Programa
Engenheiro de dados Em Python
40 h
O cenário da arquitetura de dados está evoluindo, impulsionado pelo uso crescente de tecnologias de nuvem e pela adoção da pilha de dados moderna. Como resultado, os processos de ELT estão se tornando mais amplamente utilizados. Mas o que exatamente está envolvido nesse processo?
Neste artigo, exploraremos o ELT e sua função na arquitetura de dados avançada.
ELT significa Extract, Load, Transform (extrair, carregar, transformar). É um processo de integração de dados que envolve a extração de dados de várias fontes, o carregamento em um sistema de armazenamento de dados e a transformação em um formato que possa ser facilmente analisado.
O processo ELT é amplamente usado em arquitetura moderna de pilha de dados em que os dados são armazenados, transformados e analisados em um lago ou armazém de dados.
Como o próprio nome sugere, o ELT envolve três etapas principais: Extrair, carregar e transformar. Vamos examinar cada etapa com mais detalhes.
A primeira etapa do processo de ELT é extrair dados de várias fontes, como bancos de dados, arquivos, APIs ou serviços da Web. Isso pode ser feito usando ferramentas como o software ELT ou scripts personalizados escritos por desenvolvedores.
Alguns exemplos de plataformas de extração de dados são a Airbyte e a Fivetran. Para escrever scripts personalizados, Apache Spark e Python são amplamente utilizados.
Os dados extraídos podem ser estruturados, semiestruturados ou não estruturados e podem vir de diferentes tipos de sistemas, como bancos de dados relacionais, bancos de dados NoSQLou armazenamento em nuvem.
Depois que os dados são extraídos, eles são carregados em um sistema de armazenamento de dados centralizado, como um data lake ou um armazém de dados. Essa etapa envolve a organização e o armazenamento dos dados extraídos em seu formato bruto, sem nenhuma transformação.
Normalmente, os engenheiros de dados estão envolvidos nessa etapa, em que carregam os dados para plataformas como:
Essas plataformas de dados permitem o carregamento rápido de grandes quantidades de dados e fornecem uma única fonte de verdade para todos os diferentes tipos de dados coletados de várias fontes.
A etapa final do processo ELT é transformar os dados brutos em um formato otimizado para análise e geração de relatórios. Isso envolve a limpeza, a filtragem, a agregação e a estruturação dos dados de forma adequada para que as ferramentas de business intelligence e análise possam trabalhar com eles.
Os engenheiros de dados ou cientistas de dados geralmente são responsáveis por essa etapa e podem usar ferramentas como:
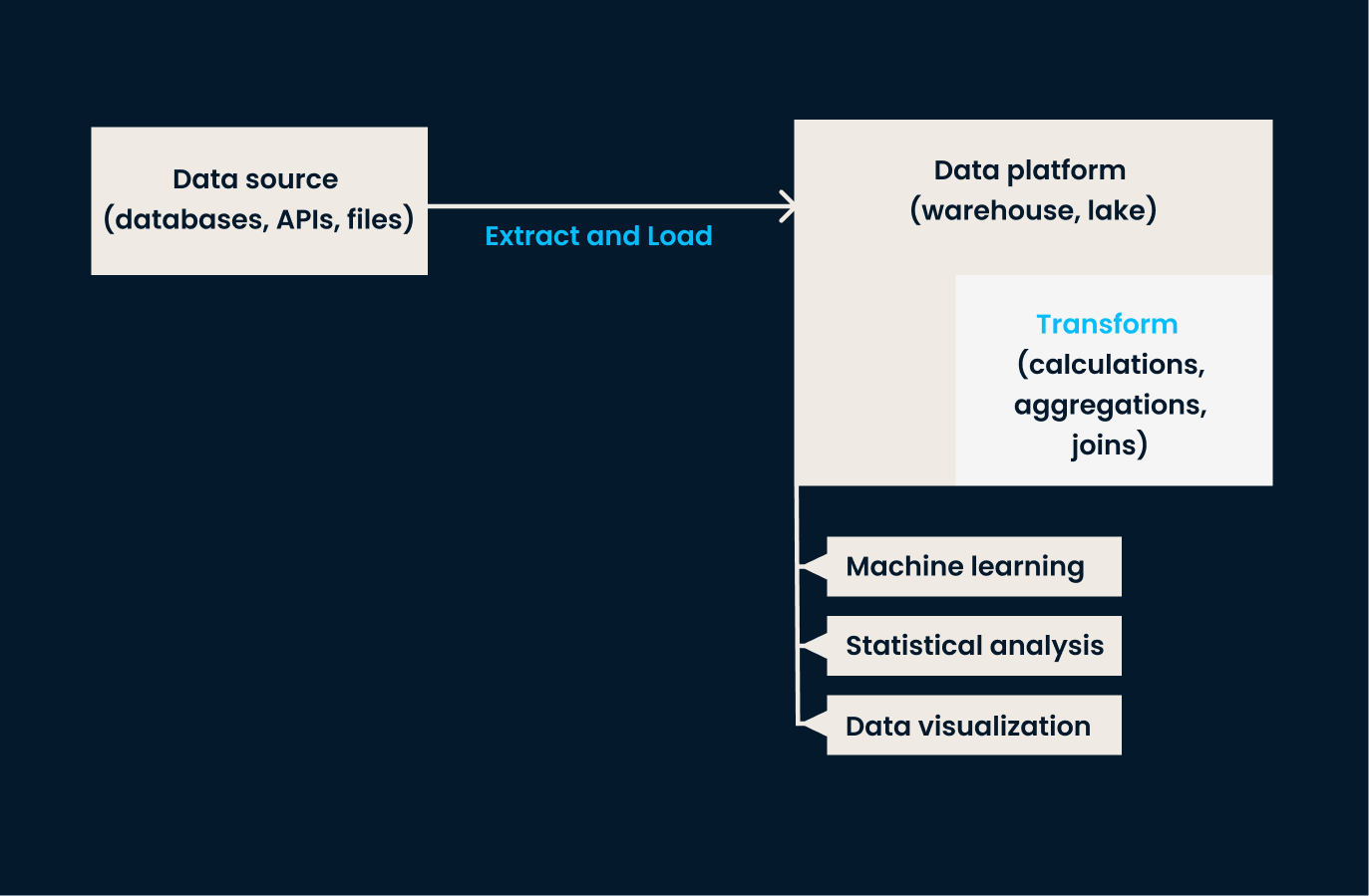
Pipeline de dados ELT: As fases de extração e carregamento ocorrem antes que qualquer transformação seja aplicada aos dados. A etapa de transformação é realizada na plataforma de dados.
A transformação de dados é feita dentro do data warehouse ou do data lake, o que permite o manuseio mais fácil de grandes volumes de dados. Com as modernas tecnologias de nuvemesse processo pode ser feito quase em tempo real, proporcionando às organizações acesso a dados novos e precisos para análise.
Você quer saber mais sobre como usar Python para ELT? O curso ETL e ELT no curso Python pode ser exatamente o que você precisa.
A ELT traz muitos benefícios, e aqui estão alguns notáveis:
Vamos agora comparar as diferenças entre ELT e ETL.
Conforme mencionado anteriormente, o ELT é uma abordagem mais recente para o processamento de dados, em que os dados são carregados primeiro em um repositório central, permitindo que as transformações ocorram após o carregamento.
Por outro lado, ETL (Extract, Transform, Load) é uma metodologia tradicional na qual os dados são transformados antes de serem carregados no sistema de destino. Essas diferenças fundamentais afetam não apenas o processo, mas também a velocidade, os custos e a segurança.
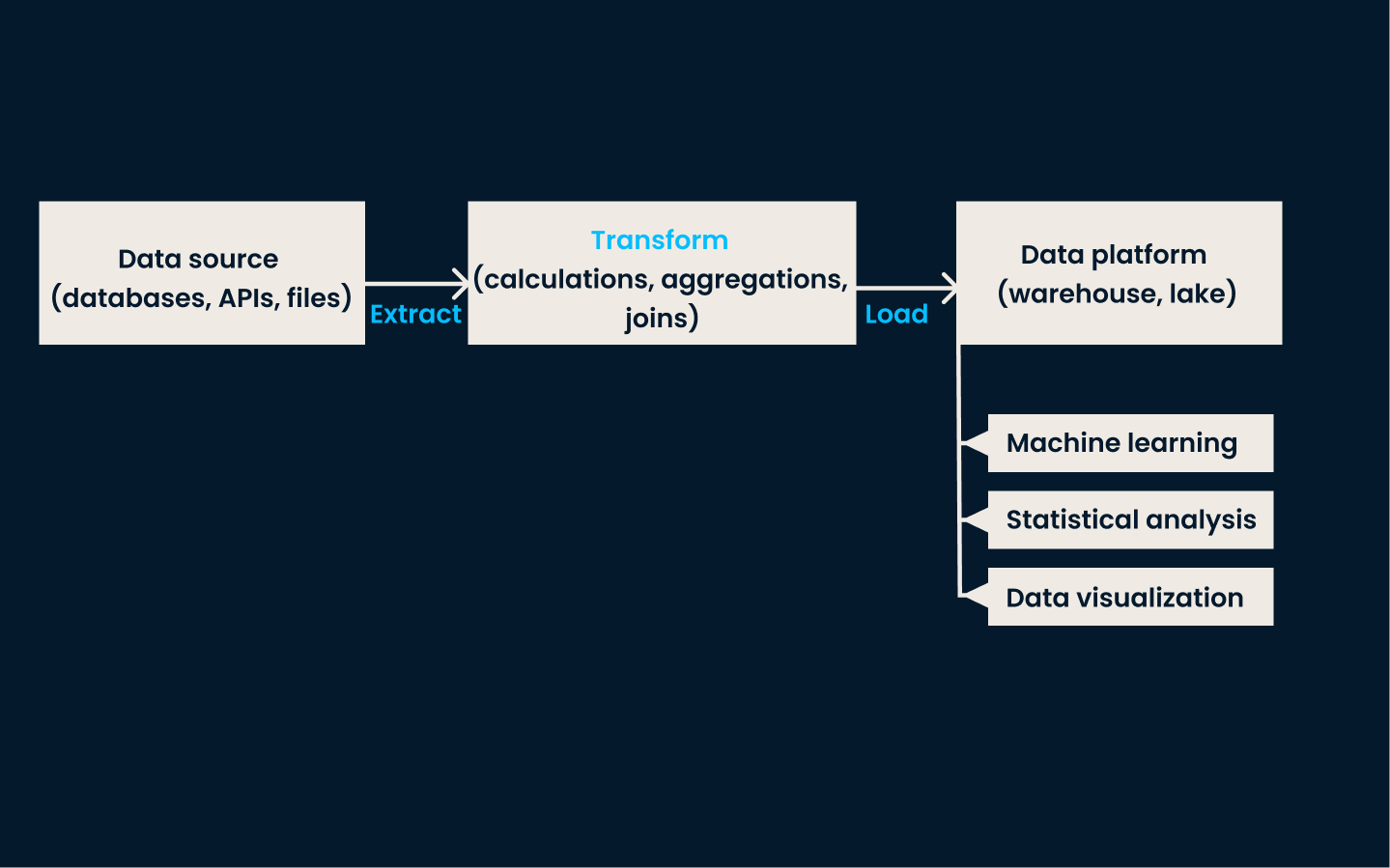
Pipeline de ETL: A etapa de transformação ocorre antes de carregar os dados em uma plataforma de destino. Normalmente, a transformação ocorre em um servidor separado, e não na própria plataforma de dados.
A ELT segue a abordagem "carregar primeiro, transformar depois", em que os dados são carregados em um sistema de armazenamento em sua forma bruta e, em seguida, transformados para análise.
Por outro lado, a ETL segue uma abordagem de "extração-transformação-carregamento", em que os dados são extraídos de várias fontes, transformados e, por fim, carregados em um data warehouse.
A abordagem ELT é conhecida por sua maior velocidade de processamento de dados, pois elimina a necessidade de uma área de preparação intermediária. Isso permite a análise de dados em tempo real ou análise de dados em tempo real ou quase real.
Por outro lado, o ETL pode levar mais tempo devido às várias etapas envolvidas na transformação e no carregamento dos dados.
Além disso, o ELT elimina a necessidade de um software ETL caro, pois as transformações podem ser feitas usando consultas SQL ou outras ferramentas de código aberto.
Em contrapartida, os processos tradicionais de ETL tendem a se adequar melhor à infraestrutura local, onde as fontes de dados são limitadas e os recursos de hardware são menos dimensionáveis do que em ambientes baseados em nuvem. A infraestrutura local geralmente tem custos mais altos do que a infraestrutura em nuvem.
Por fim, o ELT permite a criptografia e o mascaramento de dados de informações de identificação pessoal (PII) durante o processo de carregamento, pois isso é feito em um repositório central seguro.
Os processos de ETL devem garantir a segurança dos dados durante todo o processo de extração e transformação. No entanto, isso é difícil, pois os dados precisam ser movidos para um armazenamento de preparação adicional e geralmente são processados em servidores separados.
Com sua velocidade de processamento de dados mais rápida e análise de computação em nuvem, o processo ELT tem visto alguns casos de uso em que se destaca em comparação com o ETL.
Aqui estão alguns usos comuns do processo ELT:
Há várias ferramentas e tecnologias disponíveis para que as organizações implementem processos de ELT. Isso inclui:
Na etapa de carregamento do processo ELT, os data lakes e os data warehouses são essenciais para fornecer um espaço de armazenamento de dados centralizado em uma empresa.
Aqui estão as plataformas de dados em nuvem mais populares:
Muitas organizações também aproveitam as ferramentas de código aberto para seus processos de ELT por sua relação custo-benefício.
Essas ferramentas podem ajudar em diferentes estágios do processo de ELT:
As ferramentas de código aberto são uma excelente combinação para os processos de ELT porque oferecem flexibilidade, suporte ao desenvolvedor e muitas opções de integração.
Os desenvolvedores também podem optar por usar scripts criados com linguagens de programação para aumentar a capacidade de personalização. Isso tende a envolver o uso de pacotes e bibliotecas para processar e transformar dados.
Algumas linguagens de programação comuns usadas para esses scripts incluem:
Concluindo, o ELT é uma tendência nova e emergente no processamento de dados que oferece muitas vantagens em relação aos métodos tradicionais de ETL. Ele permite uma transformação de dados mais rápida e eficiente e oferece maior flexibilidade e escalabilidade.
Se estiver pensando em aprender mais sobre ELT ou outros conceitos de engenharia de dados, você pode gostar da nossa Certificação de engenheiro de dados ou nosso Programa de carreira de engenheiro de dados em Python.
Saiba mais sobre engenharia e processamento de dados com estes cursos!
Programa
Curso
Curso
blog
DataCamp Team
12 min
blog
Javier Canales Luna
14 min
Tutorial
Kurtis Pykes
