Programa
Desenvolvimento de modelos de idiomas grandes
16 h
Neste tutorial, exploraremos como ajustar o modelo Llama 3 8B usando a LlaMA-Factory WebUI no conjunto de dados de perguntas e respostas da Wikipédia. Começaremos apresentando a WebUI do LlaMA-Factory e, em seguida, você o configurará no ambiente do Google Colab. Depois de configurado, você verá o processo de ajuste fino do modelo Llama 3 8B no conjunto de dados e, em seguida, avaliará o desempenho do modelo por meio da interface de bate-papo.
À medida que avançarmos, você também aprenderá a carregar conjuntos de dados personalizados, mesclar modelos e exportá-los para o Hugging Face. Por fim, abordaremos como implantar o modelo ajustado, tornando-o acessível por meio da API da OpenAI.
Você pode obter conhecimento prático sobre tópicos populares de IA, como ChatGPT, modelos de linguagem grandes, IA generativa e muito mais, fazendo o curso Fundamentos de IA programa de habilidades.

Imagem do autor | Canva
hiyouga/LLaMA-Factory é um projeto de código aberto que permite que você faça o ajuste fino de mais de 100 modelos de linguagem grandes (LLMs) por meio de uma interface WebUI. Ele fornece um conjunto abrangente de ferramentas e scripts para ajuste fino, chatbot, atendimento e avaliação comparativa de LLMs.
O LLaMA-Factory foi projetado especificamente para iniciantes e profissionais não técnicos que desejam ajustar LLMs de código aberto em seus conjuntos de dados personalizados sem aprender conceitos complexos de IA. Os usuários só precisam selecionar um modelo, adicionar seu conjunto de dados e ajustar alguns parâmetros para iniciar o processo de treinamento.
Após a conclusão do treinamento, o mesmo aplicativo da Web pode ser usado para testar o modelo, após o que ele pode ser exportado para o Hugging Face ou salvo localmente. Isso proporciona uma maneira rápida e eficiente de fazer o ajuste fino dos LLMs localmente.
Nesta seção, aprenderemos como instalar e iniciar o LlaMA-Factory WebUI no Google Colab e no Microsoft Windows.
O Google Colab fornece acesso a GPUs gratuitas, portanto, se o seu laptop não tiver uma GPU ou CUDA instalada, você pode usar o Google Colab. Recomendei que você começasse com um notebook Colab.
%cd /content/
%rm -rf LLaMA-Factory
!git clone https://github.com/hiyouga/LLaMA-Factory.git
%cd LLaMA-Factory
%ls
%pip install -e .[torch,bitsandbytes]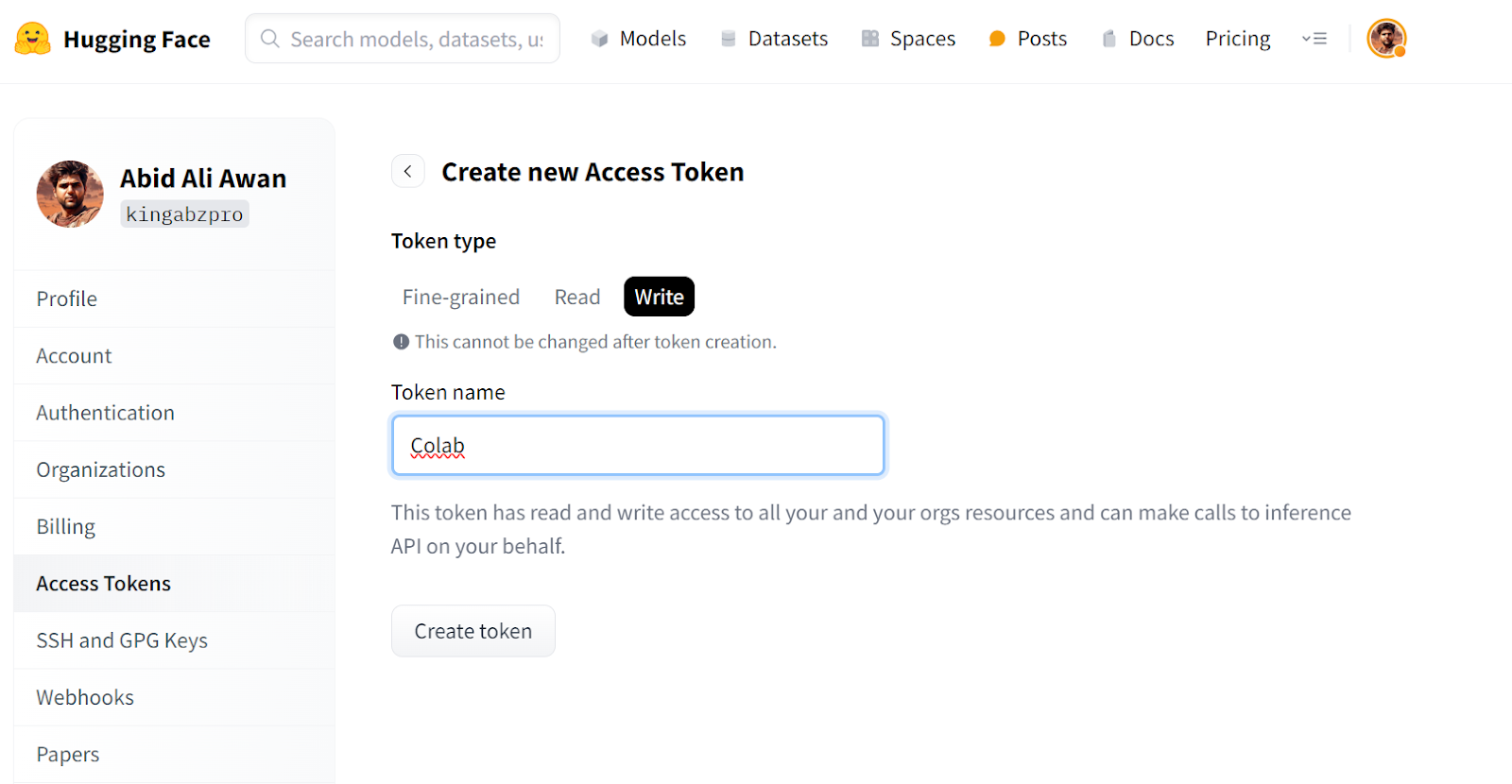
from huggingface_hub import login
from google.colab import userdata
hf_token = userdata.get("HUGGINGFACE_TOKEN")
login(token = hf_token)llamafactory-cli. Estamos definindo GRADIO_SHARE=1 para que você possa gerar um link público para acessar o aplicativo Web. %cd /content/LLaMA-Factory/
!GRADIO_SHARE=1 llamafactory-cli webui
A WebUI do LLAMA-Factory parece simples, mas tem muitas opções e guias. Vamos explorá-las na próxima seção.
Se você estiver enfrentando problemas para iniciar sua própria WebUI do LlaMA-Factory, consulte o Bloco de notas do Google Colab.
Se quiser executar o LlaMA-Factory WebUI localmente no Windows, você precisará instalar uma versão pré-construída da biblioteca bitsandbytes. Ele é compatível com CUDA 11.1 a 12.2, portanto, selecione a versão apropriada com base na versão que você possui. versão CUDA.
$ git clone https://github.com/hiyouga/LLaMA-Factory.git
$ cd LLaMA-Factory
$ pip install -e .[torch,bitsandbytes]
$ pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl$ llamafactory-cli webui$ huggingface-cli loginNão haverá codificação nesta seção. Selecionaremos o modelo e o conjunto de dados para ajuste fino, alteraremos alguns parâmetros e pressionaremos alguns botões para um treinamento mais rápido.
Para entender a teoria por trás do ajuste fino de modelos de linguagem grandes, confira este guia abrangente: Ajuste fino de modelos de idiomas grandes.
Estaremos ajustando o unsloth/llama-3-8b-bnb-4bit no modelo Microsoft/wiki_qa da Microsoft. O conjunto de dados contém várias colunas, conforme mostrado abaixo, mas usaremos as colunas "pergunta" e "resposta" para o ajuste fino do modelo.
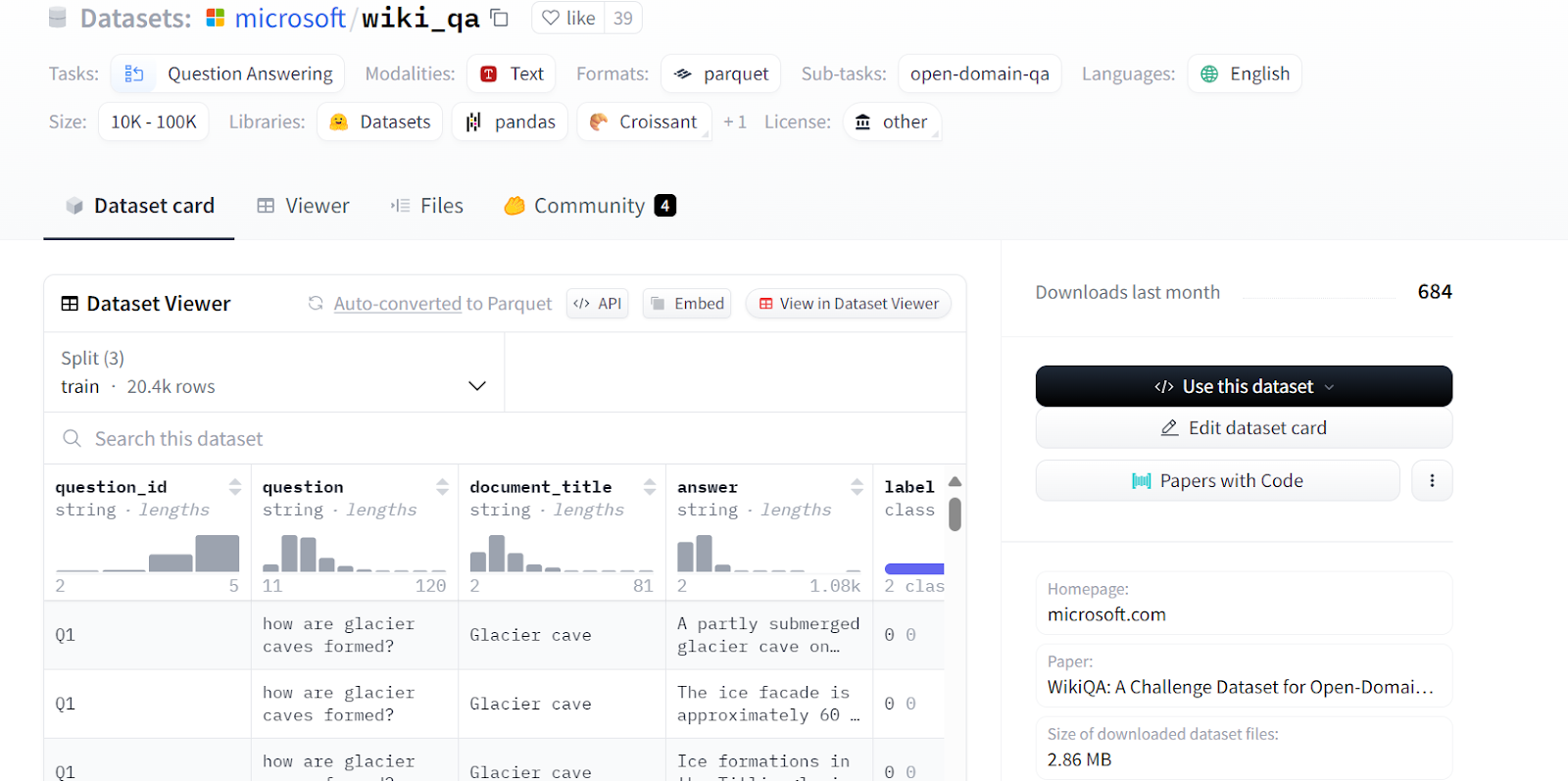
Fonte: microsoft/wiki_qa | Corpus de resposta a perguntas Wiki da Microsoft
Não é possível carregar o modelo completo de instruções LLaMA-3-8B na versão gratuita do Google Colab. Em vez disso, carregaremos a versão quantizada de 4 bits do mesmo modelo fornecido pelo Unsloth.
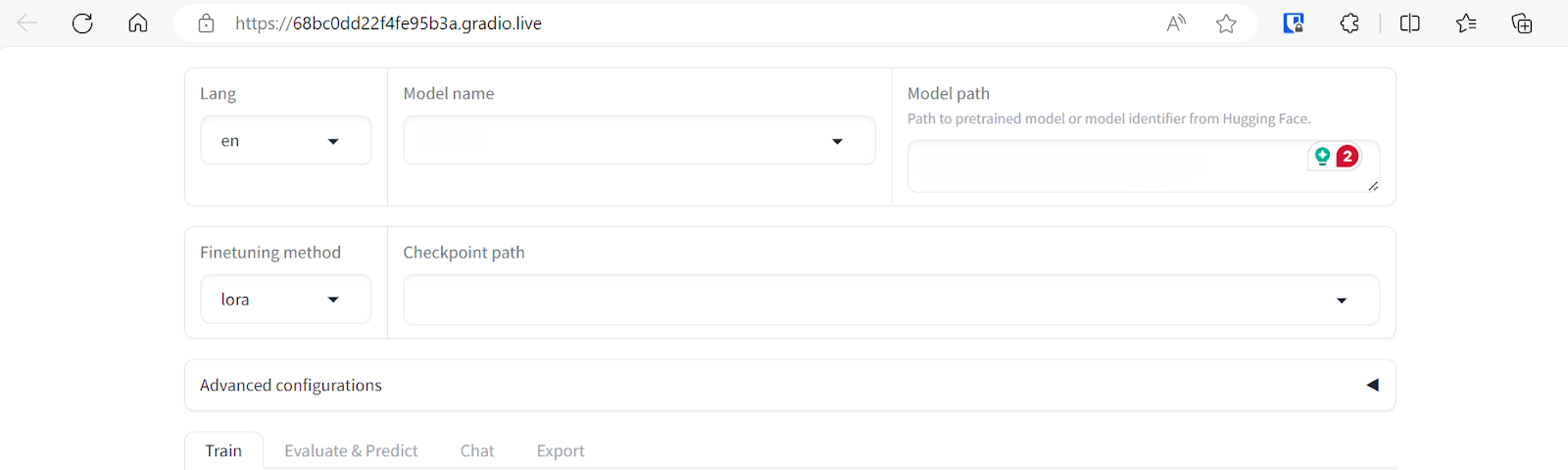
Para fazer isso, selecione o nome do modelo "Custom" (Personalizado) e cole o link do repositório "unsloth/llama-3-8b-bnb-4bit" no caminho do modelo.
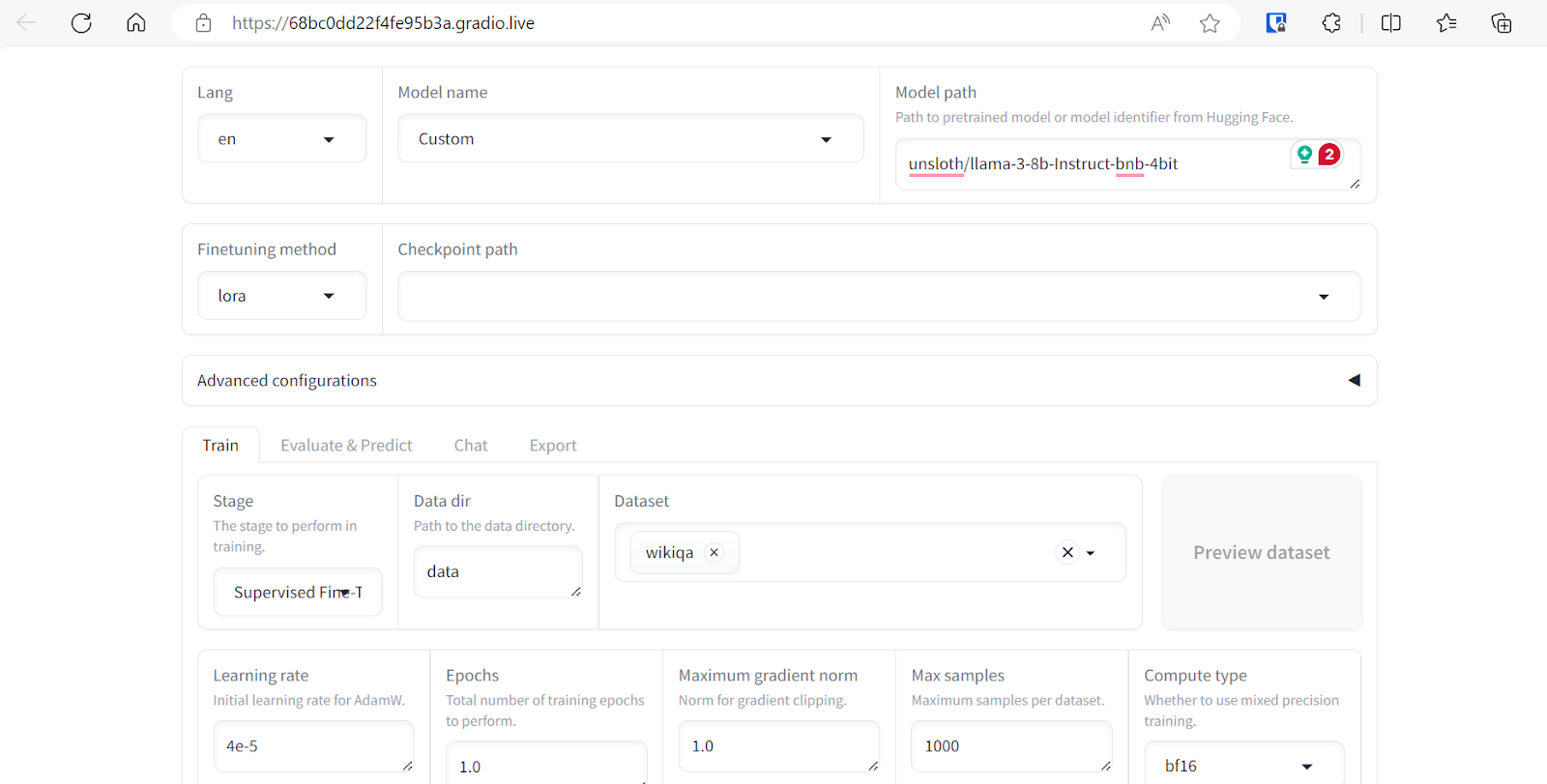
Podemos selecionar vários conjuntos de dados para ajustar nosso modelo. No entanto, para este tutorial, usaremos apenas o conjunto de dados "Wikiqa", que você pode selecionar facilmente em um conjunto de dados predefinido, conforme mostrado acima.
Ajuste os argumentos de treinamento do modelo rolando a página para baixo. Vamos definir os seguintes parâmetros:
O restante dos argumentos será mantido com seus valores padrão. Esses valores podem ser alterados para modificar o comportamento do modelo ajustado.
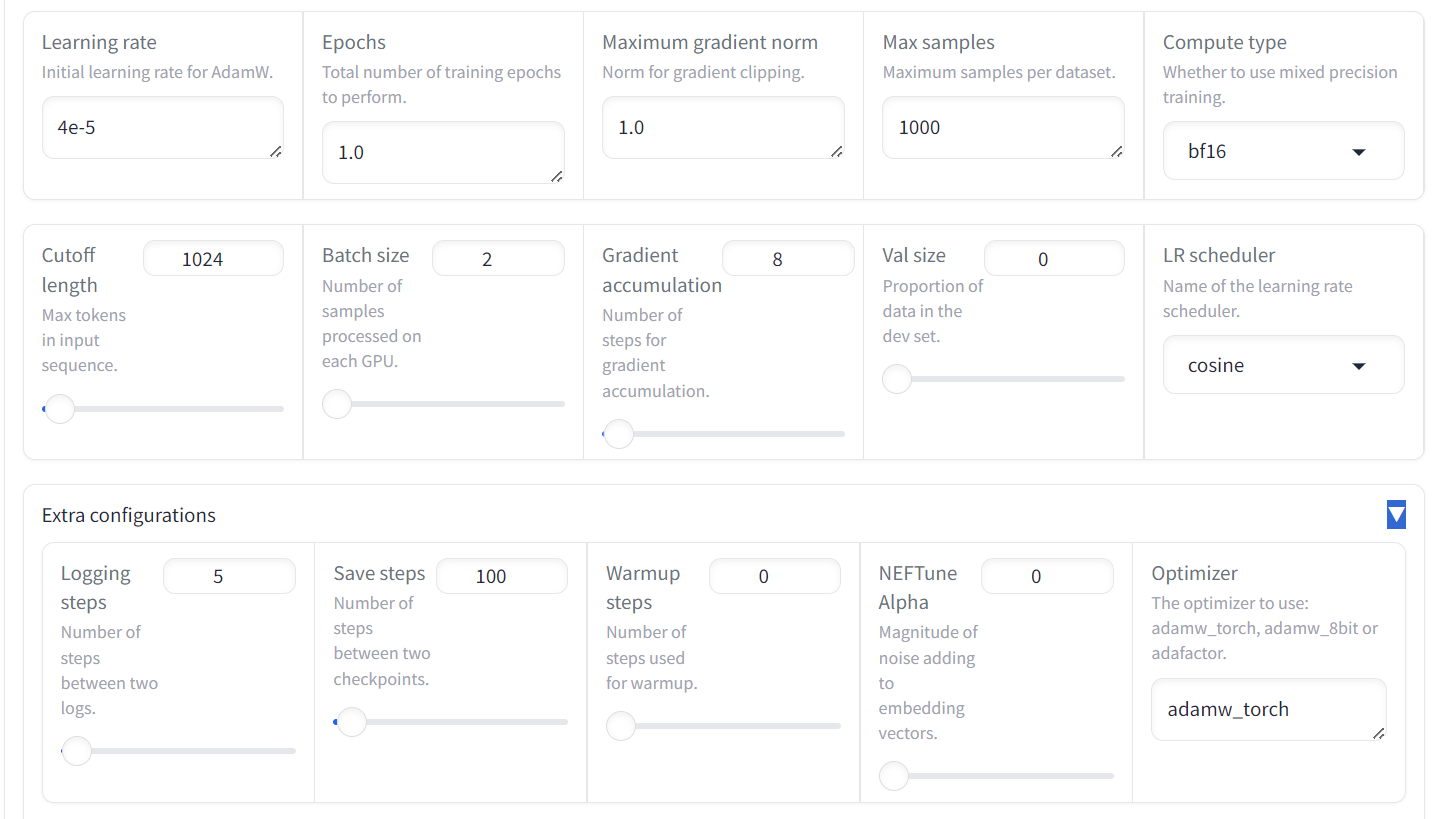
Também temos a opção de alterar o LoRa e outras configurações relacionadas à LoRa. Para este tutorial, manteremos todas as outras configurações em seus valores padrão.
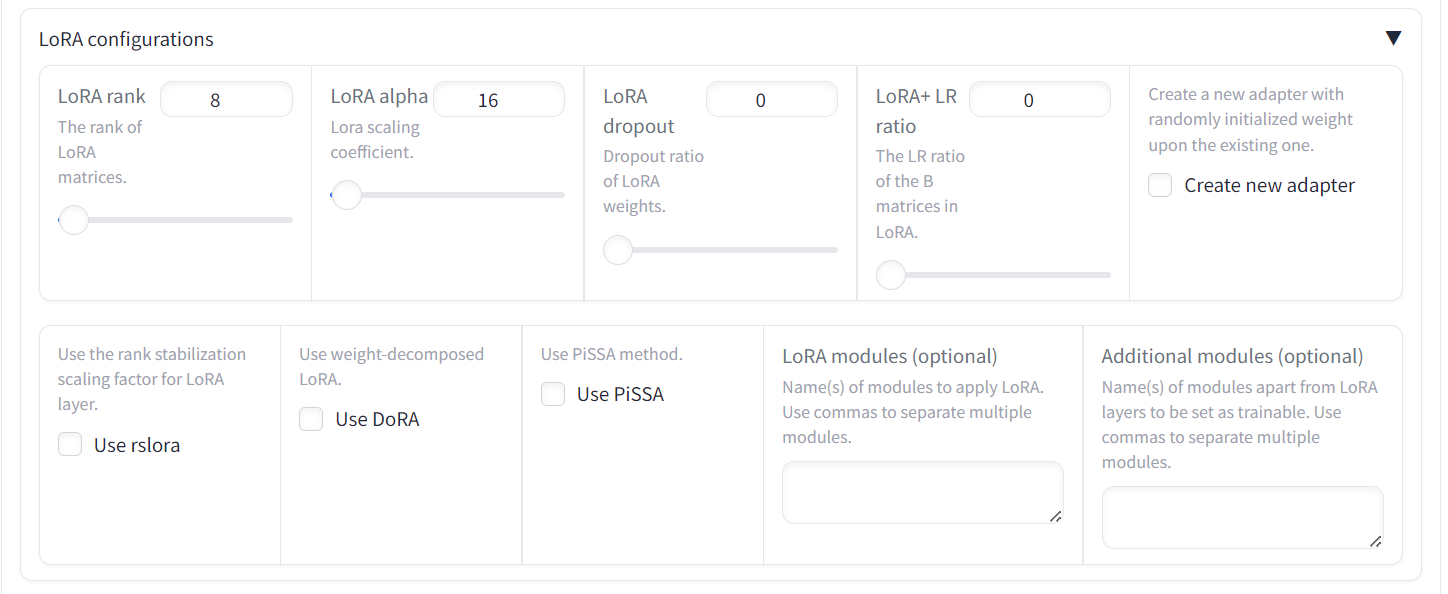
Role mais para baixo na página para ver a configuração do treinamento. Forneça o diretório de saída e o caminho de configuração e pressione o botão "Start" (Iniciar). O gráfico de perdas levará algum tempo para ser exibido, pois o LlaMA-Factor primeiro fará o download do modelo e do conjunto de dados e, em seguida, carregará ambos, o que pode levar pelo menos 5 minutos.
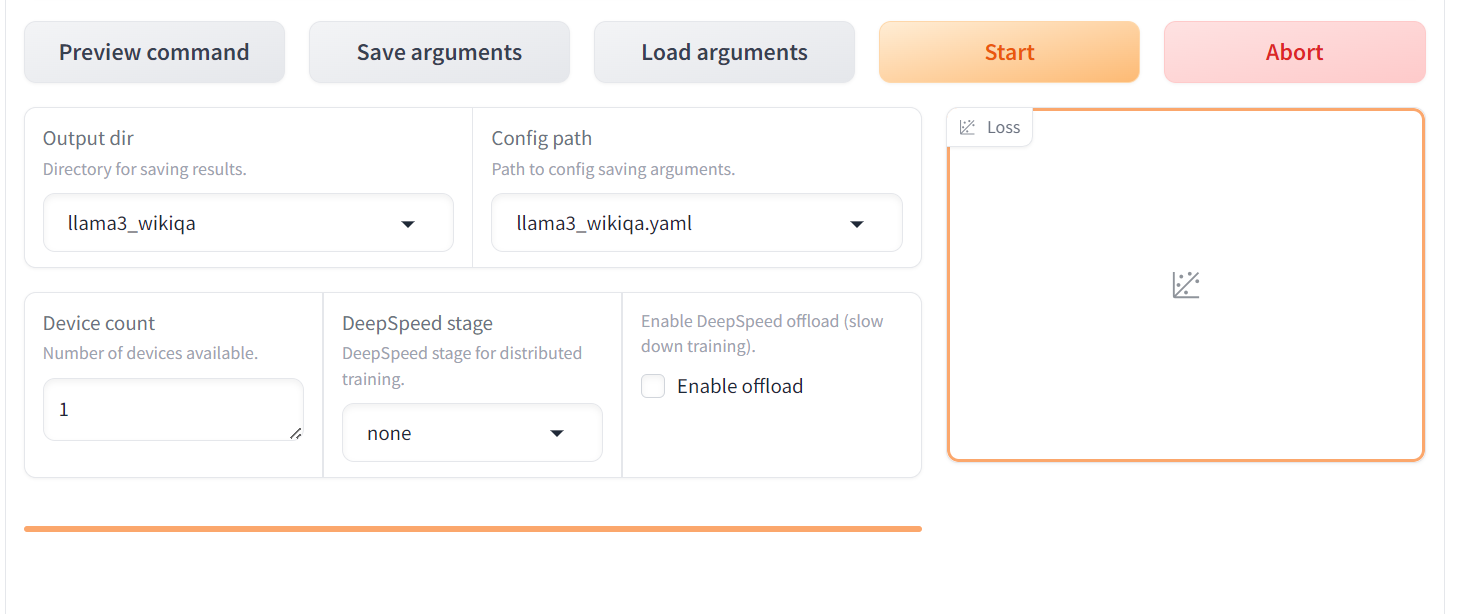
Quando o modelo estiver totalmente carregado e o treinamento for iniciado, você começará a ver visualizações no gráfico de perdas. Como podemos observar, a perda está diminuindo gradualmente com o número de etapas, o que é ótimo.
Quando o treinamento for concluído, você verá a mensagem de conclusão no canto inferior esquerdo. Como podemos observar, a perda foi reduzida gradualmente e atingiu um patamar após 45 etapas.
Se você for um cientista ou desenvolvedor de dados, será fácil ajustar seu modelo usando a linguagem Python.
Temos um guia detalhado para pessoas técnicas que desejam treinar o LlaMA-3 aqui: Ajuste fino do Llama 3 e seu uso local: Um guia passo a passo.
Para avaliar o modelo ajustado, precisamos mudar o menu de "Train" (Treinar) para "Chat" (Conversar). Em seguida, vá para "Caminho do ponto de verificação" e carregue o adotante ajustado salvo.
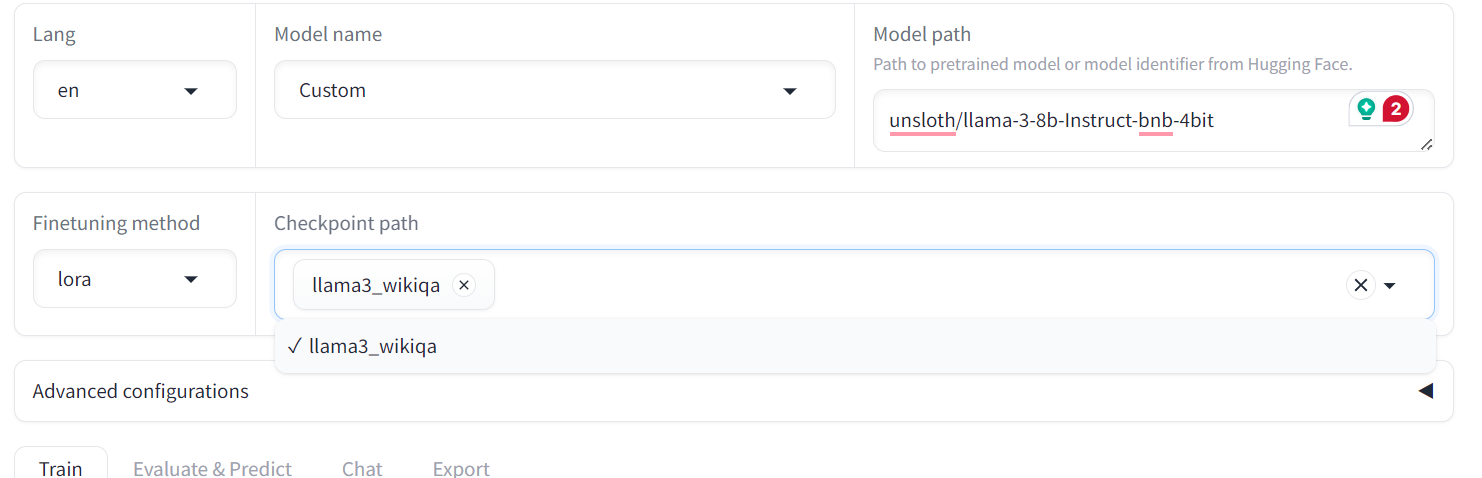
Depois disso, clique no botão "Load model" (Carregar modelo) e aguarde alguns segundos até que o modelo seja carregado com sucesso.
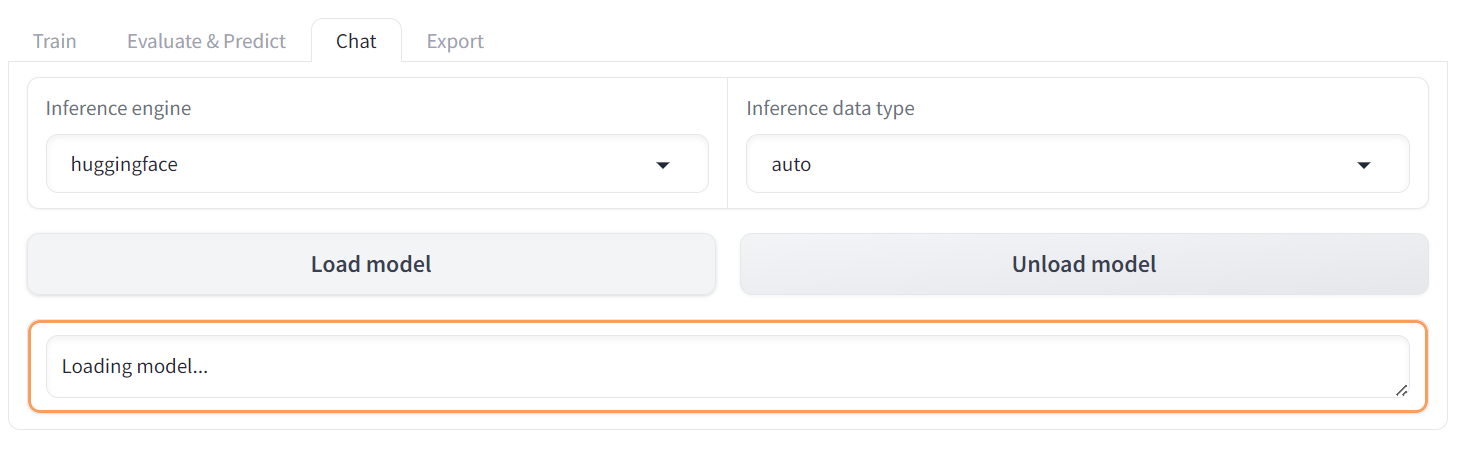
Role para baixo para ver a caixa de entrada do bate-papo e escreva uma pergunta geral sobre a cadeia de montanhas.
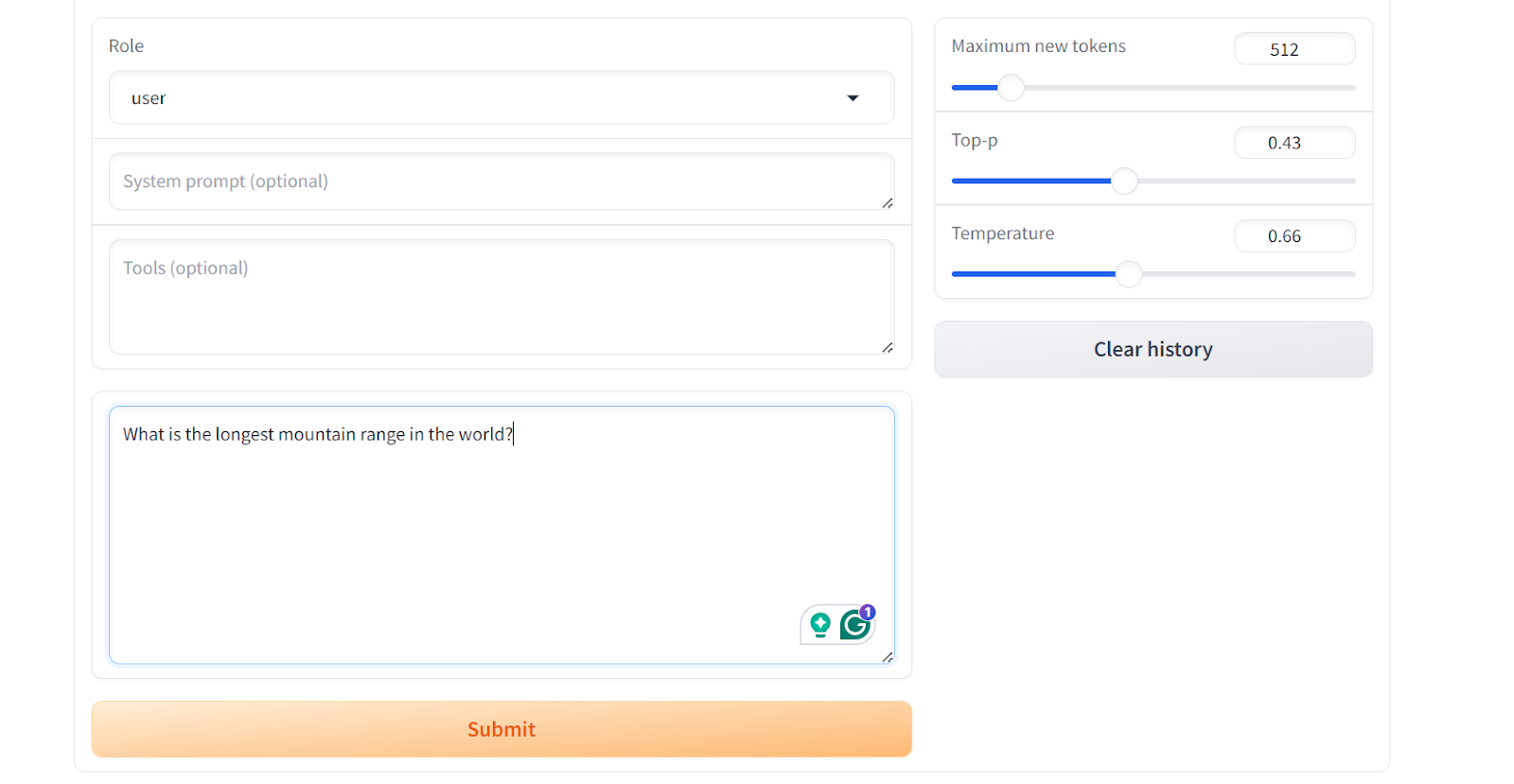
Como resultado, você obterá uma resposta simples e direta, semelhante ao conjunto de dados "wiki_qa".
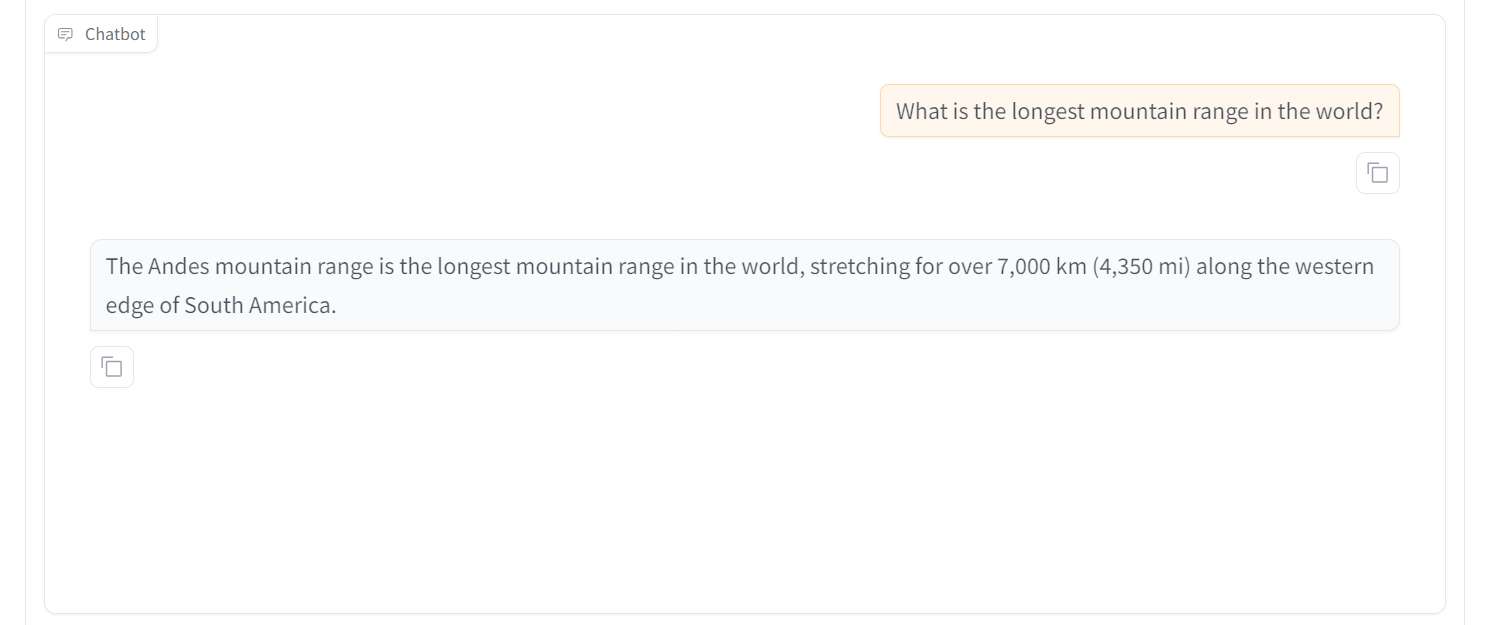
Vamos tentar fazer outra pergunta. Podemos ver que o modelo tem um desempenho excepcional. Em 30 minutos, fizemos o ajuste fino do modelo, o que levaria mais de 4 horas usando a biblioteca Transformer. Isso é incrível.
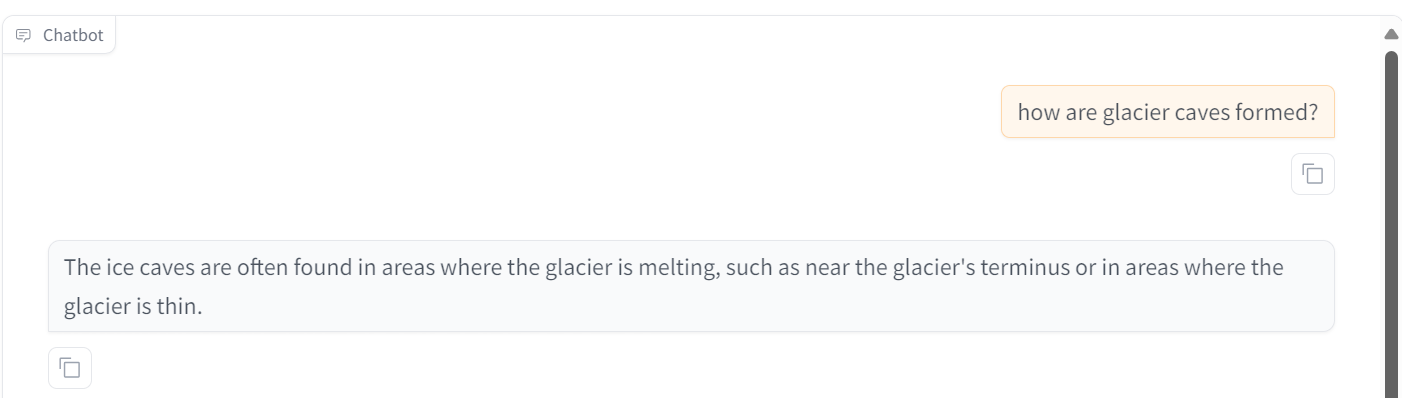
Às vezes, o ajuste fino não é a solução para todos os problemas do LLM. É por isso que você deve ler o site RAG vs Fine-Tuning: A Comprehensive Tutorial with Practical Examples e saiba o que funciona melhor para você.
Além dos modelos de ajuste fino e teste, o ecossistema LLaMA-Factory oferece vários recursos principais, incluindo o uso de dados personalizados para ajuste fino, fusão e exportação de modelos e implantação de modelos ajustados usando o VLLM.
Para adicionar um conjunto de dados personalizado, basta modificar o arquivo data/dataset_info.json e ele se tornará acessível na WebUI do LLaMA-Factory.
Para obter informações detalhadas sobre o formato necessário dos arquivos de conjunto de dados e como modificar o arquivo dataset_info.json, consulte o arquivo data/README.md que você pode consultar.
Você pode optar por usar conjuntos de dados dos hubs Hugging Face ou ModelScope, ou pode carregar o conjunto de dados do seu disco local.
Visualização do arquivo data/dataset_info.json
Você pode mesclar facilmente o adaptador LoRA ajustado com o modelo completo e exportá-lo para o Hugging Face Hub clicando na guia "Export".
Ajuste o tamanho máximo do fragmento, defina o caminho do diretório de exportação e especifique o ID do repositório do Hugging Face Hub e o dispositivo de exportação. O processo levará alguns minutos para que você mescle o modelo e carregue todos os arquivos do modelo no Hugging Face Hub.
Observação: A versão gratuita do Colab oferece apenas 12 GB de RAM, enquanto a fusão do LoRA de um modelo de 8 bilhões de parâmetros exige pelo menos 16 GB de RAM. Portanto, essa operação não pode ser realizada na versão gratuita do Colab.
Ao mesclar e enviar o modelo ajustado para o Hugging Face Hub, você pode fazer a fusão e a experiência.
O LlaMA-Factory é fornecido com a estrutura do vLLM para o serviço e a implementação de modelos. Ao digitar o seguinte comando, podemos servir o modelo Llama-3-8B-Instruct e acessá-lo por meio da API Python da OpenAI ou da RestAPI.
$ API_PORT=8000 llamafactory-cli api examples/inference/llama3_vllm.yamlVocê pode até mesmo modificar o arquivo ou criar seu próprio arquivo .yaml para servir seu modelo ajustado na produção. Tudo o que você precisa fazer é fornecer o caminho para a pasta do modelo localmente ou no Huggin Face Hub.
Fonte: hiyouga/LLaMA-Factory (github.com)
Se você estiver procurando uma solução low-code semelhante que permita o ajuste fino dos LLMs, especificamente o modelo proprietário GPT-4o, temos um guia abrangente para você. Confira nosso tutorial passo a passo aqui: Ajuste fino do GPT-4 da OpenAI: Um guia passo a passo.
A WebUI do LLaMA-Factory simplifica o processo para iniciantes e especialistas. Tudo o que você precisa fazer é ajustar alguns parâmetros para fazer o ajuste fino do modelo em um conjunto de dados personalizado. Usando a mesma interface de usuário, você pode testar o modelo e exportá-lo para o Hugging Face ou salvá-lo localmente. Isso permite que você implante o modelo em produção posteriormente usando o comando LLaMA-Factory CLI api. É muito simples.
Em vez de escrever centenas de linhas de código e solucionar problemas de ajuste fino, você pode obter resultados semelhantes com apenas alguns cliques.
Neste tutorial, aprendemos sobre a WebUI do LLaMA-Factory e como ajustar o modelo LLaMA-3-8B-Instruct em um conjunto de dados de perguntas e respostas da Wikipédia usando essa estrutura. Além disso, testamos o modelo ajustado usando o menu do chatbot integrado e exploramos os recursos adicionais oferecidos pelo LLaMA-Factory.
Saiba como fazer o ajuste fino dos LLMs usando Python, inscrevendo-se gratuitamente no próximo webinar Como ajustar seu próprio modelo Llama 3.
Principais cursos de LLM da DataCamp
Programa
Curso
Curso
blog
Abid Ali Awan
8 min
blog
Stanislav Karzhev
9 min
blog
Abid Ali Awan
8 min
blog
Nisha Arya Ahmed
12 min
Tutorial
Josep Ferrer
Tutorial
Zoumana Keita
