
Corso
Python - Livello Intermedio
4 h
1.4M
Per dimostrare la tua comprensione delle strutture dati di base, devi essere molto sicuro delle strutture fondamentali e delle loro implementazioni. Domande come le seguenti metteranno alla prova la tua capacità di spiegare queste idee e mostrare la tua conoscenza.
Le strutture dati si classificano come segue:
Array e liste collegate sono due modi per memorizzare gruppi di elementi, ma funzionano in modo diverso. Vediamo le differenze principali:
Uno stack è una lista ordinata in cui aggiungi e rimuovi elementi da un’unica estremità, chiamata top. Segue il principio last-in-first-out (LIFO): l’elemento aggiunto più di recente è il primo a essere rimosso.
Gli stack possono essere usati in varie applicazioni, come la valutazione di espressioni, il backtracking, la gestione della memoria e le chiamate/ritorni di funzione.
In Python, una lista funziona come uno stack pronta all’uso: append() è push e pop() rimuove l’elemento in cima.
my_stack = []
item = 1
my_stack.append(item)
my_stack.pop()Tenendo traccia della posizione del top con un indice, puoi rendere queste operazioni rapide ed efficienti.
Una coda è una struttura first-in, first-out (FIFO) — come una fila al supermercato, dove si entra in fondo e si esce davanti.
In Python, puoi implementare una coda in diversi modi:
Usando un array o una lista e sfruttando i metodi append() e pop():
my_queue = []
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.pop(0)Usando deque() dalla libreria collections, che esegue le funzioni append() e pop() più velocemente delle liste:
from collections import deque
my_queue = deque()
item = 1
# Enqueue
my_queue.append(item)
# Dequeue
my_queue.popleft()Usando il modulo integrato queue.Queue:
from queue import Queue
my_queue = Queue(maxsize = 3)
# Enqueue
my_queue.put(item)
# Dequeue
my_queue.get()Un albero binario è una struttura dati in cui ogni nodo ha al massimo due figli: un figlio sinistro e uno destro. Poi, un binary search tree (BST) è un tipo specifico di albero binario che ha proprietà di ordinamento precise: Per ogni nodo, tutte le chiavi nel sottoalbero sinistro sono più piccole, tutte le chiavi nel sottoalbero destro sono più grandi e entrambi i sottoalberi sono a loro volta BST.
Queste proprietà facilitano operazioni efficienti come ricerca, inserimento ed eliminazione, ottenendo tipicamente una complessità O(log n) negli alberi bilanciati.
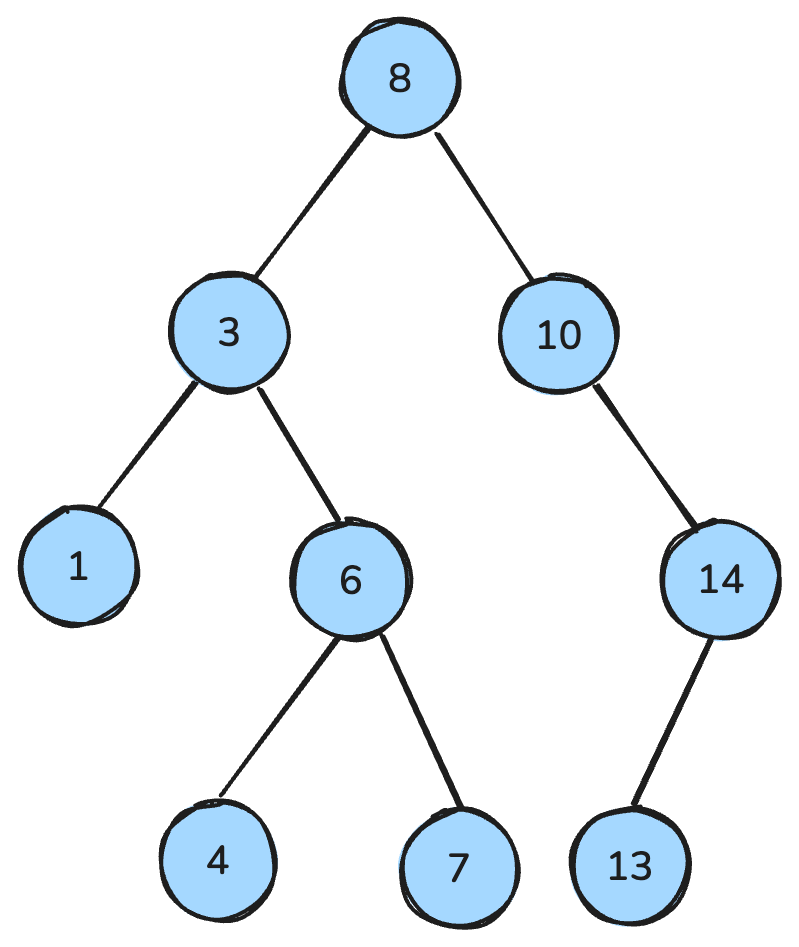
Albero di ricerca binaria. Immagine dell’autore.
L’hashing è una tecnica che prende dati di qualsiasi dimensione e li trasforma in un valore di dimensione fissa chiamato hash value usando una funzione di hash.
Un uso comune dell’hashing è nelle tabelle hash, dove aiuta ad abbinare chiavi a posizioni specifiche in un array, rendendo facile trovare e recuperare rapidamente i dati. L’hashing può avere molte applicazioni, dalla protezione delle password in crittografia all’organizzazione dei dati tramite deduplica.
Un heap è una struttura dati che assomiglia a un albero e segue regole particolari.
In un max-heap, ogni genitore è maggiore o uguale ai suoi figli; in un min-heap, ogni genitore è minore o uguale ai suoi figli.
Gli heap sono spesso usati per creare code di priorità, che aiutano a ordinare gli elementi in base alla loro importanza o valore. Sono importanti anche per l’heap sort, un metodo per organizzare i dati in modo efficiente.
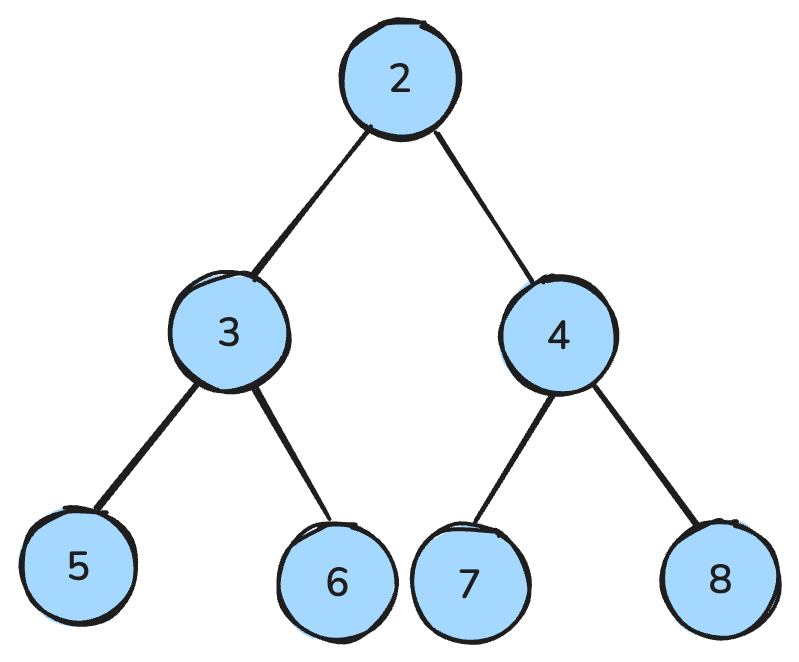
Un min-heap è una struttura in cui tutti i nodi genitori sono più piccoli dei figli — immagine dell’autore.
Dopo aver coperto le basi, passiamo a qualche domanda di livello intermedio sulle strutture dati che esplora la tua padronanza tecnica nell’implementare e usare questi concetti fondamentali.
Un albero di ricerca binaria bilanciato mantiene un’altezza relativamente uguale tra i sottoalberi sinistro e destro. Bilanciare un BST è molto importante per mantenere efficienti le operazioni di ricerca, inserimento ed eliminazione.
Tecniche come gli alberi AVL e gli alberi rosso-neri sono comunemente usate per ottenere l’autobilanciamento. Gli alberi AVL mantengono una differenza di altezza di al massimo 1 tra i sottoalberi sinistro e destro di qualsiasi nodo, mentre gli alberi rosso-neri hanno vincoli di bilanciamento più rigorosi.
Un min-heap è tipicamente basato su una lista. Le due operazioni chiave sono insert (che aggiunge un elemento e lo fa “risalire” per ripristinare la proprietà dell’heap) ed extract_min (che rimuove la radice e fa “scendere” per ripristinare l’ordine):
class MinHeap:
def __init__(self):
self.heap = []
def __len__(self): # Get the size of the heap
return len(self.heap)
def __parent(self, i): # Get the parent index
return (i - 1) // 2
def __left(self, i): # Get the left child index
return 2 * i + 1
def __right(self, i): # Get the right child index
return 2 * i + 2
def __swap(self, i, j): # Swap two elements
self.heap[i], self.heap[j] = self.heap[j], self.heap[i]
def __heapify_up(self, i): # Restore min-heap property after insertion
while i > 0 and self.heap[i] < self.heap[self.__parent(i)]:
self.__swap(i, self.__parent(i))
i = self.__parent(i)
def __heapify_down(self, i): # Restore min-heap property after extraction
while True:
smallest = i
left = self.__left(i)
right = self.__right(i)
if left < len(self) and self.heap[left] < self.heap[smallest]:
smallest = left
if right < len(self) and self.heap[right] < self.heap[smallest]:
smallest = right
if smallest != i:
self.__swap(i, smallest)
i = smallest
else:
break
def insert(self, val): # Insert a value into the heap
self.heap.append(val)
self.__heapify_up(len(self) - 1)
def extract_min(self): # Extract the minimum value from the heap
if not self.heap:
return None
min_val = self.heap[0]
self.heap[0] = self.heap[-1]
self.heap.pop()
self.__heapify_down(0)
return min_valUn trie, noto anche come albero dei prefissi, è una struttura dati basata su albero progettata per un recupero efficiente di stringhe e il matching dei prefissi.
In un trie, ogni nodo rappresenta un singolo carattere e i percorsi dalla radice ai nodi corrispondono a stringhe complete. I trie sono comunemente usati in varie applicazioni, come funzioni di completamento automatico, strumenti di controllo ortografico e implementazione di dizionari.
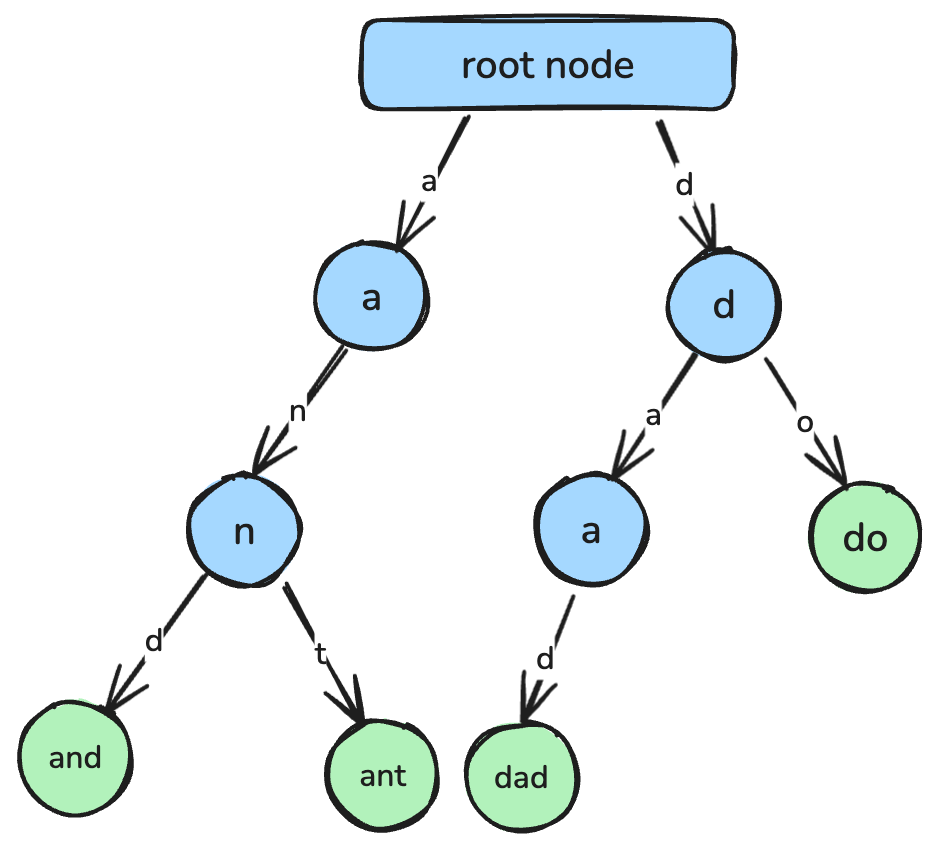
Un trie, dove ogni nodo rappresenta un singolo carattere che si collega per formare una stringa. Immagine dell’autore.
Si verifica una collisione quando due chiavi diverse fanno hash allo stesso indice.
Esistono diversi metodi per risolvere le collisioni, tra cui il chaining, in cui gli elementi in collisione sono archiviati in una lista collegata all’indice corrispondente, e l’open addressing, che consiste nel trovare il prossimo slot disponibile nell’array tramite metodi di probing come il probing lineare, quadratico o il double hashing.
Un grafo è una struttura dati costituita da una collezione di vertici, detti anche nodi, interconnessi da archi. Questa struttura è utile per illustrare relazioni e connessioni tra varie entità.
La visita in profondità (DFS) è un algoritmo che esplora un grafo o un albero andando in profondità in ciascun ramo prima di fare backtracking. Può essere implementata usando uno stack esplicito o tramite ricorsione. La complessità temporale è O(V + E), dove V è il numero di vertici ed E il numero di archi, il che significa che può dover esaminare tutti i vertici e gli archi.
La visita in ampiezza (BFS) esplora sistematicamente tutti i nodi al livello di profondità corrente prima di passare al successivo. È efficace per trovare il percorso più breve nei grafi non pesati ed è tipicamente implementata usando una coda. Come la DFS, la BFS ha complessità O(V + E), richiedendo la revisione di tutti i vertici e gli archi.
Gli algoritmi di ordinamento sono essenziali per l’elaborazione efficiente dei dati — abilitano ricerche più veloci, analisi migliori e visualizzazioni più semplici. Quando li confronti, ci sono alcuni compromessi chiave da considerare:
Ecco implementazioni Python pulite per ciascuno:
# Bubble sort — sorts in place
def bubble_sort(arr):
n = len(arr)
for i in range(n):
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
# Quick sort — sorts in place
def partition(arr, low, high):
pivot = arr[high]
i = low - 1
for j in range(low, high):
if arr[j] <= pivot:
i += 1
arr[i], arr[j] = arr[j], arr[i]
arr[i + 1], arr[high] = arr[high], arr[i + 1]
return i + 1
def quick_sort(arr, low, high):
if low < high:
pi = partition(arr, low, high)
quick_sort(arr, low, pi - 1)
quick_sort(arr, pi + 1, high)
# Merge sort — returns a new sorted list
def merge(left, right):
result = []
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append[right[j]]
j += 1
result.extend(left[i:])
result.extend(right[j:])
return result
def merge_sort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
left_half = merge_sort(arr[:mid])
right_half = merge_sort(arr[mid:])
return merge(left_half, right_half)nums = [3, 1, 4, 1, 5, 9, 2, 6]
bubble_sort(nums) # sorts nums in place
quick_sort(nums, 0, len(nums) - 1) # also in place
sorted_nums = merge_sort(nums) # returns a new listIn un colloquio, la risposta sopra è sufficiente. Ma se vuoi distinguerti, menziona che le funzioni integrate di Python sorted() e list.sort() usano Timsort, un ibrido tra merge sort e insertion sort. Ecco perché quasi mai scrivi un sort da zero nel Python di produzione.
Esistono diversi algoritmi per trovare il percorso più breve nei grafi.
Per i grafi non pesati, la visita in ampiezza esplora efficacemente i nodi strato per strato. Nei grafi pesati con archi non negativi, l’algoritmo di Dijkstra individua il percorso più breve esaminando prima il vertice più vicino.
L’algoritmo di ricerca A* migliora l’efficienza usando euristiche per stimare i costi rimanenti. La scelta dell’algoritmo dipende dalle caratteristiche del grafo e dai requisiti specifici del problema.
Esploriamo alcune domande avanzate per chi punta a ruoli più senior o vuole dimostrare una profonda conoscenza di strutture dati specializzate o complesse.
La programmazione dinamica è un metodo usato per risolvere problemi complessi dividendoli in sottoproblemi più piccoli e sovrapposti. Invece di ripartire da zero ogni volta, tieni traccia delle soluzioni a quelle parti più piccole, così non devi ripetere gli stessi calcoli.
Questo metodo è molto utile per trovare la sottosequenza comune più lunga tra due stringhe o il costo minimo per raggiungere un punto specifico su una griglia.
I B-tree sono strutture dati ad albero bilanciato progettate per un accesso efficiente al disco. Alcune caratteristiche sono:
Offrono diversi vantaggi rispetto agli alberi di ricerca binaria:
L’ordinamento topologico è un algoritmo usato per ordinare i vertici di un grafo aciclico diretto (DAG) tale che, se esiste un arco dal vertice u al vertice v, allora u appare prima di v nell’ordine. È comunemente usato nel task scheduling — determinare l’ordine in cui i compiti devono essere eseguiti rispettando le dipendenze — e in sistemi di build, package manager e pianificazione dei prerequisiti dei corsi.
Un min-heap è una specifica implementazione di una coda di priorità ed è definito come un albero binario completo in cui il valore di ciascun nodo è minore o uguale ai valori dei suoi figli, consentendo operazioni efficienti per trovare ed estrarre l’elemento minimo.
Una coda di priorità è invece una struttura dati astratta che consente l’inserimento di elementi con una priorità associata, con gli elementi estratti in base alla loro priorità. I min-heap sono un modo comune per implementare le code di priorità grazie alla loro capacità di gestire queste operazioni in modo efficiente.
Una struttura dati disjoint-set, nota anche come union-find, mantiene una collezione di insiemi disgiunti. Questa struttura supporta due operazioni principali:
Le applicazioni dei disjoint set sono molte, ma le più comuni sono l’algoritmo di Kruskal per trovare l’albero ricoprente minimo di un grafo e il problema del flusso di rete per determinare le componenti connesse in un grafo.
Un segment tree è una struttura dati progettata per facilitare query e aggiornamenti efficienti su intervalli in un array. È particolarmente utile negli scenari in cui è necessario eseguire ripetutamente operazioni come trovare somma, minimo, massimo o massimo comun divisore su un intervallo specifico di elementi nell’array.
È costruito come un albero binario, in cui ogni nodo rappresenta un segmento dell’array. Le foglie dell’albero corrispondono ai singoli elementi dell’array, mentre i nodi interni memorizzano informazioni che aggregano i valori dei nodi figli in base all’operazione eseguita. Ottengono una complessità temporale O(log n) sia per gli aggiornamenti che per le query.
Un albero dei suffissi memorizza ogni suffisso di una stringa in modo che le query di pattern possano essere risposte in tempo proporzionale alla lunghezza del pattern, non del testo. Un vero suffix tree usa la compressione degli archi per ottenere spazio O(n) ed è tipicamente costruito con l’algoritmo di Ukkonen — ma è abbastanza complesso che raramente ci si aspetta di codificarlo da zero in 45 minuti in un colloquio.
Un compromesso comune è il più semplice suffix trie, che memorizza un carattere per nodo. Usa spazio O(n²) ma è molto più semplice da scrivere e spiegare. Il trucco in un colloquio è conoscere il trade-off e dichiararlo esplicitamente.
Ecco una pulita implementazione Python:
class SuffixTrieNode:
def __init__(self):
self.children = {} # Map of character -> child node
self.indices = [] # Starting positions of suffixes passing through this node
class SuffixTrie:
def __init__(self, text):
self.root = SuffixTrieNode()
self.text = text + "$" # Append a unique terminator
self._build()
def _build(self):
"""Insert every suffix of the text into the trie."""
for i in range(len(self.text)):
self._insert_suffix(i)
def _insert_suffix(self, index):
node = self.root
for i in range(index, len(self.text)):
c = self.text[i]
if c not in node.children:
node.children[c] = SuffixTrieNode()
node = node.children[c]
node.indices.append(index)
def search(self, pattern):
"""Return all starting positions where `pattern` appears in the text."""
node = self.root
for c in pattern:
if c not in node.children:
return []
node = node.children[c]
return node.indicesI quadtree sono una struttura dati ad albero gerarchica che suddivide ricorsivamente uno spazio bidimensionale in quattro quadranti uguali. Questa tecnica di partizionamento spaziale è molto efficace per applicazioni come l’elaborazione di immagini, il rilevamento delle collisioni nei giochi e i sistemi informativi geografici per un’archiviazione e un recupero efficienti dei dati spaziali.
Dimostrare la tua conoscenza delle strutture dati è importante, ma mostrare che sai quando usarle correttamente ti farà distinguere nel colloquio. In questa sezione, rivedremo come applicare le strutture dati a situazioni pratiche.
Data la natura in tempo reale del problema, questa sfida richiederà strutture dati efficienti.
Per esperienza, userei i quadtree per i dati geografici, code di priorità per classificare gli abbinamenti potenziali in base a distanza e urgenza del passeggero e tabelle hash per ricerche efficienti delle posizioni di autisti e passeggeri.
Possiamo sfruttare una combinazione di strutture dati per consigliare efficacemente prodotti in base al comportamento utente.
Una matrice sparsa utente-prodotto memorizzerebbe le interazioni, mentre le tabelle hash mapperebbero efficientemente utenti e articoli. Le code di priorità classificano i suggerimenti e le strutture a grafo possono modellare le relazioni utente-articolo per analisi più sofisticate come il rilevamento di comunità.
Una struttura a grafo può essere molto efficace per rilevare e rimuovere account spam su una piattaforma social. Rappresentando gli utenti come nodi e le loro connessioni come archi, puoi analizzare la topologia della rete. Identificare cluster densamente connessi, nodi isolati e picchi improvvisi di attività può aiutare a segnalare account sospetti.
Userei una combinazione di strutture dati in un’app di chat in tempo reale.
Le tabelle hash memorizzerebbero gli ID utente e le rispettive liste di connessioni, consentendo lookup rapidi degli utenti a cui inviare i messaggi. Code per ogni utente manterrebbero l’ordine dei messaggi, garantendo la consegna nella sequenza di invio. Inoltre, alberi come gli AVL potrebbero essere usati per memorizzare e recuperare in modo efficiente lo stato online/offline degli utenti, permettendo aggiornamenti in tempo reale sulla disponibilità.
Per un correttore ortografico, un lookup efficiente delle parole è molto importante. Un trie sarebbe una struttura dati ideale. Ogni nodo del trie rappresenterebbe una lettera e i percorsi attraverso il trie formerebbero parole. Questo consente ricerche rapide basate su prefissi, permettendo al correttore di suggerire velocemente correzioni per parole errate.
In questo scenario specifico, i segment tree spiccano come un’ottima scelta. Sono molto bravi a gestire query su intervalli e aggiornamenti in modo efficiente. Possiamo rappresentare la mappa del gioco come un array 1D, dove ogni elemento corrisponde a una cella della griglia. Ogni cella può memorizzare informazioni sulla presenza o assenza di una struttura.
So che prepararsi a un colloquio sulle strutture dati può essere impegnativo, ma un approccio strutturato può aiutarti a renderlo più gestibile!
Concentrati nel padroneggiare i concetti fondamentali delle strutture dati, come array, liste collegate, stack, code, alberi, grafi e tabelle hash. Comprendi i principi, come gestiscono i dati e le complessità temporali associate a operazioni come inserimento, eliminazione e ricerca.
Conoscere i concetti è bene ma non basta. Dovresti saper implementare queste strutture dati da zero. Puoi partecipare ai corsi DataCamp per sfruttare le sfide di coding che affinano le tue capacità di problem solving.
Capire i compromessi tra strutture dati è fondamentale. Ad esempio, gli array permettono accesso rapido ma possono essere costosi per inserimenti ed eliminazioni, mentre le liste collegate offrono modifiche efficienti ma richiedono attraversamenti per l’accesso. Preparati a discutere questi trade-off durante il colloquio.
Ricorda, la comunicazione è importante quanto il codice. I selezionatori cercano candidati che sappiano adattare le spiegazioni al pubblico. Come discusso nel podcast DataFramed sul futuro dei ruoli nei dati:
Devi essere in grado di fornire qualsiasi tipo di insight in un modo che anche un bambino di sei anni possa capire e in un modo che soddisfi me o persino qualcuno ancora più tecnico. Quindi, se conosci davvero la materia, puoi semplificarla al massimo, ma puoi anche renderla così complicata che, onestamente, solo le persone con una competenza tecnica davvero, davvero alta possono capirla.
Mo Chen, Data & Analytics Manager at NatWest Group
Approfondisci le strutture dati e le basi di Python con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

