course
Intermediate Python
4 oră
1.4M
Pentru a-ți demonstra înțelegerea structurilor de date de bază, trebuie să fii foarte sigur pe structurile de bază și implementările lor. Întrebări precum cele de mai jos îți vor testa abilitatea de a explica aceste idei și îți vor evidenția cunoștințele.
Structurile de date sunt clasificate astfel:
Array-urile și listele înlănțuite sunt două moduri de a stoca grupuri de elemente, dar funcționează diferit. Iată principalele diferențe:
Un stack este o listă ordonată în care adaugi și elimini elemente la un singur capăt, numit vârf (top). Urmează principiul last-in-first-out (LIFO): elementul adăugat cel mai recent este primul eliminat.
Stack-urile pot fi folosite în mai multe aplicații, precum evaluarea expresiilor, backtracking, managementul memoriei și apeluri și returnări de funcții.
În Python, o listă funcționează ca un stack din start: append() este push, iar pop() elimină elementul din vârf.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Păstrând poziția vârfului cu un index, poți face aceste operații rapide și eficiente.
O coadă este o structură first-in, first-out (FIFO) — ca o coadă la magazin, unde oamenii intră la final și ies din față.
În Python, poți implementa o coadă folosind tehnici diferite:
Folosind un array sau o listă și metodele append() și pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Folosind deque() din biblioteca collections, care execută funcțiile append() și pop() mai rapid decât listele:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Folosind modulul încorporat queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Un arbore binar este o structură de date în care fiecare nod are cel mult doi copii: un copil stâng și unul drept. Apoi, un arbore de căutare binară (BST) este un tip specific de arbore binar care are proprietăți de ordonare distincte: Pentru fiecare nod, toate cheile din subarborele stâng sunt mai mici, toate cheile din subarborele drept sunt mai mari, iar ambele subarbori sunt la rândul lor BST-uri.
Aceste proprietăți facilitează operații eficiente precum căutarea, inserarea și ștergerea, atingând de obicei o complexitate de timp O(log n) în arbori echilibrați.
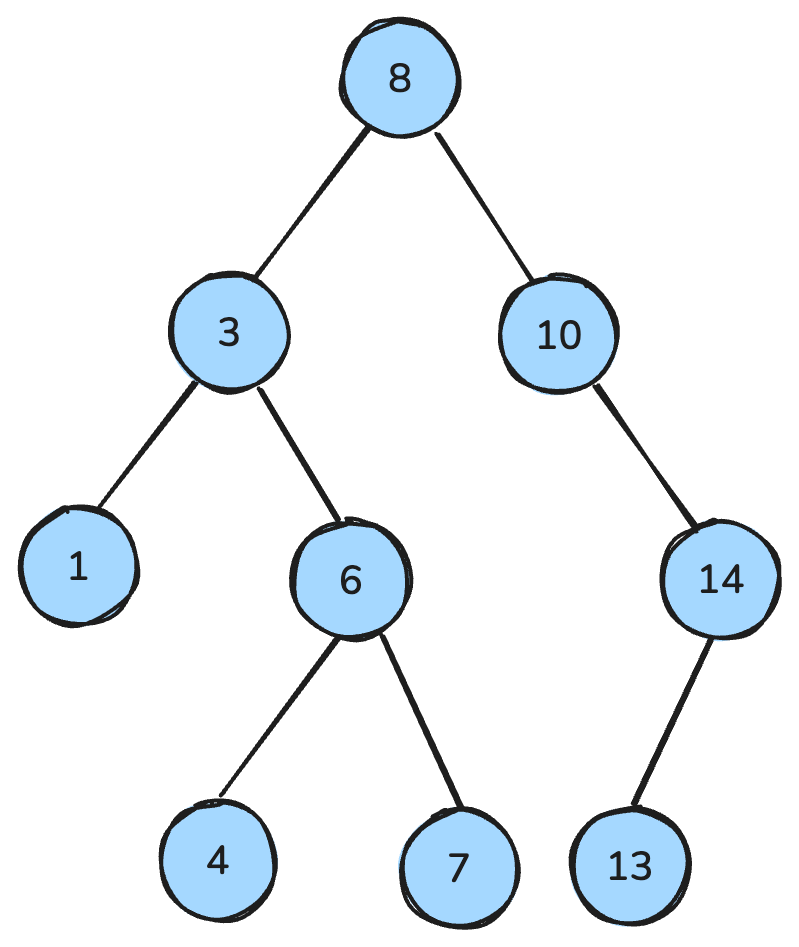
Arbore de căutare binară. Imagine de autor.
Hashing-ul este o tehnică ce preia date de orice dimensiune și le transformă într-o valoare de dimensiune fixă numită valoare hash folosind o funcție de hash.
O utilizare frecventă a hashing-ului este în tabelele de dispersie (hash tables), unde ajută la asocierea cheilor cu locații specifice într-un array, facilitând găsirea și regăsirea rapidă a datelor. Hashing-ul poate avea multe aplicații, de la securizarea parolelor în criptografie până la menținerea datelor organizate prin deduplicare.
Un heap este o structură de date asemănătoare unui arbore și urmează reguli speciale.
Într-un max-heap, fiecare părinte este mai mare sau egal cu copiii săi; într-un min-heap, fiecare părinte este mai mic sau egal cu copiii săi.
Heap-urile sunt adesea folosite pentru a crea cozi cu priorități (priority queues), care ajută la ordonarea elementelor în funcție de importanță sau valoare. Sunt importante și pentru heap sort, o metodă de organizare eficientă a datelor.
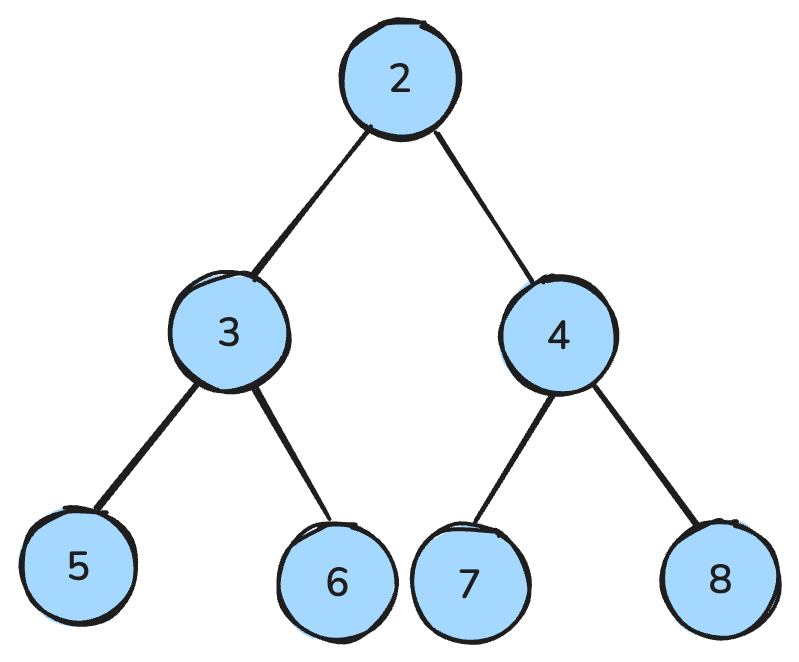
Un min-heap este acolo unde toți părinții sunt mai mici decât copiii — imagine de autor.
După ce am acoperit elementele de bază, să trecem la câteva întrebări la nivel intermediar care îți explorează competența tehnică în implementarea și utilizarea acestor concepte fundamentale.
Un arbore de căutare binară echilibrat menține o înălțime relativ egală între subarborii stâng și drept. Echilibrarea unui BST este foarte importantă pentru a păstra eficiente operațiile de căutare, inserare și ștergere.
Tehnici precum arborii AVL și arborii roșu-negru sunt folosite frecvent pentru a obține auto-echilibrarea. Arborii AVL mențin o diferență de înălțime de cel mult 1 între subarborii stâng și drept ai oricărui nod, în timp ce arborii roșu-negru au constrângeri de echilibru mai stricte.
Un min-heap este de obicei susținut de o listă. Cele două operații cheie sunt insert (care adaugă un element și îl urcă pentru a restabili proprietatea de heap) și extract_min (care elimină rădăcina și coboară pentru a restabili ordinea):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valUn trie, cunoscut și ca arbore de prefixe, este o structură de date bazată pe arbori, proiectată pentru regăsirea eficientă a șirurilor și potrivirea prefixelor.
Într-un trie, fiecare nod reprezintă un singur caracter, iar căile de la rădăcină la noduri corespund unor șiruri complete. Trie-urile sunt folosite frecvent în aplicații precum funcțiile de completare automată, instrumente de verificare ortografică și implementarea dicționarelor.
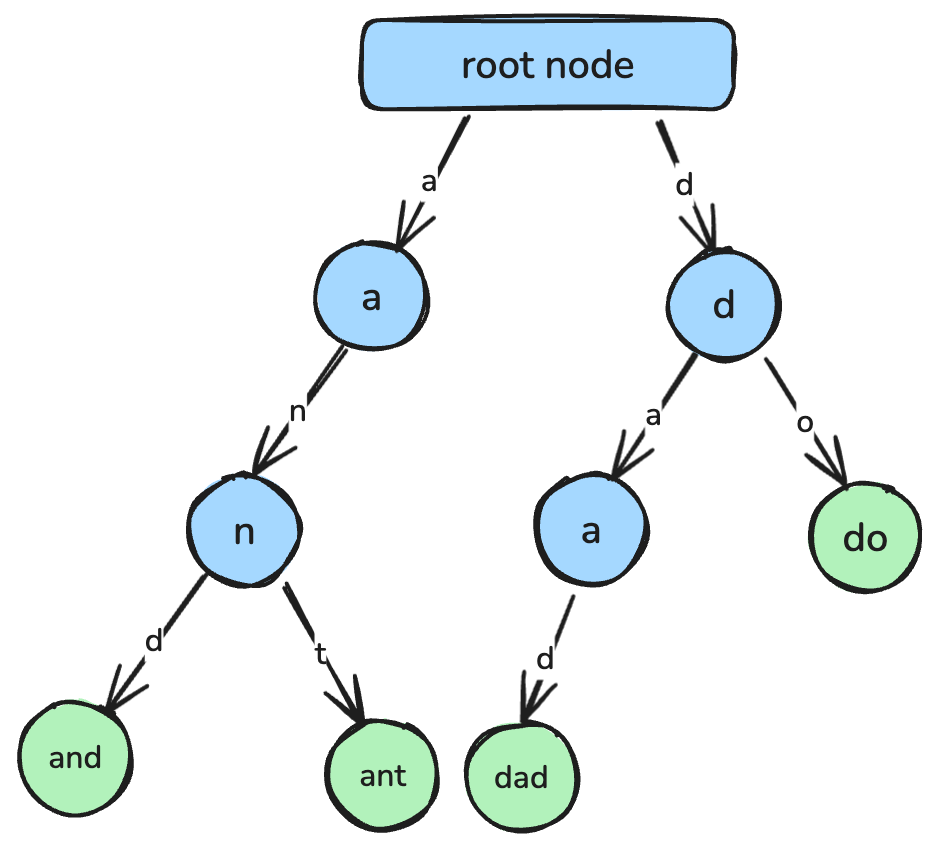
Un trie, unde fiecare nod reprezintă un singur caracter care se conectează pentru a forma un șir. Imagine de autor.
O coliziune apare atunci când două chei diferite au același index rezultat din funcția de hash.
Există mai multe metode de rezolvare a coliziunilor, inclusiv chaining (lanțuri), unde elementele care colizionează sunt stocate într-o listă înlănțuită la indexul corespunzător, și adresarea deschisă (open addressing), care presupune găsirea următorului slot disponibil în array prin metode de sondare precum sondare liniară, sondare pătratică sau double hashing.
Un graf este o structură de date formată dintr-o colecție de vârfuri (noduri) interconectate prin muchii. Această structură este utilă pentru a ilustra relațiile și conexiunile dintre diverse entități.
Căutarea în adâncime (DFS) este un algoritm care explorează un graf sau arbore coborând adânc pe fiecare ramură înainte de a reveni. Poate fi implementat folosind un stack explicit sau recursiv. Complexitatea de timp este O(V + E), unde V este numărul de vârfuri și E este numărul de muchii, ceea ce înseamnă că poate fi nevoie să examineze toate vârfurile și muchiile.
Căutarea în lățime (BFS) explorează sistematic toți nodurile la nivelul de adâncime curent înainte de a trece la următorul nivel. Este eficientă pentru găsirea celui mai scurt drum în grafuri neponderate și este de obicei implementată cu o coadă. La fel ca DFS, BFS are o complexitate de timp O(V + E), necesitând parcurgerea tuturor vârfurilor și muchiilor.
Algoritmii de sortare sunt esențiali pentru procesarea eficientă a datelor — permit căutări mai rapide, analize mai bune și vizualizare mai ușoară a datelor. Când alegi între ei, sunt câteva compromisuri cheie de avut în vedere:
Iată implementări curate în Python pentru fiecare:
# Bubble sort — sortează in-place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sortează in-place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returnează o listă nouă sortată
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sortează nums in-place
quick_sort(nums, 0, len(nums) - 1) # tot in-place
sorted_nums = merge_sort(nums) # returnează o listă nouăLa un interviu, răspunsul de mai sus este suficient. Dar dacă vrei să ieși în evidență, menționează că funcțiile integrate din Python sorted() și list.sort() folosesc Timsort, un hibrid între merge sort și insertion sort. De aceea, aproape niciodată nu scrii o sortare de la zero în Python de producție.
Mai mulți algoritmi pot fi folosiți pentru a găsi cel mai scurt drum în grafuri.
Pentru grafuri neponderate, căutarea în lățime explorează eficient nodurile strat cu strat. În grafuri ponderate cu muchii nenegative, algoritmul lui Dijkstra identifică cel mai scurt drum examinând mai întâi vârful cel mai apropiat.
Algoritmul A* îmbunătățește eficiența folosind euristici pentru a estima costurile rămase. Alegerea algoritmului depinde de caracteristicile grafului și de cerințele specifice ale problemei.
Să explorăm câteva întrebări avansate pentru cei care vizează roluri mai senior sau doresc să demonstreze o cunoaștere profundă a structurilor de date specializate sau complexe.
Programarea dinamică este o metodă folosită pentru a rezolva probleme complexe împărțindu-le în subprobleme mai mici care se suprapun. În loc să începi de la zero de fiecare dată, păstrezi soluțiile pentru acele părți mai mici, astfel încât nu trebuie să refaci aceleași calcule în mod repetat.
Această metodă este foarte utilă pentru a găsi cel mai lung subșir comun între două șiruri sau pentru a găsi costul minim de a ajunge într-un anumit punct pe o grilă.
B-tree-urile sunt structuri de date de tip arbore echilibrat, proiectate pentru acces eficient la disc. Câteva dintre caracteristicile lor sunt:
Oferă mai multe avantaje față de arborii de căutare binară:
Sortarea topologică este un algoritm folosit pentru ordonarea vârfurilor unui graf direcționat aciclic (DAG) astfel încât, dacă există o muchie de la vârful u la vârful v, atunci u apare înaintea lui v în ordine. Este folosită frecvent la programarea sarcinilor — stabilirea ordinii în care trebuie rulate sarcinile pentru a respecta dependențele — și în sisteme de build, manageri de pachete și planificarea prerechizitelor pentru cursuri.
Un min-heap este o implementare specifică a unei cozi cu priorități și este definit ca un arbore binar complet în care valoarea fiecărui nod este mai mică sau egală cu valorile copiilor săi, permițând operații eficiente pentru găsirea și extragerea elementului minim.
Pe de altă parte, o coadă cu priorități este o structură de date abstractă ce permite inserarea de elemente cu o prioritate asociată, iar elementele sunt extrase în ordinea priorității lor. Min-heap-urile sunt o modalitate comună de a implementa cozile cu priorități datorită capacității lor de a gestiona eficient aceste operații.
O structură de date mulțimi disjuncte, cunoscută și ca structură union-find, menține o colecție de mulțimi disjuncte. Această structură de date suportă două operații principale:
Există multe aplicații ale mulțimilor disjuncte, dar cele mai comune sunt algoritmul lui Kruskal pentru găsirea arborelui parțial de cost minim al unui graf și problema fluxului în rețea pentru determinarea componentelor conexe dintr-un graf.
Un segment tree este o structură de date concepută pentru a facilita interogări și actualizări eficiente pe intervale într-un array. Este deosebit de utilă în scenarii în care avem nevoie să efectuăm repetat operații precum găsirea sumei, minimului, maximului sau a celui mai mare divizor comun pe un interval specific de elemente din array.
Este construit ca un arbore binar, unde fiecare nod reprezintă un segment al array-ului. Frunzele arborelui corespund elementelor individuale ale array-ului, în timp ce nodurile interne stochează informații care agregă valorile nodurilor copil conform operației efectuate. Atinge O(log n) pentru atât actualizări, cât și interogări.
Un arbore de sufixe stochează fiecare sufix al unui șir astfel încât interogările de tip pattern să poată fi răspunse în timp proporțional cu lungimea patternului, nu cu lungimea textului. Un arbore de sufixe veritabil folosește comprimarea muchiilor pentru a obține spațiu O(n) și este construit de obicei cu algoritmul lui Ukkonen — dar asta e suficient de complex încât intervievatorii rareori se așteaptă să îl codezi de la zero în 45 de minute.
Un compromis comun este trie-ul de sufixe, mai simplu, care stochează un caracter per nod. Folosește spațiu O(n²), dar este mult mai ușor de scris și explicat. Șmecheria la interviu este să cunoști acest compromis și să îl enunți explicit.
Iată o implementare curată în Python:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesQuadtrees sunt o structură ierarhică de tip arbore care subdivide în mod recursiv un spațiu bidimensional în patru cadrane egale. Această tehnică de partiționare spațială este foarte eficientă pentru aplicații precum procesarea imaginilor, detectarea coliziunilor în jocuri și sistemele de informații geografice pentru stocarea și regăsirea eficientă a datelor spațiale.
Demonstrarea cunoașterii structurilor de date este importantă, dar să arăți că știi când să le folosești corect te va face să ieși în evidență la interviu. În această secțiune, vom analiza cum să aplici cunoștințele despre structuri de date în situații practice.
Datorită naturii în timp real a problemei, această provocare va necesita structuri de date eficiente.
Din experiența mea, aș folosi quadtrees pentru datele geografice, cozi cu priorități pentru a clasa potrivirile potențiale în funcție de distanță și urgența pasagerului și tabele de dispersie pentru căutări eficiente ale locațiilor șoferilor și pasagerilor.
Putem valorifica o combinație de structuri de date pentru a recomanda eficient produse pe baza comportamentului utilizatorilor.
O matrice rară utilizator–produs ar stoca interacțiunile utilizator–produs, în timp ce tabelele de dispersie ar mapa eficient utilizatorii și produsele. Cozile cu priorități ar clasa recomandările, iar structurile de tip graf ar putea modela relațiile utilizator–produs pentru analize mai sofisticate, precum detectarea comunităților.
O structură de date de tip graf poate fi foarte eficientă pentru detectarea și eliminarea conturilor de spam pe o platformă de socializare. Poți analiza topologia rețelei reprezentând utilizatorii ca noduri și conexiunile lor ca muchii. Identificarea clusterelor dens conectate, a nodurilor izolate și a creșterilor bruște de activitate poate ajuta la semnalarea conturilor suspecte.
Aș folosi o combinație de structuri de date într-o aplicație de chat în timp real.
Tabele de dispersie ar stoca ID-urile utilizatorilor și listele corespunzătoare de conexiuni, permițând căutări rapide ale utilizatorilor cărora să le trimiți mesaje. Cozi ar fi implementate pentru fiecare utilizator pentru a menține ordinea mesajelor, asigurând livrarea în secvența în care au fost trimise. În plus, arbori, cum ar fi arborii AVL, ar putea fi folosiți pentru a stoca și regăsi eficient statusul online/offline al utilizatorilor, permițând actualizări în timp real ale disponibilității.
Pentru un corector ortografic, căutarea eficientă a cuvintelor este foarte importantă. Un trie ar fi o structură de date ideală. Fiecare nod din trie ar reprezenta o literă, iar căile prin trie ar forma cuvinte. Acest lucru permite căutări rapide bazate pe prefixe, permițând corectorului să sugereze rapid corecții pentru cuvintele greșite.
În acest scenariu, segment tree-urile se remarcă drept o alegere excelentă. Sunt foarte bune la gestionarea eficientă a interogărilor pe intervale și a actualizărilor. Putem reprezenta harta jocului ca un array 1D, unde fiecare element corespunde unei celule din grilă. Fiecare celulă poate stoca informații despre prezența sau absența unei structuri.
Știu că pregătirea pentru un interviu pe structuri de date poate fi provocatoare, dar o abordare structurată te poate ajuta să o faci mai gestionabilă!
Concentrează-te pe stăpânirea conceptelor fundamentale din spatele structurilor de date, precum array-uri, liste înlănțuite, stive (stacks), cozi (queues), arbori, grafuri și tabele de dispersie. Înțelege-le principiile, cum gestionează datele și complexitățile de timp asociate operațiilor precum inserare, ștergere și căutare.
Să cunoști conceptele e bine, dar nu e suficient. Ar trebui să știi cum să implementezi aceste structuri de date de la zero. Poți participa la cursurile DataCamp pentru a profita de provocări de cod care îți ascut abilitățile de rezolvare a problemelor.
Înțelegerea compromisurilor dintre structurile de date este esențială. De exemplu, array-urile permit acces rapid, dar pot fi costisitoare pentru inserări și ștergeri, în timp ce listele înlănțuite oferă modificări eficiente, dar necesită parcurgere pentru acces. Fii pregătit să discuți aceste compromisuri în timpul interviului.
Amintește-ți, comunicarea este la fel de importantă ca și codul. Intervievatorii caută candidați care își pot adapta explicațiile la public. Așa cum s-a discutat în podcastul DataFramed despre viitorul rolurilor din date:
Trebuie să poți livra orice tip de insight într-un mod pe care un copil de șase ani să îl poată înțelege și într-un mod care să mă mulțumească pe mine sau chiar pe cineva și mai tehnic. Deci, dacă îți cunoști cu adevărat domeniul, poți să îl explici foarte simplu, dar poți și să îl faci atât de complicat încât, sincer, doar oamenii cu expertiză tehnică foarte, foarte ridicată îl pot înțelege.
Mo Chen, Data & Analytics Manager at NatWest Group
Învață mai multe despre structurile de date și bazele Python cu aceste cursuri!
course
course
course