%pip install -U bitsandbytes
%pip install -U transformers
%pip install -U accelerate
%pip install -U peftEm seguida, fazemos login na API do hub da Hugging Face usando a chave da API para enviar nossos arquivos de modelo para o repositório de modelos da Hugging Face.
from huggingface_hub import login
from kaggle_secrets import UserSecretsClient
user_secrets = UserSecretsClient()
hf_token = user_secrets.get_secret("HUGGINGFACE_TOKEN")
login(token = hf_token)Em seguida, podemos definir o diretório do modelo básico e do modelo ajustado.
base_model = "/kaggle/input/llama-3.1/transformers/8b-instruct/1"
fine_tuned_model = "/kaggle/input/fine-tune-llama-3-1-for-text-classification/llama-3.1-fine-tuned-model/"Em seguida, carregue o tokenizador e o modelo básico.
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
from peft import PeftModel
import torch
# Reload tokenizer and model
tokenizer = AutoTokenizer.from_pretrained(base_model)
base_model_reload = AutoModelForCausalLM.from_pretrained(
base_model,
return_dict=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True,
)Combinamos o modelo básico com o adaptador ajustado, conforme mostrado abaixo.
# Merge adapter with base model
model = PeftModel.from_pretrained(base_model_reload, fine_tuned_model)
model = model.merge_and_unload()Antes de salvarmos nosso modelo, vamos verificar se ele está funcionando corretamente. Crie um pipeline de geração de texto com o modelo e o tokenizador e forneça a ele o prompt de amostra.
text = "I'm trapped in a storm of emotions that I can't control, and it feels like no one understands the chaos inside me"
prompt = f"""Classify the text into Normal, Depression, Anxiety, Bipolar, and return the answer as the corresponding mental health disorder label.
text: {text}
label: """.strip()
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipe(prompt, max_new_tokens=2, do_sample=True, temperature=0.1)
print(outputs[0]["generated_text"].split("label: ")[-1].strip())Nosso modelo está funcionando perfeitamente.
DepressionAgora podemos salvar o modelo e o tokenizador localmente.
model_dir = "Llama-3.1-8B-Instruct-Mental-Health-Classification"
model.save_pretrained(model_dir)
tokenizer.save_pretrained(model_dir)Em seguida, envie o modelo e o tokenizador para o Hugging Face Hub.
model.push_to_hub(model_dir, use_temp_dir=False)
tokenizer.push_to_hub(model_dir, use_temp_dir=False)Isso criará o repositório no Hugging Face e enviará todos os arquivos do modelo e do tokenizador.
CommitInfo(commit_url='https://huggingface.co/kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification/commit/e1244abeaac159e0a48439095200a4190c2b493c', commit_message='Upload tokenizer', commit_description='', oid='e1244abeaac159e0a48439095200a4190c2b493c', pr_url=None, pr_revision=None, pr_num=None)Você pode visualizar todos os arquivos de modelo visitando o site da Hugging Face.
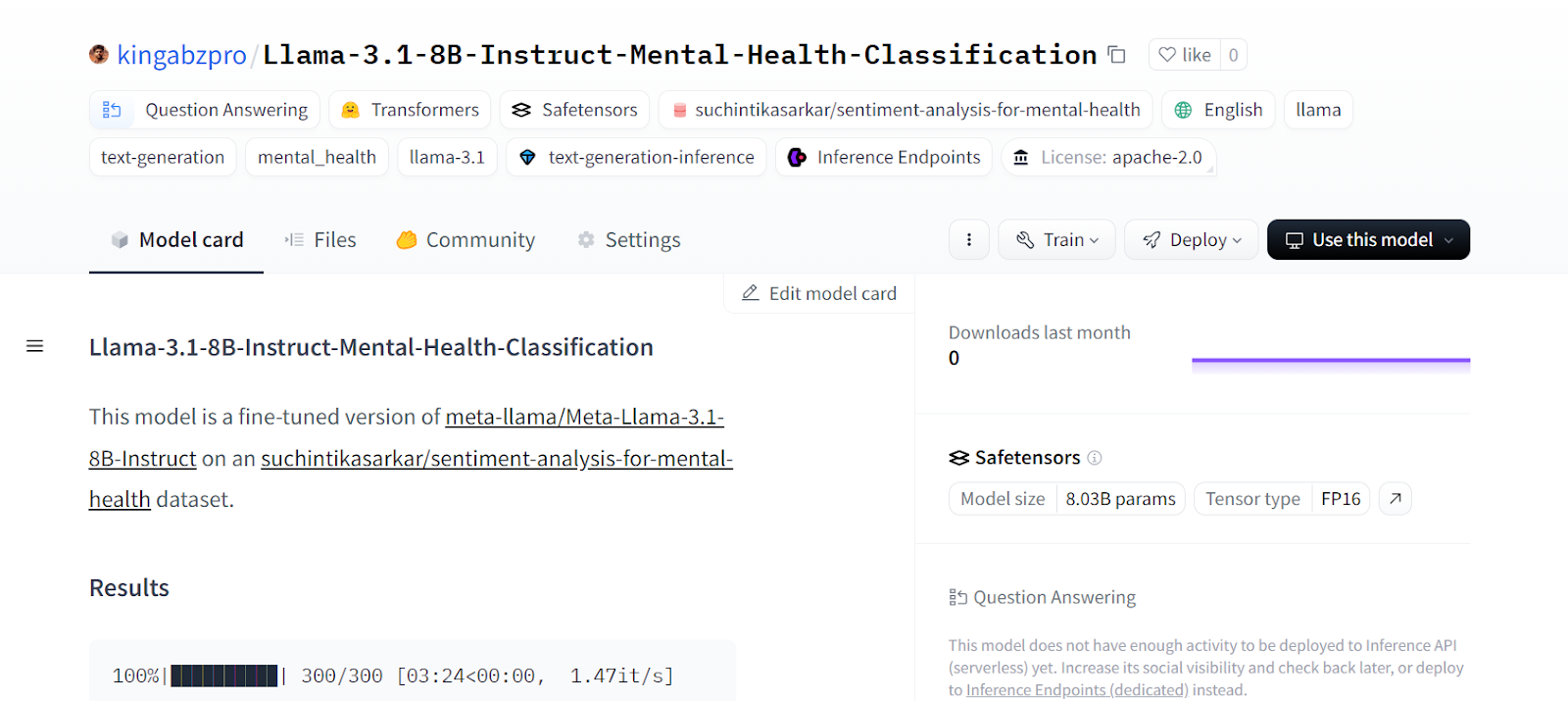
Fonte: kingabzpro/Llama-3.1-8B-Instruct-Mental-Health-Classification - Cara de Abraço
Se você estiver enfrentando problemas para mesclar o adaptador com o modelo básico, consulte o Caderno do Kaggle.
Se achar difícil fazer o ajuste fino dos LLMs, você pode seguir o site Fine-Tuning OpenAI's GPT-4: A Step-by-Step Guide tutorial para você aprender uma maneira mais fácil de usar a API OpenAI para ajustar o modelo em qualquer conjunto de dados com apenas algumas linhas de código.
O ajuste fino do modelo não se limita à personalização com base no conjunto de dados. Podemos ajustar grandes modelos de linguagem em várias tarefas de linguagem natural, como tradução automática, agrupamento, classificação, perguntas e respostas, incorporação e muito mais.
Neste tutorial, aprendemos a fazer o ajuste fino do modelo Llama 3.1 em um conjunto de dados de classificação de saúde mental. Esse modelo pode ser usado para identificar pacientes e até mesmo funcionários que estejam enfrentando desafios em seu dia a dia.
Se você está se perguntando como pode começar a trabalhar com LLMs e começar a ajustar os modelos por conta própria, considere fazer o curso Desenvolvimento de modelos de idiomas grandes que você pode fazer. Com esta série de cursos, você criará uma base sólida em LLMs, impulsionando-o para o novo cenário alimentado por IA.
Principais cursos de LLM da DataCamp
Programa
Curso
Curso
Tutorial
Josep Ferrer
Tutorial
Abid Ali Awan
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Dimitri Didmanidze
Tutorial
Zoumana Keita


