
Curso
Introdução a Deep Learning em Python
4 h
263.5K
A adoção maciça de ferramentas como o ChatGPT e outras ferramentas de IA generativa resultou em um grande debate sobre os benefícios e os desafios da IA e sobre como ela reformulará nossa sociedade. Para avaliar melhor essas questões, é importante saber como funcionam os chamados Modelos de Linguagem Grande (LLMs) que estão por trás das ferramentas de IA de última geração.
Este artigo apresenta uma introdução ao Reinforcement Learning from Human Feedback (RLHF), uma técnica inovadora que combina técnicas de aprendizado por reforço e orientação humana para ajudar LLMSs como o ChatGPT a fornecer resultados impressionantes. Abordaremos o que é RLHF, seus benefícios, limitações e sua relevância no desenvolvimento futuro do campo acelerado da IA generativa. Continue lendo!
Para entender o papel do RLHF, primeiro precisamos falar sobre o processo de treinamento dos LLMs.
A tecnologia subjacente dos LLMs mais populares é um transformador. Desde que foram desenvolvidos pelos pesquisadores do Google, os transformadores se tornaram o modelo de última geração no campo da IA e da aprendizagem profunda, pois oferecem um método mais eficaz para lidar com dados sequenciais, como as palavras em uma frase.
Para obter uma introdução mais detalhada sobre LLMs e transformadores, confira nosso Curso de Conceitos de Modelos de Linguagem Grande (LLMs).
Os Transformers são pré-treinados com um enorme corpus de texto coletado da Internet usando aprendizado autossupervisionado, um tipo inovador de treinamento que não exige ação humana para rotular os dados. Os transformadores pré-treinados são capazes de resolver uma grande variedade de problemas de processamento de linguagem natural (NLP).
No entanto, para que uma ferramenta de IA como o ChatGPT forneça respostas envolventes, precisas e semelhantes às humanas, usar um LLM pré-treinado não será suficiente. No final, a comunicação humana é um processo criativo e subjetivo. O que torna um texto "bom" é profundamente influenciado pelos valores e preferências humanos, o que torna muito difícil medir ou capturar usando uma solução algorítmica clara.
A ideia por trás do ELF é usar o feedback humano para medir e melhorar o desempenho do modelo. O que torna a RLHF única em comparação com outras técnicas de aprendizagem por reforço é o uso da participação humana para otimizar o modelo, em vez de uma função estatisticamente predefinida para maximizar a recompensa do agente.
Essa estratégia permite uma experiência de aprendizado mais adaptável e personalizada, tornando os LLMs adequados para todos os tipos de aplicações específicas do setor, como assistência a códigos, pesquisa jurídica, redação de ensaios e geração de poemas.
O RLHF é um processo desafiador que envolve um processo de treinamento com vários modelos e diferentes estágios de implantação. Em essência, ele pode ser dividido em três etapas diferentes.
O primeiro estágio envolve a seleção de um LLM pré-treinado que será posteriormente ajustado usando RLHF.
Você também pode fazer o pré-treinamento do seu LLM do zero, mas esse é um processo caro e demorado. Por isso, é altamente recomendável que você escolha um dos muitos LLMs pré-treinados disponíveis para o público.
Se você quiser saber mais sobre como treinar o LLM, nosso tutorial How to Train a LLM with PyTorch fornece um exemplo ilustrativo.
Observe que, para atender à necessidade específica do seu modelo, antes de iniciar a fase de ajuste fino usando feedback humano, você pode ajustar seu modelo em textos ou condições adicionais.
Por exemplo, se você quiser desenvolver um assistente jurídico de IA, poderá ajustar seu modelo com um corpus de texto jurídico para que seu LLM se familiarize especialmente com a redação e os conceitos jurídicos.
Em vez de usar um modelo de recompensa pré-definido estatisticamente (que seria muito restritivo para calibrar as preferências humanas), o RLHF usa o feedback humano para ajudar o modelo a desenvolver um modelo de recompensa mais sutil. O processo é o seguinte:
A imagem a seguir ilustra todo o processo:
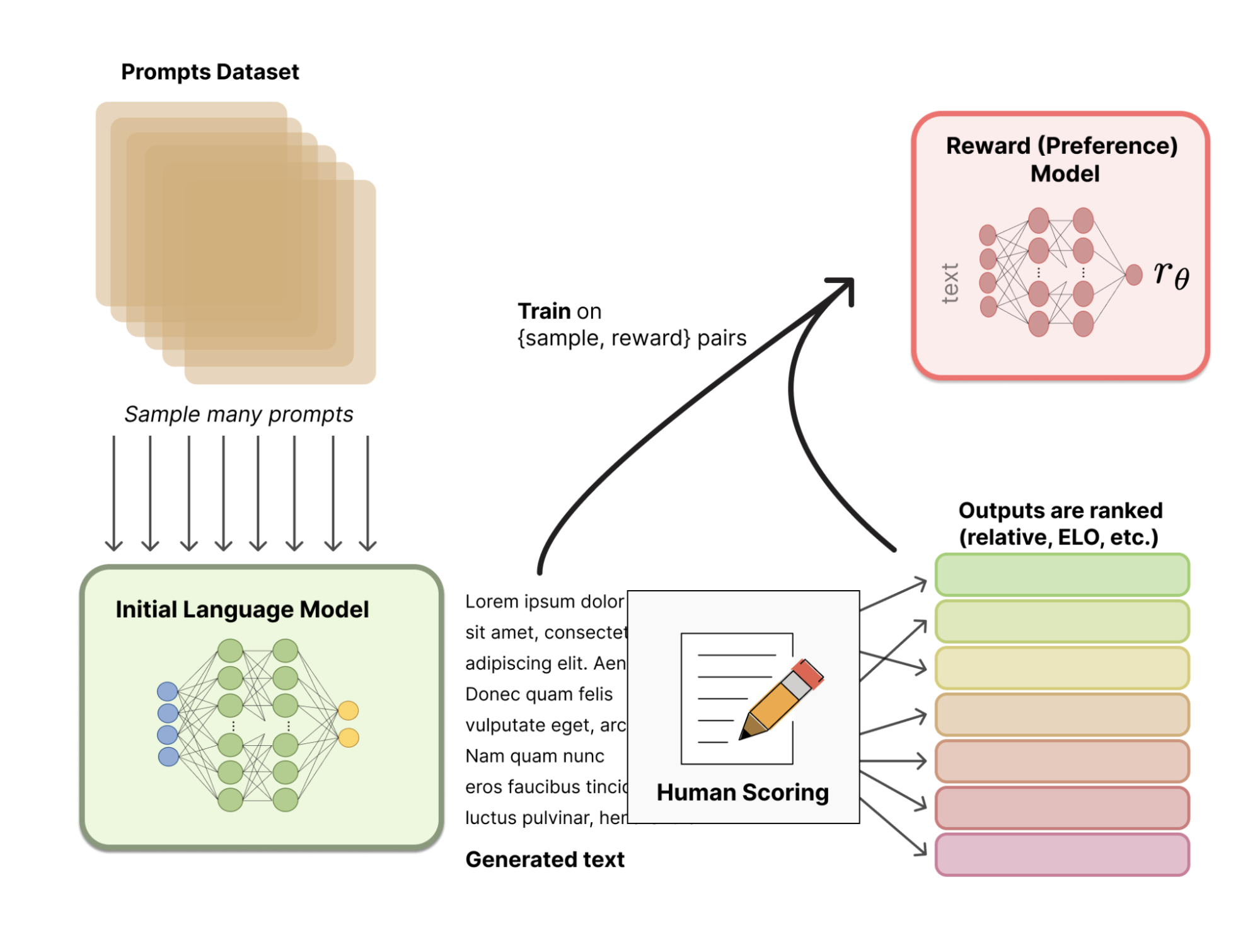
Fonte: Cara de abraço
No último estágio, o LLM produz novos textos e usa seu modelo de recompensa baseado em feedback humano para produzir uma pontuação de qualidade. A pontuação é então usada pelo modelo para melhorar seu desempenho nos prompts subsequentes.
O feedback humano e o ajuste fino com técnicas de aprendizagem por reforço são, portanto, combinados em um processo iterativo que continua até que um determinado grau de precisão seja alcançado.
O RLHF é uma técnica de última geração para fazer o ajuste fino dos LLMs, como o ChatGPT. No entanto, a RLHF é um tópico popular, com uma literatura crescente que explora outras possibilidades além dos problemas de PNL. Abaixo, você encontra uma lista de outras áreas em que o RLHF foi aplicado com sucesso:
A RLHF é uma técnica avançada e promissora sem a qual as ferramentas de IA de última geração não seriam possíveis. Aqui estão alguns dos benefícios do RLHF:
No entanto, o RLHF não é infalível. Essa técnica também apresenta certos riscos e limitações. Abaixo, você pode ver alguns dos mais relevantes:
O RLHF é um dos pilares das ferramentas modernas de IA generativa, como o ChatGPT e o GPT-4. Apesar de seus resultados impressionantes, a RLHF é uma técnica relativamente nova, e ainda há uma ampla margem para aprimoramento. Pesquisas futuras sobre técnicas de RLHF são essenciais para tornar os LLMs mais eficientes, reduzir sua pegada ambiental e abordar alguns dos riscos e limitações dos LLMs.
Para ficar por dentro dos últimos desenvolvimentos em IA generativa, aprendizado de máquina e LLMs, recomendamos que você confira nossos materiais de aprendizado selecionados:
Aprenda os tópicos mencionados neste artigo!
Curso
Curso
Curso