course
Intermediate Python
4 घंटा
1.4M
बुनियादी डेटा स्ट्रक्चर की समझ दिखाने के लिए, आपको कोर स्ट्रक्चर और उनके इम्प्लीमेंटेशन पर बहुत आत्मविश्वासी होना चाहिए। नीचे जैसे प्रश्न आपकी इन अवधारणाओं को समझाने और अपने ज्ञान को प्रदर्शित करने की क्षमता को परखेंगे।
डेटा स्ट्रक्चर का वर्गीकरण इस प्रकार किया जाता है:
एरे और लिंक्ड लिस्ट, आइटम के समूहों को संग्रहीत करने के दो तरीके हैं, लेकिन वे अलग तरह से काम करते हैं। आइए मुख्य अंतर देखें:
स्टैक एक क्रमबद्ध सूची है जिसमें आप आइटम्स को एक ही छोर, जिसे टॉप कहते हैं, पर जोड़ते और हटाते हैं। यह लास्ट-इन-फर्स्ट-आउट (LIFO) सिद्धांत का पालन करता है: सबसे हाल में जोड़ा गया तत्व सबसे पहले हटता है।
स्टैक्स का उपयोग कई अनुप्रयोगों में किया जा सकता है, जैसे एक्सप्रेशन इवैल्यूएशन, बैकट्रैकिंग, मेमोरी प्रबंधन, और फ़ंक्शन कॉल्स व रिटर्न।
Python में, लिस्ट बॉक्स से बाहर ही स्टैक की तरह काम करती है: append() पुश है, और pop() टॉप आइटम हटाता है।
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()टॉप की स्थिति को एक इंडेक्स से ट्रैक करके, आप इन ऑपरेशनों को तेज़ और कुशल बना सकते हैं।
क्यू एक फर्स्ट-इन, फर्स्ट-आउट (FIFO) स्ट्रक्चर है — जैसे किसी दुकान में लाइन, जहाँ लोग पीछे से जुड़ते हैं और आगे से निकलते हैं।
Python में, आप अलग-अलग तरीकों से क्यू को इम्प्लीमेंट कर सकते हैं:
एरे या लिस्ट का उपयोग करते हुए और append() तथा pop() मेथड का लाभ उठाते हुए:
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)collections लाइब्रेरी से deque() का उपयोग करते हुए, जो append() और pop() को लिस्ट की तुलना में तेज़ी से करता है:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()इन-बिल्ट मॉड्यूल queue.Queue का उपयोग करते हुए:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()एक बाइनरी ट्री एक डेटा स्ट्रक्चर है जहाँ प्रत्येक नोड के अधिकतम दो बच्चे हो सकते हैं: लेफ्ट चाइल्ड और राइट चाइल्ड। फिर, बाइनरी सर्च ट्री (BST) बाइनरी ट्री का एक विशिष्ट प्रकार है जिसमें अलग-अलग क्रमबद्ध गुण होते हैं: हर नोड के लिए, लेफ्ट सबट्री की सभी keys छोटी होती हैं, राइट सबट्री की सभी keys बड़ी होती हैं, और दोनों सबट्री स्वयं BST होते हैं।
ये गुण खोज, इंसर्शन और डिलीशन जैसे ऑपरेशनों को कुशल बनाते हैं, जो प्रायः बैलेंस्ड ट्री में O(log n) समय जटिलता प्राप्त करते हैं।
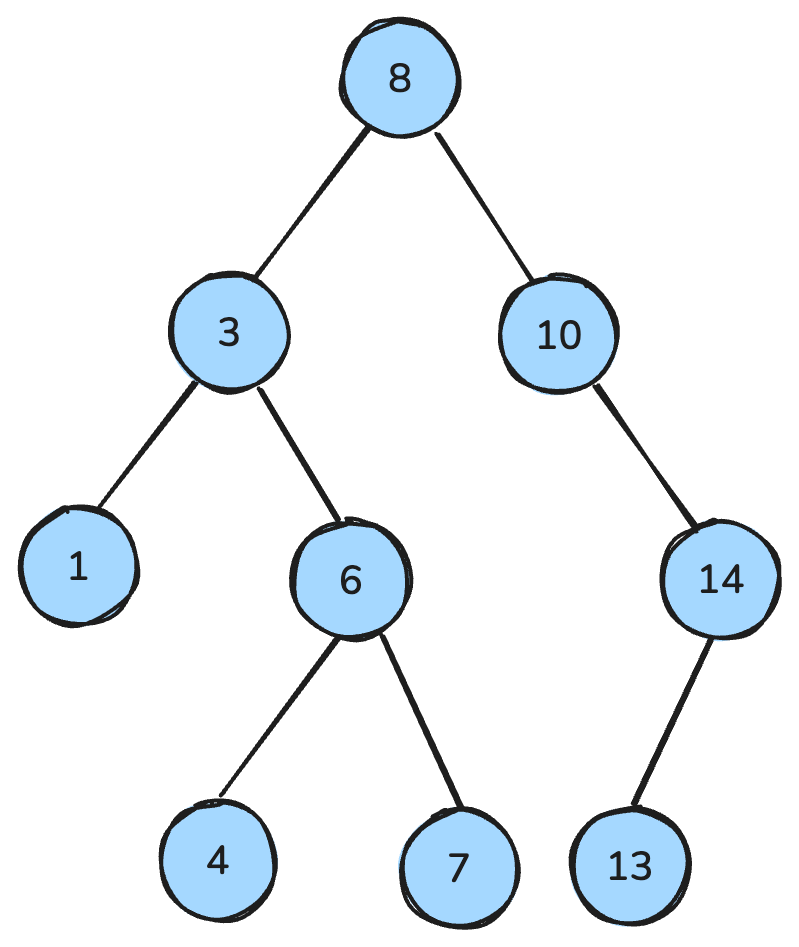
बाइनरी सर्च ट्री। छवि लेखक द्वारा।
हैशिंग एक तकनीक है जो किसी भी आकार के डेटा को लेकर उसे एक निश्चित आकार के मान में बदल देती है, जिसे हैश वैल्यू कहते हैं, जो एक हैश फ़ंक्शन से उत्पन्न होती है।
हैशिंग का एक आम उपयोग हैश टेबल्स में होता है, जहाँ यह keys को एरे में विशिष्ट लोकेशनों से मिलाने में मदद करता है, जिससे डेटा को तेज़ी से ढूंढना और प्राप्त करना आसान हो जाता है। हैशिंग के कई अनुप्रयोग हो सकते हैं, क्रिप्टोग्राफी में पासवर्ड की सुरक्षा से लेकर डिडुप्लिकेशन के माध्यम से डेटा को व्यवस्थित रखने तक।
हीप एक डेटा स्ट्रक्चर है जो पेड़ जैसा दिखता है और विशेष नियमों का पालन करता है।
मैक्स-हीप में, हर पैरेंट अपने बच्चों से बड़ा या बराबर होता है; मिन-हीप में, हर पैरेंट अपने बच्चों से छोटा या बराबर होता है।
हीप्स का उपयोग अक्सर प्रायोरिटी क्यू बनाने में किया जाता है, जो आइटम्स को उनकी प्राथमिकता या वैल्यू के आधार पर क्रमबद्ध करने में मदद करती हैं। ये हीप सॉर्टिंग के लिए भी महत्वपूर्ण हैं, जो डेटा को कुशलता से संगठित करने की एक विधि है।
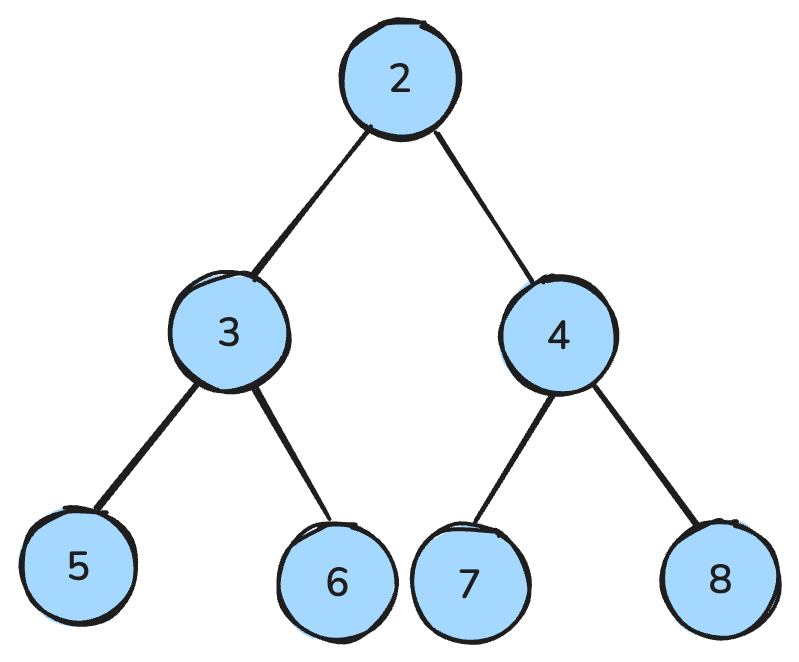
मिन-हीप में सभी पैरेंट नोड्स बच्चों से छोटे होते हैं — छवि लेखक द्वारा।
बुनियादी बातें कवर करने के बाद, अब कुछ इंटरमीडिएट-लेवल के डेटा स्ट्रक्चर इंटरव्यू प्रश्नों पर चलते हैं, जो इन मूलभूत अवधारणाओं को इम्प्लीमेंट और उपयोग करने में आपकी तकनीकी दक्षता का पता लगाते हैं।
एक बैलेंस्ड बाइनरी सर्च ट्री अपने लेफ्ट और राइट सबट्रीज़ के बीच अपेक्षाकृत समान ऊँचाई बनाए रखता है। BST को बैलेंस करना खोज, इंसर्शन और डिलीशन ऑपरेशनों को कुशल बनाए रखने के लिए बहुत महत्वपूर्ण है।
AVL ट्री और रेड-ब्लैक ट्री जैसी तकनीकों का उपयोग आम तौर पर सेल्फ-बैलेंसिंग प्राप्त करने के लिए किया जाता है। AVL ट्री किसी भी नोड के लेफ्ट और राइट सबट्री के बीच अधिकतम 1 की ऊँचाई का अंतर रखते हैं, जबकि रेड-ब्लैक ट्री में और भी कड़े बैलेंस नियम होते हैं।
मिन-हीप आमतौर पर एक लिस्ट द्वारा समर्थित होती है। दो प्रमुख ऑपरेशन हैं insert (जो एक एलिमेंट जोड़ता है और हीप गुण बहाल करने के लिए उसे ऊपर की ओर बबल करता है) और extract_min (जो रूट हटाता है और क्रम बहाल करने के लिए नीचे की ओर सिफ्ट करता है):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valट्राई, जिसे प्रीफ़िक्स ट्री भी कहा जाता है, स्ट्रिंग्स को कुशलतापूर्वक प्राप्त करने और प्रीफ़िक्स मिलान के लिए डिज़ाइन किया गया एक ट्री-आधारित डेटा स्ट्रक्चर है।
ट्राई में, प्रत्येक नोड एक अक्षर का प्रतिनिधित्व करता है, और रूट से नोड्स तक के पथ पूर्ण स्ट्रिंग्स के अनुरूप होते हैं। ट्राई का उपयोग आम तौर पर ऑटोकम्प्लीट फीचर्स, स्पेल-चेकिंग टूल्स और डिक्शनरी के इम्प्लीमेंटेशन में होता है।
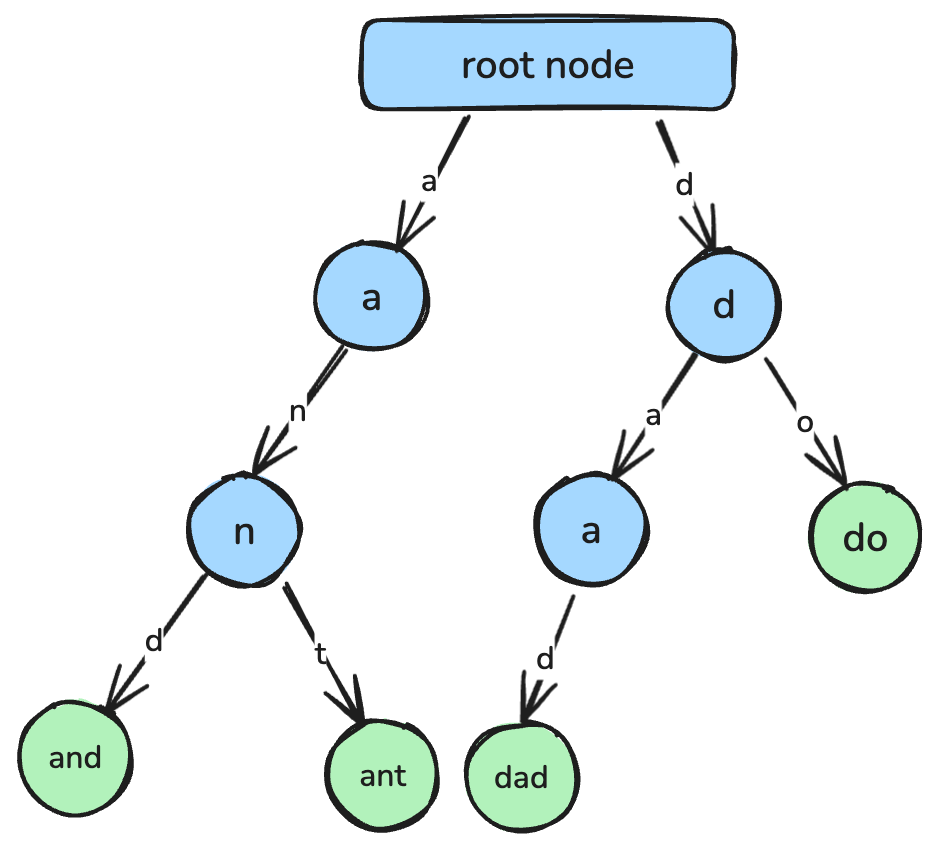
एक ट्राई, जहाँ प्रत्येक नोड एक अक्षर का प्रतिनिधित्व करता है जो मिलकर एक स्ट्रिंग बनाते हैं। छवि लेखक द्वारा।
कोलिजन तब होती है जब दो अलग-अलग keys एक ही इंडेक्स पर हैश हो जाती हैं।
कोलिजन सुलझाने के कई तरीके हैं, जिनमें chaining शामिल है, जहाँ टकराने वाले तत्वों को संबंधित इंडेक्स पर एक लिंक्ड लिस्ट में संग्रहीत किया जाता है, और ओपन एड्रेसिंग, जिसमें एरे में अगला उपलब्ध स्लॉट खोजने के लिए probing विधियों जैसे linear probing, quadratic probing, या double hashing का उपयोग किया जाता है।
एक ग्राफ एक डेटा स्ट्रक्चर है जो वर्टिसेस (नोड्स) के संग्रह और उन्हें जोड़ने वाले एजेस से मिलकर बना होता है। यह संरचना विभिन्न एंटिटीज़ के बीच संबंधों और कनेक्शनों को दर्शाने में उपयोगी है।
डेप्थ-फ़र्स्ट सर्च (DFS) एक एल्गोरिदम है जो बैकट्रैकिंग से पहले हर शाखा में गहराई तक जाकर ग्राफ या ट्री का अन्वेषण करता है। इसे एक स्पष्ट स्टैक का उपयोग करके या रिकर्शन के माध्यम से इम्प्लीमेंट किया जा सकता है। समय जटिलता O(V + E) होती है, जहाँ V वर्टिसेस की संख्या और E एजेस की संख्या है, यानी इसे सभी वर्टिसेस और एजेस की जाँच करनी पड़ सकती है।
ब्रेड्थ-फ़र्स्ट सर्च (BFS) अगले स्तर पर जाने से पहले वर्तमान गहराई स्तर के सभी नोड्स का व्यवस्थित रूप से अन्वेषण करता है। यह अनवेटेड ग्राफ्स में सबसे छोटा पथ खोजने के लिए प्रभावी है और आम तौर पर क्यू का उपयोग करके इम्प्लीमेंट किया जाता है। DFS की तरह, BFS की समय जटिलता भी O(V + E) होती है, जिसमें सभी वर्टिसेस और एजेस की समीक्षा आवश्यक हो सकती है।
सॉर्टिंग एल्गोरिदम कुशल डेटा प्रोसेसिंग के लिए अनिवार्य हैं — ये तेज़ सर्चिंग, बेहतर डेटा विश्लेषण, और आसान डेटा विज़ुअलाइज़ेशन संभव बनाते हैं। उनके बीच चयन करते समय कुछ प्रमुख ट्रेड-ऑफ्स ध्यान में रखने चाहिए:
यहाँ प्रत्येक के साफ़-सुथरे Python इम्प्लीमेंटेशन दिए हैं:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listइंटरव्यू में, ऊपर का उत्तर पर्याप्त है। लेकिन यदि आप अलग दिखना चाहते हैं, तो बताएं कि Python के इन-बिल्ट sorted() और list.sort() टिमसॉर्ट का उपयोग करते हैं, जो मर्ज सॉर्ट और इन्सर्शन सॉर्ट का हाइब्रिड है। यही कारण है कि आप प्रोडक्शन Python में शायद ही कभी सॉर्ट शुरू से लिखते हैं।
ग्राफ में सबसे छोटा पथ खोजने के लिए कई एल्गोरिदम उपयोग किए जा सकते हैं।
अनवेटेड ग्राफ्स के लिए, ब्रेड्थ-फ़र्स्ट सर्च परत दर परत नोड्स का प्रभावी अन्वेषण करता है। वेटेड ग्राफ्स जिनमें एज वेट नॉन-नेगेटिव हों, में डाइकस्ट्रा का एल्गोरिदम निकटतम वर्टेक्स से शुरुआत करके सबसे छोटा पथ पहचानता है।
A* सर्च एल्गोरिदम हीयूरिस्टिक्स का उपयोग करके शेष लागत का अनुमान लगाकर दक्षता बढ़ाता है। एल्गोरिदम का चुनाव ग्राफ की विशेषताओं और विशिष्ट समस्या आवश्यकताओं पर निर्भर करता है।
आइए कुछ उन्नत इंटरव्यू प्रश्नों का अन्वेषण करें, जो अधिक वरिष्ठ भूमिकाओं की तलाश कर रहे उम्मीदवारों या विशिष्ट/जटिल डेटा स्ट्रक्चर का गहरा ज्ञान प्रदर्शित करने वालों के लिए हैं।
डायनेमिक प्रोग्रामिंग जटिल समस्याओं को छोटे-छोटे, ओवरलैपिंग सबप्रॉब्लम्स में बाँटकर हल करने की विधि है। हर बार शुरुआत से शुरू करने के बजाय, आप उन छोटे हिस्सों के समाधानों को सहेजते हैं, जिससे बार-बार वही गणनाएँ करने की आवश्यकता नहीं पड़ती।
यह तरीका दो स्ट्रिंग्स के बीच लॉन्गेस्ट कॉमन सबसेक्वेंस ढूँढने या ग्रिड पर किसी विशेष बिंदु तक पहुँचने की न्यूनतम लागत खोजने के लिए बहुत उपयोगी है।
बी-ट्री डिस्क एक्सेस को कुशल बनाने के लिए डिज़ाइन किए गए बैलेंस्ड ट्री डेटा स्ट्रक्चर हैं। इसकी कुछ विशेषताएँ हैं:
वे बाइनरी सर्च ट्री पर कई लाभ प्रदान करते हैं:
टोपोलॉजिकल सॉर्टिंग एक एल्गोरिदम है जिसका उपयोग डायरेक्टेड एसीक्लिक ग्राफ (DAG) के वर्टिसेस को इस क्रम में व्यवस्थित करने के लिए किया जाता है कि यदि वर्टेक्स u से वर्टेक्स v तक एज है, तो क्रम में u, v से पहले आए। यह आम तौर पर टास्क शेड्यूलिंग में उपयोग होता है — उन कार्यों का क्रम निर्धारित करने में, जिन्हें उनकी निर्भरताओं का सम्मान करते हुए चलना चाहिए — और बिल्ड सिस्टम्स, पैकेज मैनेजर्स, तथा कोर्स पूर्व-आवश्यकता योजना में।
मिन-हीप प्रायोरिटी क्यू का एक विशिष्ट इम्प्लीमेंटेशन है और इसे एक पूर्ण बाइनरी ट्री के रूप में परिभाषित किया जाता है जहाँ प्रत्येक नोड का मान उसके बच्चों के मानों से कम या बराबर होता है, जिससे न्यूनतम तत्व को ढूँढने और निकालने के ऑपरेशन कुशल हो जाते हैं।
दूसरी ओर, प्रायोरिटी क्यू एक अमूर्त डेटा स्ट्रक्चर है जो संबद्ध प्राथमिकता के साथ तत्वों का इन्सर्शन अनुमति देता है, और तत्वों को उनकी प्राथमिकता के क्रम में डी-क्यू किया जाता है। मिन-हीप्स इन ऑपरेशनों को कुशलतापूर्वक प्रबंधित करने की क्षमता के कारण प्रायोरिटी क्यू को इम्प्लीमेंट करने का आम तरीका हैं।
डिजॉइंट-सेट डेटा स्ट्रक्चर, जिसे यूनियन-फाइंड डेटा स्ट्रक्चर भी कहा जाता है, असंबद्ध सेट्स के संग्रह को बनाए रखता है। यह डेटा स्ट्रक्चर दो प्रमुख ऑपरेशनों का समर्थन करता है:
डिजॉइंट सेट्स के कई अनुप्रयोग हैं, लेकिन सबसे सामान्य हैं ग्राफ का न्यूनतम स्पैनिंग ट्री खोजने के लिए क्रूस्कल का एल्गोरिदम और नेटवर्क फ्लो समस्या जिसमें ग्राफ के भीतर कनेक्टेड कंपोनेंट्स का निर्धारण किया जाता है।
सेगमेंट ट्री एक डेटा स्ट्रक्चर है जिसे किसी एरे पर कुशल रेंज क्वेरीज़ और अपडेट्स के लिए डिज़ाइन किया गया है। यह विशेष रूप से उन परिस्थितियों में उपयोगी है जहाँ हमें एरे के किसी विशेष रेंज पर बार-बार योग, न्यूनतम, अधिकतम, या महत्तम समापवर्तक जैसी क्रियाएँ करनी हों।
इसे एक बाइनरी ट्री के रूप में बनाया जाता है, जहाँ प्रत्येक नोड एरे के एक सेगमेंट का प्रतिनिधित्व करता है। ट्री की लीव्स एरे के व्यक्तिगत तत्वों से मेल खाती हैं, जबकि आंतरिक नोड्स अपने चाइल्ड नोड्स के मानों को किए जा रहे ऑपरेशन के अनुसार एग्रीगेट करके जानकारी संग्रहीत करते हैं। ये अपडेट्स और क्वेरीज़ दोनों के लिए O(log n) समय जटिलता प्राप्त करते हैं।
एक सuffix ट्री किसी स्ट्रिंग के हर सuffix को स्टोर करता है ताकि पैटर्न क्वेरीज़ का उत्तर पैटर्न की लंबाई के अनुपातिक समय में दिया जा सके, न कि टेक्स्ट की लंबाई के अनुपातिक समय में। एक वास्तविक सuffix ट्री एज कंप्रेशन का उपयोग करके O(n) स्पेस पाता है और आम तौर पर उक्कोनेन के एल्गोरिदम से बनाया जाता है — लेकिन यह इतना जटिल है कि इंटरव्यूअर शायद ही आपसे 45 मिनट में इसे शुरू से कोड करने की उम्मीद करें।
एक आम समझौता सरल सuffix ट्राई है, जो प्रति नोड एक अक्षर स्टोर करता है। यह O(n²) स्पेस लेता है लेकिन लिखना और समझाना बहुत आसान है। इंटरव्यू में ट्रिक यह है कि इस ट्रेड-ऑफ को जानें और उसे स्पष्ट रूप से बताएं।
यहाँ एक साफ़ Python इम्प्लीमेंटेशन है:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesक्वाडट्रीज़ एक पदानुक्रमित ट्री डेटा स्ट्रक्चर हैं जो दो-आयामी स्पेस को पुनरावृत्त रूप से चार समान चतुर्थांशों में विभाजित करती हैं। यह स्थानिक विभाजन तकनीक छवि प्रसंस्करण, गेम्स में कोलिजन डिटेक्शन, और भू-स्थानिक सूचना प्रणालियों में कुशल स्थानिक डेटा भंडारण और पुनर्प्राप्ति जैसी अनुप्रयोगों के लिए अत्यंत प्रभावी है।
डेटा स्ट्रक्चर का ज्ञान दिखाना महत्वपूर्ण है, लेकिन यह दर्शाना कि आप उन्हें कब और कैसे सही ढंग से उपयोग करते हैं, आपको इंटरव्यू में अलग बनाएगा। इस अनुभाग में, हम देखेंगे कि अपने डेटा स्ट्रक्चर के ज्ञान को व्यावहारिक परिस्थितियों में कैसे लागू करें।
समस्या की रियल-टाइम प्रकृति के कारण, इस चुनौती के लिए कुशल डेटा स्ट्रक्चर आवश्यक होंगे।
मेरे अनुभव में, मैं भौगोलिक डेटा के लिए क्वाडट्रीज़, दूरी और राइडर की तात्कालिकता के आधार पर संभावित मैचों को रैंक करने के लिए प्रायोरिटी क्यू, और ड्राइवर व राइडर लोकेशनों के कुशल लुकअप के लिए हैश टेबल्स का उपयोग करूँगा।
उपयोगकर्ता व्यवहार के आधार पर उत्पादों की प्रभावी सिफारिश करने के लिए हम डेटा स्ट्रक्चर का एक संयोजन उपयोग कर सकते हैं।
एक sparse यूज़र-आइटम मैट्रिक्स उपयोगकर्ता-उत्पाद इंटरैक्शंस को स्टोर करेगा, जबकि हैश टेबल्स उपयोगकर्ताओं और आइटम्स की कुशल मैपिंग करेंगी। प्रायोरिटी क्यू सिफारिशों को रैंक करेंगी, और ग्राफ स्ट्रक्चर यूज़र-आइटम संबंधों को मॉडल कर सकते हैं ताकि कम्युनिटी डिटेक्शन जैसी अधिक परिष्कृत विश्लेषण संभव हो सकें।
स्पैम अकाउंट्स का पता लगाने और हटाने के लिए ग्राफ डेटा स्ट्रक्चर अत्यंत प्रभावी हो सकता है। उपयोगकर्ताओं को नोड्स और उनके कनेक्शनों को एजेस के रूप में दर्शाकर आप नेटवर्क टोपोलॉजी का विश्लेषण कर सकते हैं। घनी क्लस्टरिंग, अलग-थलग नोड्स, और गतिविधि में अचानक उछाल की पहचान करने से संदिग्ध अकाउंट्स को फ़्लैग करने में मदद मिलती है।
मैं रियल-टाइम चैट एप्लिकेशन में डेटा स्ट्रक्चर का संयोजन उपयोग करूँगा।
हैश टेबल्स यूज़र IDs और उनके संबंधित कनेक्शन लिस्ट्स को संग्रहीत करेंगी, जिससे संदेश भेजने के लिए यूज़र्स का त्वरित लुकअप संभव होगा। प्रत्येक यूज़र के लिए क्यू इम्प्लीमेंट की जाएगी ताकि संदेशों का क्रम बना रहे और वे उसी अनुक्रम में वितरित हों जिसमें वे भेजे गए थे। अतिरिक्त रूप से, ट्री, जैसे AVL ट्री, उपयोगकर्ताओं की ऑनलाइन/ऑफ़लाइन स्थिति को कुशलतापूर्वक संग्रहीत और प्राप्त करने के लिए काम आ सकते हैं, जिससे उपलब्धता पर रियल-टाइम अपडेट मिलें।
स्पेल चेकर के लिए तेज़ शब्द-खोज बहुत महत्वपूर्ण है। ट्राई आदर्श डेटा स्ट्रक्चर होगा। ट्राई के प्रत्येक नोड में एक अक्षर होगा, और ट्राई के पथ शब्द बनाएँगे। यह प्रीफ़िक्स-आधारित खोज को तेज़ बनाता है, जिससे स्पेल चेकर गलत वर्तनी के लिए तुरंत सुझाव दे सके।
इस विशेष परिदृश्य में, सेगमेंट ट्री उत्कृष्ट विकल्प के रूप में उभरते हैं। वे रेंज क्वेरीज़ और अपडेट्स को कुशलतापूर्वक संभालने में बहुत अच्छे हैं। हम गेम मैप को 1D एरे के रूप में प्रस्तुत कर सकते हैं, जहाँ प्रत्येक तत्व एक ग्रिड सेल से मेल खाता है। प्रत्येक सेल में किसी स्ट्रक्चर की उपस्थिति या अनुपस्थिति की जानकारी संग्रहीत की जा सकती है।
मुझे पता है कि डेटा स्ट्रक्चर इंटरव्यू की तैयारी चुनौतीपूर्ण हो सकती है, लेकिन एक संरचित दृष्टिकोण इसे अधिक प्रबंधनीय बना सकता है!
एरे, लिंक्ड लिस्ट, स्टैक्स, क्यूज़, ट्री, ग्राफ और हैश टेबल्स जैसे डेटा स्ट्रक्चर के बुनियादी सिद्धांतों पर महारत हासिल करने पर ध्यान दें। उनके सिद्धांतों, वे डेटा को कैसे प्रबंधित करते हैं, और इन्सर्शन, डिलीशन और सर्च जैसे ऑपरेशनों की समय जटिलताओं को समझें।
सिर्फ अवधारणाएँ जानना अच्छा है लेकिन पर्याप्त नहीं। आपको इन डेटा स्ट्रक्चर को शुरुआत से इम्प्लीमेंट करना आना चाहिए। आप DataCamp courses के साथ जुड़कर कोडिंग चुनौतियों का लाभ उठा सकते हैं जो आपकी समस्या-समाधान क्षमता को निखारती हैं।
डेटा स्ट्रक्चर के बीच ट्रेड-ऑफ्स को समझना महत्वपूर्ण है। उदाहरण के लिए, एरे तेज़ एक्सेस देते हैं लेकिन इन्सर्शन और डिलीशन महंगे हो सकते हैं, जबकि लिंक्ड लिस्ट कुशल संशोधन देती हैं लेकिन एक्सेस के लिए ट्रैवर्सल चाहिए। अपने इंटरव्यू के दौरान इन ट्रेड-ऑफ्स पर चर्चा करने के लिए तैयार रहें।
याद रखें, संचार कोड जितना ही महत्वपूर्ण है. इंटरव्यूअर ऐसे उम्मीदवारों की तलाश करते हैं जो अपने स्पष्टीकरण को श्रोताओं के अनुसार ढाल सकें। डेटा भूमिकाओं के भविष्य के बारे में DataFramed पॉडकास्ट में जैसा चर्चा हुआ:
आपको किसी भी प्रकार की अंतर्दृष्टि को इस तरह प्रस्तुत करने में सक्षम होना चाहिए कि एक छह साल का बच्चा उसे समझ सके और इस तरह भी कि वह मुझे या मुझसे भी अधिक तकनीकी व्यक्ति को संतुष्ट कर दे। तो यदि आप वास्तव में अपने विषय के जानकार हैं, तो आप उसे बहुत सरल बना सकते हैं, लेकिन आप उसे इतना जटिल भी बना सकते हैं कि सच कहें तो केवल वही लोग समझ पाएँ जो तकनीकी विशेषज्ञता के मामले में वास्तव में, बहुत आगे हैं।
Mo Chen, Data & Analytics Manager at NatWest Group
इन कोर्सेज़ के साथ डेटा स्ट्रक्चर और Python की बुनियादों के बारे में और जानें!
course
course
course